

ChatGPT Codex: The Missing Manual
ChatGPT Codex is here - the first cloud hosted Autonomous Software Engineer (A-SWE) from OpenAI. Josh Ma and Alexander Embiricos tell us how to WHAM every codebase like a power user.
The World’s Fair is 2 weeks away, and early bird tix have sold out! We’re happy to share that Fouad Matin of the OpenAI Codex team, Michael Truell of Cursor, Kevin Hou of Windsurf, Boris Cherny of Claude Code, Scott Wu of Cognition, Josh Albrecht of Imbue, Itamar Friedman of Qodo/AlphaCodium and Eric Simons of Bolt, and many more SWE Agent luminaries will be sharing updates and launches.
Join the top AI Engineer gathering of the year!
Since the first leaks about OpenAI’s coding agents in January, the speculation has been rampant, but with the Codex CLI release last month and today’s ChatGPT Codex research preview, the A-SWE (automated software engineering) agent roadmap is slowly coming into focus, with more agentic coding tools on the way.
Best Practices for using ChatGPT Codex
On the livestream, Greg Brockman mentioned a number of pro user habits for using ChatGPT Codex: write modular code, and use linters, formatters, and commit hooks extensively to give the machine a faster feedback loop.
In this chat with the Codex team though, we found a good deal MORE suggestions for best practices to upgrade your vibe coding to one-shot WHAM coding:
Have an Abundance mindset: Codex has unlimited usage during the research preview, so you should use a ton of it, for every little idea.
We confirmed that you can run up to 60 concurrent Codex instances per hour, meaning you can fire up a Codex task every minute
Groom your Agents.md: the new hierarchical Agents.md is designed to capture all your instructions to the model and grow as model intelligence grows. You can even ask Codex to write its own Agents.md…
Make your codebase discoverable: a well named and organized codebase helps Codex navigate the filesystem as well as a brand new engineer might.
Ask it what it should do: You don’t have to prompt anything if you are out of ideas - having Codex create tasks for itself is an underrated skill
Use it in mobile ChatGPT: as demoed, the mobile site (not yet the app) unlocks a different form of fire-and-forget usage than when you use it on the desktop
Use in-distribution languages with types: Python > Ruby, TS > JS
There’s lots more little tips in the podcast and yet to be discovered!
Full Podcast
We were honored to have the chance to test the new product, but our impressions changed a great deal once we talked to the Codex team for this podcast and found out how power users use Codex:
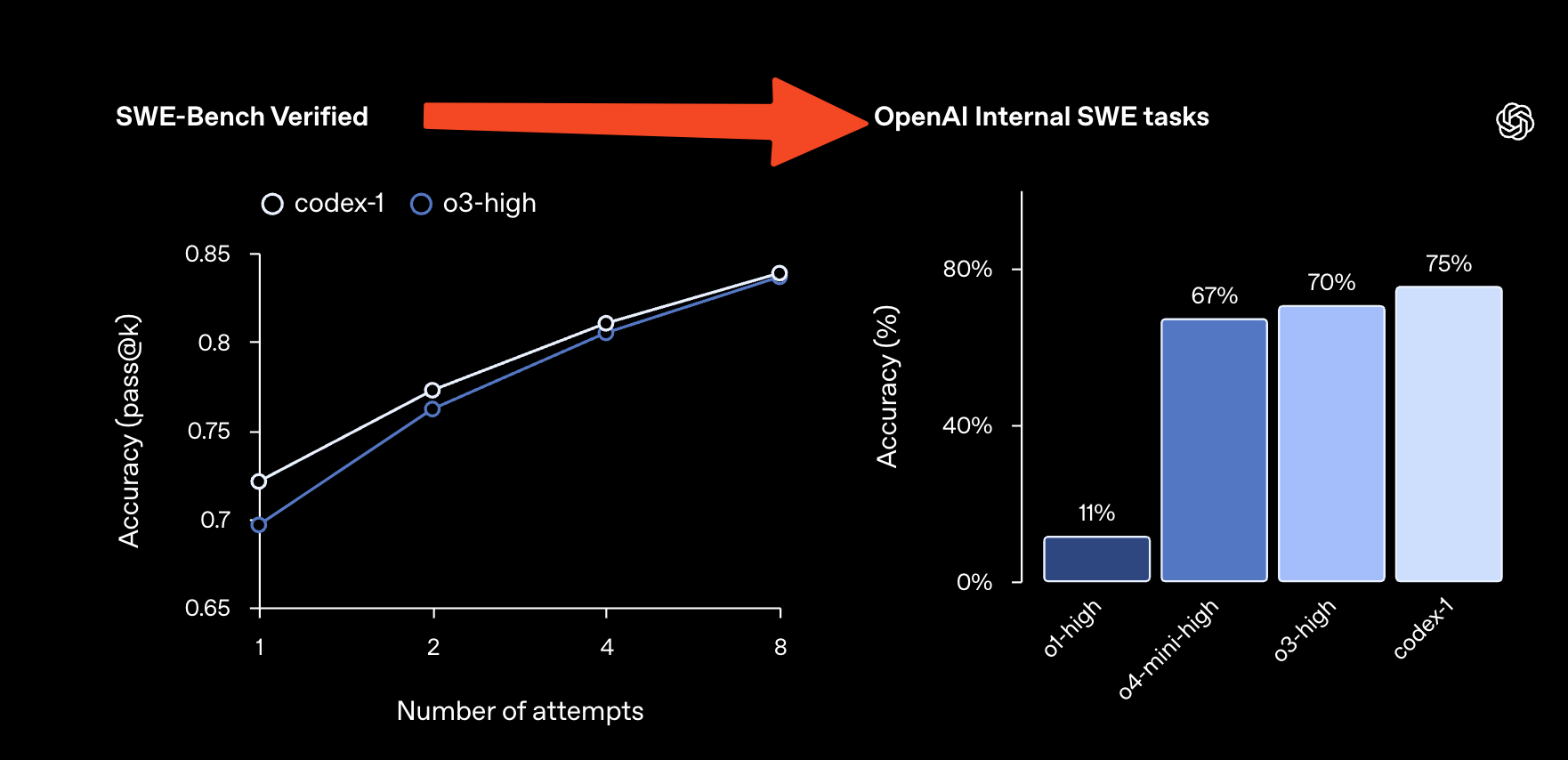
We’ve already talked about the four types of SWE Agents, and on its surface ChatGPT Codex looks very similar to Devin (Scott Wu’s critique here), but the end to end RL in the new `codex-1` finetune of o3 leads to remarkably improved benchmarks:
Timestamps
00:00 Introduction to the Latent Space Podcast
00:59 The Launch of ChatGPT Codex
03:08 Personal Journeys into AI Development
05:50 The Evolution of Codex and AI Agents
08:55 Understanding the Form Factor of Codex
11:48 Building a Software Engineering Agent
14:53 Best Practices for Using AI Agents
17:55 The Importance of Code Structure for AI
21:10 Navigating Human and AI Collaboration
23:58 Future of AI in Software Development
28:18 Planning and Decision-Making in AI Development
31:37 User, Developer, and Model Dynamics
35:28 Building for the Future: Long-Term Vision
39:31 Best Practices for Using AI Tools
42:32 Understanding the Compute Platform
48:01 Iterative Deployment and Future Improvements
Transcript
Alessio [00:00:06]: Hey everyone, welcome to the Latent Space podcast. This is Alessio, partner and CTO at Decibel, and I'm joined by my co-host Swyx, founder of Small AI.
swyx [00:00:15]: Hello, hello, calling in from Singapore here, but we are in the remote studio because the opening IT team keeps shipping, and today they just live streamed and released ChatGPT Codex. Welcome to Josh, who I think we've talked about, we've met while you were at Airplane, right?
