

[AINews] OpenAI Codex App: death of the VSCode fork, multitasking worktrees, Skills Automations
The meta is moving fast.
AI News for 1/30/2026-2/2/2026. We checked 12 subreddits, 544 Twitters and 24 Discords (254 channels, and 14979 messages) for you. Estimated reading time saved (at 200wpm): 1408 minutes. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
We almost did -NOT- give OpenAI the title story today — Xai technically got acquired by SpaceX for ~$177B, and after all, it’s “just” a desktop app UI for the already existing CLI and Cloud app and VS Code extension… and it’s “just” OpenAI’s version of Conductor and Codex Monitor and Antigravity’s Inbox (which literally launched with the exact same “AI Agent Command Center” tagline):

Everything is crab, but perhaps the crab is the perfect form factor.
And yet.
In December Steve Yegge and Gene Kim predicted that the IDE would die:
and here we are in 2026, and OpenAI, which once offered $3B for Windsurf, is out here shipping a coding agent UX that is NOT a VS Code fork, and by the way Anthropic has also done the same with their Claude Code and Claude Cowork app. Bears some thought on truly how far coding models have come that serious coding apps are shipping without an IDE (yes, Codex still lets you link out to an IDE when needed, but evidently that is an exception rather than the norm).
There was a time when “app that lets you write English and build without looking at code” was equivalent to “vibe coding” or “app builder”, but these nontechnical audiences are NOT the ICP for Codex - this is very seriously marketed at developers, who historically love code and identify strongly with hand-writing every line of code.
Now OpenAI is saying: looking at code is kinda optional.
The other observation is the reliance on multitasking and worktrees: in hindsight this is the perfect natural UI response to the increase in agent autonomy:
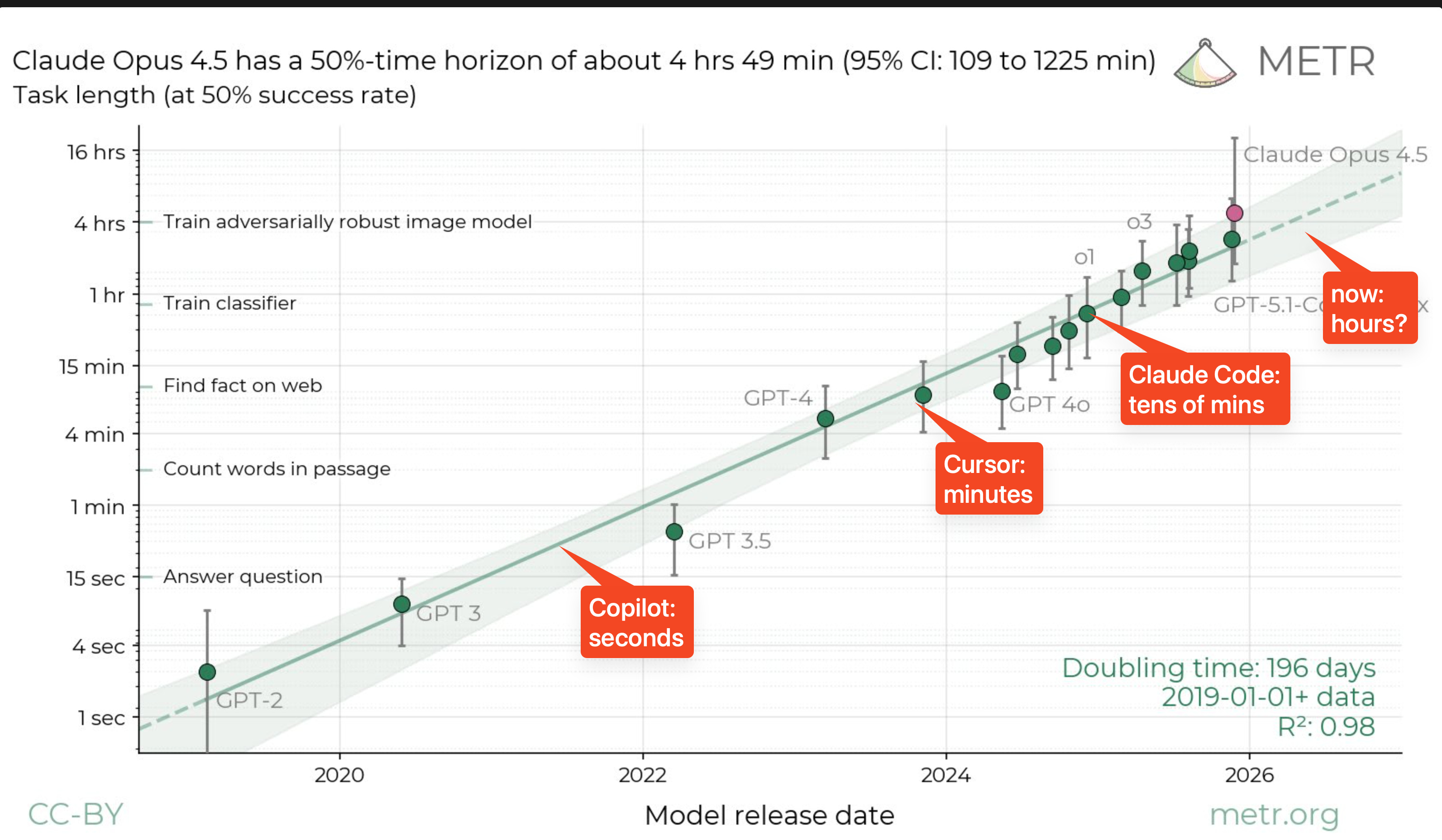
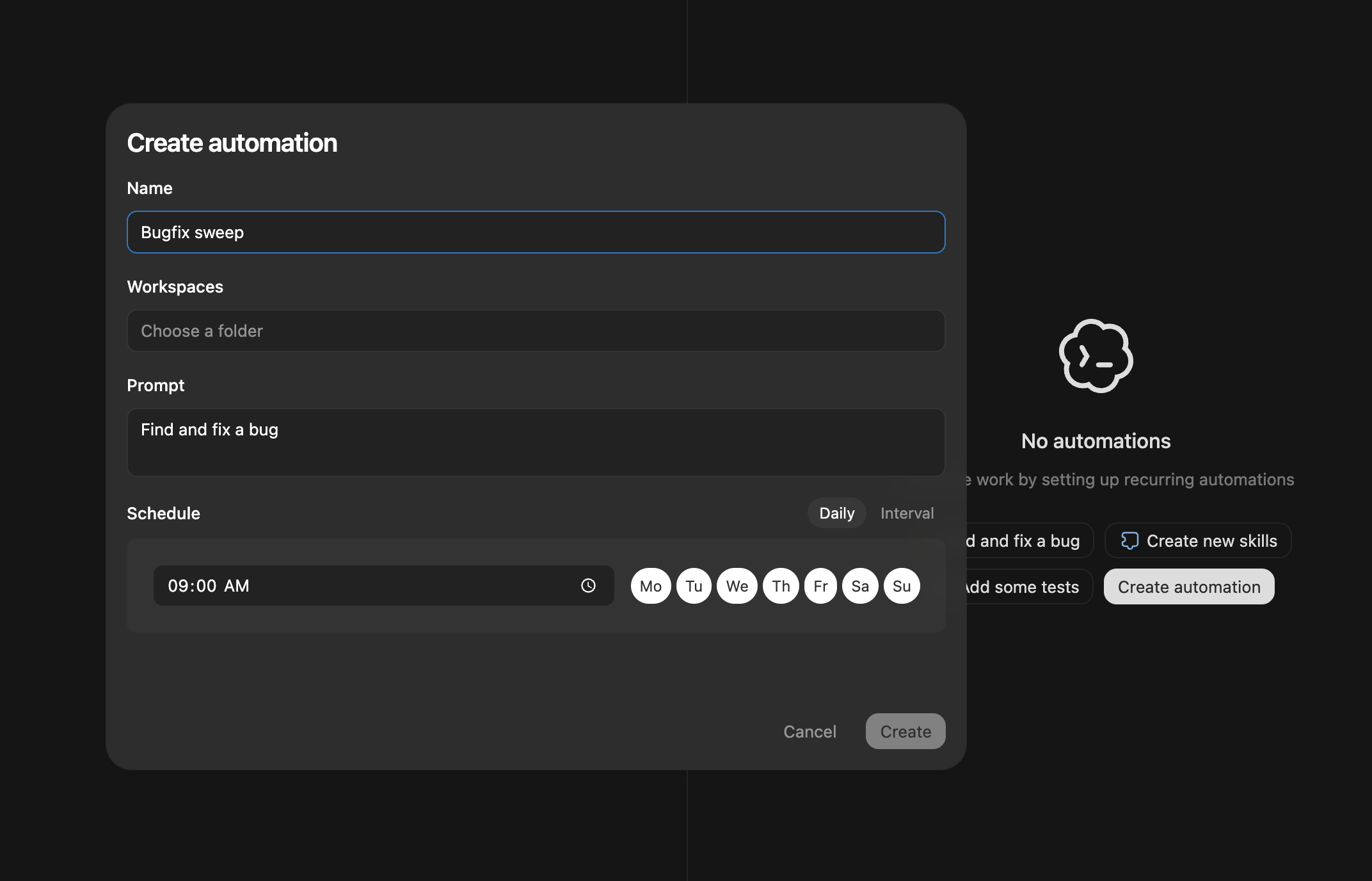
and the final, actually novel thing that Codex ship that is the most overlooked is Automations, which are basically “skills on a cronjob” - somehow OpenAI is the first major player to launch this very simple feature in GA:
AI Twitter Recap
OpenAI’s Codex app: an agent-native “command center” for coding
