

[AINews] new Gemini 3 Deep Think, Anthropic $30B @ $380B, GPT-5.3-Codex Spark, MiniMax M2.5
There's too much going on!
China open model week kept going with MiniMax M2.5 claiming an Opus-matching 80.2% on SWE-Bench Verified, however, as often happens on Thursdays, all 3 leading US labs had updates - Anthropic closed their $380B round confirming a historic >10xing of revenue to $14B as of today (remember in August Dario projected $10B), with Claude Code’s ARR doubling, hitting 2.5B year to date. Not to be outdone, OpenAI rolled out their answer to Claude’s fast mode (2.5x speedup) with GPT-5.3-Codex-Spark, which delivers >1000 tok/s (10x speedup), an impressively fast turnaround of the Cerebras deal.
All fantastic news, but we give the title story to the new Gemini 3 Deep Think today, and Jeff Dean dropped by the studio to give an update on the general state of GDM:
This is the same model that scored that IMO Gold last summer, and is simultaneously the #8 best Codeforces programmer in the world and helping new semiconductor research, but perhaps most impressive is that it reaches new SOTA levels (eg on ARC-AGI-2) while also being very efficient - 82% cheaper per task - something Jeff was very excited about in his pod.
AI Twitter Recap
Google DeepMind’s Gemini 3 Deep Think V2: benchmark jump + “science/engineering reasoning mode” shipping to users
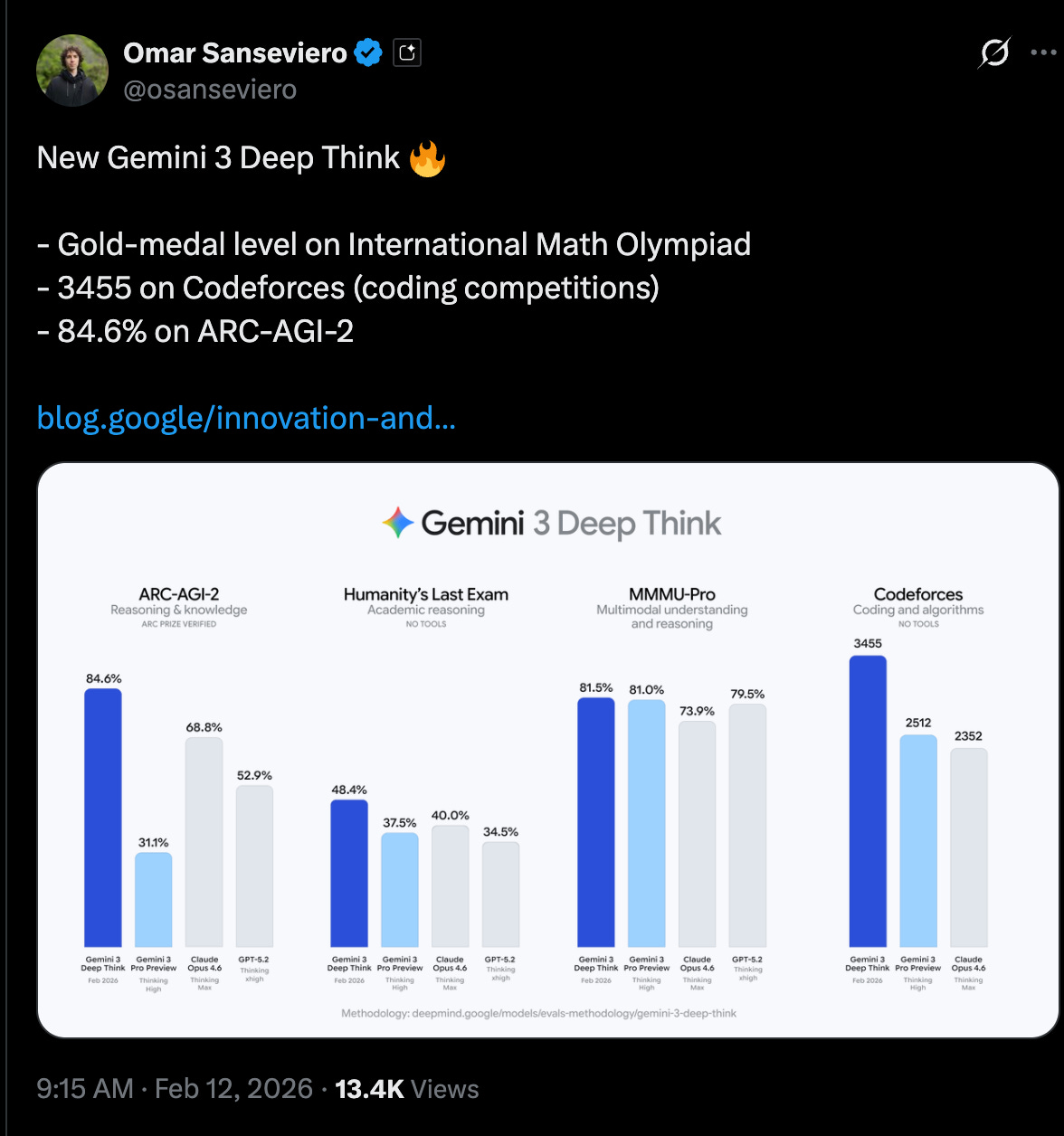
Deep Think V2 rollout + access paths: Google is shipping an upgraded Gemini 3 Deep Think reasoning mode to Google AI Ultra subscribers in the Gemini app, and opening a Vertex AI / Gemini API early access program for select researchers/enterprises (GoogleDeepMind, Google, GeminiApp, tulseedoshi). Multiple Googlers emphasized this is meant to be a productized test-time compute heavy mode rather than a lab-only demo (OriolVinyalsML, JeffDean, demishassabis, sundarpichai).