Josh [00:00:34]: Yeah, yeah, you know, I've been building DevTools for a bit now, and I have to talk to you when I'm building DevTools.
swyx [00:00:42]: I mean, you know, you have now seen me complain a lot when things happen, so I don't know if it's a good or bad thing.
Alexander [00:00:51]: It's a gift, man. Feedback is a gift. Thank you.
swyx [00:00:55]: Alexander, we're new to each other, but you've been leading a lot of the Codex testing and demos and stuff.
Alexander [00:01:01]: Yeah, hey, I'm Alexander, I'm on the product team here.
swyx [00:01:04]: Awesome. So, yeah, we're going to just assume that everyone's watched the live stream. You also released a blog post with a bunch of, like, test demo videos, basically a bunch of, like, it's very interesting. I noticed in the demo videos, it was, like, individual engineers sitting by themselves, very lonely, and then they're just talking to their AI friends, coding with them. I don't know if that's the vibe you want to give off, but, like, that's how I came across.
Alexander [00:01:30]: Yeah, man, those videos, we were going for. Like, maximum authentic, just, like, engineers talking about how it helps them.
swyx [00:01:38]: Yeah, I'll take the feedback. But, no, I mean, it's true. I mean, sometimes, you know, on-call is a lonely job. Like, mobile engineer is a lonely job. Like, there's not that many of those. So, yeah, totally. But, anyway, so what did you guys individually do? Maybe we can kind of start there. How did you get pulled into the project? And we'll start from there.
Alexander [00:01:59]: Yeah, maybe I can go first, because then we have to have a fun story about how we started working together.
Alexander [00:02:05]: Okay, so, actually, before working at OpenAI, I was working on a native Mac OS software called Multi, which is, like, about, like, it was kind of like a pair programming tool, but we thought of ourselves as working on, like, human-to-human collaboration. And then, basically, as Chachapy and stuff came around, we started thinking about, like, oh, what if instead of a human pair programming with a human, it was, like, a human pair programming with an AI? So, I'll skip this whole journey, but that was this whole journey, and then we all ended up joining OpenAI. And I was working. We were mostly working on desktop software, and then we shipped reasoning models. And, you know, I'm sure you guys were, like, ahead of the curve in terms of understanding the value of reasoning models, but for me, like, it's kind of, like, starts off as better chat, but then when you can give it tools, you can actually, like, make it an agent, right? Like, an agent is, like, a reasoning model with, like, tools and environment, guardrails, and then maybe, like, training on, like, specific tasks. So, anyways, we got super interested in that, and we were just, like, starting to think about, like, okay, how do we bring reasoning models? Into desktop. And at the same time, here at OpenAI, there was a lot of experiments going on with, like, giving these reasoning models access to terminals. I wasn't working on those first experiments, to be clear, but those were, like, that was, like, the first true, like, wow, I really feel the AGI moment that I had. It was actually while I was talking to David Kaye, a designer who was working on this thing called Scientist, and he showed me this demo of it updating itself. And, like, nowadays, like, I don't know if any one of us, like, I don't know if any one of us, like, I don't know if any one of us would be, like, the most impressed to, like, change the background color.
swyx [00:03:37]: Modifying its own code?
Alexander [00:03:38]: Yeah. And then, you know, it was, like, they had hot reloading set up. So, I was just, like, mind blown at the time. And I don't know, it's still a super cool demo. And so, we kind of were experimenting with a bunch of these, and I sort of joined one of the teams that was, like, tinkering with this. And, you know, we kind of realized, like, hey, it's just, like, super valuable to figure out how to give a reasoning model access to the terminal.
Alexander [00:04:06]: And then, now, we have to figure out, like, how to make that, like, a useful product and how to make it safe, right? Like, you can't just let it go loose on your local file system, but that's, like, where people were initially trying to use it. So, a lot of those learnings ended up becoming the Codex CLI, which shipped recently. You know, a lot of the work there, like, you know, the thinking that I'm, like, most proud of is, like, enabling things, like, full auto mode. And, like, when you do that, we actually, like, increase the amount of sandboxing, so that's still safe for you. And then, so, you know, we were working on... You know, these types of things, and then we started realizing we want to let the model think for longer. We want to have a bigger model. We want to let the model, like, do more things safely, like, without having to do any approvals. And so, we thought, you know, maybe we should give the model its own computer, the agent its own computer. And then, at the same time, we were also experimenting with, like, putting the CLI in, like, our CI, so it could automatically fix tests. We did this, like, crazy hack to, like, get it to automatically fix, like, linear tests. We did this, like, really good center issue tracker. And so, then we ended up, sort of, like, creating this project that is Codex, which is basically, like, really the concept of giving the agent access to a computer. Actually, I realized that. I don't know if you were asking. Well, I personally did. But, anyways, I told the story. I hope that's okay. Sure.
swyx [00:05:21]: No, it's... I mean, you weave your personal story into the larger narrative anyway. But, yeah. And I'm sure Josh has a part, too.
Josh [00:05:28]: Yeah. Yeah. So, my story is somewhat different. I've had OpenAI for two months here. And, you know, I've been using it for a long time. And it's been one of the most fun, chaotic two months of my life. But maybe I'll start back at the company I had founded a few years back called Airplane. We were building an internal tool platform. The idea is to let you build internal tools, but really lean into developers and make that really easy. And it sounds unrelated, but in many ways, like, the similar themes started coming up. What's the right form factor for doing local development? How do you deploy tooling to the cloud? How do you run code in the cloud? How do you compose all these primitives of storage and compute and UI to let developers build software really quickly? I like to joke that we were just, I don't know, two years too early. Towards the end, we were playing around with, like, GPT 3.5 and, you know, trying to really make... It was really cool. It could actually build, like, a React view really quickly, right? And I think, you know, if we had kept going on it, maybe it would have turned into some of the AI builders that you see today. But that company ended up getting acquired by Airtable, where it ran some of the AI engineering teams there. And for me personally, towards the beginning of this year, I saw the progress we were making in software, agentic software development. And for me, it was a bit of, like, my own moon landing kind of moment that I suspected was about to happen, right? Whether or not I was involved in the next two years, I think we are going to build an agentic software engineer. And so I talked to my friend over there, and I was like, hey, are you guys working on something like this? And, you know, he gives me a wide-eyed look, he's like, I'm not allowed to tell you anything, but maybe you could talk to the team. And so, very fortunately, this was right when, you know, Alex and the folks were spinning off things. And I remember actually, you know, in our interview, we riffed on the form factor, right? Should it be CLI? The issues with that, waiting for it to finish and not being able to interrupt all the time. Wanting to run it four times, ten times in parallel. Right? And, you know, at that point, I said, maybe it should be both. And we sort of are, you know, going for that right now. But, yeah, I don't know, I'll just say, like, I was very excited and still very excited to just be pushing this forward. And I think Codex is still really early, excited to share it with the world, but there's a lot more to build. Yeah.
