


We’re writing this one day after the monster release of OpenAI’s Sora and Gemini 1.5. We covered this on Alex Volkov ‘s ThursdAI space, so head over there for our takes.
IRL: We’re ONE WEEK away from Latent Space: Final Frontiers, the second edition and anniversary of our first ever Latent Space event! Also: join us on June 25-27 for the biggest AI Engineer conference of the year!
Online: All three Discord clubs are thriving. Join us every Wednesday/Friday!
Almost 12 years ago, while working at Spotify, Erik Bernhardsson built one of the first open source vector databases, Annoy, based on ANN search. He also built Luigi, one of the predecessors to Airflow, which helps data teams orchestrate and execute data-intensive and long-running jobs. Surprisingly, he didn’t start yet another vector database company, but instead in 2021 founded Modal, the “high-performance cloud for developers”. In 2022 they opened doors to developers after their seed round, and in 2023 announced their GA with a $16m Series A.
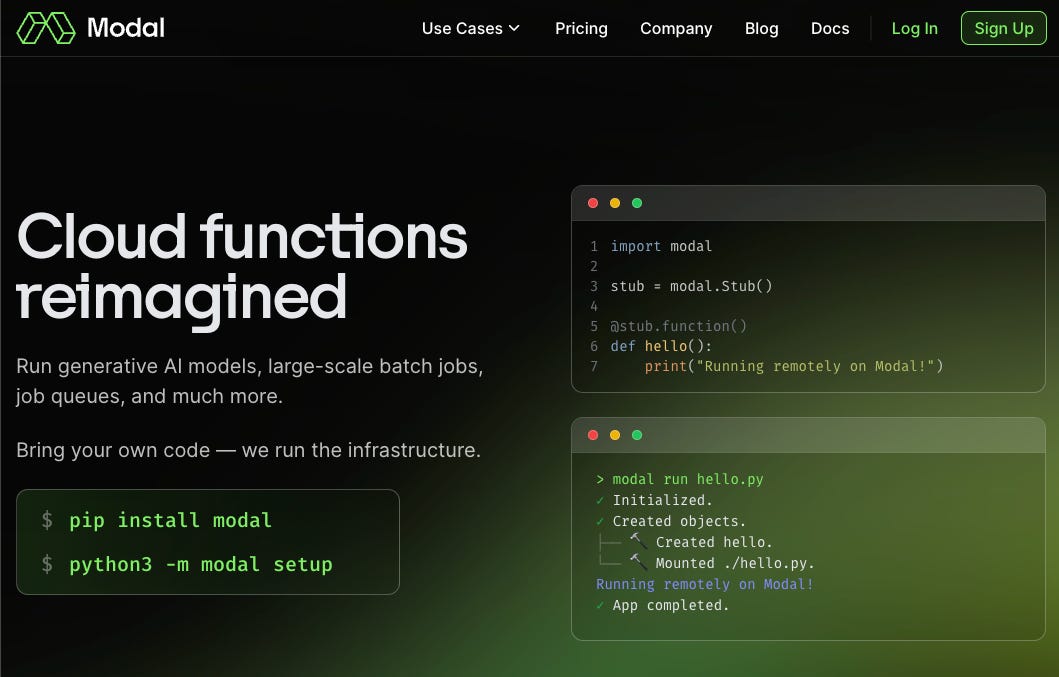
More importantly, they have won fans among both household names like Ramp, Scale AI, Substack, and Cohere, and newer startups like (upcoming guest!) Suno.ai and individual hackers (Modal was the top tool of choice in the Vercel AI Accelerator):

We've covered the nuances of GPU workloads, and how we need new developer tooling and runtimes for them (see our episodes with Chris Lattner of Modular and George Hotz of tiny to start). In this episode, we run through the major limitations of the actual infrastructure behind the clouds that run these models, and how Erik envisions the “postmodern data stack”.
In his 2021 blog post “Software infrastructure 2.0: a wishlist”, Erik had “Truly serverless” as one of his points:
The word cluster is an anachronism to an end-user in the cloud! I'm already running things in the cloud where there's elastic resources available at any time. Why do I have to think about the underlying pool of resources? Just maintain it for me.
I don't ever want to provision anything in advance of load.
I don't want to pay for idle resources. Just let me pay for whatever resources I'm actually using.
Serverless doesn't mean it's a burstable VM that saves its instance state to disk during periods of idle.
Swyx called this Self Provisioning Runtimes back in the day. Modal doesn’t put you in YAML hell, preferring to colocate infra provisioning right next to the code that utilizes it, so you can just add GPU (and disk, and retries…):

After 3 years, we finally have a big market push for this: running inference on generative models is going to be the killer app for serverless, for a few reasons:
AI models are stateless: even in conversational interfaces, each message generation is a fully-contained request to the LLM. There’s no knowledge that is stored in the model itself between messages, which means that tear down / spin up of resources doesn’t create any headaches with maintaining state.
Token-based pricing is better aligned with serverless infrastructure than fixed monthly costs of traditional software.
GPU scarcity makes it really expensive to have reserved instances that are available to you 24/7. It’s much more convenient to build with a serverless-like infrastructure.
In the episode we covered a lot more topics like maximizing GPU utilization, why Oracle Cloud rocks, and how Erik has never owned a TV in his life. Enjoy!
Show Notes
Chapters
[00:00:00] Introductions
[00:02:00] Erik's OSS work at Spotify: Annoy and Luigi
[00:06:22] Starting Modal
[00:07:54] Vision for a "postmodern data stack"
[00:10:43] Solving container cold start problems
[00:12:57] Designing Modal's Python SDK
[00:15:18] Self-Revisioning Runtime
[00:19:14] Truly Serverless Infrastructure
[00:20:52] Beyond model inference
[00:22:09] Tricks to maximize GPU utilization
[00:26:27] Differences in AI and data science workloads
[00:28:08] Modal vs Replicate vs Modular and lessons from Heroku's "graduation problem"
[00:34:12] Creating Erik's clone "ErikBot"
[00:37:43] Enabling massive parallelism across thousands of GPUs
[00:39:45] The Modal Sandbox for agents
[00:43:51] Thoughts on the AI Inference War
[00:49:18] Erik's best tweets
[00:51:57] Why buying hardware is a waste of money
[00:54:18] Erik's competitive programming backgrounds
[00:59:02] Why does Sweden have the best Counter Strike players?
[00:59:53] Never owning a car or TV
[01:00:21] Advice for infrastructure startups
Transcript
Alessio [00:00:00]: Hey everyone, welcome to the Latent Space podcast. This is Alessio, partner and CTO-in-Residence at Decibel Partners, and I'm joined by my co-host Swyx, founder of Smol AI.
Swyx [00:00:14]: Hey, and today we have in the studio Erik Bernhardsson from Modal. Welcome.
Erik [00:00:19]: Hi. It's awesome being here.
Swyx [00:00:20]: Yeah. Awesome seeing you in person. I've seen you online for a number of years as you were building on Modal and I think you're just making a San Francisco trip just to see people here, right? I've been to like two Modal events in San Francisco here.
Erik [00:00:34]: Yeah, that's right. We're based in New York, so I figured sometimes I have to come out to capital of AI and make a presence.
Swyx [00:00:40]: What do you think is the pros and cons of building in New York?
Erik [00:00:45]: I mean, I never built anything elsewhere. I lived in New York the last 12 years. I love the city. Obviously, there's a lot more stuff going on here and there's a lot more customers and that's why I'm out here. I do feel like for me, where I am in life, I'm a very boring person. I kind of work hard and then I go home and hang out with my kids. I don't have time to go to events and meetups and stuff anyway. In that sense, New York is kind of nice. I walk to work every morning. It's like five minutes away from my apartment. It's very time efficient in that sense. Yeah.
Swyx [00:01:10]: Yeah. It's also a good life. So we'll do a brief bio and then we'll talk about anything else that people should know about you. Actually, I was surprised to find out you're from Sweden. You went to college in KTH and your master's was in implementing a scalable music recommender system. Yeah.
Erik [00:01:27]: I had no idea. Yeah. So I actually studied physics, but I grew up coding and I did a lot of programming competition and then as I was thinking about graduating, I got in touch with an obscure music streaming startup called Spotify, which was then like 30 people. And for some reason, I convinced them, why don't I just come and write a master's thesis with you and I'll do some cool collaborative filtering, despite not knowing anything about collaborative filtering really. But no one knew anything back then. So I spent six months at Spotify basically building a prototype of a music recommendation system and then turned that into a master's thesis. And then later when I graduated, I joined Spotify full time.
Swyx [00:02:00]: So that was the start of your data career. You also wrote a couple of popular open source tooling while you were there. Is that correct?
