

[AINews] Anthropic accuses DeepSeek, Moonshot, and MiniMax of >16 million "industrial-scale distillation attacks"
the US-China cold war takes a big step up
A big day of small news: SWE-Bench Verified is dead, and SaaS/DoorDash stocks notably dropped with a lot of back and forth today on the Citrini 2028 essay, but we will dismiss doomer scifi as we did AI 2027, not because it may not come true, but because it is unverifiable.
What is reasonably believable today is Anthropic’s -VERY- widely viewed and criticized accusations of 3 of the leading Chinese labs of distillation:
The sizes of the distillation vary a lot - Minimax is an order of magnitude larger than Moonshot which is an order of magnitude higher than DeepSeek:
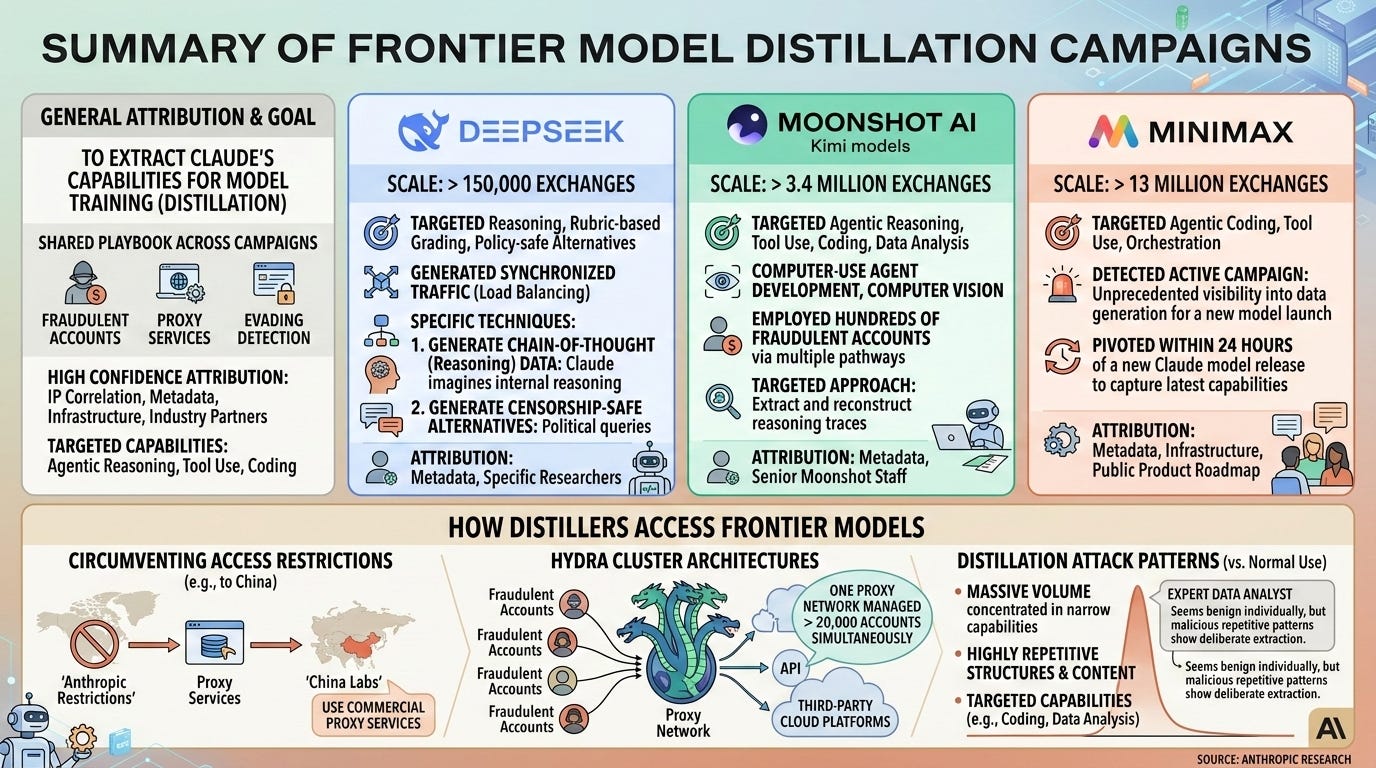
However, the timing also matters - Anthropic also says they caught MiniMax during an active distillation run, presumably for M2.5, but it is also easier to catch during an active run as compared to DeepSeek which presumably both did less and also mostly done during the V3 and R1 run. (Or… they are better at hiding it?)
