



Want to help define the AI Engineer stack? >800 folks have weighed in on the top tools, communities and builders for the first State of AI Engineering survey, which we will present for the first time at next week’s AI Engineer Summit. Join us online!
This post had robust discussion on HN and Twitter.

In October 2022, Robust Intelligence hosted an internal hackathon to play around with LLMs which led to the creation of two of the most important AI Engineering tools: LangChain 🦜⛓️ (our interview with Harrison here) and LlamaIndex 🦙 by Jerry Liu, which we’ll cover today. In less than a year, LlamaIndex has crossed 600,000 monthly downloads, raised $8.5M from Greylock, has a fast growing open source community that contributes to LlamaHub, and it doesn’t seem to be slowing down.
LlamaIndex’s Origin (aka GPT Tree Index)
Jerry struggled to make large amounts of data work with GPT-3 (which had a 4,096 tokens context window). Today LlamaIndex is at the forefront of the RAG wave (Retrieval Augmented Generation), but in the beginning Jerry wasn’t focused on embeddings and search, but rather on understanding how models could summarize, link, and reason about data.
On November 5th, Jerry pushed the first version to Github under the name “GPT Tree Index”:
The GPT Tree Index first takes in a large dataset of unprocessed text data as input. It then builds up a tree-index in a bottom-up fashion; each parent node is able to summarize the children nodes using a general summarization prompt; each intermediate node containing summary text summarizing the components below. Once the index is built, it can be saved to disk and loaded for future use.
Then, say the user wants to use GPT-3 to answer a question. Using a query prompt template, GPT-3 will be able to recursively perform tree traversal in a top-down fashion in order to answer a question. For example, in the very beginning GPT-3 is tasked with selecting between *n* top-level nodes which best answers a provided query, by outputting a number as a multiple-choice problem. The GPT Tree Index then uses the number to select the corresponding node, and the process repeats recursively among the children nodes until a leaf node is reached.
[…]
How is this better than an embeddings-based approach / other state-of-the-art QA and retrieval methods?
The intent is not to compete against existing methods. A simpler embedding-based technique could be to just encode each chunk as an embedding and do a simple question-document embedding look-up to retrieve the result. This project is a simple exercise to test how GPT can organize and lookup information.
The project attracted a lot of attention early on (the announcement tweet has ~330 likes), but it wasn’t until ~February 2023 that the open source community really started to explode, which was around the same time that LlamaHub was released. LlamaHub made it easy for developers to import data from Google Drive, Discord, Slack, databases, and more into their LlamaIndex projects.

What is LlamaIndex?
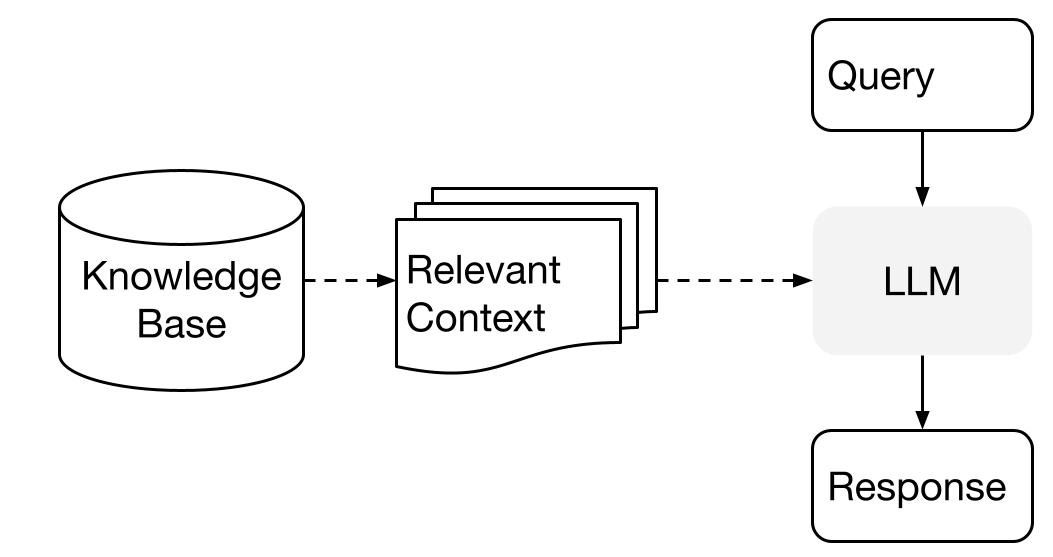
As we mentioned, LlamaIndex is leading the charge in the development of the RAG stack. RAG boils down to two parts:
Indexing (i.e. how do you load and index the data in your knowledge base)
Querying (i.e. how do you surface the data and fit it in the model context)
Indexing

To get your data from all your sources to your RAG knowledge base, you can leverage a few tools:
Documents / Nodes: A
Documentis a generic container around any data source - for instance, a PDF, an API output, or retrieved data from a database. ANodeis the atomic unit of data in LlamaIndex and represents a “chunk” of a sourceDocument(i.e. oneDocumenthas manyNode) as well as its relationship to otherNodeobjects.Data Connectors: A data connector ingest data from different sources and turn them into
Documentrepresentations (text and simple metadata). These connectors are offered through LlamaHub, and there are over 200 of them today.Data Indexes: Once you’ve ingested your data, LlamaIndex will help you index the data into a format that’s easy to retrieve. There are many types of indexes (Summary, Tree, Vector, etc). Under the hood, LlamaIndex parses the raw documents into intermediate representations, calculates vector embeddings, and infers metadata. The most commonly used index is the VectorStoreIndex, which can then be paired with any of the vector stores out there (an example with Chroma).
Querying
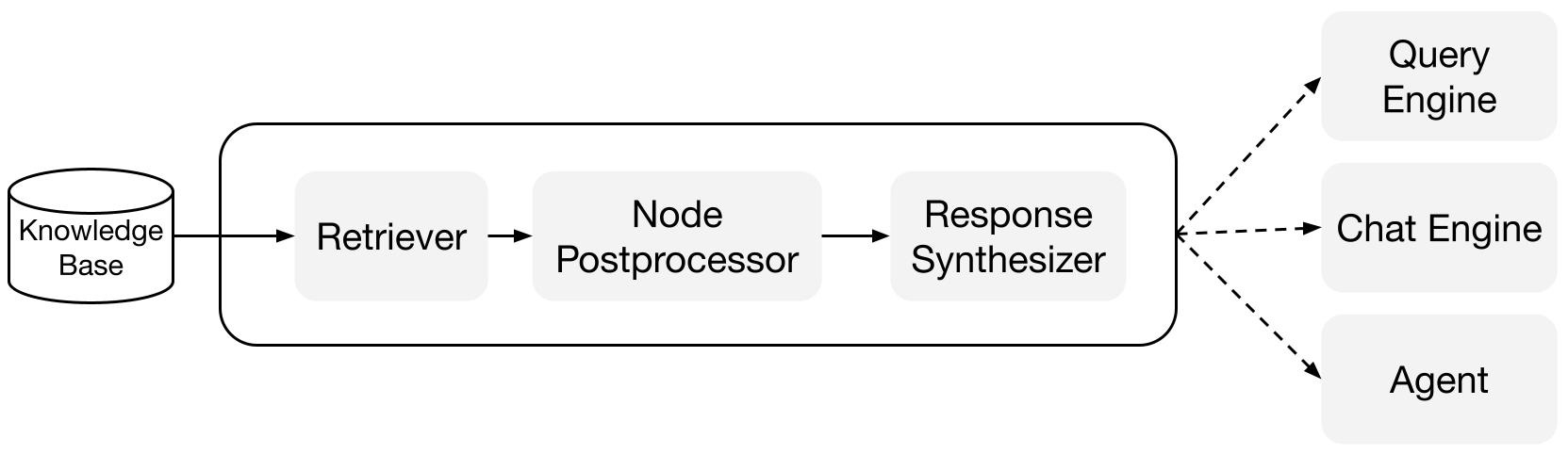
The RAG pipeline, during the querying phase, sources the most pertinent context from a user's prompt, forwarding it along to the LLM. This equips the LLM with current / private knowledge beyond its foundational training data. LlamaIndex offers adaptable modules tailored for building RAG pathways for Q&A, chatbots, or agent use, since each of them has different requirements. For example, a chatbot should expect the user to interject with follow up questions, while an agent will try to carry out a whole task on its own without user intervention.
Building Blocks
Retrievers: A retriever defines how to efficiently retrieve relevant context from a knowledge base (i.e. index) when given a query. Vector index is the most popular mode, but there are other options like Summary, Tree, Keyword Table, Knowledge Graph, and Document Summary.
Node Postprocessors: Once the retriever gets you
Nodeobjects back, you will need to do additional work like discarding low similarity ones. There are many options here as well, such as `SimilarityPostprocessor` (i.e. drop nodes below a certain similarity score) or `LongContextReorder` which helps avoid the issues raised in the “Lost in the Middle, U-shaped recollection curve” paper.Response Synthesizers: Takes a user query and your retrieved chunks, and prompts and LLM with them. There are a few response modes here that balance thoroughness and compactness.
Pipelines
Query Engines: A query engine is an end-to-end pipeline that allow you to ask question over your data. It takes in a natural language query, and returns a response, along with reference context retrieved and passed to the LLM. This makes it possible to do things like “Ask panda questions” by leveraging Panda dataframes as a data source.
Chat Engines: A chat engine is an end-to-end pipeline for having a conversation with your data (multiple back-and-forth instead of a single question & answer). This supports traditional OpenAI-style chat interfaces, as well as more advanced ones like ReAct.
Agents: An agent is an automated decision maker (powered by an LLM) that interacts with the world via a set of tools. Agent may be used in the same fashion as query engines or chat engines, but they have the power to both read and write data. For reasoning, you can use either OpenAI Functions or ReAct. Both can leverage the tools offered through LlamaHub for further analysis.
RAG vs Finetuning
Now that you have a full overview of what LlamaIndex does, the next question is “When should I use this and when should I fine tune?”. Jerry’s TLDR is that “RAG is just a hack”, but a powerful one. Each option has pros and cons:
Lower investment: RAG requires almost 0 upfront investment, unlike finetuning which requires data cleaning, model training, increased costs for finetuned inference, etc.
Stricter access control and higher visibility: when finetuning, the model learns everything. With RAG, you can decide what documents the index should have access to, making it more secure by default. You are also able to see everything that was passed into the context if a response doesn’t look right.
Context window limitation: you can only fit so many tokens into the prompt due to the way models work. Finetuning helps you circumvent that by compressing the knowledge into the model weights rather than putting it in the prompt.