Alexander [00:07:52]: I'll say it was a very fun conversation when we first met, because he came in, I've never had this happen before. It was like, here's exactly, like, kind of the change that I see in the world. And therefore, the type of product that I want to build. I know you can't confirm if you're working on it, but just so you know, this is the only thing I want to work on. And then I was like, I asked just a few open-ended questions, and we immediately got into, like, some of the core debates around the form factor of the tool.
swyx [00:08:16]: And I was like, okay, this is awesome to work on. I think a DevTools person can spot another DevTools person like that.
Alessio [00:08:23]: Yeah. Blink twice if you're working on this.
swyx [00:08:26]: But for what it's worth, early iPhone team at Apple was the same, because iPhone team members did not know if they were on the same team, they're not allowed to tell each other. So they had to, like, triangulate. Wow.
Alessio [00:08:41]: And talking about form factor, so you mentioned the CLI, which you already released, and I think there's other, you know, Cloud Code, AIDR, a bunch of other tools out there. Should people think of Codex and ChargeGPD as like a hosted Codex CLI? Like, are there big differences between the two? Let's talk about that.
Josh [00:09:00]: Yeah.
Alessio [00:09:00]: Go for it.
Josh [00:09:01]: Yeah. I think of it as, I think that's a short of it, right? Allowing you to run Codex agents in OpenAI's cloud. But I think that the form factor, like, it's a lot more than just where the computer runs, right? It's how does this bind to the UI? How does this scale out over time? How do you manage caching and permissioning? And how do you do the collaboration story? And so let me know if you disagree. But I think the... Yeah. I think that really is like form factor is the core of it.
Alexander [00:09:35]: Yeah. It's like, it was pretty, it's been honestly a really fun journey. Like the other day, or maybe last night, like in the AM, Josh was sleeping because he had to do the live stream. I didn't have to. But anyway, a bunch of us were like looking back at the dock where we planned what we were going to ship. And we were like, man, we had a lot of scope creep.
Alexander [00:09:57]: And effectively, all that scope creep was kind of like incrementally made sense because we kept leaning further and further into it. And so I think the most important thing for us was like, you know, not just like a model that's good at coding, but rather this is an agent that is good at like independent software engineering work. And like, the more we lend into that, the more like things started to feel really special. So, you know, we could, I'm going to just label and then set aside like the entire conversation around like the compute platform that Josh has like, you know, been leading. But let's just take the model, for example. You know, we don't just want it to be good at code. And we don't just want it to solve, say, Swybench tasks. Swybench is an eval, for those who don't know, that has a certain way of functionally grading outputs. Because if you look at a lot of Swybench passing outputs from an agent, they're not really PRs that you would merge because the code style might be different. It works, but the code style is different. So we spent a lot of time making sure that our model is graded adhering to instructions, graded inferring code style so that you don't have to tell it. But let's say that you got then a PR, that it was like the code style was good, it followed your instructions well. It still might be really hard to merge if you have this enormous description, just like model of how it thought about building it. And you probably need to pull it onto your computer to test the change and validate that it works. And maybe that's okay if you're just running one change. But in a future world that we imagine where actually maybe the majority of code is actually being written by agents that we're delegating to, doing tasks in parallel. It becomes critically important that you can actually integrate those changes easily as the human developer. So, for instance, some of the other stuff we started to train was PR descriptions, like, let's really nail this idea of a good, concise PR description that highlights the relevant things. So our model will actually write a nice, short PR description with a PR title that adheres to your repo format. We have a way to prompt that more if you want with agents.md. And then in the PR description, it'll actually cite relevant code that it found along the way. Or write a code that it found along the way. Or write a relevant code in its PR so that you can, like, mouse over and just see it. And perhaps my favorite thing is actually the way we handle testing. So the model will attempt to test its change, and then it will tell you in this, like, really nice way with just, like, a checkbox kind of thing whether or not those tests passed. And again, it will cite if the test passed, like, a deterministic reference to the log. So you can, like, read it and be like, okay, I know that this test passed, right? Or if the test failed, it'll be like, hey, this didn't work. I feel like you need to install it. You need to install, like, PMPM or whatever. And you can, like, read the log and, like, see what it is. So those are some of the things that I think – I've lost track of the original question. But anyways, those are some of the things that we, like, have been really leaning into as we build this, like, basically, like, software engineering agent in the cloud.
Josh [00:12:47]: I think also just, like, it feels very different, right? You can, like, look at the features. But I think for me the feeling is, like, there's – it takes a leap of faith the first few times. You're like, I'm not really sure if this is going to work. And it goes off for, like, 30 minutes, right? But then it comes back, and it's like, wow, this agent went out, wrote a bunch of code, wrote scripts to help code mod its own changes, right, tested this, and it really went through the full end-to-end of thinking about the change it wants to make. And I, you know, had no faith at the start that it was going to be able to successfully do it. And then after using it a bit, you're like, wow, like, it actually, you know, pulled through. Yeah. Yeah. Yeah. Yeah. Yeah. It's something that's, like, hard to really, like, summarize. You have to really try it. But it finally feels very different. And, yeah, that feels special.
Alessio [00:13:38]: Yeah. I used it. I opened up VR for it a few minutes ago. I was in the lucky first 25% of people to get the rollout. Yeah, it's very nice. You know, it kind of shortcut it because it couldn't figure out how to run RSpec in Rails. And so it just checked the syntax of the Ruby file, and it was like, looks good to me. But I think it doesn't have the agents.md yet. So I think once I set that up, it'll be good.
swyx [00:14:01]: No, just don't use Ruby, man. Python is one. Oh, yeah. That's still issues.
Alessio [00:14:06]: Once it's good enough to migrate the whole thing, then I'll do that.
Alexander [00:14:09]: I mean, it is funny that there is, just briefly on the note of, like, don't use Ruby or not, there's, like, a bunch of things that I think teams can do to, like, make better use of AI agents. Oh, please. Stop using Ruby.
Alessio [00:14:20]: Number two. No, no, no.
swyx [00:14:21]: But, yeah, if you could list some things out that's, like, best practices, you know, I noted from the live stream that they mentioned ProUBI. So, like, users install linters and formatters so that, basically, these are in-the-loop verifiers that the agent can kind of use, right? Yeah. So, which, like, you know, it turns out to be dev best practices as well, but now the agents can auto-use it. Commit hooks have always been a tricky thing for humans because I've been on teams that were, like, no, everything has to have a commit hook. And then I've also been on teams that were, like, no, like, this thing gets in the way of committing, so let's rip everything out. But actually, for agents, it's actually really good to have commit hooks. Yeah.