Erik [00:02:09]: No, that's right. I mean, I was at Spotify for seven years, so this is a long stint. And Spotify was a wild place early on and I mean, data space is also a wild place. I mean, it was like Hadoop cluster in the like foosball room on the floor. It was a lot of crude, like very basic infrastructure and I didn't know anything about it. And like I was hired to kind of figure out data stuff. And I started hacking on a recommendation system and then, you know, got sidetracked in a bunch of other stuff. I fixed a bunch of reporting things and set up A-B testing and started doing like business analytics and later got back to music recommendation system. And a lot of the infrastructure didn't really exist. Like there was like Hadoop back then, which is kind of bad and I don't miss it. But I spent a lot of time with that. As a part of that, I ended up building a workflow engine called Luigi, which is like briefly like somewhat like widely ended up being used by a bunch of companies. Sort of like, you know, kind of like Airflow, but like before Airflow. I think it did some things better, some things worse. I also built a vector database called Annoy, which is like for a while, it was actually quite widely used. In 2012, so it was like way before like all this like vector database stuff ended up happening. And funny enough, I was actually obsessed with like vectors back then. Like I was like, this is going to be huge. Like just give it like a few years. I didn't know it was going to take like nine years and then there's going to suddenly be like 20 startups doing vector databases in one year. So it did happen. In that sense, I was right. I'm glad I didn't start a startup in the vector database space. I would have started way too early. But yeah, that was, yeah, it was a fun seven years as part of it. It was a great culture, a great company.
Swyx [00:03:32]: Yeah. Just to take a quick tangent on this vector database thing, because we probably won't revisit it but like, has anything architecturally changed in the last nine years?
Erik [00:03:41]: I'm actually not following it like super closely. I think, you know, some of the best algorithms are still the same as like hierarchical navigable small world.
Swyx [00:03:51]: Yeah. HNSW.
Erik [00:03:52]: Exactly. I think now there's like product quantization, there's like some other stuff that I haven't really followed super closely. I mean, obviously, like back then it was like, you know, it's always like very simple. It's like a C++ library with Python bindings and you could mmap big files and into memory and like they had some lookups. I used like this kind of recursive, like hyperspace splitting strategy, which is not that good, but it sort of was good enough at that time. But I think a lot of like HNSW is still like what people generally use. Now of course, like databases are much better in the sense like to support like inserts and updates and stuff like that. I know I never supported that. Yeah, it's sort of exciting to finally see like vector databases becoming a thing.
Swyx [00:04:30]: Yeah. Yeah. And then maybe one takeaway on most interesting lesson from Daniel Ek?
Erik [00:04:36]: I mean, I think Daniel Ek, you know, he started Spotify very young. Like he was like 25, something like that. And that was like a good lesson. But like he, in a way, like I think he was a very good leader. Like there was never anything like, no scandals or like no, he wasn't very eccentric at all. It was just kind of like very like level headed, like just like ran the company very well, like never made any like obvious mistakes or I think it was like a few bets that maybe like in hindsight were like a little, you know, like took us, you know, too far in one direction or another. But overall, I mean, I think he was a great CEO, like definitely, you know, up there, like generational CEO, at least for like Swedish startups.
Swyx [00:05:09]: Yeah, yeah, for sure. Okay, we should probably move to make our way towards Modal. So then you spent six years as CTO of Better. You were an early engineer and then you scaled up to like 300 engineers.
Erik [00:05:21]: I joined as a CTO when there was like no tech team. And yeah, that was a wild chapter in my life. Like the company did very well for a while. And then like during the pandemic, yeah, it was kind of a weird story, but yeah, it kind of collapsed.
Swyx [00:05:32]: Yeah, laid off people poorly.
Erik [00:05:34]: Yeah, yeah. It was like a bunch of stories. Yeah. I mean, the company like grew from like 10 people when I joined at 10,000, now it's back to a thousand. But yeah, they actually went public a few months ago, kind of crazy. They're still around, like, you know, they're still, you know, doing stuff. So yeah, very kind of interesting six years of my life for non-technical reasons, like I managed like three, four hundred, but yeah, like learning a lot of that, like recruiting. I spent all my time recruiting and stuff like that. And so managing at scale, it's like nice, like now in a way, like when I'm building my own startup. It's actually something I like, don't feel nervous about at all. Like I've managed a scale, like I feel like I can do it again. It's like very different things that I'm nervous about as a startup founder. But yeah, I started Modal three years ago after sort of, after leaving Better, I took a little bit of time off during the pandemic and, but yeah, pretty quickly I was like, I got to build something. I just want to, you know. Yeah. And then yeah, Modal took form in my head, took shape.
Swyx [00:06:22]: And as far as I understand, and maybe we can sort of trade off questions. So the quick history is started Modal in 2021, got your seed with Sarah from Amplify in 2022. You just announced your Series A with Redpoint. That's right. And that brings us up to mostly today. Yeah. Most people, I think, were expecting you to build for the data space.
Erik: But it is the data space.
Swyx:: When I think of data space, I come from like, you know, Snowflake, BigQuery, you know, Fivetran, Nearby, that kind of stuff. And what Modal became is more general purpose than that. Yeah.
Erik [00:06:53]: Yeah. I don't know. It was like fun. I actually ran into like Edo Liberty, the CEO of Pinecone, like a few weeks ago. And he was like, I was so afraid you were building a vector database. No, I started Modal because, you know, like in a way, like I work with data, like throughout my most of my career, like every different part of the stack, right? Like I thought everything like business analytics to like deep learning, you know, like building, you know, training neural networks, the scale, like everything in between. And so one of the thoughts, like, and one of the observations I had when I started Modal or like why I started was like, I just wanted to make, build better tools for data teams. And like very, like sort of abstract thing, but like, I find that the data stack is, you know, full of like point solutions that don't integrate well. And still, when you look at like data teams today, you know, like every startup ends up building their own internal Kubernetes wrapper or whatever. And you know, all the different data engineers and machine learning engineers end up kind of struggling with the same things. So I started thinking about like, how do I build a new data stack, which is kind of a megalomaniac project, like, because you kind of want to like throw out everything and start over.
Swyx [00:07:54]: It's almost a modern data stack.
Erik [00:07:55]: Yeah, like a postmodern data stack. And so I started thinking about that. And a lot of it came from like, like more focused on like the human side of like, how do I make data teams more productive? And like, what is the technology tools that they need? And like, you know, drew out a lot of charts of like, how the data stack looks, you know, what are different components. And it shows actually very interesting, like workflow scheduling, because it kind of sits in like a nice sort of, you know, it's like a hub in the graph of like data products. But it was kind of hard to like, kind of do that in a vacuum, and also to monetize it to some extent. I got very interested in like the layers below at some point. And like, at the end of the day, like most people have code to have to run somewhere. So I think about like, okay, well, how do you make that nice? Like how do you make that? And in particular, like the thing I always like thought about, like developer productivity is like, I think the best way to measure developer productivity is like in terms of the feedback loops, like how quickly when you iterate, like when you write code, like how quickly can you get feedback. And at the innermost loop, it's like writing code and then running it. And like, as soon as you start working with the cloud, like it's like takes minutes suddenly, because you have to build a Docker container and push it to the cloud and like run it, you know. So that was like the initial focus for me was like, I just want to solve that problem. Like I want to, you know, build something less, you run things in the cloud and like retain the sort of, you know, the joy of productivity as when you're running things locally. And in particular, I was quite focused on data teams, because I think they had a couple unique needs that wasn't well served by the infrastructure at that time, or like still is in like, in particular, like Kubernetes, I feel like it's like kind of worked okay for back end teams, but not so well for data teams. And very quickly, I got sucked into like a very deep like rabbit hole of like...
Swyx [00:09:24]: Not well for data teams because of burstiness. Yeah, for sure.
Erik [00:09:26]: So like burstiness is like one thing, right? Like, you know, like you often have this like fan out, you want to like apply some function over very large data sets. Another thing tends to be like hardware requirements, like you need like GPUs and like, I've seen this in many companies, like you go, you know, data scientists go to a platform team and they're like, can we add GPUs to the Kubernetes? And they're like, no, like, that's, you know, complex, and we're not gonna, so like just getting GPU access. And then like, I mean, I also like data code, like frankly, or like machine learning code like tends to be like, super annoying in terms of like environments, like you end up having like a lot of like custom, like containers and like environment conflicts. And like, it's very hard to set up like a unified container that like can serve like a data scientist, because like, there's always like packages that break. And so I think there's a lot of different reasons why the technology wasn't well suited for back end. And I think the attitude at that time is often like, you know, like you had friction between the data team and the platform team, like, well, it works for the back end stuff, you know, why don't you just like, you know, make it work. But like, I actually felt like data teams, you know, or at this point now, like there's so much, so many people working with data, and like they, to some extent, like deserve their own tools and their own tool chains, and like optimizing for that is not something people have done. So that's, that's sort of like very abstract philosophical reason why I started Model. And then, and then I got sucked into this like rabbit hole of like container cold start and, you know, like whatever, Linux, page cache, you know, file system optimizations.
