

[AINews] Anthropic's Agent Autonomy study
a quiet day lets us dive deep into Anthropic's own version of the METR data
There’s a lot of small tidbits going on, with former guest Fei-Fei Li’s World Labs and The Era of Experience’s David Silver both raising monster $1B rounds, and Anthropic officially blocking OpenClaw using Claude OAuth tokens (consistent with post-OpenCode policy), with OpenAI employees politely reminding everyone that they’re more than welcome to use OpenAI plans instead on the same day (complete coincidence, we are sure).
However, all that will pass. What we’d highlight today is Anthropic’s study of its own API usage patterns, Measuring AI agent autonomy in practice. As you might expect, most usage is coding, but you can start to go down the list of the other uses and pick off the next likely targets for agents:
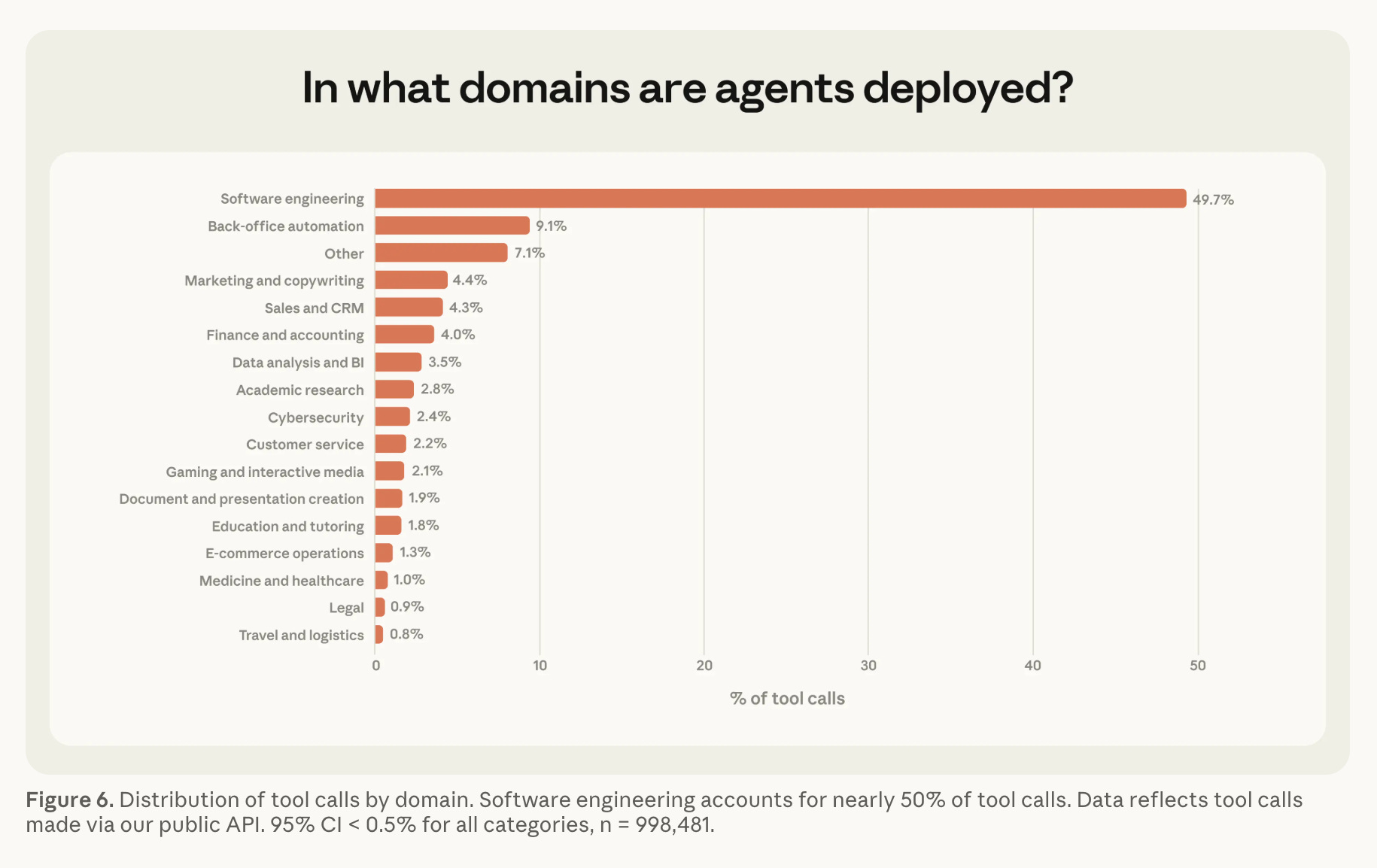
Most of the post is about Claude Code usage. We see Anthropic’s side of the “increasing autonomy story” - starting at 25 mins in Sept to over 45 mins in Jan, with a dip coinciding with the sudden 2x jump in userbase in Jan-Feb 2026, and then rebounding with the release of Opus 4.6.