As Jerry says, the best way to know this inside out is to learn to build RAG from scratch (without LlamaIndex) - and they have plenty of tutorials on his Twitter and blog to learn this.
The other issue is that the math for finetuning isn’t well known yet as we discussed with Quentin Anthony from Eleuther, so unless you have money and time to invest into exploring fine tuning, you’re better off starting with RAG.

Full YouTube Discussion!
Show Notes
Timestamps
[00:00:00] Introductions and Jerry’s background
[00:04:30] Starting LlamaIndex as a side project
[00:05:11] Evolution from tree-index to current LlamaIndex and LlamaHub architecture
[00:11:39] Deciding to leave Robust to start the LlamaIndex company and raising funding
[00:20:06] Context window size and information capacity for LLMs
[00:21:34] Minimum viable context and maximum context for RAG
[00:22:52] Fine-tuning vs RAG - current limitations and future potential
[00:24:02] RAG as a hack but good hack for now
[00:26:19] RAG benefits - transparency and access control
[00:27:46] Potential for fine-tuning to take over some RAG capabilities
[00:30:04] Baking everything into an end-to-end trained LLM
[00:33:24] Similarities between iterating on ML models and LLM apps
[00:34:47] Modularity and customization options in LlamaIndex: data loading, retrieval, synthesis, reasoning
[00:40:16] Evaluating and optimizing each component of Lama Index system
[00:46:02] Building retrieval benchmarks to evaluate RAG
[00:47:24] SEC Insights - open source full stack LLM app using LlamaIndex
[00:49:48] Enterprise platform to complement LlamaIndex open source
[00:51:00] Community contributions for LlamaHub data loaders
[00:53:21] LLM engine usage - majority OpenAI but options expanding
[00:56:25] Vector store landscape
[00:59:46] Exploring relationships and graphs within data
[01:03:24] Additional complexity of evaluating agent loops
[01:04:01] Lightning Round
Transcript
Alessio: Hey everyone, welcome to the Latent Space Podcast. This is Alessio, partner and CTO of Residence and Decibel Partners, and I'm joined by my co-host Swyx, founder of Smol AI. [00:00:20]
Swyx: And today we finally have Jerry Liu on the podcast. Hey Jerry. [00:00:24]
Jerry: Hey guys. Hey Swyx and Alessio. Thanks for having me. [00:00:27]
Swyx: It's kind of weird because we keep running into each other in San Francisco AI events, so it's kind of weird to finally just have a conversation recorded for everybody else. [00:00:34]
Jerry: Yeah, I know. I'm really looking forward to this, aside from the questions. [00:00:38]
Swyx: So I tend to introduce people on their formal background and then ask something on the more personal side. So you are part of the Princeton gang. [00:00:46]
Jerry: I don't know if there is like official Princeton gang. [00:00:48]
Swyx: No, small Princeton gang. Okay. I attended your meeting. There was like four of you with Prem and the others. And then you have a bachelor's in CS and a certificate in finance. That's also fun. I also did finance and I think I saw that you also interned at Two Sigma where I worked in New York. You were a machine learning engineer. [00:01:06]
Jerry: You were at Two Sigma?
Swyx: Yeah, very briefly.
Jerry: Oh, cool. I didn't know that. [00:01:09]
Swyx: That was my first like proper engineering job before I went into DevRel. [00:01:12]
Jerry: Oh, okay. Nice. [00:01:14]
Swyx: And then you were a machine learning engineer at Quora, AI research scientist at Uber for three years, and then two years machine learning engineer at Robust Intelligence before starting LlamaIndex. So that's your LinkedIn. It's not only LinkedIn that people should know about you. [00:01:27]
Jerry: I think back during my Quora days, I had this like three-month phase where I just wrote like a ton of Quora answers. And so I think if you look at my tweets nowadays, you can basically see that as like the V2 of my three-month like Forrestant where I just like went ham on Quora for a bit. I actually, I think I was back then actually when I was working on Quora, I think the thing that everybody was fascinated in was just like general like deep learning advancements and stuff like GANs and generative like images and just like new architectures that were evolving. And it was a pretty exciting time to be a researcher actually, because you were going in like really understanding some of the new techniques. So I kind of use that as like a learning opportunity, basically just like read a bunch of papers and then answer questions on Quora. And so you can kind of see traces of that basically in my current Twitter where it's just like really about kind of like framing concepts and trying to make it understandable and educate other users on it. Yeah. [00:02:17]
Swyx: I've said, so a lot of people come to me for my Twitter advice, but like, I think you are doing one of the best jobs in AI Twitter, which is explaining concepts and just consistently getting hits out. Thank you. I didn't know it was due to the Quora training. Let's just sign on on Quora. A lot of people, including myself, like kind of wrote off Quora as like one of the web 1.0 like sort of question answer forums. But now I think it's becoming, seeing a resurgence obviously due to Poe and obviously Adam and D'Angelo has always been a leading tech figure, but what do you think is kind of underrated about Quora? [00:02:46]
Jerry: Well, I mean, I like the, I really liked the mission of Quora when I, when I joined. In fact, I interned there like in 2015 and I joined full time in 2017. One is like they had, and they have like a very talented engineering team and just like really, really smart people. And the other part is the whole mission of the company is to just like spread knowledge and to educate people. And to me that really resonated. I really liked the idea of just like education and democratizing the flow of information. If you imagine like kind of back then it was like, okay, you have Google, which is like for search, but then you have Quora, which is just like user generated, like grassroots type content. And I really liked that concept because it's just like, okay, there's certain types of information that aren't accessible to people, but you can make accessible by just like surfacing it. And so actually, I don't know if like most people know that about like Quora and if they've used the product, whether through like SEO, right, or kind of like actively, but that really was what drew me to it. [00:03:39]
Swyx: Yeah. I think most people challenges with it is that sometimes you don't know if it's like a veiled product pitch, right? [00:03:44]
Jerry: Yeah. Of course, like quality of the answer matters quite a bit. And then you start running into these like- [00:03:47]
Swyx: It's like five alternatives and then here's the one I work on. Yeah. [00:03:50]
Jerry: Like recommendation issues and all that stuff. I used, I worked on recsys at Quora actually, so I got a taste of some of that stuff. Well, I mean, I kind of more approached it from machine learning techniques, which might be a nice segue into RAG actually. A lot of it was just information retrieval. We weren't like solving anything that was like super different than what was standard in the industry at the time, but just like ranking based on user preferences. I think a lot of Quora was very metrics driven. So just like trying to maximize like daily active hours, like time spent on site, those types of things. And all the machine learning algorithms were really just based on embeddings. You have a user embedding and you have like item embeddings and you try to train the models to try to maximize the similarity of these. And it's basically a retrieval problem. [00:04:30]
Swyx: Okay. So you've been working on RAG for longer than most people think? [00:04:33]
Jerry: Well, kind of. So I worked there for like a year, right, just transparently. And then I worked at Uber where I was not working on ranking. It was more like kind of deep learning training for self-driving and computer vision and that type of stuff. But I think in the LLM world, it's kind of just like a combination of like everything these days. I mean, retrieval is not really LLMs, but like it fits within the space of like LLM apps. And then obviously like having knowledge of the underlying deep learning architectures helps. Having knowledge of basic software engineering principles helps too. And so I think it's kind of nice that like this whole LLM space is basically just a combination of just like a bunch of stuff that you probably like people have done in the past. [00:05:11]
Swyx: It's good. It's like a summary capstone project. Yeah, exactly. [00:05:14]
Jerry: Yeah. [00:05:15]
Alessio: And before we dive into LlamaIndex, what do they feed you a robust intelligence that both you and Harrison from LangChain came out of it at the same time? Was there like, yeah. Is there any fun story of like how both of you kind of came up with kind of like core infrastructure to LLM workflows today? Or how close were you at robust? Like any fun behind the scenes? [00:05:37]
Jerry: Yeah. Yeah. We, um, we work pretty closely. I mean, we were on the same team for like two years. I got to know Harrison and the rest of the team pretty well. I mean, I have a respect that people there, the people that were very driven, very passionate. And it definitely pushed me to be, you know, a better engineer and leader and those types of things. Yeah. I don't really have a concrete explanation for this. I think it's more just, we have like an LLM hackathon around like September. This was just like exploring GPT-3 or it was October actually. And then the day after I went on vacation for a week and a half, and so I just didn't track Slack or anything. And then when I came back, saw that Harrison started LangChain [00:06:09]
Swyx: Oh that's cool. [00:06:10]
Jerry: I was like, oh, I'll play around with LLMs a bit and then hacked around on stuff. And I think I've told the story a few times, but you know, I was like trying to feed in information into GPT-3. And then, then you deal with like context window limitations and there was no tooling or really practices to try to understand how do you, you know, get GPT-3 to navigate large amounts of data. And that's kind of how the project started. Really was just one of those things where early days, like we were just trying to build something that was interesting. Like I wanted to start a company. I had other ideas actually of what I wanted to start. And I was very interested in, for instance, like multimodal data, like video data and that type of stuff. And then this just kind of grew and eventually took over the other idea. [00:06:48]
Swyx: Text is the universal interface. [00:06:50]
Jerry: I think so. I think so. I actually think once the multimodal models come out, I think there's just like mathematically nicer properties of you can just get like join multiple embeddings, like clip style. But text is really nice because from a software engineering principle, it just makes things way more modular. You can just convert everything into text and then you just represent everything as text. [00:07:08]
Swyx: Yeah. I'm just explaining retroactively why working on LlamaIndex took off versus if you had chose to spend your time on multimodal, we probably wouldn't be talking about whatever you ended up working on. [00:07:18]
Jerry: Yeah. [00:07:19]
Swyx: That's true. It's troubled. Interesting. So November 9th, that was a very productive month. I guess October, November, November 9th, you announced GPT-3 Index and you picked a tree logo. Very cool. Every project must have an emoji. [00:07:32]
Jerry: Yeah. Yeah. I probably was somewhat inspired by a light train, but I will admit, yeah. [00:07:37]
Swyx: It uses GPT to build a knowledge tree in a bottoms-up fashion by applying a summarization prompt for each node. Yep. Which I like that original vision. Your messaging roundabout then was also that you're creating optimized data structures. What's the sort of journey to that and how does that contrast with LlamaIndex today? Okay. [00:07:56]