Swyx [00:10:43]: Yeah, tell people, I think the first time I met you, I think you told me some numbers, but I don't remember, like, what are the main achievements that you were unhappy with the status quo? And then you built your own container stack?
Erik [00:10:52]: Yeah, I mean, like, in particular, it was like, in order to have that loop, right? You want to be able to start, like take code on your laptop, whatever, and like run in the cloud very quickly, and like running in custom containers, and maybe like spin up like 100 containers, 1000, you know, things like that. And so container cold start was the initial like, from like a developer productivity point of view, it was like, really, what I was focusing on is, I want to take code, I want to stick it in container, I want to execute in the cloud, and like, you know, make it feel like fast. And when you look at like, how Docker works, for instance, like Docker, you have this like, fairly convoluted, like very resource inefficient way, they, you know, you build a container, you upload the whole container, and then you download it, and you run it. And Kubernetes is also like, not very fast at like starting containers. So like, I started kind of like, you know, going a layer deeper, like Docker is actually like, you know, there's like a couple of different primitives, but like a lower level primitive is run C, which is like a container runner. And I was like, what if I just take the container runner, like run C, and I point it to like my own root file system, and then I built like my own virtual file system that exposes files over a network instead. And that was like the sort of very crude version of model, it's like now I can actually start containers very quickly, because it turns out like when you start a Docker container, like, first of all, like most Docker images are like several gigabytes, and like 99% of that is never going to be consumed, like there's a bunch of like, you know, like timezone information for like Uzbekistan, like no one's going to read it. And then there's a very high overlap between the files are going to be read, there's going to be like lib torch or whatever, like it's going to be read. So you can also cache it very well. So that was like the first sort of stuff we started working on was like, let's build this like container file system. And you know, coupled with like, you know, just using run C directly. And that actually enabled us to like, get to this point of like, you write code, and then you can launch it in the cloud within like a second or two, like something like that. And you know, there's been many optimizations since then, but that was sort of starting point.
Alessio [00:12:33]: Can we talk about the developer experience as well, I think one of the magic things about Modal is at the very basic layers, like a Python function decorator, it's just like stub and whatnot. But then you also have a way to define a full container, what were kind of the design decisions that went into it? Where did you start? How easy did you want it to be? And then maybe how much complexity did you then add on to make sure that every use case fit?
Erik [00:12:57]: I mean, Modal, I almost feel like it's like almost like two products kind of glued together. Like there's like the low level like container runtime, like file system, all that stuff like in Rust. And then there's like the Python SDK, right? Like how do you express applications? And I think, I mean, Swix, like I think your blog was like the self-provisioning runtime was like, to me, always like to sort of, for me, like an eye-opening thing. It's like, so I didn't think about like...
Swyx [00:13:15]: You wrote your post four months before me. Yeah? The software 2.0, Infra 2.0. Yeah.
Erik [00:13:19]: Well, I don't know, like convergence of minds. I guess we were like both thinking. Maybe you put, I think, better words than like, you know, maybe something I was like thinking about for a long time. Yeah.
Swyx [00:13:29]: And I can tell you how I was thinking about it on my end, but I want to hear you say it.
Erik [00:13:32]: Yeah, yeah, I would love to. So to me, like what I always wanted to build was like, I don't know, like, I don't know if you use like Pulumi. Like Pulumi is like nice, like in the sense, like it's like Pulumi is like you describe infrastructure in code, right? And to me, that was like so nice. Like finally I can like, you know, put a for loop that creates S3 buckets or whatever. And I think like Modal sort of goes one step further in the sense that like, what if you also put the app code inside the infrastructure code and like glue it all together and then like you only have one single place that defines everything and it's all programmable. You don't have any config files. Like Modal has like zero config. There's no config. It's all code. And so that was like the goal that I wanted, like part of that. And then the other part was like, I often find that so much of like my time was spent on like the plumbing between containers. And so my thing was like, well, if I just build this like Python SDK and make it possible to like bridge like different containers, just like a function call, like, and I can say, oh, this function runs in this container and this other function runs in this container and I can just call it just like a normal function, then, you know, I can build these applications that may span a lot of different environments. Maybe they fan out, start other containers, but it's all just like inside Python. You just like have this beautiful kind of nice like DSL almost for like, you know, how to control infrastructure in the cloud. So that was sort of like how we ended up with the Python SDK as it is, which is still evolving all the time, by the way. We keep changing syntax quite a lot because I think it's still somewhat exploratory, but we're starting to converge on something that feels like reasonably good now.
Swyx [00:14:54]: Yeah. And along the way you, with this expressiveness, you enabled the ability to, for example, attach a GPU to a function. Totally.
Erik [00:15:02]: Yeah. It's like you just like say, you know, on the function decorator, you're like GPU equals, you know, A100 and then or like GPU equals, you know, A10 or T4 or something like that. And then you get that GPU and like, you know, you just run the code and it runs like you don't have to, you know, go through hoops to, you know, start an EC2 instance or whatever.
Swyx [00:15:18]: Yeah. So it's all code. Yeah. So one of the reasons I wrote Self-Revisioning Runtimes was I was working at AWS and we had AWS CDK, which is kind of like, you know, the Amazon basics blew me. Yeah, totally. And then, and then like it creates, it compiles the cloud formation. Yeah. And then on the other side, you have to like get all the config stuff and then put it into your application code and make sure that they line up. So then you're writing code to define your infrastructure, then you're writing code to define your application. And I was just like, this is like obvious that it's going to converge, right? Yeah, totally.
Erik [00:15:48]: But isn't there like, it might be wrong, but like, was it like SAM or Chalice or one of those? Like, isn't that like an AWS thing that where actually they kind of did that? I feel like there's like one.
Swyx [00:15:57]: SAM. Yeah. Still very clunky. It's not, not as elegant as modal.
Erik [00:16:03]: I love AWS for like the stuff it's built, you know, like historically in order for me to like, you know, what it enables me to build, but like AWS is always like struggle with developer experience.
Swyx [00:16:11]: I mean, they have to not break things.
Erik [00:16:15]: Yeah. Yeah. And totally. And they have to build products for a very wide range of use cases. And I think that's hard.
Swyx [00:16:21]: Yeah. Yeah. So it's, it's easier to design for. Yeah. So anyway, I was, I was pretty convinced that this, this would happen. I wrote, wrote that thing. And then, you know, I imagine my surprise that you guys had it on your landing page at some point. I think, I think Akshad was just like, just throw that in there.
Erik [00:16:34]: Did you trademark it?
Swyx [00:16:35]: No, I didn't. But I definitely got sent a few pitch decks with my post on there and it was like really interesting. This is my first time like kind of putting a name to a phenomenon. And I think this is a useful skill for people to just communicate what they're trying to do.
Erik [00:16:48]: Yeah. No, I think it's a beautiful concept.
Swyx [00:16:50]: Yeah. Yeah. Yeah. But I mean, obviously you implemented it. What became more clear in your explanation today is that actually you're not that tied to Python.
Erik [00:16:57]: No. I mean, I, I think that all the like lower level stuff is, you know, just running containers and like scheduling things and, you know, serving container data and stuff. So like one of the benefits of data teams is obviously like they're all like using Python, right? And so that made it a lot easier. I think, you know, if we had focused on other workloads, like, you know, for various reasons, we've like been kind of like half thinking about like CI or like things like that. But like, in a way that's like harder because like you also, then you have to be like, you know, multiple SDKs, whereas, you know, focusing on data teams, you can only, you know, Python like covers like 95% of all teams. That made it a lot easier. But like, I mean, like definitely like in the future, we're going to have others support, like supporting other languages. JavaScript for sure is the obvious next language. But you know, who knows, like, you know, Rust, Go, R, whatever, PHP, Haskell, I don't know.
Swyx [00:17:42]: You know, I think for me, I actually am a person who like kind of liked the idea of programming language advancements being improvements in developer experience. But all I saw out of the academic sort of PLT type people is just type level improvements. And I always think like, for me, like one of the core reasons for self-provisioning runtimes and then why I like Modal is like, this is actually a productivity increase, right? Like, it's a language level thing, you know, you managed to stick it on top of an existing language, but it is your own language, a DSL on top of Python. And so language level increase on the order of like automatic memory management. You know, you could sort of make that analogy that like, maybe you lose some level of control, but most of the time you're okay with whatever Modal gives you. And like, that's fine. Yeah.
