



FlashAttention was first published by Tri Dao in May 2022 and it had a deep impact in the large language models space. Most open models you’ve heard of (RedPajama, MPT, LLaMA, Falcon, etc) all leverage it for faster inference. Tri came on the podcast to chat about FlashAttention, the newly released FlashAttention-2, the research process at Hazy Lab, and more.
This is the first episode of our “Papers Explained” series, which will cover some of the foundational research in this space. Our Discord also hosts a weekly Paper Club, which you can signup for here.
How does FlashAttention work?
The paper is titled “FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness”. There are a couple keywords to call out:
“Memory Efficient”: standard attention memory usage is quadratic with sequence length (i.e. O(N^2)). FlashAttention is sub-quadratic at O(N).
“Exact”: the opposite of “exact” in this case is “sparse”, as in “sparse networks” (see our episode with Jonathan Frankle for more). This means that you’re not giving up any precision.
The “IO” in “IO-Awareness” stands for “Input/Output” and hints at a write/read related bottleneck.
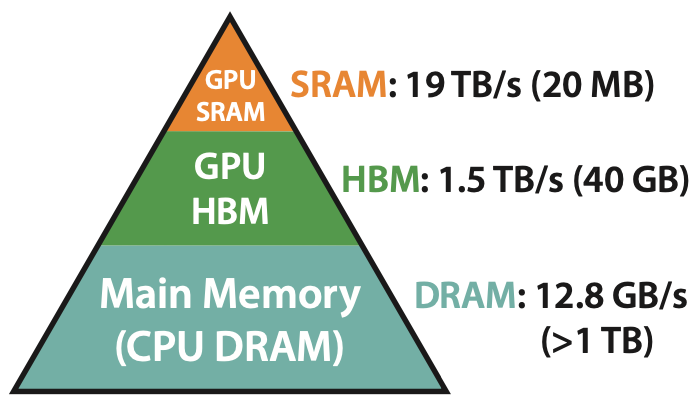
Before we dive in, look at this simple GPU architecture diagram:

The GPU has access to three memory stores at runtime:
SRAM: this is on-chip memory co-located with the actual execution core. It’s limited in size (~20MB on an A100 card) but extremely fast (19TB/s total bandwidth)
HBM: this is off-chip but on-card memory, meaning it’s in the GPU but not co-located with the core itself. An A100 has 40GB of HBM, but only a 1.5TB/s bandwidth.
DRAM: this is your traditional CPU RAM. You can have TBs of this, but you can only get ~12.8GB/s bandwidth, which is way too slow.

Now that you know what HBM is, look at how the standard Attention algorithm is implemented:

As you can see, all 3 steps include a “write X to HBM” step and a “read from HBM” step. The core idea behind FlashAttention boils down to this: instead of storing each intermediate result, why don’t we use kernel fusion and run every operation in a single kernel in order to avoid memory read/write overhead? (We also talked about kernel fusion in our episode with George Hotz and how PyTorch / tinygrad take different approaches here)
The result is much faster, but much harder to read:


As you can see, FlashAttention is a very meaningful speed improvement on traditional Attention, and it’s easy to understand why it’s becoming the standard for most models.
This should be enough of a primer before you dive into our episode! We talked about FlashAttention-2, how Hazy Research Group works, and some of the research being done in Transformer alternatives.
Show Notes:
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness (arXiv)
Transformer alternatives:
Timestamps:
Tri's background [00:00:00]
FlashAttention’s deep dive [00:02:18]
How the Hazy Research group collaborates across theory, systems, and applications [00:17:21]
Evaluating models beyond raw performance [00:25:00]
FlashAttention-2 [00:27:00]
CUDA and The Hardware Lottery [00:30:00]
Researching in a fast-changing market [00:35:00]
Promising transformer alternatives like state space models and RNNs [00:37:30]
The spectrum of openness in AI models [00:43:00]
Practical impact of models like LLAMA2 despite restrictions [00:47:12]
Incentives for releasing open training datasets [00:49:43]
Lightning Round [00:53:22]
Transcript:
Alessio: Hey everyone, welcome to the Latent Space podcast. This is Alessio, Partner and CTO-in-Residence at Decibel Partners. Today we have no Swyx, because he's in Singapore, so it's a one-on-one discussion with Tri Dao. Welcome! [00:00:24]
Tri: Hi everyone. I'm Tri Dao, excited to be here. [00:00:27]
Alessio: Tri just completed his PhD at Stanford a month ago. You might not remember his name, but he's one of the main authors in the FlashAttention paper, which is one of the seminal work in the Transformers era. He's got a lot of interest from efficient transformer training and inference, long range sequence model, a lot of interesting stuff. And now you're going to be an assistant professor in CS at Princeton next year. [00:00:51]
Tri: Yeah, that's right. [00:00:52]
Alessio: Yeah. And in the meantime, just to get, you know, a low pressure thing, you're Chief Scientist at Together as well, which is the company behind RedPajama. [00:01:01]
Tri: Yeah. So I just joined this week actually, and it's been really exciting. [00:01:04]
Alessio: So what's something that is not on the internet that people should know about you? [00:01:09]
Tri: Let's see. When I started college, I was going to be an economist, so I was fully on board. I was going to major in economics, but the first week I was at Stanford undergrad, I took a few math classes and I immediately decided that I was going to be a math major. And that kind of changed the course of my career. So now I'm doing math, computer science, AI research. [00:01:32]
Alessio: I had a similar thing. I started with physics and then I took like a programming course and I was like, I got to do computer science. I don't want to do physics. So FlashAttention is definitely, everybody's using this. Everybody loves it. You just released FlashAttention 2 last week. [00:01:48]
Tri: Yeah. Early this week on Monday. Yeah. [00:01:53]
Alessio: You know, AI time. Things move fast. So maybe let's run through some of the FlashAttention highlights, some of the innovation there, and then we can dive into FlashAttention 2. So the core improvement in FlashAttention is that traditional attention is a quadratic sequence length. And to the two, FlashAttention is linear, which obviously helps with scaling some of these models. [00:02:18]
Tri: There are two factors there. So of course the goal has been to make attention go faster or more memory efficient. And ever since attention became popular in 2017 with the Transformer paper, lots and lots of folks have been working on this. And a lot of approaches has been focusing on approximating attention. The goal is you want to scale to longer sequences. There are tons of applications where you want to do that. But scaling to longer sequences is difficult because attention scales quadratically in sequence length on both runtime and memory, as you mentioned. So instead of trying to approximate attention, we were trying to figure out, can we do the same computation and maybe be more memory efficient? So in the end, we ended up being the memory is linear in sequence length. In terms of computation, it's still quadratic, but we managed to make it much more hardware friendly. And as a result, we do get wall clock speed up on the order of 2 to 4x, which really helps because that just means that you'll be able to train with 2 to 4x longer sequence length for the same cost without doing any approximations. As a result, lots of folks have been using this. The thing is available in a lot of libraries that do language model training or fine tuning. [00:03:32]
Alessio: And the approximation thing is important because this is an exact thing versus a sparse. So maybe explain a little bit the difference there. [00:03:40]