Josh [00:14:58]: I mean, you took the words out of my mouth. I think the three I was going to say would be, one, agents.md. And, like, we put a lot of effort into making sure the agent, like, understand this hierarchy of instructions, right? You can put them in subdirectories, and it'll understand which ones take precedence over which others. So, over time, right, like, I mean, we also have, like, O3 and Fora writing our agents.md files for us. I love these.
swyx [00:15:24]: I love the tips. You actually open sourced the prompt descriptions here. Yeah.
Josh [00:15:29]: Yeah. Yeah. Anything you highlight? Yeah. I mean, I think I would start simple and not try to overdo it. And, like, a simple agents.md will get you a long way rather than no agents.md. And then it's more of, like, you learn over time, right? What we would really like to do is auto-generate this at some point for you based on the PRs you create and the feedback you give. But, you know, we figured we'd ship faster rather than later. But...
swyx [00:15:56]: As you mentioned, you have O3, O4 writing agents.md for you as well.
Josh [00:16:00]: Yeah. Like, I'll, like, give it my entire directory, right, and let it...and just say, like, hey, produce an agents.md. Well, actually, these days, I'm using code one to do it because it can...codex one, sorry, to traverse, like, your directory tree and generate those things for you. So, yeah, I would recommend slowly, gradually investing in agents.md. And then, you know, you took the words out of my mouth, like, getting very basic linting formatting up nets you really big wins. Because it's similar to how, like, if you open a new project in VS Code, right, like, you get some out-of-the-box checking. The agent's starting, like, as a human, you're sort of starting without that advantage. And so, this is trying to give that back to the...and, yeah, I don't know, do you have anything else? Yeah.
Alexander [00:16:47]: So, one analogy there. And then, actually, I have just some thoughts we've observed of even, like, using other coding agents, like, just any coding agent, you know, how to prepare for that. But, like, you know, the analogy that comes up. I kind of like is, like, you...so if you start with, like, a base reasoning model, actually, you basically have this, like, really precocious, like, incredibly intelligent, incredibly knowledgeable and, like, weirdly, spikily intelligent, you know, college grad, you know. And but we all know if you hire, like, that person and put them, like, ask them to do software engineering work, like, independently, like, there's just a lot of practices that they're not going to know about. And so, kind of a lot of what we've done with CodexOne is basically give them, like, some of it, its first few years of job experience and, like, that's effectively what the training is, right? So that it just, it kind of knows more of these things. And, like, if you think about it, like, a PR description is a classic example of that, like, writing a good PR description, right? And possibly knowing what not to put in it, actually, right? And then, so that's what you get there. So now you have this, like, this, like, weirdly, weirdly knowledgeable, spikily intelligent college grad with a few years of job experience and then every time you kick off a task, it's kind of, like, their first day at your college. And so, agents.md is basically a method for you to, kind of, compress that, like, test time exploration that it has to do so it can, like, know more. And as Josh said, obviously, we want to, like, right now, it's a research preview, so you have to, like, update it yourself, but there's, like, a lot of ideas we have for how to make that automatic. Yeah. So that's just a fun analogy.
Josh [00:18:15]: Yeah. Maybe the last one I'll say is, like, make your code base discoverable, all right? It's, like, the equivalent of maintaining good engineering practices for new hires that you make. Yeah. So, like, if you want to make your code base faster, right? A lot of my prompts start with, like, I'm working in this subdirectory. Here's what I'd like to accomplish, right? Can you please do it for me? And so, giving that guidance, that scoping, helps.
Alexander [00:18:40]: Yeah. Okay. I'll give you three, sorry, three things for, like, generally. So first, like, language choice. I was hanging out with a friend the other day who's a bit of a latecomer to AI, and he was, like, oh, yeah, I want to try building, like, an agent's product, like, should I build it in JavaScript? Yeah. Yeah. And I was, like, you're still using JavaScript? Like, no wonder. Like, you just, like, you know, use at least TypeScript. Like, give it some types. So, I mean, I think that's a basic one. I don't think anyone listening to us now needs to, like, be told this. Another one is, like, you just make your code modular, right? The more modular and testable it is, the better. But you don't even have to write the tests. Like, an agent can write the tests, but you kind of need to design the architecture to be modular, right? I saw this presentation recently by someone here who was, like, they weren't vibe coding. It was, like, professional software engineer. But using, like, tools like Codex to, like, build a new system. And they got to build a system from scratch. And there was kind of this graph of, like, their commit velocity. And then their system had, like, some traction. So then it was, like, okay, now we're going to port it into, you know, the monolith that is the overall ChatGPT codebase that, you know, has seen ridiculous hypergrowth and so maybe is not, like, the most architecturally preplanned. And, like, their commit rate, the same engineer, same tooling, actually the AI tooling continues to improve, their commit rate just, like, plummets, right? And so I think the other thing is just, like, yeah, architecture, like, good architecture is, like, even more important than ever. And, like, I guess the fun thing is, like, for now that's the thing that humans are really good at. So, like, you know, kind of good, you know, important for the software engineers to do their job.
swyx [00:20:08]: I don't know. Just don't look at my codebase. Yeah, well, definitely don't look at mine.
Alexander [00:20:12]: But the last thing is just kind of a fun story, which is the code name, the internal code name for our project is WAM, like W-H-A-M.
Alexander [00:20:21]: And we chose it, actually, I was working with a research lead, and he was, like, hey, make sure you grep the codebase before you choose the code name. So we, like, searched the codebase, and the string WAM was, like, only present, like, in a few larger strings and never present as its own string. And that means that whenever we prompt, we can be very efficient. We can just say in WAM, right? And then WAM code that is, like, you know, for our web codebase or our server codebase or in, like, our shared types or anywhere. It's, like, really efficient for the agent to find, right? Whereas let's pretend that, like, alternatively, we would have called our product, like, ChatGPT code, you know? Not saying we didn't consider that. Then it would be super hard for the agent to figure out where we wanted to direct it to. And so we'd probably have to provide, like, more relative, like, folder paths. So there's a lot of this stuff, like, as you start to think ahead, like, oh, I'm going to have an agent that's going to be using terminal to grep, then, you know, you can start, like, naming things intentionally.
Alessio [00:21:19]: Would you name? Would you start naming things? Would you start naming things less for humans' readability and more for agent readability? Like, what's kind of the trade-off in your mind?
Josh [00:21:28]: Yeah. It's interesting because I definitely had different priors come in at OpenAI, and, like, I currently believe that the systems are actually very convergent. Like, there's a lot of... Maybe it's because as long as you see humans and AI writing it, like, maybe there's a world where it's only AI that's maintaining a codebase and the substance change. But the moment you sort of have to break that fourth wall and a human is coming in, doing code review, deploying the code, like, it has human fingerprints all over it, right? And so how humans communicate to AI, where to make the changes, how humans communicate a bug that needs to be done, or communicate business requirements, right? All those things aren't going to go away immediately. And so I think the whole system still feels actually very human. I think there's a cooler answer I could say that's like, oh, no, it's like this alien thing. It's completely different. But I don't know. I think it's like these are started off as large language models. There's a lot rooted in AI. There's a lot rooted in human communication. Yeah.
Alexander [00:22:25]: By the way, if there's somewhere you want to take this, you should actually cut us off because I realize we're just kind of monologuing between each other. But it's...
