

The Shape of Compute — with Chris Lattner for Modular
The Modular/Mojo creator returns to the pod to discuss the CUDA monopoly, matching NVIDIA performance with AMD, and building a company of "elite nerds",

Watch on YouTube, listen on Apple Podcast, Spotify, or add our RSS feed to your favorite player!
When Chris Lattner first came on the podcast, we titled the episode “Doing it The Hard Way”. Rather than simply building an inference platform and posting charts showing GPUs going brrr, they went down to the compiler level and started rebuilding the whole stack from scratch.
Modular is being built as “concentric circles”, as Chris calls them. You drop into the layer you need; everything lower is optional plumbing you never touch. We covered a lot of the Mojo design in the previous episode, so refer to that if you need a refresher. At the core of its uniqueness, there’s one thing: Mojo exposes every accelerator instruction (tensor cores, TMAs, etc.) in a Python‑familiar syntax so you can:
Write once, re‑target to H100, MI300, or future Blackwell.
Run 10‑100× faster than CPython; usually beats Rust on the same algo.
Works as a zero‑binding extension language:
import my_fast_fn.mojoand call from normal Python.
This removes the need for any Triton/CUDA kernels and C++ “glue” code.
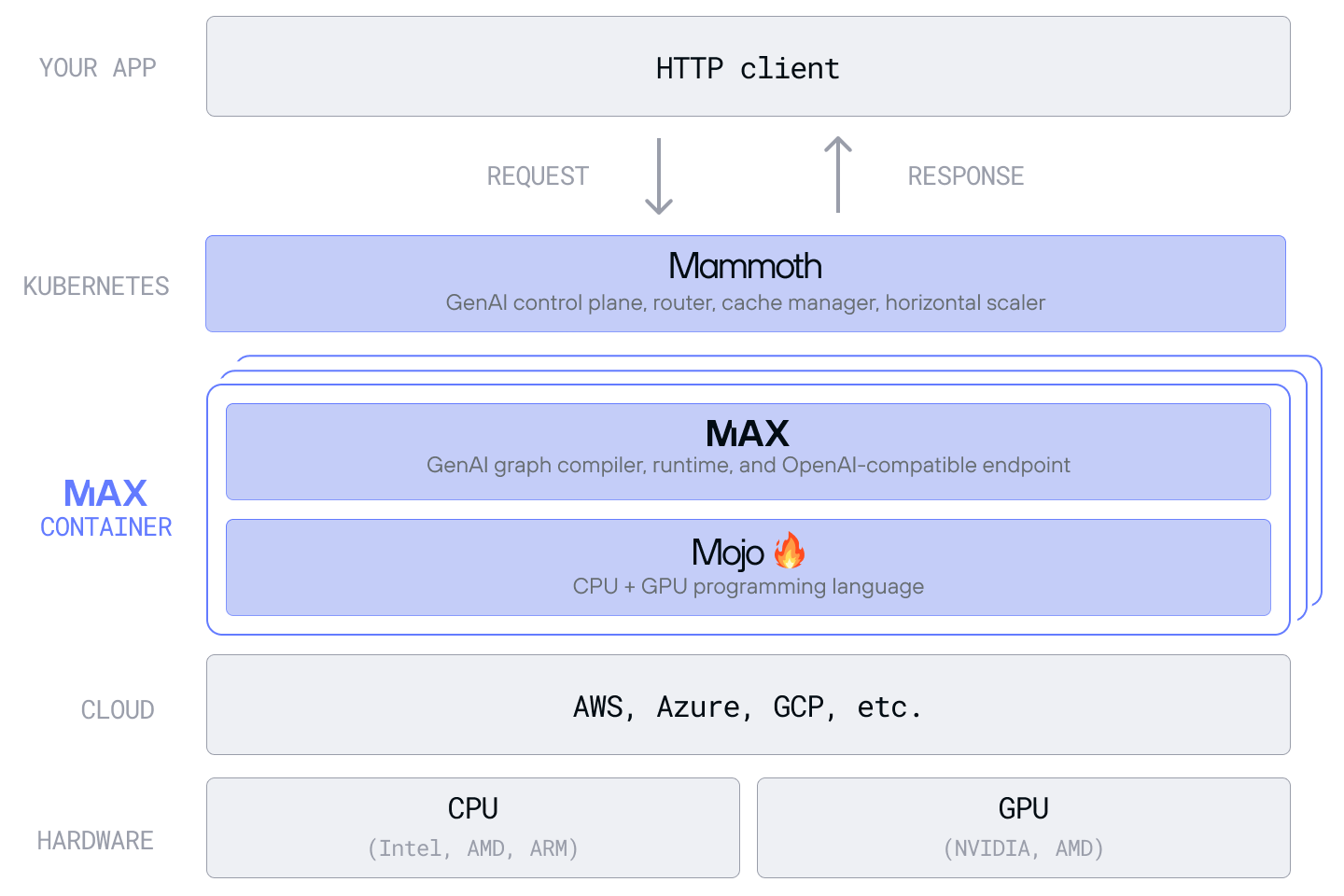
The same approach has been applied to the MAX inference platform:
Max’s base image is ≈ 1 GB because it strips the Python dispatch path.
Supports ~500 models with pre-built containers which include all the optimizations needed like Flash‑Attention, paged KV, DeepSeek style MLA, etc.
Most importantly they ship nightly builds to really get the open source community involved
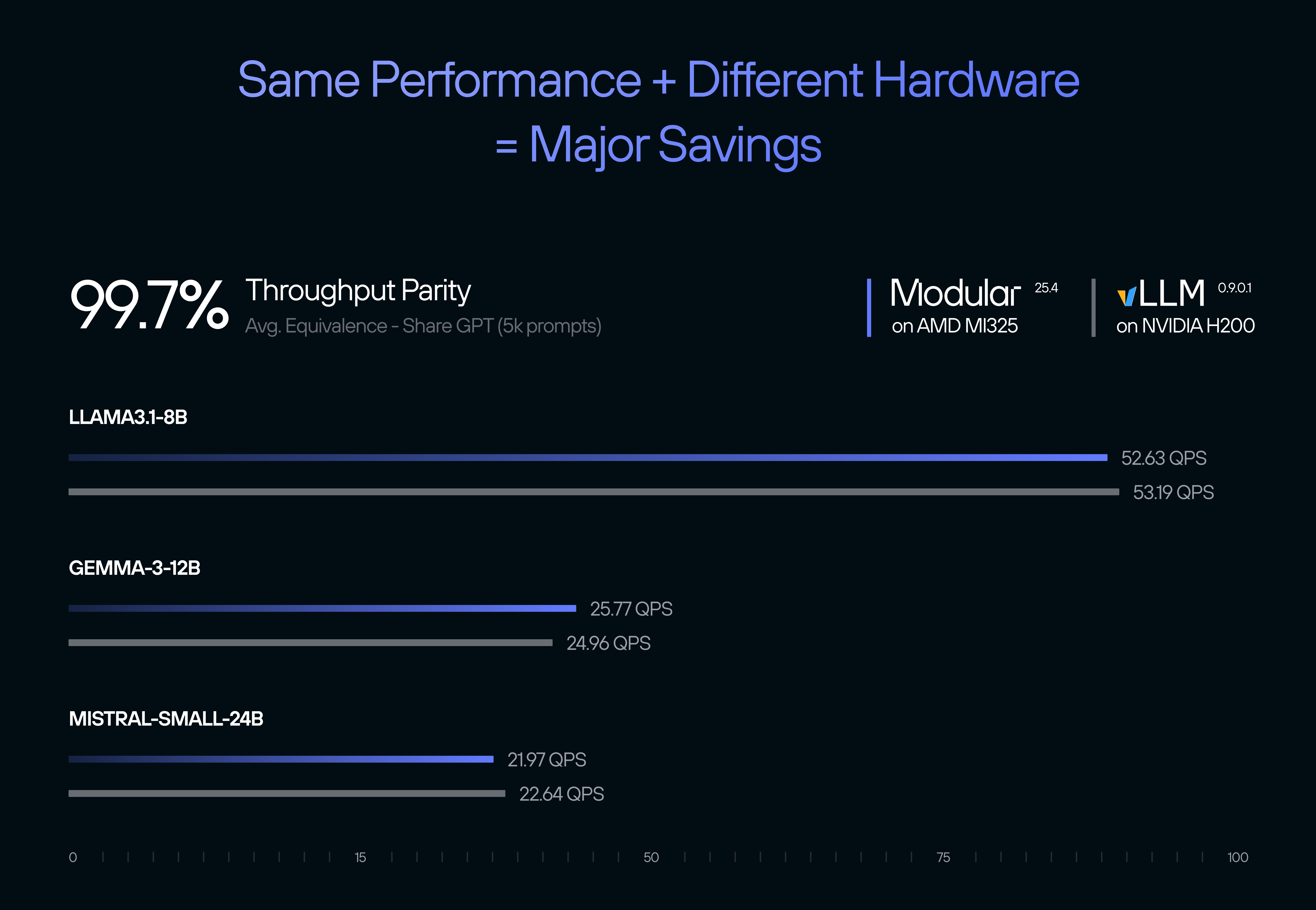
This week, they had a big announcement with AMD showing that they are ~matching MI325 performance with H200s running on vLLM on some of the more popular open source models. This is a huge step forward in breaking up NVIDIA’s dominance (you can also listen to our geohot episode for more on AMD’s challenges).
Chris has also been on a blogging bonanza with his Democratizing AI Compute series, at once a masterclass in the problems CUDA solves, but also the most coherent pitch for Modular’s approach: https://www.modular.com/democratizing-ai-compute
Chris already replaced GCC with LLVM and Objective‑C with Swift; is Mojo replacing CUDA next? We talked through what it’s needed to make that happen in the full episode. Enjoy!