Tri: For sure. So in addition, essentially you compute pairwise similarity between every single element in a sequence against each other. So there's been other approaches where instead of doing all that pairwise computation, you only compute similarity for some pairs of elements in the sequence. So you don't do quadratic number of comparison. And this can be seen as some form of sparsity. Essentially you're ignoring some of the elements. When you write down the matrix, you essentially say, OK, I'm going to pretend there's zero. So that has some benefits in terms of runtime and memory. But the trade-off is that it tends to do worse in terms of quality because you're essentially approximating or ignoring some elements. And I personally have worked on this as well for a few years. But when we talk to practitioners who actually train models, especially at large scale, they say, tend not to use these approximate attention methods. Because it turns out, this was surprising to me at the time, was that these approximation methods, even though they perform fewer computation, they tend to not be faster in walk-on time. So this was pretty surprising because back then, I think my background was more on the theoretical side. So I was thinking of, oh, how many flops or floating point operations are you performing? And hopefully that correlates well with walk-on time. But I realized that I was missing a bunch of ideas from the system side where flops or floating point operations don't necessarily correlate with runtime. There are other factors like memory reading and writing, parallelism, and so on. So I learned a ton from just talking to systems people because they kind of figured this stuff out a while ago. So that was really eye-opening. And then we ended up focusing a lot more on memory reading and writing because that turned out to be the majority of the time when you're doing attention is reading and writing memory. [00:05:34]
Alessio: Yeah, the I.O. awareness is probably one of the biggest innovations here. And the idea behind it is, like you mentioned, the FLOPS growth of the cards have been going up, but the memory bandwidth, not as much. So I think maybe that was one of the assumptions that the original attention paper had. So talk a bit about how that came to be as an idea. It's one of those things that like in insight, it's like, obviously, why are we like rewriting to like HBM every time, you know, and like once you change it, it's clear. But what was that discovery process? [00:06:08]
Tri: Yeah, in hindsight, a lot of the ideas have already been there in the literature. And I would say is it was somehow at the intersection of both machine learning and systems. And you kind of needed ideas from both sides. So on one hand, on the system side, so lots of systems folks have known that, oh, you know, kernel fusion is great. Kernel fusion just means that instead of performing, you know, loading the same element, instead of performing an operation, write it down, load it back up and perform the second operation, you just load it once, perform two operations and then write it down again. So that saves you kind of memory read and write in the middle there. So kernel fusion has been a classic. There's been other techniques from the system side, like tiling, where you perform things in the form of computations in block, again, so that you can load it into a really fast memory. Think of it as a cache. And this is, again, classical computer science ideas, right? You want to use the cache. So the system folks have been thinking about these ideas for a long time, and they apply to attention as well. But there were certain things in attention that made it difficult to do a complete kernel fusion. One of which is there is this softmax operation in the middle, which requires you to essentially sum across the row of the attention matrix. So it makes it difficult to kind of break it, because there's this dependency. So it makes it difficult to break things into a block. So on the system side, people have been thinking about these ideas, but it's been difficult to kind of do kernel fusion for the entire operation. On the machine learning side, people have been thinking more algorithmically. They say, okay, either we can approximate attention, or there's this trick called the online softmax trick, which says that because of softmax, the way it's written mathematically, you can actually break it up into smaller pieces, do some rescaling, and still get the right answer. So this online softmax trick has been around for a while. I think there was a paper from NVIDIA folks back in 2018 about this. And then there was a paper from Google. So Marcus, Rob, and Stats wrote a paper late 2021 on using this online softmax trick to break attention up into smaller pieces. So a lot of the ideas were already there. But it turns out, you kind of need to combine ideas from both sides. So you need to understand that, hey, we want to do kernel fusion to reduce memory written writes. But we also need this online softmax trick to be able to break the softmax into smaller pieces so that a lot of the systems tricks kind of carry through. We saw that, and it was kind of a natural idea that we ended up using ideas from both sides, and it ended up working pretty well. Yeah. [00:08:57]
Alessio: Are there any downsides to kernel fusion? If I think about databases and the reasons why we have atomic operations, you know, it's like, you have observability and fallback in between them. How does that work with attention? Is there anything that we lose by fusing the operations? [00:09:13]
Tri: Yeah, I think mostly on the practical side is that you lose a little bit of flexibility in the sense that, hey, now you have, for example, faster attention, it's just a subroutine that you would call to do attention. But as a researcher, let's say you don't want that exact thing, right? You don't want just attention, let's say you want some modification to attention. You want to do, hey, I'm going to multiply the query and key, but then I'm going to do this extra thing before I carry on. So kernel fusion just means that, okay, we have a subroutine that does the entire thing. But if you want to experiment with things, you won't be able to use that fused kernel. And the answer is, can we have a compiler that then automatically does a lot of this kernel fusion? Lots of compiler folks are thinking about this, either with a new language or you can embed it in PyTorch. PyTorch folks have been working on this as well. So if you write just your code in PyTorch and they can capture the graph, can they generate code that will fuse everything together? That's still ongoing, and it works for some cases. But for attention, because of this kind of softmax rewriting stuff, it's been a little bit more difficult. So maybe in a year or two, we'll have compilers that are able to do a lot of these optimizations for you. And you don't have to, for example, spend a couple months writing CUDA to get this stuff to work. Awesome. [00:10:41]