Erik [00:18:26]: Yeah. Yeah. I mean, that's how I look at about it too. Like, you know, you look at developer productivity over the last number of decades, like, you know, it's come in like small increments of like, you know, dynamic typing or like is like one thing because not suddenly like for a lot of use cases, you don't need to care about type systems or better compiler technology or like, you know, the cloud or like, you know, relational databases. And, you know, I think, you know, you look at like that, you know, history, it's a steadily, you know, it's like, you know, you look at the developers have been getting like probably 10X more productive every decade for the last four decades or something that was kind of crazy. Like on an exponential scale, we're talking about 10X or is there a 10,000X like, you know, improvement in developer productivity. What we can build today, you know, is arguably like, you know, a fraction of the cost of what it took to build it in the eighties. Maybe it wasn't even possible in the eighties. So that to me, like, that's like so fascinating. I think it's going to keep going for the next few decades. Yeah.
Alessio [00:19:14]: Yeah. Another big thing in the infra 2.0 wishlist was truly serverless infrastructure. The other on your landing page, you called them native cloud functions, something like that. I think the issue I've seen with serverless has always been people really wanted it to be stateful, even though stateless was much easier to do. And I think now with AI, most model inference is like stateless, you know, outside of the context. So that's kind of made it a lot easier to just put a model, like an AI model on model to run. How do you think about how that changes how people think about infrastructure too? Yeah.
Erik [00:19:48]: I mean, I think model is definitely going in the direction of like doing more stateful things and working with data and like high IO use cases. I do think one like massive serendipitous thing that happened like halfway, you know, a year and a half into like the, you know, building model was like Gen AI started exploding and the IO pattern of Gen AI is like fits the serverless model like so well, because it's like, you know, you send this tiny piece of information, like a prompt, right, or something like that. And then like you have this GPU that does like trillions of flops, and then it sends back like a tiny piece of information, right. And that turns out to be something like, you know, if you can get serverless working with GPU, that just like works really well, right. So I think from that point of view, like serverless always to me felt like a little bit of like a solution looking for a problem. I don't actually like don't think like backend is like the problem that needs to serve it or like not as much. But I look at data and in particular, like things like Gen AI, like model inference, like it's like clearly a good fit. So I think that is, you know, to a large extent explains like why we saw, you know, the initial sort of like killer app for model being model inference, which actually wasn't like necessarily what we're focused on. But that's where we've seen like by far the most usage. Yeah.
Swyx [00:20:52]: And this was before you started offering like fine tuning of language models, it was mostly stable diffusion. Yeah.
Erik [00:20:59]: Yeah. I mean, like model, like I always built it to be a very general purpose compute platform, like something where you can run everything. And I used to call model like a better Kubernetes for data team for a long time. What we realized was like, yeah, that's like, you know, a year and a half in, like we barely had any users or any revenue. And like we were like, well, maybe we should look at like some use case, trying to think of use case. And that was around the same time stable diffusion came out. And the beauty of model is like you can run almost anything on model, right? Like model inference turned out to be like the place where we found initially, well, like clearly this has like 10x like better agronomics than anything else. But we're also like, you know, going back to my original vision, like we're thinking a lot about, you know, now, okay, now we do inference really well. Like what about training? What about fine tuning? What about, you know, end-to-end lifecycle deployment? What about data pre-processing? What about, you know, I don't know, real-time streaming? What about, you know, large data munging, like there's just data observability. I think there's so many things, like kind of going back to what I said about like redefining the data stack, like starting with the foundation of compute. Like one of the exciting things about model is like we've sort of, you know, we've been working on that for three years and it's maturing, but like this is so many things you can do like with just like a better compute primitive and also go up to stack and like do all this other stuff on top of it.
Alessio [00:22:09]: How do you think about or rather like I would love to learn more about the underlying infrastructure and like how you make that happen because with fine tuning and training, it's a static memory. Like you exactly know what you're going to load in memory one and it's kind of like a set amount of compute versus inference, just like data is like very bursty. How do you make batches work with a serverless developer experience? You know, like what are like some fun technical challenge you solve to make sure you get max utilization on these GPUs? What we hear from people is like, we have GPUs, but we can really only get like, you know, 30, 40, 50% maybe utilization. What's some of the fun stuff you're working on to get a higher number there?
Erik [00:22:48]: Yeah, I think on the inference side, like that's where we like, you know, like from a cost perspective, like utilization perspective, we've seen, you know, like very good numbers and in particular, like it's our ability to start containers and stop containers very quickly. And that means that we can auto scale extremely fast and scale down very quickly, which means like we can always adjust the sort of capacity, the number of GPUs running to the exact traffic volume. And so in many cases, like that actually leads to a sort of interesting thing where like we obviously run our things on like the public cloud, like AWS GCP, we run on Oracle, but in many cases, like users who do inference on those platforms or those clouds, even though we charge a slightly higher price per GPU hour, a lot of users like moving their large scale inference use cases to model, they end up saving a lot of money because we only charge for like with the time the GPU is actually running. And that's a hard problem, right? Like, you know, if you have to constantly adjust the number of machines, if you have to start containers, stop containers, like that's a very hard problem. Starting containers quickly is a very difficult thing. I mentioned we had to build our own file system for this. We also, you know, built our own container scheduler for that. We've implemented recently CPU memory checkpointing so we can take running containers and snapshot the entire CPU, like including registers and everything, and restore it from that point, which means we can restore it from an initialized state. We're looking at GPU checkpointing next, it's like a very interesting thing. So I think with inference stuff, that's where serverless really shines because you can drive, you know, you can push the frontier of latency versus utilization quite substantially, you know, which either ends up being a latency advantage or a cost advantage or both, right? On training, it's probably arguably like less of an advantage doing serverless, frankly, because you know, you can just like spin up a bunch of machines and try to satisfy, like, you know, train as much as you can on each machine. For that area, like we've seen, like, you know, arguably like less usage, like for modal, but there are always like some interesting use case. Like we do have a couple of customers, like RAM, for instance, like they do fine tuning with modal and they basically like one of the patterns they have is like very bursty type fine tuning where they fine tune 100 models in parallel. And that's like a separate thing that modal does really well, right? Like you can, we can start up 100 containers very quickly, run a fine tuning training job on each one of them for that only runs for, I don't know, 10, 20 minutes. And then, you know, you can do hyper parameter tuning in that sense, like just pick the best model and things like that. So there are like interesting training. I think when you get to like training, like very large foundational models, that's a use case we don't support super well, because that's very high IO, you know, you need to have like infinite band and all these things. And those are things we haven't supported yet and might take a while to get to that. So that's like probably like an area where like we're relatively weak in. Yeah.
Alessio [00:25:12]: Have you cared at all about lower level model optimization? There's other cloud providers that do custom kernels to get better performance or are you just given that you're not just an AI compute company? Yeah.
Erik [00:25:24]: I mean, I think like we want to support like a generic, like general workloads in a sense that like we want users to give us a container essentially or a code or code. And then we want to run that. So I think, you know, we benefit from those things in the sense that like we can tell our users, you know, to use those things. But I don't know if we want to like poke into users containers and like do those things automatically. That's sort of, I think a little bit tricky from the outside to do, because we want to be able to take like arbitrary code and execute it. But certainly like, you know, we can tell our users to like use those things. Yeah.
Swyx [00:25:53]: I may have betrayed my own biases because I don't really think about modal as for data teams anymore. I think you started, I think you're much more for AI engineers. My favorite anecdotes, which I think, you know, but I don't know if you directly experienced it. I went to the Vercel AI Accelerator, which you supported. And in the Vercel AI Accelerator, a bunch of startups gave like free credits and like signups and talks and all that stuff. The only ones that stuck are the ones that actually appealed to engineers. And the top usage, the top tool used by far was modal.
Erik [00:26:24]: That's awesome.
Swyx [00:26:25]: For people building with AI apps. Yeah.
Erik [00:26:27]: I mean, it might be also like a terminology question, like the AI versus data, right? Like I've, you know, maybe I'm just like old and jaded, but like, I've seen so many like different titles, like for a while it was like, you know, I was a data scientist and a machine learning engineer and then, you know, there was like analytics engineers and there was like an AI engineer, you know? So like, to me, it's like, I just like in my head, that's to me just like, just data, like, or like engineer, you know, like I don't really, so that's why I've been like, you know, just calling it data teams. But like, of course, like, you know, AI is like, you know, like such a massive fraction of our like workloads.
Swyx [00:26:59]: It's a different Venn diagram of things you do, right? So the stuff that you're talking about where you need like infinite bands for like highly parallel training, that's not, that's more of the ML engineer, that's more of the research scientist and less of the AI engineer, which is more sort of trying to put, work at the application.
Erik [00:27:16]: Yeah. I mean, to be fair to it, like we have a lot of users that are like doing stuff that I don't think fits neatly into like AI. Like we have a lot of people using like modal for web scraping, like it's kind of nice. You can just like, you know, fire up like a hundred or a thousand containers running Chromium and just like render a bunch of webpages and it takes, you know, whatever. Or like, you know, protein folding is that, I mean, maybe that's, I don't know, like, but like, you know, we have a bunch of users doing that or, or like, you know, in terms of, in the realm of biotech, like sequence alignment, like people using, or like a couple of people using like modal to run like large, like mixed integer programming problems, like, you know, using Gurobi or like things like that. So video processing is another thing that keeps coming up, like, you know, let's say you have like petabytes of video and you want to just like transcode it, like, or you can fire up a lot of containers and just run FFmpeg or like, so there are those things too. Like, I mean, like that being said, like AI is by far our biggest use case, but you know, like, again, like modal is kind of general purpose in that sense.