Jerry: Maybe I can tell a little bit about the beginning intuitions. I think when I first started, this really wasn't supposed to be something that was like a toolkit that people use. It was more just like a system. And the way I wanted to think about the system was more a thought exercise of how language models with their reasoning capabilities, if you just treat them as like brains, can organize information and then traverse it. So I didn't want to think about embeddings, right? To me, embeddings just felt like it was just an external thing that was like, well, it was just external to trying to actually tap into the capabilities of language models themselves, right? I really wanted to see, you know, just as like a human brain could like synthesize stuff, could we create some sort of like structure where this neural CPU, if you will, can like organize a bunch of information, you know, auto-summarize a bunch of stuff and then also traverse the structure that I created. That was the inspiration for this initial tree index, to be honest. And I think I said this in the first tweet, it actually works super well, right? Like GPT-4 obviously is much better at reasoning. I'm one of the first to say, you know, you shouldn't use anything pre-GPT-4 for anything that requires complex reasoning because it's just going to be unreliable, okay, disregarding stuff like fine tuning. But it worked okay. But I think it definitely struck a chord with kind of like the Twitter crowd, which is just like new ideas at the time, I guess, just like thinking about how you can actually bake this into some sort of application. Because I think what I also ended up discovering was the fact that there was starting to become a wave of developers building on top of GPT-3 and people were starting to realize that what makes them really useful is to apply them on top of your personal data. And so even if the solution itself was kind of like primitive at the time, like the problem statement itself was very powerful. And so I think being motivated by the problem statement, right, like this broad mission of how do I unlock elements on top of the data also contributed to the development of LOM index to the state it is today. And so I think part of the reason, you know, our toolkit has evolved beyond the just existing set of like data structures is we really tried to take a step back and think, okay, what exactly are the tools that would actually make this useful for a developer? And then, you know, somewhere around December, we made an active effort to basically like push towards that direction, make the code base more modular, right, more friendly as an open source library. And then also start adding in like embeddings, start thinking into practical considerations like latency, cost, performance, those types of things. And then really motivated by that mission, like start expanding the scope of the toolkit towards like covering the life cycle of like data ingestion and querying. Where you also added Llamahub and yeah, so I think that was in like January on the data loading side. And so we started adding like some data loaders, saw an opportunity there, started adding more stuff on the retrieval querying side, right? We still have like the core data structures, but how do you actually make them more modular and kind of like decouple storing state from the types of like queries that you could run on top of this a little bit. And then starting to get into more complex interactions, like chain of thought reasoning, routing and, you know, like agent loops. [00:10:44]
Alessio: You and I spent a bunch of time earlier this year talking about Llamahub, what that might become. You were still at Robust. When did you decide it was time to start the company and then start to think about what LlamaIndex is today? [00:10:58]
Jerry: Yeah, I mean, probably December. It was kind of interesting. I was getting some inbound from initial VCs, I was talking about this project. And then in the beginning, I was like, oh, yeah, you know, this is just like a design project. But you know, what about my other idea on like video data, right? And then I was trying to like get their thoughts on that. And then everybody was just like, oh, yeah, whatever, like that part's like a crowded market. And then it became clear that, you know, this was actually a pretty big opportunity. And like, coincidentally, right, like this actually did relate to like, my interests have always been at the intersection of AI data and kind of like building practical applications. And it was clear that this was evolving into a much bigger opportunity than the previous idea was. So around December, and then I think I gave a pretty long notice, but I left officially like early March. [00:11:39]
Alessio: What were your thinkings in terms of like moats and, you know, founders kind of like overthink it sometimes. So you obviously had like a lot of open source love and like a lot of community. And you're like, were you ever thinking, okay, I don't know, this is maybe not enough to start a company or did you always have conviction about it? [00:11:59]
Jerry: Oh, no, I mean, 100%. I felt like I did this exercise, like, honestly, probably more late December and then early January, because I was just existentially worried about whether or not this would actually be a company at all. And okay, what were the key questions I was thinking about? And these were the same things that like other founders, investors, and also like friends would ask me is just like, okay, what happens if context windows get much bigger? What's the point of actually structuring data right in the right way? Right? Why don't you just dump everything into the prompt, fine tuning, like, what if you just train the model over this data? And then, you know, what's the point of doing this stuff? And then some other ideas is what if like OpenAI actually just like takes this like builds upwards on top of the their existing like foundation models and starts building in some like built in orchestration capabilities around stuff like RAG and agents and those types of things. And so I basically ran through this mental exercise and, you know, I'm happy to talk a little bit more about those thoughts as well. But at a high level, well, context windows have gotten bigger, but there's obviously still a need for a rag. I think RAG is just like one of those things that like, in general, what people care about is, yes, they do care about performance, but they also care about stuff like latency and costs. And so my entire reasoning at the time was just like, okay, like, yes, maybe you will have like much bigger context windows, as we've seen with like 100k context windows. But for enterprises, like, you know, data, which is not in just like the scale of like a few documents, it's usually in like gigabytes, terabytes, petabytes. How do you actually just unlock language models over that data, right? And so it was clear there was just like, whether it's RAG or some other paradigm, no one really knew what that answer was. And so there was clearly like technical opportunity here. Like there was just stacks that needed to be invented to actually solve this type of problem, because language models themselves didn't have access to this data. The other piece here is just like, and so if like you just dumped all this data into, let's say a model had like hypothetically an infinite context window, right? And you just dump like 50 gigabytes of data into a context window. That just seemed very inefficient to me, because you have these network transfer costs of uploading 50 gigabytes of data to get back a single response. And so I kind of realized, you know, there's always going to be some curve, regardless of like the performance of the best performing models of like cost versus performance. What RAG does is it does provide extra data points along that access, because you kind of control the amount of context you actually wanted to retrieve. And of course, like RAG as a term was still evolving back then, but it was just this whole idea of like, how do you just fetch a bunch of information to actually, you know, like stuff into the prompt. And so people even back then were kind of thinking about some of those considerations. [00:14:29]
Swyx: And then you fundraised in June, or you announced your fundraiser in June. Yeah. Take us through that process of thinking about the fundraise and your plans for the company, you know, at the time. Yeah, definitely. [00:14:41]
Jerry: I mean, I think we knew we wanted to, I mean, obviously we knew we wanted to fundraise. There was also a bunch of like investor interest, and it was probably pretty unusual given the, you know, like hype wave of generative AI. So like a lot of investors were kind of reaching out around like December, January, February. In the end, we went with Greylock. Greylock's great. You know, they've been great partners so far. And to be honest, like there's a lot of like great VCs out there. And a lot of them who are specialized on like open source, data, infra, and that type of stuff. What we really wanted to do was, because for us, like time was of the essence, like we wanted to ship very quickly and still kind of build Mindshare in this space. We just kept the fundraising process very efficient. I think we basically did it in like a week or like three days. And so, yeah, just like front loaded it and then just like pick the one named Jerry. Yeah, exactly. Yeah. [00:15:27]
Swyx: I'm kidding. I mean, he's obviously great and Greylock's a fantastic firm. [00:15:32]
Jerry: Embedding some of my research. So, yeah, just we've had Greylock. They've been great partners. I think in general, when I talk to founders about like the fundraise process, it's never like the most fun period, I think, because it's always just like, you know, there's a lot of logistics, there's lawyers you have to, you know, get in the loop. And like a lot of founders just want to go back to building. I think in the end, we're happy that we kept it to a pretty efficient process. [00:15:54]
Swyx: And so you fundraise with Simon. How do you split things with him? How big is your team now? [00:15:57]
Jerry: The team is growing. By the time this podcast is released, we'll probably have had one more person join the team. So basically, it's between, we're rapidly getting to like eight or nine people. At the current moment, we're around like six. And so just like there'll be some exciting developments in the next few weeks. I'm excited to announce that. So the team is, has kind of like, we've been pretty selective in terms of like how we like grow the team. Obviously, like we look for people that are really active in terms of contributions to Lum Index, people that have like very strong engineering backgrounds. And primarily, we've been kind of just looking for builders, people that kind of like grow the open source and also eventually this like managed like enterprise platform as well with us. In terms of like Simon, yeah, I've known Simon for a few years now. I knew him back at Uber ATG in Toronto. He's one of the smartest people I knew, has a sense of both like a deep understanding of ML, but also just like first principles thinking about like engineering and technical concepts in general. And I think one of my criteria, criteria is when I was like looking for a co-founder for this project with someone that was like technically better than me, because I knew I wanted like a CTO. And so honestly, like there weren't a lot of people that, I mean, there's, I know a lot of people that are smarter than me, but like that fit that bill. We're willing to do a startup and also just have the same like values that I shared. Right. And just, I think doing a startup is very hard work, right? It's not like, I'm sure like you guys all know this, it's, it's a lot of hours, a lot of late nights and you want to be like in the same place together and just like being willing to hash out stuff and have that grit basically. And I really looked for that. And so Simon really fit that bill and I think I convinced him to bring Trump on board. [00:17:24]
Swyx: Yeah. And obviously I've had the pleasure of chatting and working with a little bit with both of you. What would you say those, those like your top one or two values are when, when thinking about that or the culture of the company and that kind of stuff? [00:17:36]
Jerry: I think in terms of the culture of the company, it's really like, I mean, there's a few things I can name off the top of my head. One is just like passion, integrity. I think that's very important for us. We want to be honest. We don't want to like, obviously like copy code or, or kind of like, you know, just like, you know, not give attribution, those types of things and, and just like be true to ourselves. I think we're all very like down to earth, like humble people, but obviously I think just willingness to just like own stuff and dive right in. And I think grit comes with it. I think in the end, like this is a very fast moving space and we want to just like be one of the, you know, like dominant forces and helping to provide like production quality outline applications. Yeah. [00:18:11]
Swyx: I promise we'll get to more technical questions, but I also want to impress on the audience that this is a very conscious and intentional company building. And since your fundraising post, which was in June, and now it's September, so it's been about three months, you've actually gained 50% in terms of stars and followers. You've 3x'd your download count to 600,000 a month and your discord membership has reached 10,000. So like a lot of ongoing growth. [00:18:37]
Jerry: Yeah, definitely. And obviously there's a lot of room to expand there too. And so open source growth is going to continue to be one of our core goals because in the end it's just like, we want this thing to be, well, one big, right? We all have like big ambitions, but to just like really provide value to developers and helping them in prototyping and also productionization of their apps. And I think it turns out we're in the fortunate circumstance where a lot of different companies and individuals, right, are in that phase of like, you know, maybe they've hacked around on some initial LLM applications, but they're also looking to, you know, start to think about what are the production grade challenges necessary to actually, that to solve, to actually make this thing robust and reliable in the real world. And so we want to basically provide the tooling to do that. And to do that, we need to both spread awareness and education of a lot of the key practices of what's going on. And so a lot of this is going to be continued growth, expansion, education, and we do prioritize that very heavily. [00:19:30]