Show Notes
Timestamps
[00:00:00] Introductions
[00:00:12] Overview of Modular and the Shape of Compute
[00:02:27] Modular’s R&D Phase
[00:06:55] From CPU Optimization to GPU Support
[00:11:14] MAX: Modular’s Inference Framework
[00:12:52] Mojo Programming Language
[00:18:25] MAX Architecture: From Mojo to Cluster-Scale Inference
[00:29:16] Open Source Contributions and Community Involvement
[00:32:25] Modular's Differentiation from VLLM and SGLang
[00:41:37] Modular’s Business Model and Monetization Strategy
[00:53:17] DeepSeek’s Impact and Low-Level GPU Programming
[01:00:00] Inference Time Compute and Reasoning Models
[01:02:31] Personal Reflections on Leading Modular
[01:08:27] Daily Routine and Time Management as a Founder
[01:13:24] Using AI Coding Tools and Staying Current with Research
[01:14:47] Personal Projects and Work-Life Balance
[01:17:05] Hiring, Open Source, and Community Engagement
Transcript
Alessio [00:00:05]: Hey everyone, welcome to the Latent Space podcast. This is Alessio, partner and CTO at Decibel, and I'm joined by my co-host Swyx, founder of SmolAI.
Overview of Modular and the Shape of Compute
Swyx [00:00:12]: And we're so excited to be back in the studio with Chris Lattner from Mojo / Modular. Welcome back.
Chris: Yeah, I'm super excited to be here. As you know, I'm a huge fan of both of you and also the podcast and a lot of what's going on in the industry. So thank you for having me.
Swyx: Thanks for keeping us involved in your journey. And I think like you spend a lot of time writing when obviously your time is super valuable. Educating the rest of the world. I just saw your like a two and a half hour workshop with the GPU mode guys. And that was super exciting. We're decked out in your swag. We'll get to the part where you are a personal human machine of just productivity and you do so much. And, you know, I think there's a lot to learn. And for people just on a personal level. But I think a lot of people are going to be here just for the state of modular. We're also calling it the shape of compute. I think it's going to be probably the podcast title.
Chris: Yeah, it's super exciting. I mean, there's so much going on in the industry with hardware and software and just innovation everywhere. Most people can catch up on like the first episode that we did and we introduced modular. I think people want to know, like, I think since then you sort of open sourced it. There's been a lot of updates. What would you highlight as like the past year or so of updates? Yeah. So if you zoom out and say, what is modular? Yeah. So we're a company that's just over three years old. Three and a quarter. So we're quite a ways in. The first three years was a very mysterious time to a lot of people because I didn't want people to really use our stuff. And so why that? Why do you build something that you don't want people to use? Well, it's because we're figuring it all out. And so the way I explain is we were very much in a research phase. And so we were trying to solve this really hard problem of how do we unlock heterogeneous compute? How do we enable GP programming to be way easier? How do we enable innovation that's full stack across the AI stack by making it way simpler and driving out complexity? Like there are these core questions. And I had a lot of hypotheses, right? But building an alternate AI stack that is not as good as the existing one isn't very useful because people will always evaluate it against state of the art. And at that point, you say, okay, well, let's just break it down like a normal engineering problem. It's not R&D anymore. It's an engineering problem. You say, okay, cool. Let's refactor these APIs. Let's deprecate this thing. Let's, oh yeah, let's add H100 support. Let's add function calling and token sampling and like all the different things you need. You can project manage that, right? And so every six weeks, we've been shipping a new release. And so we added all the function calling features. And now you have agentic workflows. We have 500 models. We have H100 support. We're about to launch our AMD MI300 and 325 support. That'll be a big deal for the industry. And as you do that in Blackwell, like all this stuff is like all now in the product. And so as this happens now, suddenly it's like, oh, okay, I get it. But this is a very fundamentally different phase for us because it works, right? And once it works, you can see it end to end. Lots of people can put the pieces together in their brain. It's not just in my brain. And a few other people that understand how all the different individual pieces work. Or now everybody can see it. So as we face shift now, suddenly it's like, yeah, okay, let's open source it. Well, now we want more people involved. Now let's do each of these things. It's actually, we had a hackathon. And so we invited 100 people to come visit and spend the day with us. And we learned GPU programming from scratch. And so, you know, we built a very fancy inference framer. You know, the winning team for the hackathon took that four person team. And one day they had not used Mojo before. They hadn't programmed GPUs before. And they had built a training. They wrote an Adam Optimizer, a bunch of training kernels, they built a simple backprop system and they actually showed that you could train a model using all the stuff we'd built for inference because it's so hackable and also because the AI coding tools are awesome, but, but this is the power of what you can do when, when you're ready to scale. Now, if we had done that six months ago or 12 months ago or something, it would have been a huge mess, right? Because everything would break and there are a lot of bugs and, you know, honestly, today it's still an early state system. There's still some bugs, but now it's useful. It can solve real world problems. And so that's, that's the difference. And that's kind of the evolution that we've gone through as a team.
From CPU Optimization to GPU Support
Alessio [00:06:55]: I remember when we first had you at the start, you were focused on CPU actually. How long did you work on CPU and then how much of a jump was it to go from CPU to GPU?
Chris [00:07:06]: So, so the way I would, the way I explain modular is if you take that first three year R&D journey, and if you round a little bit, first year was, um, prove compilation philosophy. And so this was writing. Very. Very abstract compiler stuff and then prove that we can make a matrix multiplication go faster than Intel MKL's matrix multiplication on Intel silicon and make it configurable and multiple D types and prove like a very narrow problem and do that by writing this MLIR compiler representation directly by hand, which was really horrible. But we proved the technology and some technology milestone year two was then say, okay, cool. I believe the, the fundamental approach can work, but guess what? Usability is terrible. Writing internal compiler stuff by hand sucks. And also Matt Moles a long ways from an AI framework. And so year two embarked on two paths. One is Mojo. So program language syntax, member of the Python family, make it much more accessible and easy to write kernels and performance and all that kind of stuff. And then second, build an AI framework for CPUs, as you say, where you could go beat OpenVINO and things like this on Intel CPUs. End of year two, we, we got in, we're like, foof, we've achieved this amazing thing, but you know, it's cool. GPUs. And so again, two things we said, okay, well, let's prove we could do GPUs. Number one, also let's not just build a, you know, air quotes, a CUDA replacement. Let's actually show that we could do something useful. Let's take on LLM serving. No big deal. Right. And so again, two things where you say, let's go prove that we can do a thing, but then validate it against a really hard benchmark. And then that was, that's what, what brought us to year three. Yep. So in each of these stages is really hard and lots of interesting technical problems. Um, probably the biggest problem that you face. So you face people that are constantly telling you it's impossible, but again, you just have to be a little bit stubborn and believe in yourself and work hard and stay focused on milestones. When they say impossible, do they mean impossible or very, very hard? Well, so, I mean, it's, it's common sense that CUDA is nearly 20 years old and VIA's got hundreds or thousands of people working on it. The entire world's been writing CUDA code for many years, very, very hard. And so it's, no, I mean, many people think it's impossible for a startup to do anything in the space. Yeah. Like that's just common sense. I, all these people have thrown all this money at all. All these different systems, they've all failed. Why is your thing going to succeed when all these other things built by other smart people have failed? Right. And so it's conventional wisdom that change is impossible, but Hey, we're an AI, you know, this like changes all around us all the time. Right. And so what you need to do is you need to map out what are the success criteria, what causes change to actually work. And across my career, like with LLVM, all the GCC people told me it was impossible. Like LLVM will fail because GCC is 20 years old and it's had hundreds of people working on it and blah, blah, blah. And spec benchmarks. And whatever, nobody told me it was impossible outside because it was secret. So that was a little bit different, but everybody inside Apple that knew about it said, no, no, no objective C is fine. Like we should just improve objective C. The world doesn't need new programming languages that new programming languages never get adopted. Yeah. Right. And, and it's common sense that like new programming languages don't go anywhere. That's conventional wisdom. You know, MLIR super funny. MLIR is another compiler thing. And so built this thing, brought it to the LLVM community and said, Hey, we open sources. Does LLVM work? I want to it. I know a few LLVM people, right? It was my PhD project and all the LLVM Illuminati in the community had been working on LLVM for 15 years or something. They're like, no, no, LLVM is good enough. We don't need a new thing. Machine learning is not that important. And so again, obviously have developed a few skills to work through this kind of challenge, but you get back to the reality that humans don't like change. And when you do have change, it takes time to diffuse into the ecosystem. For people to process it. And this is where we talk about hackathon. Well, you kind of have to teach people about new things. And so this is why it's like really important to take time to do that. And the blog post series and things like this are all kind of part of this like education campaign, because none of this stuff is actually impossible. It's just really hard work and requires an elite team and good vision and guidance and stuff like this. But but it's understandably conventional wisdom that it's impossible to do this.
MAX: Modular’s Inference Framework
Alessio [00:11:14]: And it's the idea to build serving basically. I don't need to tell you how much better this is. I can just actually serve the models using our platform and then you can see how much faster it is. And then obviously you'll adopt it. Yeah.
Chris [00:11:27]: Well, so today you can download MAX, it's available for free. You can scale it to thousands of GPUs you want for free. I'll tell you some cool things about it. So it's not as good as something like VLLM because it's missing some features and it only supports NVIDIA and AMD hardware, for example. But by the way, the container is like a gigabyte. Wow. Right. Well, why is it a gigabyte? Well, it's a completely new stack. It doesn't need. You can use CUDA, you can run arbitrary PyTorch models. And if that's the case, then OK, you pull in some dependencies. But like if you're running the common LLMs and the Gen AI models that people really care about. Well, guess what? It's a completely native stack. It's super efficient. Doesn't have Python in the loop. And for eager mode op dispatch and stuff like this, because you don't have all that dependency, guess what? Your server starts up really fast. So if you care about horizontal auto scaling, that's actually pretty cool. If you care about reliability, it's pretty cool. They don't have all these weird things that are stacked in there. If you're wanting to do something slightly custom, guess what? You have full control over everything and stuff's all open source. And so you can go hack it. This thing's more open source than VLM because VLM depends on all these crazy binary CUDA kernels and stuff like this that are just opaque blobs from NVIDIA. Right. And so this is a very different world. And so I don't want everybody just like overnight drop VLM because I think it's a great project. Right. But but I think there's some interesting things here and there's specific reasons that it's interesting to certain people.