Key reported numbers (and what’s notable about them):
ARC-AGI-2: 84.6% (promoted as new SOTA; independently certified/verified by the ARC community) (Google, arcprize, fchollet, scaling01).
Humanity’s Last Exam (HLE): 48.4% without tools (sundarpichai, _philschmid, JeffDean).
Codeforces Elo: 3455 (framed as “only ~7 humans” above it; discussion about “no tools” conditions and what that implies for evaluation) (scaling01, YouJiacheng, DeryaTR_).
Olympiad-level written performance in Physics/Chemistry (and references to IMO/ICPC history) (Google, NoamShazeer, demishassabis, _philschmid).
Cost disclosures for ARC: ARC Prize posted semi-private eval pricing like $13.62/task for ARC-AGI-2 and $7.17/task for ARC-AGI-1 (arcprize).
Real-world “engineering” demos and claimed impact: Several posts push the message that Deep Think’s value is in practical scientific/engineering workflows: finding errors in math papers, modeling physical systems in code, optimizing semiconductor crystal growth, and even a sketch → CAD/STL pipeline for 3D printing (e.g., laptop stand and turbine-blade-esque components) (Google, Google, Google, GeminiApp, joshwoodward, tulseedoshi, OriolVinyalsML).
ARC context / what “saturating ARC” means: François Chollet (ARC’s creator) both celebrated certification and later reiterated that ARC’s purpose is to steer research toward test-time adaptation / fluid intelligence, not to “prove AGI” (fchollet, fchollet). In a separate thread he defines “AGI” as the end of the human–AI gap and argues benchmarks must evolve until humans can no longer propose tasks where they outperform AI, with a rough expectation of ~2030 for that state (fchollet, fchollet).
Open coding/agent models shipping fast: MiniMax M2.5 + Zhipu’s GLM-5 battle for “best open agentic coder”
MiniMax M2.5: distribution + positioning: MiniMax’s new model is pushed as an “agent-verse / long-horizon agent” model, rapidly appearing across aggregators and tools: OpenRouter (OpenRouterAI), Arena (arena), IDE/agents like Cline (cline), Ollama cloud free promo (ollama), Eigent agent scaffolds (Eigent_AI), Qoder (qoder_ai_ide), and Blackbox AI (blackboxai).
Benchmarks cited in the thread include claims like 80.2% SWE-Bench Verified and strong performance vs closed models in coding settings; multiple tweets stress throughput + cost as differentiators (e.g., 100 tokens/s and $0.06/M blended with caching are cited by Cline) (cline, cline, guohao_li, shydev69). Community vibe checks (e.g., Neubig) claim it’s one of the first open-ish coding models he’d seriously consider switching to for daily work (gneubig).
GLM-5: model scale + infra hints + “open model leaderboards”:
Tooling ecosystem reports: GLM-5 is used on YouWare with a 200K context window for web projects (YouWareAI); one user reports ~14 tps on OpenRouter (scaling01).
A more detailed (but still third-party) technical summary claims GLM-5 is 744B params with ~40B active, trained on 28.5T tokens, integrates DeepSeek Sparse Attention, and uses “Slime” asynchronous RL infra to increase post-training iteration speed (cline). Another tweet nitpicks terminology confusion around attention components (eliebakouch).
Local inference datapoint: awnihannun reports running GLM-5 via mlx-lm on a 512GB M3 Ultra, generating a small game at ~15.4 tok/s using ~419GB memory (awnihannun).
Arena signal: the Arena account says GLM-5 is #1 open model in Code Arena (tied with Kimi) and overall #6, still ~100+ points behind Claude Opus 4.6 on “agentic webdev” tasks (arena).
A long Chinese-language-style analysis reposted via ZhihuFrontier argues GLM-5 improves hallucination control and programming fundamentals but is more verbose/“overthinks,” suggesting compute constraints (concurrency limits) show through (ZhihuFrontier).