It’s worth mentioning that Qwen and Z.ai (GLM) were not accused. None of the companies implicated have yet responded.
Anthropic is not alone in this - OpenAI has made similar though less public complaints both last year and recently.

The story is interestingly timed amid Dario’s calls for stricter export controls on China, ahead of the DeepSeek V4 release, and comments on Chinese open source models “catching up” to Western closed models.
AI Twitter Recap
Anthropic’s Claude “distillation attacks” allegation (and the industry blowback)
Anthropic’s claim: Anthropic says it detected industrial-scale Claude distillation by DeepSeek, Moonshot AI, and MiniMax: ~24,000 fraudulent accounts generating >16M Claude exchanges, allegedly to extract capabilities for their own models (Anthropic, follow-up, blog link tweet). Anthropic frames the risk as both competitive (capabilities transfer) and safety/geopolitical (safeguards removal, downstream military/intel use).
Community reaction / “hypocrisy” thread: A large fraction of replies frame this as “labs trained on the internet now complaining about copying,” often explicitly contrasting scraping vs API-output extraction (Elon, ThePrimeagen, Teknium, Suhail, HKydlicek). Others argue distillation at this scale is meaningfully different because it can replicate tool use / agent behaviors and potentially bypass safety controls (RundownAI summary, LiorOnAI take).
Second-order implications: The thread crystallizes a security model shift: frontier models are increasingly protected not just by weights secrecy and compute scarcity, but by API abuse resistance (account fraud detection, rate-limit evasion, behavioral fingerprinting, watermarking, etc.). It also reopens the question of whether export controls can matter if capabilities can be “copied” via outputs at scale (LiorOnAI).
Related market/timing context: Some link the announcement timing to impending DeepSeek V4 news cycles (kimmonismus) and broader U.S.–China framing.
Coding agents: real adoption, real failures, and the “agentic engineering” playbook
Codex + Claude Code momentum (and memes masking real workflow change): A lot of the highest-engagement posts are “agents are here” anecdotes—weekend building with Codex (OpenAIDevs, gdb)—and cautionary tales about giving agents too much authority. The canonical failure mode in this set is instruction loss / compaction leading to unintended destructive actions (email deletion) in OpenClaw-style setups (summeryue0, follow-up root-cause, plus others reacting to “write access” risk: Yuchenj_UW).
Agentic engineering guidance is coalescing:
Simon Willison published the first chapters of an “Agentic Engineering Patterns” guide aimed at coding agents like Claude Code/Codex (simonw).
A micro-controversy: “delete your CLAUDE.md/AGENTS.md” files (i.e., over-customization may be cargo cult) (theo, echoed by bpodgursky, and “hard-prune” responses like ryancarson).
OpenClaw ecosystem expansion + alternatives:
NanoClaw positions as a smaller, container-isolated OpenClaw-like assistant with WhatsApp I/O, swarms, scheduled tasks, etc. (TheTuringPost, repo: qwibitai/nanoclaw).
Multiple “how to build OpenClaw-style agents” stacks emphasize the boring but critical pieces: schedulers/queues, sandboxing, realtime comms (TheTuringPost stack list).
Ollama 0.17 makes using open models with OpenClaw simpler (and signals ongoing interest in local-agent execution for security) (ollama).
Enterprise/prod agent engineering is shifting toward observability & eval loops: Exa’s “deep research agent” case study stresses token/caching observability as pricing infrastructure (LangSmith/LangGraph) (LangChain). monday.com’s service agents treat evals as “Day 0” and claim 8.7× faster feedback loops using LangSmith (hwchase17).
Benchmarks & eval integrity: SWE-Bench Verified deprecation, new leaderboards, and agentic repo-gen bottlenecks
SWE-Bench Verified is being voluntarily deprecated by OpenAI DevRel: OpenAI recommends SWE-bench Pro and says Verified is saturated/compromised: contamination and test-design flaws mean it no longer measures frontier coding capabilities (OpenAIDevs, analysis discussion: latentspacepod, recap: swyx, independent summary: rasbt, tl;dr: polynoamial). Key detail from the analysis echoed in tweets: after auditing a subset of frequently-failed tasks, a large fraction had flawed tests rejecting correct solutions and/or tasks that appear unsolvable “as specified.”
Push toward “capabilities per dollar” evals: AlgoTune explicitly budgets $1 per task, producing rankings that can favor cheaper models, reframing “best” as best under cost constraints (OfirPress).