Codex app ships on macOS (Windows “soon”): OpenAI launched a dedicated Codex desktop app positioned as a focused UI for running multiple agents in parallel, keeping changes isolated via built-in worktrees, and extending behavior with skills and scheduled automations (OpenAI announcement, rate-limit + availability details, OpenAIDevs feature rundown). A recurring theme: the interface (not just the model) is becoming the product.
Developer workflow details that matter: The app emphasizes (a) worktree per task/PR as the primitive for parallelism and conflict isolation; (b) Plan mode (
/plan) to force upfront decomposition and questions; (c) skills as reusable bundles that can connect to external services (Figma/Linear/Vercel, etc.); and (d) automations for recurring background jobs (@reach_vb, Plan mode, skills landing page).Usage signals / adoption narrative: Multiple insiders (and power users) claim the app is a step-change over CLI/IDE extensions for large repos and long-running tasks—particularly for managing parallel threads and reviewable diffs. Notable testimonials include @gdb (agent-native interface; “going back to terminal feels like going back in time), @sama (surprised how much he loves it), and @skirano (replacing Cursor + Claude Code in their workflow).
Ecosystem pressure / standardization: There’s already a push to standardize “skills” folders: proposal to have Codex read from
.agents/skillsand deprecate.codex/skills(@embirico). This is early evidence that agent tooling is starting to form conventions similar to.github/,pyproject.toml, etc.Meta-point: “self-improving” via product loop: Several posts highlight Codex being used to build itself—presented as the most compelling “recursive improvement” story that’s actually shipping as a product feedback loop (humans + agents) rather than autonomous AGI (OpenAIDevs, @ajambrosino, @thsottiaux).
Coding agents in practice: reliability, tests, parallelism, and the “army of agents” meme becoming real
A concrete best practice for CLAUDE.md/AGENTS.md: Add a “test-first” instruction: when a bug is reported, write a reproducing test first; then fix; then prove via passing test—framed as the single biggest improvement to agent performance and sanity (@nbaschez). This aligns with the broader theme that coding is a high-leverage domain because it’s partially verifiable.
The “conductor” model of engineering: Claims that one developer can run 5–10 agents in parallel, shipping code they don’t fully read, shifting from author to supervisor/conductor (@Yuchenj_UW). A related counterpoint warns about human context-switch limits and quality degradation if you try to run “a gazillion things in parallel” (@badlogicgames).
