

"RAG is Dead, Context Engineering is King" — with Jeff Huber of Chroma
What actually matters in vector databases in 2025, why “modern search for AI” is different, and how to ship systems that don’t rot as context grows.
The AI Engineer Fall Summit is coming back to NYC - Nov 20-21! Apply now.
In December 2023, we first covered The Four Wars of AI and the RAG/Ops War. After tens of millions poured into vector databases, ups and downs in the hype cycle, we finally have Jeff Huber from Chroma joining us today for the new hot take: “RAG” is dead…

and as context lengths increase, and more and more AI workloads are shifting from simple chatbots to IMPACTful agents, new work from thoughtleaders like Lance Martin and Dex Horthy are making genuine contributions of substance to the previously underrated context box.
Chroma has been driving some of the most interesting research in the new context engineering space, including their Context Rot and Generative Benchmarking reports.
We spent most of our time talking about current state of retrieval, memory, retrieval benchmarking, etc.
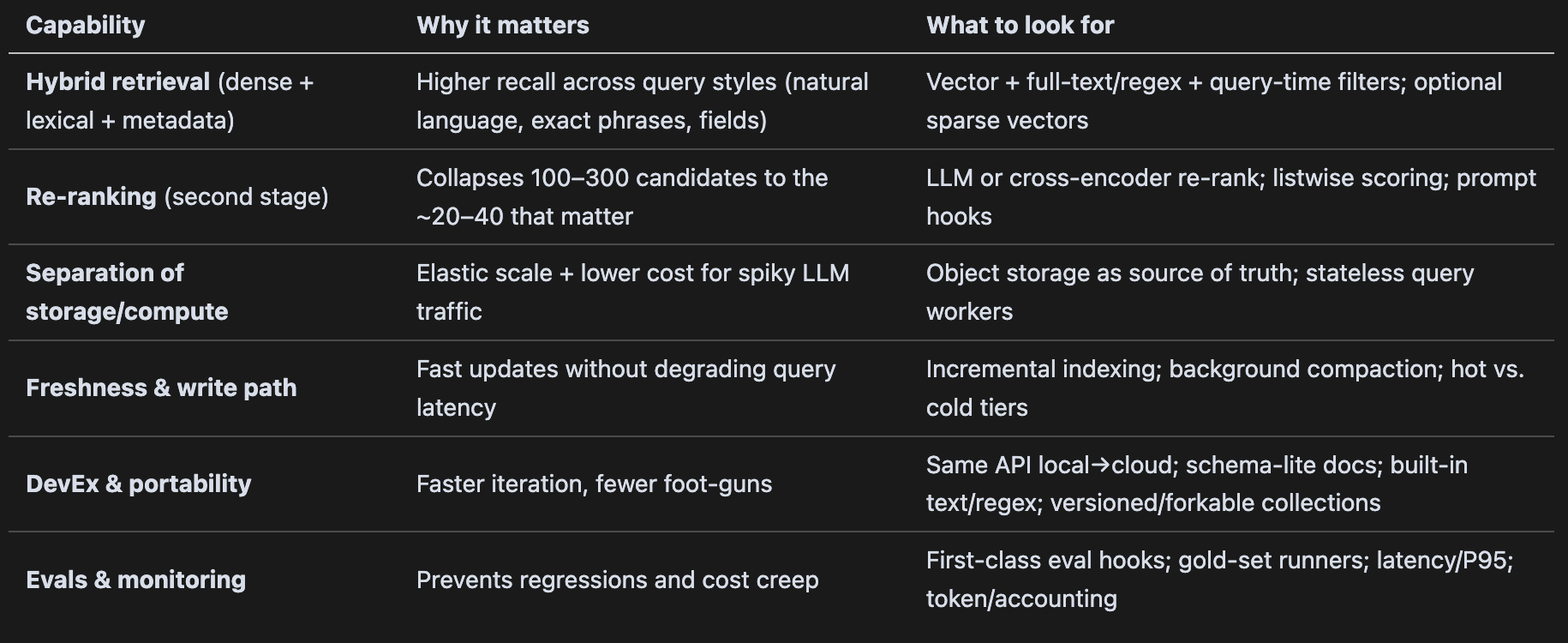
The 5 Retrieval Tips
Don’t ship “RAG.” Ship retrieval. Name the primitives (dense, lexical, filters, re‑rank, assembly, eval loop).
Win the first stage with hybrid recall (200–300 candidates is fine—LLMs can read).
Always re‑rank before you assemble context.
Respect context rot: tight, structured contexts beat maximal windows.
Invest one evening in buying some pizza and creating a small gold set; wire it into CI and dashboards.
[Ingest]
├─ Parse + chunk (domain-aware: headings, code blocks, tables)
├─ Enrich: titles, anchors, symbols, metadata
├─ Optional: LLM “chunk summaries” (NL glosses for code/API)
├─ Embeddings (dense) + optionally sparse signals
└─ Write to DB (text, vectors, metadata)
[Query]
├─ First-stage hybrid: vector + lexical/regex + metadata filters
├─ Candidate pool: ~100–300
├─ Re-rank (LLM or cross-encoder) → top ~20–40
└─ Context assembly:
- instructions/system prompt first
- dedupe/merge near-duplicates
- diversify sources
- hard cap on tokens
[Outer loop]
├─ Cache/cost guardrails
├─ Generative benchmarking on small gold sets
├─ Error analysis → re-chunk/retune filters/re-rank prompt
└─ Memory/compaction: summarize interaction traces → retrievable facts
Our podcast studio is at the Chroma office, so it we were excited to finally have our landlord as a guest! Enjoy!
Show Notes
Timestamps
[00:00:00] Introductions
[00:00:48] Why Build Chroma
[00:02:55] Information Retrieval vs. Search
[00:04:29] Staying Focused in a Competitive AI Market
[00:08:08] Building Chroma Cloud
[00:12:15] Context Engineering and the Problems with RAG
[00:16:11] Context Rot
[00:21:49] Prioritizing Context Quality
[00:27:02] Code Indexing and Retrieval Strategies
[00:32:04] Chunk Rewriting and Query Optimization for Code
[00:34:07] Transformer Architecture Evolution and Retrieval Systems
[00:38:06] Memory as a Benefit of Context Engineering
[00:40:13] Structuring AI Memory and Offline Compaction
[00:45:46] Lessons from Previous Startups and Building with Purpose
[00:47:32] Religion and values in Silicon Valley
[00:50:18] Company culture, design, and brand consistency
[00:52:36] Hiring at Chroma: Designers, Researchers, and Engineers
Transcript
Alessio [00:00:04]: Hey, everyone. Welcome to the Latent Space podcast in the new studio. This is Alessio, partner and CTO at Decibel, and I'm joined by Swyx, founder of SmolAI.
Swyx [00:00:11]: Hey, hey, hey. It's weird to say welcome because obviously, actually, today's guest, Jeff, has welcomed us to Chroma for many months now. Welcome. Thanks for having me. Good to be here. Jeff, you're a founder, CEO of Chroma. I've sort of observed Chroma for a long, long time, especially back in the old office. And you were, you originally sort of got your start in the open source vector database, right? Like you sort of, you're the open source vector database of choice of a lot of different projects, particularly with even, even projects like the Voyager paper, you guys were used in that. I don't even know like the full list, but how do you introduce Chroma today?