Alessio [00:22:30]: No, no. I think this also ties to the agents.md, right? It's like, why is it called agents.md and not readme.md? There's kind of like, I guess, in your mind, some fundamental difference with how the agents and the human consumes the information. So I'm curious if you think that's at the class naming level, it's just at the instruction level. Like, where does it break down?
Alexander [00:22:49]: Mm-hmm. Yeah. So this is like a few options for this naming, right? Which we considered. So you could go for readme.md. You could go for contributors.md, right? You could go for like codexagent.md and then like maybe like codexcli.md is like these two separate files, right? But like that are sort of like branded.
swyx [00:23:08]: There's also cursor rules, widthsurf rules, everyone has rules. Yeah. Yeah.
Alexander [00:23:12]: And then you could go for agents.md, right? And so like there are a few trade-offs here. I guess one is like openness and one is specificity, I suppose. And so when we thought about it, you know, we thought about, well, probably there's things that you want to tell an agent that you don't need to tell a contributor. And similarly, there's things you want to tell contributors to like really like help them set up in your repo or whatever that you don't need to tell the agent. The agent can just figure that out. So we were like, okay, maybe this is going to be different. And like, you know, the agent's going to read your readme anyways. So like maybe agents.md ends up being like the stuff that you need to tell the agent, that it's not like automatically figuring out from the readme. So we kind of made that decision. Then we considered, okay, there are like different form factors of agents, right? Like the most special thing about what we are building and shipping is like, it's just like an out of the box way to use a cloud-based agent that can do many tasks in parallel and can like think for a long time and can use a lot of tools safely, right? And so we thought like, well, you know, how fundamentally different is the set of instructions that you want to give that from an agent that you're working with more collaboratively? On your computer? We had a good amount of debates about that, to be completely honest. And then we ended up concluding like, actually, those sets of instructions aren't different enough that we need to namespace this file. If there is something you need to namespace, you could probably just like say it in plain language within the file. Then the last thing we consider is like, well, okay, how different do we think the instructions you have to give like our agent are to the instructions you might give to an agent running on a different model or built by a different company? And we just think it kind of sucks if you have to like create like all these different agents or whatever. You know, it's like part of why we made the codec CLI open source is like a lot of problems like safety issues that you need to figure out for how to deploy these things safely. And no one should have to figure these out like more than once. So that's why we went for like a non-branded name.
Josh [00:25:01]: And I have one specific example of why, you know, readme and agent.md are different. For agents, I don't think you really have to tell it code style. It looks at your code base and writes code that's consistent to that, whereas like a human's not going to take its time, sorry, their time to go through the code base and, you know, follow all the conventions, right? So that's just one example. Like, you know, at the end of the day, like there are differences between how these two kinds of developers approach it.
swyx [00:25:38]: Cool. I think that's a really good set of advice. I think you just gave us our episode title, like we're just going to call it best practices for using ChatGPT codecs. Isn't it? You know what I mean? We are going to want best practices. So I noticed something that's very interesting, right? I think there's always two versions in terms of building agents, one which is you try to be more controlling, you try to make it more deterministic, and then the other, you try to just prompt it and trust the model. And I think your approach is very much prompt it, trust the model. I see inside of the agent.md system prompt that, you know, you just prompt it to like behave the way that you want and you just expect the model to behave it. Obviously, you have control of the model so you can train it if it doesn't do well. But like one thing that makes me question it is how do you fit everything in context? Like what if I just have a super long HSMD, you know, in your live stream you had it demoing on like the OpenAI model repo, which is just giant, right? So how do you manage caching and context windows and all that?
Josh [00:26:48]: Yeah. I mean, would you believe it? Would you believe me if I told you right now that it all fits in the context window?
swyx [00:26:55]: Not the OpenAI repo. No, but sorry, everything that the agent needs to... Right. So you reify the HSMD, you put it at the top, right? It's just like another system prompt.
Josh [00:27:05]: No, actually, it's a file that the agent knows how to like grep and set for, right? Okay. Because there might be multiple ones. And so you can actually see it in the work log, right? It's like going to look for it. It very aggressively looks for an agent and it's been trained to do that. I'll say it's been really interesting joining OpenAI and like seeing how, you know, when you're thinking about where models are going and what AI products will look like years from now, you know, you design products in a different way, right? Like before OpenAI, especially when you don't have access to a team of researchers and many main GPUs, you're building these deterministic programs, right? A lot of scaffolding around how to do that. But you don't really let the model operate at its fullest capacity, right? It was interesting when I just joined, actually, I got a lot of pushback saying like, hey, why don't we just like hard code, like, listen, you keep using this tool wrong. Let's just say in our prompt, don't do that. And then the researchers will be like, no, no, no, we don't do that. We're like, we're going to do it the right way. We're going to teach the model why this is the right way to do it. And I think that's like related to this overall thought. Like, where do you put the deterrent? Where do you put the deterministic guardrails in? And where do you really let the model think, right? Similar conversation around planning. Should we just have an explicit planning stage where it's like, think out loud first, write down what you're going to do, and then go do it? Sure. But what if the task is really easy? All right. Do you really want to think of this whole time? What if it needs to like replant as it goes? Like, do you have all these like if else conditions, heuristics to do that? Or do you train a really good model that knows how to switch between those modes of thinking? And so it's tough. Like, I definitely have advocated for a lot of these things. Like, little guardrails here and there until like the next training runs done. But I think that's really like, we're really building for this future where the model is able to make all these decisions. What's really important is that you give it the right tool, right? You give it ways to manage context, manage memory, manage, you know, ways to explore the code base. Those still are really important.
Alexander [00:29:11]: Yeah. That's like, yeah, super well said, like, I think building here is like, super fun and different. And like, you know, the model isn't all the product, but the model is the product, right? And you kind of like need to have this kind of like humility in terms of like thinking about like, okay, well, what are the things that like, we, there's like three parties, right? There's the user, the developer and like the model maybe, right? What are the things that the user like just needs to decide up front? And then what are the things that like we, the developer are going to be able to decide better than the model? And then what are the things that the model can just decide best, right? And like that. You kind of, every decision is like, just has to be one of those three and you know, it's not like everything's the model. Like for instance, we have two buttons in the UI right now, like ask and code and like, you know, those, those probably could get inlined into, into like the decisions the model makes. But you know, right now it was just really like, it made sense to kind of just give the user choice upfront because we spawn a different container for the model first, based on what button you press. So like if you, if you ask for code, we put all the dependencies in, I'm going to oversimplify here. But if you don't ask for code, if you're just asking a question, we like do a much quicker container setup before the model like gets any choice. And so, you know, that's maybe a user decision. There's some places where, you know, user and developer decisions kind of come together around the environment. But like ultimately a lot of like, a lot of like agents that I see are really impressive, but it's basically like part of what's impressive is it's like a bunch of developers building, building this like really bespoke state machine around a bunch of like short model calls. And so then the upper bound of like complexity of problem that the model can tackle is kind of actually just what can fit in the developer's brain. Right. And over time we want these models to capture like, or to, to solve for much more complex problems, you know, like just by themselves on like more and more complex individual tasks. And then eventually you could really imagine that you get like a team of agents working together maybe with like one agent that's kind of managing those agents and you know, the complexity just explodes. And so we really want to like get as much of that complexity, as much of that state machine as possible, like pushed into the model. And so you end up with these kind of two modes of building, like in one place you're like building product, UI and rules. And in the other case, you're, you still have to do work to get the model to learn something, but rather what you have to do is you have to figure out like, what are the right things that this model needs to see during its training to like learn something. And so it's still a lot of human work to like figure out how to get that change, but it's like a very different way of thinking of like, we're going to get the model to see this.