Alessio [00:12:47]: Can you just maybe run people through the pieces of MAX because I think last time none of this existed.
Mojo Programming Language
Chris [00:12:52]: Yeah, exactly. Last time has been a long time ago, both in AI and also in modular time. Yeah. So the bottom of our stack is we think about it as concentric circles. So the inside is a programming programming language called Mojo. Chris, why did you have to build another programming language? Well, the answer is that none of the existing ones actually solve the problem. So what's the problem? Well, the problem is that all of compute is now accelerated. Yeah. You have GPUs, you have TPUs, you have all these chips, you have CPUs also. And so we need a programming language that can scale across this. And so if you go shopping and you look at that, like the best thing ish is C++. Like there are things like OpenCL and SYCL and there's like a million things coming out of the HPC community that have tried to scale across different kinds of hardware. Let me be the first to tell you, and I can say this now, I feel I feel comfortable saying this, that C++ sucks. I've earned that right. Having written so much. And so and let me also claim AI people generally don't love C++. What do they love? They love Python. Right. And so what we decided to do is say, OK, well, even and even within the space of C++, there isn't an actually good unifying thing that can talk to tensor cores and things like this. And so we said, OK, I want again, Chris being unreasonable, I want something that can expose the full power of the hardware, not just one chip coming from one vendor, but the full power of any chip. It has to support the next level of very fancy compilers and other stuff like this with graph compilers and stuff like that needs to be portable. So portable across vendors and enable portable code. So, yeah, it turns out that an H100 and AMD chip are actually quite different. That is true. But there's a lot that you can reuse across that. And so the more common code that you can have, the better. The other piece is usability. And so we want something people can actually use and actually learn. And so it's not good enough. Yeah. Just to have Python syntax. You want to have performance and control and again, full power of the hardware. And so this is where Mojo came from. And so today, Mojo is really useful for two things. And so Mojo will grow over time. But today I recommend you use it for places you care about performance. So something running on GPU, for example, or really high performance, doing continuous batching within a web server or something like this where you have to do fancy hashing. And like if you care about performance, Mojo is a good thing. Other cool thing that we're about to talk about. So stay tuned is it's the best way to extend Python. And so if you have a big blob of Python code, you care about performance, you want to get the performance part out of Python. You can make it. We make it super easy to move that to Mojo. Mojo is not just a little faster than Python. It's faster than Rust. So it's like tens of thousands of times faster than Python. And it's in the Python family. And so you can literally just like rip out some for loops, put in Mojo, and now you get performance wins. And then you can start improving the code in place. You can offload it to GPU. You can do this stuff. And all the packaging is super simple. And it's just a beautiful way to make Python code go fast.
Swyx: Just to double-click, you said you were about to ship this?
Chris: It's technically in our nightlies, but we haven't actually announced it yet. Isn't it? Okay. We do a lot of that, by the way, because we're very developer-centric. And so if you join our Discord or Discourse. Nightlies is great. It's like the best program. Yeah. And so we have a ton of stuff that's kind of unannounced but well-known in the community. Okay. I thought this was already released. Yeah. Yeah.
Alessio [00:16:12]: And when you say rip out, is this, you have a Python binding to then run the Mojo? Like, you have C bindings or how does that work?
Chris [00:16:19]: This is the cool thing, is it's binding-free. So think about, like, so today, again, sorry, I get excited about this. I forget how tragic the world is outside of our walls. The thing we're competing with is if you have a big blob of Python code, which a lot of us do, you build it, build it, build it, build it, performance becomes a problem. Okay. What do you do? Well, you have a couple of different things. You can say, I'm going to rewrite my entire application in Rust or something, right? Some people do that. The other thing you can do is you can say, okay, I'm going to use Pybind or Nanobind or some Rust thingy and rewrite a part of my module, the performance-critical part. And now I have to have this binding logic and this build system goop and all this complexity around I have Rust code over here and I have Python code over here. Oh, by the way, you now have to hire people who can work on Rust and Python and like that. Right. So this fragments your team. It's very difficult to hire Rust people. I love them, but there's just too few of them. And so what we're doing is we're saying, okay, well, let's keep the language that's basically the same. So Mojo doesn't have all the features that Python does. Notably, Mojo doesn't have classes. But it has functions. Yeah, you can use arbitrary Python objects. You can get this binding-free experience and it's very similar. And so you can look at this as being like a super fast, slightly more limited Python. And now it's cohesive within the ecosystem. Yeah. And so I think this is useful way beyond just the AI ecosystem. I think this is a pretty cool thing for Python in general. But now you bring in GPUs and you say like, okay, well, I can take your code and you can make it real fast. Because CPUs have lots of fancy features like their own tensor cores and SIMD and all this stuff. Then you can put it on a GPU. And then you can put it on eight GPUs. And so you can keep going. And this is something that Rust can't do. Right. You can't put Rust on a GPU, really. Right. And things like this. And this is part of this new wave of technology that we're bringing into the world. And also, I'm sorry, I get excited about the stuff we've shipped and what we're about to ship. But this fall is going to be even more fun. Okay. So stay tuned. There may be more hardware beyond AMD and NVIDIA. Nice.
MAX Architecture: From Mojo to Cluster-Scale Inference
Swyx [00:18:25]: So that was Mojo. Yep. The first concentric circle. Yeah.
Chris [00:18:28]: Thank you for keeping me on track. So the inner circle is the programming language, right? And so it's a good way to make stuff go fast. And next level out is you say, okay, well, you know what's cool? AI. Have I convinced you? And so if you get into the world of AI, you start thinking about models. And beyond models, now we have Gen AI. And so you have things like pipelines, right? And the entire pipeline where you have KV cache orchestration and you have stateful batching. And I mean, you guys are the experts, agentic everything and all this kind of stuff. And so next level out is a very simple Gen AI inference focused framework we call Max. And so Max has a serving component. Is it Max Engine? Yeah. Yeah. Okay. There's different sections. We just call it Max. We got too complicated with sub-brands. This is also part of our R&D on branding is that- HBO has the same problem. Yeah, exactly. Well, and also like who named LLVM? I mean, what the heck is that? Right? So- Honestly, it's short. It's Google-able. Not the worst. Yeah. And VLLM came and decided to mess with it. Yeah. Yeah. No. So Max, the way to think about it is it's not a PyTorch. That's not what it wants to be, but it's really focused on inference. It's really focused on performance and control and latency. And if you want to be able to write something that then gets Python out of the loop of the model logic, like it's really good for control. And so it dovetails and is designed to work directly with Mojo. And so within a lot of LLVM, there's LLM applications. As you all know, there's a lot of very customized GPU kernels. And so you have a lot of crazy forms of attention, like the deep seek things that just came out and like all this stuff is always changing. And so a lot of those are custom kernels. But then you have a graph level that's outside of it. And the way that has always worked is you have, for example, CUDA or things like Tritonlang or things like this on the inside, and then you have Python on the outside. We've embraced that model, like don't fix what ain't broken. So we use straight Python for the model level. And so we have an API. It's very simple. It's not, it's not like designed to be fancy, but it feels kind of like a very simple PyTorch. And you can say, give me an attention block, give me these things, like configure out these ops, but it directly integrates with Mojo. And so now it's, you get full integration. And in a way that you can't get because none of the other frameworks and things like this can see into the code that you're running. And so this means that you get things like automatic kernel fusion. What's that? Well, that's a very fancy compiler technology that allows you to say, okay, you write one version of a flash attention and then cool. We can auto fuse in and so you, and the other activation functions that you might want to use, and you don't have to write all the permutations of these kernels, but that just means you're more productive. That means you get better performance. I mean, it's like a lot of things. It's just drives down complexity in the system. And so you shouldn't have to know there's a fancy compiler. Everybody should hate compilers. Like the only reason people should know about compilers is if they're breaking, right? And so it just feels like a, a very nice, very ergonomic and efficient way to like build custom models and customize existing models and things like this. And so with max, we have five, 600 very common model families and, and implemented that you can see a build stop modular.com. We have a whole bunch of models. You can scroll through them. You can get the source code and play with them and do that. That's actually really great for people that care about serving and research and, and, and all this, this kind of stuff. Next layer out is you say, okay, well you have a very fancy, uh, way to do serving on a single node. That's pretty useful and pretty important, but you know, it's actually cool, large scale deployment. And so we have a next level out, level out cluster level. And so that's the, okay, cool. I have a Kubernetes cluster. I have got a platform team. They've, uh, got a three-year commit on. 300 GPUs. And now I have product teams. I want to throw workloads against this shared pool of compute and the folks carrying the pagers want the product teams to behave and so they want to keep track of what's actually happening. And so that's the cluster level that goes out and each of the, and so very fancy, um, prefix caching on a per node basis. And then you have intelligent routing and there's a whole bunch of, uh, disaggregated pre-fill and like a whole bunch of cool technologies at each of these layers. But the cool thing about it is that they're all co-designed. Yup. And because the inside is heterogeneous, you can say, Hey, I have some in AMD, I have some Nvidia. Hey, I throw a model on there, run it on the best architecture. Well, this actually simplifies a lot of the management problems. And so a lot of the complexity that we've all internalized as being inherent to AI is actually really a consequence of these systems that are being designed together. And so to me, what, you know, my number one goal right now is to drive out complexity, both of our stack, cause we do have some tech debt that we're still fixing, but, um, but of AI in general and AI in general has way more tech debt. And then it deserves.
Swyx: Well, yeah. I mean, there's only so much that most people excluding you can do to comprehend their part of the stack and optimize it. I'm curious if you have any views or insider takes on what's happening with VLLM versus SGLang and everything coming out of Berkeley.