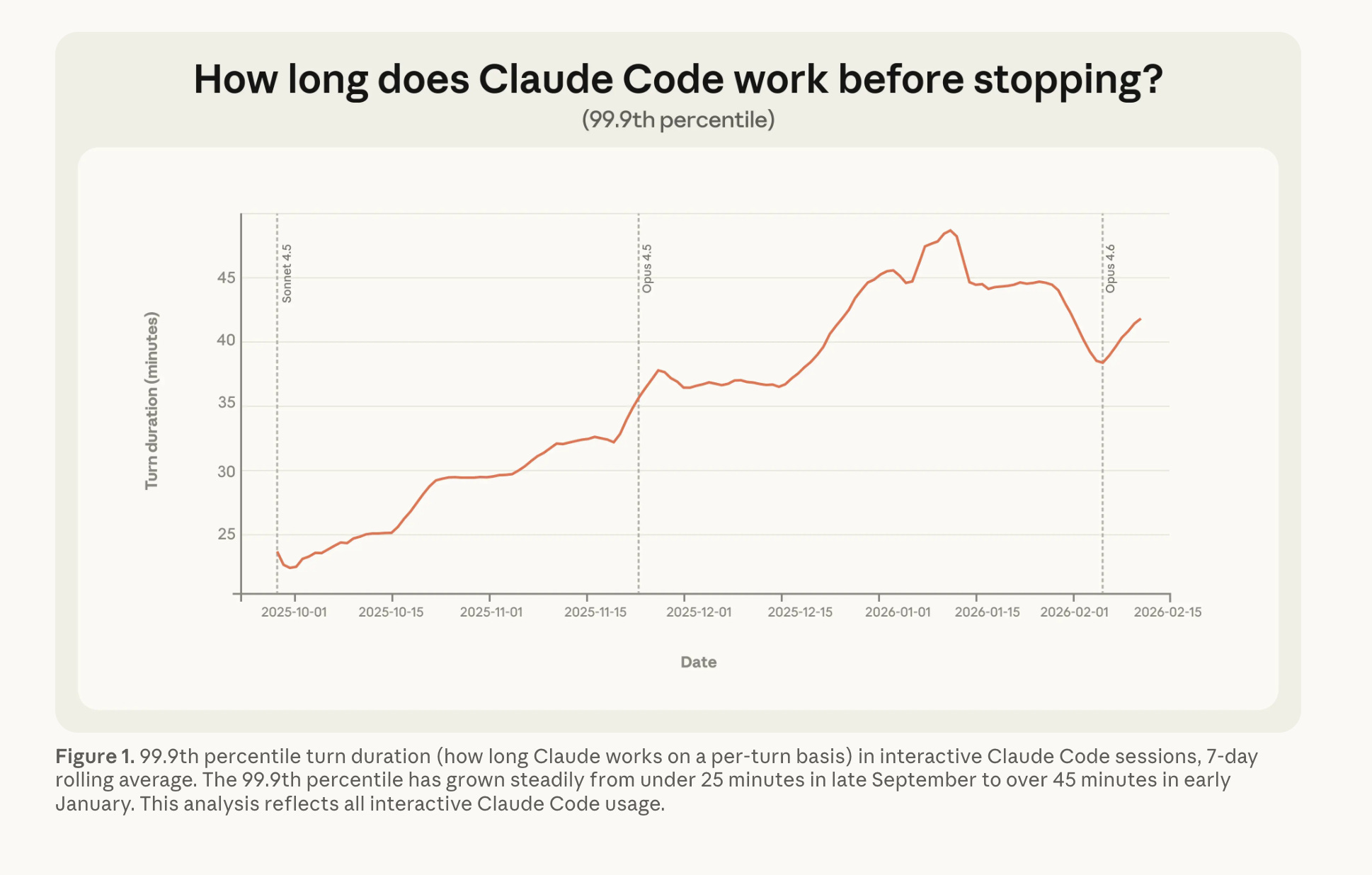
This is a somewhat different but directionally similar story with the famous METR chart, which, as we explain in our upcoming podcast with them, because it picks the 50th percentile success rate of HUMAN EQUIVALENT HOURS instead of the 99.9th percentile long tail autonomy of Claude Code autonomous execution, shows a very different (and volatile at the extremes) trend of almost 5 hours of human work done by agents:
