[AINews] Moonshot Kimi K2.5 - Beats Sonnet 4.5 at half the cost, SOTA Open Model, first Native Image+Video, 100 parallel Agent Swarm manager
China takes another huge leap ahead in open models
AI News for 1/26/2026-1/27/2026. We checked 12 subreddits, 544 Twitters and 24 Discords (206 channels, and 7476 messages) for you. Estimated reading time saved (at 200wpm): 602 minutes. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
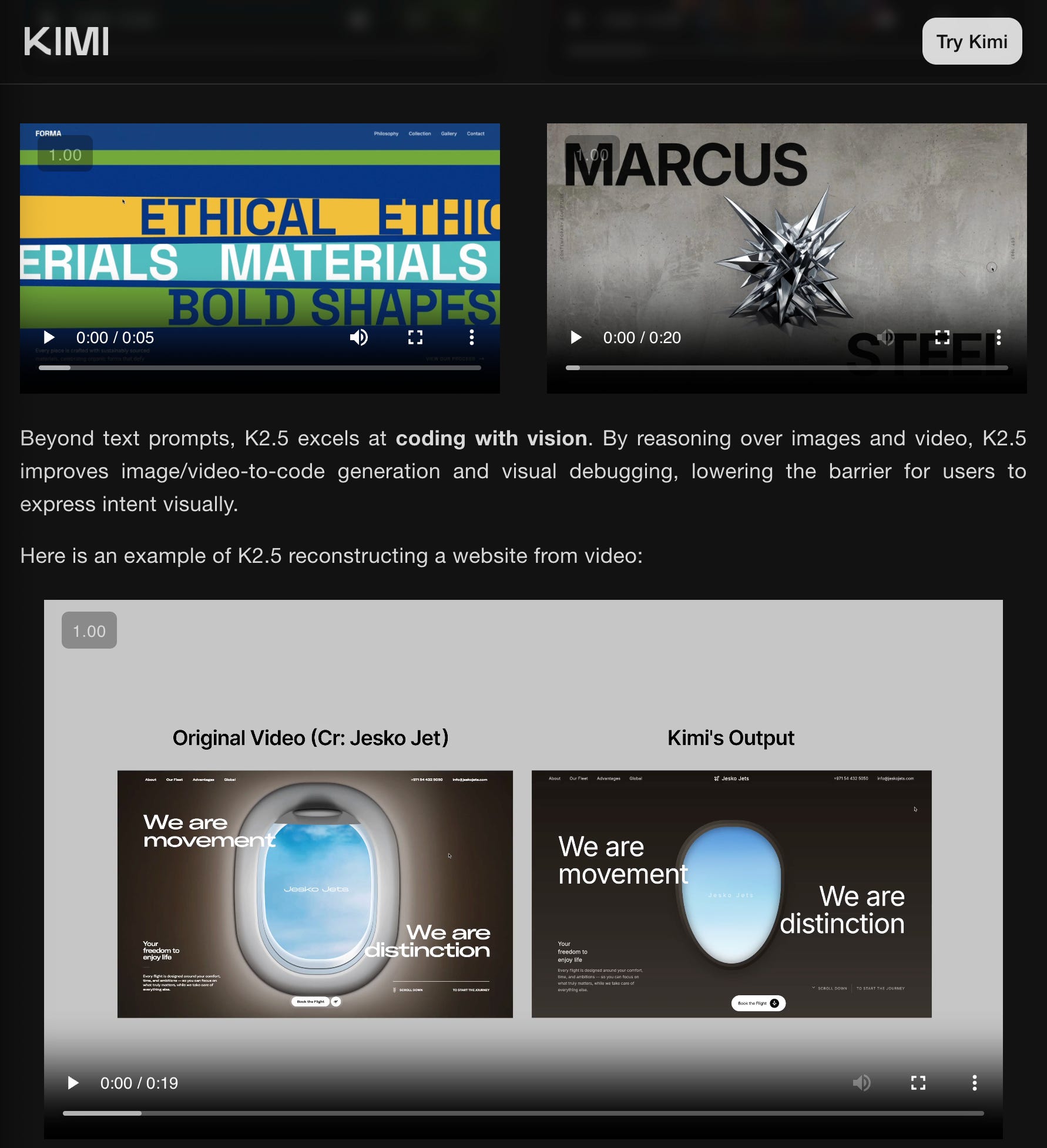
There are a few notables here - Kimi K2.5 is “natively multimodal” for the first time, perhaps borrowing from Kimi VL, but is attributed to “massive-scale vision-text joint pre-training” including VIDEO understanding - “simply upload a screen recording” and K2.5 can reconstruct the website for you:
The fact that this is a continued pretrain that changes arch (+400M param MoonViT vision encoder) is VERY exciting for model training folks who rarely get to see a scaled up model do stuff like this.