Chris Yeah, I don't, I have outsider perspective. I don't have any inside knowledge. Um, SG Lang seems to me as an outsider, so I'm not directly involved with either community. Sure. Um, so I can be a fan boy without, without participating, but, um, as she, they have a beef going on. So I see, I don't know the politics and drama, but SG Lang to me seems like a very focused team that has specific objectives and things they want to prove. And they're executing really hard towards a specific set of goals, much like the modular team. Right. And so that's, so I think there's some kindred spirits there. VLM seems much more like a massive community with a lot of stakeholders, a lot of stuff going on and it's kind of a hot mess. And so. But they want to be like the default inference platform that everyone kind of benchmarks against. Well, and, and I mean, it's, as far as I know, it's like crushing TRT LLM and some of the other older systems and things like that. And so I think like metrics are good probably for that. And so I can't speak to their ambition, but, but it seems structurally like they're very different approaches. One is say, let's be really good at a small number of things that are really important. Yeah. That's our, that's our approach too. One is saying, let's just say yes to lots of things. And then we'll have lots of things and some of them will work and some of them don't. One of the challenges I hear constantly about VLM for what it's worth is if you go to go to the webpage, they say, yeah, we support all of this hardware. We support Google TPUs and Inferentia and AMD and Nvidia, obviously, and CPUs and this and that. And the other thing is they have this huge, huge list of stuff that they, they support. But then you go and you try to follow any demo on some random webpage saying, here's how you do something with VLM. And if you do it on a non-NVIDIA piece of hardware, it fails. And so what is the value of something like VLM? Well, the value is you want to build on top of it. Generally, you don't want to be obsessing about the internals of it. If you have something that, you know, advertises that it works and then you pick it up and it doesn't work and I have to debug it. It's kind of a betrayal of the goal. And so to me, again, I know how hard it is. I know the fundamental reason why they're trying to build on top of a bunch of stuff below them that they didn't invent that doesn't work very well, honestly. Right. Cause we know that the hardware is hard and software for hardware is even harder these days. So I understand why that is, but, but that approach of saying, here's all the things we can do. And then having a sparse matrix of things that actually work is very different than the conservative approach, which is saying, okay, well we do a small number of things really well and you can rely on it. And so I can't say to which one's better. I mean, I appreciate them both and they both have great ideas. And the fact that there's the competition is good for everybody in the industry. It is. And so. They're in the benchmark wars state of the way that this industry evolves. That's right. But, but, but I also hear just on the enterprise side of things that they're all so good. They don't want to follow the drama. Right. And so like, this is where having less chaos and more, I can work with somebody is actually really valuable these days. And, and you need state of the art, you need performance and things like this, but, but actually having somebody that is executing well and works together, can work with you is also super important.
Swyx Have we rounded out the offerings? You talked about Max. Yeah. Yeah. I realized like it impresses me that you named the company Modular and you've designed all these things in a very modular way. Yeah. I'm wondering if there are any sacrifices to that or is modular everything the right approach? Like there's no trade-offs.
Chris If you allow me to show my old age, like my, my obsession with modular design came from back when creating LLVM. Okay. So at the time there was GCC. GCC is again, I love it as a C and C++ compiler and stuff. Right. And have tons of respect for it, but it's a monolith. It was designed from the old school Unix, like, like compilers are Unix pipe. Everything's global variables, C code. It was written in KNRC. If you even know what that is anymore. And so it was from a different epoch of software and LLVM came and said, you know what everybody teaches you in school is you have a front end and optimizer and a code generator. Let's make that clean. Right. And so at the time people told me again, first of all, it's impossible to replace GCC because so established, et cetera, et cetera. But then also that you can't have clean design because look at what GCC did and it's successful. And therefore you can't have performance or good support for hardware or whatever it is without that. They might be right. If in an infinitely perfect universe, but we don't live in an infinitely perfect universe. Instead, what we live in is a universe where you have teams, like you have people that are really good at writing. Parsers, people that are really good at writing optimizers, people that are really good at writing a code generator for x86 or something like that. And so these are very different skill sets. Also, as like we see in AI, the requirements change all the time. And so if you write a monolith that is super hard code and hack today, well, two years from now is going to be relevant. And this is why what we see a lot in AI is we see these like really cool and very promising systems that rise and grow very rapidly. And then they end up falling. It's because they're almost disposable frameworks. This concept really comes from... The language is a framework. Each of these systems end up being different. But what I believe in very strongly is that in AI, we want progress to go faster, not slower. That's controversial because it's already going so fast, right? But if we can accelerate things, we get more product value into our lives. We get more impact. We get all the good things that come with AI. I'm a maximalist, by the way. But with that comes... The reality is that everything will change and break. And so if you have modularity, if you have clean architecture, you can evolve and change the design. It's not over-specialized for a specific use case. The challenge is you have to set your baseline and metrics right. This is why it's like compare against the best in the industry, right? And so you can't say, or at least it's unfulfilling to me to say, let's build something that's 80% as good as the best. But it's got this other benefit. I want to be best of in the categories we care about.
Open Source Contributions and Community Involvement
Alessio [00:29:16]: And when it comes to using like a prefix caching, pay-per-use, etc. Paged attention. How do you decide what you want to innovate on versus like, hey, you are actually the team that has built the best thing. We're just going to go ahead and use that. Yeah.
Chris [00:29:28]: I'm very shameless about using good ideas from wherever they come. Like everything's a remix, right? And so if somebody, if I don't care who it is, if it's Nvidia, if it's SGLang or VLM, and if somebody has a good idea, let's pull it together. But the key thing is make it composable and orthogonal and flexible and expressive. To me, what I look at is not just the things that people have done and put together. I don't put it into VLM, for example, but the continuous stream of archive papers, right? And so I follow, you know, there's a very vibrant industry around inference research. It used to be it was just training research, right? And much of that never gets into these standard frameworks, right? And the reason for that is you have to write massively hand-coded CUDA kernels and all this stuff for any new thing. And I would want one new D type and I have to change everything because nothing composes. Mm-hmm. And so this is, again, where if you get some of these software architecture things right, I mean, which admittedly requires you to invent a new programming language. There's a few hard parts to this problem, but the cool thing about that is you can move way faster. And so I'll give you an example of that. This is fully public because not only do we open source our thing, we open source all the version control history. And so you can go back in time and say, like, Chris likes open source software, by the way. Let me convince you of this. I don't like people meddling in my stuff too early. But I like open source software. And so you can go look at how we brought up H100, built Flash Attention from scratch in a few weeks, built, like, all this stuff. We're beating the TreeDAO reference implementation that everybody uses, for example, right? Written fully in Mojo. Again, all of our GPU kernels are written in Mojo. You can go see the history of the team building this, and it was done in just a few weeks, right? And so we brought up H100, entirely new GPU architecture. If you're familiar, it has very fancy asynchronous features and tensor memory accelerator things. And, like, all this goofy stuff they added, which is really critical for performance. And again, our goal is meet and beat QDNN and TRTLM and these things. And so it's not, you can't just do a quick path to success. You have to get everything right and everything to line up. Because any little thing being wrong nerfs performance. And we did that in, I think it was less than two months. Public on GitHub, right? And so, like, that velocity is just incredible. I think it took nine months or 12 months to invent Flash Attention. And it took another six months to get into VLM. And this is just, like, that latter part is just integration work, right? And so now you're talking about, like, building all this stuff from scratch in a composable way that scales against other architectures and has these advantages. It's just a different level. So anyways, our stuff's still early in many ways. And so we're missing features. But if you're interested in what we're doing, you can totally follow the changelogs. And you can, like, follow them nightly where we publish all the cool stuff and all the kernels are public. And so you can see and contribute to it. And you can do this as well if you're interested.
Alessio [00:32:19]: Yeah. Do you have any requests for projects that people should take on outside of modular that you don't want to bring in?