Why Build Chroma
Jeff [00:00:48]: It's a good question. I mean, naturally, you always want to kind of take your messaging and make it fit your audience. Yeah. But I think the reason that Chroma got started. Is because we had worked for many years in applied machine learning and we'd seen how demos, demos were easy to build, but building a production reliable system was incredibly challenging and that the gap between demo and production didn't really feel like engineering. It felt a lot more like alchemy. There's some good, like XKCD memes about this guy standing on top of a giant steaming pile of garbage and the other character asks, this is your data system. And he's like, yes. And he's like, how do you know if it, how do you know if it's good or how do you make it better? Oh, you just like stir the pot and then like, see if it gets any better. That just seemed intrinsically wrong. And this is back in like 2021, 2022, that like we were having these conversations. And so that coupled with like a thesis that like Latent Space was a very important tool. That is a plug. Yes, that is a plug. We need to ring the bell. Yeah, exactly. The gong. That Latent Space, both the podcast, but also the technology was a very underrated tool and a very like important tool for interpretability. It's fundamentally how models see their own. Data, we as humans can kind of, you know, have that shared space to understand what's going on. That's where we got started. And so I think that's also where we continue to want to go. Like, what do we want to do? We want to help developers build production applications with AI and what would make the process of going from demo to production feel more like engineering and less like alchemy. Doing a database is like not a side quest. It is a part of the main quest. What we realized along the way was search was really a key workload to how like AI applications were going to get built. It's not the only workload, but it's like definitely a really important. Workload and that you don't earn the right to do more things until you've done one thing at a world class level that requires maniacal and, you know, kind of, uh, maniacal focus. Um, and so that's really what we've been doing for the last few years. That was a long kind of rambling introduction, but like maybe to sort of land the plane, you know, if you ask people, you know, what does Chrome do today? We build a retrieval engine for AI applications. We're working on modern search infrastructure for AI, um, some version of that.
Information Retrieval vs. Search
Swyx [00:02:55]: I'll do a double click on this. Is information retrieval and. And search the same thing, or are they slowly different in your mind? I just wanted to clarify our terminology. Yeah.
Jeff [00:03:04]: I think that, you know, that modern search infrastructure for AI, we're going to maybe unpack that for a couple of seconds. So modern is in contrast to traditional. And mostly what that means is like modern distributed systems. So there's a bunch of primitives and building great distributed systems that have come on to the scene in the last five, 10 years that obviously are not in technology that is older than that. By definition, separation of read and write separation of storage, compute, Chrome is written in rust. It's fully multi-tenant, um, we have, we use object storage as a key assistance tier and like data layer for Chroma, uh, distributed in Chroma cloud as well. So that's the modern piece. And then the four AI piece actually, I think is it matters in four kind of different ways. Like four AI means four different things. Like it means number one, the tools and technology that you use for search are different than in classic search systems. Number two, the workload is different than classic search systems. Number three, the developer is different than classic. Search systems and number four, the people who's the person who's consuming those search results is also different than in classic search systems. Think about like classic search systems. Like you as the human, we're doing the last mile of search, you know, you were doing click, click, exactly. You're like, oh, like which of these are relevant, open a new tab, summarize, blah, blah, blah, blah. You, the human we're doing that. And now it's a language model. Humans can only digest 10 blue links. Language models can digest orders of magnitude more. All of these things matter. And I think influence like how a system is designed. Yeah. Yeah. It's sort of like made for.
Staying Focused in a Competitive AI Market
Alessio [00:04:29]: Back in 2023, I think the VectorDB category was kind of one of the hottest ones. And you had Pinecon raise a hundred million. You had all these different WVAs, all these companies. Yeah. How did you stay focused on like what matter to you rather than just try to raise a lot of money and make a big splash? And it took you a while to release ChromaCloud too, which rather than just getting something out that maybe broke once you got to production, you kind of took your time. Yeah. Can you maybe give people advice on in the AI space, how to be patient? How do you have your own vision as a founder and how to have your own vision that you follow versus kind of like following the noise around you?
Jeff [00:05:03]: There are different ways to build a startup. And so, you know, there's schools of thought here. So one school of thought certainly is like the find signal and kind of follow the gradient descent of what people want sort of lean startup style. My critique of that would be that if you follow that methodology, you will probably end up building a gating app for middle schoolers because that just seems to be like the lowest base take of what humans want to some degree. The slot machine would be the AI equivalent of that versus, you know, the other way to build a startup is to have a very strong view, presumably a contrarian view, or at least a view that seems like a secret. And then to just be maniacally focused on that thing, you know, there are different strokes for different folks, but we've always taken the second approach. And yeah, there was the option of like, okay, Chroma's single node is like doing really well, getting a bunch of traffic. Clearly having a hosted service is the thing people want. Like we could just spend. Uh, we could very quickly get a product in the market, but we felt like no, really what we want Chroma to be known for is our developer experience. Like we want our brand to be, we want Chroma's brand and the craft expressed in our brand to be extremely well known. And we felt like by offering a single node product as a service, like it was not going to meet our bar of like what great developer experience could and should look like. Yeah, we made the decision of like, no, we're going to like build the thing that we think is right, which was really challenging, um, it took a long time and obviously I'm incredibly proud that it exists today and that it's like serving hundreds of thousands of developers and they love it, but it was hard to get there.
Alessio [00:06:38]: When you're building the team, how do you message that? If I go back maybe like a year and a half ago, you know, I could join Chroma, I could join all these different companies. How do you keep the vision clear to people when on the outside you have, oh, I'll just use PG vector or like, you know, whatever else the thing of the day is. Um, do you feel like that helps you bring people that are more aligned with the vision versus more of the missionary type on just joining this company before it's hot and maybe any learning that you have from recruiting early on?
Jeff [00:07:07]: The upstream version of Conway's law, like you ship your org chart is you ship your culture because I think your org chart is downstream of your company's culture. We've always placed an extremely high premium on that, on people that we actually have here on the team. Um, I think that the slope of our future growth is entirely. Dependent on the people that are here in this office and, you know, that could mean going back to zero. That could mean, you know, linear growth. That could mean all kinds of versions of like hyperlinear growth, exponential growth, hockey stick growth. And so, yeah, we've just really decided to hire very slowly and be really picky. And I don't know, I mean, you know, the future will determine whether or not that was the right decision, but I think having worked on a few startups before, like that was something that I really cared about was like, I just want to work with people that I love working with. And. Like want to be shoulder to shoulder with in the trenches. And I think in independently execute on the level of like craft and quality that like we owe developers. And so that was how we chose to do it.
Building Chroma Cloud
Swyx [00:08:08]: We'll talk about standard condition on the other fun stuff towards the end, but we'll, we'll focus on Chroma. I always want to put like some headline numbers up front. So I'm just trying to do a better job of like giving people the brain dump on what they should know about Chroma. 5 million monthly downloads is what I have on Pi Pi and 21,000 GitHub stars. Anything else people should know, like, that's like the typical sales call, like headline stuff like that, you know?
Jeff [00:08:33]: Yeah. Um, yeah, 20,000 GitHub stars, 5 million plus monthly downloads. Um, I've looked at the number recently, I think it's like over 60 or 70 million all time downloads now for many years running Chrome has been the number one used project broadly, but also within communities like playing chain and a lot of index. Okay, cool. Fair enough. Yeah.
Swyx [00:08:51]: I think like when you say single node Chroma, like I think you're describing the quality. Yeah. Like the core difference between like what Chroma cloud has been, and I think we're releasing this in, in line with like your GA and Chroma cloud. Uh, yes. So like, what should people know about Chroma cloud and like how you've developed this experience from, from the start? Like you, you, you mentioned separation of storage and compute, like what does that. Yeah.