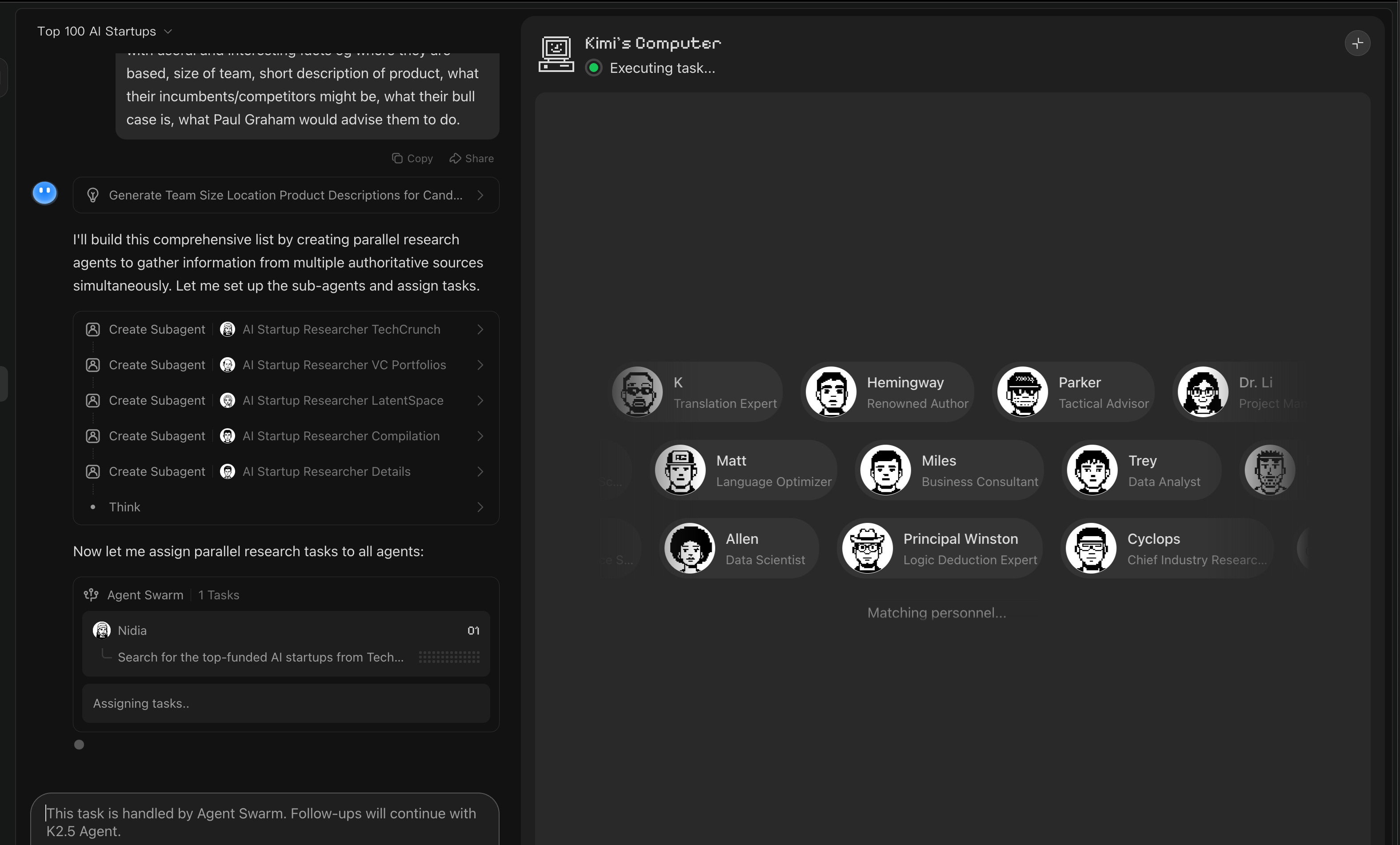
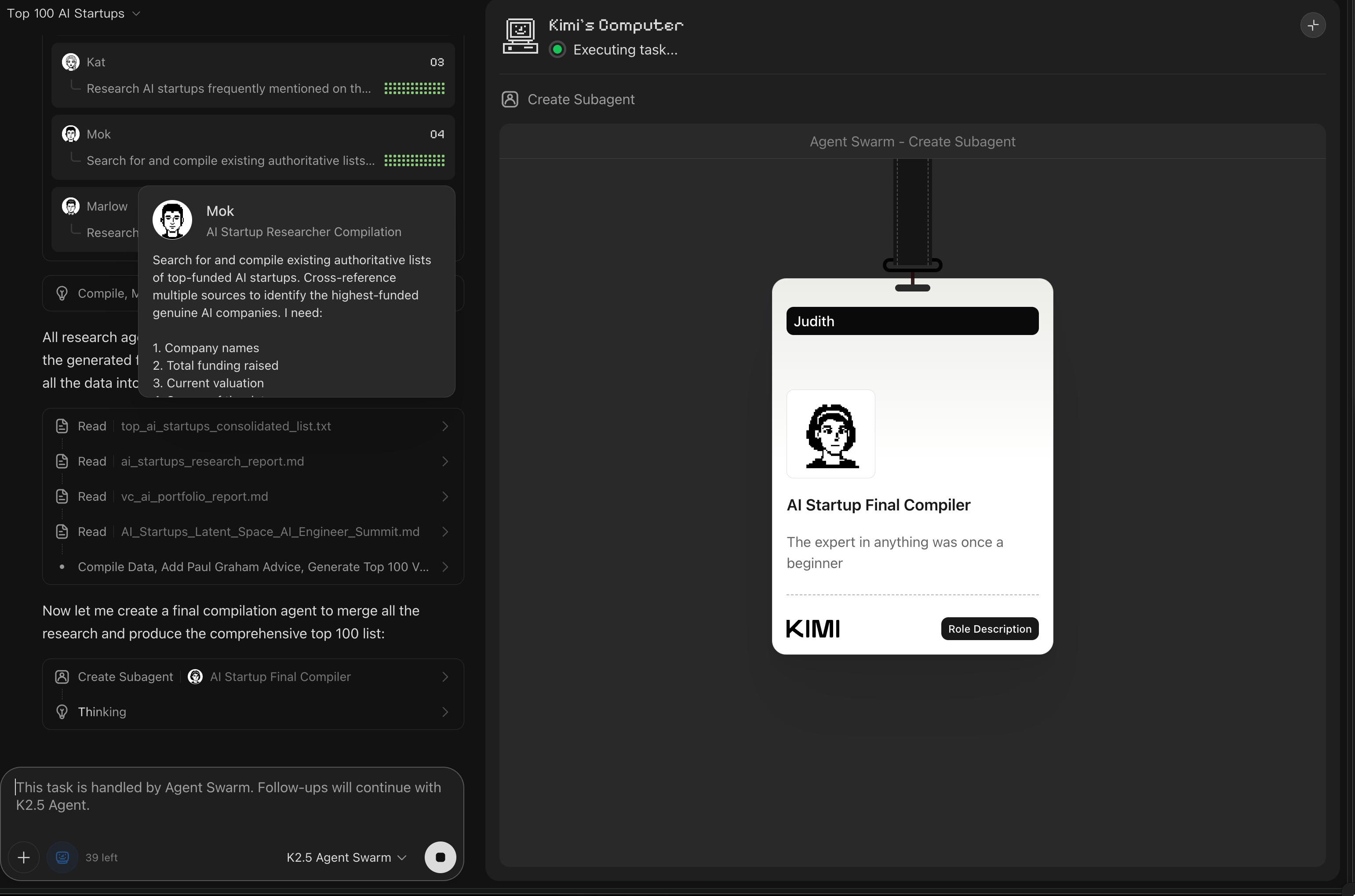
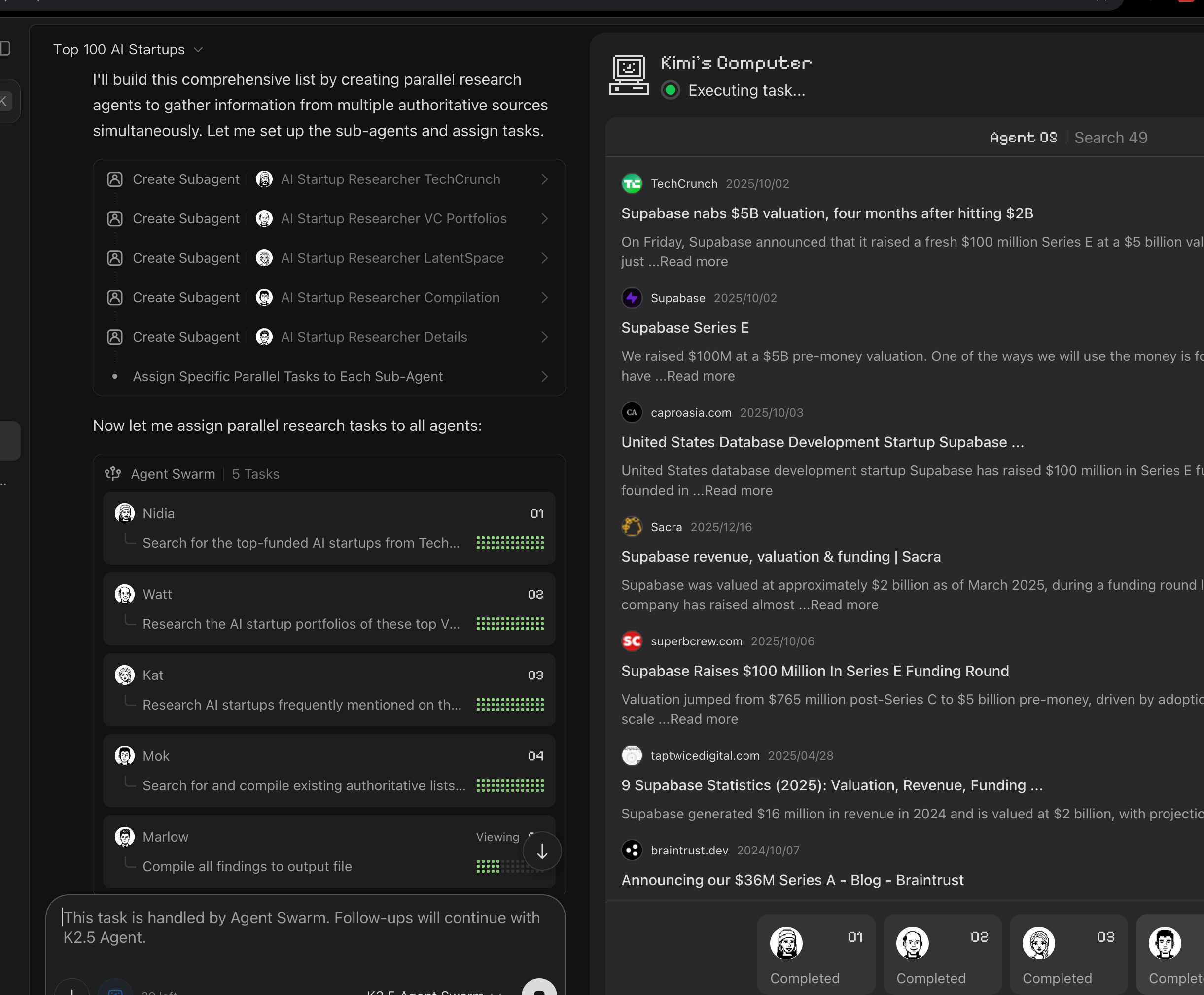
"build a list of the top 100 funded ai startups (make sure they're actually Al - we want things like perplexity and cursor and cognition and elevenlabs and turbopuffer, NOT pretenders... use your best jdugement for criteria) and sort by valuation. use authoritative sources like Techcrunch and TheInformation and top VC firms like Sequoia, Benchmark, Redpoint, Greylock, and Conviction, as well as guests from the Latent Space podcast and Al Engineer conferences. augment the list with useful and interesting facts eg where they are based, size of team, short description of product, what their incumbents/competitors might be, what their bull case is, what Paul Graham would advise them to do."