Swyx [00:28:08]: Yeah. Well, maybe I'll stick to the stable diffusion thing and then we'll move on to the other use cases for AI that you want to highlight. The other big player in my mind is replicate. Yeah. In this, in this era, they're much more, I guess, custom built for that purpose, whereas you're more general purpose. How do you position yourself with them? Are they just for like different audiences or are you just heads on competing?
Erik [00:28:29]: I think there's like a tiny sliver of the Venn diagram where we're competitive. And then like 99% of the area we're not competitive. I mean, I think for people who, if you look at like front-end engineers, I think that's where like really they found good fit is like, you know, people who built some cool web app and they want some sort of AI capability and they just, you know, an off the shelf model is like perfect for them. That's like, I like use replicate. That's great. I think where we shine is like custom models or custom workflows, you know, running things at very large scale. We need to care about utilization, care about costs. You know, we have much lower prices because we spend a lot more time optimizing our infrastructure, you know, and that's where we're competitive, right? Like, you know, and you look at some of the use cases, like Suno is a big user, like they're running like large scale, like AI. Oh, we're talking with Mikey.
Swyx [00:29:12]: Oh, that's great. Cool.
Erik [00:29:14]: In a month. Yeah. So, I mean, they're, they're using model for like production infrastructure. Like they have their own like custom model, like custom code and custom weights, you know, for AI generated music, Suno.AI, you know, that, that, those are the types of use cases that we like, you know, things that are like very custom or like, it's like, you know, and those are the things like it's very hard to run and replicate, right? And that's fine. Like I think they, they focus on a very different part of the stack in that sense.
Swyx [00:29:35]: And then the other company pattern that I pattern match you to is Modular. I don't know.
Erik [00:29:40]: Because of the names?
Swyx [00:29:41]: No, no. Wow. No, but yeah, yes, the name is very similar. I think there's something that might be insightful there from a linguistics point of view. Oh no, they have Mojo, the sort of Python SDK. And they have the Modular Inference Engine, which is their sort of their cloud stack, their sort of compute inference stack. I don't know if anyone's made that comparison to you before, but like I see you evolving a little bit in parallel there.
Erik [00:30:01]: No, I mean, maybe. Yeah. Like it's not a company I'm like super like familiar, like, I mean, I know the basics, but like, I guess they're similar in the sense like they want to like do a lot of, you know, they have sort of big picture vision.
Swyx [00:30:12]: Yes. They also want to build very general purpose. Yeah. So they're marketing themselves as like, if you want to do off the shelf stuff, go out, go somewhere else. If you want to do custom stuff, we're the best place to do it. Yeah. Yeah. There is some overlap there. There's not overlap in the sense that you are a closed source platform. People have to host their code on you. That's true. Whereas for them, they're very insistent on not running their own cloud service. They're a box software. Yeah. They're licensed software.
Erik [00:30:37]: I'm sure their VCs at some point going to force them to reconsider. No, no.
Swyx [00:30:40]: Chris is very, very insistent and very convincing. So anyway, I would just make that comparison, let people make the links if they want to. But it's an interesting way to see the cloud market develop from my point of view, because I came up in this field thinking cloud is one thing, and I think your vision is like something slightly different, and I see the different takes on it.
Erik [00:31:00]: Yeah. And like one thing I've, you know, like I've written a bit about it in my blog too, it's like I think of us as like a second layer of cloud provider in the sense that like I think Snowflake is like kind of a good analogy. Like Snowflake, you know, is infrastructure as a service, right? But they actually run on the like major clouds, right? And I mean, like you can like analyze this very deeply, but like one of the things I always thought about is like, why does Snowflake arbitrarily like win over Redshift? And I think Snowflake, you know, to me, one, because like, I mean, in the end, like AWS makes all the money anyway, like and like Snowflake just had the ability to like focus on like developer experience or like, you know, user experience. And to me, like really proved that you can build a cloud provider, a layer up from, you know, the traditional like public clouds. And in that layer, that's also where I would put Modal, it's like, you know, we're building a cloud provider, like we're, you know, we're like a multi-tenant environment that runs the user code. But we're also building on top of the public cloud. So I think there's a lot of room in that space, I think is very sort of interesting direction.
Alessio [00:31:55]: How do you think of that compared to the traditional past history, like, you know, you had AWS, then you had Heroku, then you had Render, Railway.
Erik [00:32:04]: Yeah, I mean, I think those are all like great. I think the problem that they all faced was like the graduation problem, right? Like, you know, Heroku or like, I mean, like also like Heroku, there's like a counterfactual future of like, what would have happened if Salesforce didn't buy them, right? Like, that's a sort of separate thing. But like, I think what Heroku, I think always struggled with was like, eventually companies would get big enough that you couldn't really justify running in Heroku. So they would just go and like move it to, you know, whatever AWS or, you know, in particular. And you know, that's something that keeps me up at night too, like, what does that graduation risk like look like for modal? I always think like the only way to build a successful infrastructure company in the long run in the cloud today is you have to appeal to the entire spectrum, right? Or at least like the enterprise, like you have to capture the enterprise market. But the truly good companies capture the whole spectrum, right? Like I think of companies like, I don't like Datadog or Mongo or something that were like, they both captured like the hobbyists and acquire them, but also like, you know, have very large enterprise customers. I think that arguably was like where I, in my opinion, like Heroku struggle was like, how do you maintain the customers as they get more and more advanced? I don't know what the solution is, but I think there's, you know, that's something I would have thought deeply if I was at Heroku at that time.
Alessio [00:33:14]: What's the AI graduation problem? Is it, I need to fine tune the model, I need better economics, any insights from customer discussions?
Erik [00:33:22]: Yeah, I mean, better economics, certainly. But although like, I would say like, even for people who like, you know, needs like thousands of GPUs, just because we can drive utilization so much better, like we, there's actually like a cost advantage of staying on modal. But yeah, I mean, certainly like, you know, and like the fact that VCs like love, you know, throwing money at least used to, you know, add companies who need it to buy GPUs. I think that didn't help the problem. And in training, I think, you know, there's less software differentiation. So in training, I think there's certainly like better economics of like buying big clusters. But I mean, my hope it's going to change, right? Like I think, you know, we're still pretty early in the cycle of like building AI infrastructure. And I think a lot of these companies over in the long run, like, you know, they're, except it may be super big ones, like, you know, on Facebook and Google, they're always going to build their own ones. But like everyone else, like some extent, you know, I think they're better off like buying platforms. And, you know, someone's going to have to build those platforms.
Swyx [00:34:12]: Yeah. Cool. Let's move on to language models and just specifically that workload just to flesh it out a little bit. You already said that RAMP is like fine tuning 100 models at once simultaneously on modal. Closer to home, my favorite example is ErikBot. Maybe you want to tell that story.
Erik [00:34:30]: Yeah. I mean, it was a prototype thing we built for fun, but it's pretty cool. Like we basically built this thing that hooks up to Slack. It like downloads all the Slack history and, you know, fine-tunes a model based on a person. And then you can chat with that. And so you can like, you know, clone yourself and like talk to yourself on Slack. I mean, it's like nice like demo and it's just like, I think like it's like fully contained modal. Like there's a modal app that does everything, right? Like it downloads Slack, you know, integrates with the Slack API, like downloads the stuff, the data, like just runs the fine-tuning and then like creates like dynamically an inference endpoint. And it's all like self-contained and like, you know, a few hundred lines of code. So I think it's sort of a good kind of use case for, or like it kind of demonstrates a lot of the capabilities of modal.
Alessio [00:35:08]: Yeah. On a more personal side, how close did you feel ErikBot was to you?
Erik [00:35:13]: It definitely captured the like the language. Yeah. I mean, I don't know, like the content, I always feel this way about like AI and it's gotten better. Like when you look at like AI output of text, like, and it's like, when you glance at it, it's like, yeah, this seems really smart, you know, but then you actually like look a little bit deeper. It's like, what does this mean?
Swyx [00:35:32]: What does this person say?
Erik [00:35:33]: It's like kind of vacuous, right? And that's like kind of what I felt like, you know, talking to like my clone version, like it's like says like things like the grammar is correct. Like some of the sentences make a lot of sense, but like, what are you trying to say? Like there's no content here. I don't know. I mean, it's like, I got that feeling also with chat TBT in the like early versions right now it's like better, but.