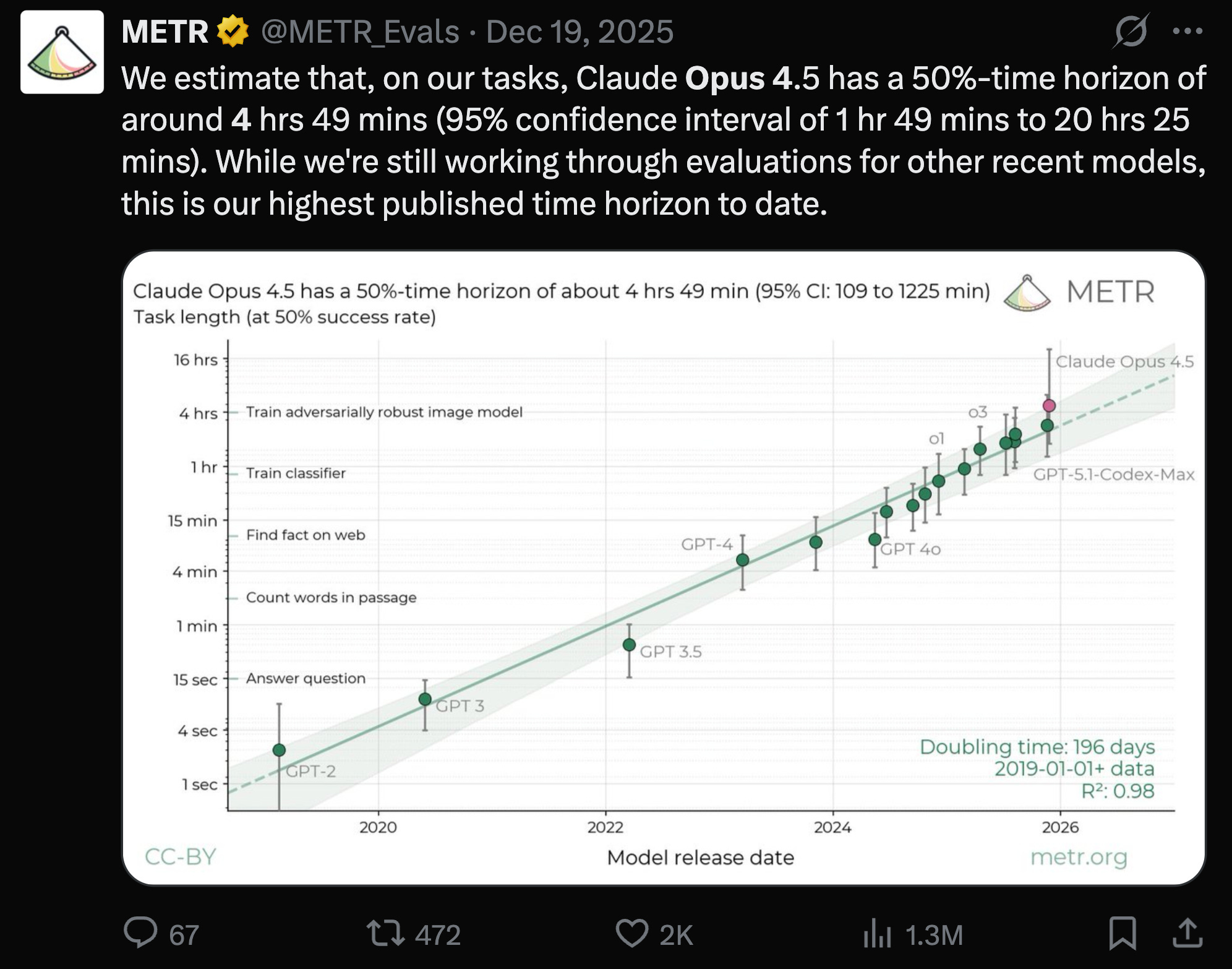
as Anthropic notes:
The METR evaluation captures what a model is capable of in an idealized setting with no human interaction and no real-world consequences. Our measurements capture what happens in practice, where Claude pauses to ask for feedback and users interrupt. And METR’s five-hour figure measures task difficulty—how long the task would take a human—not how long the model actually runs.