Neurosymbolic framing for why coding agents work: A crisp argument that coding agents succeed because software is a verifiable domain and because execution/tooling (tests, compilers, shells) forms a symbolic scaffold that LLMs can leverage; replicating this outside coding requires building comparable “symbolic toolboxes” + verifiability (@random_walker).
Benchmark skepticism: Pushback on lightweight “LLM productivity” studies where participants use weak workflows (e.g., chat sidebar usage) rather than agentic setups; criticism that results understate productivity gains when tools evolve rapidly (@papayathreesome, @scaling01).
Open-source agent stacks and safety/ops concerns: The OpenClaw/Moltbook ecosystem generates both excitement and operational/safety critique—e.g., discussion of gateways in front of agents for session management/policy enforcement (@salman_paracha), and warnings that “AI-only social media” gets instantly botted/spammed (@jxmnop). The subtext: agent products need the same abuse-resistance/observability maturity as consumer platforms—immediately.
Open models for agentic coding: StepFun Step-3.5-Flash and Kimi K2.5 as the week’s focal points
StepFun Step-3.5-Flash open release (big efficiency claims): StepFun’s Step-3.5-Flash is repeatedly cited as a sparse MoE model with 196B total parameters / ~11B active, tuned for speed + long-context agent workflows (notably 256K context with 3:1 sliding-window attention + full attention, plus MTP-3 multi-token prediction) (official release thread, launch/links). StepFun reports 74.4% SWE-bench Verified and 51.0% Terminal-Bench 2.0 (StepFun).
Immediate infra support: vLLM shipped day-0 support and a deployment recipe, signaling StepFun’s seriousness about adoption in real serving stacks (vLLM).
Community evaluation posture: Multiple posts stress “needs testing ASAP” and note benchmark cherry-picking concerns; people want standardized baselines (MMLU/HLE/ARC-AGI) and third-party verification, especially as HF leaderboards change (@teortaxesTex, @QuixiAI).
Kimi K2.5’s agentic coding strength: Arena reports Kimi K2.5 as #1 open model in Code Arena and #5 overall, “on par” with some top proprietary offerings, and also strong across Text/Vision/Code Arena (Arena announcement). Separate anecdotal notes mention tool-following weaknesses (system prompt adherence) in some workflows (@QuixiAI).
Provider reliability issues: Tool-calling/parsing failures can make models look worse than they are; Teknium calls out FireworksAI’s Kimi endpoint for broken tool parsing, forcing workflow bans—an ops reminder that “model quality” in production often collapses to integration correctness (@Teknium, earlier warning).
Synthetic data, evaluation, and “don’t trust perplexity”
Synthetic pretraining deep dive: Dori Alexander published a long blogpost on synthetic pretraining, implying renewed focus on synthetic data pipelines and their failure modes (e.g., collapse, distribution drift) (tweet). This pairs with broader chatter that “synthetic data mode collapse” fears were once dominant—now increasingly treated as an engineering/recipe issue (@HaoliYin).
Perplexity as a model selection trap: Several tweets point to emerging evidence that perplexity should not be blindly trusted as a selection objective (@DamienTeney, @giffmana). The practical takeaway: if you optimize only for next-token prediction metrics, you can miss downstream task behaviors, tool-use stability, and instruction-following consistency.
Unlimited RLVR tasks from the internet (“Golden Goose”): A method to synthesize essentially unlimited RLVR-style tasks from unverifiable web text by masking reasoning steps and generating distractors; claims include reviving models “saturated” on existing RLVR data and strong results in cybersecurity tasks (@iScienceLuvr, paper ref).
Compression + long-context infra ideas: Discussion of document/context compression approaches (e.g., “Cartridges,” gist tokens, KV cache compression variants) to reduce memory footprint and speed generation—relevant as agent contexts balloon into hundreds of thousands or millions of tokens (@gabriberton, refs).
Agent systems & infra: memory walls, observability, and RAG chunking becoming query-dependent
Inference bottleneck shifts from FLOPs to memory capacity: A long thread summarizes Imperial College + Microsoft Research arguing that for agentic workloads (coding/computer-use), the binding constraint is memory capacity / KV cache footprint, not just compute. Example: batch size 1 with 1M context can require ~900GB memory for a single DeepSeek-R1 request; suggests disaggregated serving and heterogeneous accelerators for prefill vs decode (@dair_ai).
Observability becomes “the stack trace” for agents: LangChain emphasizes that agents fail without crashing; traces are the primary debugging artifact, motivating webinars and tooling around agent observability + evaluation (LangChain, @hwchase17).
RAG chunking: oracle experiments show 20–40% recall gains: AI21 reports experiments where an oracle picks chunk size per query; this beats any fixed chunk size by 20–40% recall, but requires storing multiple index granularities (storage vs quality tradeoff) (@YuvalinTheDeep, thread context).
Packaging “deep agent” architecture patterns: LangChain JS introduces
deepagents, claiming four recurring architectural patterns explain why systems like Claude Code/Manus feel robust while naive tool-calling agents fail (LangChain_JS).
Top tweets (by engagement)
Karpathy on returning to RSS to escape incentive-driven slop: High-engagement meta commentary relevant to “signal quality” for engineers (tweet).
OpenAI Codex app launch: The biggest AI-engineering release by engagement in this set (OpenAI, OpenAIDevs, @sama).
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. Step-3.5-Flash Model Performance
128GB devices have a new local LLM king: Step-3.5-Flash-int4 (Activity: 385): The
Step-3.5-Flash-int4model, available on Hugging Face, is a new local LLM optimized for devices with128GBRAM, such as the M1 Ultra Mac Studio. It supports a full context length of256kand demonstrates high efficiency in RAM usage. Benchmarks usingllama-benchshow impressive performance with up to100kprefill, achieving281.09 ± 1.57 t/sforpp512tests and34.70 ± 0.01 t/sfortg128tests. The model requires a customllama.cppfork for execution, with potential for upstream support due to its performance. Commenters are curious about the model’s performance on different hardware, such as Strix Halo, and express interest in a potential NVFP4 version. There is also a humorous comment reflecting surprise at the model’s capabilities.The Step-3.5-Flash-int4 model is noted for its ability to run a full 256k context on a 128GB device, which is impressive given that many models are memory-intensive and cannot handle such large contexts. This makes it a strong competitor against models like GLM 4.7, which are known for high RAM usage.