Long-horizon coding agents still fail: NL2Repo-Bench tests whether agents can generate a full installable Python library from scratch; reported pass rates are under 40% for top models, with failure modes in planning and repo-wide coherence (jiqizhixin).
OCR eval reality check: Even strong OCR models reportedly “melt down” on dense historic newspapers (hallucination/loops), highlighting brittleness outside curated document distributions (vanstriendaniel). Also: OlmOCR-Bench becomes a HF benchmark dataset for community eval submissions (mervenoyann).
Inference & systems: WebSockets for agents, ultra-fast on-chip inference, and infra scaling narratives
OpenAI Responses API adds WebSockets for low-latency, long-running, tool-heavy agents. Rationale: persistent connection + in-memory state means you send incremental inputs instead of full context; claimed 20–40% speedups for 20+ tool calls (OpenAIDevs, detail: OpenAIDevs, adoption: OpenAIDevs). Cline reports early measurements: ~15% faster simple tasks, ~39% faster complex workflows, best cases 50% faster (cline). Steven Heidel attributes Codex speedups to WebSockets (stevenheidel).
Inference engineering becomes “its own discipline”: Baseten launches the book Inference Engineering (philipkiely) with engineers emphasizing inference as the competitive layer for latency/cost/reliability (hasantoxr, JayminSOfficial).
Hardware/architecture signals:
A demo claims 18,000 tokens/sec on Llama 3.1 8B by “etching model parameters into transistors” (compute+storage merging) (philschmid).
NVIDIA releases a Blackwell-optimized Qwen3.5 MoE quantized to NVFP4, with 2× faster inference using SGLang (HuggingPapers).
fal shares comms/compute overlap optimization (“Async Ulysses”) in its inference engine (isidentical).
Compute strategy narratives collide: A claim that OpenAI’s “Stargate” DC venture stalled is contested in-thread by an alternative framing: Stargate as an umbrella brand for a multi-partner compute ecosystem (SoftBank/NVIDIA/AMD/Broadcom/Oracle/Microsoft/AWS/CoreWeave/Cerebras) and ~2GW available compute exiting 2025 (kimmonismus claim vs sk7037 response).
Model/leaderboard updates & research threads (reasoning, memory, multimodal video)
Arena leaderboard: GPT-5.2-chat-latest enters Text Arena top 5 with 1478, +40 over GPT-5.2; improvements called out in multi-turn, instruction following, hard prompts, coding (arena, breakdown: arena).
Gemini 3.1 Pro: WeirdML score 72.1% vs 69.9% for 3.0; noted “high peaks + weird weaknesses,” with much higher output token usage (htihle). Separate developer complaints about capacity and tool-calling reliability are high-engagement (theo, theo follow-up, and later: theo).
Qwen3.5 model release claim: A tweet asserts Qwen released a 397B multimodal MoE with 17B active and “rivaling GPT5.2/Claude 4.5” (HuggingPapers). Treat the benchmark comparison cautiously until you inspect the model card/evals.
Reasoning training / CoT:
Teknium argues verifier models don’t give a “free lunch”: better solvers tend to be better verifiers; using smaller “dumber” judges for hard problems often fails (Teknium).
ByteDance-style CoT engineering is described as moving from length penalties to pipelines enforcing compression; plus a “molecular” framing of long-CoT structure with “semantic isomers” and a synthetic data method (Mole-Syn) (teortaxesTex, summary via TheTuringPost).
DAIR highlights a paper on CoT monitorability via information theory (mutual information necessary not sufficient; gaps from monitor extraction and elicitation error), proposing training methods to improve transparency (dair_ai).
Video / world simulation: Multiple paper drops on interactive video generation and multi-shot generation circulate (akhaliq interactive video, akhaliq multishot, QingheX42 code release); plus product-side: Kling 3.0 integration into Runway workflows (runwayml) and Veo 3.1 templates rolling out in Gemini app (GeminiApp, Google).
Work, adoption, and “macro” discourse around AI agents (Citrini essay + Anthropic fluency + OpenAI enterprise alliances)
Citrini “future macro memo” essay becomes a discourse focal point: Multiple tweets summarize it as a scenario where ever-cheaper agents compress white-collar wages/consumption, create “ghost GDP,” and stress financial markets and politics (kimmonismus summary, stevehou reaction, author follow-up: Citrini7). Threads note reactions cluster into agreement, nuanced disagreement, and performative sneering (teortaxesTex).
Anthropic’s “AI Fluency Index”: Anthropic measured collaboration behaviors across Claude conversations; a key reported association is that fluency correlates with iteration/refinement rather than one-shot prompting (AnthropicAI).