(also…
Most Claude Code turns are short. The median turn lasts around 45 seconds, and this duration has fluctuated only slightly over the past few months (between 40 and 55 seconds). In fact, nearly every percentile below the 99th has remained relatively stable.
Enough said. Because Anthropic has full access to Claude Code telemetry, there are other autonomy measures nobody else has. For example… new users start off with 20% auto-approve, and increase to >50% over time with experience
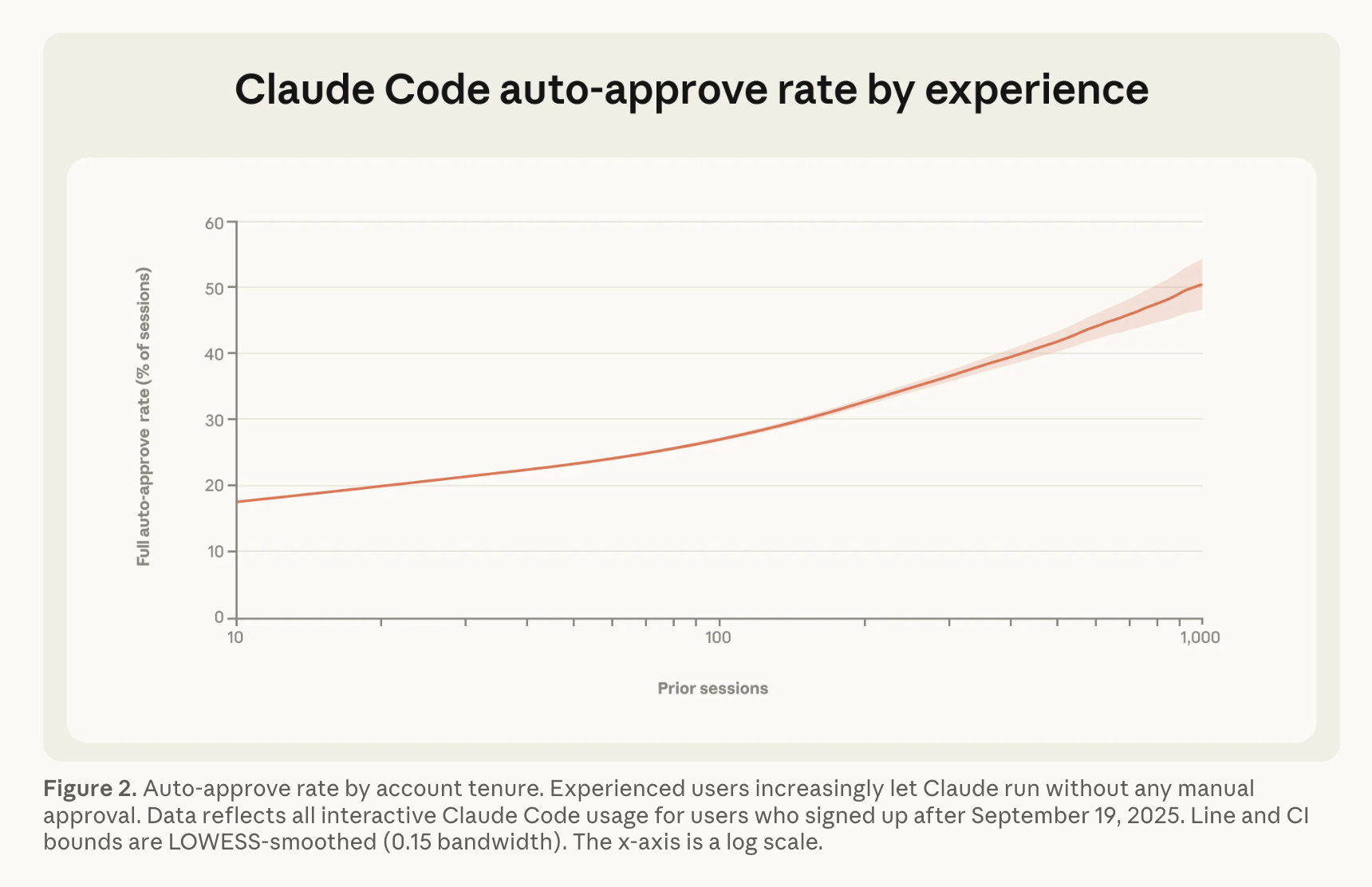
…although they do also interrupt it almost twice as often:
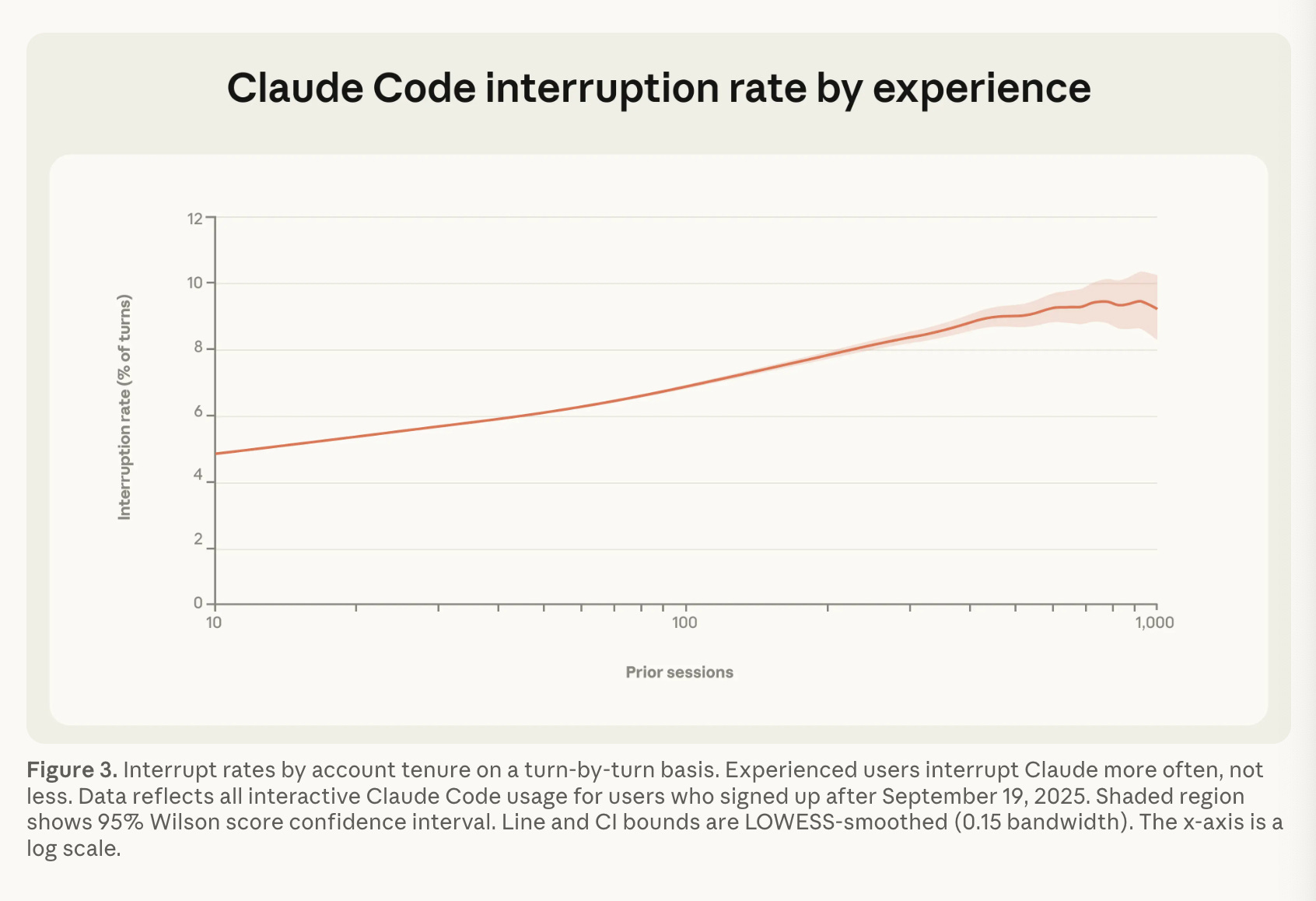
There’s also good analysis of when -Claude- interrupts the flow to ask for clarification, with decent calibration and good breakdown of reasons with frequency:

The rest of the post is more safety oriented, but AI Engineers can take away alot from this agent usage data alone.