Alessio: Let's dive into some of the questions you were asking yourself initially around fine tuning and RAG , how these things play together. You mentioned context. What is the minimum viable context for RAG ? So what's like a context window too small? And at the same time, maybe what's like a maximum context window? We talked before about the LLMs are U-shaped reasoners. So as the context got larger, like it really only focuses on the end and the start of the prompt and then it kind of peters down. Any learnings, any kind of like tips you want to give people as they think about it? [00:20:06]
Jerry: So this is a great question. And part of what I wanted to talk about a conceptual level, especially with the idea of like thinking about what is the minimum context? Like, okay, what if the minimum context was like 10 tokens versus like, you know, 2k tokens versus like a million tokens. Right. Like, and what does that really give you? And what are the limitations if it's like 10 tokens? It's kind of like, um, like eight bit, 16 bit games, right? Like back in the day, like if you play Mario and you have like the initial Mario where the graphics were very blocky and now obviously it's like full HD, 3d, just the resolution of the context and the output will change depending on how much context you can actually fit in. So the way I kind of think about this from a more principled manner is like you have like, there's this concept of like information capacity, just this idea of like entropy, like given any fixed amount of like storage space, like how much information can you actually compact in there? And so basically a context window length is just like some fixed amount of storage space, right? And so there's some theoretical limit to the maximum amount of information you can compact until like a 4,000 token storage space. And what does that storage space use for these days with LLMs? For inputs and also outputs. And so this really controls the maximum amount of information you can feed in terms of the prompt plus the granularity of the output. If you had an infinite context window, you're going to have an infinitely detailed response and also infinitely detailed memory. But if you don't, you can only kind of represent stuff in more quantized bits, right? And so the smaller the context window, just generally speaking, the less details and maybe the less, um, and for like specific, precise information, you're going to be able to surface any given point in time. [00:21:34]
Alessio: So when you have short context, is the answer just like get a better model or is the answer maybe, Hey, there needs to be a balance between fine tuning and RAG to make sure you're going to like leverage the context, but at the same time, don't keep it too low resolution? [00:21:48]
Jerry: Yeah, yeah. Well, there's probably some minimum threat, like I don't think anyone wants to work with like a 10. I mean, that's just a thought exercise anyways, a 10 token context window. I think nowadays the modern context window is like 2k, 4k is enough for just like doing some sort of retrieval on granular context and be able to synthesize information. I think for most intents and purposes, that level of resolution is probably fine for most people for most use cases. I think the question there is just like, um, the limitations actually more on, okay, if you're going to actually combine this thing with some sort of retrieval data structure mechanism, there's just limitations on the retrieval side because maybe you're not actually fetching the most relevant context to actually answer this question, right? Like, yes, like given the right context, 4,000 tokens is enough. But if you're just doing like top-k similarity, like you might not be able to be fetching the right information from the documents. [00:22:34]
Alessio: So how should people think about when to stick with RAG versus when to even entertain and also in terms of what's like the threshold of data that you need to actually worry about fine tuning versus like just stick with rag? Obviously you're biased because you're building a RAG company, but no, no, actually, um, I [00:22:52]
Jerry: think I have like a few hot takes in here, some of which sound like a little bit contradictory or what we're actually building. And I think to be honest, I don't think anyone knows the right answer. I think this is the truth. [00:23:01]
Alessio: Yeah, exactly. [00:23:01]
Jerry: This is just like thought exercise towards like understanding the truth. [00:23:04]
Alessio: Right. [00:23:04]
Jerry: So, okay. [00:23:05]
Alessio: I have a few hot takes. [00:23:05]
Jerry: One is like RAG is basically just, just a hack, but it turns out it's a very good hack because what is RAG rag is you keep the model fixed and you just figure out a good way to like stuff stuff into the prompt of the language model and everything that we're doing nowadays in terms of like stuffing stuff into the prompt is just algorithmic. We're just figuring out nice algorithms to, to like retrieve right information with top case similarity, do some sort of like, uh, you know, hybrid search, some sort of like a chain of thought decomp and then just like stuff stuff into a prompt. So it's all like algorithmic and it's more like just software engineering to try to make the most out of these like existing APIs. The reason I say it's a hack is just like from a pure like optimization standpoint. If you think about this from like the machine learning lens, unless the software engineering lens, there's pieces in here that are going to be like suboptimal, right? Like, like the thing about machine learning is when you optimize like some system that can be optimized within machine learning, like the set of parameters, you're really like changing like the entire system's weights to try to optimize the subjective function. [00:24:02]
Jerry: And if you just cobble a bunch of stuff together, you can't really optimize the pieces are inefficient, right? And so like a retrieval interface, like doing top cam batting lookup, that part is inefficient. [00:24:13]
Jerry: If you, for instance, because there might be potentially a better, more learned retrieval algorithm, that's better. If you know, you do stuff like some sort of, I know nowadays there's this concept of how do you do like short-term and long-term memory represent stuff in some sort of vector embedding, do trunk sizes, all that stuff. It's all just like decisions that you make that aren't really optimized and it's not really automatically learned. It's more just things that you set beforehand to actually feed into the system. So I do think like there is a lot of room to actually optimize the performance of an entire LLM system, potentially in a more like machine learning based way. Right. [00:24:48]
Jerry: And I will leave room for that. And this is also why I think like in the long term, I do think fine tuning will probably have like greater importance. And just like there will probably be new architectures invented that where you can actually kind of like include a lot of this under the black box, as opposed to having like hobbling together a bunch of components outside the black box. That said, just very practically given the current state of things, like even if I said RAG is a hack, it's a very good hack and it's also very easy to use. Right. [00:25:16]
Jerry: And so just like for kind of like the AI engineer persona, which to be fair is kind of one of the reasons generative AI has gotten so big is because it's way more accessible for everybody to get into, as opposed to just like traditional machine learning, it tends to be good enough. [00:25:30]
Jerry: Right. And if we can basically provide these existing techniques to help people really optimize how to use existing systems without having to really deeply understand machine learning, I still think that's a huge value add. And so there's very much like a UX and ease of use problem here, which is just like RAG is way easier to onboard and use. And that's probably like the primary reason why everyone should do RAG instead of fine tuning to begin with. If you think about like the 80-20 rule, like RAG very much fits within that and fine tuning doesn't really right now. And then I'm just kind of like leaving room for the future that, you know, like in the end, fine tuning can probably take over some of the aspects of like what RAG does. [00:26:04]
Swyx: I don't know if this is mentioned in your explainability also allows for sourcing. And at the end of the day, like to increase trust that we have to source documents. Yeah. [00:26:14]
Jerry: So, so I think what RAG does is it increases like transparency, visibility into the actual documents, right. [00:26:19]
Jerry: That are getting fed into their context. [00:26:21]
Swyx: Here's where they got it from. [00:26:22]
Alessio: Exactly. [00:26:22]
Jerry: That's definitely an advantage. I think the other piece that I think is an advantage, and I think that's something that someone actually brought up is just you can do access control with, with RAG . If you have an external storage system, you can't really do that with, with large language models. [00:26:35]
Jerry: It's just like gate information to the neural net weights, like depending on the type of user for the first point, you could technically, you could technically have the language model. [00:26:45]
Jerry: Like if it memorized enough information, just like a site sources, but there's a question of just trust whether or not you're actually, yeah, well, but like it makes it up right now because it's like not good enough, but imagine a world where it is good enough and it does give accurate citations.
Swyx: No, I think to establish trust, you just need a direct connection.So it's, it's kind of weird. It's, it's this melding of deep learning systems versus very traditional information retrieval. Yeah, exactly. [00:27:11]
Jerry: Well, so, so I think, I mean, I kind of think about it as analogous to like humans, right? [00:27:15]
Jerry: Like, uh, we as humans, obviously we use the internet, we use tools. Uh, these tools have API interfaces are well-defined. Um, and obviously we're not like the tools aren't part of us. And so we're not like back propping or optimizing over these tools. And so when you think about like RAG , it's basically, um, LLM is learning how to use like a vector database to look up information that it doesn't know. And so then there's just a question of like how much information is inherent within the network itself and how much does it need to do some sort of like tool used to look up stuff that it doesn't know. [00:27:42]
Jerry: And I do think there'll probably be more and more of that interplay as time goes on. [00:27:46]
Swyx: Yeah. Some followups on discussions that we've had, you know, we discussed fine tuning a bit and what's your current take on whether you can, you can fine tune new knowledge into LLMs. [00:27:55]
Jerry: That's one of those things where I think longterm you definitely can. I think some people say you can't, I disagree. I think you definitely can. Just right now I haven't gotten it to work yet. So, so I think like we've tried, yeah, well, um, not in a very principled way, right? Like this is something that requires like an actual research scientist and not someone that has like, you know, an hour or two per night to actually look at this. [00:28:12]
Swyx: Like I, you were a research scientist at Uber. I mean, it's like full-time, full-time working. [00:28:16]
Jerry: So, so I think, um, what I specifically concretely did was I took OpenAI's fine tuning endpoints and then tried to, you know, it's in like a chat message interface. And so there's like, um, input question, like a user assistant message format. And so what I did was I tried to take just some piece of text and have the LLM memorize it by just asking it a bunch of questions about the text. So given a bunch of context, I would generate some questions and then generate some response and just fine tune over the question responses. That hasn't really worked super well, but that's also because I'm, I'm just like trying to like use OpenAI's endpoints as is. If you just think about like traditional, like how you train a Transformers model, there's kind of like the, uh, instruction, like fine tuning aspect, right? You like ask it stuff when guided with correct responses, but then there's also just like, um, next token production. And that's something that you can't really do with the OpenAI API, but you can do with, if you just train it yourself and that's probably possible if you just like train it over some corpus of data. I think Shashira from Berkeley said like, you know, when they trained Gorilla, they were like, Oh, you know, this, a lot of these LLMs are actually pretty good at memorizing information. Um, just the way the API interface is exposed is just no one knows how to use them right [00:29:22]
Alessio: now. Right. [00:29:22]
Jerry: And so, so I think that's probably one of the issues. [00:29:24]
Swyx: Just to clue people in who haven't read the paper, Gorilla is the one where they train to use specific APIs. [00:29:30]
Jerry: Yeah, I think this was on the Gorilla paper. Like the, the model itself could, uh, try to learn some prior over the data to decide like what tool to pick. But there's also, it's also augmented with retrieval that helps supplement it in case like the, the, the, um, prior doesn't actually work. [00:29:45]
Swyx: Is that something that you'd be interested in supporting? [00:29:48]
Jerry: I mean, I think in the longterm, like if like, this is kind of how fine tuning, like RAG evolves. Like I do think there'll be some aspect where fine tuning will probably memorize some high level concepts of knowledge, but then like RAG will just be there to supplement like aspects of that, that aren't work that don't, that, that it doesn't know.