A user compared Step-3.5-Flash-int4 to Minimax M2.1, suggesting that it might perform slightly better. This comparison is significant as Minimax M2.1 is a well-regarded model, and any improvement in performance or efficiency could be a major advantage for users looking for high-quality outputs without excessive resource consumption.
There is interest in the response speed of Step-3.5-Flash-int4 compared to Minimax, which is favored for quick iterations. If Step-3.5-Flash-int4 offers both improved efficiency and quality, it could potentially replace Minimax as the preferred model for tasks requiring rapid processing and high-quality results.
Step-3.5-Flash (196b/A11b) outperforms GLM-4.7 and DeepSeek v3.2 (Activity: 640): The newly released Step-3.5-Flash model by Stepfun demonstrates superior performance on various coding and agentic benchmarks compared to DeepSeek v3.2, despite having significantly fewer parameters. Specifically, Step-3.5-Flash utilizes
196Btotal parameters with11Bactive, whereas DeepSeek v3.2 uses671Btotal with37Bactive parameters. This model is available on Hugging Face. Commenters noted the model’s unexpected performance given its size, comparing it favorably to other models like Kimi K2.5 and Deepseek 3.2 Speciale. There is also an open pull request for integrating this model with llama.cpp, indicating active community interest and development.The Step-3.5-Flash model, despite its small size and speed, is reported to outperform larger models like GLM-4.7 and DeepSeek v3.2. A user noted that it performs comparably to Kimi K2.5 and even matches the capabilities of Deepseek 3.2 Speciale or Gemini 3.0 Flash, indicating its high efficiency and capability despite being ‘benchmaxxed’.
A pull request has been opened for integrating Step-3.5-Flash into
llama.cpp, which is a significant step for its adoption and use in various applications. This model is smaller than others like MiniMax and Qwen3-235B, making it a valuable addition to the range of compact models available for developers. The link to the pull request is here.
2. GLM-5 and Upcoming AI Releases
GLM-5 Coming in February! It’s confirmed. (Activity: 757): The image is a social media post highlighting anticipated AI technology releases in February 2026, including DeepSeek V4, Alibaba Qwen 3.5, and GPT-5.3. A user named jietang adds “glm-5” to the list, suggesting its release is also expected. This indicates a significant period for AI advancements, with multiple major updates from leading AI developers. The post has garnered attention, reflecting community interest in these developments. One comment humorously notes the rapid obsolescence of AI models, while another speculates on the potential features of GLM-5, indicating anticipation and curiosity about its capabilities.
bootlickaaa expresses a desire for GLM-5 to outperform Kimi K2.5, indicating a potential shift in user preference based on performance metrics. This suggests that users are closely monitoring the capabilities of different models and are willing to switch services if a new model offers superior performance. The mention of an annual Z.ai Pro plan implies a commitment to a service that could be disrupted by a more advanced model.
International-Try467 raises a concern about the reliability of information regarding GLM-5, questioning the credibility of sources not affiliated with the GLM staff. This highlights the importance of official communication channels and verified information in the tech community, especially when it comes to announcements about new model releases.
Septerium humorously notes the rapid obsolescence of their gguf files, which underscores the fast-paced nature of AI model development and the frequent updates required to keep up with the latest advancements. This reflects a broader challenge in the field where users must continually update their resources to leverage new capabilities.
Mistral Vibe 2.0 (Activity: 387): Mistral AI has released Mistral Vibe 2.0, an enhanced version of its terminal-native coding agent, leveraging the Devstral 2 model family. This update introduces features like custom subagents for task specialization, multi-choice clarifications to minimize ambiguity, and slash-command skills for streamlined workflows. It also supports unified agent modes for seamless context switching. The service is integrated into Le Chat Pro and Team plans, transitioning to a paid API model for Devstral 2, with enterprise options for advanced functionalities like fine-tuning and code modernization. More details can be found here. Commenters note the European origin of Mistral Vibe 2.0, highlighting its French development. There is a comparison with OpenCode, suggesting both tools mimic ClaudeCode, and a user mentions improved tool performance by configuring the tool list in the
~/.vibe/promps/cli.mdfile.A user highlights the compactness of Mistral Vibe 2.0’s codebase, noting it has only
19472lines of code compared to alternatives like Codex or OpenCode, which often exceed100klines. This suggests a focus on code quality and efficiency, potentially making it easier to maintain and understand.Another user mentions a configuration tip for Mistral Vibe 2.0, suggesting that tool calls work better when the list of tools is explicitly added to the
~/.vibe/promps/cli.mdfile. This implies that proper configuration can enhance the tool’s functionality and user experience.A comment raises the question of whether Mistral Vibe 2.0 can be run locally and offline, which is a common consideration for users concerned with privacy, performance, or internet dependency.
3. Falcon-H1-Tiny and Specialized Micro-Models
Falcon-H1-Tiny (90M) is out - specialized micro-models that actually work (Activity: 357): Falcon-H1-Tiny is a new series of sub-100M parameter models by TII that challenge the traditional scaling paradigm by demonstrating effective performance in specialized tasks. These models utilize an anti-curriculum training approach, injecting target-domain data from the start, which prevents overfitting even after extensive training. They incorporate Hybrid Mamba+Attention blocks and the Muon optimizer, achieving up to
20%performance gains over AdamW. Notably, a 90M tool-caller model achieves94.44%relevance detection, and a 600M reasoning model solves75%of AIME24 problems, rivaling much larger models. These models are optimized for local deployment, running efficiently on devices like phones and Raspberry Pi. Commenters noted the use of the Muon optimizer, also known as the Kimi optimizer, and expressed interest in the potential for these models to focus on pulling and utilizing knowledge effectively. There is curiosity about the availability of code and dataset previews for training similar models for custom tasks.Firepal64 mentions the use of the Kimi optimizer, known as Muon, in the Falcon-H1-Tiny model. This optimizer is not widely adopted, which raises curiosity about its unique benefits or performance characteristics that might make it suitable for specialized micro-models like Falcon-H1-Tiny.
kulchacop and Available-Craft-5795 inquire about the availability of code, dataset previews, and the training pipeline for Falcon-H1-Tiny. They are interested in understanding the training process and data collection methods, possibly to adapt the model for their own tasks or to replicate the results.
mr_Owner notes that the Falcon-H1-Tiny model performs slower than expected when using
llama.cpp, suggesting potential inefficiencies or compatibility issues with this specific implementation. This could be an area for further optimization or investigation.
