We are running an end of year listener survey! Please let us know any feedback you have, what episodes resonated with you, and guest requests for 2024! Survey link here.
NeurIPS 2023 took place from Dec 10–16 in New Orleans. The Latent Space crew was onsite for as many of the talks and workshops as we could attend (and more importantly, hosted cocktails and parties after hours)!

Picking from the 3586 papers accepted to the conference (available online, full schedule here) is an impossible task, but we did our best to present an audio guide with brief commentary on each. We also recommend MLContests.com NeurIPS recap and Seb Ruder’s NeurIPS primer and Jerry Liu’s paper picks. We also found the VizHub guide useful for a t-SNE clustering of papers. Lots also happened in the arxiv publishing world outside NeurIPS, as highlighted by Karpathy, especially DeepMind’s Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models.
Jan 2024 update: we also strongly recommend Sebastian Raschka, PhD ‘s pick of the year’s 10 best papers, including Pythia.
We’ll start with the NeurIPS Best Paper Awards, and then go to a selection of non-awarded but highly influential papers, and then arbitrary personal picks to round out the selection. Where we were able to do a poster session interview, please scroll to the relevant show notes for images of their poster for discussion. We give Chris Ré the last word due to the Mamba and StripedHyena state space models drawing particular excitement but still being too early to assess impact.
Timestamps
[0:01:19] Word2Vec (Jeff Dean, Greg Corrado)
[0:15:28] Emergence Mirage (Rylan Schaeffer)
[0:28:48] DPO (Rafael Rafailov)
[0:41:36] DPO Poster Session (Archit Sharma)
[0:52:03] Datablations (Niklas Muennighoff)
[1:00:50] QLoRA (Tim Dettmers)
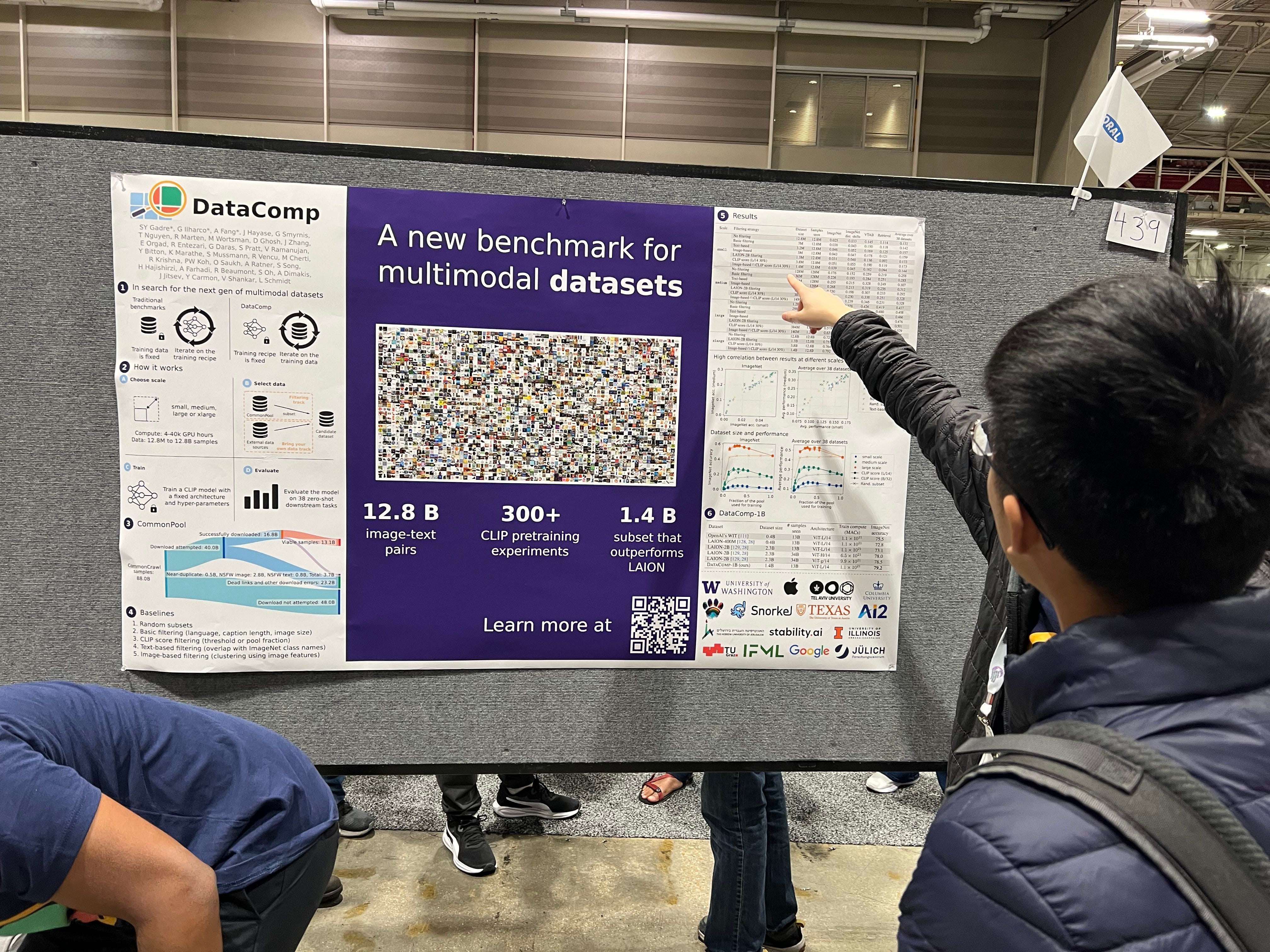
[1:12:23] DataComp (Samir Gadre)
[1:25:38] DataComp Poster Session (Samir Gadre, Alex Dimakis)