Jerry: Um, the way I think about this is kind of like, obviously RAG is the default way, like to be clear, RAG right now is the default way to actually augment stuff with knowledge. I think it's just an open question of how much the LM can actually internalize both high level concepts, but also details as you can like train stuff over it. And coming from an ML background, there is a certain beauty and just baking everything into some training process of a language model. Like if you just take raw chat, GPT or chat, GPT code interpreter, right? Like GPT four, it's not like you do RAG with it. You just ask it questions about like, Hey, how do I like to find a pedantic model in Python? And I'm like, can you give me an example? Can you visualize a graph? It just does it right. Like, and we'll run it through code interpreters as a tool, but that's not like a source for knowledge. [00:30:46]
Jerry: It's just an execution environment. And so there is some beauty in just like having the model itself, like just, you know, instead of you kind of defining the algorithm for what the data structure should look like the model just learns it under the hood. That said, I think the reason it's not a thing right now is just like, no one knows how to do it. [00:31:01]
Jerry: It probably costs too much money. And then also like the API interfaces and just like the actual ability to kind of evaluate and improve on performance, like isn't known to most people. [00:31:12]
Alessio: Yeah. [00:31:12]
Swyx: It also would be better with browsing. [00:31:14]
Alessio: Yeah. [00:31:16]
Swyx: I wonder when they're going to put that back. [00:31:18]
Alessio: Okay. Yeah. [00:31:19]
Swyx: So, and then one more follow up before we go into RAG for AI engineers is on your brief mentioned about security or off. How many of your, the people that you talk to, you know, you talk to a lot of people putting LlamaIndex into production. How many people actually are there versus just like, let's just dump a whole company notion into this thing. [00:31:36]
Jerry: Wait, are you talking about from like the security off standpoint? [00:31:39]
Alessio: Yeah. [00:31:39]
Swyx: How big a need is that? Because I, I talked to some people who are thinking about building tools in that domain, but I don't know if people want it. [00:31:47]
Jerry: I mean, I think bigger companies, like just bigger companies, like banks, consulting firms, like they all want this requirement, right? The way they're using LlamaIndex is not with this, obviously. Cause I don't think we have support for like access control or author that have stuff like on a hood. [00:32:02]
Jerry: Cause we're more just like an orchestration framework. And so the way they build these initial apps is more kind of like prototype. Like, let's kind of, yeah. Like, you know, use some publicly available data. That's not super sensitive. Let's like, you know, assume that every user is going to be able to have access to the same amount of knowledge, those types of things. I think users have asked for it, but I don't think that's like a P zero. Like I think the P zero is more on like, can we get this thing working before we expand this to like more users within the work? [00:32:25]
Alessio: There's a bunch of pieces to rag. Obviously it's not a, just an acronym. And you two recently, you think every AI engineer should build the front scratch at least once. Why is that? I think so. [00:32:37]
Jerry: I'm actually kind of curious to hear your thoughts about this. Um, but this kind of relates to the initial like AI engineering posts that you put out and then also just like the role of an AI engineer and the skills that they're going to have to learn to truly succeed because there's an entire On one end, you have people that don't really, uh, like understand the fundamentals and just want to use this to like cobble something together to build something. And I think there is a beauty in that for what it's worth. Like, it's just one of those things. And Gen AI has made it so that you can just use these models in inference only mode, call something together, use it, power your app experiences, but on the other end, what we're increasingly seeing is that like more and more developers building with these apps start running into honestly, like pretty similar issues that like we'll play just a standard engineer building like a classifier model, which is just like accuracy problems, like, and hallucinations, basically just an accuracy problem, right? [00:33:24]
Like it's not giving you the right results. So what do you do? You have to iterate on the model itself. You have to figure out what parameters you tweak. You have to gain some intuition about this entire process. That workflow is pretty similar, honestly, like even if you're not training the model to just like tuning a ML model with like hyper parameters and learning like proper ML practices of like, okay, how do I have like define a good evaluation benchmark? How do I define like the right set of metrics to do to use, right? How do I actually iterate and improve the performance of this pipeline for [00:33:52]
Alessio: production? What tools do I use? [00:33:53]
Jerry: Right? Like every ML engineer use like some form of weights and biases, tensor boards, or like some other experimentation tracking tool. What tools should I use to actually help build like LLM applications and optimize it for production? There's like a certain amount of just like LLM ops, like tooling and concepts and just like practices that people will kind of have to internalize if they want to optimize these. And so I think that the reason I think being able to build like RAG from scratch is important is it really gives you a sense of like how things are working to get, help you build intuition about like what parameters are within a RAG system and which ones actually tweak to make them better. Cause otherwise I think that one of the advantages of the LlamaIndex quick start is it's three lines of code. The downside of that is you have zero visibility into what's actually going on [00:34:37]
Alessio: under the hood. [00:34:37]
Jerry: And I think there's something that we've kind of been thinking about for a while and I'm like, okay, let's just release like a new tutorial series. That's just like, we're in set, not no three lines of code. We're just going to go in and actually show you how the thing actually works on [00:34:47]
Alessio: the hood. Right. [00:34:47]
Jerry: And so I like, does everybody need this? Like probably not as for some people, the three lines of code might work, but I think increasingly, like honestly, 90% of the users I talked to have questions about how to improve the performance of their app. And so just like, given this, it's just like one of those things that's like better for the understanding. [00:35:03]
Alessio: Yeah. [00:35:03]
Swyx: I'd say it is one of the most useful tools of any sort of developer education toolkit to write things yourself from scratch. So Kelsey Hightower famously wrote Kubernetes the hard way, which is don't use Kubernetes. Here's everything that you would have to do by yourself. And you should be able to put all these things together yourself to understand the value of Kubernetes. And the same thing for LLlamaIndex. I've done, I was the guy who did the same for React. And it's a pretty good exercise for you to just fully understand everything that's going on under the hood. And I was actually going to suggest while in one of the previous conversations, there's all these like hyperparameters, like the size of the chunks and all that. And I was thinking like, what would hyperparameter optimization for RAG look [00:35:44]
Alessio: like? [00:35:44]
Jerry: Yeah, definitely. I mean, so absolutely. I think that's going to be an increasing thing. I think that's something we're kind of looking at because like, I think someone [00:35:52]
Swyx: should just put, do like some large scale study and then just ablate everything. And just you, you tell us. [00:35:57]
Jerry: I think it's going to be hard to find a universal default that works for [00:36:00]
Alessio: everybody. [00:36:00]
Jerry: I think it's going to be somewhat, I do think it's going to be somewhat like dependent on the data and use case. I think if there was a universal default, that would be amazing. But I think increasingly we found, you know, people are just defining their own like custom parsers for like PDFs, markdown files for like, you know, SEC filings versus like Slack conversations. And then like the use case too, like, do you want like a summarization, like the granularity of the response? Like it really affects the parameters that you want to pick. I do like the idea of hyperparameter optimization though, but it's kind of like one of those things where you are kind of like training the model basically kind of on your own data domain. [00:36:36]
Alessio: Yeah. [00:36:36]
Swyx: You mentioned custom parsers. You've designed LlamaIndex, maybe we can talk about like the surface area of the [00:36:41]
Alessio: framework. [00:36:41]
Swyx: You designed LlamaIndex in a way that it's more modular, like you mentioned. How would you describe the different components and what's customizable in each? [00:36:50]
Jerry: Yeah, I think they're all customizable. And I think that there is a certain burden on us to make that more clear through the [00:36:57]
Alessio: docs. [00:36:57]
Jerry: Well, number four is customization tutorials. [00:36:59]
Swyx: Yeah, yeah. [00:37:00]
Jerry: But I think like just in general, I think we do try to make it so that you can plug in the out of the box stuff. But if you want to customize more lower level components, like we definitely encourage you to do that and plug it into the rest of our abstractions. So let me just walk through like maybe some of the basic components of LlamaIndex. There's data loaders. You can load data from different data sources. We have Llama Hub, which you guys brought up, which is, you know, a collection of different data loaders of like unstructured and unstructured data, like PDFs, file types, like Slack, Notion, all that stuff. Now you load in this data. We have a bunch of like parsers and transformers. You can split the text. You can add metadata to the text and then basically figure out a way to load it into like a vector store. So, I mean, you worked at like Airbrite, right? It's kind of like there is some aspect like E and T, right? And in terms of like transforming this data and then the L, right, loading it into some storage abstraction, we have like a bunch of integrations with different document storage systems. [00:37:49]
Alessio: So that's data. [00:37:50]
Jerry: And then the second piece really is about like, how do you retrieve this data? How do you like synthesize this data and how do you like do some sort of higher level reasoning over this data? So retrieval is one of the core abstractions that we have. We do encourage people to like customize, define your own retrievers, that section on kind of like how do you define your own, like custom retriever, but also we have like out of the box ones. The retrieval algorithm kind of depends on how you structure the data, obviously. Like if you just flat index everything with like chunks with like embeddings, then you can really only do like top K like lookup plus maybe like keyword search or something. But if you can index it in some sort of like hierarchy, like defined relationships, you can do more interesting things like actually traverse relationships between nodes. Then after you have this data, how do you like synthesize the data? [00:38:32]
Alessio: Right. [00:38:32]
Jerry: Um, and, and this is the part where you feed it into the language model. There's some response abstraction that can abstract away over like long contacts to actually still give you a response, even if the context overflows a context window. And then there's kind of these like higher level, like reasoning primitives that I'm going to define broadly. And I'm just going to call them in some general bucket of like agents, even though everybody has different definitions of agents, but you're the first to data agents, [00:38:56]
Swyx: which I was very excited. [00:38:57]
Alessio: Yeah. [00:38:57]
Jerry: We, we kind of like coin, coin that term. And the way we, we thought about it was, you know, we wanted to think about how to use agents for, uh, like data workflows basically. And, and so what are the reasoning primitives that you want to do? So the most simple reasoning primitive you can do is some sort of routing module. It's a classifier, like given a query, just make some automated decision on what choice to pick, right? You could use LLMs. You don't have to use LLMs. You could just try and classifier basically. That's something that we might actually explore. And then the next piece is, okay, what are some higher level things? You can have the LLM like define like a query plan, right. To actually execute over the data. You can do some sort of while loop, right? That's basically what an agent loop is, which is like react a chain of thought, like the open AI function calling, like while loop to try to like take a question and try to break it down into some, some, uh, series of steps to actually try to execute to get back a response. And so there's a range and complexity from like simple reasoning primitives to more advanced ones. The way we kind of think about it is like, which ones should we implement and how do [00:39:50]