Alessio: And just to make it clear for listeners, when we say we're not writing it to memory, we are storing it, but just in a faster memory. So instead of the HBM, we're putting it in the SRAM. Yeah. [00:10:53]
Tri: Yeah. [00:10:54]
Alessio: Maybe explain just a little bit the difference there. [00:10:56]
Tri: Yeah, for sure. This is kind of a caricature of how you think about accelerators or GPUs in particular, is that they have a large pool of memory, usually called HBM, or high bandwidth memory. So this is what you think of as GPU memory. So if you're using A100 and you list the GPU memory, it's like 40 gigs or 80 gigs. So that's the HBM. And then when you perform any operation, you need to move data from the HBM to the compute unit. So the actual hardware unit that does the computation. And next to these compute units, there are on-chip memory or SRAM, which are much, much smaller than HBM, but much faster. So the analogy there is if you're familiar with, say, CPU and RAM and so on. So you have a large pool of RAM, and then you have the CPU performing the computation. But next to the CPU, you have L1 cache and L2 cache, which are much smaller than DRAM, but much faster. So you can think of SRAM as the small, fast cache that stays close to the compute unit. Physically, it's closer. There is some kind of asymmetry here. So HBM is much larger, and SRAM is much smaller, but much faster. One way of thinking about it is, how can we design algorithms that take advantage of this asymmetric memory hierarchy? And of course, lots of folks have been thinking about this. These ideas are pretty old. I think back in the 1980s, the primary concerns were sorting. How can we sort numbers as efficiently as possible? And the motivating example was banks were trying to sort their transactions, and that needs to happen overnight so that the next day they can be ready. And so the same idea applies, which is that they have slow memory, which was hard disk, and they have fast memory, which was DRAM. And people had to design sorting algorithms that take advantage of this asymmetry. And it turns out, these same ideas can apply today, which is different kinds of memory. [00:13:00]
Alessio: In your paper, you have the pyramid of memory. Just to give people an idea, when he says smaller, it's like HBM is like 40 gig, and then SRAM is like 20 megabytes. So it's not a little smaller, it's much smaller. But the throughput on card is like 1.5 terabytes a second for HBM and like 19 terabytes a second for SRAM, which is a lot larger. How do you think that evolves? So TSMC said they hit the scaling limits for SRAM, they just cannot grow that much more. HBM keeps growing, HBM3 is going to be 2x faster than HBM2, I think the latest NVIDIA thing has HBM3. How do you think about the future of FlashAttention? Do you think HBM is going to get fast enough when maybe it's not as useful to use the SRAM? [00:13:49]
Tri: That's right. I think it comes down to physics. When you design hardware, literally SRAM stays very close to compute units. And so you don't have that much area to essentially put the transistors. And you can't shrink these things too much. So just physics, in terms of area, you don't have that much area for the SRAM. HBM is off-chip, so there is some kind of bus that essentially transfers data from HBM to the compute unit. So you have more area to essentially put these memory units. And so yeah, I think in the future SRAM probably won't get that much larger, because you don't have that much area. HBM will get larger and faster. And so I think it becomes more important to design algorithms that take advantage of this memory asymmetry. It's the same thing in CPU, where the cache is really small, the DRAM is growing larger and larger. DRAM could get to, I don't know, two terabytes, six terabytes, or something, whereas the cache stays at, I don't know, 15 megabytes or something like that. I think maybe the algorithm design becomes more and more important. There's still ways to take advantage of this, I think. So in the future, I think flash attention right now is being used. I don't know if in the next couple of years, some new architecture will come in and whatnot, but attention seems to be still important. For the next couple of years, I still expect some of these ideas to be useful. Not necessarily the exact code that's out there, but I think these ideas have kind of stood the test of time. New ideas like IO awareness from back in the 1980s, ideas like kernel fusions, tiling. These are classical ideas that have stood the test of time. So I think in the future, these ideas will become more and more important as we scale models to be larger, as we have more kinds of devices, where performance and efficiency become much, much more important. [00:15:40]
Alessio: Yeah, and we had Jonathan Frankle on the podcast, and if you go to issattentionallyouneed.com, he has an outstanding bet, and he does believe that attention will be the state of the art architecture still in a few years. Did you think flash attention would be this popular? I'm always curious on the research side, you publish a paper, and obviously you know it's great work, but sometimes it just kind of falls flat in the industry. Could you see everybody just starting to use this, or was that a surprise to you? [00:16:11]
Tri: Certainly, I didn't anticipate the level of popularity. Of course, we were extremely happy to have people using this stuff and giving us feedback and so on, and help us improve things. I think when we were writing the paper, I remember sending an email to one of my advisors, and like, hey, I'm excited about this paper, but I think the most important thing will be the artifact, which is the code. So I knew that the code will be valuable. So we kind of focus a lot on the code and make sure that the code is usable and as fast as can be. Of course, the idea, the paper presents the ideas and explain it and have experiments that validate the idea, but I knew that the artifact or the code was also pretty important. And that turned out to be the right focus, which is, you know, we put out the paper, we release the code and continue working on the code. So it's a team effort with my co-authors as well. [00:17:07]
Alessio: We mentioned Hazy Research a bunch of times on the podcast before. I would love for you to spend five minutes just talking about how does the group work? How do people get together? How do you bounce ideas off of each other? Yeah. [00:17:21]