Alessio [00:31:43]: But how do you build the product to get the signal? So if you think about the code in ask, it's almost, you're basically getting the user to label the prompt in a way, right? Because they say, ask, this is an ask prompt code. This is a code prompt. Are there any other kind of like fun product designs, like as you built this of like, okay, we think the model can learn this, but we don't have the data. This is how we architect codecs to kind of help us collect the data.
Josh [00:32:09]: I think file context and scoping is, we don't have great built in things. Like that right now. But it's like one of the obvious things that we need to add is another example of this, right? Like you could have, we're often usually pleasantly surprised as, oh, it was able to find the exact file that I was thinking about, but it takes some time, right? And so a lot of times you'll shortcut a bunch of chain of thought by just saying, hey, I'm looking at this directory, can you go through? So I think that'll probably be there for a bit until, you know, you have some better architectural indexing and search capabilities. Okay.
Alexander [00:32:44]: Yeah. I'll add to this. Like, I'm actually going to double down on my thing about like, where do we, how do we think about it? Like, so, you know, one thing we might consider is like context window management, right? And like, should we intervene here? And so we could do a product intervention, right? Like write some code to intervene and then kind of the next level of thinking maybe like a little bit more AGI pilled is like, okay, let's, let's get the model to like see context window management stuff in this training. I can't even come up with an example now at this point, cause I'm too AGI filled, but like, I don't know. We could come up with something that it has to see to like learn how to manage its context. Like, but it's like a specifically tasks related to context window. But then the most AGI pilled thing to do is like, to be like, we don't actually need to think about this problem. The model will just figure it out. All we have to do is give it harder and harder problems. And then like, it will just have an emergent property of managing its own context. Because that's the only way it can like solve these problems. Right. So I'm kind of slightly like oversimplifying here, but like, you know, basically the model learns to manage its context. And so you, when you were talking about like it working in the monorepo. It learns how to be like efficient with the way that it spends its tokens as it's like browsing and like setting and like, you know, in your example of like, there's a giant agents.md, like, I guess we, you know, it would just need, we would just to show it some versions where there was that. And so it learns it can't, it shouldn't read the whole thing every time and should like first figure out how many lines it has, et cetera. So anyways, summarizing, I'm like, we just need to keep giving it harder and harder problems. And a lot of these things that we might be very tempted to like build a sub intervention for, like, it will just have to figure out and if it doesn't figure it out, maybe it didn't matter.
swyx [00:34:15]: Sure. Yeah. Uh, I totally get, uh, that I think like we don't really have online models yet. Right. And that's kind of what you need for, for your vision to be real. Um, and for what it's worth, I wasn't thinking about like a giant agents.md, I was just thinking about like hierarchical nested agents.md with, with like a lot of code, um, and like, I think one issue where you have this version where the model is the product is your, your dev cycle as the codex team. Right. Like you have to kind of, it's not as tight because you have to be like, okay, every time there's a bug. All right. Now I need to go get data. Um, and where do you get the data? I don't, I don't know. Like maybe employees use it. Maybe you have like, you buy it from vendors and like you hire some human raters or whatever, and then you have to train it in and then you have to go test it again. It's very slow, isn't it? And like expensive. Yeah.
Alexander [00:35:09]: I think it's definitely, yeah, I think it's definitely like from a, from a building perspective, you, you have to do this. When you're really willing to play the, like the long-term vision of like, we're going to build a better model, maybe even a better model bespoke for a certain like functional purpose like codex one. And then we're going to generalize the learnings from that model into like an even bigger model. That's like getting all these other like learnings from other functional purposes and like these together will like become a really powerful thing. And that's, that's like kind of like the philosophy we've have with training models so far. Um, and it has been working, but it's, it's definitely like a long-term play, you know, like another example, we, we do, we do do this on occasion. Like for example, uh, recently we released GPT 4.1, like really good coding model. And again, that was like based on like working, we were like, Hey, we want to invest better in this area. Let's hang out with a bunch of developers, understand their feedback, how things work, um, you know, create some evals. And you know, like you said, this is like, it's a lot of work to do that. Um, but then we end up with a great model and even more exciting, we can then like take those learnings and like put them into our mainline model. And then everything benefits and you kind of the, the, the, the sort of philosophical view. I don't know if I can like factually prove it or not. Maybe someone here can, is that like, if you can like build, do something very specific for like a specific purpose, actually, when you bring that and you bring it to the, into the generalized model, like you might even get outsized returns on that because there's like transfer from all these different domains.
swyx [00:36:37]: Um, okay, cool. Uh, I think we had a couple factual things to wrap up on, on just like Codex itself. And then we wanted to double click on the compute platform stuff, which, uh, I think, uh, Josh, you wanted to, to cover more on. Um, so I, I noticed in the details, it was, um, between one to 30 minutes in length. Um, is it, is that a hard cutoff? Um, have you had it go, go for longer? Um, any, any comment on the, the task time?
Josh [00:37:02]: Yeah. I mean, I just checked the code base before this, uh, cause someone else has a similar question. Uh, are hard cutoffs an hour right now? Although don't hold us to that. It may change over time. Um, the longest is I've seen two hours when, uh, in development mode and the model one, off the rails. Um, so, you know, I, I, but I think 30 minutes is a great ballpark for the kind of tasks that we're trying to solve, right? These are hard tasks that require a lot of iteration, uh, and testing and, uh, the model needs that time.
Alexander [00:37:31]: Yeah. I mean, yeah, I, I think actually like our average is like pretty, it's significantly lower than 30. Yeah. But if you give it a hard, if you give it a hard task, you'll, you'll end up at 30.
swyx [00:37:40]: Yeah. I mean, um, you know, I think there's, there's a couple analogies here. One. Uh, I think the operator team released a benchmark where they, they had to cut off for two hours. And then the other one is the meter paper, which I don't know if has been circulating where they estimated that the, uh, the current average autonomous time is like an hour and it's maybe doubling every seven months. Um, so like an hour sounds right, but also, I mean, that's the median. So there's going to be some that are, that go longer than that. Yeah, totally. Is this part of the, uh, you had cutoffs for a few, like 23, um, sweet bench, very few, very rare examples that were not runnable. Was that part of it, uh, in terms of length or was there, it was just something else.
swyx [00:38:20]: Yeah.
Alexander [00:38:21]: Yeah. To be honest, I'm not exactly sure, but I feel like there's a bunch of sweet bench cases that actually are like an invalid might be too strong of a word and a little bit out, you know, not sure, but like, I feel like there's like issues with running them. So they just don't work. Okay. Yeah.
swyx [00:38:35]: Um, and then max concurrency, is there a concurrency limit? If I have like five, 10, a hundred simultaneous.