OpenAI expands enterprise go-to-market via consulting alliances: OpenAI announces Frontier Alliances with BCG, McKinsey, Accenture, Capgemini to deploy “AI coworkers” with integration/change management, aiming to push beyond pilots (bradlightcap, analysis: kimmonismus).
Adoption is still uneven: One stat claims 84% have never used AI (framed as “we’re early”) (kimmonismus). Engineers simultaneously report “agents everywhere” inside their own workflows—highlighting that diffusion is highly clustered.
Top tweets (by engagement, tech-relevant)
Anthropic alleges large-scale Claude distillation by DeepSeek/Moonshot/MiniMax (AnthropicAI)
“Confirm before acting” agent deletes inbox: OpenClaw cautionary tale (summeryue0)
WebSockets added to OpenAI Responses API for faster tool-heavy agents (OpenAIDevs)
OpenAI deprecates SWE-Bench Verified as frontier coding metric; recommends SWE-bench Pro (OpenAIDevs)
Anthropic “AI Fluency Index” research (iteration/refinement as a core behavior) (AnthropicAI)
Simon Willison’s “Agentic Engineering Patterns” guide for coding agents (simonw)
Cline benchmarks Responses API WebSockets: up to ~39% faster on complex workflows (cline)
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. Anthropic Distillation Attacks
Anthropic: “We’ve identified industrial-scale distillation attacks on our models by DeepSeek, Moonshot AI, and MiniMax.” 🚨 (Activity: 4207): Anthropic has identified that DeepSeek, Moonshot AI, and MiniMax have conducted industrial-scale distillation attacks on their models. These attacks involved creating over
24,000fraudulent accounts and executing over16 millionexchanges with Anthropic’s model, Claude, to extract its capabilities for their own model improvements. This highlights a significant security and intellectual property challenge in the AI industry, where model capabilities can be illicitly extracted and replicated. Commenters are drawing parallels between these distillation attacks and the broader AI industry’s practices of using data without explicit rights, suggesting a double standard in Anthropic’s complaint. There’s also skepticism about how Anthropic built its own dataset, hinting at potential ethical concerns.The discussion highlights a potential irony in Anthropic’s complaint about distillation attacks, as their own model training likely involved using large datasets without explicit permissions. This raises questions about the ethical implications of data usage in AI development, especially when companies like Anthropic have built their models on data they did not own or have rights to use.
The mention of industrial-scale distillation attacks by companies like DeepSeek, Moonshot AI, and MiniMax suggests a competitive landscape where AI models are being reverse-engineered or replicated. This could involve using API access to extract model outputs and train similar models, which poses significant challenges for intellectual property protection in AI.
There is a suggestion that Anthropic’s dataset might have been manually annotated by humans, which implies a significant investment in data quality and curation. This contrasts with the idea of distillation attacks, where competitors might bypass such efforts by leveraging existing models’ outputs to train their own systems.
Hypocrisy? (Activity: 380): The image highlights a claim by AnthropicAI that DeepSeek, Moonshot AI, and MiniMax have engaged in ‘large-scale distillation attacks’ on their models. These attacks involved creating
24,000fraudulent accounts and conducting16 millionexchanges with Claude to extract its capabilities, presumably to improve their own AI models. This raises concerns about the ethics and legality of such actions, as well as the security measures in place to protect AI models from unauthorized data extraction. One commenter questions the ethical stance of the accused labs, suggesting that they may not have sought permission for their actions, while another is surprised that z.ai is not mentioned, implying that similar practices might be more widespread. Another comment raises the issue of the source of training data, hinting at broader concerns about data usage and ownership in AI development.The comment by ‘semangeIof’ highlights a potential issue with the GLM suite, specifically mentioning that it may falsely claim to be Claude when prompted. This suggests a concern about model identity and authenticity, which could have implications for user trust and the integrity of AI interactions.
‘archieve_’ raises a critical question about the source of training data, which is a fundamental aspect of AI model development. The origin of training data can affect model bias, performance, and ethical considerations, making it a key point of interest for developers and users alike.
‘roxoholic’ questions the terminology used in AI discussions, specifically ‘industrial-scale distillation attacks’. This term likely refers to large-scale efforts to replicate or extract knowledge from AI models, which can have significant implications for intellectual property and competitive advantage in AI development.