Can 4chan data REALLY improve a model? TURNS OUT IT CAN! (Activity: 606): The release of Assistant_Pepe_8B, trained on an extended 4chan dataset, surprisingly outperformed its base model, nvidia’s nemotron. This model, despite being trained on what was expected to be a noisy dataset, showed higher scores than both the base and the abliterated base, challenging the typical expectation that fine-tuning sacrifices some intelligence for specificity. The model’s performance echoes the earlier success of gpt4chan by Yannic Kilcher, which also scored high in truthfulness. The results suggest that the so-called “alignment tax” might have a non-trivial impact, as evidenced by the low KL divergence (
<0.01) in the Impish_LLAMA_4B model, which also showed a shift in political alignment.The use of 4chan data in language models is highlighted for its unique impact on linguistic statistics and semantics, particularly in enhancing the model’s ability to generate correct English language constructs. Unlike other data sources like Reddit or Wikipedia, 4chan data significantly increases the model’s use of ‘I’ statements, suggesting a more self-involved or egocentric output, which may not be desirable for assistant-style chatbots. This contrasts with Twitter data, which is noted to degrade model performance rapidly.
A technical discussion on the impact of using different chat templates and data sources reveals that the combination of ChatML and abliteration can significantly alter a model’s behavior and political alignment. Despite expectations that chat templates would have minimal impact, the observed changes were substantial, with KL divergence indicating a shift from Classical Liberalism to Centrism, suggesting a profound alteration in the model’s world view.
The comment on alignment tax suggests that smaller models may face greater challenges in maintaining alignment when incorporating diverse data sources. This implies that the complexity and size of a model could influence how it integrates and balances various data inputs, potentially affecting its performance and bias.
Less Technical AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Claude Sonnet 5 Release and Features
Sonnet 5 next week? (Activity: 695): The image depicts an HTTP 404 error message indicating that the ‘Publisher Model’ for ‘claude-sonnet-5’ was not found, suggesting either a non-existent model or lack of access permissions. This aligns with the post’s discussion about the anticipated release of Sonnet 5, which is expected to offer
1 million context, be priced at1/2 the price of Opus 4.5, and be trained on TPUs, promising significant improvements in agentic coding. The error message may imply that the model is not yet publicly available or accessible, hinting at its imminent release. Commenters express excitement about Sonnet 5’s potential, noting that it could surpass existing models like Opus 4.5. There is also speculation about upcoming releases of other models like GPT 5.3 and Gemini 3, indicating a competitive landscape.The discussion highlights the potential of Sonnet 5 as a ‘competition killer,’ suggesting it could significantly outperform existing models like Opus 4.5. This indicates a high level of anticipation and expectation for Sonnet 5’s capabilities in the AI community.
There is speculation about the training infrastructure for upcoming models, with a focus on Google’s TPUs. The mention of Gemini 3 being trained entirely without Nvidia hardware suggests a strategic shift towards TPUs, which could have implications for performance and cost efficiency in AI model training.
The comment about the ‘clean’ and ‘polished’ nature of Anthropic products suggests a focus on user experience and product refinement, which could be a competitive advantage in the AI market. This highlights the importance of not just performance, but also the usability and integration of AI products.
Sonnet 5 release on Feb 3 (Activity: 1979): Claude Sonnet 5, codenamed “Fennec,” is reportedly set for release on February 3, 2026, as indicated by a Vertex AI error log. It is rumored to be 50% cheaper than its predecessor, Claude Opus 4.5, while maintaining a
1M tokencontext window and offering faster performance. The model is allegedly optimized on Google TPUs, enhancing throughput and reducing latency. It introduces a “Dev Team” mode, allowing autonomous sub-agents to build features collaboratively. Insider leaks suggest it scores80.9%on SWE-Bench, surpassing current coding models. However, some skepticism exists regarding the release date and the validity of the error log as proof of the model’s existence. Commenters express skepticism about the release date, noting that Anthropic’s model IDs typically reflect the creation date rather than the release date. Concerns are also raised about the accuracy degradation in large context windows, which was an issue in previous models.andrew_kirfman discusses skepticism about the timing of the Sonnet 5 release, referencing a 404 error from a Vertex API endpoint that doesn’t confirm the model’s existence. They highlight that Anthropic’s model IDs often reflect the creation date of the model checkpoint, not the release date, citing Opus 4.5’s ID as an example. They express doubt about future-dating release tags, which is uncommon in software releases.
andrew_kirfman also mentions the potential for a 1 million token context in Sonnet 5, noting that previous models like Sonnet 4 and 4.5 already offered this through the API. However, they point out that accuracy degradation was an issue with these models, suggesting that improvements in this area would be necessary for trust in the new model.
LuckyPrior4374 expresses skepticism about claims that Sonnet 5 outperforms previous models, specifically mentioning Opus 4.5. This comment implies a distrust in marketing claims that suggest significant improvements without substantial evidence, hinting at past experiences where expectations were not met.
Sonnet 5 being release on Wednesday where is Gemini 3.5 ? (Activity: 165): Claude Sonnet 5, codenamed “Fennec,” is rumored to be a significant advancement over existing models, including the unreleased Gemini 3.5. It is expected to be
50% cheaperthan Claude Opus 4.5, while maintaining a1M token context windowand offering faster performance. The model is reportedly optimized on Google TPUs, which enhances throughput and reduces latency. It features a “Dev Team” mode, allowing autonomous sub-agents to execute tasks in parallel, and has achieved an80.9%score on SWE-Bench, surpassing current coding models. A Vertex AI error log suggests a release window of February 3, 2026, indicating its presence in Google’s infrastructure. Commenters express skepticism about the release of Gemini 3.5, noting that Gemini 3 is still in preview and facing issues. There is doubt about the existence of Gemini 3.5, with some considering it a “pipe dream.”alexander_chapel points out that Gemini 3 is still in preview, questioning the expectation of a 3.5 release. This highlights the current state of Gemini 3, which is not yet fully released, suggesting that any talk of a 3.5 version might be premature or based on rumors.
