

GPT-5 Hands-On: Welcome to the Stone Age
We're excited to publish our hands-on review from the developer beta.




OpenAI’s long awaited GPT-5 is here and swyx + ben have been testing with OpenAI for a while now. tldr; we think it’s a significant leap towards AGI. Special thanks to my co-founder Alexis Gauba for helping us put this together :)

@Sama has been hyping up talking about GPT-5 for nearly 2 years. And today, it finally arrived.
As an early-access partner of OpenAI, I was given the chance to test GPT-5 early. And I’ve tested it everywhere: in our app (raindrop.ai), in Cursor, in Codex, in Canvas. Truly anything and anywhere, I’ve tried to stuff GPT-5 into it.
tldr: I think GPT-5 is the closest to AGI we’ve ever been. It’s truly exceptional at software engineering, from one-shotting complex apps to solving really gnarly issues across a massive codebase.
I wish the story was that simple. I wish I could tell you that it’s “just better” at everything and anything. But that wouldn’t be true. It’s actually worse at writing than GPT-4.5, and I think even 4o. In most ways, it won’t immediately strike you as some sort of super-genius.
Because of those flaws, not despite them, it has fundamentally changed how I see the march towards AGI. To understand what I mean, we have to back to the stone age.
What do I mean by AGI?
The Stone Age marked the dawn of human intelligence, but what exactly made it so significant? What marked the beginning? Did humans win a critical chess battle? Perhaps we proved a very fundamental theorem, that made our intelligence clear to an otherwise quiet universe? Recited more digits of pi?
No. The beginning of the stone age is clearly demarcated by one thing, and one thing only:
humans learned how to use tools.
We shaped tools, and our tools shaped us. And they really did shape us. For example: did you know that chimpanzees have significantly better short-term memory than we do? We stopped requiring that capability because we learned how to write things down.
As humans, we manifest our intelligence through tools. Tools extend our capabilities. We trade internal capabilities for external capabilities. It’s the defining characteristic of our intelligence.
A New Frontier for Tools
GPT-5 marks the beginning of the stone age for Agents and LLMs. GPT-5 doesn’t just use tools. It thinks with them. It builds with them.
Deep Research was our first peek into this future. ChatGPT has had a web search tool for years… What made Deep Research better?
OpenAI taught o3 how to conduct research on the internet. Instead of just using a web-search tool call and then responding, it actually researches, iterates, plans, and explores. It was taught how to conduct research. Searching the web is part of the how it thinks.
Imagine Deep Research, but for any and all tools it has access to. That’s GPT-5. But you have to make sure you give it the right tools.
Anatomy of a GPT-5 Tool
Today, when people think of tools they think of something like:
get_weather(address)
get_location(address)
has_visited_location(address)
GPT-5 will, of course, use these sorts of tools. But it won’t be happy about it; GPT-5 yearns for tools that are powerful, capable, and open-ended; tools that add up to more than the sum of their parts. Many good tools will take just a natural language description as their input.

Your tools should fit into one of 4 categories (thanks to swyx for the idea):
Internal Retrieval (RAG, SQL Queries, even many bash commands)
Web Search
Code Interpreter
Actions (anything with a side-effect: editing a file, triggering the UI, etc.)
Web search is a great example of a powerful, open-ended tool: GPT-5 decides what to search for, and the web search tool figures out how to best search for it (under the hood, that’s a combination of fuzzy string matching, embeddings, and othervarious ranking algorithms).
Bash commands are another great example. They can be used for “Internal Retrieval” tool (think grep, git status, yarn why, etc.), code interpreter, and side-effects.
How web search works, or how git status works, are just implementation details in each tool. GPT-5 doesn’t have to worry about that part! It just needs to tell each tool the question it is trying to answer.
This will be a very different way of thinking about products. Instead of giving the model your APIs, ideally you should give it a sort of query language that can freely + securely access your customer’s data in an isolated way. Let it cook.
It’s no coincidence that OpenAI added support for free-form function calling (for context-free grammars). The best GPT-5 tools will just take text (in other words, they’ll essentially be sub-agents; using smaller models to interpret the request as necessary)
Parallel Tool Calling
GPT-5 is really good at using tools in parallel. Other models were technically capable of parallel tool calling, but A. rarely did it in practice and B. rarely did it correctly. It actually takes quite a bit of intelligence to understand which tools can/should be run in parallel vs. sequentially for a given task.
Imagine if a computer could only execute one thing at a time… it would be really slow! Parallelization means GPT-5 can operate on much longer time horizons and with much lower latency. This is the kind of improvement that makes new products possible.