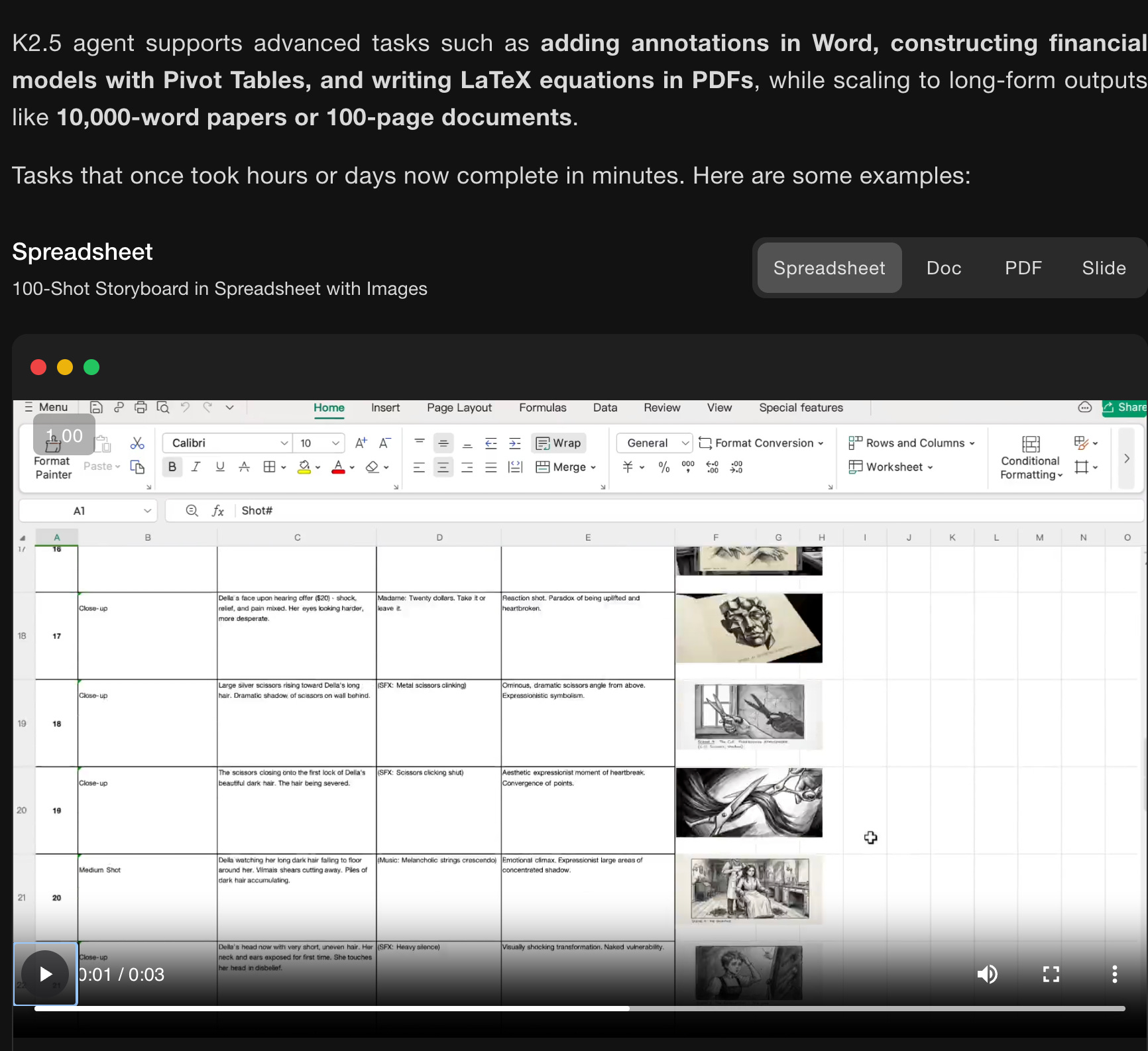
and “Office Productivity” with K2.5 Agent focused on “high-density, large-scale office work end to end”.
This is not empty regurgitation - We saw enough to sign up as a paying subscriber of the Kimi App going forward. As Artificial Analysis notes, the China-Western gap in open models just took another big leap today.
AI Twitter Recap
MoonshotAI’s Kimi K2.5 ecosystem: open multimodal MoE + “Agent Swarm” push
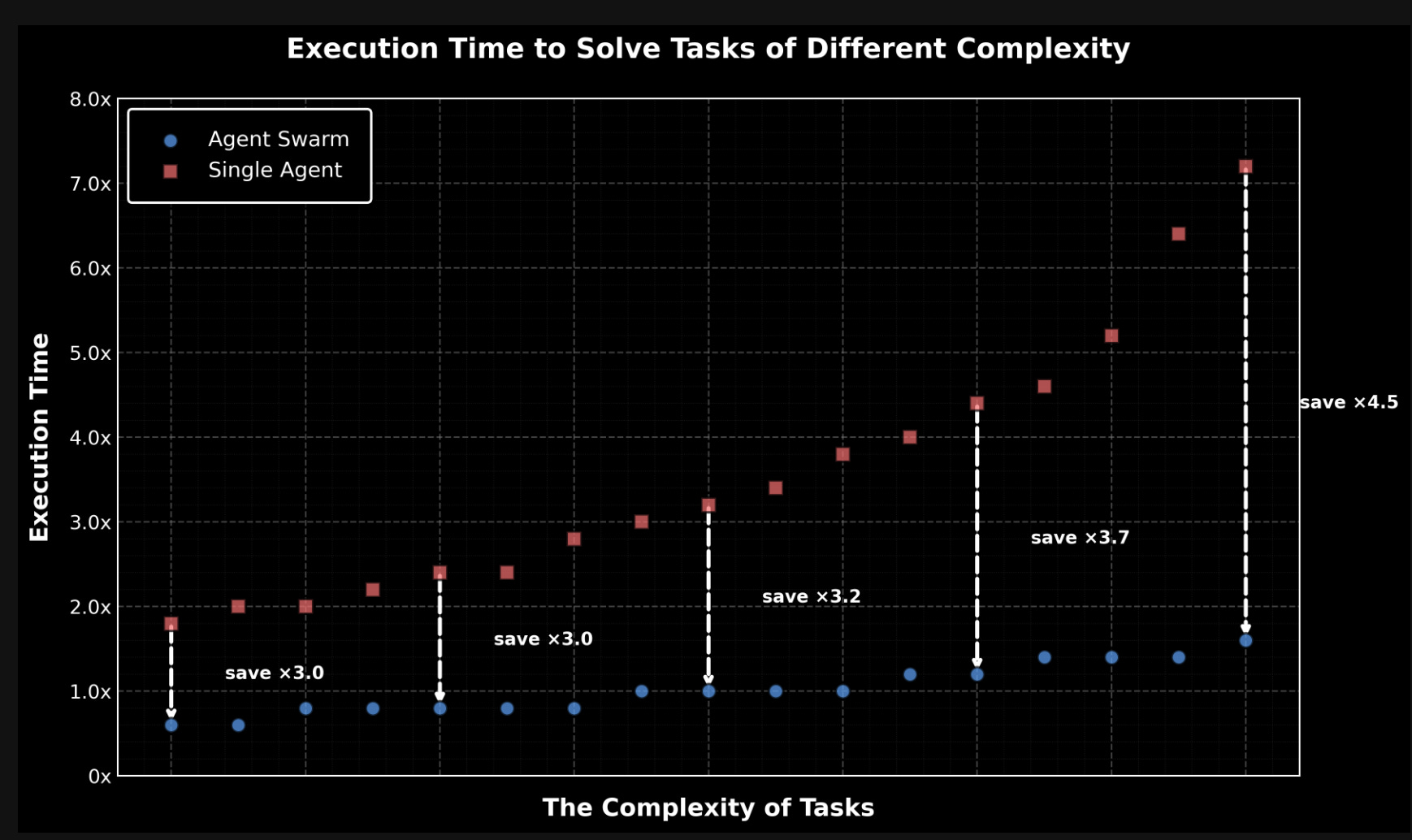
Technical gist (as surfaced by the community): A useful unpacking of K2.5’s reported ingredients—~15T mixed visual+text tokens continual pretraining, context 128K→256K via YaRN, release in INT4 with selective quantization (only routed experts quantized), and the “Agent Swarm” orchestration concept (dynamic generation of subagents; up to 100 parallel subagents / 1,500 steps; wall-time improvements claimed 3–4.5×) is summarized by @TheZachMueller (and points to the technical report).
Benchmarks/third-party eval framing: Artificial Analysis positions K2.5 as “leading open weights” and closer to frontier labs, highlighting GDPval-AA Elo 1309 (agentic knowledge work harness), MMMU Pro 75%, INT4 ~595GB, and a 64% hallucination rate (improved vs K2 Thinking) among other stats: @ArtificialAnlys. LMArena announcements also place K2.5 Thinking at #1 open model in their Text Arena snapshot: @arena. (Treat leaderboards as point-in-time; harness/tooling and prompting matter.)
Distribution and “runs at home” signals: K2.5 landed quickly across infra surfaces: Ollama cloud with launch integrations (@ollama), Together AI listing (@togethercompute), and Fireworks as a partner (Moonshot). A notable local-inference datapoint: K2.5 reportedly runs (slowly but “usable”) on 2× M3 Ultra via MLX with sharded generation, ~21.9 tok/s at high memory use: @awnihannun (+ command snippet here).
Product surface area around Kimi: Moonshot also pushed adjacent tooling: Kimi Code, an Apache-2.0 open-source coding agent integrating with common IDEs/editors (announcement), and an Agent SDK to build custom agents (link). A “Kimi Product” account is explicitly aimed at distributing prompts/use-cases (launch), with a viral demo of “video-to-code” website cloning (demo).