AI Twitter Recap
Frontier model + benchmark churn (Claude 4.6, Qwen3.5, GLM‑5, Gemini 3.1 Pro, MiniMax M2.5)
Anthropic Claude Opus/Sonnet 4.6: big jump, big token bill: Artificial Analysis reports Sonnet 4.6 at 51 on its Intelligence Index (up from 43 for Sonnet 4.5 reasoning), sitting just behind Opus 4.6 at 53, but with markedly worse token efficiency: ~74M output tokens to run the suite vs ~25M for Sonnet 4.5 and ~58M for Opus 4.6 (and $2,088 to run the index for Sonnet 4.6 in max effort) (AA summary, token note). Community sentiment echoes “4.6 feels better at critique/architecture” (eshear) while also flagging reliability/product issues around Claude Code (see “Anthropic drama” discourse around SDK/docs and tooling stability) (theo).
Claude in Search Arena + autonomy telemetry: Arena added Opus/Sonnet 4.6 to its search modality leaderboard (arena). Anthropic also published “Measuring AI agent autonomy in practice,” analyzing millions of tool-using interactions: ~73% of tool calls appear human-in-the-loop, only 0.8% appear irreversible, and software engineering is ~50% of tool calls on their API—framed as “autonomy is co-constructed by model + user + product,” motivating post-deployment monitoring (Anthropic, metrics, industry mix).
Qwen 3.5: reasoning efficiency vs “excess thinking”: Multiple posts highlight Qwen3.5’s “overthinking”/token usage as a key axis—both complaints (QuixiAI) and deeper community analysis claiming Qwen3.5-Plus reduces long-chain token bloat vs older Qwen reasoning variants, while noting regressions in non-reasoning mode (ZhihuFrontier). On the distribution side, Qwen3.5-Plus shipped to Vercel AI Gateway (Alibaba_Qwen) and Alibaba Cloud launched a Qwen Coding Plan subscription with fixed monthly pricing and high request caps aimed at coding agents (Alibaba_Qwen).
Qwen3.5-397B-A17B FP8 weights opened: Alibaba released FP8 weights for Qwen3.5‑397B‑A17B, with SGLang support merged and a vLLM PR in flight (vLLM support “next couple days”)—a concrete example of “open weights + immediate ecosystem bring-up” becoming table stakes for competitive OSS releases (Alibaba_Qwen).
GLM‑5 technical report + “agentic engineering” RL infrastructure: The GLM‑5 tech report is referenced directly (scaling01) and summarized as pushing from vibe-coding to “agentic engineering,” featuring asynchronous agent RL that decouples generation from training and introducing DSA to reduce compute while preserving long-context performance (omarsar0). Practitioners called the report unusually detailed and valuable for OSS replication, pointing out optimizer/state handling and agentic data curation details (terminal envs, slide generation, etc.) (Grad62304977).
Gemini 3.1 Pro rumors + “thinking longer”: Early testing anecdotes suggest Gemini 3.1 Pro runs substantially longer “thinking” traces than Gemini 3 Pro and may close the gap with Opus/GPT—paired with skepticism about benchmark trustworthiness and failures on adversarial cases (e.g., mishandling ARC-AGI-2 prompt containing the solution) (scaling01, ARC anecdote).
MiniMax M2.5 appears on community leaderboards: Yupp/OpenRouter posts indicate onboarding MiniMax M2.5 and M2.5 Lightning and tracking results via prompt-vote leaderboards (yupp_ai, OpenRouter benchmark tab).
Agentic coding + harness engineering (Claude Code, Cursor, LangSmith, Deep Agents, SWE-bench process)
Keep reading with a 7-day free trial
Subscribe to Latent.Space to keep reading this post and get 7 days of free access to the full post archives.