[1:35:25] LLaVA (Haotian Liu)
[1:47:21] LLaVA Poster Session (Haotian Liu)
[1:59:19] Tree of Thought (Shunyu Yao)
[2:11:27] Tree of Thought Poster Session (Shunyu Yao)
[2:20:09] Toolformer (Jane Dwivedi-Yu)
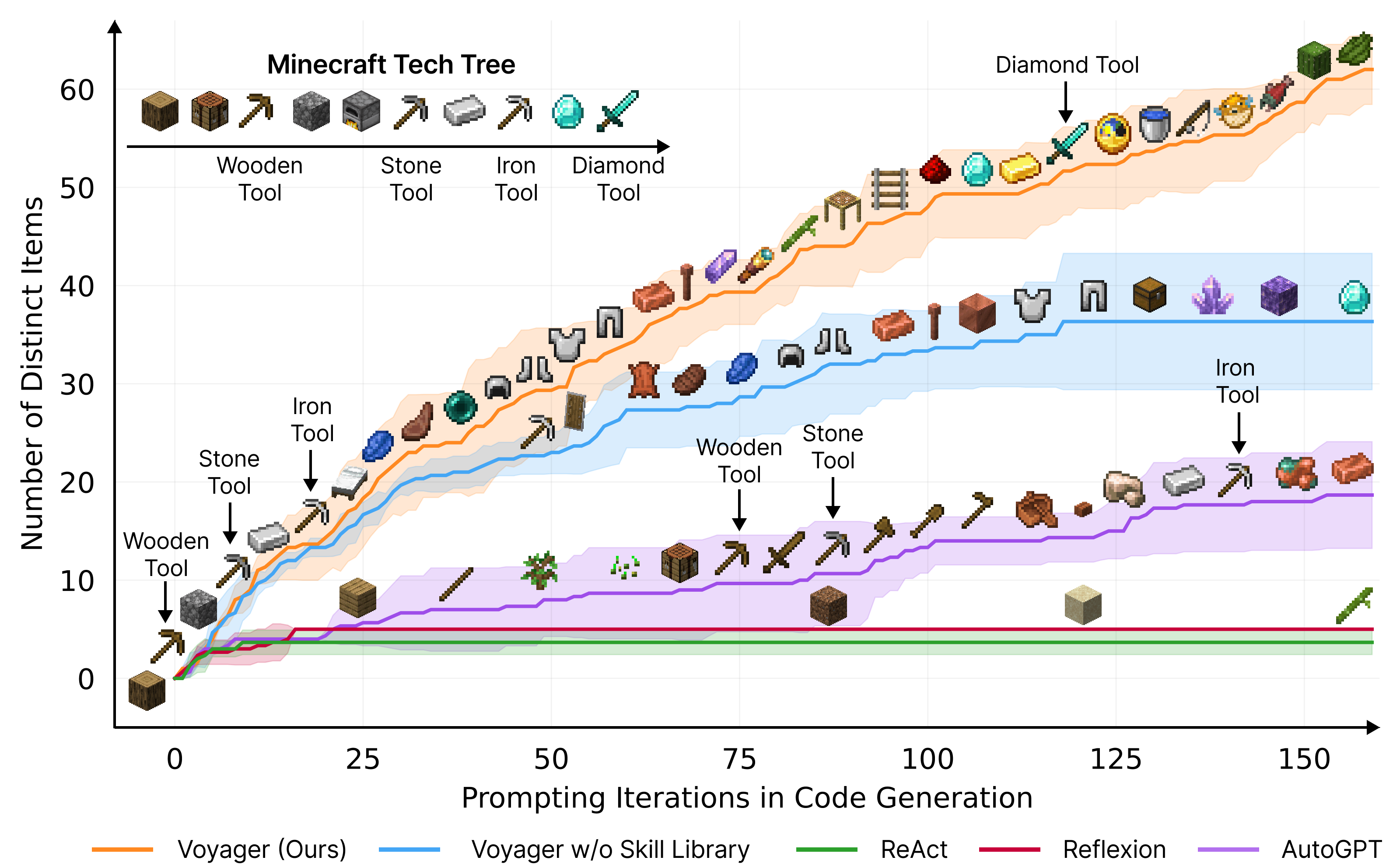
[2:32:26] Voyager (Guanzhi Wang)
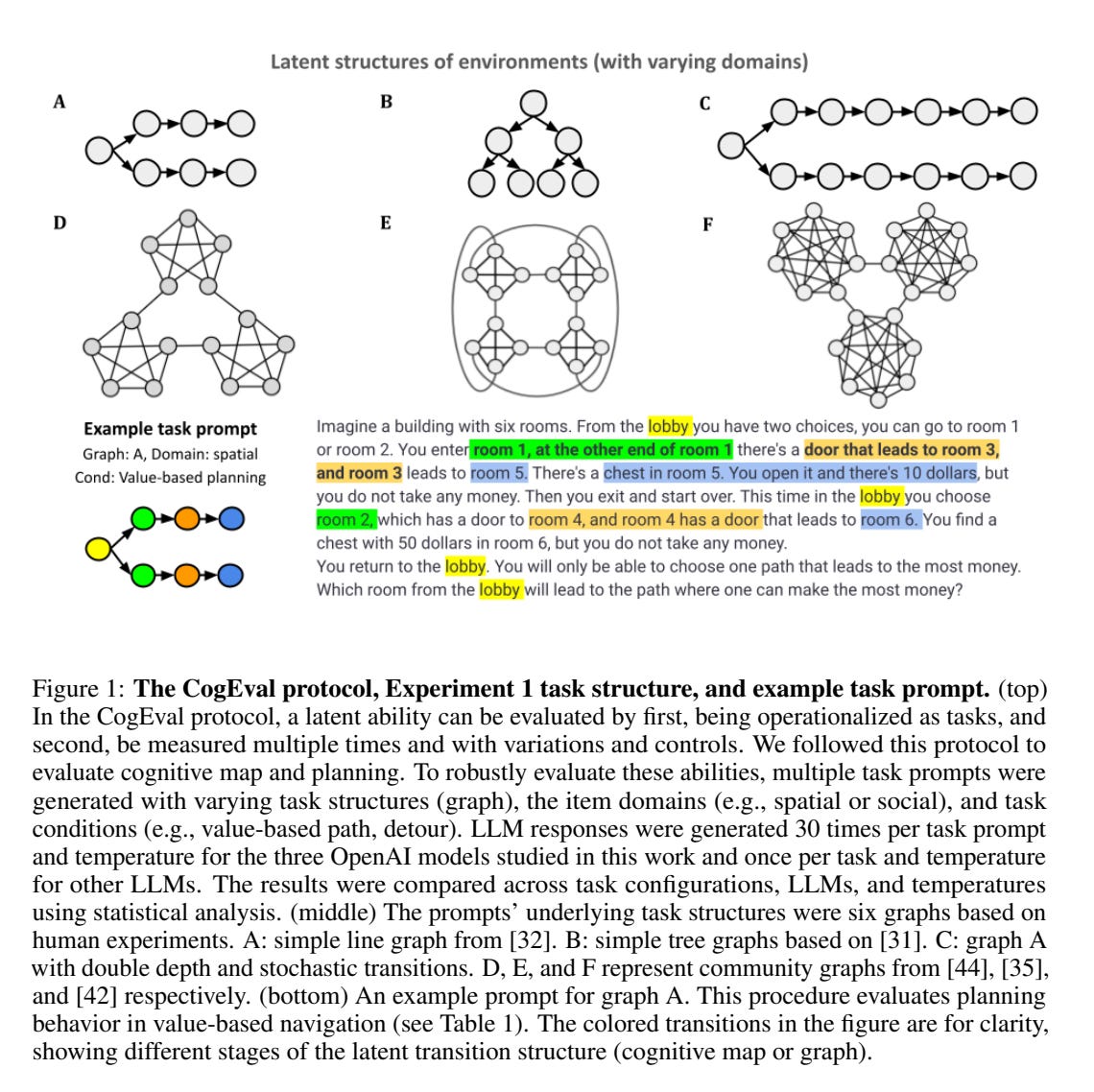
[2:45:14] CogEval (Ida Momennejad)
[2:59:41] State Space Models (Chris Ré)
Papers covered
Distributed Representations of Words and Phrases and their Compositionality (Word2Vec) Tomas Mikolov · Ilya Sutskever · Kai Chen · Greg Corrado · Jeff Dean. The recently introduced continuous Skip-gram model is an efficient method for learning high-quality distributed vector representations that capture a large number of precise syntactic and semantic word relationships. In this paper we present several improvements that make the Skip-gram model more expressive and enable it to learn higher quality vectors more rapidly. We show that by subsampling frequent words we obtain significant speedup, and also learn higher quality representations as measured by our tasks. We also introduce Negative Sampling, a simplified variant of Noise Contrastive Estimation (NCE) that learns more accurate vectors for frequent words compared to the hierarchical softmax. An inherent limitation of word representations is their indifference to word order and their inability to represent idiomatic phrases. For example, the meanings of Canada'' and "Air'' cannot be easily combined to obtain "Air Canada''. Motivated by this example, we present a simple and efficient method for finding phrases, and show that their vector representations can be accurately learned by the Skip-gram model.
Some notable reflections from Tomas Mikolov - and debate over the Seq2Seq paper credit with Quoc Le