Modular's Differentiation from VLLM and SGLang
Chris [00:32:25]: Absolutely. So we're a small team. I mean, we're over 100 people. But compared to the size of the problem we're taking on. Size of your ambitions. Yeah. We're infinitesimal compared to the size of the AI industry, right? And so this is where, for example, we didn't really care about Turing support. Turing's an older GPU architecture. And so somebody on the community is like, okay, I'll enable a new GPU architecture too. So they contributed Turing support. Now you can use Max and Colab for free. That's pretty cool. There's a bunch of operators. So we're very focused on AI and Gen AI and things like this. By the way, our stuff isn't AI specific. So people have written ray tracers and there's people doing flight safety and, like, all kinds of weird things. Flight simulation? At our hackathon, somebody made a demo of, like, looking at, I think it was a voice transcript, the black box type traffic. And then predicting when the pilot had made a mistake. And the airplane was going to have a big problem. And predicting that with high confidence. So it's like your car, you know, you're driving your car until it starts beeping when you're not slowing down. It's like lane assist. Yeah, yeah, yeah. Okay, okay. That kind of thing. But for the FAA. Wow. And stuff like this, right? And I know nothing about that. Like, this is not my domain. Trust me. This is the power of there's so many people in our industry that are almost infinitely smart, it feels like. They're way smarter than I am in most ways. And you give them tools and you enable things. And also you have AI coding tools and things like this that help, like, bridge the gap. I think we're going to have so many more products. This is really what motivates me, right? And this is where I think we talked about last time. One of the things that really frustrated me years ago and inspired me to start Modular in the first place is that I saw what the trillion-dollar companies could do. Right? You look at the biggest labs with all the smart people that built all the stuff vertically top to bottom. And they could do incredible product and research and other work. And that, you know, nobody with a five-person team or a startup or something could afford to do. And here we're not even talking about the compute. We're just talking about the talent. Well, and the reason for that is just all the complexity. It only worked, for example, at Google because you could walk, proverbially walk down the hallway, tap on somebody's shoulder and say, hey, your stuff doesn't work. How do I get it to work? I'm off of the happy path. Like, how do I get this new thing to work? And they'll say, I'll hack it for you. Right? Well, that doesn't work at scale. Like, we need things that compose right, that are simple, that you can understand, that you can cross boundaries. And, you know, so much of AI is a team sport. Right? And we want it so more people can participate and grow and learn. And if you do that, then I think you get, again, more product innovation and less just like gigantic AI will solve all problems kind of solutions and more fine-grained, purpose-built, product-integrated AI. Yeah. I think one way of phrasing what you're doing is, you know, you have this line about it's, you want AI to accelerate and that's contrarian because it's already fast and people are already uncomfortable. But I think you're more, you're accelerating distribution. I have mixed feelings about the words democratizing, but that's really what you're doing. Well, it used to be, democratizing AI used to be the cool thing back in 2017. I know, it's not cool anymore. Yeah, I know. But it used to be the cool thing. And what it meant and what it came to mean is democratizing model training. Right? And it's super interesting. Again, as veterans, like back in 2017, AI was about the research because nobody knew both what the product applications were, but then we didn't know how to train models. And so things like that. Things like PyTorch came on the scene. And I think PyTorch gets all credit for democratizing model training, right? It's taught to pretty much every computer science student that graduates. That's a huge deal, but nobody democratized inference. Inference always remained a black art, right? And so this is why we have things like VLM and SG Lang because they're the black box that you can just hopefully build on top of and not have to know how any of that scary stuff works. It's because we haven't taught the industry how to do this stuff. And, you know, it'll take time. But I think that that's not an issue. It's not an inherent problem. I think it's just that we don't have like a PyTorch for inference or something like that. And so as we start making this stuff easier and breaking it down, we can get a lot more diffusion of good ideas. I want to double click a little bit more on some technical things. But just to sidetrack on, you know, VLM is an open source project led by academics and all that. And I think a lot of the other inference team, because effectively every team is a startup, like the fireworks together, you know, all those guys. Your business model is very different from them. And I want to spend a little bit of time on that. Happy to talk about it. You intentionally, well, you believe in open source, but, you know, it's not just that. You just choose not to make money from a lot of the normal sort of hosted cloud offerings that everyone else does. Yeah. There's a philosophical reason and differentiation. There's a whole bunch of reasons. Yeah. So like maybe remind people of what that is, like how basically how they pay you money and what they get for that and why you pick that. So, again, we're doing this in hard mode. Right. We took a long path to product. We're not just right away. We're going to get a few kernels and have some alpha and go buy a GPU reserve thing and resell our GPUs like that. That path has been picked by many companies and they're really good at it. So that's not a contribution that I'm very good at. And I'm not going to go build a data center for you like this. There's people that are way, way better than that. Okay. And so all the best luck. I want that. Literally Crusoe like walking the Stargate grounds. I want those people to use Macs. You know, I'm pretty good. That's a Crusoe. Yeah. I'm pretty good at this software thing. And so you can handle all the compute. Moreover, if you get out of startups, you have a lot of people that are struggling with GPUs and cloud. Right. And so GPUs and cloud fundamentally are a different thing than CPUs and cloud. And a lot of people walk up to it and say, it's all just cloud. Right. But let me convince you that's not true. And so, first of all, CPUs and cloud. Why was that awesome? Well, all the workloads were stateless. They all could horizontally auto scale. CPUs are comparatively cheap. And so you get elasticity. That's really cool. You can load them pretty quickly. Yeah. It's not like gigabytes of weights. Yeah. And so it turns out what business, you know, knows what they're doing in two and a half years? Nobody. Nobody. Right. And so cloud for CPUs is incredibly valuable because you don't have to capacity plan that far out. Right. Now you fast forward to GPUs. Well, now you have to get a three year commit. Three years. Right. So you have a three year commit on a piece of hardware that Jensen's going to make obsolete in a year. Right. And so now you get this thing. And so you make some big commit. And what do you do with it? Well, you have to overcommit because you don't know what your needs are going to be and you're not ready to do this. Also, all the tech is super complicated and scary. Also, GPU workloads are stateful. And so you talk about like the fancy agentic stuff and you all know all this stuff. Yeah. It's stateful. And so now you don't get horizontal auto scaling. You don't get stateless elasticity. And so you get a huge management problem. And so what we think we can do and we can help with people is say, OK, well, let's give you power over your compute. And a lot of people have different systems and there's very simple systems that go into this. But you can get like five X performance TCO benefit by doing intelligent routing. That's actually a big deal for a platform team. They don't like to have to deal with this. They want hardware optionality to get to AMD. They want this kind of. Power and technology. And so we're very happy to work with those folks. The way I explain it in a simple way is that a lot of the endpoint companies and there's a lot of them out there. And so you can't make they're not all one thing. They obviously have pros and cons and tradeoffs. But but generally the value prop of an endpoint is to say, look, AI and AI software and applications and workloads. It's all a hot mess. It's too complicated. Don't worry your little head about it. I'll take AI off your plate so that you don't have to worry about it. We'll take care of all the complexity for you. And it'll be easy. Just talk to our endpoint. Our approach is to say, okay, well, guess what? It's all a hot mess. Yes, 100%. Like, it's horrible. It's worse than you probably even know. And get to tomorrow. It's going to be even worse because everything keeps changing. We'll make it easy. We'll give you power. We'll give you superpowers for your enterprise and your team. Because every CEO that I talk to not only wants to have AI in their products, they want their team to upskill in AI. And so we don't take AI away from the enterprise. We give power over AI. We give power back to their team and allow them to both have an easy experience to get started. Because a lot of people do want to run standard commodity models and you do want stuff to just work as table stakes. But then when they say, hey, I want to actually fine-tune it, well, I don't want to give my proprietary data to some other startup or even some big startups out there. And you know whose these are. That's my proprietary IP. And then you get to people who say, hey, I have a fancy data model. I actually have data scientists. I actually have a few GPUs. I'm going to train my model. Cool. That got democratized. Now how do I deploy it? Right? Well, again, you get back into hacking the internals of VLM. And PyTorch isn't really designed for KV cache optimizations and all the modern transformer features and things like this. And so suddenly you fall off this complexity cliff if you care about it being good. And so we say, okay, well, yeah, this is another step in complexity. But you can own this and you can scale this. And so we can help you with that. And so it's a different trade-off in the space. But I will admit that there are time to market and revenue growth and stuff like that. And that has been much faster because they didn't have to build an entire replacement for CUDA to get there.
Modular’s Business Model and Monetization Strategy
Alessio [00:41:37]: Nice. And when it comes to charging, people are buying this as a platform. It's not tied to token, inferred, anything like that.
Chris [00:41:45]: We have two things going on. So the Max framework and the Mojo language, free to use on NVIDIA and CPUs, any scale. Go nuts. Do whatever you want. Please send patches. It's free. Right. Why is this? Well, it turns out CUDA is already free. NVIDIA is already dominant in here. We want the technology to go far and wide. Use it for free. It would be great if you send us patches, but you don't even have to do that, right? We do ask you to allow us to use your logo on our webpage. And so send us an email and say, hey, you're using it and you're scanning on 10,000 GPUs. That'd be awesome. But that's the only requirement. If you want cluster management and you want enterprise support and you want things like this, then you can pay on a per GPU basis and you can contact our sales team. And then we can work out a deal and we can work with you directly. And so that's how we break this down. And also, let me say it. One thing I would love to see, and again, it's still early days, but I would love to see PyTorch adopt Macs. I'd love to see VLM adopt Macs. I'd love to see SGLang adopt a Macs. We have our own little serving thing, but go look at it. It's really simple. It would be amazing. And again, we're in the phase now where I do want people to actually use our stuff. And so we have historically been in the mode of like, no, our stuff's closed, stay away. But we're phase shifting right now. And so you'll see much more of this being announced. Yeah. I don't know how to make this happen, but I think you win when Mistral, Meta, DeepSeq, and Quen adopt you and ship you natively, right? How does that happen? I don't want to talk that far in the future. I don't think it's that far. We may have an industry-leading state-of-the-art model launching first on Mac soon. I'll stay tuned for that, but also let us know. But that hasn't happened, so assume it doesn't happen. I think that's when it really tips. Because then everyone's like, okay, it's good enough for them, it's good enough for us, right? And then you get the rest of the industry. Yeah. But again, I mean, I'm in it for a long game, right? And I realize, again, the stuff I work on, it takes time for people to process. And so what we need to do and what I want us to do and what I ask the team to do is keep making things better and better and better and better and better. And there's like an S-curve of technology adoption. And so I think it's great that there's a small number of crazy early adopters that were using our stuff in February. Before it was open source, and it made no rational sense. It barely worked. But it was amazing, and I'm very thankful for those people. And then, of course, we open sourced it, and we started teaching people, and you get a much bigger adoption curve. You make it free, go adopt and go. And then, as you say, there's more validation that will be coming soon. And each of these things is a knee in the curve. But what it also does is it gives us the ability to fix bugs and improve things and add more features and roll out new capabilities.
Swyx: How does this feel, rolling this out, as compared to software?