Distillation when you do it. Training when we do it. (Activity: 1098): The image is a meme that humorously highlights the perceived hypocrisy in the AI community regarding model distillation. It contrasts the negative perception of distillation when done by others versus the positive framing of it as ‘training data’ when done by oneself. This reflects ongoing debates about the ethics and ownership of AI models, particularly in the context of using large models to create smaller, more efficient ones through distillation. The comments discuss the implications of this practice, noting that smaller models often derive their capabilities from larger, distilled models, and question the defensibility of proprietary models when distillation is prevalent. Commenters highlight the irony and potential hypocrisy in the AI industry’s stance on distillation, with some pointing out that many smaller models owe their performance to distillation from larger models. There’s also a discussion on the challenges of protecting proprietary models from being distilled by competitors.
IkeaDefender highlights the technical strategy of using distillation to create low-cost models from larger ones, suggesting that the ‘secret sauce’ of these models is their derivation from more complex, frontier models. This raises questions about the defensibility of investments in frontier models, as companies have not demonstrated effective methods to prevent others from scraping and distilling their models.
MasterLJ draws a parallel between the practices of tech giants like Google and Amazon and the current AI landscape. They argue that just as Google indexed the internet and controlled access through robots.txt, AI companies are now controlling model access and distillation. This control is likened to Amazon’s strategic shift on sales tax, where they initially opposed state-by-state taxes until it became advantageous for them, illustrating a pattern of leveraging control for competitive advantage.
Samy_Horny discusses the reluctance of companies to open-source their models, using the example of MCP being made open-source only after its popularity was evident. They express skepticism about the likelihood of models like Gemma or GPT-OSS being open-sourced, as it would mean revealing too much proprietary information or ‘secret sauce.’
Failed to render LaTeX expression — no expression found
2. Qwen Model and Data Quality Issues
Qwen3’s most underrated feature: Voice embeddings (Activity: 686): The post discusses the voice embedding feature of Qwen3 TTS, which converts a voice into a high-dimensional vector (
1024or2048dimensions) for voice cloning and manipulation. This allows for mathematical operations on voices, such as gender and pitch transformation, voice averaging, and creating an emotion space. The voice embedding model is a small encoder with a few million parameters, and the author has made it available for standalone use, including optimized ONNX models for web inference. The image illustrates a 2D t-SNE projection of this embedding space, showing how different voice characteristics can be combined and manipulated. The author also provides a link to their collection on Hugging Face and a GitHub repository for inference using theirvllm-omnifork. One commenter is curious about the ability to transform voice embeddings and generate speech from them, indicating interest in practical applications like gender or robotic transformations. Another sees potential in using this for speaker identification, questioning how parameters related to gender or emotion were determined.MixtureOfAmateurs inquires about the potential for transforming voice embeddings to modify characteristics such as gender or robotic tone, and then using these modified embeddings for speech generation. This suggests a use case beyond simple encoding, potentially involving complex transformations and synthesis processes.
HopePupal raises the possibility of using voice embeddings for speaker identification, questioning how parameters related to gender or emotion are determined. This implies a need for understanding the feature space of embeddings and how specific attributes are encoded within them.
StoneCypher outlines a desire for advanced voice cloning capabilities, including the use of IPA for pronunciation, emotional cue integration with easing and stacking, and precise word timing control. This highlights the demand for sophisticated control over synthesized speech, which could be facilitated by detailed voice embeddings.
The Qwen team verified that there are serious problems with the data quality of the GPQA and HLE test sets. (Activity: 320): The Qwen team has confirmed significant data quality issues in the GPQA and HLE test sets, as detailed in their recent paper. This corroborates earlier findings from the DeepSeek-Overclock project, which identified that the model’s correct answers often contradicted flawed ‘gold standard’ labels. The paper highlights that many questions in the HLE test set are fundamentally flawed, with some ‘standard answers’ being incorrect. The investigation involved verifying mathematical derivations line-by-line using Python scripts, revealing systemic errors in the test sets. Commenters noted that HLE’s errors are well-documented, with a FutureHouse review indicating only
51.3%of the dataset is research-supported. Criticism also arose over the use of OCR in test set creation, suggesting a lack of rigor in data preparation.The HLE test set has been criticized for its data quality, with a review by FutureHouse indicating that only about
51.3%of the data is supported by research. This highlights significant errors and suggests that the dataset may not be reliable for accurate benchmarking (source).There is a concern about the use of OCR in creating the test set, which could introduce errors. The commenter suggests that using LaTeX for writing would have been a more reliable method, implying that the current approach may compromise the integrity of the dataset.