Alessio: they work? [00:39:50]
Jerry: Well, like, do they work well over like the types of like data tasks that we give them? [00:39:54]
Alessio: How do you think about optimizing each piece? So take, um, embedding models is one piece of it. You offer fine tuning, embedding models. And I saw it was like fine tuning gives you like 5, 10% increase. What's kind of like the Delta left on the embedding side? Do you think we can get models that are like a lot better? Do you think like that's one piece where people should really not spend too much time? [00:40:16]
Jerry: I just think it's, it's not the only parameter. Cause I think in the end, if you think about everything that goes into retrieval, the chunking algorithm, um, how you define like metadata will bias your embedding representations. Then there's the actual embedding model itself, which is something that you can try optimizing. And then there's like the retrieval algorithm. Are you going to just do top K? Are you going to do like hybrid search? Are you going to do auto retrieval? Like there's a bunch of parameters. And so I do think it's something everybody should try. I think by default we use like OpenAI's embedding model. A lot of people these days use like sentence transformers because it's, it's just like free open source and you can actually optimize, directly optimize it. This is an active area of exploration. I do think one of our goals is it should ideally be relatively free for every developer to just run some fine tuning process over their data to squeeze out some more points and performance. And if it's that relatively free and there's no downsides, everybody should basically do [00:41:04]
Alessio: it. [00:41:04]
Jerry: There's just some complexities, right? In terms of optimizing your embedding model, especially in a production grade data pipeline. If you actually fine tune the embedding model and the embedding space changes, you're going to have to reindex all your documents. And for a lot of people, that's not feasible. And so I think like Joe from Vespa on our webinars, like there's this idea that depending on if you're just using like document and query embeddings, you could keep the document embeddings frozen and just train a linear transform on the query or, or any sort of transform on the query, right? So therefore it's just a query side transformation instead of actually having to reindex all the document embeddings. That's pretty smart. We weren't able to get like huge performance gains there, but it does like improve performance a little bit. And that's something that basically, you know, everybody should be able to kick off. You can actually do that on LLlamaIndex too. [00:41:45]
Swyx: OpenAIO has a cookbook on adding bias to the embeddings too, right? [00:41:49]
Alessio: Yeah. [00:41:49]
Jerry: There's just like different parameters that you can, you can try adding to try to like optimize the retrieval process. And the idea is just like, okay, by default you have all this text. It kind of lives in some latent space, right? [00:42:01]
Swyx: Yeah. Shut out, shut out latent space. You should take a drink every time. [00:42:05]
Jerry: But it lives in some latent space. But like depending on the type, specific types of questions that the user might want to ask, the latent space might not be optimized to actually retrieve the relevant piece of context that the user want to ask. So can you shift the embedding points a little bit, right? And how do we do that? Basically, that's really a key question here. So optimizing the embedding model, even changing the way you like chunk things, these all shift the embeddings. [00:42:26]
Alessio: So the retrieval is interesting. I got a bunch of startup pitches that are like, like ragged school, but like there's a lot of stuff in terms of ranking that could be better. There's a lot of stuff in terms of sun setting data. Once it starts to become stale, that could be better. Are you going to move into that part too? So like you have SEC Insights as one of kind of like your demos. And that's like a great example of, Hey, I don't want to embed all the historical documents because a lot of them are outdated and I don't want them to be in the context. [00:42:55]
Jerry: What's that problem space? [00:42:57]
Alessio: Like how much of it are you going to also help with and versus how much you expect others to take care of? [00:43:03]
Jerry: Yeah, I'm happy to talk about SEC Insights in just a bit. I think more broadly about the like overall retrieval space. We're very interested in it because a lot of these are very practical problems that [00:43:11]
Alessio: people have asked us. [00:43:11]
Jerry: And so the idea of outdated data, I think, how do you like deprecate or time wait data and do that in a reliable manner, I guess. So you don't just like set some parameter and all of a sudden that affects your, all your retrieval items, like is pretty important because people have started bringing [00:43:25]
Alessio: that up. [00:43:25]
Jerry: Like I have a bunch of duplicate documents, things get out of date. How do I like sunset documents? And then remind me, what was the, what was the first thing you said? Cause I think there was, there was something like the ranking ranking, right? [00:43:35]
Alessio: Yeah. [00:43:35]
Jerry: So I think this space is not new. I think everybody who is new to this space starts learning some basic concepts of information retrieval, which to be fair has been around for quite a bit. But our goal is to kind of like take some of like just general ranking and information retrieval concepts. So by encoding, like crossing coding, right? Like we're based models versus like kind of keyword based search. How do you actually evaluate retrieval? These things start becoming relevant. And so I think for us, like rather than inventing like new retriever techniques for the sake of like just inventing better ranking, we want to take existing ranking techniques and kind of like package it in a way that's like intuitive and easy for people to understand. That said, I think there are interesting and new retrieval techniques that are kind of in place that can be done when you tie it into some downstream rack system. The reason for this is just like, if you think about the idea of like chunking text, right? Like that just really wasn't a thing, or at least for this specific purpose, like the reason chunking is a thing in RAG right now is because like you want to fit within the context bundle of an LLM, right? Like why do you want to chunk a document? That just was less of a thing. I think back then, if you wanted to like transform a document, it was more for like structured data extraction or something in the past. And so there's kind of like certain new concepts that you got to play with that you can use to invent kind of more interesting retrieval techniques. Another example here is actually LLM based reasoning, like LLM based chain of thought reasoning. You can take a question, break it down into smaller components and use that to actually send to your retrieval system. And that gives you better results. And it's kind of like sending the full question to a retrieval system. That also wasn't really a thing back then, but then you can kind of figure out an interesting way to like blending old and the new, right? With LLMs and data. [00:45:13]
Swyx: There's a lot of ideas that you come across. Do you have a store of them? [00:45:17]
Jerry: Yeah, I think I, sometimes I get like inspiration. There's like some problem statement and I'm just like, oh, it's like, following you is [00:45:23]
Swyx: very hard because it's just a lot of homework. [00:45:25]
Jerry: So I think I've, I've started to like step on the brakes just a little bit. Cause then I start, no, no, no. Well, the, the reason is just like, okay, if I just have invent like a hundred more retrieval techniques, like, like sure. But like, how do people know which one is good and which one's like bad. [00:45:41]
Alessio: Right. [00:45:41]
Jerry: And so have a librarian, right? [00:45:42]
Swyx: Like it's going to catalog it and you're going to need some like benchmarks. [00:45:45]
Jerry: And so I think that's probably the focus for the next, next few weeks is actually like properly kind of like having an understanding of like, oh, you know, when should you do this or like, what does this actually work well? [00:45:54]
Alessio: Yeah. [00:45:54]
Swyx: Some kind of like a, maybe like a flow chart, decision tree type of thing. Yeah, exactly. When this do that, you know, something like that, that would be really helpful for me. [00:46:02]
Alessio: Thank you. [00:46:02]
Swyx: It seems like your most successful side project. Yeah. What is SEC Insights for our listeners? [00:46:07]
Jerry: Um, our SEC Insights is a full stack LLM chatbot application, um, that does. Analysis of your sec 10 K and 10 Q filings. And so the goal for building this project is really twofold. The reason we started building this was one, it was a great way to dog food, the production readiness for our library. We actually ended up like adding a bunch of stuff and fixing a ton of bugs because of this. And I think it was great because like, you know, thinking about how we handle like callbacks streaming, actually generating like reliable sub responses and bubbling up sources, citations. These are all things that like, you know, if you're just building the library in isolation, you don't really think about it. But if you're trying to tie this into a downstream application, like it really starts mattering for your error messages. When you talk about bubbling up stuff for like sources, like if you go into SEC Insights and you type something, you can actually see the highlights in the right side. That was something that like took a little bit of like, um, understanding to figure out how to build wall. And so it was great for dog fooding improvement of the library itself. And then as we're building the app, um, the second thing was we're starting to talk to users and just like trying to showcase like kind of, uh, bigger companies, like the potential of LLM index as a framework, because these days obviously building a chatbot, right. With Streamlight or something, it'll take you like 30 minutes or an hour. Like there's plenty of templates out there on LLM index, like train, like you can just build a chatbot, but how do you build something that kind of like satisfies some of these, uh, this like criteria of surfacing, like citations, being transparent, seeing like, uh, having a good UX, um, and then also being able to handle different types of questions, right? Like more complex questions that compare different documents. That's something that I think people are still trying to explore. And so what we did was like, we showed, well, first like organizations, the possibilities of like what you can do when you actually build something like this. And then after like, you know, we kind of like stealth launched this for fun, just as a separate project, uh, just to see if we could get feedback from users who are using this world to see like, you know, how we can improve stuff. And then we were thought, we thought like, ah, you know, we built this, right? Obviously we're not going to sell like a financial app. Like that's not really our, in our wheelhouse, but we're just going to open source the entire thing. And so that now is basically just like a really nice, like full stack app template you can use and customize on your own, right. To build your own chatbot, whether it is a really financial documents or like other types of documents. Um, and it provides like a nice template for basically anybody to kind of like go in and get started. There's certain components though, that like aren't released yet that we're going to going to, and then next few weeks, like one is just like kind of more detailed guides on like different modular components within it. So if you're like a full stack developer, you can go in and actually take the pieces that you want and actually kind of build your own custom flows. The second piece is like, take, there's like certain components in there that might not be directly related to the LLM app that would be nice to just like have people use, uh, an example is the PDF viewer, like the PDF viewer with like citations. I think we're just going to give that right. So, you know, you could be using any library you want, but then you can just, you know, just drop in a PDF viewer. [00:48:53]
Alessio: Right. [00:48:53]
Jerry: So that it's just like a fun little module that you can do. [00:48:55]