Tri: So Hazy Research is a research group at Stanford led by one of my advisors, Chris Re. I love the people there. It was one of the best experiences I had. They've made my PhD so much more enjoyable. And I think there are a couple of ways that the group has been working pretty well. So one is, I think there's a diverse pool of people who either, you know, some of them focus on algorithms and theory, some of them focus on building systems, some of them focus on applications. And as a result, there is this flow of idea. So as an example, some of us were working on like more algorithms and theory, and then we can talk to the folks building systems and say, hey, let's try it out and let's put it in the systems and see how it is. And there you will get feedback from systems folks. They will say, hey, we implemented this, or we tried this and this is where it doesn't work, something like that. And once we put it in the systems, the application folks can use the algorithm or new methods or new models. And we again get great feedback from them because the application folks, for example, some of my good friends, they focus on medical imaging or seizure detection. And that is the problem they care about. And if your method doesn't work on the task they care about, they will tell you. Whereas I think a lot of people in machine learning, they're a little bit more flexible. So they will be like, hey, it doesn't work on seizure detection. Let's try some other task, right? But having that direct feedback of like, hey, it doesn't work there, let's figure out why. I think that that feedback allows us to do better work. And I think that kind of process of exchanging ideas, validating it in a real system so that applications folks can try it out and give you feedback. That cycle has been very, very useful. And so that's one, having a diverse group of people. The other one is, and this is something I really appreciate from advice from Chris was try to understand the fundamental, right? And he's happy letting me go off and read some textbooks and playing with things because I think a lot of research ideas come from understanding the old literature and see how it fits with the new landscape. And so if you just new archive papers every day, that's great, but you also need to read textbooks. And that's one advice I got from Chris, which is understand the fundamentals. And I think that allows us to do more impactful work. [00:19:46]
Alessio: How do you think about academia versus industry? I feel like AI / Machine Learning has been an area where up until three, four years ago, most of the cutting edge work was being done in academia. And now there's all these big industry research labs. You're obviously going to Princeton, so you're an academia believer. How should people think about where to go? Say I'm doing my master's, I have to decide between doing a PhD and going into OpenAI Anthropic. How should I decide? [00:20:15]
Tri: I think they kind of play a complementary role, in my opinion. Of course, I also was considering different paths as well. So I think right now, scaling matters a lot, especially when you talk about language models and AI and so on. Scaling matters a lot. And that means that you need compute resources and you need infrastructure and you need engineers time. And so industry tends to have an advantage when it comes to scaling things. But a lot of the ideas actually came from academia. So let's take Attention, which got popular with the Transformer in 2017. Attention actually has been around for a while. So I think the first mention was in 2014, a paper from Bernadot and others and Yoshua Bengio, which is coming from academia. A lot of ideas did come from academia. And scaling things up, of course, I think OpenAI has been great at scaling things up. That was the bet that they made after, I think, GPT-2. So they saw that scaling these things up to back then was 1.5 billion parameter seemed to give you amazing capabilities. So they really committed to that. They really committed to scaling things. And that turned out to be, it's been a pretty successful bet. I think for academia, we're still trying to figure out exactly what we're doing in this shifting landscape. And so lots of folks have been focusing on, for example, evaluation. So I know the Stanford Center for Foundation Model led by Percy, they have this benchmark called HELM, which is this holistic benchmark. So trying to figure out, okay, characterizing the landscape of different kinds of models, what people should evaluate, what people should measure, and things like that. So evaluation is one role. The other one is understanding. So this has happened historically where there's been some development in the industry and academia can play a role in explaining, understanding. They have the luxury to slow down trying to understand stuff, right? So lots of paper on understanding what's really going on, probing these models, and so on. I think I'm not as familiar with the NLP literature, but my impression is there's a lot of that going on in the NLP conferences, which is understanding what these models are doing, what capabilities they have, and so on. And the third one I could see is that the academia can take more risky bets in the sense that we can work on stuff that is quite different from industry. I think industry, my impression is you have some objective. You're trying to say, hey, for this quarter, we want to scale the model in this particular way. Next quarter, we want the model to have these capabilities. You're trying to get objectives that maybe, I don't know, 70% that will work out because it's important for the company's direction. I think for academia, the way things work is you have many, many researchers or PhD students, and they're kind of pursuing independent directions. And they have a little bit more flexibility on, hey, I'm going to try out this seemingly crazy idea and see, let's say there's a 30% chance of success or something. And however you define success, for academia, a lot of the time, success just means like, hey, we found something interesting. That could eventually go into industry through collaboration and so on. So I do see academia and industry kind of playing complementary roles. And as for someone choosing a career, I think just more and more generally, industry would be probably better in terms of compensation, in terms of probably work-life balance. But my biased perspective is that maybe academia gives you a little bit more freedom to think and understand things. So it probably comes down to personal choice. I end up choosing to be a professor next year at Princeton. But of course, I want to maintain a relationship with industry folks. I think industry folks can provide very valuable feedback to what we're doing in academia so that we understand where the field is moving because some of the directions are very much influenced by what, for example, OpenAI or Google is doing. So we want to understand where the field is moving. What are some promising applications? And try to anticipate, okay, if the field is moving like this, these applications are going to be popular. What problems will be important in two, three years? And then we try to start thinking about those problems so that hopefully in two, three years, we have some of the answers to some of these problems in two, three years. Sometimes it works out, sometimes it doesn't. But as long as we do interesting things in academia, that's the goal. [00:25:03]
Alessio: And you mentioned the eval side. So we did a Benchmarks 101 episode. And one of the things we were seeing is sometimes the benchmarks really influence the model development. Because obviously, if you don't score well on the benchmarks, you're not going to get published and you're not going to get funded. How do you think about that? How do you think that's going to change now that a lot of the applications of these models, again, is in more narrow industry use cases? Do you think the goal of the academia eval system is to be very broad and then industry can do their own evals? Or what's the relationship there? [00:25:40]