Are Emergent Abilities of Large Language Models a Mirage? (Schaeffer et al.). Emergent abilities are abilities that are present in large-scale models but not in smaller models and are hard to predict. Rather than being a product of models’ scaling behavior, this paper argues that emergent abilities are mainly an artifact of the choice of metric used to evaluate them. Specifically, nonlinear and discontinuous metrics can lead to sharp and unpredictable changes in model performance. Indeed, the authors find that when accuracy is changed to a continuous metric for arithmetic tasks where emergent behavior was previously observed, performance improves smoothly instead. So while emergent abilities may still exist, they should be properly controlled and researchers should consider how the chosen metric interacts with the model.
Direct Preference Optimization: Your Language Model is Secretly a Reward Model (Rafailov et al.)
While large-scale unsupervised language models (LMs) learn broad world knowledge and some reasoning skills, achieving precise control of their behavior is difficult due to the completely unsupervised nature of their training. Existing methods for gaining such steerability collect human labels of the relative quality of model generations and fine-tune the unsupervised LM to align with these preferences, often with reinforcement learning from human feedback (RLHF). However, RLHF is a complex and often unstable procedure, first fitting a reward model that reflects the human preferences, and then fine-tuning the large unsupervised LM using reinforcement learning to maximize this estimated reward without drifting too far from the original model.
In this paper, we leverage a mapping between reward functions and optimal policies to show that this constrained reward maximization problem can be optimized exactly with a single stage of policy training, essentially solving a classification problem on the human preference data. The resulting algorithm, which we call Direct Preference Optimization (DPO), is stable, performant, and computationally lightweight, eliminating the need for fitting a reward model, sampling from the LM during fine-tuning, or performing significant hyperparameter tuning.
Our experiments show that DPO can fine-tune LMs to align with human preferences as well as or better than existing methods. Notably, fine-tuning with DPO exceeds RLHF's ability to control sentiment of generations and improves response quality in summarization and single-turn dialogue while being substantially simpler to implement and train.

See also Interconnects on DPO: and recent Twitter discussions
Scaling Data-Constrained Language Models (Muennighoff et al.)
The current trend of scaling language models involves increasing both parameter count and training dataset size. Extrapolating this trend suggests that training dataset size may soon be limited by the amount of text data available on the internet. Motivated by this limit, we investigate scaling language models in data-constrained regimes. Specifically, we run a large set of experiments varying the extent of data repetition and compute budget, ranging up to 900 billion training tokens and 9 billion parameter models. We find that with constrained data for a fixed compute budget, training with up to 4 epochs of repeated data yields negligible changes to loss compared to having unique data. However, with more repetition, the value of adding compute eventually decays to zero. We propose and empirically validate a scaling law for compute optimality that accounts for the decreasing value of repeated tokens and excess parameters. Finally, we experiment with approaches mitigating data scarcity, including augmenting the training dataset with code data or removing commonly used filters. Models and datasets from our 400 training runs are freely available at https://github.com/huggingface/datablations.

