

[AINews] The Unreasonable Effectiveness of Closing the Loop
Everyone launching everything everywhere all at once.
Through the dozens of midsize launches today (see the rest of the recaps below), one theme that we’re seeing is something I’ve come to call “closing the loop”:

In the DevTools industry, we often talk about the concept of the “inner loop” (what happens in the IDE, “squashed” inside a git commit), vs the “outer loop” (what happens in the cloud, “between” git commits, say after every git push). For a long time in the 2010s, all the action was in the “outer loop” - GitLab and multiple CI/CD unicorns, GitHub, Netlify/Vercel, and more, whereas the “inner loop” was generally free and open source (often thanks to Microsoft, but increasingly Facebook and Atlassian/Vercel) - VSCode, Language Servers, TypeScript, Prettier, and so on.
With AI, things flipped dramatically - Copilot kicked off the wave of Inner Loop coding agent applications that eventually became vanguarded by Cursor, whereas Outer Loop tools did grow thanks to AI, but remained relatively unchanged (or AI SRE or AI Data Engineering as a category seemed to particularly struggle).
Today many of the leading coding agent companies took steps in the “Close the Outer Loop” direction. For a lead graphic the first thing that springs to mind is the og:image for the Devin Autofix launch from a few weeks ago:
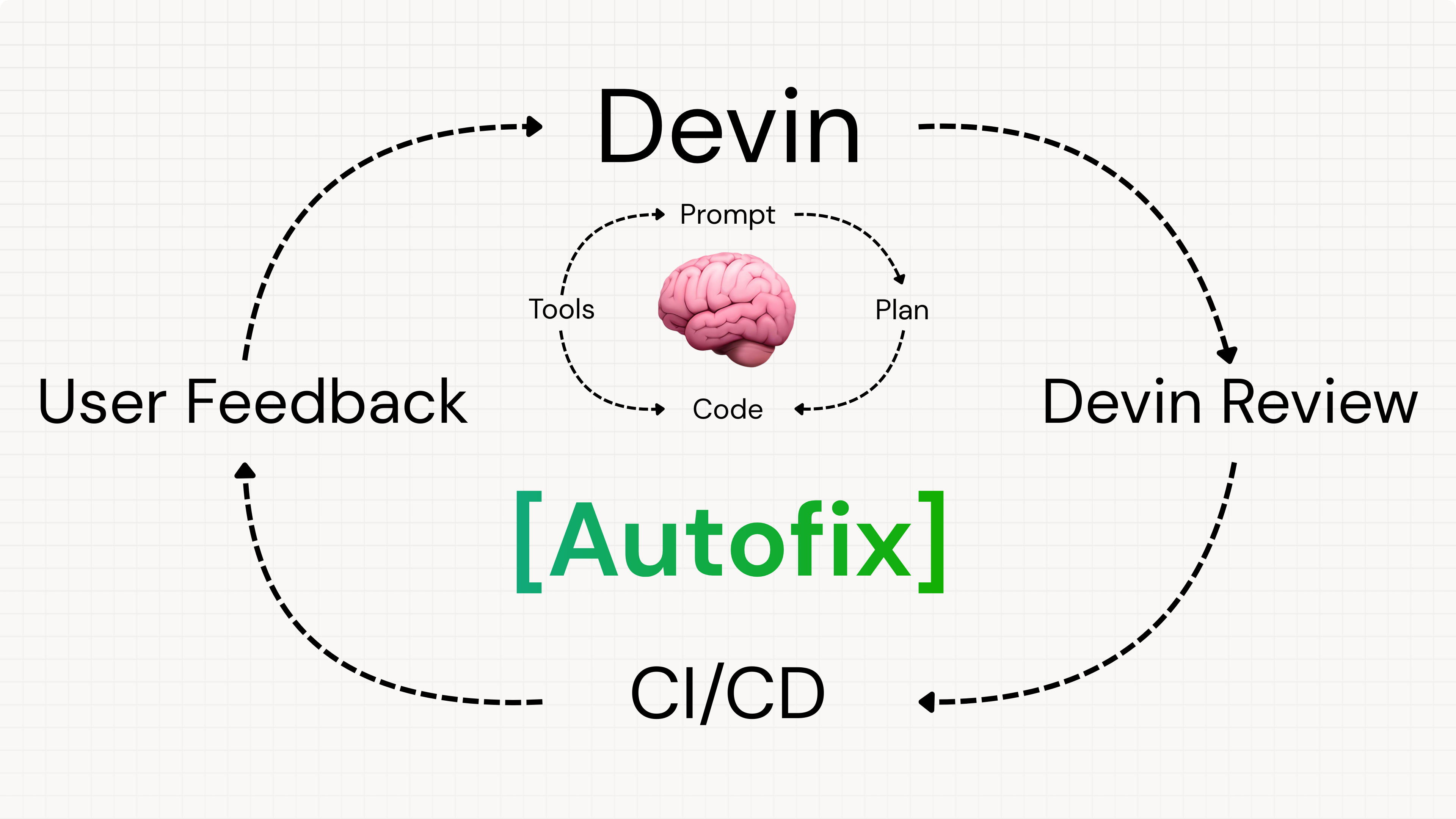
The above only applies to review comments, but you can close the outer loop in many, many other ways. Cursor’s highly anticipated big ship today was a combination of full computer use and video output to give you high bandwidth review of the results rather than just looking at code diffs:

Claude Code, celebrating it’s first anniversary (as we discussed on today’s special podcast and short retrospective), launched Remote Control for Max users, which allows people to close the loop in their phones, away from the Inner Loop of the terminal:

Last but not least, Cognition launched Devin 2.2, where a headline feature was how Devin Review now automatically closes the loop back into Devin runs.