Tri: Yeah, so I think evaluation is important and often a little bit underrated. So it's not as flashy as, oh, we have a new model that can do such and such. But I think evaluation, what you don't measure, you can't make progress on, essentially. So I think industry folks, of course, they have specific use cases that their models need to do well on. And that's what they care about. Not just academia, but other groups as well. People do understand what are some of the emerging use cases. So for example, now one of the most popular use cases is Chatbot. And then I think folks from Berkeley, some of them are from Berkeley, call them MLCs. They set up this kind of Chatbot arena to essentially benchmark different models. So people do understand what are some of the emerging use cases. People do contribute to evaluation and measurement. And as a whole, I think people try to contribute to the field and move the field forward, albeit that maybe slightly different directions. But we're making progress and definitely evaluation and measurement is one of the ways you make progress. So I think going forward, there's still going to be just more models, more evaluation. We'll just have better understanding of what these models are doing and what capabilities they have. [00:26:56]
Alessio: I like that your work has been focused on not making benchmarks better, but it's like, let's just make everything faster. So it's very horizontal. So FlashAttention 2, you just released that on Monday. I read in the blog post that a lot of the work was also related to some of the NVIDIA library updates. Yeah, maybe run us through some of those changes and some of the innovations there. Yeah, for sure. [00:27:19]
Tri: So FlashAttention 2 is something I've been working on for the past couple of months. So the story is the NVIDIA CUTLASS team, they released a new version of their library, which contains all these primitives to allow you to do matrix multiply or memory loading on GPU efficiently. So it's a great library and I built on that. So they released their version 3 back in January and I got really excited and I wanted to play with that library. So as an excuse, I was just like, okay, I'm going to refactor my code and use this library. So that was kind of the start of the project. By the end, I just ended up working with the code a whole lot more and I realized that, hey, there are these inefficiencies still in Flash Attention. We could change this way or that way and make it, in the end, twice as fast. But of course, building on the library that the NVIDIA folks released. So that was kind of a really fun exercise. I was starting out, it's just an excuse for myself to play with the new library. What ended up was several months of improvement, improving Flash Attention, discovering new ideas. And in the end, we managed to make it 2x faster and now it's pretty close to probably the efficiency of things like matrix multiply, which is probably the most optimized subroutine on the planet. So we're really happy about it. The NVIDIA Cutlass team has been very supportive and hopefully in the future, we're going to collaborate more. [00:28:46]
Alessio: And since it's an NVIDIA library, can you only run this on CUDA runtimes? Or could you use this and then run it on an AMD GPU? [00:28:56]
Tri: Yeah, so it's an NVIDIA library. So right now, the code we release runs on NVIDIA GPUs, which is what most people are using to train models. Of course, there are emerging other hardware as well. So the AMD folks did implement a version of Flash Attention, I think last year as well, and that's also available. I think there's some implementation on CPU as well. For example, there's this library, ggml, where they implemented the same idea running on Mac and CPU. So I think that kind of broadly, the idea would apply. The current implementation ended up using NVIDIA's library or primitives, but I expect these ideas to be broadly applicable to different hardware. I think the main idea is you have asymmetry in memory hierarchy, which tends to be everywhere in a lot of accelerators. [00:29:46]
Alessio: Yeah, it kind of reminds me of Sara Hooker's post, like the hardware lottery. There could be all these things that are much better, like architectures that are better, but they're not better on NVIDIA. So we're never going to know if they're actually improved. How does that play into some of the research that you all do too? [00:30:04]
Tri: Yeah, so absolutely. Yeah, I think Sara Hooker, she wrote this piece on hardware lottery, and I think she captured really well of what a lot of people have been thinking about this. And I certainly think about hardware lottery quite a bit, given that I do some of the work that's kind of really low level at the level of, hey, we're optimizing for GPUs or NVIDIA GPUs and optimizing for attention itself. And at the same time, I also work on algorithms and methods and transformer alternatives. And we do see this effect in play, not just hardware lottery, but also kind of software framework lottery. You know, attention has been popular for six years now. And so many kind of engineer hours has been spent on making it as easy and efficient as possible to run transformer, right? And there's libraries to do all kinds of tensor parallel, pipeline parallel, if you use transformer. Let's say someone else developed alternatives, or let's just take recurrent neural nets, like LSTM, GRU. If we want to do that and run that efficiently on current hardware with current software framework, that's quite a bit harder. So in some sense, there is this feedback loop where somehow the model architectures that take advantage of hardware become popular. And the hardware will also kind of evolve to optimize a little bit for that kind of architecture and software framework will also evolve to optimize for that particular architecture. Right now, transformer is the dominant architecture. So yeah, I'm not sure if there is a good way out of this. Of course, there's a lot of development. Things like, I think compilers will play a role because compilers allow you to maybe still be much more efficient across different kinds of hardware because essentially you write the same code and compiler will be able to make it run efficiently different kinds of hardware. So for example, there's this language Mojo, they're compiler experts, right? And their bet is AI models will be running on different kinds of devices. So let's make sure that we have really good compilers with a good language that then the compiler can do a good job optimizing for all kinds of devices. So that's maybe one way that you can get out of this cycle. But yeah, I'm not sure of a good way. In my own research, I have to think about both the algorithm new model and how it maps to hardware. So there are crazy ideas that seem really good, but will be really, really difficult to run efficiently. And so as a result, for example, we can't really scale some of the architectures up simply because they're not hardware friendly. I have to think about both sides when I'm working on new models. [00:32:50]