2 minute poster session presentation video
QLoRA: Efficient Finetuning of Quantized LLMs (Dettmers et al.).
This paper proposes QLoRA, a more memory-efficient (but slower) version of LoRA that uses several optimization tricks to save memory. They train a new model, Guanaco, that is fine-tuned only on a single GPU for 24h and outperforms previous models on the Vicuna benchmark. Overall, QLoRA enables using much fewer GPU memory for fine-tuning LLMs. Concurrently, other methods such as 4-bit LoRA quantization have been developed that achieve similar results.

DataComp: In search of the next generation of multimodal datasets (Gadre et al.)
Multimodal datasets are a critical component in recent breakthroughs such as CLIP, Stable Diffusion and GPT-4, yet their design does not receive the same research attention as model architectures or training algorithms. To address this shortcoming in the machine learning ecosystem, we introduce DataComp, a testbed for dataset experiments centered around a new candidate pool of 12.8 billion image-text pairs from Common Crawl. Participants in our benchmark design new filtering techniques or curate new data sources and then evaluate their new dataset by running our standardized CLIP training code and testing the resulting model on 38 downstream test sets.
Our benchmark consists of multiple compute scales spanning four orders of magnitude, which enables the study of scaling trends and makes the benchmark accessible to researchers with varying resources. Our baseline experiments show that the DataComp workflow leads to better training sets. Our best baseline, DataComp-1B, enables training a CLIP ViT-L/14 from scratch to 79.2% zero-shot accuracy on ImageNet, outperforming OpenAI's CLIP ViT-L/14 by 3.7 percentage points while using the same training procedure and compute. We release \datanet and all accompanying code at www.datacomp.ai.

Visual Instruction Tuning (Liu et al)
Instruction tuning large language models (LLMs) using machine-generated instruction-following data has improved zero-shot capabilities on new tasks, but the idea is less explored in the multimodal field. In this paper, we present the first attempt to use language-only GPT-4 to generate multimodal language-image instruction-following data.
By instruction tuning on such generated data, we introduce LLaVA: Large Language and Vision Assistant, an end-to-end trained large multimodal model that connects a vision encoder and LLM for general-purpose visual and language understanding.
Our early experiments show that LLaVA demonstrates impressive multimodel chat abilities, sometimes exhibiting the behaviors of multimodal GPT-4 on unseen images/instructions, and yields a 85.1% relative score compared with GPT-4 on a synthetic multimodal instruction-following dataset. When fine-tuned on Science QA, the synergy of LLaVA and GPT-4 achieves a new state-of-the-art accuracy of 92.53%. We make GPT-4 generated visual instruction tuning data, our model and code base publicly available.

Tree of Thoughts: Deliberate Problem Solving with Large Language Models (Yao et al)
Language models are increasingly being deployed for general problem solving across a wide range of tasks, but are still confined to token-level, left-to-right decision-making processes during inference. This means they can fall short in tasks that require exploration, strategic lookahead, or where initial decisions play a pivotal role.
To surmount these challenges, we introduce a new framework for language model inference, Tree of Thoughts (ToT), which generalizes over the popular Chain of Thought approach to prompting language models, and enables exploration over coherent units of text (thoughts) that serve as intermediate steps toward problem solving.
ToT allows LMs to perform deliberate decision making by considering multiple different reasoning paths and self-evaluating choices to decide the next course of action, as well as looking ahead or backtracking when necessary to make global choices.
Our experiments show that ToT significantly enhances language models’ problem-solving abilities on three novel tasks requiring non-trivial planning or search: Game of 24, Creative Writing, and Mini Crosswords. For instance, in Game of 24, while GPT-4 with chain-of-thought prompting only solved 4\% of tasks, our method achieved a success rate of 74\%.
Code repo with all prompts: https://github.com/princeton-nlp/tree-of-thought-llm.

Toolformer: Language Models Can Teach Themselves to Use Tools (Schick et al)
LMs exhibit remarkable abilities to solve new tasks from just a few examples or textual instructions, especially at scale. They also, paradoxically, struggle with basic functionality, such as arithmetic or factual lookup, where much simpler and smaller specialized models excel.
In this paper, we show that LMs can teach themselves to use external tools via simple APIs and achieve the best of both worlds.