Jeff [00:09:13]: A hundred percent. Chroma is known for its developer experience. I don't know that we were the first to do this. I think we were with Chroma, you just pip install ChromaDB and then you can use it. It's just like in memory. Like, I think you can persist.
Swyx [00:09:25]: It could be the first.
Jeff [00:09:26]: Database to ever be pip installable. Um,
Swyx [00:09:28]: Any SQLite wrapper is pip installable technically, you know? No, SQLite was not like pip installable even to this day. I don't think. Well, you would probably have a, a deeper dive and knowledge of this site. I'm just speculating myself. Yeah.
Jeff [00:09:40]: So that, that led to like a very seamless onboarding experience for new users. Cause you could just run a command and then you could use it. We did all the work to make sure that like, regardless of the deployment target or architecture that you're running it on, like it would just work. In the early days, we had people do really great stuff, like run it on Arduinos and PowerPC architectures and like really esoteric stuff, but like we would like go the extra mile to like, make sure that it worked everywhere and just, it just always worked. So that was Chroma single node. So going back to like the developer experience that we wanted to have in a cloud product, like we felt that in the same way that you could run pip install ChromaDB and be up and running in five seconds and like not have to think about it, you can learn a bunch of abstractions. You don't have to like spend a bunch of time learning, which this is a really complicated API. That same story had to be true. For the cloud. And so what that meant is like having a version of the product where you'd have to be forced to think about like how many nodes you want or how to size those nodes or how your sharding strategy should be, or your backup strategy or your data tiering strategy, or I could go on, like, it just wasn't, wasn't good enough. It needed to be like zero config, zero knobs to tune. It should just be always fast, always very cost-effective and always fresh without you having to do or think about anything. Right. Regardless of how your traffic goes up and down and how your data scale goes up and down. That was sort of the motivating criteria. It also like usage-based billing was really important because that just is like so fair. We only charge you for the minimal slice of compute that you use and like nothing more, which not all serverless databases can claim, but it is true inside of Chroma that we like truly only charge you for the narrow slice of what you use. And so like that was the criteria that we entered kind of the design criteria process.
Swyx [00:11:19]: Which is, you know, de facto, you're also building a serverless compute platform.
Jeff [00:11:23]: Yeah, you have to. No, exactly. That motivated the design of Chroma Distributed. Chroma Distributed is also a part of the same monorepo that's open source Apache 2 and then the control and data plane are both fully open source Apache 2 and then Chroma Cloud uses Chroma Distributed to run a service and that service you can sign up, create a database and load in data in under 30 seconds and this is sort of a time of filming people get like five bucks of free credits, which is actually enough to load in like 100,000 documents and query it 100,000 times, which obviously takes a lot of time. I think for a lot of use cases actually might mean they use it for free for years, which is fine. And to get there, we had to do kind of all the hard work. Yeah.
Swyx [00:12:03]: I think every blog should basically have semantic indexing. So like, you know, you host your personal blog on Chroma, you know, like we're not.
Jeff [00:12:10]: Yeah, I mean, you know, the mission of organizing the world's information remains unsolved.
Context Engineering and the Problems with RAG
Swyx [00:12:15]: Yeah.
Context Engineering and the Problems with RAG
Alessio [00:12:15]: You have one of your usual cryptic tweets. I need text. You tweeted context engineering a couple months ago. What was it? April. I think everybody.
Jeff [00:12:24]: I think something that's incredibly important when a new market is emerging is abstractions and the primitives that you use to reason about that thing. And AI, I think, in part of its hype, has also had a lot of primitives and abstractions that have gotten thrown around and have led to a lot of developers not actually being able to think critically about what is this thing, how do I put it together, what problems can I solve, what matters, where should I spend my time? For example, the term rag. We never use the term rag. I hate the term rag.
Swyx [00:13:08]: Yeah, I killed the rag track partially because of your influence.
Jeff [00:13:10]: Thank you. Thank you. A is just retrieval, first of all. Like, retrieval, I've been a generation. Are three concepts put together into one thing? Like, that's just really confusing. And, of course, rag got known now as these branded as, like, you know, oh, you're just using single dense vector search, and that's what rag is. It's also dumb. I think one of the reasons I was really excited about the term, I mean, obviously, AI engineering, which you did a ton of work for, like, context engineering is in some ways a subset of AI engineering. Like, what is it? It's a high-status job. Context engineering is the job of figuring out what should be in the context window. Any given LLM generation step. And there's both an inner loop, which is setting up the, you know, what should be in the context window this time. And there's the outer loop, which is how do you get better over time at filling the context window with only the relevant information. And we recently released a technical report about context rot, which goes sort of in detail, in depth about how the performance of LLMs is not invariant to how many tokens you use. As you use more and more tokens, the model can pay attention to less and then also can reason sort of less effectively. I think this really motivates the problem. You know, context rot implies the need for context engineering. And I guess, like, why I'm really excited about the meme and, you know, I got maybe both lucky to some degree that, you know, called it back in April, this is going to be a big meme, is that it elevates the job to, it clearly describes the job and it elevates the status of the job. This is what, frankly, most AI startups, any AI startup that you know of that you think of today that's doing very well, like, what are they fundamentally good at? What is the one thing that they're good at? It is context engineering.
Swyx [00:14:45]: Particularly, I would feel like a lot of pieces I've read, a lot of it focuses on agents versus non-agent stuff. Like, the context engineering is more relevant for agents. Do you make that distinction at all? Or you're just looking at context engineering generally?
Jeff [00:15:00]: No. I mean, there's interesting agent implications of, like, you know, agent learning, you know, can agents kind of learn from their interactions, which maybe are less relevant and like static sort of knowledge-based corpuses, chat your documents, obviously. Then again, like, you know, I think you could make the argument that even, like, chat your document use cases, like, should get better with more interactions. I don't draw a distinction between agent and non-agent. I don't actually know what agent means still, but, again, impermitted subtractions, words, they matter. I don't know. Like, what does agent mean? I don't know. Well, there's many definitions out there. Exactly. I've taken a stab. Most terms that can mean anything are just a vehicle for people's hopes and fears. Yeah. I think, you know, agent is the same thing. For sure.
Swyx [00:15:42]: Well, maybe we'll try to be more. More concise or precise about context engineering so that it doesn't, it actually means something and, you know, people can actually use it to do stuff. One thing I definitely will call out for context engineering or context rot in general is I think that there's been a lot of marketing around needle in a haystack, where every frontier model now comes out with, like, completely green, perfect charts of full utilization across, you know, 1 million tokens. I'm wondering what you guys' takes are on that kind of marketing. Yeah. Yeah.
Context Rot
Jeff [00:16:11]: So maybe back up a little bit. But the way that we came to work on this research was we were looking actually at agent learning. So we were very curious, like, could you give agents access to, like, prior successes or prior failures? And if you did, would that help boost agent performance? So we were specifically looking at a couple different data sets, SweetBench inclusive, and we started seeing interesting patterns where, like, on sort of multi-turn agent interactions where you're giving it the whole conversation window, like, the number of tokens explodes extremely quickly and instructions that were clearly in there, like, were being ignored and were not being announced. And we're like, oh, that clearly is a problem. We've now felt the pain. It was sort of a meme amongst people in the know that, like, this was true. And, like, I think also, you know, some of the research community's reaction to the context rot technical report is like, yeah, we know. And, you know, that's fine. Nobody else knew. And, like, it's kind of nice if, like, you can actually teach builders what is possible today versus what is not possible today. I don't blame the labs. I mean, building models is so insanely competitive. Everybody invariably is, like, picking the benchmarks that they want to do the best on. They're training around those. Those are also the ones that, you know, find their way into their marketing. You know, most people are not motivated to come out and say, here are all the ways that our thing is great, and here are all the ways that our thing is not great. You know, I don't know. I have some sympathy for, you know, why this was not reported on. But, yeah, I mean, there was this bit of, like, this sort of implication where, like, oh, look, our model is perfect on this task, needle in a haystack. Therefore, the context window you can use for whatever you want. There was an implication there. And, well, I hope that that is true someday. That is not the case. Yeah.