Alessio: Yeah. Have you spent any time looking at some of the new kind of like AI chips companies, so to speak, like the Cerebras of the world? Like one of their innovations is co-locating everything on the chip. So you remove some of this memory bandwidth issue. How do you think about that? [00:33:07]
Tri: Yeah, I think that's an interesting bet. I think Tesla also has this Dojo supercomputer where they try to have essentially as fast on-chip memory as possible and removing some of these data transfer back and forth. I think that's a promising direction. The issues I could see, you know, I'm definitely not a hardware expert. One issue is the on-chip memory tends to be really expensive to manufacture, much more expensive per gigabyte compared to off-chip memory. So I talked to, you know, some of my friends at Cerebros and, you know, they have their own stack and compiler and so on, and they can make it work. The other kind of obstacle is, again, with compiler and software framework and so on. For example, if you can run PyTorch on this stuff, lots of people will be using it. But supporting all the operations in PyTorch will take a long time to implement. Of course, people are working on this. So I think, yeah, we kind of need these different bets on the hardware side as well. Hardware has, my understanding is, has a kind of a longer time scale. So you need to design hardware, you need to manufacture it, you know, maybe on the order of three to five years or something like that. So people are taking different bets, but the AI landscape is changing so fast that it's hard to predict, okay, what kind of models will be dominant in, let's say, three or five years. Or thinking back five years ago, would we have known that Transformer would have been the dominant architecture? Maybe, maybe not, right? And so different people will make different bets on the hardware side. [00:34:39]
Alessio: Does the pace of the industry and the research also influence the PhD research itself? For example, in your case, you're working on improving attention. It probably took you quite a while to write the paper and everything, but in the meantime, you could have had a new model architecture come out and then it's like nobody cares about attention anymore. How do people balance that? [00:35:02]
Tri: Yeah, so I think it's tough. It's definitely tough for PhD students, for researchers. Given that the field is moving really, really fast, I think it comes down to understanding fundamental. Because that's essentially, for example, what the PhD allows you to do. It's been a couple of years understanding the fundamentals. So for example, when I started my PhD, I was working on understanding matrix vector multiply, which has been a concept that's been around for hundreds of years. We were trying to characterize what kind of matrices would have theoretically fast multiplication algorithm. That seems to have nothing to do with AI or anything. But I think that was a time when I developed mathematical maturity and research taste and research skill. The research topic at that point didn't have to be super trendy or anything, as long as I'm developing skills as a researcher, I'm making progress. And eventually, I've gotten quite a bit better in terms of research skills. And that allows, for example, PhD students later in their career to quickly develop solutions to whatever problems they're facing. So I think that's just the natural arc of how you're being trained as a researcher. For a lot of PhD students, I think given the pace is so fast, maybe it's harder to justify spending a lot of time on the fundamental. And it's tough. What is this kind of explore, exploit kind of dilemma? And I don't think there's a universal answer. So I personally spend some time doing this kind of exploration, reading random textbooks or lecture notes. And I spend some time keeping up with the latest architecture or methods and so on. I don't know if there's a right balance. It varies from person to person. But if you only spend 100% on one, either you only do exploration or only do exploitation, I think it probably won't work in the long term. It's probably going to have to be a mix and you have to just experiment and kind of be introspective and say, hey, I tried this kind of mixture of, I don't know, one exploration paper and one exploitation paper. How did that work out for me? Should I, you know, having conversation with, for example, my advisor about like, hey, did that work out? You know, should I shift? I focus more on one or the other. I think quickly adjusting and focusing on the process. I think that's probably the right way. I don't have like a specific recommendation that, hey, you focus, I don't know, 60% on lecture notes and 40% on archive papers or anything like that. [00:37:35]
Alessio: Let's talk about some Transformer alternatives. You know, say Jonathan Franco loses his bet and Transformer is not the state of the art architecture. What are some of the candidates to take over? [00:37:49]
Tri: Yeah, so this bet is quite fun. So my understanding is this bet between Jonathan Franco and Sasha Rush, right? I've talked to Sasha a bunch and I think he recently gave an excellent tutorial on Transformer alternatives as well. So I would recommend that. So just to quickly recap, I think there's been quite a bit of development more recently about Transformer alternatives. So architectures that are not Transformer, right? And the question is, can they do well on, for example, language modeling, which is kind of the application that a lot of people care about these days. So there are methods based on state space methods that came out in 2021 from Albert Gu and Curran and Chris Re that presumably could do much better in terms of capturing long range information while not scaling quadratically. They scale sub-quadratically in terms of sequence length. So potentially you could have a much more efficient architecture when sequence length gets really long. The other ones have been focusing more on recurrent neural nets, which is, again, an old idea, but adapting to the new landscape. So things like RWKV, I've also personally worked in this space as well. So there's been some promising results. So there's been some results here and there that show that, hey, these alternatives, either RNN or state space methods, can match the performance of Transformer on language modeling. So that's really exciting. And we're starting to understand on the academic research side, we want to understand, do we really need attention? I think that's a valuable kind of intellectual thing to understand. And maybe we do, maybe we don't. If we want to know, we need to spend serious effort on trying the alternatives. And there's been folks pushing on this direction. I think RWKV scale up to, they have a model at 14 billion that seems pretty competitive with Transformer. So that's really exciting. That's kind of an intellectual thing. We want to figure out if