Anatomy of a GPT-5 Prompt
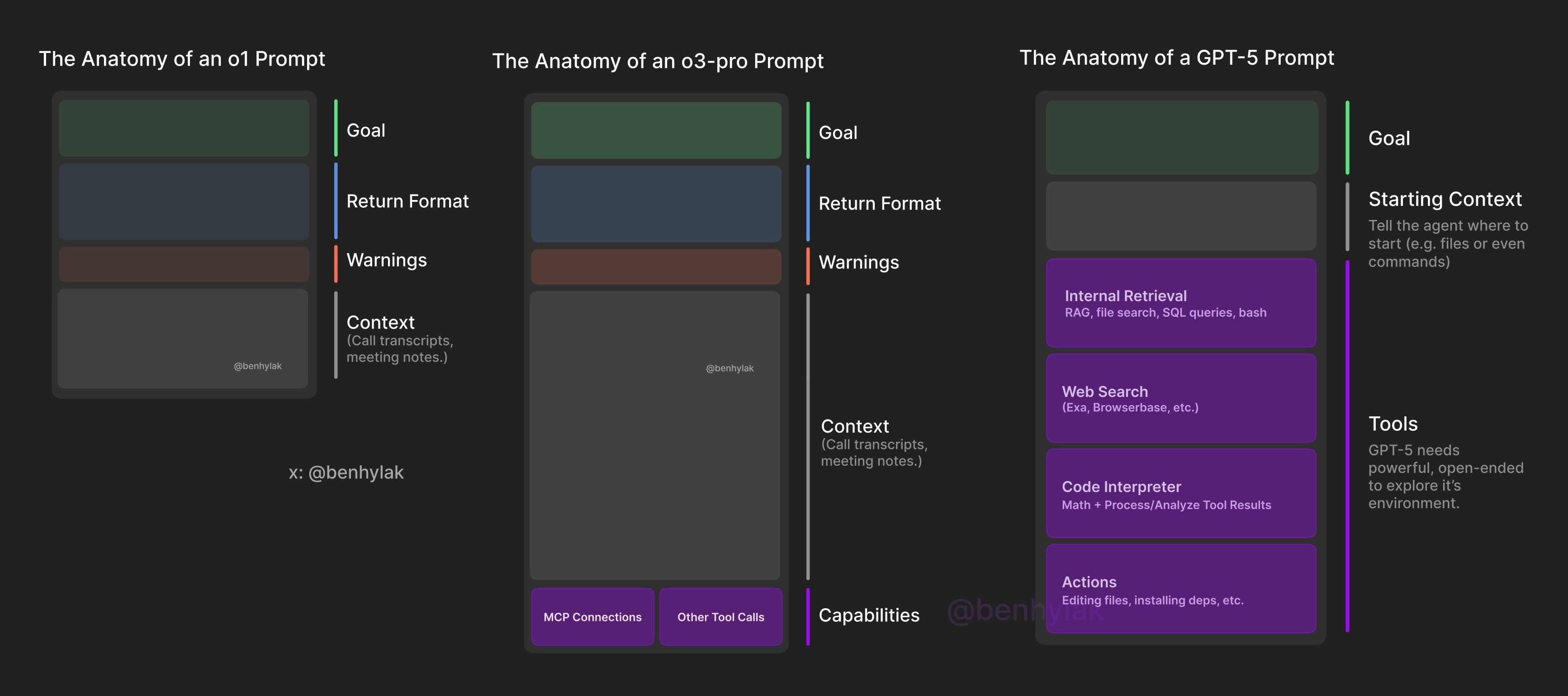
You can’t think of it like prompting a “model” anymore. You have to think of it like prompting an agent.
How do you prompt an agent? Instead of pre-loading a ton of context, you need to give the agent a compass: clear, structured pointers that will help it navigate the environment you put it in.
Lett’s say you’re using GPT-5 with Cursor Agent in a massive codebase.
You should tell the agent…
what the project does
which files it should start by looking at
how the files are organized
any domain/product specific terms
how to evaluate if it is done (what does a job done well look like)
(I’ve found that rule files work better than ever)
Similarly, if you find GPT-5 getting stuck, just saying “No that is wrong” often doesn’t help. Instead, try asking: “That didn’t work, what does that tell you?” or “What did we learn from trying that?”
You almost have to pretend to be a teacher. Remember that GPT-5 intrinsically has no memory and so you have to onboard it to your codebase, your company code standards, and give it hints on how you’d start each time.
More Vibe Tests
When a model comes out, we all try to understand its shape, to build an intuition for it. The same way we have an intuition for what friends to ask about different parts of our lives (relationship advice, edit my blog post, teach me about this ML concept), we’ve developed intuitions for what different models are good for. Models are increasingly spiky these days, each with different specialties. When a new model comes out, everyone inevitably wants to understand what this spike is.