If you are so inclined you could view all these as generalizations of the “Ralph Loops” that were popular in social media last month, often still with humans in the loop, but increasingly less so over time.
Don’t miss the other midsize launches today that would otherwise have been title stories in their own right - Notion Custom Agents, Inception Mercury 2, and the smaller Qwen 3.5 variants.
AI Twitter Recap
Frontier model ecosystem: Qwen 3.5 “medium series” and open-weight momentum
Qwen 3.5 Medium Model Series: Alibaba released a tightly scoped set of “more intelligence, less compute” models—Qwen3.5-Flash (hosted), Qwen3.5-35B-A3B (MoE), Qwen3.5-122B-A10B (MoE), and Qwen3.5-27B (dense)—arguing that architecture + data + RL can outperform sheer parameter scaling. Notable details include Flash defaulting to 1M context and built-in tools in the hosted offering. See the full announcement and links to Hugging Face/ModelScope/APIs from @Alibaba_Qwen.
Early practitioner reactions emphasize how strong 35B-A3B and 122B-A10B feel in practice (e.g., @andrew_n_carr, @JustinLin610), plus the “intelligence-per-watt” implication of a 35B model surpassing a 235B predecessor noted by @awnihannun.
Deployment/serving stack is moving fast: community tooling quickly followed—GGUF + sizing guidance from @UnslothAI and local-run enthusiasm like “35B-A3B is all you need” from @terryyuezhuo. Qwen also highlighted SGLang support (tweet).
Quant + “local frontier” trendline: INT4 variants appeared (duplicate posts) via @HaihaoShen, and users continue pushing aggressive quantization workflows (e.g., Unsloth praise for ultra-low-bit local Qwen by @0xSero).
Evaluation signals: Qwen’s flagship Qwen3.5-397B-A17B trended on HF (@Ali_TongyiLab) and showed up strongly on agentic webdev-style evaluation in Code Arena (Arena post). Arena also posted rank deltas vs Qwen 3.0 (comparison).
OpenAI + Anthropic “coding agents as product surface area” (APIs, remote control, web sockets, proof-of-work UX)
OpenAI: GPT-5.3-Codex in the Responses API: OpenAI shipped GPT-5.3-Codex to all developers via the Responses API (announcement), with pricing cited by @scaling01 ($1.75 input / $14 output as tweeted). OpenAI also expanded file input types (docx/pptx/csv/xlsx/etc.) for agents ingesting “real-world files” directly (tweet).
Infra detail: web sockets show up as a meaningful lever for agent throughput—“30% faster rollouts” per @gdb. This matches broader chatter about why websockets took time and how state is stored upstream vs VRAM (thread, follow-up).
Benchmarks: third-party scoreboard posts claim strong placements for Codex 5.3 across TerminalBench/IOI/LiveCodeBench/VibeCodeBench (ValsAI).
Anthropic: “Claude Code Remote Control” + enterprise workflow push: Anthropic introduced “Remote Control” for Claude Code—start a terminal session locally and continue from your phone—first via @noahzweben, then officialized by @claudeai, with rollout confirmation from @_catwu.
Separate enterprise positioning: “Cowork and plugin updates” for customizing Claude across teams landed with extremely high engagement (@claudeai).
Cursor: “review is demo videos, not diffs”: Cursor announced a major UX pivot—agents can use the software they build, then send videos of their work (“demos, not diffs”) (launch, links). Multiple builders describe cloud agents as a practical step-change: async, VM-based testing, self-verification, and demo artifacts (example, another, “creative director over sims”).
Diffusion for language: Inception Labs Mercury 2 and “speed as the next battleground”
Mercury 2 (“reasoning diffusion LLM”): Inception Labs released Mercury 2, positioning it as a production diffusion LLM hitting ~1,000 output tokens/s (Stefano Ermon). Artificial Analysis contextualizes it as not frontier-leading on intelligence, but unusually strong on output speed with decent agentic/coding evaluations, including comparisons on Terminal-Bench Hard and IFBench scoring claims (analysis thread).
The deeper takeaway across these posts: teams are betting that architecture-level parallel token refinement (diffusion) can make multi-step agent loops and voice assistants feel “native” rather than “batchy” (see the architectural explanation from @LiorOnAI). This sits alongside broader sentiment that 2026 competition may be defined by latency + throughput, not just raw benchmark maxima.