Chris: Oh, well, so let me reinterpret your question. Given you've done a few interesting things in the past, what have you learned? And what are you not doing again? That actually is a better question than the one I asked. Because Swift is too narrow, almost. The character of Swift, so just because I assume most people don't know about this. Character of Swift was I started as a nights and weekends project in 2010. Hacked on it alone, nights and weekends, for a year and a half. Eventually told management at Apple about it. Their heads exploded. Like, why do we need something? Objective-C is good enough, why do you need this? Got approval to have a couple more people get involved in it. You were on a fellowship or an internship at Apple at the time? No, I was leading the developer tools team. I think you were doing something, yeah. Yeah, I was leading a huge team. Let's just say this was not my day job. But so, started in 2010. It launched publicly by Apple in 2014. And by the time it launched in 2014, only about 250 people in the world knew about it. Most of whom were in my team. About 200 and something of them were in my team. And then it was senior execs, marketing, Tim Cook, etc. And this was the category of people that knew about Swift. So we had built it in secret. Literally an NDA. Within Apple. To know about it. When we launched it, part of the requirement was that you had to be able to submit apps to the app store in Swift. That was the requirement put on me. And so it's like, cool, that sounds great. And so we launched it and said it's a 1.0. So you're launching a 1.0, brand new programming language. Nobody has ever seen it before. No internal user. Like one demo app. It was a frickin' nightmare. Yeah. So it was a nightmare for the community. Because, I mean, fortunately a lot of people were excited and wanted to adopt it. And a lot of people did adopt it right away. But it was not battle-hardened. It had tons of bugs. We should have launched it as a 0.5. Right? And so it took another year for it to become. Pretty good. And then two years for it to become quite good, in my opinion. Also, none of the software engineers at Apple knew about it. And so they, their heads exploded. They said, wait a second, why are you replacing Objective-C? I joined Apple because I love Objective-C. Why didn't you ask me my opinions about the new programming language? Right? And so there's that whole dynamic. Oh, was there a company mandate that they had to write Swift from now on? No. But still, it's like, wait a second, this isn't the company I thought I joined. Right? And stuff like this. Right? And so there's this huge amount of turmoil and drama and nonsense that came out of that. And so, okay, fast forward to Mojo. Lessons learned. Hey, one, don't have a hot start. And so we launched Mojo a long time ago, before it even made sense. And we called it a 0.1. And so that, how's that honesty in advertisement? Right? It's like, this is 0.1. Please don't use it. But if you're interested, we'd love your feedback. Right? And so soft start, go. Second thing that's very different is that in Swift. We had one demo app. And so you have a very, I think, high power team building a language that had done lots of credible stuff, but was building a language for iOS developers. And the compiler's written in C++. Right? And so, yeah, there's sympathy for the user, but not a lot of understanding and not a lot of learning internally when we launch. In the case of Mojo, guess what? Modular is Mojo's first customer. We have more Mojo code in our repository than any other language. Right? That's awesome. And it's open source. And we open source like 650,000 lines of Mojo code. Right? This is a lot. And so we suffer and we drive the features and the improvements based on our needs. We also appreciate the community. And we have a whole bunch of contributions coming in. And somebody just optimized my string to get rid of a bit out of my string implementation, which was suboptimal. And so that was super awesome. But driving it that way makes sure it's real. It's grounded. It's on the use case. We're trying not to overpromise. Even when you're asking me what it's useful for earlier, I didn't say it's a replacement for Python. I said it's a go-fast language. Someday it may be a pretty credible Python alternative. But for right now, it's good at a specific class of use cases. And if you're interested in those use cases, like making GPUs go brr, Mojo's awesome. But if you want a replacement for Rust end-to-end, give us six months. Yeah. Yeah.
Swyx: I mean, you're a force of nature. I think there's a lot of mystery around what is going on with Apple's AI initiatives. And I think the consumers suffer. At the end of the day, the end users are waiting for this. And it's not happening.
Chris: Unfortunately, anything I know is massively out of date. They've changed and reorged and grown and culture. And it's a very successful company. And so I think that they probably feel success. And they're having trouble adapting to changes in the industry. And that's pretty typical of a lot of big companies. And so I can't speak to the specific causes. Speaking of Google, obviously, I think they were one of the earliest. What are we talking about? The invented transformers. A lot of other things. TensorFlow, remember that? Yeah, exactly. Huge. Yeah. NTPs. I credit Google with making AI open source. Well, they did not have to open source TensorFlow. Yeah. That was an incredible decision. Full kudos to Jeff Dean and many of the other people that were involved in this. Because they said, you know what's actually the most important thing for Google? Is for AI to go faster. How do we do that? We open source TensorFlow rather than making it some proprietary internal thing. Which they had a previous system called Disbelief. And so that is a huge moment that set the stage for PyTorch to be open source. And for the research to be open. And for all of these things. Because they decided the value system was AI go faster. The transformer paper being published. So many contributions from Google came from that. I don't think Google gets enough credit for that. Yeah. Why is it better for Google for AI to be open source rather than Google owns it? Well, so I can't tell you if the bet worked. But I can tell you that that was a bet. But from my outsider now perspective, because I haven't been at Google for over five years somehow, time flies. The bet makes sense when you have an amazing team of researchers and Swyx that can go incorporate this into your products. And so Google does have billions of users. It has all the product services. It has all the different applications. And it has an incredible density of talent. And I think that Google's recent announcements, so just after Google I.O. and things like this. Yeah, we were both there. Yeah, it's like Google's actually working, I think. It's pretty impressive. And for a while they were dealing with organizational drama and Google Brain versus DeepMind and some of this stuff. And I can't speak to what they've done. But it seems like they're a much more unified team. They're executing well. They're getting research into product. And so it feels like a different Google to me. Yeah, it totally does. It used to be that there was just two of everything in Google. And you didn't know which one to use. Killed by Google. They all deprecated in a year. So yeah, I think they've gotten the memo, whatever. Yeah, and the other thing that's super impressive to me about them, and this is me fanboying Google, right? Sure. After railing, it's the trillion dollar companies. But the things that they announced they were actually shipping. Yeah. So much in AI is. This is more Apple shade. I wasn't specifically saying Apple. This is very common in AI. And Modular's done this in the past too. This is why. So I gave this very deep tech talk. I sent you a link to the GPU mode talk. And slide two was warning. You can actually use this. This is not vaporware. Everything here you can reproduce. These claims you can download. This is actually real. Here's links to the source code. I was wondering why you stressed that so much. I'm like, who hurt you? I know. I mean, there's so many claims. Nobody knows what is real anymore. I know. Right? And I mean, there's literally been product demos where it's like. Some electric semi rolled downhill instead of working under its own power. And nobody knows what's real.
Alessio [00:52:18]: I knew they started to work. There's like a WhatsApp chat. We're like playing soccer at the Google field during the week. And about six months ago, some the admin posted. It's like, hey, not enough people are showing up anymore to play soccer at lunch. What is going on? And I think that's when people started. That's your Google indicator. Working again. Yeah. There you go.
Chris [00:52:35]: I mean, Sergey Brin was at IO. And he's definitely. He's like working again. And it's awesome. Yeah. So I have mad respect for that. Right. And so my values are aligned with people who ship stuff. Yeah. Because that's what impacts the world.
Alessio [00:52:47]: Let's talk about open source a little more. There's the more recent maybe open source thing, which is deep seek, obviously. And I think specifically in your case, you know, they worked at the BTX layer of the GPU, which is like even lower and more proprietary than CUDA. Yeah. I'm curious how both in terms of like, obviously the impact was like huge, but maybe impact on how much people should actually try and move away from this proprietary. Because now the next, from my understanding is like the next set of chips, all the code is like useless.
DeepSeek’s Impact and Low-Level GPU Programming
Chris [00:53:17]: Well, so it's not widely known, but Blackwell is not compatible with Hopper. Right. Hopper kernels don't always run on Blackwell, for example. Right. But so your question is like, what does it mean for the industry?
Alessio [00:53:27]: Well, it's like, why is it so important? Like why the DeepSeek, the DeepSeek example is like so important of like they need to navigate all this like proprietary stuff just to make it work. Yeah.
Chris [00:53:37]: So I'll give you my lived experience. Yeah. Because deep seek came out in December, which is when I, and probably you noticed it. Right. But then the world had a big wakeup call and video stock price went down and all that stuff like a month later. Right. And so here's my explanation of what happened. Okay. What the deep seek team did was really impressive research. They pushed MLA forward, like they, which is a form of attention and they pushed a low precision training forward. They pushed a whole bunch of stuff forward. They reverse engineered some PTX instructions that weren't well known at the time. Right. Yeah. And so a lot of people were just like, and it was a Chinese team, right. Which put Americanism, threatened Americanism, right. And things like this. And so what I found really exciting about it was they pushed the research forward and they did this incredible things. They showed the world that it was possible and they opened it and they published it and they actually taught the world about it because I don't know why they chose to do that, but it's because they believe in openness and AI moving forward. Right. Yeah. Yeah. Yeah. Yeah. So I think the other thing that I found striking is that the world's reaction to that was more striking to me than the actual world. Or whatever. I don't know. Yeah. Because, so first of all, there's the Chinese American drama, which geopolitics is not exactly my strong point. So I w I, I get it then I push that aside. Right. But the other thing I found really interesting is that people said, wow, okay. Only deep seek is able to go down to the PTX level, but that is standard. That is what all of the leading teams do in the case of modular. Yeah. We only work at that level because we get rid of all of CUDA, right? And so we've replaced the entire stack. And so we only do that. But a lot of teams that care about performance will actually go down and use the PTX, TensorCore, Instruction, Foo, which isn't really documented. You kind of have to figure it out and look at cutlass code. NVIDIA doesn't make it as easy as they should to do this. I wonder why. Well, I think it's because they're breaking in Blackwell, and so they didn't want people to actually use it, and so they had their own issues, right? But good luck with that. There's a lot of smart people out in the world. And so to me, I thought it was really interesting because there wasn't a lot of awareness of how that level of the stack worked. For me, I thought it was a great wake-up call where people were like, oh, wow, if you work at this level of the stack, a level of the stack I have inhabited for decades now, you have power over compute. You can understand and solve problems. You can drive research forward in ways that nobody else can do. And this is what the trillion-dollar companies do. It's not just DeepSeek. But I think DeepSeek was a huge wake-up call, and it drew attention to that layer of the stack because it wasn't just like throwing layers on top of PyTorch or VLM or it was like doing that fun amount of work. And I thought that was incredible. Now, the challenge with it and the challenge with the way DeepSeek did it and the way that everybody else does all this work is that it's completely specific to one GPU. It's not just that you're working at the PTX level. It's that you're writing code that really can only work on that one GPU, and that means that when Blackwell comes out, you have to throw it away and write a new one, right? But here's the open secret. That's what VLM is. Go look at VLM. They have different kernels for AVLM. They're now trying to catch up with Blackwell. And so, state-of-the-art for these systems, since Gen AI, before that, there were fancy AI compilers like XLA and that kind of stuff in the Trat AI world provided some