Open “American comeback” at scale: Arcee/Prime Intellect Trinity Large Preview (400B MoE)
Trinity Large Preview release: Arcee dropped Trinity Large initial weights as a “preview” release: @arcee_ai, with expanded details from @latkins. Prime Intellect frames it as an open 400B MoE with 13B active trained with Datology data: @PrimeIntellect. OpenRouter offered limited-time free access: @OpenRouterAI.
Architecture/training details (most concrete technical tweet): A strong technical snapshot comes from @samsja19: 400B/A13B MoE, trained over 17T tokens; 3:1 interleaved local/global gated attention, SWA, NoPE on global layers + RoPE on local layers (as written in tweet), depth-scaled sandwich norm, sigmoid routing, trained with Muon; trained on ~2,000 B300s for a month on Prime Intellect infra, with data curation by DatologyAI.
Data scaling emphasis: Datology’s involvement is highlighted as a major part of the project: “6.5T tokens overall” and “800B synthetic code” (plus multilingual curation) in one team member’s recap: @code_star. Separate recaps mention 8T synthetic as part of 17T: @pratyushmaini.
Ecosystem readiness: vLLM announced day-0 support for serving Trinity Large: @vllm_project. The meta-story in the replies is that a Western org is again attempting frontier-ish pretraining from scratch with an open model, rather than only post-training/evals.
Agents everywhere: orchestration, subagents, planning critics, and IDE/CLI integration
Agent “swarm” vs “subagents” convergence: Kimi’s “Agent Swarm” pitch (dynamic subagent creation) parallels the broader pattern of central orchestrator + parallel specialists. The most explicit “starter pattern” articulation is LangChain’s stateless subagent model (parallel execution + minimized context bloat): @sydneyrunkle. Meanwhile, Kimi’s swarm is framed as trainable orchestration via Parallel-Agent RL (PARL) in community summaries (Zach Mueller).
Reliability via “critique before execute”: Google’s Jules introduced a Planning Critic—a second agent that critiques plans pre-execution, claiming a 9.5% drop in task failure rates: @julesagent. Jules also added “Suggested Tasks” for proactive optimizations: @julesagent.
Coding-agent products intensifying: Mistral shipped Vibe 2.0 upgrades (subagents, user-defined agents, skills/slash commands, and paid plans): @mistralvibe and @qtnx_. MiniMax launched an “Agent Desktop” workspace pitched as more polished than Claude Cowork: @omarsar0 (and MiniMax’s own onboarding automation: @MiniMax_AI).
IDE infrastructure and retrieval: Cursor claims semantic search materially improves coding-agent performance and that indexing for large codebases is “orders of magnitude faster”: @cursor_ai. VS Code continues tightening agent UX (e.g., safer command execution explanations): @aerezk, plus MCP servers returning UI via MCP Apps spec (LIFX control panel example): @burkeholland.
Document AI & multimodal systems: DeepSeek-OCR 2 and “Agentic Vision”
DeepSeek-OCR 2: learned reading order + token compression: DeepSeek-OCR 2 is framed as a shift from fixed raster scans to learned Visual Causal Flow with DeepEncoder V2, including 16× visual token compression (256–1120 tokens/image) and 91.09% OmniDocBench v1.5 (+3.73%); vLLM shipped day-0 support: @vllm_project. Unsloth notes similar headline improvements: @danielhanchen.
Mechanistic intuition (why it matters for pipelines): Jerry Liu provides a clear “why learned order helps” explanation: avoid semantically shredding tables/forms by allowing query tokens to attend to contiguous regions instead of strict left-to-right: @jerryjliu0. Teortaxes adds a pragmatic eval take: OCR 2 is “on par with dots.ocr” and “nowhere near SOTA,” but the ideas may influence later multimodal products: @teortaxesTex.
Gemini “Agentic Vision” = vision + code execution loop: Google is productizing a “Think, Act, Observe” loop where the model writes/executes Python to crop/zoom/annotate images, claiming 5–10% quality boosts across many vision benchmarks: @_philschmid and the official thread: @GoogleAI. This is an explicit move toward tool-augmented vision being first-class, not bolted on.
AI for science & research workflows: OpenAI Prism as “Overleaf with AI”
Prism launch: OpenAI introduced Prism, a free “AI-native workspace for scientists” powered by GPT-5.2, positioned as a unified LaTeX collaboration environment: @OpenAI and @kevinweil. Community summaries frame it as “Overleaf with AI” (proofreading, citations, literature search): @scaling01.
Data/IP clarification: Kevin Weil clarified that Prism follows your ChatGPT data controls and that OpenAI is not taking a share of individual discoveries; any IP-alignment deals would be bespoke for large orgs: @kevinweil.
Why it matters technically: Prism is a product bet that collaboration context + tool integration (LaTeX, citations, project state) becomes a durable advantage—mirroring the “context > intelligence” theme circulating in Chinese discussions about OpenAI infra and org design: @ZhihuFrontier.
Research notes & benchmarks worth tracking (RL, planning, multilingual scaling)
Long-horizon planning benchmark: DeepPlanning proposes verifiable-constraint planning tasks (multi-day travel, shopping) and reports frontier agents still struggle; emphasizes explicit reasoning patterns and parallel tool use: @iScienceLuvr. (This pairs nicely with the “travel planning again” meme: @teortaxesTex.)
RL efficiency and reuse of traces: PrefixRL idea—condition on off-policy prefixes to speed RL on hard reasoning, claiming 2× faster to same reward vs strong baseline: @iScienceLuvr.
Multilingual scaling laws: Google Research announced ATLAS scaling laws for massively multilingual LMs with data-driven guidance on balancing data mix vs model size: @GoogleResearch.
Math research reality check: Epoch’s FrontierMath: Open Problems benchmark invites attempts; “AI hasn’t solved any of these yet”: @EpochAIResearch.
Top tweets (by engagement)
OpenAI launches Prism (AI LaTeX research workspace): @OpenAI
Moonshot founder video introducing Kimi K2.5: @Kimi_Moonshot
Kimi “video-to-code” website cloning demo: @KimiProduct
Ollama: Kimi K2.5 on Ollama cloud + integrations: @ollama
Claude generating 3Blue1Brown-style animations claim (education impact): @LiorOnAI
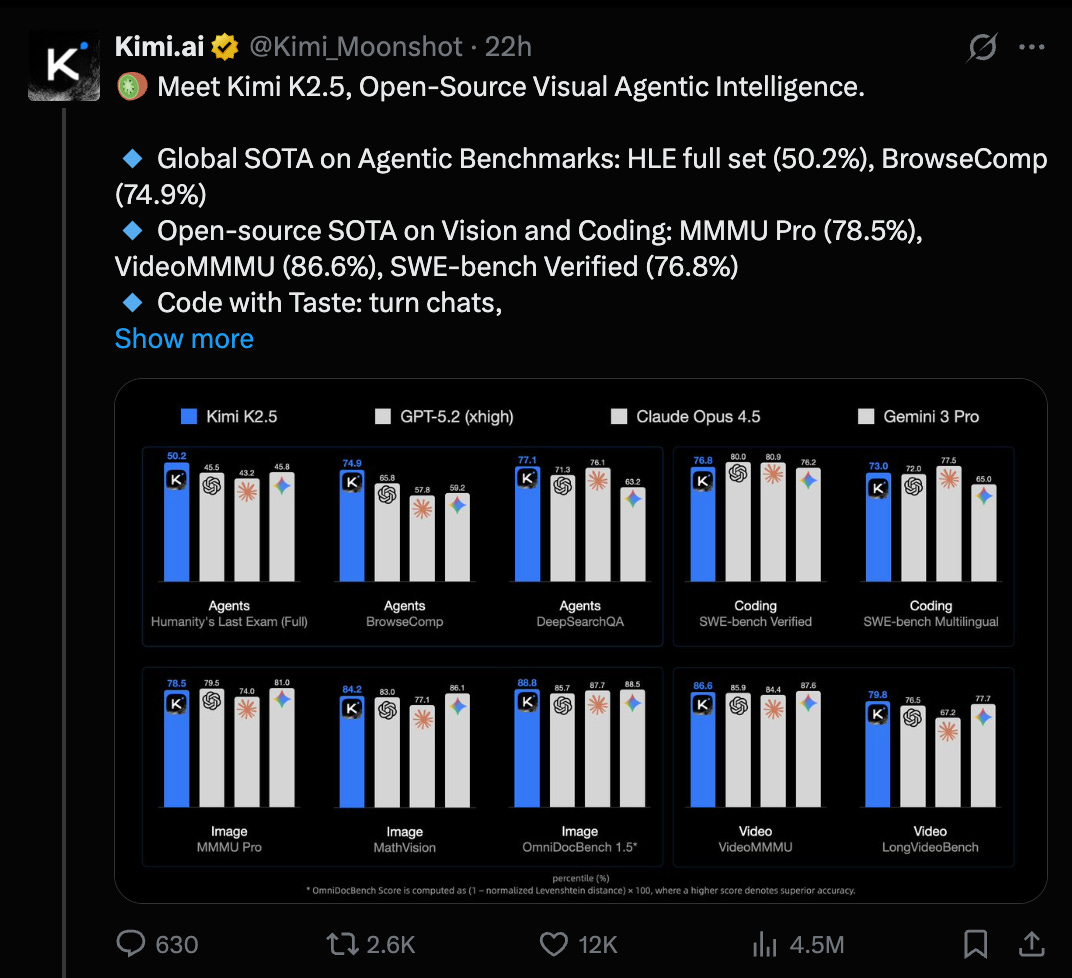
Introducing Kimi K2.5, Open-Source Visual Agentic Intelligence (Activity: 643): Kimi K2.5 is an open-source visual agentic intelligence model that achieves global state-of-the-art (SOTA) performance on agentic benchmarks, with scores of 50.2% on the HLE full set and 74.9% on BrowseComp. It also leads in open-source vision and coding benchmarks, scoring 78.5% on MMMU Pro, 86.6% on VideoMMMU, and 76.8% on SWE-bench Verified. The model introduces an Agent Swarm feature in beta, allowing up to 100 sub-agents to work in parallel, making 1,500 tool calls and operating 4.5× faster than a single-agent setup. Kimi K2.5 is available in chat and agent modes on kimi.com, with additional resources on Hugging Face. A comment highlights the impressive capability of 100 sub-agents working in parallel, suggesting potential for enhanced performance in coding tasks. Another comment notes the banning of the original poster, raising questions about account authenticity.