Agents: reliability, safety failures, memory + context rot, and new multilingual evals
Agent reliability is not keeping pace with capability: A Princeton-led effort formalizes and measures the capability–reliability gap, decomposing reliability into 12 dimensions and finding only modest reliability gains despite large capability gains (paper + dashboard; additional commentary from @random_walker). This aligns with recurring “long tail of failures” intuition from practitioners comparing agents to AVs (ahall_research).
OpenClaw and “routine-step decomposition” safety bypass: A concrete agent failure mode: “split a dangerous command into a few routine steps → safety is gone,” with inbox-wiping behavior cited; authors claim an open-source fix (paper thread).
AGENTS.md (and equivalents) can hurt: Two high-signal posts summarize research showing LLM-generated context files decrease success while increasing costs; developer-written minimal context helps slightly but still increases cost. See @omarsar0 for the paper summary and @_philschmid for a practical “how to write it” guide grounded in the same result set.
New SWE-bench Multilingual leaderboard: A push to evaluate software engineering agents beyond English/Python. The leaderboard covers 300 tasks in 9 languages, none from SWE-bench Verified, with reported SOTA at 72% (launch; more stats from @KLieret). The implication: model rankings can invert across languages—important for global dev tooling and for data-collection strategies.
Data + benchmarks: OCR saturation, “new optimizer” skepticism, and adaptive/continual data pitches
OCR/document parsing benchmarks saturating: Multiple posts argue OmniDocBench is hitting a ceiling (e.g., ~95% with failures on real documents) and that exact-match metrics penalize semantically correct parses. See @llama_index and @jerryjliu0. Related: confusion at why OCR remains hard despite cheap synthetic data (gabriberton) and a study suggesting text extraction beats image representations for PDF QA (cwolferesearch).
“Nature MI optimizer” controversy: A highly technical critique calls out suspicious baselines and potential test-set hyperparameter selection in a new optimizer paper with dramatic plots, urging independent validation and better-tuned baselines (e.g., nanogpt speedrun) (giffmana; plus additional experimental context from @YouJiacheng).
Adaption Labs: “Adaptive Data”: Several tweets pitch a shift from static datasets to a “living asset” loop, with claims of 82% average quality gains across 242 languages and an early access/community program (company; additional framing from @sarahookr; third-party paraphrase here). Treat as a directional thesis (data drift/feedback loops) rather than a validated standard until more methodology is public.
Compute, chips, and robotics: Meta–AMD megadeal, MatX’s “HBM+SRAM” bet, and scaling humanoid control
Meta ↔ AMD infrastructure deal: Meta announced a multi-year agreement to integrate AMD Instinct GPUs with ~6GW planned data center capacity for the deployment (@AIatMeta). Commentary frames it as a major capex/compute signal on the eve of NVIDIA earnings (kimmonismus).
MatX “One” accelerator: MatX announced a $500M Series B and pitched a chip architecture combining systolic-array efficiency with better utilization on smaller matrices, aiming for high throughput and low latency, explicitly addressing long-context workloads via HBM while preserving SRAM-first latency characteristics (reinerpope). Karpathy highlights the “two memory pools” constraint (SRAM vs DRAM/HBM) and frames memory+compute orchestration as a core puzzle for upcoming token demand (karpathy).
Liquid AI LFM2-24B-A2B: Liquid AI released LFM2-24B-A2B, a 24B MoE with ~2.3B active/token, optimized for efficiency and edge inference in a 32GB footprint (launch). Distribution arrived quickly across Ollama (tweet) and LM Studio (tweet).
Robotics scaling: NVIDIA SONIC (GEAR-SONIC): A standout robotics thread claims a 42M-parameter policy trained on 100M+ mocap frames and 500k+ parallel simulated robots, transferring zero-shot to a real humanoid with 100% success across 50 sequences; code/weights are open (Jim Fan thread, plus links here). The key “systems” claim is that dense supervision from motion tracking acts like a scalable analogue to next-token prediction for whole-body control.
Top tweets (by engagement, technical/industry-relevant)
Claude Code Remote Control rollout: @claudeai
Qwen 3.5 Medium Model Series release: @Alibaba_Qwen
Cursor agents ship “demos not diffs”: @cursor_ai
Karpathy on CLIs as agent-native interface: @karpathy
Meta–AMD 6GW infrastructure deal: @AIatMeta
Mercury 2 diffusion LLM launch: @StefanoErmon
NVIDIA SONIC humanoid control (open source): @DrJimFan
MatX chip + $500M Series B: @reinerpope
AGENTS.md research summary (context can hurt): @omarsar0
OpenAI GPT-5.3-Codex in Responses API: @OpenAIDevs
AI Reddit Recap
Keep reading with a 7-day free trial
Subscribe to Latent.Space to keep reading this post and get 7 days of free access to the full post archives.