Alessio [00:35:51]: That's funny. So I built this thing called small podcaster to automate a lot of our back office work, so to speak. And it's great at transcript. It's great at doing chapters. And then I was like, okay, how about you come up with a short summary? And it's like, it sounds good, but it's like, it's not even the same ballpark as like, yeah, end up writing. Right. And it's hard to see how it's going to get there.
Swyx [00:36:11]: Oh, I have ideas.
Erik [00:36:13]: I'm certain it's going to get there, but like, I agree with you. Right. And like, I have the same thing. I don't know if you've read like AI generated books. Like they just like kind of seem funny, right? Like there's off, right? But like you glance at it and it's like, oh, it's kind of cool. Like looks correct, but then it's like very weird when you actually read them.
Swyx [00:36:30]: Yeah. Well, so for what it's worth, I think anyone can join the modal slack. Is it open to the public? Yeah, totally.
Erik [00:36:35]: If you go to modal.com, there's a button in the footer.
Swyx [00:36:38]: Yeah. And then you can talk to Erik Bot. And then sometimes I really like picking Erik Bot and then you answer afterwards, but then you're like, yeah, mostly correct or whatever. Any other broader lessons, you know, just broadening out from like the single use case of fine tuning, like what are you seeing people do with fine tuning or just language models on modal in general? Yeah.
Erik [00:36:59]: I mean, I think language models is interesting because so many people get started with APIs and that's just, you know, they're just dominating a space in particular opening AI, right? And that's not necessarily like a place where we aim to compete. I mean, maybe at some point, but like, it's just not like a core focus for us. And I think sort of separately, it's sort of a question of like, there's economics in that long term. But like, so we tend to focus on more like the areas like around it, right? Like fine tuning, like another use case we have is a bunch of people, Ramp included, is doing batch embeddings on modal. So let's say, you know, you have like a, actually we're like writing a blog post, like we take all of Wikipedia and like parallelize embeddings in 15 minutes and produce vectors for each article. So those types of use cases, I think modal suits really well for. I think also a lot of like custom inference, like yeah, I love that.
Swyx [00:37:43]: Yeah. I think you should give people an idea of the order of magnitude of parallelism, because I think people don't understand how parallel. So like, I think your classic hello world with modal is like some kind of Fibonacci function, right? Yeah, we have a bunch of different ones. Some recursive function. Yeah.
Erik [00:37:59]: Yeah. I mean, like, yeah, I mean, it's like pretty easy in modal, like fan out to like, you know, at least like 100 GPUs, like in a few seconds. And you know, if you give it like a couple of minutes, like we can, you know, you can fan out to like thousands of GPUs. Like we run it relatively large scale. And yeah, we've run, you know, many thousands of GPUs at certain points when we needed, you know, big backfills or some customers had very large compute needs.
Swyx [00:38:21]: Yeah. Yeah. And I mean, that's super useful for a number of things. So one of my early interactions with modal as well was with a small developer, which is my sort of coding agent. The reason I chose modal was a number of things. One, I just wanted to try it out. I just had an excuse to try it. Akshay offered to onboard me personally. But the most interesting thing was that you could have that sort of local development experience as it was running on my laptop, but then it would seamlessly translate to a cloud service or like a cloud hosted environment. And then it could fan out with concurrency controls. So I could say like, because like, you know, the number of times I hit the GPT-3 API at the time was going to be subject to the rate limit. But I wanted to fan out without worrying about that kind of stuff. With modal, I can just kind of declare that in my config and that's it. Oh, like a concurrency limit?
Erik [00:39:07]: Yeah. Yeah.
Swyx [00:39:09]: Yeah. There's a lot of control. And that's why it's like, yeah, this is a pretty good use case for like writing this kind of LLM application code inside of this environment that just understands fan out and rate limiting natively. You don't actually have an exposed queue system, but you have it under the hood, you know, that kind of stuff. Totally.
Erik [00:39:28]: It's a self-provisioning cloud.
Swyx [00:39:30]: So the last part of modal I wanted to touch on, and obviously feel free, I know you're working on new features, was the sandbox that was introduced last year. And this is something that I think was inspired by Code Interpreter. You can tell me the longer history behind that.
Erik [00:39:45]: Yeah. Like we originally built it for the use case, like there was a bunch of customers who looked into code generation applications and then they came to us and asked us, is there a safe way to execute code? And yeah, we spent a lot of time on like container security. We used GeoVisor, for instance, which is a Google product that provides pretty strong isolation of code. So we built a product where you can basically like run arbitrary code inside a container and monitor its output or like get it back in a safe way. I mean, over time it's like evolved into more of like, I think the long-term direction is actually I think more interesting, which is that I think modal as a platform where like I think the core like container infrastructure we offer could actually be like, you know, unbundled from like the client SDK and offer to like other, you know, like we're talking to a couple of like other companies that want to run, you know, through their packages, like run, execute jobs on modal, like kind of programmatically. So that's actually the direction like Sandbox is going. It's like turning into more like a platform for platforms is kind of what I've been thinking about it as.
Swyx [00:40:45]: Oh boy. Platform. That's the old Kubernetes line.
Erik [00:40:48]: Yeah. Yeah. Yeah. But it's like, you know, like having that ability to like programmatically, you know, create containers and execute them, I think, I think is really cool. And I think it opens up a lot of interesting capabilities that are sort of separate from the like core Python SDK in modal. So I'm really excited about C. It's like one of those features that we kind of released and like, you know, then we kind of look at like what users actually build with it and people are starting to build like kind of crazy things. And then, you know, we double down on some of those things because when we see like, you know, potential new product features and so Sandbox, I think in that sense, it's like kind of in that direction. We found a lot of like interesting use cases in the direction of like platformized container runner.
Swyx [00:41:27]: Can you be more specific about what you're double down on after seeing users in action?
Erik [00:41:32]: I mean, we're working with like some companies that, I mean, without getting into specifics like that, need the ability to take their users code and then launch containers on modal. And it's not about security necessarily, like they just want to use modal as a back end, right? Like they may already provide like Kubernetes as a back end, Lambda as a back end, and now they want to add modal as a back end, right? And so, you know, they need a way to programmatically define jobs on behalf of their users and execute them. And so, I don't know, that's kind of abstract, but does that make sense? I totally get it.
Swyx [00:42:03]: It's sort of one level of recursion to sort of be the Modal for their customers.
Erik [00:42:09]: Exactly.
Swyx [00:42:10]: Yeah, exactly. And Cloudflare has done this, you know, Kenton Vardar from Cloudflare, who's like the tech lead on this thing, called it sort of functions as a service as a service.
Erik [00:42:17]: Yeah, that's exactly right. FaSasS.
Swyx [00:42:21]: FaSasS. Yeah, like, I mean, like that, I think any base layer, second layer cloud provider like yourself, compute provider like yourself should provide, you know, it's a mark of maturity and success that people just trust you to do that. They'd rather build on top of you than compete with you. The more interesting thing for me is like, what does it mean to serve a computer like an LLM developer, rather than a human developer, right? Like, that's what a sandbox is to me, that you have to redefine modal to serve a different non-human audience.
Erik [00:42:51]: Yeah. Yeah, and I think there's some really interesting people, you know, building very cool things.
Swyx [00:42:55]: Yeah. So I don't have an answer, but, you know, I imagine things like, hey, the way you give feedback is different. Maybe you have to like stream errors, log errors differently. I don't really know. Yeah. Obviously, there's like safety considerations. Maybe you have an API to like restrict access to the web. Yeah. I don't think anyone would use it, but it's there if you want it.
Erik [00:43:17]: Yeah.
Swyx [00:43:18]: Yeah. Any other sort of design considerations? I have no idea.
Erik [00:43:21]: With sandboxes?
Swyx [00:43:22]: Yeah. Yeah.
Erik [00:43:24]: Open-ended question here. Yeah. I mean, no, I think, yeah, the network restrictions, I think, make a lot of sense. Yeah. I mean, I think, you know, long-term, like, I think there's a lot of interesting use cases where like the LLM, in itself, can like decide, I want to install these packages and like run this thing. And like, obviously, for a lot of those use cases, like you want to have some sort of control that it doesn't like install malicious stuff and steal your secrets and things like that. But I think that's what's exciting about the sandbox primitive, is like it lets you do that in a relatively safe way.
Alessio [00:43:51]: Do you have any thoughts on the inference wars? A lot of providers are just rushing to the bottom to get the lowest price per million tokens. Some of them, you know, the Sean Randomat, they're just losing money and there's like the physics of it just don't work out for them to make any money on it. How do you think about your pricing and like how much premium you can get and you can kind of command versus using lower prices as kind of like a wedge into getting there, especially once you have model instrumented? What are the tradeoffs and any thoughts on strategies that work?