Swyx [00:17:43]: We'll send people, at least on the YouTube video, we'll put this chart, which is kind of your figure one of the context route report. It seems like Sonnet 4 is the best in terms of area under curve, is how I think about it. Then Quinn, wow. And then GPC 4.1 and Gemini Flash are degraded a lot quicker in terms of the context length. Yeah.
Jeff [00:18:03]: I don't have much commentary. That is what we found for this particular task. Again, how that translates to people's actual experience in real world, you know, tasks is entirely different. I mean, there is a certain amount of love that developers have for Claude and, like, maybe those two things are correlated. Yeah. I think it shows here if this is true, that's a big explanation for why. You follow my instructions, you know, like, here's a clear baseline, you know, thing people want.
Swyx [00:18:27]: I don't think it's super answered here, but I have a theory also that reasoning models are better at context utilization because they can loop back. Normal autoregressive models, they just kind of go left to right. But reasoning models, in theory, they can loop back and look for things that they need. They need connections for that they may not have paid attention to in the initial pass. There's a paper today that showed, I think, maybe the opposite. Really?
Jeff [00:18:49]: I'll send it to you later. Yeah.
Swyx [00:18:50]: That'd be fascinating to figure out.
Alessio [00:18:52]: There's papers every day. I thought the best thing was that you did not try to sell something. You're just like, hey, this thing is broken. Kind of sucks. How do you think about problems that you want to solve versus research that you do to highlight some of the problems and then hoping that other people will participate? Like, does everything that you talk about? Is it on the Chroma roadmap, basically? Or are you just advising people, hey, this is bad, work around it, but don't ask us to fix it?
Jeff [00:19:20]: Going back to what I said a moment ago, like, Chroma's broad mandate is to make the process of building applications more like engineering and less like alchemy. And so, you know, it's a pretty broad tent, but we're a small team and we can only focus on so many things. We've chosen to focus very much on one thing for now. And so I don't think that I don't have the hubris to think that we can ourselves solve. This stuff conclusively for a very dynamic and large emerging industry, I think it does take a community, it does take like a rising tide of people all working together. We intentionally wanted to, like, make very clear that, like, we do not have any, like, commercial motivations in this research. You know, we do not posit any solutions. We don't tell people to use Chroma. It's just here's the here's the problem.
Swyx [00:20:02]: It's implied.
Jeff [00:20:05]: Listen, we weren't sad that that was maybe and maybe it may be a positive vacation, you know, but it's still there's no reasons around that. But, you know, speed and cost regardless, I think. But there's just a lot of work to do. And I think that, like, it's interesting where, like, the labs don't really care and they're not motivated to care increasingly as the market to be to be a good LLM provider. The main market seems to be consumer. You're just not that motivated to, like, help developers as a secondary concern, as a secondary concern. And so you're not that motivated really to do the legwork to, like, help developers learn how to build stuff. Yeah. And then, like, if you're a SaaS company or you're a consumer company, you're building with AI, you're an AI native company. Like, this is your, like, this is your secret sauce. You're not going to market how to do stuff. And so, like, I mean, it's just like there's a natural empty space, which is people that are actually have the motivations to, like, help show the way for how developers can build with AI. Like, they're just there's not a lot of obvious people who are, like, obviously invest in their time and energy in that. But I think that is obviously a good thing for us to do. And so that's kind of how I thought about it.
Swyx [00:21:02]: Just a pushback on the consumer thing. Like, you say labs and, you know, don't you think, like, opening eye, building memory into ChatGPT and making it available to literally everyone? I mean, it's probably too much in your face, I would argue, but, like, they would really care to make the memory utilization good. I think context utilization, context engineering is important for them, too, even if they're only building for consumer and don't care about developers.
Jeff [00:21:25]: Yeah. How good is it today is obviously one important question, but we'll skip that one. Like, even if that's the case, are they actually going to publish those findings? No, Exactly. It's alpha, right? Why would you give away your secrets? Yeah. And so I think there's just, like, very few companies that actually are, like, in the business. I think there's a position where, like, they have the incentive and they really care about, like, trying to teach developers how to build useful stuff with AI. And so I think that we have that incentive.
Prioritizing Context Quality
Alessio [00:21:49]: But do you think you could get this to grow to the point of being the next needle in a haystack and then forcing the model's providers to actually be good at it?
Jeff [00:21:57]: There's no path to forcing anybody to do anything. And so we thought about that when we were kind of putting this together. Like, oh, maybe we should, like, sort of formulate this as a formal benchmark that you can make it very easy to, like, we did open source, all the code. So, like, you could. You know, if you're watching this and you're from a large model company, you can do this. You can take your new model that you haven't released yet and you can run, you know, these numbers on it. And, you know, I would rather have a model that has a 60,000 context, token context window that is able to perfectly pay attention to and perfectly reason over those 60,000 tokens than a model that's, like, 5 million tokens. Like, just as a developer, the former is, like, so much more valuable to me than the latter. I certainly hope that model providers do, like, pick this up as something that they care about and that they train around and that they, you know, evaluate their progress on and they communicate to developers. As well. That would be great.
Alessio [00:22:42]: Do you think this will get a better lesson as well? How do you decide which of the... Because, you know, you're busy saying, yeah, the models will not learn this. It's going to be a trick on top of it that you won't get access to. I'm not saying that. Well, but when you're saying that they will not publish how to do it, well, it means that the model API will not be able to do it, but they will have something in ChatGPT that will be able to do it. I see. Yeah.
Jeff [00:23:04]: It's very risky to bet what's going to be a better lesson versus what is not. I don't think I'll hazard a guess. Hopefully not AI engineers. Yeah. Hopefully not all of humanity. I don't know. You know, yeah.
Swyx [00:23:14]: To me, also an interesting discipline developing just around context engineering. Lance Martin from Langchain did a really nice blog post of like all the different separations. And then you in New York, you had, you hosted your first meetup. We're going to do one here in San Francisco as well. But I'm just kind of curious, like, what are you seeing in the fields? Like who's doing interesting work? What are the top debates? That kind of stuff.