Swyx: Nice. That's really good community service right there. I want to talk a little bit about your cloud offering, because you mentioned, I forget the name that you had for it. [00:49:04]
Alessio: Enterprise something. [00:49:04]
Jerry: Well, one, we haven't come up with a name. Uh, we're kind of calling it LLM index platform, platform LLM index enterprise. I'm open to suggestions here. Um, and the second thing is I don't actually know how much I can, I can share right now because it's mostly kind of like, uh, we, we, yeah, exactly. [00:49:20]
Swyx: To the extent that you can talk about LLM index as a business. Um, always just want to give people in the mind, like, Hey, like you sell things too, you know what I mean? [00:49:28]
Jerry: Yeah, a hundred percent. So I think the high level of what I can probably say is just like, I think we're looking at ways of like actively kind of complimenting the developer experience, like building LLM index. We've always been very focused on stuff around like plugging in your data into the language model. And so can we build tools that help like augment that experience beyond the open [00:49:47]
Alessio: source library? Right. [00:49:48]
Jerry: And so I think what we're going to do is like make a build an experience where it's very seamless to transition from the open source library with like a one line toggle, you can basically get this like complimentary service and then figure out a way to like monetize in a bit. I think where our revenue focus this year is less emphasized. Like it's more just about like, can we build some manage offering that like provides complimentary value to what the open source library provides? [00:50:09]
Alessio: Yeah. [00:50:10]
Swyx: I think it's the classic thing about all open source is you want to start building the most popular open source projects in your category to own that category. You're going to make it very easy to host. Therefore you're just built your biggest competitor, which is you. [00:50:22]
Jerry: I think it will be like complimentary. Cause I think it will be like, you know, use the open source library and then you have a toggle and all of a sudden, you know, you can see this basically like a pipeline ish thing pop up and then it will be able to kind of like, you'll have a UI. There'll be some enterprise guarantees and the end goal would be to help you build like a production RAG app more easily. [00:50:42]
Alessio: Data loaders. There's a lot of them. What are maybe some of the most popular, maybe under, not underrated, but like underexpected, you know, and how has the open source side of it helped with like getting a lot more connectors, you only have six people on the team today, so you couldn't have done it all yourself. [00:51:00]
Jerry: Yeah. I think the nice thing about like Walmart hub itself, it's supposed to be a community driven hub. Um, and so actually the bulk of the peers are completely community contributed. Um, and so we haven't written that many like first party connectors actually for this, it's more just like a kind of encouraging people to contribute to the community in terms of the most popular tools, uh, or the data loaders. I think we have Google analytics on this and I forgot the specifics. It's some mix of like the PDF loaders. We have like 10 of them, but there's some subset of them that are popular. And then there's Google, like I think Gmail and like G drive. Um, and then I think maybe it's like one of Slack or notion. One thing I will say though, uh, and I think like Swix might probably knows this better than I do, given that you were, she used to work at air bite. It's very hard to build, like, especially for full on service, like notion Slack or like Salesforce to build like a really, really high quality loader that really extracts all the information that people want. [00:51:51]
Alessio: Right. [00:51:51]
Jerry: And so I think the thing is when people start out, like they will probably use these loaders and it's a great tool to get started. And for a lot of people, it's like good enough. And they submit PRs if they want more additional features. But if you get to a point where you actually want to call like an API that hasn't been supported yet, or, you know, you want to load in stuff that like in metadata or something that hasn't been directly baked into the logic of a loader itself, people start adding up, like writing their own custom loaders. And that is a thing that we're seeing. That's something that we're okay with. [00:52:18]
Alessio: Right. [00:52:18]
Jerry: Cause like a lot of this is more just like community driven. And if you want to submit a PR to improve the existing one, you can, otherwise you can create your own custom ones. [00:52:24]
Alessio: Yeah. [00:52:25]
Swyx: And all that is custom loaders all supported within LLlamaIndex, or do you pair it with something else? [00:52:29]
Jerry: Oh, it's just like, I mean, you just define your own subclass. I think, I think that's it. [00:52:33]
Alessio: Yeah. Yeah. [00:52:33]
Swyx: Cause typically in the data ecosystem with everybody, everybody has his own strategies with custom loaders, but also you could write your own with like Dagster or like Prefect or one of those tools. [00:52:43]
Alessio: Yeah. [00:52:44]
Jerry: Yeah, exactly. So I think for us, it's more, we just have a very flexible like document abstraction that you can fill in with any content that you want. [00:52:50]
Swyx: Are people really dumping all their Gmail into these things? You said Gmail is number two. Uh, I'm not sure actually. I mean, that's these, you know, that's the most private data source. [00:52:59]
Alessio: That's true. [00:53:00]
Swyx: So I'm surprised that people are dumping too. I mean, I'm sure some, some people are, but like, I'm sure I'm surprised it's [00:53:06]
Alessio: popular. [00:53:06]
Swyx: Well, and then, so, uh, the LLM engine, uh, I assume OpenAI is going to be a majority. Is it an overwhelming majority? Uh, how, what's the market share between like OpenAI, Cohere, Anthropic, you know, whatever you're seeing. [00:53:21]
Alessio: OpenSource too. [00:53:21]
Jerry: Yeah, I think it's probably some, uh, OpenAI has a majority, but then like there's Anthropic and there's also, um, OpenSource. I think there is a lot of people trying out like Llama 2, um, and, and, um, some variant of like a top OpenSource model. [00:53:33]
Swyx: Side note, any confusion there, Llama 2 versus Llama? [00:53:36]
Jerry: Yeah, I think whenever I go to these talks, I always open it up with like, we started before it. Yeah, exactly. We start before meta, right? [00:53:43]
Alessio: I want to point that out. [00:53:43]
Jerry: Uh, but no, for us, we try to use it for like branding. We just add two llamas when we have like a Llama 2 integration instead of one llama. So I think a lot of people are trying out the popular OpenSource models. Uh, there's a lot of toolkits and OpenSource projects that allow you to self-host and deploy Llama 2 and like, oh, Llama is just a very recent example. I think that we, we added integration with, and so we just, uh, by virtue of having more of these services, I think more and more people are trying it out. [00:54:07]
Swyx: Do you think there's, there's potential there? Is like, um, is that going to be an increasing trend? Like OpenSource? [00:54:12]
Alessio: Yeah. [00:54:12]
Jerry: Yeah, definitely. I think in general people hate monopolies. And so, um, like there's a, whenever like OpenAI has something really cool or like any, um, company has something really cool, even meta, like there's just going to be a huge competitive pressure from other people to do something that's more open and better. Um, and so I do think just market pressures will, will improve like OpenSource adoption. [00:54:32]
Swyx: Last thing I'll say about this, which is just really like, it gets clicks. It's people like psychologically want that, but then at the end of the day, they want, they fall for brand name and popular and performance benchmarks. You know, at the end of the day, OpenAI still wins on that. I think that's true. [00:54:47]
Jerry: But I, I just think like, unless you were like an active employee at OpenAI, right? Like all these research labs are putting out like ML, like PhDs or kind of like other companies too, that are investing a lot of dollars. Uh, there's going to be a lot of like competitive pressures developed, like better models. So is it going to be like all fully open source with like a permissive license? Like, I'm not completely sure, but like, there's just a lot of just incentive for people to develop their stuff here. [00:55:09]
Swyx: Have you looked at like RAG specific models, like contextual? [00:55:12]
Alessio: No. [00:55:13]
Jerry: Is it public? [00:55:14]
Swyx: No, they literally just, uh, so Dewey Keeler. I think it's his name. And you probably came across him. He wrote the RAG paper at Meta and just started contextual AI to create a RAG specific model. I don't know what that means. I was hoping that you do, cause it's your business. [00:55:29]
Jerry: I had insider information. I mean, you know, to be honest, I think this, this kind of relates to my previous point on like RAG and fine tuning, like a RAG specific model is a model architecture that's designed for better RAG and it's less the software engineering principle of like, how can I take existing stuff and just plug and play different components into it? Um, and there's a beauty in that from ease of use and modularity, but when you want to end to end optimize the thing, you might want a more specific model. I think, I think building your own models is honestly pretty hard. Um, and I think the issue is if you also build your own models, like you're also just gonna have to keep up with like the rate of LM advances, like how, like basically the question is when GPT five and six and whatever, like anthropic cloud three comes out, how can you prove that you're actually better than, uh, software developers cobbling together and components on top of a base model. Right. Even if it's just like conceptually, this is better than maybe like GPT three or GPT four. [00:56:21]
Alessio: What about vector stores? I know Spooks is wearing a chroma sweatshirt. [00:56:25]
Swyx: Yeah, because they use a swagging. [00:56:27]
Jerry: I have, I have the mug from Chroma. [00:56:29]
Alessio: Yeah. It's been great. Yeah. [00:56:30]
Jerry: What do you think there? [00:56:31]
Alessio: Like there's a lot of them. Are they pretty interchangeable for like your users use case? Uh, is HNSW all we need? Is there room for improvements? [00:56:40]
Swyx: Is NTRA all we need? [00:56:42]
Jerry: I think, um, yeah, we try to remain unopinionated about storage providers. So it's not like we don't try to like play favorites. So we have like a bunch of integrations obviously. And we, the way we try to do it is we just tried to find like some standard interfaces, but obviously like different vector stores will support kind of like, uh, slightly additional things like metadata filters and those things. I mean, the goal is to have our users basically leave it up to them to try to figure out like what makes sense for their use case in terms of like the algorithm itself, I don't think the Delta on like improving the vector store, like. Embedding lookup algorithm. [00:57:10]
Alessio: Is that high? [00:57:10]
Jerry: I think the stuff has been mostly solved or at least there's just a lot of other stuff you can do to try to improve the overall performance. No, I mean like everything else that we just talked about, like in terms of like [00:57:20]
Alessio: accuracy, right. [00:57:20]
Jerry: To improve rag, like everything that we talked about, like chunking, like metadata, like. [00:57:24]
Swyx: I mean, I was just thinking like, maybe for me, the interesting question is, you know, there are like eight, it's a kind of game of thrones. There's like eight, the war of eight databases right now. Oh, I see. Um, how do they stand out and how did they become very good partners? [00:57:36]
Alessio: If not my index. [00:57:36]
Jerry: Yeah, we're pretty good partners with, with most of them. [00:57:39]
Alessio: Uh, let's see. [00:57:39]
Swyx: Well, like if you're a, you know, vector database founder, like what do you, what do you work on? [00:57:44]
Alessio: It's a good question. [00:57:44]
Jerry: I think one thing I'm very interested in is, and this is something I think I've started to see a general trend towards is combining structured data querying with unstructured data querying. Um, and I think that will probably just expand the query sophistication of these vector stores and basically make it so that users don't have to think about whether they would just call this like hybrid querying. [00:58:05]
Swyx: Is that what we've it's doing? [00:58:06]
Alessio: Yeah. [00:58:07]