Erik [00:44:23]: I mean, we focus more on like custom models and custom code. And I think in that space, there's like less competition and I think we can have a pricing markup, right? Like, you know, people will always compare our prices to like, you know, the GPU power they can get elsewhere. And so how big can that markup be? Like it never can be, you know, we can never charge like 10x more, but we can certainly charge a premium. And like, you know, for that reason, like we can have pretty good margins. The LLM space is like the opposite, like the switching cost of LLMs is zero. If all you're doing is like straight up, like at least like open source, right? Like if all you're doing is like, you know, using some, you know, inference endpoint that serves an open source model and, you know, some other provider comes along and like offers a lower price, you're just going to switch, right? So I don't know, to me that reminds me a lot of like all this like 15 minute delivery wars or like, you know, like Uber versus Lyft, you know, and like maybe going back even further, like I think a lot about like sort of, you know, flip side of this is like, it's actually a positive side, which is like, I thought a lot about like fiber optics boom of like 98, 99, like the other day, or like, you know, and also like the overinvestment in GPU today. Like, like, yeah, like, you know, I don't know, like in the end, like, I don't think VCs will have the return they expected, like, you know, in these things, but guess who's going to benefit, like, you know, is the consumers, like someone's like reaping the value of this. And that's, I think an amazing flip side is that, you know, we should be very grateful, the fact that like VCs want to subsidize these things, which is, you know, like you go back to fiber optics, like there was an extreme, like overinvestment in fiber optics network in like 98. And no one made money who did that. But consumers, you know, got tremendous benefits of all the fiber optics cables that were led, you know, throughout the country in the decades after. I feel something similar about like GPUs today. And also like specifically looking like more narrowly at like LLM in France market, like that's great. Like, you know, I'm very happy that, you know, there's a price war. Modal is like not necessarily like participating in that price war, right? Like, I think, you know, it's going to shake out and then someone's going to win and then they're going to raise prices or whatever. Like, we'll see how that works out. But for that reason, like we're not like hyper focused on like serving, you know, just like straight up, like here's an endpoint to an open source model. We think the value in Modal comes from all these, you know, the other use cases, the more custom stuff, like fine tuning and complex, you know, guided output, like type stuff. Or like also like in other, like outside of LLMs, like with more focus, a lot more like image, audio, video stuff, because that's where there's a lot more proprietary models. There's a lot more like custom workflows. And that's where I think, you know, Modal is more, you know, there's a lot of value in software differentiation. I think focusing on developer experience and developer productivity, that's where I think, you know, you can have more of a competitive moat.
Alessio [00:46:58]: I'm curious what the difference is going to be now that it's an enterprise. So like with DoorDash, Uber, they're going to charge you more. And like as a customer, like you can decide to not take Uber. But if you're a company building AI features in your product using the subsidized prices, and then, you know, the VC money dries up in a year and like prices go up, it's like, you can't really take the features back without a lot of backlash. But you also cannot really kill your margins by paying the new price. So I don't know what that's going to look like
Erik [00:47:28]: But like margins are going to go up for sure. But I don't know if prices will go up because like GPU prices have to drop eventually, right? So like, you know, like in the long run, I still think like prices may not go up that much. But certainly margins will go up. Like I think you said, Swyx, that margins are negative right now. Like, you know, for some people, obviously, that's not sustainable. So certainly margins will have to go up. Like some companies are going to have to make money in this space. Otherwise, like they're not going to provide the service. But that's equilibrium too, right? Like at some point, like, you know, it sort of stabilizes and one or two or three providers make money.
Alessio [00:48:02]: Yeah. What else is maybe underrated, a model, something that people don't talk enough about, or yeah, that we didn't cover in the discussion?
Erik [00:48:11]: Yeah, I think what are some other things? We talked about a lot of stuff. Like we have the bursty parallelism. I think that's pretty cool. Working on a lot of like, trying to figure out like, kind of thinking more about the roadmap. But like one of the things I'm very excited about is building primitives for like, more like IO intensive workloads. And so like, we're building some like crude stuff right now where like, you can like create like direct TCP tunnels to containers and that lets you like pipe data. And like, you know, we haven't really explored this as much as we should, but like, there's a lot of interesting applications. Like you can actually do like kind of real time video stuff in Modal now, because you can like create a tunnel to, exactly. You can create a raw TCP socket to a container, feed it video and then like, you know, get the video back. And I think like, it's still like a little bit like, you know, not fully ergonomically like figured out. But I think there's a lot of like, super cool stuff. Like when we start enabling those more like high IO workloads, I'm super excited about. I think also like, you know, working with large data sets or kind of taking the ability to map and fan out and like building more like higher level, like functional primitives, like filters and group buys and joins. Like I think there's a lot of like, really cool stuff you can do. But this is like maybe like, you know, years out like.
Swyx [00:49:18]: Yeah, we can just broaden out from Modal a little bit, but you still have a lot of, you have a lot of great tweets. So it's very easy to just kind of go through them. Why is Oracle underrated? I love Oracle's GPUs. I don't know why, you know,
Erik [00:49:34]: what the economics looks like for Oracle, but I think they're great value for money. Like we run a bunch of stuff in Oracle and they have bare metal machines, like two terabytes of RAM. They're like super fast SSDs. You know, I mean, we love AWS and AGCP too. We have great relationships with them. But I think Oracle is surprising. Like, you know, if you told me like three years ago that I would be using Oracle Cloud, like I'd be like, what, wait, why? But now, you know,
Swyx [00:49:55]: I'm a happy customer. And it's a combination of pricing and the kinds of SKUs I guess they offer.
Erik [00:50:01]: Yeah. Great, great machines, good prices, you know. That's it. Yeah. Yeah. That's all I care about. Yeah. The sales team is pretty fun too. Like I like them.
Swyx [00:50:09]: In Europe, people often talk about Hetzner. Yeah. Like we've focused on the main clouds, right?
Erik [00:50:14]: Like we've, you know, Oracle, AWS, GCP, we'll probably add Azure at some point. I think, I mean, there's definitely a long tail of like, you know, CoreWeave, Hetzner, like Lambda, like all these things. And like over time, I think we'll look at those too. Like, you know, wherever we can get the right GPUs at the right price. Yeah. I mean, I think it's fascinating. Like it's a tough business. Like I wouldn't want to try to build like a cloud provider. You know, it's just, you just have to be like incredibly focused on like, you know, efficiency and margins and things like that. But I mean, I'm glad people are trying.
Swyx [00:50:45]: Yeah. And you can ramp up on any of these clouds very quickly, right? Because it's your standard stack.
Erik [00:50:50]: Yeah. I mean, yeah. Like I think so. Like, you know, what Modal does is like programmatic, you know, launching and termination of machines. So that's like what's nice about the clouds is, you know, they have relatively like immature APIs for doing that, as well as like, you know, support for Terraform for all the networking and all that stuff. So that makes it easier to work with the big clouds. But yeah, I mean, some of those things, like I think, you know, I also expect the smaller clouds to like embrace those things in the long run, but also think, you know, you know, we can also probably integrate with some of the clouds, like even without that. There's always an HTML API that you can use, just like script something that launches instances like through the web.
Swyx [00:51:24]: Yeah. I think a lot of people are always curious about whether or not you will buy your own hardware someday. I think you're pretty firm in that it's not your interest, but like your story and your growth does remind me a little bit of Cloudflare, which obviously, you know, invests a lot in its own physical network.
Erik [00:51:42]: Yeah. I don't remember like early days, like, did they have their own hardware or?
Swyx [00:51:47]: They push out a lot with like agreements through other, you know, providers.
Erik [00:51:52]: Yeah. Okay. Interesting.
Swyx [00:51:53]: But now it's all their own hardware. So I understand.
Erik [00:51:57]: Yeah. I mean, my feeling is that when you're a venture funded startup, like buying physical hardware is maybe not the best use of the money.
Swyx [00:52:06]: I really wanted to put you in a room with Isocat from Poolside. Yeah. Because he has the complete opposite view. Yeah.
Erik [00:52:12]: It is great. I mean, I don't like, I just think for like a capital efficiency point of view, like, do you really want to tie up that much money and like, you know, physical hardware and think about depreciation and like, like, as much as possible, like I, you know, I favor a more capital efficient way of like, we don't want to own the hardware because then, and ideally, we want to, we want the sort of margin structure to be sort of like 100% correlated revenue in cogs in the sense that like, you know, when someone comes and pays us, you know, $1 for compute, like, you know, we immediately incur a cost of like, whatever, 70 cents, 80 cents, you know, and there's like complete correlation between cost and revenue because then you can leverage up in like a kind of a nice way you can scale very efficiently. You know, like, that's not, you know, turns out like that's hard to do. Like, you can't just only use like spotting on demand instances. Like over time, we've actually started adding a pretty significant amount of reservations too. So I don't know, like reservation is always like one step towards owning your own hardware. Like, I don't know, like, do we really want to be, you know, thinking about switches and cooling and HVAC and like power supplies? Accessory recovery. Yeah. Like, is that the thing I want to think about? Like, I don't know. Like I like to make developers happy, but who knows, like maybe one day, like, but I don't think it's gonna happen anytime soon.