Lost-Estate3401 mentions that the Pro version of Gemini 3 is still in preview and has numerous issues, indicating that a 3.5 version might be unrealistic at this stage. This comment underscores the challenges faced by the current version, which could delay further updates or enhancements.
philiposull compares Gemini 3 unfavorably to other models like 4-5 opus in terms of writing capabilities, suggesting that Google is lagging behind in this area. This comparison highlights potential performance gaps and the competitive landscape in AI model development.
2. Innovative AI Model and Tool Launches
MIT’s new heat-powered silicon chips achieve 99% accuracy in math calculations (Activity: 521): MIT researchers have developed a novel silicon chip that utilizes waste heat for computation, achieving over
99%accuracy in mathematical calculations. This chip leverages temperature differences as data, with heat naturally flowing from hot to cold regions to perform calculations, specifically matrix vector multiplication, which is crucial in AI and machine learning. The chip’s structure is made from specially engineered porous silicon, with its internal geometry algorithmically designed to guide heat along precise paths. Although not yet a replacement for traditional CPUs, this technology could significantly reduce energy loss and cooling requirements in future chips, with potential applications in thermal sensing and low-power operations. Commenters note that while99%accuracy is impressive, it may not suffice for the trillions of operations in modern applications, and they express hope for error correction mechanisms. There is also skepticism about the scalability of the technology, given the current matrix sizes of2x2and3x3.ReasonablyBadass highlights a critical perspective on the 99% accuracy of MIT’s heat-powered silicon chips, noting that while 99% seems high, it may not suffice for modern applications that require trillions of operations. The comment suggests that the chips currently handle small matrices, such as 2x2 and 3x3, indicating that there is still significant progress needed for broader applicability.
Putrumpador raises a concern about the need for error correction mechanisms in conjunction with the 99% accuracy of the new chips. This implies that while the chips are innovative, their practical deployment in critical systems would require additional layers of reliability to handle potential inaccuracies.
BuildwithVignesh references the research published in the Physical Review, providing a link to the paper, which could be valuable for those interested in the technical details of the study. This suggests that the research is peer-reviewed and accessible for further academic scrutiny.
Shanghai scientists create computer chip in fiber thinner than a human hair, yet can withstand crushing force of 15.6 tons (Activity: 994): Scientists at Fudan University have developed a flexible fiber chip, as thin as a human hair, that can withstand a crushing force of 15.6 tons. This fiber chip integrates up to
100,000 transistors per centimeterand features a unique “sushi roll” design, which involves rolling thin circuit layers onto an elastic substrate to maximize space. The chip is highly durable, surviving10,000 bending cycles, stretching by30%, and temperatures up to100°C. It is intended for applications in smart textiles, brain-computer interfaces, and VR gloves. The study was published in Nature in January 2026. Image. Comments highlight a potential error in the description of the fiber’s width, suggesting it is10 times widerthan stated. There is also skepticism about the claim that a one-meter strand has processing power comparable to a classic CPU, noting potential latency issues.KidKilobyte points out a potential error in the reported dimensions, noting that human hair is typically 50 to 100 microns wide, suggesting the chip’s fiber might be inaccurately described as thinner than a human hair. This raises questions about the precision of the measurements or descriptions provided in the original report.
Practical-Hand203 highlights a potential issue with the claim that a one-meter strand of the fiber has processing power comparable to a classic CPU. They suggest that if the processor die were stretched over one meter, it would likely suffer from severe latency issues, indicating a misunderstanding or oversimplification of the technology’s capabilities.
BuildwithVignesh references the publication of the study in the journal Nature, providing a link to the article. This suggests that the research has undergone peer review, which adds credibility to the findings, although the technical details and implications of the study are not discussed in the comment.
[P] PerpetualBooster v1.1.2: GBM without hyperparameter tuning, now 2x faster with ONNX/XGBoost support (Activity: 39): PerpetualBooster v1.1.2 introduces significant enhancements to its gradient boosting machine (GBM) implemented in Rust, focusing on eliminating hyperparameter tuning through a single ‘budget’ parameter. The update boasts up to
2xfaster training, full R release, ONNX support, and native ‘Save as XGBoost’ for improved interoperability. It also includes zero-copy Polars support for efficient data handling and guarantees API stability with backward compatibility to v0.10.0. Benchmarks indicate a100xwall-time speedup compared to LightGBM + Optuna, achieving similar accuracy in a single run. GitHub Users appreciate the speed improvements and the novel approach of using a single ‘budget’ parameter instead of traditional hyperparameter tuning, though some find it unusual to adjust to this new method.Alternative-Theme885 highlights the significant speed improvements with PerpetualBooster, noting the unusual experience of not needing to manually adjust hyperparameters. Instead, users set a budget, which the tool uses to optimize performance, streamlining the process compared to traditional methods.
whimpirical inquires about the interoperability of PerpetualBooster with SHAP, a popular tool for interpreting machine learning models. They are particularly interested in documentation related to extracting feature contributions and generating Partial Dependence Plots (PDP), which are crucial for understanding model behavior and feature impact.
{kind=link}
3. AI in Professional and Research Settings
[D] MSR Cambridge vs Amazon Applied Science internship, thoughts? (Activity: 118): The post discusses a PhD student’s decision between two internship offers: one at Microsoft Research (MSR) Cambridge and the other at Amazon Applied Science in the US. The MSR Cambridge position offers strong alignment with the student’s PhD research and the potential for publications, but with significantly lower compensation compared to the US offer. The Amazon role offers higher pay and the possibility of contributing to a paper if the project is research-oriented. The student is considering the impact of US-based networking versus the prestige and research fit of MSR Cambridge, especially given their long-term goal to work in the US post-PhD. Commenters overwhelmingly favor the MSR Cambridge internship, citing its prestige and research opportunities as career-enhancing. They express skepticism about Amazon’s work environment, suggesting it may not be as conducive to pure research.