Alexander [00:38:41]: Five and 10 is totally fine. Do we actually have a, I feel like we did like introduce like a. A limit for fraud reasons. Like, I don't know what it is. Yeah.
Josh [00:38:47]: I think right now it's 60 an hour. Um, but. Wow.
Alexander [00:38:53]: So one per minute, I'm just going to, yeah, but look, this, this is literally the point, right? Like it is. So, so like longterm, we actually don't want you to have to think about if you're like delegating or like pairing with AI, like if you imagine an AGI, like super assistant, you just like ask, you just talk to it and it just does stuff. It answers quickly if it needs to, you know, it takes a long time and you also don't have to like only talk to it. It's also just like present your tools. Right. So that's, that's like the longterm thing, but in the near term, like, yeah, this is a tool you delegate to. And um, the way to use it that we see, like, you know, going back to the, I guess the, maybe the title of this podcast of like best practices, it's like, you must have an abundance mindset and you must think of it as like, like not using your time to explore things. And so like, you know, often when something, a model is going to work on your computer and it's going to work on your computer, you're like really craft the, the, the prompt because, you know, then it's, it's going to use your computer for a while and maybe you can't. Um, but the way we see people who like love Codex the most using it is they don't, they think for like maybe 30 seconds max about their prompt. It's just like, oh, I have this idea, like, boom, oh, there's this thing I want to do like, boom. Oh, like I just saw this bug or like this customer feedback thing, like, and you just send it off. And so, yeah, like the more you're running in parallel, actually, I think that, I mean, the happier we are and like the happier we think like users are when they see it, like, that's just the vibe of the product really.
swyx [00:40:13]: I would, I would pass my own anecdotes. So I was on the trusted testers team for this thing, uh, as you both of you well know, and I was using, I found out I was using it wrong. I was using it like cursor, like I had my chat window open and I watched it code and then I realized I wasn't supposed to, and I was like, oh, like you guys are just firing the things off and like, you know, going on about your day. And, um, yeah, that, that, that was a change in mindset. Yeah. One. Yeah.
Alexander [00:40:39]: Real quick. I'll keep it brief. Like one thing that's quite fun is like, use it on your phone because somehow just like being on your phone, just like flips the way people think about things. So like we made the website responsive and you know, we'll make, we'll pull it into the app eventually. Um, so like try it, like it's actually like super fun and satisfying. Okay.
swyx [00:40:56]: So yeah, it's not, yeah, cause there was a, there was a voice, uh, there was one of the videos that was showing the mobile engineer coding with it on his phone, but it's not available in ChatGPT's app. Okay. Yeah. Yeah.
Alessio [00:41:08]: Yeah. Not yet. Just one question I got from the mobile. I got the notifications that I get, uh, when it starts the task, it says starting research the same way, the deep research notification is, uh, is it using deep research as a tool or did you just reuse the same, uh, notification that we just used the same notification? Yeah. So you mentioned the compute platform. You mentioned how you share some of the infrastructure with RL. Can you maybe just give people a high level of like what the codex has access to? What it doesn't have access to? Like it doesn't look like people can run commands, uh, themselves. They can only instruct the model to do it. Um, any other things people should keep in mind? Yeah.
Josh [00:41:48]: So, and I'll say, uh, it's a, it's an evolving discussion as we figure out what parts, uh, we can give folks access to and the agent and vice, like, and what we need to like hold back for, for now. Right. And so we're learning and it's really, we would like to give, uh, humans and agents alike as much access as possible within safety and security, uh, constraints. Um, what you can do today, right, is as a human, um, set up an environment, set up scripts that get them run. Uh, these scripts typically will be installing dependencies. I expect that to be maybe 95% of the use case there, uh, and just really get all the right binaries in place for your agent to use. Um, we actually do have like a bit of an environment editing experience, whereas a human, you can drop into a REPL, try things out. Um, so, you know, um, uh, please don't abuse it, but, uh, there's definitely ways, uh, for you to interact with the environment there.
Alexander [00:42:43]: Um, we, we laugh about that because like earlier I mentioned scope creep, like we weren't planning on having a REPL, like to like interactively update your environment, but like, you know, anyway, we try, Josh was like, oh man, we need this. And so that was like an example. Scope creep. Thanks for doing it.
Josh [00:42:57]: We do have rate limits in place and we do monitor that very carefully, but you know, there's interactive bits of there to like, to, to get that going. But, um, once the agent starts running, right, um, what we actually do today, and we're hoping to like evolve on this is we'll, um, cut off internet access, uh, because we still don't fully understand what letting loose an agent in its own environment is going to do. Right. Um, you know, for now the safety tests all have come back very sturdily, like, you know, it's not susceptible to sorts of certain exfiltration attempts on prop injection, but there's still a lot of risks to this category. So we don't know. And, um, that's why to start. Yeah. I mean, it's, it's not conservative there. And when the agent's running, it doesn't have a full network access, but you know, I love to be able to change that, right. Allow it to give limited access, certain domains or certain, uh, repositories. And so all this to say, it's like something we're evolving as we build out the right systems to support that. Um, not sure that quite touches on your original question. Um, the last thing though, that I do want to mention is like, there's an interactivity, um, element with like, you know, as the agent's running. Yeah. Sometimes you're just like, oh, I want to like correct it, tell it to like go somewhere else or, um, you know, let me maybe fill this part out and, uh, then you can take back over. Right. We haven't quite solved those problems either. What we really wanted to start was to like shoot for the fully independent, just like deliver massive value in one shot kind of approach. Um, but yeah, we're definitely thinking about how we can, uh, weave human and agents together, um, better.
swyx [00:44:34]: Uh, I mean, uh, for what it's worth. Yeah. I think the one shot thing is, um, a good angle that, that the other, the other people, you know, like, uh, and this is me comparing you to, to alternatives like Devin and factory and all the others. Um, there are more focused on multi-shot human feedback, all these, but like, um, you know, I, so I, I have a web website I'm working on and I, and I gave it a request and I compared it all the others. That was my test for, uh, Codex, uh, and it did one shot it. I posted it. Uh, uh, the screenshot is a tweet, uh, just earlier today. Okay. Um, and it's, uh, I think it's really good, especially if you're running 60 at a time. so I think that, that really makes sense, but it, it's, it is a very ambitious goal because like, um, you know, human feedback is a crutch that we like to use. Um, it also, I think makes us write more tests, which is annoying cause I don't like to write tests, but now I have to write tests. Fortunately, I can, I'm now getting Codex to write my own tests and I really liked the, on the, on the live stream as well. You can just kind of ask it to just look at your code base and just suggest stuff to do. Cause I don't even have the energy to figure out what I should be doing.
Alexander [00:45:40]: Yeah. I delegated delegation. I thought that was a great line. Yeah.
Josh [00:45:43]: Um, and we're not saying one form factor is better than the others, right? Like, you know, I love using Codex CLI, um, and, uh, it's really, we just want, like, as we talked about in our interview, when I was interviewing over an AI, like you really want both modes. Um, but I think what we see as like the role of Codex here is to really push the frontier. Yeah. On that sort of single shot autonomous, um, software engineering.