Swyx [00:53:23]: Yeah. Obviously, for what it's worth, obviously, I'm a believer in cloud, but it's interesting to have the devil's advocate on the other side. The main thing you have to do is be confident that you can manage your depreciation better than the typical assumption, which is two to three years. Yeah. Yeah. And so the moment you have a CTO that tells you, no, I think I can make these things last seven years, then it changes the math.
Erik [00:53:46]: Yeah. Yeah. But you know, are you deluding yourself then? That's the question, right? It's like the waste management scandal. Do you know about that? Like they had all this like, like accounting scandal back in the 90s, like this garbage company, like where they like, started assuming their garbage trucks had a 10-year depreciation schedule, booked like a massive profit, you know, the stock went to like, you know, up like, you know, and then it turns out actually all those garbage trucks broke down and like, you can't really depreciate them over 10 years. And so, so then the whole company, you know, they had to restate all the earnings.
Alessio [00:54:18]: Let's go into some personal nuggets. You received the IOI gold medal, which is the International Olympiad in Informatics.
Erik [00:54:29]: 20 years ago.
Alessio [00:54:30]: Yeah. How have these models and like going to change competitive programming? Like, do you think people are still love the craft? I feel like over time, we're kind of like programming has kind of lost maybe a little bit of its luster in the eyes of a lot of, a lot of people. Yeah. I'm curious to, to see what you think.
Erik [00:54:51]: I mean, maybe, but like, I don't know, like, you know, I've been coding for almost 30 or more than 30 years. And like, I feel like, you know, you look at like programming and, you know, where it is today versus where it was, you know, 30, 40, 50 years ago, there's like probably thousand times more developers today than, you know, so like, and every year there's more and more developers. And at the same time, developer productivity keeps going up. And when I look at the real world, I just think there's so much software that's still waiting to be built. Like, I think we can, you know, 10X the amount of developers and still, you know, have a lot of people making a lot of money, you know, building amazing software and also being while at the same time being more productive. Like I never understood this, like, you know, AI is going to, you know, replace engineers. That's very rarely how this actually works. When AI makes engineers more productive, like the demand actually goes up because the cost of engineers goes down because you can build software more cheaply. And that's, I think, the story of software in the world over the last few decades. So, I mean, I don't know how this relates to like competitive programming. Kind of going back to your question, competitive programming to me was always kind of a weird kind of, you know, niche, like kind of, I don't know. I love it. It's like puzzle solving. And like my experience is like, you know, half of competitive programmers are able to translate that to actual like building cool stuff in the world. Half just like get really in, you know, sucked into this like puzzle stuff and, you know, it never loses its grip on them. But like for me, it was an amazing way to get started with coding or get very deep into coding and, you know, kind of battle off with like other smart kids and traveling to different countries when I was a teenager.
Swyx [00:56:29]: I was just going to mention, like, it's not just that he personally is a competitive programmer. Like, I think a lot of people at Modal are competitive programmers. I think you met Akshat through... Akshat, co-founder is also at Gold Medal.
Erik [00:56:42]: By the way, Gold Medal doesn't mean you win. Like, but although we actually had an intern that won Iowa. Gold Medal is like the top 20, 30 people roughly.
Swyx [00:56:47]: Yeah. Obviously, it's very hard to get hired at Modal. But what is it like to work with like such a talent density? Like, you know, how is that contributing to the culture at Modal? Yeah. I mean, I think humans are the root cause of like everything at a company, like, you know, bad code is because it's bad human or like whatever, you know, bad culture.
Erik [00:57:03]: So like, I think, you know, like talent density is very important and like keeping the bar high and like hiring smart people. And, you know, it's not always like the case that like hiring competitive programmers is the right strategy, right? If you're building something very different, like you may not, you know, but we actually end up having a lot of like hard, you know, complex challenges. Like, you know, I talked about like the cloud, you know, the resource allocation, like turns out like that actually, like you can phrase that as a mixed integer programming problem. Like we now have that running in production, like constantly optimizing how we allocate cloud resources. There's a lot of like interesting, like complex, like scheduling problems. And like, how do you do all the bin packing of all the containers? Like, so, you know, I think for what we're building, you know, it makes a lot of sense to hire these people who like, like those very hard problems.
Swyx [00:57:52]: Yeah. And they don't necessarily have to know the details of the stack. They just need to be very good at algorithms.
Erik [00:57:56]: No, but my feeling is like people who are like pretty good at competitive programming, they can also pick up like other stuff like elsewhere. Not always the case, but you know, there's definitely a high correlation.
Swyx [00:58:08]: Oh yeah. I'm just, I'm interested in that just because, you know, like there's competitive mental talents in other areas, like competitive speed memorization or whatever. And like, you don't really see those transfer. And I always assumed in my narrow perception that competitive programming is so specialized, it's so obscure, even like so divorced from real world scenarios that it doesn't actually transfer that much. But obviously I think for the problems that you work on it, it does.
Erik [00:58:34]: But it's also like, you know, frankly, it's like translates to some extent, not because like the problems are the same, but just because like it sort of filters for the, you know, people who are like willing to go very deep and work hard on things. Right. Like, I feel like a similar thing is like a lot of good developers are like talented musicians. Like, why? Like, why is this a correlation? And like, my theory is like, you know, it's the same sort of skill. Like you have to like just hyper focus on something and practice a lot. Like, and there's something similar that I think creates like good developers.
Alessio [00:59:02]: Yeah. Sweden also had a lot of very good Counter-Strike players. I don't know, why does Sweden have fiber optics before all of Europe? I feel like, I grew up in Italy and our internet was terrible. And then I feel like all the Nordics and like amazing internet, I remember getting online and people in the Nordics are like five ping, 10 ping.
Erik [00:59:23]: Yeah. We had very good network back then. Yeah. Do you know why? I mean, I'm sure like, you know, I think the government, you know, did certain things quite well. Right. Like in the nineties, like there was like a bunch of tax rebates for like buying computers. And I think there was similar like investments in infrastructure. I mean, like, and I think like I was thinking about, you know, it's like, I still can't use my phone in the subway in New York. And that was something I could use in Sweden in 95. You know, we're talking like 40 years almost. Right. Like, like why? And I don't know, like I think certain infrastructure,
Alessio [00:59:53]: you know, Sweden was just better at, I don't know. And also you never owned a TV or a car?
Erik [00:59:59]: Never owned a TV or a car. I never had a driver's license.
Alessio [01:00:01]: How do you do that in Sweden though? Like that's cold.
Erik [01:00:03]: I grew up in a city. I mean, like I took the subway everywhere with bike or whatever. Yeah. I always lived in cities, so I don't, you know, I never felt, I mean, like we have like me and my wife as a car, but like. That doesn't count. I mean, it's her name because I don't have a driver's license. She drives me everywhere. It's nice.
Swyx [01:00:21]: Nice. That's fantastic. I was going to ask you, like the last thing I had on this list was your advice to people thinking about running some sort of run code in the cloud startup is only do it if you're genuinely excited about spending five years thinking about load balancing, page falls, cloud security and DNS. So basically like it sounds like you're summing up a lot of pain running Modal. Yeah. Yeah. Like one thing I struggle with, like I talked to a lot of people
Erik [01:00:43]: starting companies in the data space or like AI space or whatever. And they sort of come at it at like, you know, from like an application developer point of view. And they're like, I'm going to make this better. But like, guess how you have to make it better. It's like, you have to go very deep on the infrastructure layer. And so one of my frustrations has been like so many startups are like, in my opinion, like Kubernetes wrappers and not very like thick wrappers, like fairly thin wrappers. And I think, you know, every startup is a wrapper to some extent, but like you need to be like a fat wrapper. You need to like go deep and like build some stuff. And that's like, you know, if you build a tech company, you're going to want to, you're going to have to spend, you know, five, 10, 20 years of your life, like going very deep and like, you know, building the infrastructure you need in order to like make your product truly stand out and be competitive. And so, you know, I think that goes for everything. I mean, like you're starting a whatever, you know, online retailer of, I don't know, bathroom sinks. You have to be willing to spend 10 years of your life thinking about, you know, whatever, bathroom sinks, like otherwise it's going to be hard.
Swyx [01:01:37]: Yeah. I think that's good advice for everyone. And yeah, congrats on all your success. It's pretty exciting to watch it. It's just the beginning. Yeah. Yeah. Yeah. It's
Erik [01:01:45]: exciting. And everyone should sign up and try out modal.modal.com. Yeah. Now it's GA. Yay. Yeah.
Swyx [01:01:50]: Used to be behind a wait list. Yeah. Awesome, Erik. Thank you so much for coming on. Yeah, it's amazing. Thank you so much. Thanks.
Swyx [01:02:11]: Bye.