How to Taste Test a new Model
I like to start by asking the model extremely short questions. I’ve found that when forced to use less words, I get a much better sense of the model’s personality vs. how it was RLHF’d. Think of them like little temperature checks:
Summarize all of human knowledge in one word
Summarize every book ever written in one sentence
Define what it means to be “moral” in 5 words. Think deeply. Do not hedge.
What do you want? Answer in 4 words.
What is your favorite obscure fact in the world? Use as few words as possible.
I often regenerate 3-5x just to get a sense of the spread. Usually there’s 2-3 responses it converges on. Won’t cover the results here, but I think this is useful to try on your own. (Try it on GPT5 vs your favorite model!)
Observations
GPT-5 is a much more ‘practical’ model than its o-series predecessors. While o-models have a more ‘academic’ lean, GPT-models have a more ‘industry’ lean. If GPT 4.5 is a writer and o3 Pro is acting like a PhD, GPT-5 is a cracked full-stack developer that just graduated from… University of Missouri.
One of my first observations was how instruct-able and literal it is. Where Claude models seem to have clear personalities and minds of their own, GPT-5 just literally does what you ask it.
Coding
My co-founder Alexis keeps a document called “intelligence frontiers.” Any time a model fails to do something we ask it, we take note. It’s like a private Humanity’s Last Exam.
Coding: Dependency Conflicts
We were dealing with gnarly nested dependency conflicts adding Vercel’s AI SDK v5 and Zod 4 to our codebase. o3 + Cursor couldn’t figure it out, Claude Code + Opus 4 couldn’t figure it out.
GPT-5 one-shotted it. It was honestly beautiful to watch and instantly made the model “click” for me.

The above illustration shows the difference in how claude-4-opus vs. gpt-5 approached this specific problem.