attention is necessary. So that's one motivation. The other motivation is Transformer Alternative could have an advantage in practice in some of the use cases. So one use case is really long sequences. The other is really high throughput of generation. So for really long sequences, when you train with Transformer, with flash attention and so on, the computation is still quadratic in the sequence length. So if your sequence length is on the order of, I don't know, 16K, 32K, 100K or something, which some of these models have sequence length 100K, then you do get significantly slower in terms of training, also in terms of inference. So maybe these alternative architectures could scale better in terms of sequence length. I haven't seen actual validation on this. Let's say an RNN model release with context length, I don't know, 100K or something. I haven't really seen that. But the hope could be that as we scale to long sequences, these alternative architectures could be more well-suited. Not just text, but things like high resolution images, audio, video, and so on, which are emerging applications. So that's one, long sequences. Number two is a high throughput generation, where I can imagine scenarios where the application isn't like an interactive chatbot, but let's say a company wants to batch as many requests as possible on their server, or they're doing offline processing, they're generating stuff based on their internal documents, that you need to process in batch. And the issue with Transformer is that during generation, it essentially needs to keep around all the previous history. It's called the KV cache. And that could take a significant amount of memory, so you can't really batch too much because you run out of memory. I am personally bullish on RNNs. I think RNNs, they essentially summarize the past into a state vector that has fixed size, so the size doesn't grow with the history. So that means that you don't need as much memory to keep around all the previous tokens. And as a result, I think you can scale to much higher batch sizes. And as a result, you can make much more efficient use of the GPUs or the accelerator, and you could have much higher generation throughput. Now, this, I don't think, has been validated at scale. So as a researcher, I'm bullish on this stuff because I think in the next couple of years, these are use cases where these alternatives could have an advantage. We'll just kind of have to wait and see to see if these things will happen. I am personally bullish on this stuff. At the same time, I also spend a bunch of time making attention as fast as possible. So maybe hatching and playing both sides. Ultimately, we want to understand, as researchers, we want to understand what works, why do the models have these capabilities? And one way is, let's push attention to be as efficient as possible. On the other hand, let's push other alternatives to be as efficient at scale, as big as possible, and so that we can kind of compare them and understand. Yeah, awesome. [00:43:01]
Alessio: And I think as long as all of this work happens and open, it's a net positive for everybody to explore all the paths. Yeah, let's talk about open-source AI. Obviously, together, when Red Pajama came out, which was an open clone of the LLAMA1 pre-training dataset, it was a big thing in the industry. LLAMA2 came out on Tuesday, I forget. And this week, there's been a lot of things going on, which they call open-source, but it's not really open-source. Actually, we wrote a post about it that was on the front page of Hacker News before this podcast, so I was frantically responding. How do you think about what open-source AI really is? In my mind, in open-source software, we have different levels of open. So there's free software, that's like the GPL license. There's open-source, which is Apache, MIT. And then there's kind of restricted open-source, which is the SSPL and some of these other licenses. In AI, you have the open models. So Red Pajama is an open model because you have the pre-training dataset, you have the training runs and everything. And then there's obviously RandomLens that doesn't make it one-to-one if you retrain it. Then you have the open-weights model that's kind of like StableLM, where the weights are open, but the dataset is not open. And then you have LLAMA2, which is the dataset is not open, the weights are restricted. It's kind of like not really open-source, but open enough. I think it's net positive because it's like $3 million of flops donated to the public. [00:44:32]
Tri: How do you think about that? [00:44:34]
Alessio: And also, as you work together, what is your philosophy with open-source AI? Right, right. [00:44:40]
Tri: Yeah, I think that's a great question. And I think about it on maybe more practical terms. So of course, Meta has done an amazing job training LLAMA1, LLAMA2. And for LLAMA2, they make it much less restrictive compared to LLAMA1. Now you can use it for businesses, unless you are a monthly active user or something like that. I think just this change will have a very significant impact in the kind of landscape of open-source AI, where now lots of businesses, lots of companies will be using, I expect will be using things like LLAMA2. They will fine-tune on their own dataset. They will be serving variants or derivatives of LLAMA2. Whereas before, with LLAMA1, it was also a really good model, but your business companies weren't allowed to do that. So I think on a more practical term, it's kind of shifting the balance between a closed-source model like OpenAI and Anthropic and Google, where you're making API calls, right? And maybe you don't understand as much of what the model is doing, how the model is changing, and so on. Versus now, we have a model with open weight that is pretty competitive from what I've seen in terms of benchmarks, pretty competitive with GPT 3.5, right? And if you fine-tune it on your own data, maybe it's more well-suited for your own data. And I do see that's going to shift the balance of it. More and more folks are going to be using, let's say, derivatives of LLAMA2. More and more folks are going to fine-tune and serve their own model instead of calling an API. So that shifting of balance is important because in one way, we don't want just a concentration of decision-making power in the hands of a few companies. So I think that's a really positive development from Meta. Of course, training the model takes a couple of millions of dollars, but engineers have and I'm sure they spend tons of time trying many, many different things. So the actual cost is probably way more than that. And they make the weights available and they allow probably a lot of companies are going to be using this. So I think that's a really positive development. And we've also seen amazing progress on the open source community where they would take these models and they either fine-tune on different kinds of data sets or even make changes to the model. So as an example, I think for LLAMA1, the context lane was limited to 2K. Like a bunch of folks figured out some really simple methods to scale up to like 8K. [00:47:12]