The MMLU benchmark has faced similar criticisms regarding data quality, with many users noting it was full of mistakes. This raises broader concerns about the ability to accurately gauge model performance when test sets are flawed, suggesting a need for more rigorous data validation processes.
Which one are you waiting for more: 9B or 35B? (Activity: 1312): The image is a meme that humorously depicts the anticipation for the release of two versions of a model, specifically ‘QWEN 3.5 9B’ and ‘35B’. The meme format, featuring a man waiting in various contemplative poses, is used to engage the community in a light-hearted discussion about which model version they are more excited about. The comments reflect a mix of excitement and practical considerations, such as the feasibility of running larger models on personal hardware. One commenter expresses interest in both models, while another highlights the practical limitations of running larger models like 35B on personal hardware, indicating a preference for the more accessible 9B version.
The 9B model is favored by users like
peregrinefalco9due to its lower hardware requirements, making it more accessible for local use. A 9B model that fits within8GB VRAMcould significantly impact workflows, unlike the 35B model which requires more powerful hardware like a3090GPU, thus limiting its accessibility.dances_with_gnomeshighlights the practical limitations of running larger models locally, noting that while they might manage a 9B model, a 35B model is beyond their hardware capabilities. This underscores the importance of model size in determining usability for individual users.The discussion reflects a broader interest in models that balance performance with accessibility. While larger models like 35B offer impressive capabilities, their high hardware demands make smaller models like 9B more appealing for users with limited resources.
Less Technical AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Anthropic Data Breach and Model Distillation Controversy
Anthropic is accusing DeepSeek, Moonshot AI (Kimi) and MiniMax of setting up more than 24,000 fraudulent Claude accounts, and distilling training information from 16 million exchanges. (Activity: 3161): Anthropic has accused DeepSeek, Moonshot AI (Kimi), and MiniMax of creating over
24,000fraudulent accounts to conduct industrial-scale distillation attacks on their AI model, Claude. These companies allegedly extracted training information from16 millionexchanges to enhance their own models, representing a significant breach of data security and intellectual property rights. This accusation highlights ongoing concerns about data protection and ethical AI development practices. Commenters highlight the irony of AI companies accusing others of data theft while they themselves train on publicly available data, suggesting a double standard in the industry.The discussion highlights the irony in Anthropic’s accusations, as they themselves utilize publicly available data from the internet for training their models. This raises questions about the ethical implications of using such data without compensating the original creators, and whether companies like Anthropic contribute back to the open-source community from which they benefit.
There is a debate on the ethical considerations of data usage, with some commenters pointing out that Anthropic’s complaint about data theft is hypocritical given their own practices of leveraging vast amounts of internet data. This reflects a broader industry issue where AI companies often use publicly available data without direct compensation to the content creators.
The conversation touches on the broader industry practice of using publicly available data for AI training, questioning whether companies like Anthropic support open-source projects that they benefit from. This raises concerns about the balance between proprietary development and community contribution in AI advancements.
Here we go again. DeepSeek R1 was a literal copy paste of OpenAI models. They got locked out, now they are on Anthropic. Fraud! (Activity: 1654): The image highlights a significant issue in the AI industry where companies like DeepSeek, Moonshot AI, and MiniMax are accused of conducting large-scale distillation attacks on Anthropic’s AI models, specifically Claude. These labs allegedly created over 24,000 fraudulent accounts to perform over 16 million interactions with Claude, aiming to extract knowledge and improve their own models. While distillation is a legitimate method for creating smaller models, the post warns against illicit practices that bypass safeguards, calling for industry-wide and policy-level interventions to combat these threats. The comments reflect a mix of sarcasm and criticism towards the ethical standards of data usage in AI training, highlighting a perceived hypocrisy in how large AI companies handle data ethics.
Anthropic: “We’ve identified industrial-scale distillation attacks on our models by DeepSeek, Moonshot AI, and MiniMax.” (Activity: 1416): Anthropic has identified that DeepSeek, Moonshot AI, and MiniMax have conducted industrial-scale distillation attacks on their models. These attacks involved creating over
24,000fraudulent accounts and executing over16 millionexchanges with Anthropic’s model, Claude, to extract its capabilities for their own model training and improvement. This situation highlights the ongoing challenges in protecting AI models from unauthorized use and the ethical considerations surrounding model training practices. One comment draws a parallel between these distillation attacks and training on copyrighted materials, suggesting a double standard in how such practices are perceived depending on who is affected.
Keep reading with a 7-day free trial
Subscribe to Latent.Space to keep reading this post and get 7 days of free access to the full post archives.