Jeff [00:23:37]: I think this is still... I mean, a lot of people are doing nothing. A lot of people are just still eating everything into the context window. That is very popular. And you know, they're using context caching and that certainly helps, but like there are costs and speed, but like isn't helping the context problem at all. And so, yeah, I don't, I don't know that there's lots of best practices in place yet. I mean, I'll highlight a few. So the problem fundamentally is quite simple. It's, you know, you have N number of sort of candidate chunks and you have Y spots. Available and you have to do the process to curate and cull down from 10,000 or a hundred thousand or a million candidate chunks, which 20 matter right now for this exact step. That optimization problem is not a new problem to many applications and industries, sort of a classic, um, a classic problem. And of course, like what tools people use to solve that problem. Again, I think it's still very early. Um, it's hard to say, but a few patterns that I've seen. So one pattern is to use what a lot of people call first stage retrieval to do a big cull down. So that's to be using signals like vector search, like full text search, like metadata filtering, metadata search, and others to go from, let's say 10,000 down to 300. Like we were saying a moment ago, like you don't have to give an LLM 10 blue links. You can brute force a lot more. And so using an LLM as a re-ranker and brute forcing from 300 down to 30, I've seen now emerging. A lot, like a lot of people are doing this and it actually is like way more cost effective than I think a lot of people realize I've heard of people that are running models themselves that are getting like a penny per million input tokens and like the output token cost is basically zero because it's like, uh, you know, the simplest. These are dedicated re-ranker models, right? Not no LLMs. No, these are LLMs. Okay. They're just using LLMs as re-rankers. Okay. And of course there are also dedicated re-ranker models that by definition are going to be so like cheaper because they're much smaller and faster. Cause they're much smaller. But like what I've seen emerge is like application developers who already know how to prompt are now applying that tool to re-ranking. And I think that like, this is going to be the dominant paradigm. I actually think that like probably purpose built re-rankers will go away. And the same way that like purpose built, they'll still exist, right? Like if you're at, if you're at extreme scale, extreme cost, yes, you'll care to optimize that. And the same way that if you're running with hardware, right? Like you're just going to use a CPU or GPU. Unless you absolutely have to. You don't have to have an ASIC or an FPGA and I think the same thing is true about like re-rankers where like, as LLMs become a hundred, a thousand times faster, a hundred, a thousand times cheaper that like people are just going to use LLMs for re-rankers and that actually like brute forcing information curation is going to become extremely, extremely popular. Now today, the prospect of running 300 parallel LLM calls, even if it's not very expensive, you know, the tail latency on any one of those like 300 LLM calls. And so like, there are good reasons to not do that today in a production application, but those will also go away over time. So those patterns I think I've seen emerge that are, that, that's a, that is a new thing that I think I've only seen start to really become popular in the last few months. And by popular, I mean like popular in like the leading tip of the spear, but I think will become a very, very dominant paradigm. Yeah.
Code Indexing and Retrieval Strategies
Swyx [00:27:02]: We've also covered a little bit on, especially on the code indexing side of the house. So everything we've been talking about applies to all kinds of contexts. I think code is obviously a special kind of context and corpus that you want to index. We've had a couple of episodes, the cloud code guys and the client guys talk about, they don't embed or they don't index your code base. They just give tools and use the tools to code search. And I've often thought about whether or not like this should be the primary context retrieval paradigm where when you build an agent, you effectively call out to another agent with all these sort of recursive re-rankers and summarizers or another agent with tools. Yep. Or do you sort of glom them on to a single agent? I don't know if you have an opinion, obviously, because agent is very ill-defined, but I'll just put it out there.
Jeff [00:27:47]: Okay. Got to pull that apart. So, you know, indexing by definition is a trade-off. Like when you index data, you're trading write time performance for query time performance, you're making it slower to ingest data, but much faster to query data, which obviously scales as data sets get larger. And so like, if you're only grepping very small, you know, 15 file code bases, you probably don't have to index it. And that's okay. If you want to search all of the open source dependencies of that project, you all have done this before in VS code or cursor, right? You've run a search over like the node modules folder. It takes a really long time to run that search. That's a lot of data. Like, so to make that indexed and sort of, again, make that trade off of write time performance or query time performance. Like that's what, that's what indexing is like, just like demystify it. What is this? Right? Like, that's what it is. You know, embeddings are known for semantic similarity today. Embeddings is just a generic concept of like information compression, and there's actually like many tools you can use embeddings for, I think embeddings for code are still extremely early and underrated, but regex is obviously an incredibly valuable tool and, you know, we've actually worked on now inside of Chroma, both single load and distributed, we support regex search natively. So you can do regex search inside of Chroma because we've seen that as like a very powerful tool for code search. It's great. And we build indexes to make regex search go fast at large. So you can do regex search data volumes on the coding use case that you mentioned. Another use case that another feature we added to Chroma is the ability to do forking. So you can take an existing index and you can create a copy of that index in under a hundred milliseconds for pennies. And in so doing, you then can just apply the diff for what file has changed to the new index. So any like corpus of data that's logically changing. So very fast re-indexing is the result. But now you can like have an index for like different each commit. So if you want to search different commits to search different branches or different release tags, like any corpus of data that's like a logically versioned, you now can search all those versions very easily and very cheaply and cost-effectively. And so, yeah, I think that, you know, that's kind of how I sort of think about like regex and indexing and embeddings. I mean, yeah, the needle continues to move here. I think that anybody who claims to have the answer, you just like shouldn't listen to them.
Jeff [00:30:02]: When you said that code embeddings are underrated, what do you think that is? Most people just take generic embedding models that are trained on the internet. And they try to use them for code. And like, it works okay for some use cases, but does it work great for all use cases? I don't know. Another way to think about these different primitives and what they're useful for, fundamentally, we're trying to find signal. Text search works really well. Lexical search, text search works really well. When the person who's writing the query knows the data. If I want to search my Google Drive, I just, for the spreadsheet that has all my investors, I'm just going to type in cap table. Because I know. Spreadsheet in my Google Drive called cap table. Full text search, great. It's perfect. I'm a subject matter expert in my data. Now, if you wanted to find that file and you didn't know that I had a spreadsheet called cap table, you're going to type in the spreadsheet that has the list of all the investors. And, of course, in embedding space, in semantic space, that's going to match. And so, I think, again, these are just like different tools. And it depends on like who's writing the queries. It depends on what expertise they have in the data. Like what blend of those tools is going to be the right fit? My guess is that. Like for code today, it's something like 90% of queries or 85% of queries can be satisfactorily run with Regex. Regex is obviously like the dominant pattern used by Google Code Search, GitHub Code Search. But you maybe can get like 15% or 10% or 5% improvement by also using embeddings. Very sophisticated teams also use embeddings for code as part of their code retrieval code search stack. And, you know, you shouldn't assume they just enjoy spending money on things unnecessarily. They're getting some, they're eking out some benefit there. And, of course, like for companies that want to be like top of their game and want to like, you know, corner their market and want to serve their users the best. This is kind of what it means to build great software with AI. 80% is quite easy. But getting from 80% to 100% is where all the work is. And like, you know, each point of improvement like is a point on the board. And it's a point that like I think users care about. And it's a point that you can use to, yeah, fundamentally just like serve your users better.
Chunk Rewriting and Query Optimization for Code
Alessio [00:32:04]: Do you have any thoughts on the developer experience versus agent experience? Like this. This is another case where, well, we should maybe reformat and rewrite the code in a way that it's easier to embed and then train models there. Where are you on that spectrum? Yeah.
Jeff [00:32:19]: I mean, one tool that I've seen work well for some use cases is instead of just embedding the code, you first have an LLM generate like a natural language description of like what this code is doing. And either you embed like just the natural language description or you embed that and the code or you embed them separately and you put them in like separate, you know. Vector search indexes, chunk rewriting is kind of like the broad category of like what that is. Again, this is like the idea here is like it's related to indexing, which is as much structured information as you can put into your write or your ingestion pipeline, you should. So all of the metadata you can extract, do it at ingestion. All of the chunk rewriting you can do, do it at ingestion. If you really invest in like trying to extract as much signal and kind of pre-bake a bunch of the signals at the ingestion side. I think it makes the downstream query task like much easier. But also, you know, just because we're here, like it's worth saying like people should be creating small golden data sets of what queries they want to work and what chunks should return. And then like they can quantitatively evaluate what matters. Maybe you don't need to do a lot of fancy stuff for your application. It's entirely possible that, again, just using regex or just using vector search, depending on the use case, that's maybe all you need. I guess, again, anybody who's claiming to know the answer. You should, the first thing you should ask is, let me see your data. And then if they don't have any data, then you have your answer already.