scalability. But in Gen AI, it's a rewrite all the things when a new piece of hardware comes out. And so this is what Mojo is solving, right? And this is where, again, we can't turn the incremental cost of a new piece of hardware to zero, but we can massively reduce it. And so this is a really exciting time, I think, for us that we've demonstrated now, but also what it means for the future. I still also wonder their hiring or internal training, that they managed to have a small team that does this in the same way that you do. I think they have a pretty significant team. I have no insider information, of course, but it's not like a five-person team. It's like hundreds of people. Okay, yeah. So it's... Yeah, you know, it's not a thousand, right? It's amazing, especially like, I mean, presumably there's some language barrier, but even ignoring that, just getting that amount of talent density in one company, it's not a significant task. Yeah, well, I agree with that. Building a company is hard. I have no visibility on how they built DeepSeek, but all I can say is thank you to DeepSeek for publishing their work. Yeah. Because they didn't have to do that. And I think it left temporarily a lot of people flat-footed. Right? And it was kind of embarrassing for certain groups, and I think a lot of people paused and were like, ooh, crap, what do I do about this? But I think that what it did is it pulled forward progress in AI by like six months. Yeah. They didn't just do GPU-level stuff. They also had a file system. Oh, yeah. If you've looked at... Yeah, it's incredible. Do you see... Obviously, that's not modular as bread and butter, but do you see a potential there for someone else to, I don't know, take that and run with it? I've been very obsessed with the inference problem for a couple of years, and so I don't know the best way to solve that problem for training. Google internally has a great... Indeed. Right? And so where is that for the rest of the world? Yeah. I'm honestly just not the right person to answer that question because I have my own obsessions. Yeah. Well, talking about inference, reasoning models and inference time compute, very big topic. Does anything change or does nothing change? Because it's just more inference. It depends on change from what, right? So when we started modular over three years ago, we made the ridiculously weird bet at the time to focus on inference instead of training. Yeah. And again, at the time, I'm used to this. People are like, what's wrong with you? Everybody obviously knows that training is the thing, and training, training, training, and people building these massive clusters, and all the spend is on training, et cetera, et cetera, et cetera. And I said, well, yeah, I understand why you see that, but I've lived this at Google. Google's like five years ahead of the rest of the industry. The most scaled inference, yeah. Yeah. Training scales the size of your research team. Inference scales the size of your customer base. Right? And so the thing that happens between those is research gets into production. And so the gap is research getting into production. Once you do that, suddenly it scales like crazy. So I didn't plan for Gen AI. I did not plan for inference time compute. And things like this. But that bet on the production use case, because it scales with the number of applications of AI, not just the hot research team, right? Which, you know, is pretty important. It's just not something I've focused on for the last few years. That was controversial. And so I think now the whole world's flipped, and I think the world gets it, right? But that was really because of lived experience. And so when you come to these new techniques, right? Another controversial thing, going back to the CPU thing, is why are you starting with CPUs? The answer at the time was pre-processing. Post-processing, full system integration, networking, you need a CPU to feed the GPU, like very standard things. But now you say KV caches. Like your eviction policy runs on a CPU. Like that Radix hashing algorithm and block hashing and all that stuff happens, like primarily CPU. That's really important for performance, because if you have latency in these steps, like you're not keeping your GPU utilized, right? And again, this comes back to the rewrite and rust and things like this. All the agentic stuff and things like this, I didn't predict that, but I'm not surprised and I think we're going to see more. And so tight integration, optimization across boundaries, like these are things I believe in. And I think this is how you move the world forward. It's amazing how like basically all the smart programmers I know always focus on where the bottleneck is. And it always leads you to the right answer. Like if you just are very clear eyed about that. And I don't know, it's nice to see that happening. The other talking point I'll mention for you, because you didn't bring it up, but it's something that other people are talking about, is that actually now because of the requirement for train of thought and reasoning models, inference is now part of training.
Swyx [01:01:06]: Okay, yeah.
Chris [01:01:07]: Because you need to inference. RL has always done that. To RL, yeah. And so that actually is a plus in favor of what you're doing anyway. Yeah, absolutely. Because it's the same code. So my experience with RL systems were like at scale, DeepMind style, AlphaGo and things like this. So it's been a couple of years ago, but setting those things up was incredibly complex. Because now you're dealing with cluster scale orchestration, you're batching across all these agents. And again, none of the systems are set up for that, right? You've got PyTorch if you want to train a model, but nothing is set up to do this. And so again, I can't speak to all RL systems everywhere, but they ended up being like duct tape and bailing wire and super crazy stuff. And it was incredible. Again, it's incredible what a team of experts who knows the full stack and what they can achieve, but it shouldn't be that hard. And so we're not just not focused on solving that, we're not focused on solving the problem yet. Maybe we'll get there. We have the building blocks. We have the building blocks. And again, we're not focused on solving training yet. Maybe we'll get there. I have some ideas on logical steps to do that, but I want to make sure we're grounded and we solve things all the way end to end. We make people happy. People talk about our stuff from their voice. It's not just me talking about our stuff. And so we're in that phase where you'll hear people talking about our stuff soon. I think people already are, but they will even more. And I think I appreciate you coming on the podcast to talk about that more. And we want to turn to some personal stuff.
Personal Reflections on Leading Modular
Alessio [01:02:31]: So I think that was a great Modular story. I think now on the personal side, there's a couple of things. So when you first joined us, I think I saw it was September 2023. So that was a year and a half into building the company, something like that. Now three years and a quarter. And what are personal learnings, both from obviously being a leader in a company, having a growing team that you're managing, having a lot of responsibilities that are not technical anymore? Kind of run us through some of that. Yeah.
Chris [01:02:58]: So for me, I've built a lot of things. I've built large teams from scratch before, but they've all been at established companies. I've worked at a startup before, but it was somebody else's startup. And so this is the first startup that I've founded and then built a significant team and built a product that takes years to build. So a lot of the lessons I learned were super valuable and allowed me to achieve some of the stuff. But it's also very different. And so one of the things that's very different is it's very personal. And so I've lost people from our team before, like many times. I've had to fire people and people have quit and gone Apple to Google or whatever. But that was never personal in the same way it is at Modular. And so this is something where the intellectual side of my brain knows if somebody leaves, it makes sense. They had a life change. I don't want to get in the way of their family or whatever. I mean, I intellectually know that. But on the other hand, it hurts a little bit. And so I think I'm getting better at handling some of that kind of stuff. The other thing is that when you're growing a team from zero to 100 people at a big company, you have all of the infrastructure. And the infrastructure is mature, right? And so even if you grow to a team of 100 people, you're still tiny compared to an Apple or Google or a company like this. You're still tiny in proportion to the size of the overall scale. And so they've already got all the recruiting and all the other stuff and all the legal and finance and all that kind of stuff going. They've got the manager training. They've got all this stuff going. And so in a startup, you're sometimes getting some hot messes where it's like, okay, well, I need to do reorganization and things like this. And so that's been good learning. It's scaled into that well. And another thing coming back to the people telling you it's impossible. Actually, here's probably the most important thing is that I'm used to being told that things are impossible. And then I'm pretty bullheaded and I have a formula. And so there's a path to success. And I can explain if you want. But I'm used to the feeling when it's that year one and it's just a completely skunkworks, let's prove a thing phase. I'm used to that. Okay, cool. Now we're telling people about it, but it's still not good enough. And people tell you all your stuff sucks. I'm used to that. Like, okay, well, you get into that window where all this stuff is almost there. People are sweating. It's really hard. There's like all these like seemingly impossible things. It's a significant team, but the pieces don't line up yet. And so we went through some of that last fall and people like, oh my gosh, maybe it will never work. And you get this like anxiety. And I think the thing that I didn't appreciate going through that, and this is also why I'm so excited to be in this phase that actually impacts other people's, like their thought processes. Cause. Cause they haven't been through it and they, and they like, trust me, we'll get there. Well, when like exactly what, like you get these like super analytical engineers who want to understand everything and they're really expert in their part of the stack and they don't really have that established trust with the other department and the other department, the other department are all lining up. And so definitely some mornings from that, but, but this is where, again, you get out of that R and D phase and you get into the execution phase and it's like, okay, well, engineers are really good at taking an imperfect thing that works end to end and making it better and better. And better and better and better. And so it's, it's just like feels fundamentally different modular now than it did in any of those previous phases. Yeah.
Alessio [01:06:04]: What's your day to day. Like you have a lot of meetings, you have just a few.
Chris [01:06:08]: Yeah, I have a lot of, you're talking about my, my, my lived life. Um, a normal weekday for me is, um, I wake up about seven 15, my wife and I get the kids out the door and she drives them to school at about eight. I usually do a half hour, 45 minute walk with my dogs, get exercise strenuous up and down the hill. Heart rate goes up. Which is good. Listen, podcasts, for example, yours. So that's, you know, why, why I have time to actually follow exciting, cool things that other people are doing, get to work at nine and so work nine to six or seven or something like that. And most of that is meetings. And so that's me trying to solve whatever the problems are of the day, get home, dinner with the kids. I insist on eating with my family, hang out with them until bedtime and then crush through for like two, three more hours until I pass out and do that regularly. The second work day. Yeah. Yeah. Yeah. Yeah. And on the weekend, it's amazing because I get a lot of time to work, not all day because I do things with kids and stuff, but I get a lot of time and there's no meetings. So that's amazing. That's when stuff actually gets done. Yeah, exactly. I think the, the key here is some kind of strategic review time that you lock off because like, I think people often say, you know, you're there's, there's times when you're working in the business and then there's times you're working on the business where you step out for a bit. Often for, for founders is when you do a board meeting. But I wonder if there's any. Anything that's very meaningful for you. Do you have a coach? Do you have something like that? Yeah. Yeah. So I guess there's two people I really owe a lot to, um, or two, two categories. Like, so one is my co-founder, Tim. Yeah. So Tim and I formed the company together. Uh, we walk every week, every Friday, catch up and it's like that zoom out and try not to make it tactical. And so make sure that we can bounce crazy ideas off. And I have a lot of crazy ideas, believe it or not. He does too. But then ground ourselves on execution and go. The other thing is. Yeah. This combination between my wife, who's a sounding board and the executive team. And I get a little bit crazy and want to solve the industry problem. And the exec team pulls it back to, okay, next quarter, let's make sure we have a plan. Let's make sure we can communicate. Let's decide what the actual priorities are. Okay. We can have three priorities, max for the whole team, not, not 50 or something. Otherwise they're not priorities. Yeah, exactly. Everything can't be the top priority. Otherwise nothing else. Right. And things like this. And then my wife who keeps me sane and has, you know, I don't know.