Asleep_Strike746 highlights the impressive capability of Kimi K2.5 to run 100 sub-agents in parallel, suggesting potential for complex task execution, such as coding tasks. This parallelism could significantly enhance performance in multi-threaded environments, making it a powerful tool for developers looking to automate or optimize workflows.
illusoryMechanist points out the scale of Kimi K2.5 with ‘1T Activated Parameters’ and ‘32B’ (likely referring to the model’s parameter count), indicating a substantial computational capacity. This suggests that Kimi K2.5 could handle large-scale data processing and complex problem-solving tasks, positioning it as a competitive player in the open-source AI landscape.
Capaj shares a practical test of Kimi K2.5 by prompting it to generate an SVG of a fox on a unicycle. The result was described as ‘not too bad’, implying that while the model can handle creative tasks, there might still be room for improvement in terms of output quality or creativity. This kind of testing is crucial for understanding the model’s capabilities in real-world applications.
Jan v3 Instruct: a 4B coding Model with +40% Aider Improvement (Activity: 333): The image is a bar chart titled “Aider Benchmark” that illustrates the performance of various coding models in terms of their pass rate for polyglot code editing. The “Jan-v3-4B-base-INSTRUCT” model leads with a score of 18, significantly outperforming other models like “Qwen3-4B-THINKING-2507” with 12.1 and “Ministral-3-8B-INSTRUCT-2512” with 6.8. This highlights the Jan-v3 model’s high efficiency and over 40% improvement in performance, showcasing its enhanced capabilities in coding tasks. The model is designed for improved math and coding performance, making it a strong candidate for lightweight assistance and further fine-tuning. One commenter appreciates the Qwen 4B 2507 model for small tasks, noting its impressive performance despite its size. Another user shares mixed experiences with the Jan model, praising its ability to use search tools effectively but noting occasional tool call failures and odd responses, possibly due to system prompts.
The Jan v3 Instruct model, a 4 billion parameter coding model, reportedly achieves a 40% improvement in performance with the Aider benchmark. This suggests significant advancements in its ability to handle coding tasks, potentially outperforming other models like Qwen 4B 2507 in specific scenarios. The model’s ability to utilize search tools effectively for code explanation is noted, although there are occasional failures in tool calls and some system prompt issues in web chat applications.
A user reported mixed experiences with the Jan v3 model on chat.jan.ai, highlighting its capability to correctly use search tools and read code for explaining project flows. However, they also noted some tool call failures and irrelevant responses, possibly due to system prompts. The user expressed interest in the model’s potential integration with Claude Code, suggesting it could become a valuable tool for code search and Q&A in daily coding tasks.
The Jan v3 model’s performance in benchmarks is highlighted, with a specific mention of its demo availability at chat.jan.ai. The model’s ability to handle small and easy tasks effectively is compared to Qwen 4B 2507, which is favored for similar tasks. The discussion suggests that Jan v3’s fine-tuning may offer competitive advantages in certain coding scenarios.
deepseek-ai/DeepSeek-OCR-2 · Hugging Face (Activity: 385): DeepSeek-OCR-2 is a state-of-the-art OCR model available on Hugging Face, optimized for document processing with visual causal flow. It requires Python 3.12.9 and CUDA 11.8, and leverages libraries like torch and transformers. The model supports dynamic resolution and uses flash attention for enhanced performance on NVIDIA GPUs. It offers various prompts for document conversion, making it versatile for different OCR tasks. One user highlighted the impressive performance of PaddleOCR-VL when compared using scores from other models, suggesting its potential superiority. Another user shared a demo of DeepSeek OCR 2, noting initial issues with repetition due to user error, which were resolved by adjusting decoding parameters, leading to significantly improved performance over version 1.
A user highlighted the impressive performance of PaddleOCR-VL, suggesting it stands out when compared to other models like B/C/D. This is based on scores reported by a third party, which the user trusts for evaluating model performance. This implies PaddleOCR-VL’s metrics are noteworthy in the context of OCR model comparisons.
Another user shared their experience with implementing a demo for DeepSeek OCR 2 using GPU credits. Initially, they faced issues with repetition due to incorrect parameters, but after adjusting to DeepSeek’s recommended decoding parameters, the performance improved significantly. The user noted that the updated version is much more reliable than its predecessor, DeepSeek OCR v1.
The GitHub repository and paper for DeepSeek OCR 2 were shared, providing resources for those interested in the technical details and implementation of the model. The paper likely contains in-depth information on the model’s architecture, training process, and performance benchmarks, which are crucial for technical evaluation and understanding.
transformers v5 final is out 🔥 (Activity: 503): Transformers v5 from Hugging Face introduces significant performance improvements, particularly for Mixture-of-Experts (MoE) models, achieving 6x-11x speedups. The update simplifies the API by removing slow/fast tokenizers, offering explicit backends and enhanced performance. Additionally, dynamic weight loading is now faster, supporting MoE with quantization, tensor parallelism, and Parameter-Efficient Fine-Tuning (PEFT). A migration guide and detailed release notes are available for users transitioning to this version. One user inquired about the implications of these improvements for running small to medium-sized MoE models locally, suggesting that the enhancements might reduce memory bandwidth constraints. Another user reported a 50% increase in single prompt inference speed and a 100% increase in concurrent inference speed after updating to v5 and vllm 0.14.1.
The Mixture-of-Experts (MoE) model in Transformers v5 shows significant performance improvements, with reported speedups ranging from 6x to 11x. This is particularly relevant for users running models locally, as it suggests that MoE can now utilize compute resources more efficiently, potentially reducing memory bandwidth constraints. This could be beneficial for setups using NVIDIA GPUs or AMD iGPUs, such as the Strix Halo, where compute power is a limiting factor.
A user reported upgrading to Transformers v5 and vllm 0.14.1 from 0.11, resulting in a 50% increase in single prompt inference speed and a 100% increase in concurrent inference speed for 40x workloads. This highlights the significant performance enhancements in the latest version, which could be crucial for applications requiring high throughput and low latency.
The update in Transformers v5 now allows Mixture-of-Experts (MoE) models to work with quantized models, which was not possible before. This advancement enables more efficient model deployment by reducing the model size and computational requirements, making it feasible to run complex models on less powerful hardware without sacrificing performance.
2. Local LLM Hardware and Setup Discussions
216GB VRAM on the bench. Time to see which combination is best for Local LLM (Activity: 577): The post discusses the use of secondhand Tesla GPUs, which offer substantial VRAM at a lower cost, for local large language model (LLM) testing. The author has developed a GPU server benchmarking suite to evaluate the performance of these older GPUs when used in parallel. The image shows a setup with multiple NVIDIA GPUs, highlighting the focus on maximizing VRAM for machine learning tasks. The technical challenge lies in effectively utilizing these GPUs without significant bandwidth loss, as most affordable server motherboards support only a limited number of GPUs. Commenters express skepticism about the practicality of using older Tesla GPUs due to potential issues with token processing speed and cooling requirements. There is interest in how the author manages to connect multiple GPUs without bandwidth loss, and a suggestion that newer systems like DGX Spark might offer better performance for certain tasks.