Swyx [00:33:47]: I'll give a plug to a talk that you gave at the conference, how to look at your data. Yes. Looking at your data is important. Having, having golden data sets. These are all like good practices that I feel like somebody should put into like a little pamphlet, call it the 10 commandments of AI engineering or something. Okay. You might do that. Yeah. Thou shall look at your data.
Transformer Architecture Evolution and Retrieval Systems
Swyx [00:34:07]: We're about to move on to memory, but like, I want us to sort of leave it there.
Jeff [00:34:09]: I want us to sort of leave space for like, you know, any other threads that you feel like you always want to get on a soapbox about that, yeah, that's a dangerous, that's a dangerous thing to ask.
Swyx [00:34:18]: I have one to, to key off of, because I think, uh, I didn't, I didn't know, I didn't, I didn't know where to insert this in the conversation, but we're kind of skirting near it that I'm trying to explore, which is, you know, uh, I think you had this rant about R, A, and G where the original transformer was sort of like an encoder decoder architecture. Hmm. Then GBT turns, uh, most transformers. Transformers into decoder only, but then we're also encoding with all the, um, um, embedding models as encoder only models. So in some sense, we sort of decoupled the transformer into first, we encode everything with the encoder only model, put it into a vector database like chroma and chroma also does other stuff, but you know, um, then, then we decode with, uh, the LMS. And I just think it's like a very interesting meta learning about the. The overall architecture, like it is stepping out of just the model to models and system. And I'm curious if you have any reflections on that or if you have any modifications to what I just said.
Jeff [00:35:20]: I think there's some intuition there, which is like the way we do things today is very crude and we'll feel very caveman and five or 10 years, you know, why aren't we just, why are we going back to natural language? Why aren't we just like passing the embeddings like directly to the models who are just going to functionally like re put it into latent space. Right. Yeah. They have a very thin embedding layer. Yeah. Yeah. So I think like, there's a few things that I think might be true about retrieval systems in the future. So like number one, they just stay in latent space. They don't go back to natural language. Number two, instead of doing like, this is actually starting out to change, which is really exciting, but like for the longest time we've done one retrieval per generation. Okay. Do you retrieve, and then you stream out and number of tokens, like, why are we not continually retrieving as we need to, um, don't call it, um, but there was a paper or a paper in a, in a, you know, maybe like a. Like a GitHub that came out a few weeks ago, I think it was called, unfortunately rag R one where they like teach, uh, DCR one, you know, kind of give it the tool of how to retrieve. And so like kind of in its internal chain of thought and it's in for tense compute, it's actually like searching.
Swyx [00:36:22]: There's also retrieval, augmented language models.
Jeff [00:36:24]: I think this is an older paper. Yeah. Yeah. There's a bunch of realm and retro and it's kind of long history here. Um, so I think that, you know,
Swyx [00:36:31]: Somehow not that popular.
Jeff [00:36:32]: I don't know why. Somehow not that popular. Well, there are a lot of those have the problem where like either the retriever or the language model has to be. Frozen. And then like the corpus can't change, which most developers don't want to like deal with the developer experience around.
Swyx [00:36:45]: I would say like, we would do it if, if the gains were that high or the labs don't want you to do it. I don't know about. Yeah.
Jeff [00:36:54]: Cause the labs have a huge amount of influence. Lots of huge amount of influence. I think it's also just like, you don't get, you don't get points on the board by doing that. Well, you just like, don't, no one cares. The status games don't, don't reward you for solving their problem. So yeah. So broadly. Continual retrieval, I think will be interesting to see come out of the scene. Number one, number two, staying in embedding space will be very interesting. And then, yeah, there's some interesting stuff also about kind of like GPUs and how you're kind of like paging information into memory on GPUs that I think can be done like much more efficiently. Um, and this is more like five or 10 years in the future that we're kind of thinking about, but yeah, I think, I think when we look back in things, this was like, like hilariously crude, the way we do things today.
Swyx [00:37:34]: Maybe, maybe not, you know, we're solving IMO, uh, challenges with. Just language, you know? Yeah, it's great. I'm still working on the implications of that. Like it's, it's still a huge achievement, but also very different than how I thought we would do things.
Alessio [00:37:47]: You said that memory is the benefit of context engineering. I think there's a, you, you had a random Twitter about stop making memory for ISO complicated. How do you think about memory? And it's what are like maybe the other benefits of context engineering that maybe we were not connecting together?
Memory as a Benefit of Context Engineering
Jeff [00:38:06]: I think memory is a good term. It is very legible to a wide population. Again, this is sort of just continuing the anthropomorphization of LMS. You know, we ourselves understand how we are, we, as humans use memory. We're very good at, well, some of us are very good at using memory to learn how to do tasks. And then those learnings being like flexible to new environments and, you know, the idea of being able to like take an AI, sit down next to an AI and then instruct it for 10 minutes or a few hours. And kind of. Just like tell it what you want it to do. And it does something and you say, Hey, actually do this next time. The same that you would with a human at the end of that 10 minutes at the end of those few hours, the AI is able to do it now and the same level of reliability that a human could do it like is an incredibly attractive and exciting vision. I think that that will happen. And I think that memory again is like the memory is the term that like everybody can understand, like we all understand our moms all understand and, and, and the benefits of memory are also very appealing. And very attractive, but what is memory under the hood? It's still just context engineering, I think, which is the domain of how do you put the right information into the context window? And so, yeah, I think of memory as the benefit context engineering is the tool that gives you that benefit. And there may be stuff as well. I mean, maybe there's some version of memory where it's like, oh, you're actually like using RL to improve the model through data scene. And so I'm not suggesting that like only changing the context is the only tool which, you know, gives you. Great performance on tasks, but I think it's a very important part.
Alessio [00:39:43]: Do you see a big difference between synthesizing the memory, which is like, based on this conversation, what is the implicit preference? Yeah, that's one side. And then there's the other side, which is based on this prompt, what are the memories that I should put in?
Jeff [00:39:58]: I think they will be all fed by the same data. So the same feedback signals that tell you how to retrieve better will also tell you what to remember better. So I don't think they're actually different problems. I think they're the same problem.
Structuring AI Memory and Offline Compaction
Swyx [00:40:13]: To me, the thing I'm wrestling with a little more is just what are the structures of memory? That makes sense. So there's like obviously all these analogies with like long term memory, short term memory, let us try to coin something around sleep. I do think that there definitely should be some sort of batch collection cycle, maybe sort of garbage collection cycle where it's like where the LLM is sleeping. But I don't know what. I don't what makes sense, like we're making all these analogies based on what we think, how we think humans work, but maybe AI doesn't work the same way. Yeah. I'm curious about anything that you've seen that's working.
Jeff [00:40:48]: Yeah, I always, again, you know, as a through line of this conversation, I always get a little bit nervous when we start creating new concepts and new acronyms for things. And then all of a sudden there's, you know, info charts that are like, here are the 10 types of memory. And you're like, why? These are actually, if you squint, they're all the same thing. Like, do they have to be different? You know, like. You have to blow the people's minds. No, I don't think you do. I don't know. You got to resist the slot machine, the slot and the slot machine.