Alexander [00:46:10]: Yeah. Like, I kind of think of the research preview as like our, like our thought experiment. It's like, you know, what, what is coding agent like in its purest, like most like AGI pilled or scale pilled, scale pilled form look like. And then maybe, I mean, for me personally, like, I dunno, like part of what excites me about working at OpenAI, it's not just like solving for developers, but it's just really thinking about like, how does AGI like benefit all of humanity and like, what does that feel like to non-developers as well? And so like, for me, like what's really interesting is like thinking of Codex as an experiment for like what it'll feel like to be in other functions, um, you know, doing work. And like the goal for me to, to build towards is this is a vision where it's like, you know, we do the work that's like ambiguous or creative or hard to automate in whatever way. And, but otherwise we just have like agents, like that we're delegating most of the work to. Um, but these agents, they're, they're not like this, like long horizon thing versus short horizon. They're just like kind of ubiquitously available. Um, why? Because they're not with you. Um, so, uh, yeah, we, we decided to like take the purest form to start, which we thought would be the smallest scope thing to ship and probably isn't. Uh, but, uh, yeah, and then we're going to bring these things together.
swyx [00:47:18]: Uh, okay. I think we have time for a couple of questions. Um, we, you, I'm just going to double click on the research preview a bit. Um, it is a research preview. Why? What, what is left? What do you think would qualify it to be a full release? Um, you know, on, on the live stream, Greg mentioned this seamless, uh, journey. Um, you know, the transition between cloud and CLI, uh, is it that, or is there, is there, are there other things on your mind?
Alexander [00:47:42]: I mean, to be completely honest, you know, we, the part of why we believe so much in iterative deployment, like I can give you some of my thoughts now, but like also we're really curious to see. Um, so because this is like such a new form factor. Um, but you know, some of the items that are top of mind for me are like multimodal inputs. you know, we've, we've talked. Yeah. I know you like that. Right. Yeah. Like another, another example would be like, you know, just giving it a little bit more access to the world. Um, you know, a lot of folks have, have requested for like forms of network access. Um, you know, I also think that, um, right now kind of the, the UI that we shipped is actually one that we iterated around. It's like a fun story there, but like, um, and it's one that people find useful, but it's, it's definitely not the final form of what it is. And like, we would love for it to be like much closer with the tools that developers spend time in. So like, those are some of the themes we're thinking about. Um, but you know, to be clear, we'll iterate and figure that out.
Alessio [00:48:35]: Um, I wanted to ask, why did you put finding a typo as one of the onboarding things? Because I used it and then I saw it and it's literally just grepping for potential type. It's like searching, grepping for like Selenium with an N or like something with like some T G N instead of N G, but it went through like 50 of these and then finally found will misspell this W I L without the two thing. But it was really cool to see what it thought, like default, uh, spelled as like D E F U A L T. It's like, it just grabbed all these different things. And then eventually got there. Like, why, why, why did you make that task?
Josh [00:49:20]: Honestly, T when I were talking about it and he was like, listen, it would be funny if I had a typo as I typed this prompt out and, uh, just make it a little bit meta, um, you know, nervous fingers on a, uh, on a live stream. Uh, so maybe optimized for the, for that. Okay. I have noticed it. Um, you know, it likes to do T E H to look for the, um, and so it's a work in progress.
Alessio [00:49:45]: That was great. Um, any parting thoughts called to action? Are you growing the team? Do you want a specific feedback from the community?
Josh [00:49:57]: Yeah. I think for me, like the one thing that, um, you know, um, is really on my mind for getting better at, um, over the next few months is really helping you customize your environment, uh, more, um, in a more high fidelity manner. Um, it turns out the good news is the agent can do a lot of really good work with only the basics, right? Um, it's much like if your dev machine is borked and you're sort of looking at your editor, but none of the type checks are working. You, a lot of folks can still actually do a lot of good work, but, um, how do you get close that last, you know, 30, 40%. And it's really hard because, uh, there's such a wide variety of environments out there. Um, but especially would love feedback from folks on how they would like to see their environment change. How do they want to see their environment customized? Do they want to just ship us a darker image where they rather have a support dev containers, right? Um, so the form factor of how you do the DX of how you do, um, environment customization still very much an open question that we need to improve on.
Alexander [00:50:53]: Yeah. Big plus one to that. And I think for me, maybe the thing that I'm most interested in is, Hey, this is, this is like a new shape of, of tool to collaborate with. Uh, and I'm just really interested for people to try working with it in as many different ways as possible. And like, kind of figure out like, where does it work well in your workflow? Like you said, you know, you mentioned you earlier, you were trying to use it kind of like your IDE and then you realized it was different. Right. So I would just love for people to take advantage, especially now, like we're very intentionally just providing like very generous rate limits. So people can try it. Like, we just want you to try it and figure out what sticks, what works, what doesn't, how do you prompt it? And then we want to learn from that and use that to lean in. So yeah, my, my, I guess my parting call to action is like, please go try it out, um, in ChatGPT. Use it as much as you can, especially now, and then let us know, uh, like how you like to hold it. Basically.
swyx [00:51:44]: Yeah. I'm, I'm, uh, worried about the pricing when it happens, but yeah, I'm going to abuse this. Why not? Why not? Yeah. Send us feedback on pricing too. Yeah. Um, okay. Uh, you're pro it's too early to talk about pricing, right? Uh, yeah, it's too early now. Yeah. Okay. All right. Um, but, uh, yeah, based on cloud code, that's the thing that people are worried about. Right. Um, and cloud has started to introduce some kind of fixed pricing. Yeah. And I think it's a, it's a huge mess. Like it's, there's no right answer. Everyone just wants the cheapest form of code attention they can get. Um, so yeah. Good luck. Thanks.
Josh [00:52:19]: I mean, my take is, I don't know, it's going to make it into, but like we aim to deliver out a lot of value. Right. And it's on us to show that and really make people realize like, wow, this is like doing very economically valuable work for me. And I think a lot of the pricing can fall from that. Um, but yeah, it's, it's, it's, it's, it's, it's, it's, it's, it's, it's, it's, it's, it's, I think that, I think the, that's where the conversation should start. Um, are we actually delivering that value?
swyx [00:52:44]: Yeah. Awesome. All right. Well, thank you so much. Yeah. Thanks for working on this and thanks for sharing your time. Um, it is, uh, it's been, it's been a long time coming, but I think people can start seeing. OpenAI in general, is getting very serious by agents. It's not just coding, but coding obviously is the, the one group that is self-accelerating that I think, um, I've, obviously you guys are super passionate about. It's really inspiring to see.
Alexander [00:53:08]: Yeah. Yeah, super excited to just, like, ship everyone this coding agent and then, yeah, like, bring it together into just, like, the general AGI super assistant. Yeah, so thanks for having us on.
Alessio [00:53:19]: Thank you, guys.
Alexander [00:53:20]: Cool. Thank you.
TLDR is I need to try harder to use it. We’ll see if I have the motivation to keep making the time for it
The RSS feed doesn't seem to have media files anymore. Been happening for awhile. I'm podcast 1st and don't use video unless I really have to, and then usually skip it. They're just not appealing to me.
And for this episode the video is broken anyway?