Daily Routine and Time Management as a Founder
Alessio [01:08:27]: She's an amazing life, life coach. How much do you get your wife involved on like the actual work?
Chris [01:08:33]: Like does she know, like, you know, yeah, she has her own thing going on. Uh, my wife runs the LVM foundation. And so she's got a bunch of things going on plus kids and everything else too.
Alessio [01:08:41]: She's like, I don't want to hear about this Cardinals.
Chris [01:08:43]: Well, but she's, she's great for helping me. So I'm more IQ than EQ. And so working with humans is not, it's an acquired skill, not a natural skill. And so I think this is something where once. Uh, you know, I often ended up this place where some weird thing is happening, what the heck is going on? It's like, Chris, it's obvious, like they're saying this, but this is what they actually mean. I'm like, oh, I never thought about that. You know, you mentioned coding agents. Yeah. What do you guys use internally? What do you like? Yeah. So, I mean, as of this recording, I personally use cursor and so cursor is great for, I mean, it's the best thing I've seen and I don't spend a lot of time dabbling with things. And so, but cursor is, uh, so I write a lot of C plus plus and mojo code, the key thing for working on. Mojo code in AI coding tools is make sure you have a lot of code in the context window. Yeah. And so cursor and these tools can index really well. I was thinking you open source mojo code. Actually, that's pretty good. That's one of the reasons we did this. Yeah. And one of the many reasons we did this. And so this is what we saw at our hackathon is people could go zero to hero with mojo because you could just put, you just index this entire huge code base and it's, it's phenomenal. And then learning a new language is actually easy when the AI is doing a lot of the mechanical stuff for you. And also it looks like Python, so you could read it, but it just like massively scales the on-ramp. Yeah. Yeah. So for new language adoptions, AI is, let me convince you, AI is cool. I would just go ahead and like, actually like ask the data sets people at the big labs what they need. Yeah. And then just like, I've asked them all feed it to them. Yeah. Just take the code, please label it for them. It's Apache too. Like just go. Yeah. Yeah. We're adding markdown files. There's a cloud.md. And so we're doing, we're doing some of the basic stuff, um, people within the company are dabbling with cloud code and some of the stuff. And so I don't have personal experience with that, but, um, but for me, I found that it's mostly, it is very. Useful, but it's really about boilerplate. And so it's not about inventing new algorithms and stuff like this. And it's probably, cause I'm not building a react component. Yeah. I mean, so the labs are touting that they are training or benchmarking their models for writing CUDA kernels. Right. I wonder if you see a noticeable performance improvement when you change model to model. I don't know if you, you probably don't benchmark them. I haven't, I haven't looked at that specific use case. Um, but, uh, people often ask me. Hey, Chris, why are you building a new programming language when AI is going to write all the code? Similarly, if you look at a lot of this, like let's generate a CUDA kernel, you start to ask and wonder, or at least I do a lot. What is the purpose of code? What I've reflected on the way I currently think about it subject to change, obviously, because we're all learning. I take a step back. I say, well, code isn't really about telling the computer what to do. Code is about humans being able to understand what code does. And so someday when we get AGI or ASI or something like this, maybe it can be completely opaque. And I really don't have to know, we're not there yet. So, and I don't know when that will happen, but in the meantime, like I want to be able to look at what the code actually does. And I live in a world of constraints. I need to know I have a product which has all these features. If I go add another feature, what happens? It's going to hit my latency budget. Is it going to crash around memory? Is it going to do, is it going to cost too much? Like I need to be able to reason about this. And so to me, I look at a lot of these coding tools, you know, scaled beyond where they currently are now, but into the foreseeable future is saying like, okay, well, it's like hiring another engineer onto your code base or into your team. And fundamentally coding and software engineering is a team sport. And like you have product managers, you have engineers, you have a lot of things. And if you automate all the engineering of code, maybe you get to product managers only and marketing only or something theoretically, but you still want to reason about what the code does. And so in that, yeah, interpretability argument. And so in that world, like what is actually the most important thing, most important thing is you can. Express. Everything the hardware can do, because you don't want to have some capabilities, some costs or some, some boundary you can't penetrate mojo does that. The second is you want readable code that you can actually understand, right? And so you don't want assembly language or something like that. You want something high level and expressive and easy to understand. And so like, this is where I think mojo is really unique. And then the AI coding tools I see is a straight value add for adoption. Cause I mean, I've already seen what people that have never touched any of this stuff can do. And it's just incredible. You put somebody that's. It's intelligent. They know the use case and now you put these tools in their hands and they can do amazing things already. And so I find it super empowering. And again, come back to me wanting to see humans being empowered with new technology and being able to upskill and be able to learn, you know, you're not a GPU programmer today, but you know, tomorrow, hopefully there'll be 10 times as many people programming GPUs. I think that'll make the world a better place. And so I don't think we're going back to the world of CPUs. I think GPUs will only get more important. And if we can help people do that, I think it's great.
Using AI Coding Tools and Staying Current with Research
Alessio [01:13:24]: You mentioned some of the research on inference and the archive papers. How do you keep up with archive?
Chris [01:13:31]: Yeah, it was, we're a Slack shop. And so we have a paper channel. It's I think, I think there's a, I don't know, somewhere between three to 10 papers a day that come through. And, and so we have amazing, smart people that do that. I also follow, uh, the Reddit communities and things like this. I'm an old school person that uses RSS still. And so if you have an RSS feed, then it's way easier for me to follow you. Which reader? Yeah. And, and, uh, I use Feedly. Feedly. Yeah. But, um, archive has the ability to follow specific groups. And so I do that for various groups. And so that's, that's another technique. Any notable papers come to mind that you want to give a mention to, or, or authors, you know, that you're really watching when anytime they publish, you're like, I'm reading that one. I can't give you a well-considered answer. Um, just, just this morning, a person from Microsoft published a paper, uh, forget his name offhand, but, uh, he just published a paper. It's a really cool paper about auto-generating, uh, flash attentions and doing blocker or something. It had some cute name with block in it. And so anyways, I mean, there, there's a ton of things going on. Okay.
Alessio [01:14:33]: So that kind of, yeah, you know, it's interesting to just see what you pay attention to. Last but not least, the question that everybody wants the answer to, have you finished building the Lego robotics table for your kids that you mentioned last time? And what's the, do you have a new project that you're working on?
Personal Projects and Work-Life Balance
Chris [01:14:47]: Massively forgot about that. So we still use Lego robotics table. So this is a big 4x8 sheet of plywood with a bunch of, uh. Uh, two by threes around the edge, but a 4x8 sheet of plywood was pretty hard to work with. And so it breaks apart into three decomposable modular sections. And so it's super great. And the kids are getting way better at programming and Legos and all this kind of stuff. Um, gosh, what's my most recent project. I was just building swords in the shop with kids on a bandsaw. And so you take a piece of wood, you have a bandsaw, give it to a kid and you say, don't cut your fingers off. Turns out that advance. I mean, I'm obviously joking a little bit. They do a lot of. They get a lot of oversight, but a bandsaw is actually a very safe tool. And so the reason for that is that a bandsaw, which if you probably a lot of people have never seen a bandsaw, you can do Google search for, you have two wheels and then you have a blade that goes around the wheels and you've got a table. And the cool thing about a bandsaw is that you can crank down the opening towards the blade. So it's just, just as big as the piece of wood and also pulls the wood into the table. And so because it pulls the wood into the table there, the risk of like something called kickback. And there's a lot of other things like this is very low. And so you can basically tell a kid, look, you see your fingers, keep them away from the blade. And there's no like sudden jerking or other things that if you, you know, use the wrong technique, you can get yourself into real trouble. And if you keep the guard all the way down, then you can't get like an arm in there or something like that.
Alessio [01:16:11]: But, uh, did you make your whole garage woodworking?
Chris [01:16:14]: Yeah, I'm a cars outside kind of guy. So that's again, my thank you to my wife for tolerating my odd behaviors. I mean, I love building things, right? And so this is fundamentally when you talk about, you know, what makes me tick is I love the joy of discovery, right? And so whether it's building an amazing team or building a new table, you know, built like dining room table or things like this. Uh, you can look at my website. I'm not a very good web designer. I have some woodworking projects on there, but I love building software. I love building and solving the problems that come to this. I'm not super great at building things that are rope mechanical. And so maybe I'd be good at building one chair, but I'm not going to build eight chairs, go around dining room table. That would just drive me crazy. The discovery and the learning is what you can build the machine that builds the chairs. There you go. That sounds great. Right? You spend 10 years building and things three weeks crank it out. Yeah.
Alessio [01:17:02]: Uh, yeah. Awesome. Yeah. Any call to actions?
Hiring, Open Source, and Community Engagement
Chris [01:17:05]: Like, are you hiring like, yeah, we're, we're, we're hiring a small number of elite nerds. And so if you care about GPU programming, you care about AI models, you care about inference, you care about Kubernetes and cloud scale stuff. Please check us out. We expect to grow a lot more later this year. The, uh, uh, other things that we have a ton of open source code. And so if you've heard about Mojo, but you looked at it a year ago, guess what? Everything's completely different now. And so if you are interested in a lot of these things, if you're interested in learning about GPUs, we have a ton of content that will teach you about GPU programming, GPU puzzles and things like this. People are now picking up Mojo and putting in a lot of like elite GPU, uh, came out today and there's a whole bunch of other people that are taking the stuff and putting it out there. And I think it's just such an exciting time because I think that lots more people should be using it. I think it's just such an exciting time because I think that lots more people should be using it. I think it's just such an exciting time because I think that lots more people should be programming GPUs. I think this is a huge opportunity for the industry. And of course, if you're enterprise and you're having trouble scaling your AI, you know, let us know. We can, we can help. Awesome. Thank you so much for coming on here. Inspiration as always. Yeah. Well, thank you for having me.
Great episode. Cool to see a super experienced engineer try and do something new in the AI space