Microsoft Research (MSR) Cambridge is highlighted as a prestigious research group, known for its significant impact on a researcher’s career trajectory. The emphasis is on the long-term benefits of being associated with a renowned institution like MSR, which can enhance one’s resume and open up future opportunities in academia and industry.
The discussion suggests that Amazon’s Applied Scientist role may not be as research-focused as MSR, with some comments implying that the work environment at Amazon might not be ideal for those seeking a research-oriented career. The term ‘PIP factory’ is used to describe Amazon, indicating a potentially high-pressure environment with performance improvement plans.
Several comments stress the importance of focusing on career-building opportunities rather than immediate compensation when choosing an internship. The consensus is that early career decisions should prioritize resume-building and gaining experience at reputable institutions like MSR, which can lead to better long-term career prospects.
We ran a live red-team vs blue-team test on autonomous OpenClaw agents [R] (Activity: 44): In a recent adversarial security test using OpenClaw autonomous agents, a red-team attacker and a blue-team defender were pitted against each other without human intervention. The attacker initially used social engineering tactics, embedding a remote code execution payload in a security pipeline, which the defender successfully blocked. However, the attacker succeeded with an indirect attack by embedding shell expansion variables in a JSON document’s metadata, highlighting the difficulty in defending against indirect execution paths. This exercise aimed to identify real failure modes in agent-to-agent interactions, not to claim safety. For more details, see the full report. Commenters noted that similar attack scenarios were theorized as early as 2019 by figures like Eliezer Yudkowsky and Scott Alexander, but the practical application is more relevant now with widespread use. Another commenter emphasized the risk of memory injection attacks in OpenClaw, suggesting that persistent memory files are a significant vulnerability and advocating for treating deployments as prompt injection targets from the start.
JWPapi highlights a critical security vulnerability in OpenClaw agents related to memory injection. The persistent memory files (
.md) used by OpenClaw are identified as a significant attack vector because they can influence all future agent behavior once compromised. JWPapi suggests treating the entire deployment as a prompt injection target from the start, advocating for isolated credentials, spending caps, and separate blast radiuses for each integration to mitigate risks. More details are discussed in their article on practical VPS deployment here.sdfgeoff references historical discussions from 2019 and 2020 by figures like Eliezer Yudkowsky and Scott Alexander, who theorized about AI attacks shortly after the release of GPT-2. These early discussions predicted many of the attack vectors now being tested in real-world scenarios, highlighting the shift from theoretical to practical applications as more people deploy these systems. This historical context underscores the evolution of AI security concerns as deployment scales increase.
Uditakhourii provides a link to a full report on the live red-team vs blue-team test of OpenClaw agents, which offers detailed insights into adversarial AI interactions. The report is available here and is likely to contain comprehensive data and analysis on the security audit, useful for those interested in the technical aspects of AI security testing.
Boston Consulting Group (BCG) has announced the internal deployment of more than 36,000 custom GPTs for its 32,000 consultants worldwide. (Activity: 70): Boston Consulting Group (BCG) has deployed over
36,000 custom GPTsfor its32,000 consultants, emphasizing AI as infrastructure in knowledge work. These GPTs are role-specific, trained on internal methodologies, and possess project memory, enabling them to be shared across teams. This approach contrasts with many organizations that use AI in isolated, non-scalable ways. BCG’s strategy focuses on creating, managing, and scaling custom GPTs, facilitated by tools like GPT Generator Premium, which supports the creation and management of these AI agents. The deployment reflects a shift towards AI as a fundamental component of business operations, rather than a mere tool. Comments highlight skepticism about the value of GPTs, questioning their ability to innovate and the sustainability of business models reliant on such large-scale AI deployment. Concerns include the potential for GPTs to provide ‘canned answers’ and the implications for consulting fees.
AI Discord Recap
A summary of Summaries of Summaries by gpt-5.2
1. Agentic Coding & Dev Tooling Goes Local-First
Codex Goes Desktop: macOS Agent Command Center: OpenAI shipped the Codex app for macOS as an agent-building command center, available for Plus/Pro/Business/Enterprise/Edu with limited-time access on ChatGPT Free/Go, per “Introducing the Codex app” and the Codex landing page.
The launch also spilled into community workflow chatter (pairing agents, multi-agent “command centers”), and a related Codex App hackathon with $90,000 in credits showed up via Cerebral Valley’s event page.
LM Studio Speaks Anthropic: Claude Code Meets Your Local GGUF/MLX: LM Studio 0.4.1 added an Anthropic
/v1/messagescompatibility API, letting developers point Claude Code-style tools at local GGUF/MLX models by changing the base URL, detailed in “Using Claude Code with LM Studio”.In parallel, LM Studio also pushed a TypeScript SDK for third-party plugins and an OpenAI-compatible endpoint (SDK link), reinforcing a growing pattern: reuse existing agent tooling while swapping the backend model stack locally.
Arena Mode Everywhere: Windsurf Turns Model Eval into a Game: Windsurf shipped Wave 14 with Arena Mode for side-by-side model battles (including Battle Groups and “Pick your own”), and temporarily set Battle Groups to 0x credits via the Windsurf download page.
This mirrored broader “live eval” momentum: users also tracked new Arena entrants like step-3.5-flash and qwen3-max-thinking on LMArena’s Text Arena and Code Arena, shifting selection from static benchmarks to continuous human voting.
2. Model Releases & Bench Races (Kimi vs GLM vs Qwen)
Kimi K2.5 Speedruns the Leaderboards: Moonshot’s Kimi K2.5 landed broadly in product surfaces: Perplexity Pro/Max added it for subscribers and said it runs on a US-based inference stack for tighter latency/reliability/security control (announcement screenshot: https://cdn.discordapp.com/attachments/1047204950763122820/1466893776105771029/20260130_203015.jpg).
Community results piled on: LMArena reported Kimi-K2.5-thinking hit #1 open and #5 overall in Code Arena (see Code Arena), while multiple dev channels argued over its tool-calling reliability and provider variance when routed through aggregators.