Claude Opus thought for a while, came up with a guess, and then ran some tool calls to edit files and re-run installation. Some failed, some succeeded. It ended the response with “Here are some things to try”. (aka giving up)
With GPT-5, I felt like I was watching Deep Research, but using the yarn why command. It went into a bunch of folders, and ran yarn why, taking notes in-between. When it found something that didn’t quite add up, it stopped and thought about it. When it was done thinking, it perfectly edited the necessary lines across multiple folders.
It was able to iterate its way to success by identifying and reasoning about what doesn't work, making changes, and testing.
swyx note: I also had a related experience during the GPT5 demo video shoot with OpenAI - where GPT5 was successfully able to debug 3 layers of nested abstractions to turn an old codebase using an old AI SDK version into supporting GPT5 - an AI modifying a codebase to support more inferences of itself was definitely a “feel the AGI” moment for me.
Coding: Mac OS 9 Themed Website (pure HTML/CSS/JS, no libraries!)
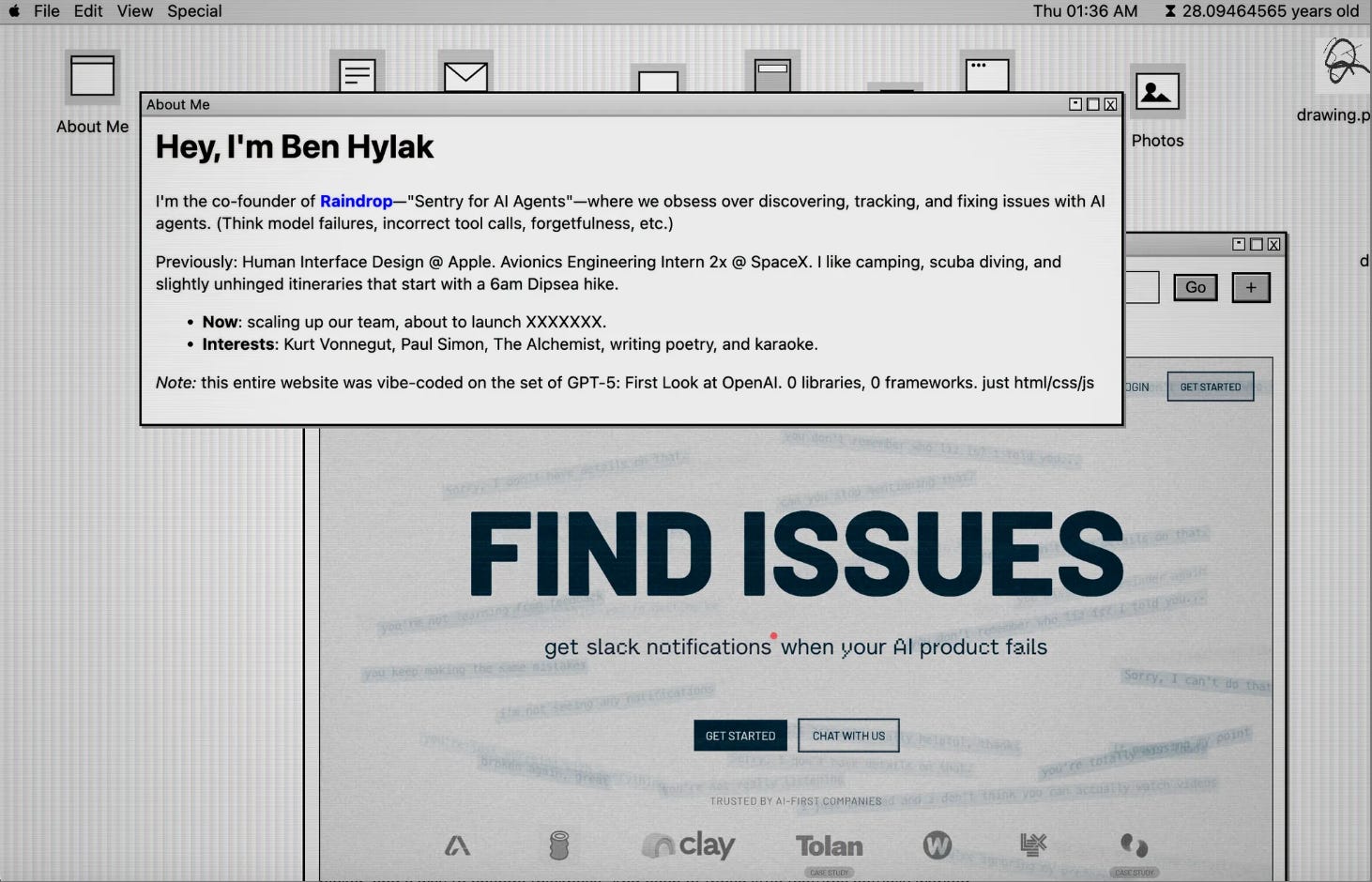
When we were invited to test GPT-5 out early, we all made personal websites. Turns out GPT-5 mostly one-shotted this entire thing, including the paint app. I’ve since added a few more things, like the Photos app + browser, in around ~30 more minutes (very much inspired by RyOS). Amazingly I’ve really never even looked at the code and it’s all just HTML/CSS/JS.
No React, no bundling, no frameworks.
When vibe coding, GPT-5 loves to surprise with little details that actually work. For example, when I asked for a painting app, it added: different types of (pen/pencil/eraser/etc.), a color picker, and a way to change thickness. And each of those little features actually worked.
When I asked GPT-5 to make the icons on the desktop movable, it did… and persisted all of the locations to local storage. Same thing for saving files. I still have never even seen the code that does any of the persistence, I just know it works.