Alessio: Like the RoPE. [00:47:13]
Tri: Yes. I think the open source community is very creative, right? And lots of people. LLAMA2 will, again, kind of accelerate this where more people will try it out. More people will make tweaks to it and make a contribution and then so on. So overall, I think I see that as still a very positive development for the field. And there's been lots of libraries that will allow you to host or fine-tune these models, like even with quantization and so on. Just a couple of hours after LLAMA2 was released, tons of companies announcing that, hey, it's on our API or hosting and so on and together did the same. So it's a very fast-paced development and just kind of a model with available weights that businesses are allowed to use. I think that alone is already a very positive development. At the same time, yeah, we can do much better in terms of releasing data sets. Data sets tend to be... Somehow people are not incentivized to release data sets. So philosophically, yeah, you want to be as open as possible. But on a practical term, I think it's a little bit harder for companies to release data sets. Legal issues. The data sets released tend to be not as eye-catchy as the model release. So maybe people are less incentivized to do that. We've seen quite a few companies releasing data sets together. Released a red pajama data set. I think Cerebus then worked on that and deduplicate and clean it up and release slim pajama and so on. So we're also seeing positive development on that front, kind of on the pre-training data set. So I do expect that to continue. And then on the fine-tuning data set or instruction tuning data set, I think we now have quite a few open data sets on instruction tuning and fine-tuning. But these companies do pay for human labelers to annotate these instruction tuning data set. And that is expensive. And maybe they will see that as their competitive advantage. And so it's harder to incentivize these companies to release these data sets. So I think on a practical term, we're still going to make a lot of progress on open source AI, on both the model development, on both model hosting, on pre-training data set and fine-tuning data set. Right now, maybe we don't have the perfect open source model since all the data sets are available. Maybe we don't have such a thing yet, but we've seen very fast development on the open source side. I think just maybe this time last year, there weren't as many models that are competitive with, let's say, ChatGPT. [00:49:43]
Alessio: Yeah, I think the open data sets have so much more impact than open models. If you think about Elusive and the work that they've done, GPT-J was great, and the Pythia models are great, but the Pyle and the Stack, everybody uses them. So hopefully we get more people to contribute time to work on data sets instead of doing the 100th open model that performs worse than all the other ones, but they want to say they released the model. [00:50:14]
Tri: Yeah, maybe the question is, how do we figure out an incentive structure so that companies are willing to release open data sets? And for example, it could be like, I think some of the organizations are now doing this where they are asking volunteers to annotate and so on. And maybe the Wikipedia model of data set, especially for instruction tuning, could be interesting where people actually volunteer their time and instead of editing Wikipedia, add annotation. And somehow they acknowledge and feel incentivized to do so. Hopefully we get to that kind of level of, in terms of data, it would be kind of like Wikipedia. And in terms of model development, it's kind of like Linux where people are contributing patches and improving the model in some way. I don't know exactly how that's going to happen, but based on history, I think there is a way to get there. [00:51:05]
Alessio: Yeah, I think the Dolly-15K data set is a good example of a company saying, let's do this smaller thing, just make sure we make it open. We had Mike Conover from Databricks on the podcast, and he was like, people just bought into it and leadership was bought into it. You have companies out there with 200,000, 300,000 employees. It's like, just put some of them to label some data. It's going to be helpful. So I'm curious to see how that evolves. What made you decide to join Together? [00:51:35]
Tri: For Together, the focus has been focusing a lot on open source model. And I think that aligns quite well with what I care about, of course. I also know a bunch of people there that I know and trust, and I'm excited to work with them. Philosophically, the way they've been really open with data set and model release, I like that a lot. Personally, for the stuff, for example, the research that I've developed, like we also try to make code available, free to use and modify and so on, contributing to the community. That has given us really valuable feedback from the community and improving our work. So philosophically, I like the way Together has been focusing on open source model. And the nice thing is we're also going to be at the forefront of research and the kind of research areas that I'm really excited about, things like efficient training and inference, aligns quite well with what the company is doing. We'll try our best to make things open and available to everyone. Yeah, but it's going to be fun being at the company, leading a team, doing research on the topic that I really care about, and hopefully we'll make things open to benefit the community. [00:52:45]
Alessio: Awesome. Let's jump into the lightning round. Usually, I have two questions. So one is on acceleration, one on exploration, and then a takeaway. So the first one is, what's something that already happened in AI machine learning that you thought would take much longer than it has? [00:53:01]
Tri: I think understanding jokes. I didn't expect that to happen, but it turns out scaling model up and training lots of data, the model can now understand jokes. Maybe it's a small thing, but that was amazing to me. [00:53:16]
Alessio: What about the exploration side? What are some of the most interesting unsolved questions in the space? [00:53:22]
Tri: I would say reasoning in the broad term. We don't really know how these models do. Essentially, they do something that looks like reasoning. We don't know how they're doing it. We have some ideas. And in the future, I think we will need to design architecture that explicitly has some kind of reasoning module in it if we want to have much more capable models. [00:53:43]
Alessio: What's one message you want everyone to remember today? [00:53:47]
Tri: I would say try to understand both the algorithm and the systems that these algorithms run on. I think at the intersection of machine learning system has been really exciting, and there's been a lot of amazing results at this intersection. And then when you scale models to large scale, both the machine learning side and the system side really matter. [00:54:06]
Alessio: Awesome. Well, thank you so much for coming on 3. [00:54:09]
Tri: This was great. Yeah, this has been really fun. [00:54:11]