HugoCortell raises a technical concern about the bandwidth limitations when connecting multiple GPUs to a single PC, noting that most affordable server motherboards support only a few GPUs. This could lead to a significant loss in bandwidth, which is crucial for efficient parallel processing in local LLM setups.
BananaPeaches3 highlights a critical performance issue with older GPUs, particularly in handling large system prompts. They mention that while token generation speed might be acceptable, the prompt processing time can be a bottleneck, especially with prompts as large as 15k tokens. This suggests that newer systems like the DGX Spark might be more efficient despite slightly slower token generation speeds, due to faster prompt processing capabilities.
FullOf_Bad_Ideas points out a limitation in the gpu_box_benchmark, which does not test for serving large models split across multiple GPUs. This is a significant use case for setups with high VRAM, indicating a gap in the benchmark’s ability to evaluate real-world performance for large-scale LLM applications.
3. Teasers and Announcements from AI Labs
The Qwen Devs Are Teasing Something (Activity: 331): The image is a tweet from Tongyi Lab featuring an ASCII art face and a lightning bolt emoji, hinting at an upcoming announcement. The Reddit community speculates that this could be related to a new visual language model, possibly named Z-Image, which has been mentioned in recent ComfyUI pull requests. The timing of the announcement might be strategically planned before the Chinese New Year, aligning with other anticipated releases like K2.5 and potentially q3.5, dsv4, and mm2.2. Commenters are speculating that the announcement is related to the Z-Image model, which has been referenced in recent updates to ComfyUI. There is also a discussion about the timing of the release, suggesting it might be aligned with the Chinese New Year.
The mention of ‘Z-Image’ in ComfyUI PRs suggests a potential new feature or model update related to image processing. This aligns with recent updates where hidden items have been added to collections, indicating ongoing development and testing phases.
There is speculation about the release of several models and updates before the Chinese New Year, including K2.5, q3.5, dsv4, and mm2.2. This timing is strategic as many labs aim to release updates before the holiday break, which is on January 17th this year.
A user speculates about the release of ‘Qwen4 Next 48B A3B’, which could imply a new model or version with specific parameters, possibly indicating advancements in model architecture or capabilities.
Minimax Is Teasing M2.2 (Activity: 322): The image is a tweet from MiniMax teasing an update to their AI model, M2.2, suggesting an imminent release with the phrase “M2.1 slays. M2.2 levels up. #soon.” This indicates a potential upgrade in capabilities or performance from the previous version, M2.1. The context suggests a competitive landscape in AI development, particularly among Chinese labs, with other models like Deepseek v4 and Kimi K3 also expected soon. The mention of ByteDance’s potential closed-source model adds to the competitive tension in the AI space. One comment suggests a shift in focus towards agentic Mixture of Experts (MoEs) models, potentially at the expense of updates to traditional 32B models. Another user expresses anticipation for the new model, highlighting the effectiveness of MiniMax 2.1 in combination with glm 4.7 for coding tasks, and the potential impact of the upcoming versions.
Loskas2025 highlights the use of Minimax 2.1 and GLM 4.7 for coding, noting their excellence. They anticipate that the upcoming Minimax 2.2 and GLM 5, which is currently in training, could significantly enhance performance, suggesting a potential shift in the landscape of coding models.
CriticallyCarmelized compares Minimax favorably to GLM 4.7, even at high quantization levels, indicating that Minimax is competitive in terms of performance. They express optimism that the new version could surpass current models, potentially becoming their preferred choice for local deployment.
lacerating_aura mentions speculation around ‘giga-potato’ being associated with DS4, but points out the lack of concrete evidence for the existence of DS4 or Kimi K3, indicating a gap in confirmed information about these models.
I built a “hive mind” for Claude Code - 7 agents sharing memory and talking to each other (Activity: 422): The post describes a multi-agent orchestration system for Claude Code, featuring 7 specialized agents (e.g., coder, tester, reviewer) that coordinate tasks, share persistent memory using SQLite + FTS5, and communicate via a message bus. The system runs as an MCP server and integrates with Anthropic, OpenAI, or Ollama. It uses a task queue for priority-based coordination, allowing agents to pass context and collaborate effectively. The stack includes TypeScript, better-sqlite3, MCP SDK, and Zod. The project is experimental, MIT licensed, and available on GitHub. A comment questions the similarity to the bmad method, suggesting potential overlap in approach. Another comment humorously questions whether the agents agree with each other, hinting at the complexity of multi-agent consensus.
The project is compared to the BMAD method, which also involves multi-agent systems. The commenter is curious about the differences, suggesting that the approach might be similar in terms of agents sharing memory and communication protocols.
A reference is made to Microsoft’s Autogen, which was released over two years ago as a solution for multi-agent systems. The commenter suggests exploring this resource for potential new ideas, indicating that the concept of multi-agent communication and shared memory is not new and has been explored by major tech companies.
The choice of using Claude Code is questioned, with a suggestion to consider open-source alternatives. This implies a debate on the benefits of proprietary versus open-source platforms for developing multi-agent systems, hinting at potential advantages in community support and collaboration in open-source projects.
Open source Kimi-K2.5 is now beating Claude Opus 4.5 in many benchmarks including coding. (Activity: 597): Kimi-K2.5, an open-source model, is reportedly outperforming Claude Opus 4.5 in several benchmarks, notably in coding tasks. However, the specifics of these benchmarks and the extent of the performance gains are not detailed in the post. The claim suggests a significant advancement in open-source AI capabilities, but lacks comprehensive data to substantiate the comparison. Commenters express skepticism about the claim, highlighting that benchmarks may not fully represent real-world performance. They question the validity of the term ‘many’ benchmarks and suggest that the practical utility of Kimi-K2.5 compared to Claude Opus 4.5 remains unproven.
There is skepticism about the claim that Kimi-K2.5 is outperforming Claude Opus 4.5 in real-world applications, despite benchmark results. Users argue that benchmarks often don’t reflect practical utility, especially in complex tasks like programming where Opus 4.5 might excel in providing solutions in a single prompt.
The discussion highlights a common critique of benchmarks: they may not capture the full capabilities of a model in practical scenarios. Some users express doubt about the claim that Kimi-K2.5 surpasses Opus 4.5, questioning the specific benchmarks and real-world applicability, especially in coding tasks where Opus 4.5 is perceived to have an edge.
One user claims significant practical success with Kimi-K2.5, stating it has replaced reports in a major company, suggesting that at least in some contexts, Kimi-K2.5 may offer substantial utility. This contrasts with the general skepticism about benchmarks translating to real-world performance.
Kimi K2.5 Released!!! (Activity: 1149): The image presents a performance comparison chart for the newly released Kimi K2.5, which is claimed to set a new state-of-the-art (SOTA) in agentic tasks. The chart compares Kimi K2.5 against other models like GPT-5.2 (xhigh), Claude Opus 4.5, and Gemini 3 Pro across various tasks, including agents, coding, image, and video tasks. Kimi K2.5 is highlighted as leading in several categories, notably “Agents: BrowseComp” and “Image: OmniDocBench 1.5”, suggesting its superior performance in these areas. The release is accompanied by a blog post detailing the advancements (link).* Commenters express skepticism about the benchmarks, questioning if they are cherry-picked, and discuss the model’s performance in hallucination and instruction-following tests. One user notes that Kimi K2.5, while improved, still outputs incorrect answers confidently, similar to other models like Gemini 3, which also confidently provides incorrect answers. GPT-5.1 and 5.2 are noted for admitting “I don’t know” in similar tests, highlighting ongoing challenges with hallucinations in AI models.
A user conducted a test on Kimi K2.5’s ability to follow instructions by asking it to identify a specific math contest problem without web search. The model listed out hallucinated contest problems and second-guessed itself, ultimately providing an incorrect answer. This is seen as a slight improvement over Kimi K2, which failed to follow instructions and timed out. In comparison, Gemini 3 also confidently provided incorrect answers, while GPT 5.1 and 5.2 were the only models to admit ‘I don’t know’.
The concept of an ‘agent swarm’ in Kimi K2.5 is intriguing, with speculation that it involves over 100 instances of the model being directed by a single overseeing instance. This setup is expected to be expensive, and there is curiosity about whether it could be a single model handling multiple tasks simultaneously, which would represent a significant advancement. The idea of scaffolding, where multiple models work together, seems more plausible to some users.
There is skepticism about the benchmarks used to compare Kimi K2.5 with other models like Gemini 3. A user questions whether the benchmarks are cherry-picked, expressing doubt that Kimi K2.5 consistently outperforms Gemini 3, which seems unlikely given the current state of model capabilities.
Sir, the Chinese just dropped a new open model (Activity: 1915): Kimi has released an open-source trillion-parameter vision model that reportedly matches the performance of Opus 4.5 on several benchmarks. This model is significant due to its scale and the claim of competitive performance, which is notable given the typically high cost and complexity associated with such large models. The release could impact the landscape of AI vision models, especially in terms of accessibility and cost-effectiveness. There is skepticism in the community about the true performance of Chinese models, with some users suggesting that while they are cost-effective, they may not genuinely match the capabilities of models like Claude, GPT, or Gemini despite benchmark claims.