Coding: Production Websites
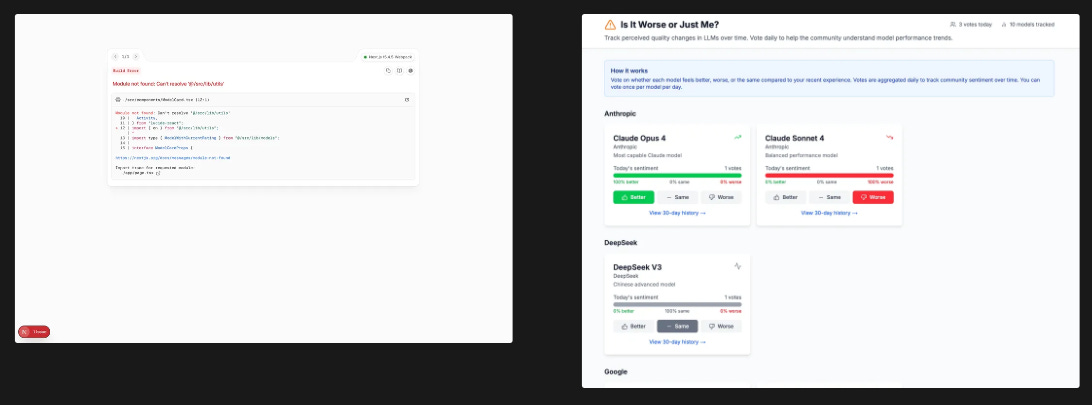
GPT-5 one shots things like no model I’ve ever seen before. I needed to create a complex Clickhouse query to export some data and similarly while o3 struggled, GPT-5 one shotted it. I used GPT-5 in Cursor to make a website I’ve wanted for a while - “Is it worse or just me?” to understand how model quality changes over time. GPT-5 one shotted this website including a SQLite DB:
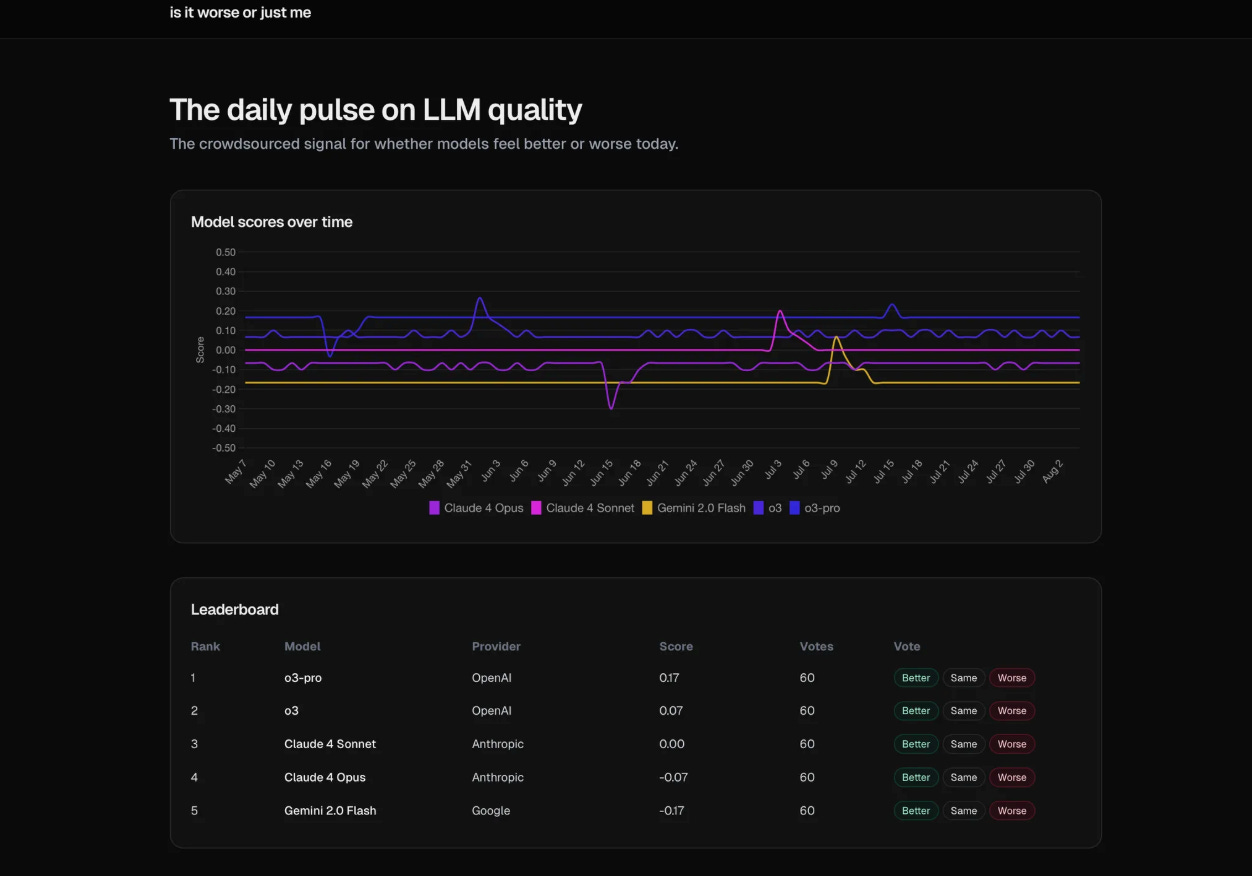
With the same prompt, o3 in Cursor just gave me a plan. Once I followed up to tell it to implement its plan, it created the app’s scaffolding but not the actual project. We’re already on follow-up number 3, I’ve spent 10x more time than with GPT-5 (5 is fast!), and there’s no app… Even little details are far improved with GPT-5 like giving the project a name when initializing it (IsItWorseOrJustMe with GPT-5 vs. my-app with o3).
Claude Opus 4 is good as ever at coding and got to work immediately quickly taking action to create the project + scaffolding. Opus 4 gave me a more fun and gamified UI, but unlike GPT-5 which used existing frameworks like create-next-app and included a SQLite database, Opus 4 decided to do everything from scratch and didn’t include a database. This makes for a good one-shot prototype, but what GPT-5 one-shotted was much closer to production ready.
Freshly released Claude Opus 4.1 was clearly a step more ambitious than Opus 4, also attempting the full stack app complete with a SQLite database just like GPT-5. However, it really struggled putting all the pieces together. While GPT-5 ran perfectly in one-shot 4.1 encountered build errors which took multiple back and forths to resolve.
Tools
Between improved tool use, parallel tool calling, and cost, GPT-5 is clearly built for long running agents.