OpenAI’s GPT-5.3-Codex-Spark: ultra-low-latency coding via Cerebras (and why UX becomes the bottleneck)
Product announcement: OpenAI released GPT-5.3-Codex-Spark as a “research preview” for ChatGPT Pro users in the Codex app/CLI/IDE extension (OpenAI, OpenAIDevs). It’s explicitly framed as the first milestone in a partnership with Cerebras (also touted by Cerebras) (cerebras).
Performance envelope:
The headline is “1000+ tokens per second” and “near-instant” interaction (OpenAIDevs, sama, kevinweil, gdb).
Initial capability details: text-only, 128k context, with plans for larger/longer/multimodal as infra capacity expands (OpenAIDevs).
Anecdotal reviews highlight a new bottleneck: humans can’t read/validate/steer as fast as the model can produce code, implying tooling/UX must evolve (better diffs, task decomposition, guardrails, “agent inboxes,” etc.) (danshipper, skirano).
Model size speculation: There are community attempts to back-calculate size from throughput vs other MoEs; one estimate suggests ~30B active and perhaps 300B–700B total parameters (scaling01). Treat this as informed speculation, not an official disclosure.
Adoption/availability: Sam Altman later says Spark is rolling to Pro; OpenAI DevRel notes limited API early access for a small group (sama, OpenAIDevs). There are also “Spark now with 100% of pro users” type rollout notes with infra instability caveats (thsottiaux).
Agent frameworks & infra: long-running agents, protocol standardization, and KV-cache as the new scaling wall
A2A protocol as “agent interoperability layer”: Andrew Ng promoted a new DeepLearning.AI course on Agent2Agent (A2A), positioning it as a standard for discovery/communication across agent frameworks, mentioning IBM’s ACP joining forces with A2A and integration patterns across Google ADK, LangGraph, MCP, and deployment via IBM’s Agent Stack (AndrewYNg).
Long-running agent harnesses are becoming product features:
Cursor launched long-running agents and explicitly ties it to a “new harness” that can complete larger tasks (cursor_ai).
LangChain folks discuss “harness engineering” research: forcing self-verification/iteration, automated context prefetch, and reflection over traces as levers that change outcomes materially (Vtrivedy10).
Deepagents added bring-your-own sandboxes (Modal/Daytona/Runloop) for safe code execution contexts (sydneyrunkle).
Serving bottlenecks: KV cache & disaggregation:
PyTorch welcomed Mooncake into the ecosystem, describing it as targeting the “memory wall” in LLM serving with KVCache transfer/storage, enabling prefill/decode disaggregation, global cache reuse, elastic expert parallelism, and serving as a fault-tolerant distributed backend compatible with SGLang, vLLM, TensorRT-LLM (PyTorch).
Moonshot/Kimi highlighted Mooncake’s origins (Kimi + Tsinghua) and open-source trajectory (Kimi_Moonshot).
A surprisingly common theme: “files as queues”: A viral thread describes a reliable distributed job queue using object storage + a queue.json (FIFO, at-least-once) as a minimalist primitive (turbopuffer). Another tweet claims Claude Code “agent teams” communicate by writing JSON files on disk, emphasizing “no Redis required” CLI ergonomics (peter6759).
Research notes: small theorem provers + label-free vision training + RL algorithms for verifiable reasoning
QED-Nano: 4B theorem proving with heavy test-time compute: A set of tweets introduces QED-Nano, a 4B natural-language theorem-proving model that matches larger systems on IMO-ProofBench and uses an agent scaffold scaling to >1M tokens per proof, with RL post-training “rubrics as rewards.” They promise open-source weights and training artifacts soon ( _lewtun, _lewtun, setlur_amrith, aviral_kumar2).
LeJEPA: simplifying self-supervised vision: NYU Data Science highlights LeJEPA (Yann LeCun + collaborators) as a simpler label-free training method that drops many tricks but scales well and performs competitively on ImageNet (NYUDataScience).
Recursive/agentic evaluation discourse: Multiple tweets debate recursive language models (RLMs) and stateful REPL loops as a way to manage long-horizon tasks outside the context window (lateinteraction, deepfates, lateinteraction).
Top tweets (by engagement)
Gemini 3 Deep Think upgrade + sketch→STL demo: @GeminiApp
OpenAI Codex-Spark announcement: @OpenAI, @OpenAIDevs, @sama
Anthropic funding/valuation: @AnthropicAI
Gemini Deep Think “unprecedented 84.6% ARC-AGI-2”: @sundarpichai
Simile launch + $100M raise; simulation framing: @joon_s_pk, @karpathy
Keep reading with a 7-day free trial
Subscribe to Latent.Space to keep reading this post and get 7 days of free access to the full post archives.