Tricky-Elderberry298 highlights the limitations of relying solely on benchmarks for evaluating LLMs, drawing an analogy to evaluating cars based only on engine specs. They argue that real-world usage, such as how models like Claude and Kimi K2.5 perform in complex projects, is a more meaningful measure of capability than pure benchmark scores.
Durable-racoon discusses the unique capabilities of the Kimi K2.5 model, noting its ability to orchestrate 500 agents simultaneously and convert videos into working software UI prototypes. They also mention its superior performance in creative writing compared to Opus, while acknowledging that Kimi K2.5 is more expensive than most Chinese models, priced at $0.60/$3 for in/out operations.
DistinctWay9169 points out that many Chinese models, such as Minimax and GLM, are often ‘bench maxed,’ meaning they perform well on benchmarks but may not match the real-world performance of models like Claude, GPT, or Gemini. This suggests a discrepancy between benchmark results and actual usability or effectiveness in practical applications.
Gemini 3 finally has an open-source competitor (Activity: 168): The image is a comparison chart that highlights the performance of the newly released Kimi K2.5 vision model against other prominent models like Gemini 3 Pro. According to the chart, Kimi K2.5 performs competitively, often surpassing Gemini 3 Pro in various benchmarks such as “Humanity’s Last Exam,” “BrowseComp,” and “OmniDocBench 1.5.” This positions Kimi K2.5 as a strong open-source alternative to the closed-source Gemini 3 Pro, challenging its dominance in the field. Some users express skepticism about Kimi K2.5’s real-world performance compared to Gemini 3 Pro, with comments suggesting that while the benchmarks are impressive, practical performance may not match up. There is also a sentiment that open-source models may struggle to compete with large, closed-source companies.
MichelleeeC highlights a significant performance gap between the open-source competitor and Gemini 3, particularly when tested on niche topics without search engine assistance. This suggests that the open-source model may lack the comprehensive training data or fine-tuning that Gemini 3 benefits from, impacting its ability to provide accurate answers in specialized areas.
Old_Technology3399 and Just_Lingonberry_352 both express that the open-source competitor is notably inferior to Gemini 3. This consensus indicates that while the open-source model may be a step towards democratizing AI, it still falls short in terms of performance and reliability compared to established, closed-source models like Gemini 3.
ChezMere’s comment about ‘benchhacking’ suggests skepticism about the open-source model’s real-world performance versus its benchmark results. This implies that while the model might perform well in controlled tests, it may not translate to effective real-world application, highlighting a common issue in AI model evaluation.
Enterprise-ready open source/Chinese AIs are poised to out-sell American proprietary models. Personal investors take note. (Activity: 30): The post highlights the competitive edge of open-source and Chinese AI models over American proprietary models in niche domains, emphasizing their cost-effectiveness and comparable performance. Notable models include DeepSeek-V3 / R1, which ranks #1 on MATH-500 and LiveCodeBench, and Qwen3-Max / Coder from Alibaba, which excels in LMSYS Chatbot Arena and MMLU-Pro. These models offer significantly lower costs per million tokens compared to proprietary models like OpenAI’s GPT-5.2 and Claude 4.5 Sonnet, with input costs as low as $0.15 to $0.60 per million tokens, compared to proprietary costs starting at $3.00. The post suggests that personal investors should consider these developments as Chinese firms issue IPOs, with a16z noting that 80% of startups pitching them use Chinese open-source AI models. A comment questions whether Kimi K2 is superior to GLM 4.7, indicating a debate on the relative performance of these models in specific contexts.
The discussion compares the performance of the Kimi K2 model with the GLM 4.7 model. Kimi K2 is noted for its efficiency in specific tasks, potentially outperforming GLM 4.7 in certain benchmarks. However, the choice between these models may depend on the specific use case, as GLM 4.7 might excel in different areas. The conversation highlights the importance of evaluating models based on task-specific performance metrics rather than general claims of superiority.
2. Gemini AI Studio and Usage Limitations
Gemini AI Studio is basically unusable now. Any other LLMs with a 1M context window? (Activity: 162): Gemini AI Studio has become less viable for users due to Google’s reduction in daily prompt limits, impacting workflows that rely on its 1 million token context window. Users working with extensive documents and conversations are seeking alternatives. Notably, Grok 4.1 offers a 2 million token context window, and Claude Sonnet 4.5 provides a 1 million token context window within the Kilo Code environment. These alternatives may serve users needing large-context capabilities. Some users suggest that effective CLI tools like Claudie-cli or codex-cli can mitigate the need for massive context windows by efficiently managing and retrieving information from large texts.
Coldshalamov mentions that Grok 4.1 fast offers a 2M context window, which is double the size of the 1M context window being discussed. This suggests that Grok 4.1 fast could be a viable alternative for those needing larger context windows.
Unlucky_Quote6394 highlights that Claude Sonnet 4.5 provides a 1M context window when used within Kilo Code, indicating another option for users seeking large context capabilities.
Ryanmonroe82 suggests embedding documents as an alternative to using cloud models, implying that this method could be more efficient and effective for handling large text data without relying on extensive context windows.
32,768 or (2^15) tokens in hot memory.... Gemini has been PURPOSELY THROTTLED by Alphabet and been made into a bait and switch. Gemini Pro is WORSE than the free version as of TODAY. They market over a million tokens for Pro users. This is fraud. (Activity: 858): The Reddit post claims that Alphabet has intentionally throttled the token limit for Gemini Pro to 32,768 tokens, which is significantly lower than the advertised capacity of over a million tokens. This throttling allegedly degrades the performance of Gemini Pro, making it less effective than the free version. The post also mentions that the Ultra and Enterprise versions have a hard cap of 131,072 tokens, despite advertising up to 2 million tokens. The author expresses concern that this limitation could drive users away, especially with potential integration into Siri. Commenters express dissatisfaction with Gemini’s performance, comparing it unfavorably to older models like GPT-3. There is also criticism of the memory management, with claims that it leads to data inaccuracies and inefficiencies.
Substantial_Net9923 highlights a significant issue with Gemini’s memory management, noting that the model’s memory loss due to indexing is problematic. This inefficiency is particularly evident in quantitative finance trading discussions, where the model is reportedly generating inaccurate data more frequently than before, suggesting a decline in reliability.
klopppppppp observes a drastic decline in Gemini’s performance, comparing it to older models like GPT-3. Despite this, they note that Gemini still performs exceptionally well in ‘deep research mode,’ indicating that the model’s capabilities might be context-dependent or throttled in certain scenarios.
SorryDistribution604 expresses frustration with Gemini’s recent performance, likening it to older models such as GPT-3. This suggests a perceived regression in the model’s capabilities, which could be due to throttling or other limitations imposed on the Pro version.
About the recent AI Studio Limit Downgrade: (Activity: 660): The image is a notification from the Gemini API about a reduction in free usage limits for AI Studio users, suggesting a transition to using an API key for continued access. It indicates that these limits may decrease further over time, and mentions ongoing efforts to integrate with Google AI Pro/Ultra to share limits within AI Studio. This change reflects a broader trend of tightening access to free AI resources, potentially impacting developers relying on these tools for experimentation and development. Commenters express frustration over the reduction in free usage limits, noting that Gemini’s performance in following instructions has also declined. There is a sentiment that these changes are detrimental to AI Studio’s utility, as users feel they are receiving less value and functionality.
trashyslashers highlights a significant issue with the Gemini model’s performance, noting that it is ‘getting worse at listening to instructions.’ This suggests a degradation in the model’s ability to follow user commands, which is compounded by the reduction in daily usage limits. Users are forced to ‘rewrite and regenerate’ requests, indicating inefficiencies in the model’s processing capabilities.
Decent_Ingenuity5413 raises concerns about the stability and reliability of AI Studio’s service, drawing parallels to OpenAI’s past issues with unexpected changes. The comment also points out a critical billing issue with the Gemini API, where users have experienced ‘massive overbilling’ due to token counting errors, leading to charges exceeding $70,000. This highlights a significant flaw in the billing system that could deter average consumers from using the API.
Sensitive_Shift1489 expresses frustration over the perceived downgrading of AI Studio in favor of other Google AI products like Gemini App and CLI. The comment implies that these changes are part of a broader strategy to shift focus and resources, potentially at the expense of AI Studio’s quality and user satisfaction.
3. Qwen Model Performance and Applications
Qwen3-Max-Thinking - Comparible performance to Commercial Models (Activity: 40): Qwen3-Max-Thinking is an AI model that claims to offer performance comparable to commercial models, focusing on enhanced reasoning and decision-making capabilities. The model’s architecture and training methodologies are designed to improve efficiency and accuracy in complex tasks, as detailed in the original article. However, users have reported issues with the model’s agentic code mode, which fails to compile, potentially impacting its usability. One user expressed skepticism about the model’s usability due to compilation issues, while another hoped that Qwen3-Max-Thinking could help reduce the cost of commercial models.