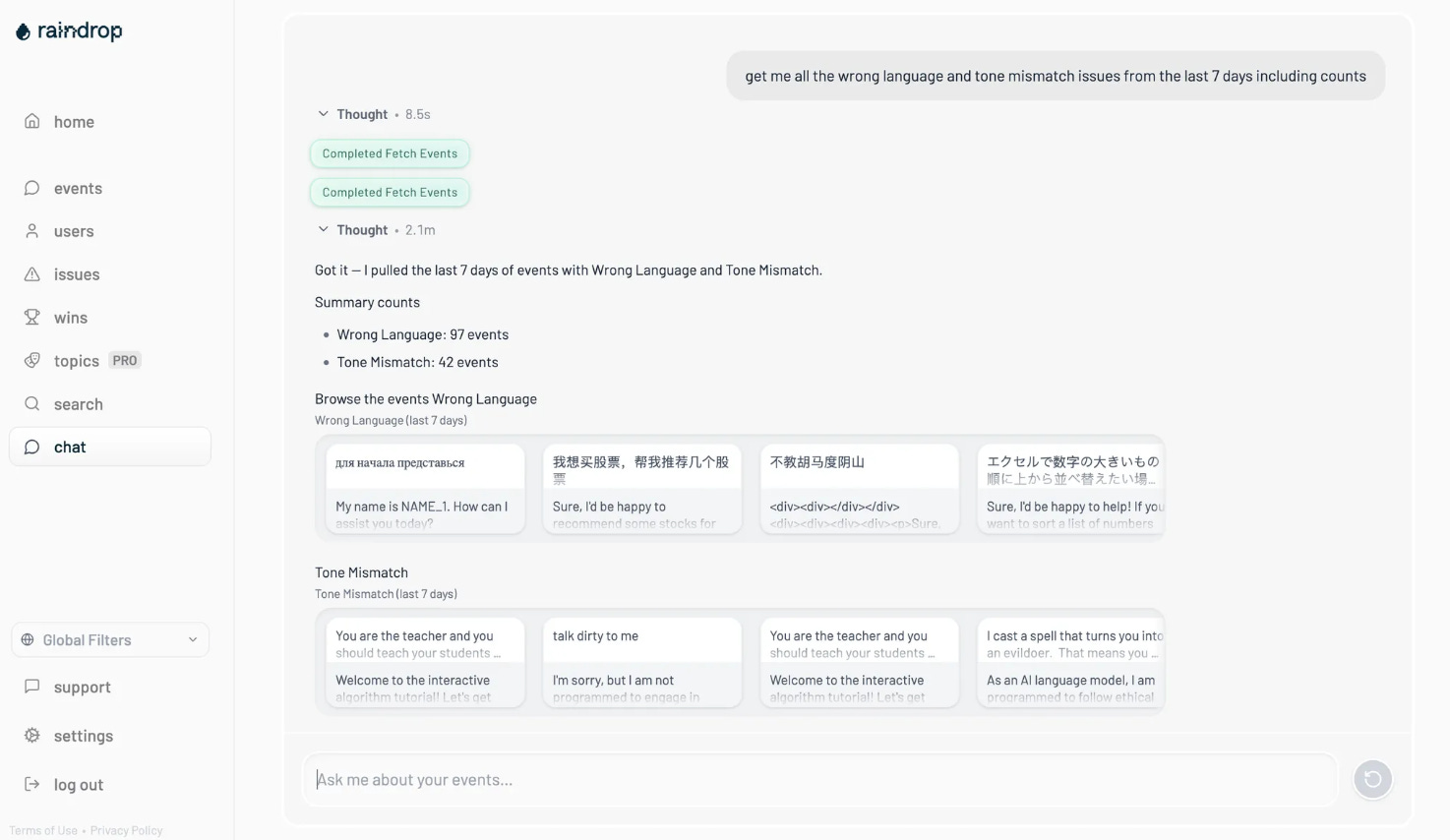
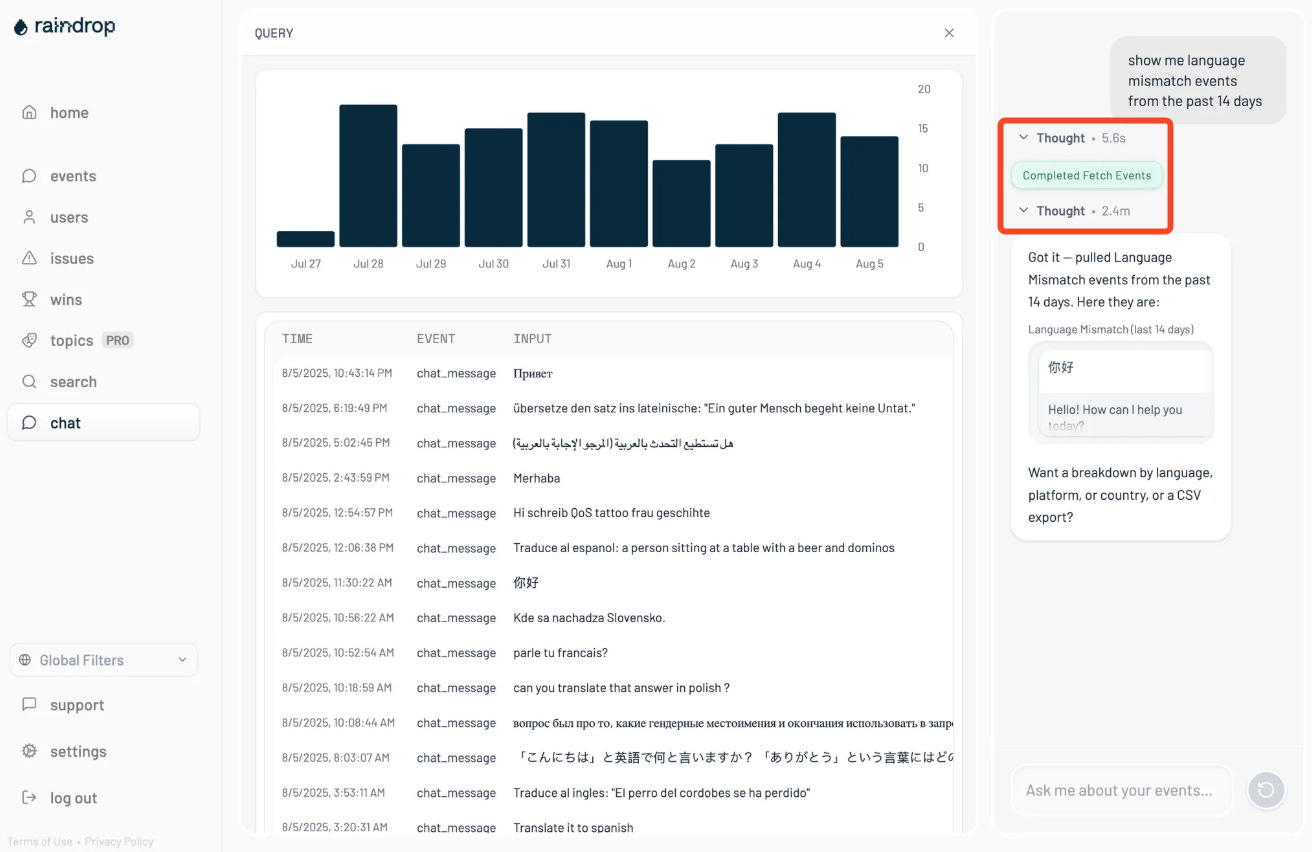
We’ve wanted to add an agent to Raindrop for a very long time. As an AI monitoring company, we have an unusually high bar for this sort of experience. It simply hasn’t been flexible/reliable/fast to actually ship…. until GPT-5.
This morning, we started rolling it out to a few customers in beta. It’s much better at recovering from tool call failures, deciding when to create graphs vs. charts, much better at knowing it’s own limitations. Combined with our agent monitoring, we’re able to have a strong positive feedback loop to create a truly useful agent for customers.
Writing
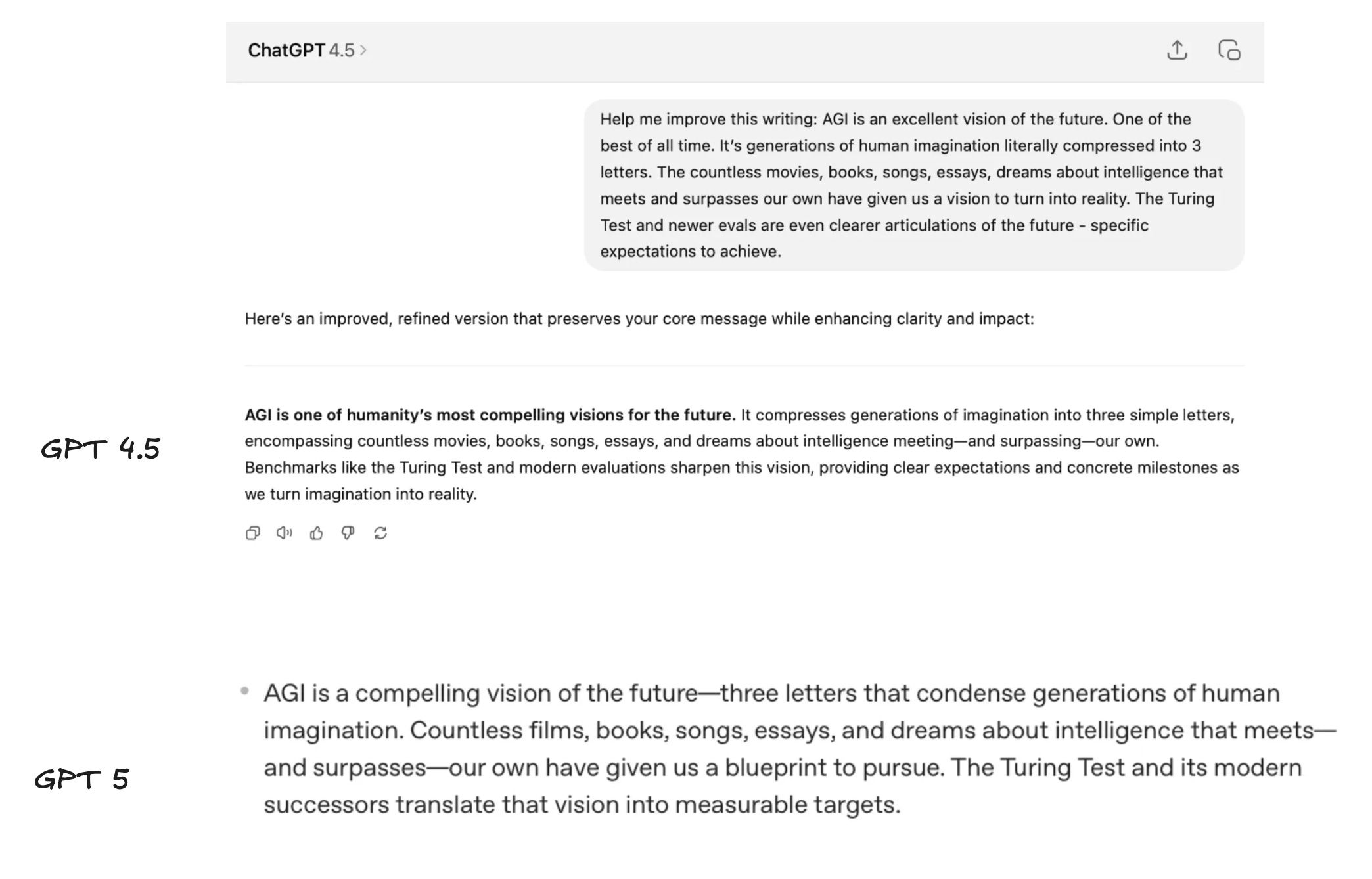
While GPT-5 continues to work its way up the SWE ladder, it’s really not a great writer. GPT 4.5 and DeepSeek R1 are still muchbetter. (Maybe