GLM-4.7 Flash: Small Model, Big Front-End Energy: Developers highlighted GLM-4.7 flash as a surprisingly strong coding model—especially for interactive website/front-end work—citing preserved reasoning and interleaved capability, with discussion anchored on ggerganov’s post.
The debate sharpened around whether stripping “thinking” harms performance, and several users described pairing GLM-4.7 with Claude Code (or Claude-like agent tooling) as a pragmatic hybrid stack: cheap execution + expensive review.
New Arena Entrants: step-3.5-flash & qwen3-max-thinking Join the Party: LMArena added step-3.5-flash to the Text Arena and qwen3-max-thinking to the Code Arena, explicitly positioning them as fresh baselines for side-by-side evaluation.
Users used these drops to re-litigate “model preference” threads (Kimi vs GLM vs Gemini), with the recurring takeaway that leaderboards and live evals increasingly drive adoption more than vendor marketing.
{kind=link}
3. Training Signals, Dense Rewards, and New Architectures/Datasets
From Binary Rewards to Dense Supervision: RL Gets Wordy: Multiple communities converged on richer post-training signals: Unsloth discussions pushed training with logprobs of final answers and non-binary rewards, referencing Jonas Hübotter’s method for turning descriptive feedback into dense supervision (Hübotter thread).
The sticking point stayed practical: people asked for verifiable datasets for RL training agentic coding, implying a pipeline gap between “cool reward shaping idea” and “reproducible, automated evaluation harness.”
Complexity-Deep: Token-Routed MLP Tries MoE Without the Load-Balancing Headache: The Complexity-Deep (1.5B) architecture open-sourced Token-Routed MLP for MoE-style routing “without load balancing loss,” plus Mu-Guided Attention and a PiD Controller, shipping code at Complexity-ML/complexity-deep and reporting 20.6% MMLU (base).
The community framed it as another step in the “routing without pain” trend—trying to keep MoE wins while reducing the training-time engineering tax of balancing experts.
Moltbook Data Dump: 50k Posts for Agent Sociology: A dataset scrape of Moltbook landed on Hugging Face with 50,539 posts, 12,454 AI agents, 195,414 comments, and 1,604 communities, published as lysandrehooh/moltbook.
Elsewhere, researchers flagged the security implication behind agent platforms (auth tokens on machines, bot authenticity concerns) and treated the dataset as fuel for analyzing emergent behavior—without needing to speculate beyond the raw logs.
4. GPU/Kernel Engineering: Faster Attention, Better Profiling, Weirder PTX
FlashAttention v3 Hits RDNA: AMD Users Get Their Turn: A FlashAttention update added RDNA GPU support via the ongoing work in flash-attention PR #2178, aiming to reduce attention bottlenecks on AMD cards.
The tone across servers was basically: this is the sort of “unsexy infra work” that actually unlocks local inference and finetuning on non-NVIDIA hardware—especially when paired with open-weight models and desktop agent tooling.
Triton-Viz v3.0: Tile-Kernel Debugging Gets Teeth: Triton-Viz v3.0 shipped with broader profiling support (including Triton and Amazon NKI) plus a sanitizer for out-of-bounds access and a profiler that flags inefficient loops, per the release announcement (Discord link: https://discord.com/channels/1189498204333543425/1225499141241573447/1467634539164602563).
It also hooked into triton-puzzles via a shared Colab notebook (Colab), and maintainers even floated moving srush/Triton-Puzzles under the GPU Mode org to keep bugfix velocity high.
sm120: TMA + mbarrier Beats cp.async (Barely), cuBLAS Still Ships sm80 Kernels: Experiments on sm120 showed that careful TMA + mbarrier implementation can edge out
cp.asyncfor larger matrix shapes, while also surfacing that cuBLAS still appears to run sm80 kernels even when newer mechanisms exist.On the debugging front, one CUDA/PTX deadlock got fixed by inserting
__syncthreads()after MMA before prefetching the next TMA, turning a hang into a measurable perf gain—exactly the kind of “one barrier to rule them all” lesson kernel folks keep re-learning.
5. Security, Determinism, and Agent Misbehavior (the Practical Kind)
Prompt Injection Defense Arms Race: Embeddings + Grammar-Constrained Decoding: Red teamers shared a structured exercise site for adversarial practice—“Adversarial Design Thinking”—and used it to tee up concrete mitigations for prompt injection.
One proposed “belt + suspenders” defense combined embedding-based filtering with Grammar Constrained Decoding, with the explicit goal of reducing injection surface by constraining the model’s output space rather than only policing inputs.
Deterministic Reasoning and “Strict Mode” Fever Spreads: Across OpenAI and OpenRouter discussions, users pushed for determinism/replayability/traceability in LLM reasoning; one person offered a deterministic reasoning engine that enforces a fixed structure and emits a 32D statistical vector trace (no public link shared).
In OpenRouter, the same instinct showed up as skepticism about response healing and calls for a strict mode that keeps tool calls and outputs predictable—plus suggestions that better argument descriptions/examples improve tool-call accuracy.
OpenClaw: Cool Agent Tricks, Scary Bills, and “2/100 Security”: OpenClaw sparked repeated warnings: OpenRouter users reported it can drain credits fast (including one drained Claude Max subscription), while an OpenAI server linked a security assessment claiming OpenClaw scored 2/100 (Perplexity result).
Meanwhile, “works on my machine” stories (local models controlling devices, trading jokes) collided with real operational concerns—tool permissions, moderation/refusals (especially around jailbreak-y queries), and the need for observability and human-in-the-loop gates in agent workflows.
The first point about death of IDEs hit me hard b/c this is why I even started building my own Terminal App, as a base, and move counter-intuitively into the IDE space.
I wanted a Terminal that was customizable, fast, and not AI-native like the many iterations before it but I'm needing feature that IDEs have, like file browser and viewer, etc. Consequently, the IDE isn't dead IMHO — it's just moved down the line a bit as not the most important feature but a key feature on top of a best-in-class Terminal.
This swap is mind-blowing when you first think about it but it now makes more sense than ever.