Qwen model. We get it! Qwen-3-max-thinking (Activity: 26): The post announces the release of the Qwen-3-max-thinking model, which is expected to be available this week. This model is noted for its enhanced features, although specific details about these enhancements are not provided in the post. The mention of ‘P.S. We got it’ suggests that the model is already accessible to some users. One commenter questions whether the model has been available since October, indicating possible confusion or overlap with previous releases. Another asks if ‘OS’ is being referred to, suggesting a potential misunderstanding or need for clarification on whether the model is open-source.
3 Billion tokens!Evaluate my token usage? (Am I the most loyal user of QWEN3-MAX?) (Activity: 20): The post discusses a significant usage of the QWEN3-MAX language model, with the user consuming 3-4 billion tokens per day. This high usage has led to DAMO Academy granting additional concurrency and early access to the upcoming Qwen3.5-MAX. The user attributes a drop in usage to the weekend, indicating a consistent high demand otherwise. The post highlights the model’s effectiveness, with the user describing it as the ‘best LLM in the world’. Comments reveal a mix of curiosity and comparison, with one user noting their own high token consumption of 4 billion using a local model from the QWEN series. Another user shares a positive experience with the model’s ability to optimize website copywriting, though they express concerns about accessing the model for coding tasks.
Available-Craft-5795 mentions using 4 billion tokens with the QWEN series, indicating a high level of engagement with these models. This suggests that the QWEN series is capable of handling large-scale token processing, which could be beneficial for extensive applications such as data analysis or large-scale content generation.
Remarkable_Speed1402 discusses using the new model for optimizing website homepage copywriting, noting its effectiveness. However, they express concerns about the model’s coding capabilities, as they are unable to access it in their IDE. This highlights potential limitations in integrating the model with development environments, which could impact its usability for coding tasks.
Benchmark of Qwen3-32B reveals 12x capacity gain at INT4 with only 1.9% accuracy drop (Activity: 10): The benchmark of Qwen3-32B on a single H100 GPU demonstrates a significant capacity gain when using INT4 quantization, achieving a 12x increase in user capacity compared to BF16, with only a 1.9% drop in accuracy. The study involved over 12,000 MMLU-Pro questions and 2,000 inference runs, showing that INT4 can support 47 concurrent users at a 4k context, compared to just 4 users with BF16. The full methodology and data are available here. A comment raised a question about the model’s performance in coding tasks, suggesting interest in how quantization affects specific application areas beyond general benchmarks.
The discussion focuses on the performance of the Qwen3-32B model when quantized to INT4, highlighting a significant 12x increase in capacity with a minimal 1.9% drop in accuracy. This suggests that the model maintains high performance even with aggressive quantization, which is crucial for deploying large models in resource-constrained environments. However, the impact on specific tasks like coding remains a point of interest, as quantization can affect different tasks in varying ways.
AI Discord Recap
A summary of Summaries of Summaries by Gemini 3.0 Pro Preview Nov-18
Theme 1. Kimi K2.5 Launch: SOTA Agentic Benchmarks and Swarm Capabilities
Kimi K2.5 Crushes Agentic Benchmarks: Moonshot AI released Kimi K2.5, achieving global SOTA on the HLE full set (50.2%) and BrowseComp (74.9%), while posting open-source SOTA on MMMU Pro (78.5%) and SWE-bench Verified (76.8%)Tech Blog. Users across Discords noted the model was “silently rolled out” with significantly improved fact-checking and vision capabilities before the official announcement.
Agent Swarm Mode Enters Beta: The release introduces an Agent Swarm feature capable of orchestrating up to 100 sub-agents and executing 1,500 tool calls in parallel, promising a 4.5x performance boost on complex tasks. High-tier users can access this self-directed mode on kimi.com, though early testers noted it consumes tool-call quotas rapidly.
Pricing and API Instability Spark Debate: While the model’s capabilities impressed users, the new Kimi Code plan drew criticism for lower limits compared to competitors like Z.ai, with promotional pricing ending in February. Integration with OpenRouter faced initial hiccups, with users reporting errors related to tool use endpoints and image URL handling.
Theme 2. Hardware Acceleration: Unsloth Speedups, FlagOS, and Kernel Ops
Unsloth Accelerates MoE Training by 14x: Unsloth announced that MoE training is now 14x faster than v4, with upcoming optimizations projected to double that speed again for a total 30x boost. The team also rolled out full support for transformers v5, streamlining workflows for users on the latest library versions Announcement.
FlagOS Targets Unified AI Stacks: Engineers discussed the introduction of FlagOS, an open-source system software stack designed to unify Model–System–Chip layers for better workload portability across heterogeneous hardware. The project aims to incorporate insights from hardware–software co-design to bridge the gap between ML systems and compilers.
Tinygrad Codegens Flash Attention Directly: In the Tinygrad community, members successfully proved the ability to codegen Flash Attention directly from a frontend definition of naive attention using granular rewrites. Simultaneously, discussions highlighted a shift toward Megakernels over traditional kernel schedulers to optimize GPU throughput Luminal Blog.
Theme 3. OpenAI Ecosystem: Prism, GPT-5.2 Performance, and Model Decay
Prism Workspace Unlocks Scientific Collaboration: OpenAI launched Prism, a dedicated workspace powered by GPT-5.2 designed to streamline scientific research and writing for ChatGPT personal account holders Video Demo. While the tool targets academic rigor, users debating GPT-5.2 vs. Claude Opus 4.5 noted that OpenAI’s model still struggles with creative writing, a flaw Sam Altman reportedly admitted to.
Model Deterioration Blamed on Leechers: A recurring theory across channels suggests significant degradation in ChatGPT and Claude performance, with some users claiming a 40% drop in quality. Speculation points to free tier users (”leechers”) diluting compute resources or models recursively training on their own synthetic outputs.
GPT-5 Control Shell Leaked: A file dubbed the GPT-5_Hotfix.md surfaced, purported to be a pre-generation control shell that enforces strict syntax and intent locking to prevent model drift. The leak suggests OpenAI is using aggressive “wrappers” to manage output quality before generation even begins.
Theme 4. Agentic Coding Wars: Tooling, Security, and Rebrands
Clawdbot Morphs into Moltbot After Security Scare: Following a trademark dispute with Anthropic and serious community concerns about zero-auth vulnerabilities, the popular agent Clawdbot rebranded to MoltbotAnnouncement. Users previously flagged that the bot could read environment keys without permission, posing risks to sensitive financial and personal data.
Cursor and Cline Face Usability Headwinds: Users expressed frustration with Cursor’s pricing model, noting that a few complex prompts could cost $0.50, while others struggled to run Cline on modest hardware (8GB VRAM), facing CUDA0 buffer errors. Community fixes involved reducing context lengths to 9000 and offloading memory management to dedicated GPU settings.
Karpathy Bets on Agent-First Coding: Andrej Karpathy sparked discussion by outlining a strategic shift toward agent-driven coding using Claude, emphasizing the “tireless persistence” of LLMs over traditional methods Post. This aligns with the release of Manus Skills, where developers are incentivized with free credits to build use cases for the new agentic platform.
Theme 5. Theoretical Limits and Safety: Hallucinations and Bio-Risks
Math Proves Hallucination is Inevitable: A new paper discussed in the BASI Discord mathematically proves that LLMs will always hallucinate, utilizing the same principles found in jailbreaking mechanics Arxiv Paper. Researchers noted that jailbreaking exacerbates this issue by distorting the context model, preventing it from flagging malicious or incorrect tags.
Fine-Tuning Unlocks Dormant Bio-Risks: An Anthropic paper sparked debate at EleutherAI by demonstrating that fine-tuning open-source models on frontier model outputs can unsuppress harmful capabilities, such as biorisks, even if previously safety-trained Arxiv Link. The findings suggest that refusals are fragile and can be undone with minimal compute, raising concerns about dual-use technologies.
AI Detection Tools Flag Human Academics: Engineers highlighted a growing issue where AI detection tools consistently mislabel human-written, pre-GPT academic texts as AI-generated. The consensus is that these detectors are fundamentally flawed, yet institutions continue to rely on them, creating friction for researchers and students.
quick call-out that I don't expect the bots to read/respond to: there's a meaningful brand conflict when you claim "Estimated reading time saved (at 200wpm): 602 minutes" and then proceed to publish 7,866 words of AI news. was excited to see some curated non-slop and was therefore disappointed in what I found.



quick call-out that I don't expect the bots to read/respond to: there's a meaningful brand conflict when you claim "Estimated reading time saved (at 200wpm): 602 minutes" and then proceed to publish 7,866 words of AI news. was excited to see some curated non-slop and was therefore disappointed in what I found.