Jeff [00:41:16]: Compaction has always been a useful concept in. Even in databases. In databases on your computer. We all remember running Defrag on our Windows machines in 1998. And, you know, so, yeah, again. Some of us not old enough to do that. I am. Not at this table. And yeah. So obviously, obviously. Offline processing is helpful, and I think that is also helpful in this case. And as you're talking about before, like, what is the goal of indexing? The goal of indexing is to, like, trade write time performance for query time performance. Compaction is another tool in the toolbox of, like, sort of write time performance. You're re-indexing data.
Swyx [00:41:52]: It's not indexing, but actually it is indexing.
Jeff [00:41:55]: It's sort of re-indexing. Yeah. You're taking data. You're like, oh, maybe those two data points should be merged. Maybe they should be split. Maybe they should be, like, rewritten. Maybe there's new metadata we can extract from those. Like, let's look at the signal of how our application is performing. Let's try to figure out, like, are we remembering the right things or not? Like, the idea that there is going to be, like, a lot of offline compute and inference under the hood that helps make AI systems continuously self-improve is a sure bet.
Alessio [00:42:19]: Part of the sleep time compute thing that we talked about was pre-computing answers. So based on the data that you have, what are likely questions that the person is going to ask? And then can you pre-compute those things? How do you think about that in terms of Chroma? We released a technical report. Yeah.
Jeff [00:42:35]: We released a technical report maybe three months ago. The title is Generative Benchmarking. And the idea there is, like, well, having a golden data set is really powerful. What a golden data set is is you have a list of queries and you have a list of chunks of those queries should result in. And now you can say, okay, this retrieval strategy gives me, for these queries, gives me 80% of those chunks. Whereas if I change the embedding model, now I get 90% of those chunks. That is better. And then you also need to consider cost and speed and API reliability. And other factors, obviously, when making good engineering decisions. But, like, you can measure now, like, changes to your system. And so what we noticed was, like, developers had the data. They had the chunks. They had the answers. But they didn't have the queries. We did a whole technical report around how do you teach an LLM to write good queries from chunks? Because, again, you want, like, chunk query pairs. And so if you have the chunks, you need the queries. Okay. We can have a human do some manual annotation, obviously. But humans are not. They're inconsistent and lazy. And, you know, QA is hard. And so can we teach an LLM how to do that? And so we sort of did a whole technical report and proved a strategy for doing that well. So I think generating QA pairs is really important for benchmarking your retrieval system, golden data set. Frankly, it's also the same data set that you would use to fine-tune in many cases. And so, yeah, there's definitely something, like, very underrated there. Yeah.
Swyx [00:43:58]: I'll throw a plus one on that. I think as much attention as the context rock paper is getting, I feel like generative benchmarking was a bigger aha moment. For me, just because I actually never came across a concept before. And I think, like, actually more people will apply it to their own personal situations. Whereas context rock is just generally, like, yeah, don't trust the models that much. But there's not much you can do about it except do better context engineering. Yeah. Yes. Yes. Whereas generative benchmarking, you're like, yeah, generate your evals. And, you know, part of that is you're going to need the data sets. And it'll sort of fall you into the place of all the best practices that everyone advocates for.
Jeff [00:44:34]: So it's really a nice piece of work. I think having worked in applied machine learning developer tools now for 10 years, like, the returns to a very high-quality small label data set are so high. Everybody thinks you have to have, like, a million examples or whatever. No. Actually, just, like, a couple hundred even, like, high-quality examples is extremely beneficial. And customers all the time, I say, hey, what you should do is say to your team Thursday night, we're all going to be in the conference room. We're ordering pizza. And we're just going to have a data labeling party for a few hours. That's all it takes to bootstrap this.
Swyx [00:45:08]: Google does this. OpenAI does this. Anthopic does this. You are not above doing this. Great. Yeah. Exactly. Yeah. Yeah. Look at your data. Again, it's what matters. Maybe you should classify that as label your data, not look at. Because look at seems a bit too… I agree with that. Yeah. There's some more… View only. Right. I agree with that. Yeah. Read and write. Read and write. While you mentioned it, I should correct myself. It wasn't standard cognition. It was standard cyborg. My favorite fact about you is you're also a cyborg with your leg. True. People… If you see Jeff in person, you should ask him about it. Or maybe not. Maybe don't. I don't know. I don't care. Don't care. Standard cyborg, mighty hive, and know it. What were those lessons there that you're applying to Chroma? Yeah.
Lessons from Previous Startups and Building with Purpose
Jeff [00:45:46]: More than I can count. I mean, it's a bit of a cliche. It's very hard to be self-reflective and honest with yourself about a lot of this stuff. But I think viewing your life as being very short. And kind of a vapor in the wind. And therefore only doing the work that you absolutely love doing. And only doing that work with people that you love spending time with. And serving customers that you love serving. Is a very useful North Star. And it may not be the North Star to print a ton of money in some sense. There may be faster ways to scam people into making $5 million or whatever. So. But if I reflect on. And I'm happy to go into more detail obviously. But if I reflect on my prior experiences. I was always making trade-offs. I was making trade-offs with the people that I was working with. Or I was making trade-offs with the customer that I was serving. Or I was making trade-offs with the technology and how proud I was of it. And maybe it's sort of like an age thing. I don't know. But the older that I get, I just more and more want to do the best work that I can. And I want that work to not just be great work. But I also want it to be seen by the most number of people. Because ultimately that is what impact looks like. Impact is not inventing something great. And then nobody using it. Like impact isn't inventing something great. As many people using it as possible.
Swyx [00:47:01]: Is any of that, you know, and we can skip this question if it's sensitive. But like, is any of that guided by religion, by Christianity? And I only ask this because I think you're one of a growing number of openly, outwardly, positively religious people in the Valley. And I think that it's kind of what I want to explore. You know, I'm not, I'm not like that religious myself, but I just kind of like, how does that inform how you view your impact? Your, you know, your choices that there was a little bit of, of that in what you just said, but I wanted to sort of tease that out more.
Religion and values in Silicon Valley
Jeff [00:47:32]: I think increasingly modern society is nihilist. Nothing matters. It's a absurdist, right? Everything is a farce. Everything is power. Everything's a comedy. Everything's a comedy. A meme. Yeah. Yeah, exactly. And so like, it's very rare. And I'm not saying that I always end the life. Living exemplar of this, but like, it's very rare to meet people that have genuine conviction about what flourishing for humanity looks like. And that's very rare to meet people that are like actually willing to sacrifice a lot to like make that happen and to start things that like they may not actually see complete in their lifetimes. Like it used to be commonplace that people would start projects that would take centuries to complete. Yeah. And you know, now that's like less and less the case.
Swyx [00:48:23]: The image that comes to mind is the Sagrada Familia in Barcelona, which I think was started like 300 years ago and it's completing next year. Yeah.
Jeff [00:48:33]: I've seen it in construction, but I can't wait to see it complete as well. Yeah. I'm sure the places are booked out already. Yeah. Yeah. And so, you know, it's, it's common. There are actually, you know, a lot of like religions in Silicon Valley. I think AGI is also a religion. It has a problem of evil. We don't have enough intelligence. It has a solution, a deus ex machina. It has the second coming of Christ that AGI, the singularity is going to come. It's going to save humanity because we will now have infinite and free intelligence. Therefore, all of our problems will be solved. And, you know, we will live in sort of like the palm of grace for all eternity. It's going to solve death. Right. And so like, I think that like religion still exists in Silicon Valley. I think that it's like, you know, there's a conservation of religion and you kind of can't get rid of it. Yeah. But. The God gene. Yeah. I mean, you know, you have different terms for this. But like, I think that. I'm always skeptical of religions that haven't been around for more than five years. Put it that way. Yeah.