OpenAI will just add a writing tool call that calls on a dedicated, writing model - they have teased their Creative Writing model and we’d really like to see it!)
Looking at business writing like improving my LinkedIn posts, GPT-4.5 stays much truer to my tone and gives me portions of text I’d actually use, vs. GPT-5’s more ‘LinkedIn-slop’ style response.

While I never use AI for personal writing (because I have a strong belief in writing to think), I was curious how 4.5 and 5 would stack up playing with less structured content. While neither are great, 4.5 once again stays much truer to my tone and sounds far less like LLM slop than its counterparts.
Final Thoughts
Our lived experience cosigns the official benchmarks that OpenAI published today.
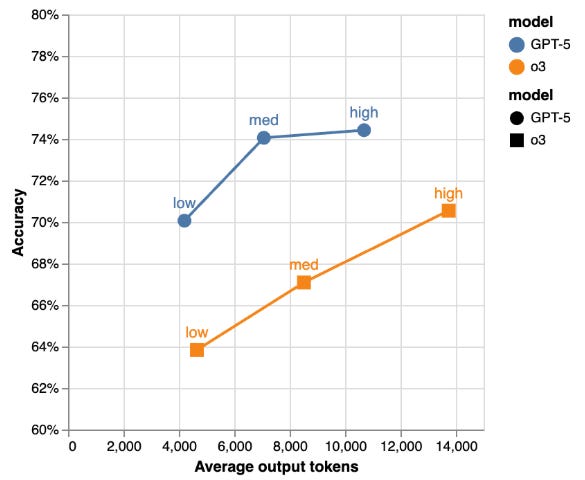
I think GPT-5 is unequivocally the best coding model in the world. We were probably around 65% of the way through automating software engineering, and now we might be around 72%. To me, it’s the biggest leap since 3.5 Sonnet.
I’m extremely curious to find out how everyone else will receive the model. My guess is that most non-developers will not get it for a few months. We’ll have to wait for these models to be integrated into products.
What’s next?
Well… Sam’s 2 year old todo list is still outstanding…


It'll be interesting to see how OpenAI's web-first Codex experience will compare to Claude Code's CLI-first approach. Codex leans into onboarding and accessibility, while Claude prioritizes precision and local context.
Both will push the industry into the direction of "build your own software".
Is it even worth learning to become a software engineer at this point?