Jerry: I mean, I think like, if you think about metadata filters, that's basically a structured filter. It's like our select where something equals something, and then you combine that with semantic search. I think like Lance DB or something was like, uh, try, I was trying to do some like joint interface. The reason is like most data is semi-structured. There's some structured annotations and there's some like unstructured texts. And so like, um, somehow combining all the expressivity of like SQL with like the flexibility of semantic search is something that I think is going to be really important. We have some basic hacks right now that allow you to jointly query both a SQL database and like a separate SQL database and a vector store to like combine the information. That's obviously going to be less efficient than if you just combined it into one [00:58:46]
Alessio: system. Yeah. [00:58:46]
Jerry: And so I think like PG vector, like, you know, that type of stuff, I think it's starting to get there, but like in general, like how do you have an expressive query language to actually do like structured querying along with like all the capabilities, semantic search. [00:58:57]
Swyx: So your current favorite is just put it into Postgres. No, no, no. We don't play with Postgres language, the query language. [00:59:05]
Jerry: I actually don't know what the best language would be for this, because I think it will be something that like the model hasn't been fine-tuned over. Um, and so you might want to train the model over this, but some way of like expressing structured data filters, and this could be include time too, right? It could, it doesn't have to just be like a where clause with this idea of like a [00:59:26]
Alessio: semantic search. Yeah. [00:59:27]
Swyx: And we talked about, uh, graph representations. [00:59:30]
Alessio: Yeah. Oh yeah. [00:59:30]
Jerry: That's another thing too. And there's like, yeah. So that's actually something I didn't even bring up yet. Like there's this interesting idea of like, can you actually have the language model, like explore like relationships within the data too, right? And somehow combine that information with stuff that's like more and more, um, structured within the DB. [00:59:46]
Alessio: Awesome. [00:59:46]
Swyx: What are your current strong beliefs about how to evaluate RAG ? [00:59:49]
Jerry: I think I have thoughts. I think we're trying to curate this into some like more opinionated principles because there's some like open questions here. I think one question I had to think about is whether you should do like evals like component by component first, or is yours do the end to end thing? I think you should, you might actually just want to do the end to end thing first, just to do a sanity check of whether or not like this, uh, given a query and the final response, whether or not it even makes sense, like you eyeball [01:00:11]
Alessio: it, right. [01:00:11]
Jerry: And then you like try to do some basic evals. And then once you like diagnose what the issue is, then you go into the kind of like specific area to define some more, uh, solid benchmarks and try to like [01:00:21]
Alessio: improve stuff. [01:00:21]
Jerry: So what is Antoine evals? Like it's, you, um, have a query, it goes in through retrieval system. You get back something, you synthesize response, and that's your final thing. And you evaluate the quality of the final response. And these days, there's plenty of projects like startups, like companies research, doing stuff around like GPT-4, right. As like a human judge to basically kind of like synthetically generate data. [01:00:41]
Swyx: I don't know from the startup side. [01:00:43]
Jerry: I just know from a technical side, I think, I think people are going to do more of it. The main issue right now is just, uh, it's really unreliable. Like it's, it's just, uh, like there's like variants on the response, whatever you want. [01:00:54]
Alessio: They won't do more of it. [01:00:54]
Swyx: I mean, cause it's bad. [01:00:55]
Jerry: No, but, but these models will get better and you'll probably fine tune a model to [01:00:59]
Alessio: be a better judge. [01:00:59]
Jerry: I think that's probably what's going to happen. So I'm like reasonably bullish on this because I don't think there's really a good alternative beyond you just human annotating a bunch of data sets, um, and then trying to like just manually go through and curating, like evaluating eval metrics. And so this is just going to be a more scalable solution in terms of the [01:01:17]
Alessio: startups. Yeah. [01:01:17]
Jerry: I mean, I think there's a bunch of companies doing this in the end. It probably comes down to some aspect of like UX speed, whether you can like fine tune a model. So that's end to end evals. And then I think like what we found is for rag, a lot of times, like, uh, what ends up affecting this, like end response is retrieval. You're just not able to retrieve the right response. And so I think having proper retrieval benchmarks, especially if you want to do production RAG is, is actually quite important. I think what does having good retrieval metrics tell you? It tells you that at least like the retrieval is good. It doesn't necessarily guarantee the end generation is good, but at least it gives you some, uh, sanity track, right? So you can like fix one component while optimizing the rest, what retrieval like evaluation is pretty standard. And it's been around for a while. It's just like an IR problem. Basically you have some like input query, you get back some retrieves out of context, and then there's some ground truth and that ranked set. And then you try to measure it based on ranking metrics. So the closer that ground truth is to the top, the more you reward the evals. And then the closer it is to the bottom where if it's not in the retrieve side at all, then you penalize the evals. Um, and so that's just like a classic ranking problem. I think like most people starting out probably don't know how to do this right [01:02:28]
Alessio: now. [01:02:28]
Jerry: We, we just launched them like basic retrieval evaluation modules to help users [01:02:32]
Alessio: do this. [01:02:32]
Jerry: One is just like curating this data set in the first place. And one thing that we're very interested in is this idea of like synthetic data set generation for evals. So how can you give in some context, generate a set of questions with Drupal 2.4, and then all of a sudden you have like question and then context pairs, and that becomes your ground truth. [01:02:47]
Swyx: Are data agent evals the same thing, or is there a separate set of stuff for agents that you think is relevant here? [01:02:53]
Jerry: Yeah, I think data agents add like another layer of complexity. Cause then it's just like, you have just more loops in the system. Like you can evaluate like each chain of thought loop itself, like every LLM call to see whether or not the input to that specific step in the chain of thought process actually works or is correct. Or you can evaluate like the final response to see if that's correct. This gets even more complicated when you do like multi-agent stuff, because now you have like some communication between like different agents. Like you have a top level orchestration agent passing it on to some low level [01:03:24]
Alessio: stuff. [01:03:24]
Jerry: I'm probably less familiar with kind of like agent eval frameworks. I know they're, they're starting to be, become a thing. Talking to like June from the Drown of Agents paper, which is pretty unrelated to what we're doing now. But it's very interesting where it's like, so you can kind of evaluate like overall agent simulations by just like kind of understanding whether or not they like modeled the distribution of human behavior. But that's not like a very macro principle. [01:03:46]
Alessio: Right. [01:03:46]
Jerry: And that's very much to evaluate stuff, to kind of like model the distribution of [01:03:51]
Alessio: things. [01:03:51]
Jerry: And I think that works well when you're trying to like generate something for like creative purposes, but for stuff where you really want the agent to like achieve a certain task, it really is like whether or not it achieved the task or not. [01:04:01]
Alessio: Right. [01:04:01]
Jerry: Cause then it's not like, Oh, does it generally mimic human behavior? It's like, no, like did you like send this email or not? [01:04:07]
Alessio: Right. [01:04:07]
Jerry: Like, cause otherwise like this, this thing didn't work. [01:04:09]
Alessio: Awesome. Let's jump into a lightning round. So we have two questions, acceleration, exploration, and then one final tag away. The acceleration question is what's something that already happened in AI that you thought would take much longer to get here? [01:04:23]
Jerry: I think just the ability of LLMs to generate believable outputs and for text and also for images. And I think just the whole reason I started hacking around with LLMs, honestly, I felt like I got into it pretty late. I should've gotten into it like early 2022 because UB23 had been out for a while. Like just the fact that there was this engine that was capable of like reasoning and no one was really like tapping into it. And then the fact that, you know, I used to work in image generation for a while. Like I did GANs and stuff back in the day. And that was like pretty hard to train. You would generate these like 32 by 32 images. And then now taking a look at some of the stuff by like Dolly and, and, you know, mid journey and those things. So it's, it's just, it's, it's very good. [01:04:59]
Alessio: Yeah. [01:04:59]
Swyx: Exploration. What do you think is the most interesting unsolved question in AI? [01:05:03]
Jerry: Yeah, I'd probably work on some aspect of, um, like personalization of memory. Like, I think I actually think that I don't think anyone's like, I think a lot of people have thoughts about that, but like, for what it's worth, I don't think the final state will be right. I think it will be some, some like fancy algorithm or architecture where you like bake it into like the, the architecture of the model itself. Like if, if you have like a personalized assistant that you can talk to that will like learn behaviors over time, right. And learn stuff through like conversation history, what exactly is the right architecture there? I do think that will be part of like the wrong continuous fine tuning. [01:05:38]
Swyx: Yeah. [01:05:39]
Jerry: Like some aspect of that, right. [01:05:40]
Alessio: Right. [01:05:40]
Jerry: Like these are like, I don't actually know the specific technique, but I don't think it's just going to be something where you have like a fixed vector store and that, that thing will be like the thing that restores all your memories. [01:05:48]
Swyx: It's interesting because I feel like using model weights for memory, it's just such an unreliable storage device. [01:05:56]
Jerry: I know. But like, I just think, uh, from like the AGI, like, you know, just modeling like the human brain perspective, I think that there is something nice about just like being able to optimize that system. [01:06:08]
Alessio: Right. [01:06:08]
Jerry: And to optimize a system, you need parameters and then that's where you just get into the neural net piece. [01:06:12]
Alessio: Cool. Cool. Uh, and yeah, take away, you got the audience ear. What's something you want everyone to think about or yeah, take away from this conversation and your thinking. [01:06:24]
Jerry: I think there were a few key things. Uh, so we talked about two of them already, which was SEC Insights, which if you guys haven't tracked it out, I've definitely encouraged you to do so because it's not just like a random like sec app, it's like a full stack thing that we open source, right. And so if you guys want to track it out, I would definitely do that. It provides a template for you to build kind of like production grade rack apps. Um, and we're going to open source like, and modularize more components of that soon and do a workshop on, um, yeah. And the second piece is I think we are thinking a lot about like retrieval and evals. Um, I think right now we're kind of exploring integrations with like a few different partners. And so hopefully some of that will be, uh, really soon. And so just like, how do you basically have an experience where you just like write law index code, all of a sudden you can easily run like retrievals, evals, and like traces, all that stuff. And, and like a service. And so I think we're working with like a few providers on that. And then the other piece, which we did talk about already is this idea of like, yeah, building like RAG from scratch. I mean, I think everybody should do it. I think I would check out the guide. If you guys haven't already, I think it's in our docs, but instead of just using, you know, either the kind of like the retriever query engine and lamin decks or like the conversational QA train and Lang train, it's, I would take a look at how do you actually chunk parse data and do like top cam batting retrieval, because I really think that by doing that process, it helps you understand the decisions, the prompts, the language models to use. [01:07:42]
Alessio: That's it. Yeah. [01:07:44]
Swyx: Thank you so much, Jerry. [01:07:45]
Alessio: Yeah. [01:07:45]
Jerry: Thank you. [01:07:46]