Swyx [00:49:27]: There's a survivorship bias. Anyway, I do think like you're one of the more prominent ones that I know of. And I think you guys are a force for good. And I like to encourage more of that. I don't know. You know, people should believe in something bigger than themselves and build for plant trees under which they will not sit. Am I mangling the quote? Is that actually a biblical quote? I don't think it's a biblical quote. But I like that quote. That's a good one.
Jeff [00:49:52]: So, yeah.
Swyx [00:49:52]: Plus one. Like, I think society is really collapsed when, like, you just live for yourself. That really is true. Agreed.
Alessio [00:49:59]: Who does your design? Because all of your swag is great. Your office looks great. The website looks great. The docs look great. How much of that is your input? How much of that do you have somebody who just gets it? And how important is that to, like, making the brand part of the culture?
Company culture, design, and brand consistency
Jeff [00:50:18]: I think all value, you know, again, going back to the question of, you know, the culture, like, the Conway's Law thing, like, you ship your org chart, you ship what you care about as a founder in some sense. And, like, I do care deeply about this aspect of what we do. And so I think it does come from me in some sense. I can't take at all credit for everything we've done. We've had the opportunity to work with some, like, really talented designers. And we're hiring, as well, for that. So if people, you know, are listening to this and want to apply, please do. I think, I mean, it's cliche to crib Patrick Collison quotes, but he does seem to be, you know, one of the, like, most sort of public embodiers of this idea that, like, how you do, and I'm not sure this is a dark quote from him, to be clear, this is more of just a broad aphorism, but, like, how you do one thing is how you do everything. And just ensuring that there's a consistent experience of what we're doing, where, like you said, if you come to our office, like, it feels intentional and thoughtful. If you go to our website, it feels intentional and thoughtful. The user API, it feels intentional and thoughtful. If you go through an interview process, it feels intentional and purposeful. I think that's so easy to lose. It's just so easy to, like, lose that. And in some ways, the only way that you keep that is by insisting on that that standard remain. And I think that that is, like, one of the main things that, like, I can do really for the company, like, as a leader. It's sort of cringe to say, but, like, you do kind of have to be, like, the curator of taste. It's not that I have to stamp everything that goes out the door before it does, but at a minimum, I can do it. I can do it. And so, like, you know, sometimes, companies, you know, maybe it's not even, like, downhill in quality. It's not sort of legible that any one thing is bad or worse, but it's more like people just have their own expressions of what good looks like. And like, you know, they turn that up to 11 and then, like, the brand becomes incoherent. Like, what does this thing mean? And like, what do they stand for? Again, it's not, there's no longer a single voice. Yeah, I don't, again, I'm not claiming that I'm good, perfect at this or good at this. But we certainly do. We wake up every day and we try.
Swyx [00:52:19]: You have a lot of, it's very powerful that the skill you have to convey like straightforward principles and values and thoughtfulness, I think in everything that you do. Like, yeah, I, you know, I, you know, I've, I've been impressed with your work for a while.
Hiring at Chroma: Designers, Researchers, and Engineers
Alessio [00:52:36]: Anything we're missing? You're hiring designers. Any other roles that you have open that you want people to, to apply for?
Jeff [00:52:42]: If you're a great product designer that wants to work on developer tools, I think we have one of the most kind of unique opportunities at Crema. If you are interested in extending the kind of research that we do, that's also an interesting opportunity. We're always also hiring like very talented engineers that want to work with other people that are very passionate about kind of low level distributed systems and in some ways solving all the hard problems so that application developers don't have to.
Swyx [00:53:07]: When you say that, can you double click on low level distributed systems? People always say this and then like, okay, Rust, like, like, you know, like Linux kernel. What are we talking here?
Jeff [00:53:18]: Yeah. I mean, like, Maybe like, you know, a useful encapsulation of this is like, if you care deeply about things like Rust or deterministic simulation testing or
Swyx [00:53:32]: Raft, Paxos,
Jeff [00:53:33]: TLA Plus, ConsenSys. TLA Plus, really? Wow.
Swyx [00:53:37]: You know, if you just keep them saying these are, these are like proxies for, you would like, you would like the work that we do here. I just really want to tease out the hiring message, but also I, part of my goal is also to try to identify who are, what, what is the type of, what is the type of AI engineer that people, that startups are really trying to hire and they cannot get, because the better we can identify this thing, I can, you know, maybe create like some kind of branding around it, create an event and like, get these, like, there's a, there's a supply side and a demand side and they can't find each other. Yeah. And that's why I put AI engineer together was that, that was, that was part of it. Yeah. But then this distributed systems person, which like I have heard from you and like a hundred other startups, what is the skillset? What are they called? What do they do? And part of that is like, it's part of that is cloud. Cloud engineering, because a lot of times you're just dealing with AWS, a lot of that, a lot of times you're just dealing with, I don't know, debugging network calls and, and, uh, consistency things, if you're doing replication or whatever, um, where do they go? What do they do? Yeah. Yeah. Like, but they don't use TLA plus at work, you know?
Jeff [00:54:36]: Probably not. Yeah. I mean, last year I started like the SF systems group. Yes. The reading group. Um, yeah, there's like presentations and the point of that was like, let's bring, let's create a meeting place. Okay. Care about this topic because like, there wasn't really a place in the Bay area for people to do that. Yeah. Um, so that continues to go now and continues to run, which is great. I mean, to be clear, we have a lot of people on the team who are extremely good at this. And so like, it's not that we have zero, it's that we have six or seven, um, and you went 20, but yeah, it's not that we want more, but we are in some ways, like, I feel like our product roadmap is very obvious and we know exactly what we need to build for the next, even like 18 months. But quality is always a limiting function, quality and focus are always limiting functions and like, well, yes, I will always make my land acknowledgement to mythical man month eventually, like it's good. More people you do, you kind of do need more people because you need more focus. Like you need more people to care deeply about the work that they do. And the AI is certainly an accelerant and it's helpful.
Swyx [00:55:39]: And it's the reason that our team is still very small today relative to many of our competitors is because like, I think we've really embraced like those tools, your cursor shop. Yeah. Yeah.
Jeff [00:55:48]: Code windsurf people use whatever they want. Okay. Yeah. So I think all of those tools get some usage internally so far. Uh, we've still not found that really any AI coding tools are particularly good at rust though. Um, I think I'm not sure why that is other than the obvious. There's just like that, that many examples of great rust on the internet. And so, um, you know, yeah.
Swyx [00:56:08]: Yeah. You, you would think that, you know, rust, uh, errors would be help you debug it itself. Right. You would think. Apparently. Apparently not. Okay. All right. I have zero experience in that, in that front. Yeah. Uh, I have, I've contributed three things to the rest SDK of temporal and that was my total experience with rust. But, uh, I, I think it's definitely on the rise. It's, it's zig, it's rust. And I don't know if there's a third cool languages. I think ghost accounts. Go, go Lang. Yeah. Ghost accounts. If you're in, in those, in that, in that bucket, uh, reach out to Jeff, but, uh, otherwise I think we're good. Thanks for coming on. Thanks for having me guys. Good to see you.
Jeff [00:56:46]: Thank you.
Jeffs definition of the SV religion is spot on. Herritics are those that don't align.
KH with the wins