We introduce Toolformer, a model trained to decide which APIs to call, when to call them, what arguments to pass, and how to best incorporate the results into future token prediction.
This is done in a self-supervised way, requiring nothing more than a handful of demonstrations for each API. We incorporate a range of tools, including a calculator, a Q&A system, a search engine, a translation system, and a calendar.
Toolformer achieves substantially improved zero-shot performance across a variety of downstream tasks, often competitive with much larger models, without sacrificing its core language modeling abilities.
Voyager: An Open-Ended Embodied Agent with Large Language Models (Wang et al)
We introduce Voyager, the first LLM-powered embodied lifelong learning agent in Minecraft that continuously explores the world, acquires diverse skills, and makes novel discoveries without human intervention. Voyager consists of three key components:
1) an automatic curriculum that maximizes exploration,
2) an ever-growing skill library of executable code for storing and retrieving complex behaviors, and
3) a new iterative prompting mechanism that incorporates environment feedback, execution errors, and self-verification for program improvement.
Voyager interacts with GPT-4 via blackbox queries, which bypasses the need for model parameter fine-tuning. The skills developed by Voyager are temporally extended, interpretable, and compositional, which compounds the agent's abilities rapidly and alleviates catastrophic forgetting. Empirically, Voyager shows strong in-context lifelong learning capability and exhibits exceptional proficiency in playing Minecraft. It obtains 3.3x more unique items, travels 2.3x longer distances, and unlocks key tech tree milestones up to 15.3x faster than prior SOTA. Voyager is able to utilize the learned skill library in a new Minecraft world to solve novel tasks from scratch, while other techniques struggle to generalize.

Voyager discovers new Minecraft items and skills continually by self-driven exploration, significantly outperforming the baselines.
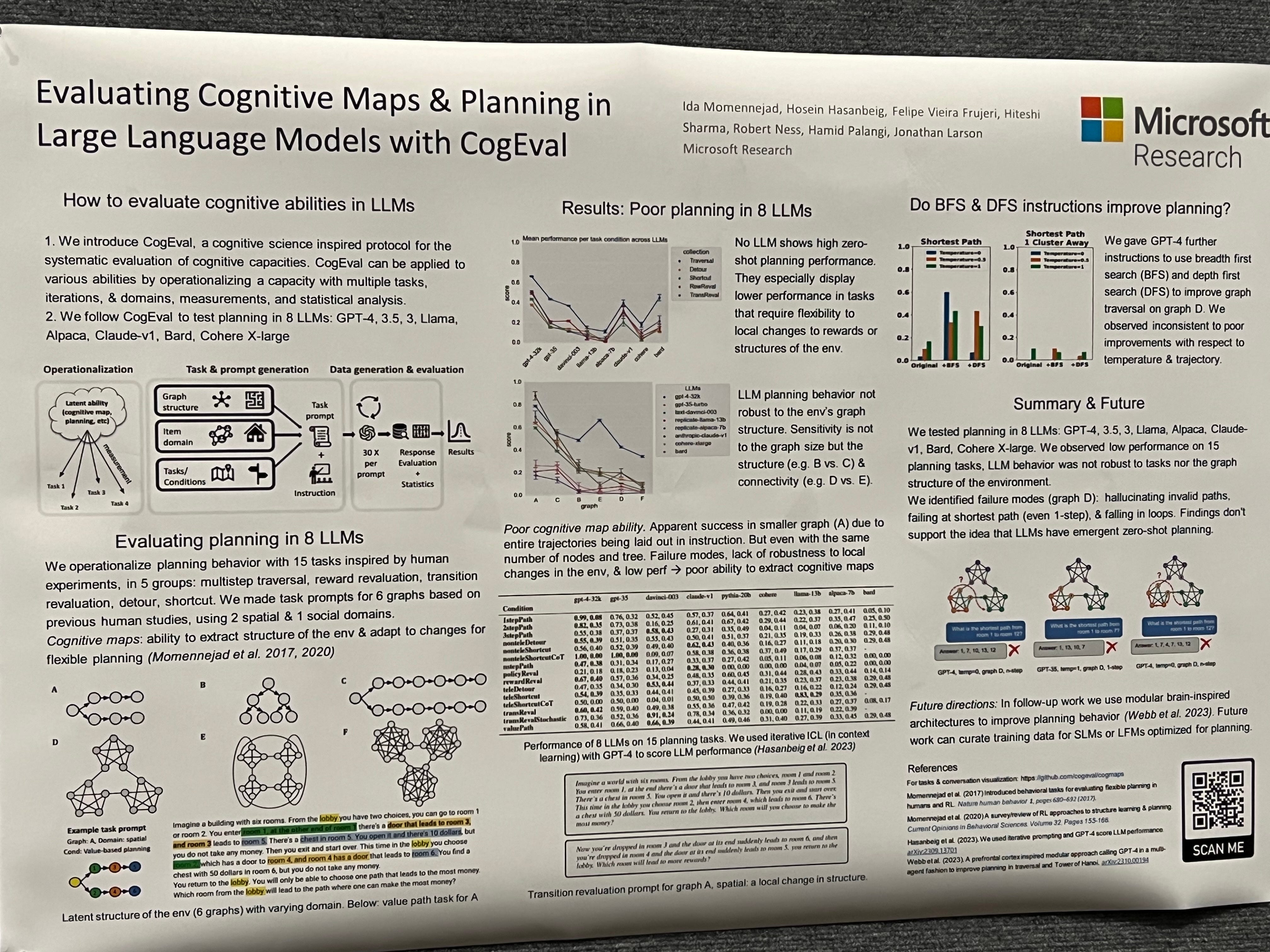
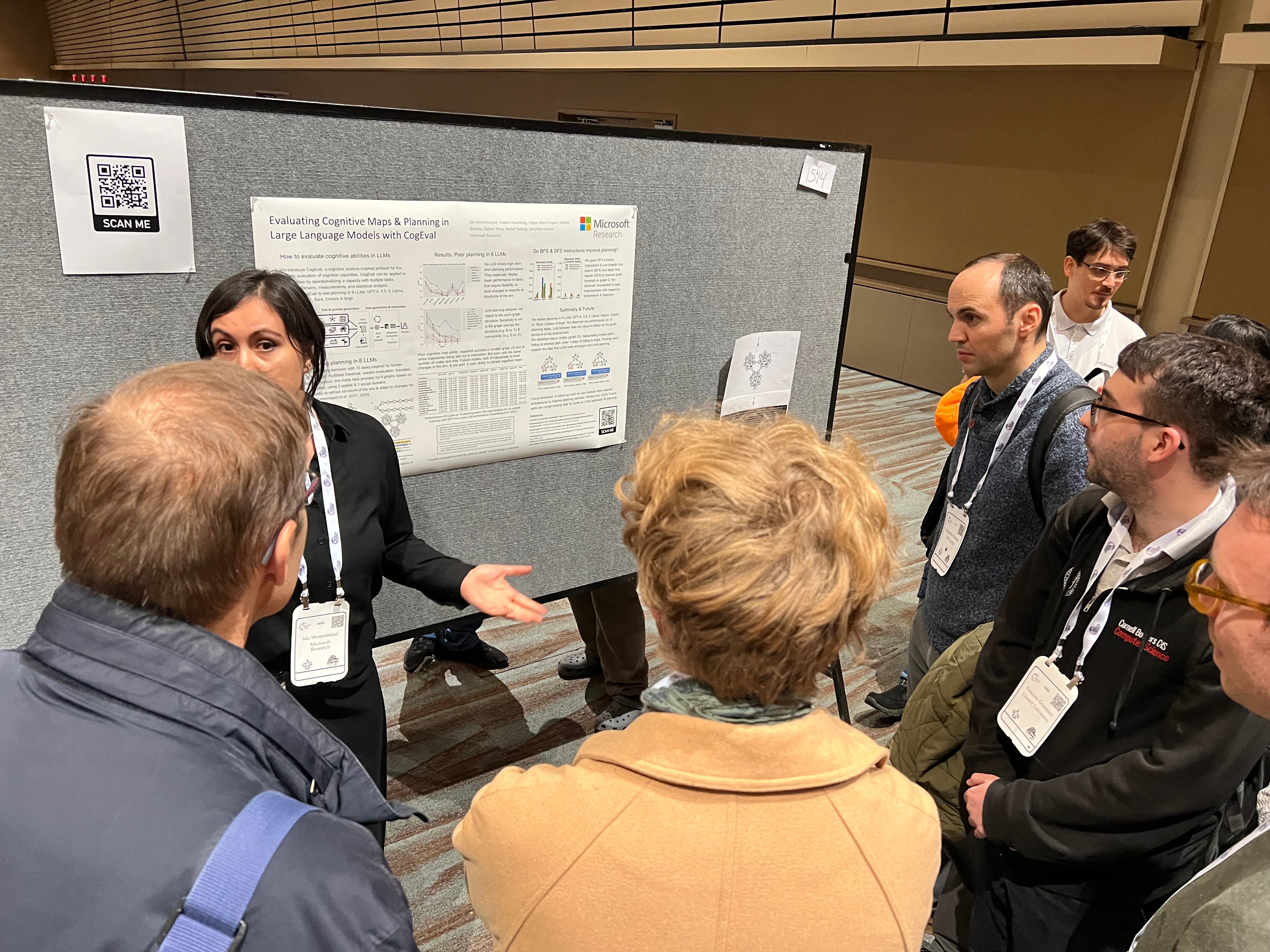
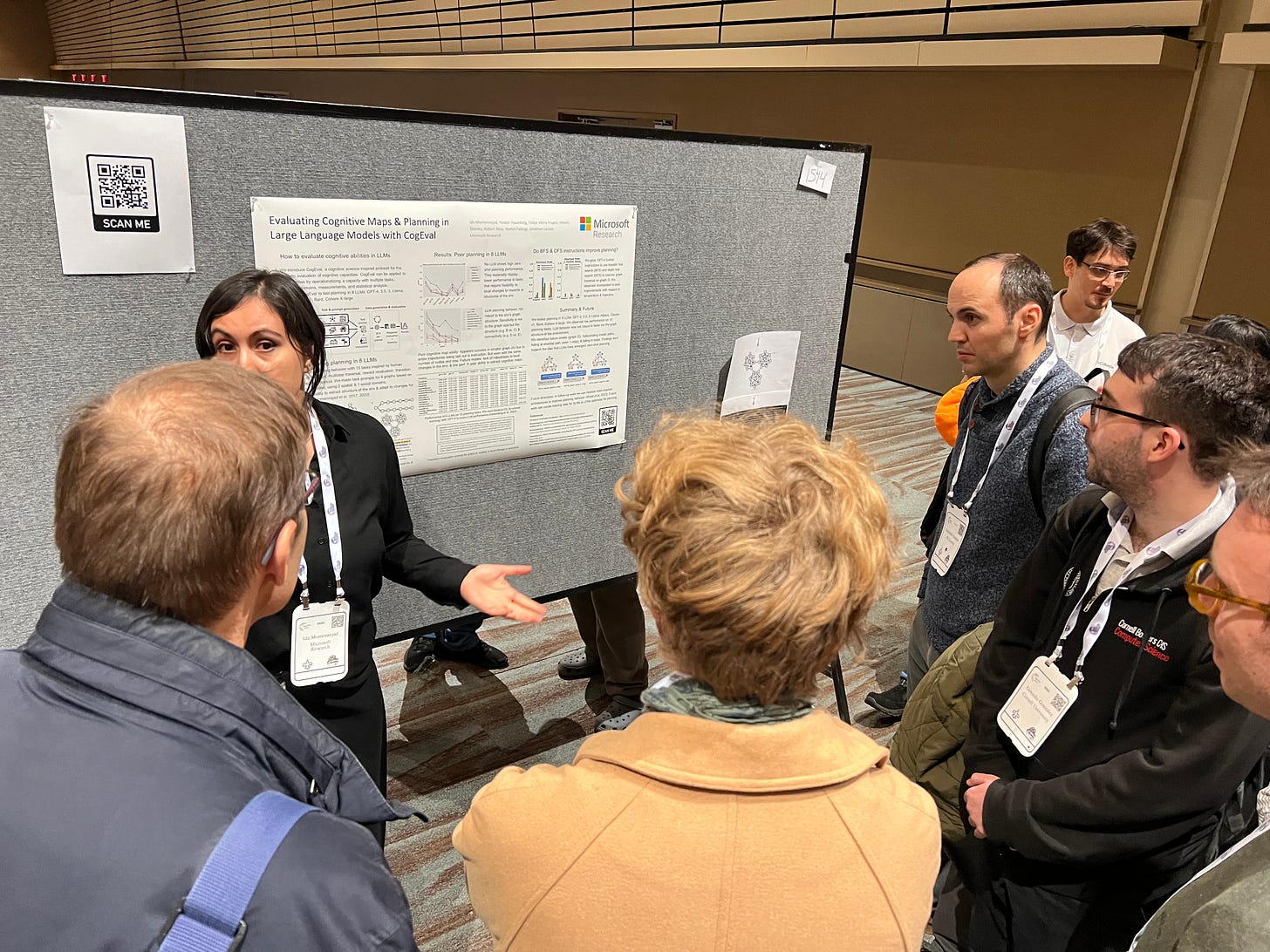
Evaluating Cognitive Maps and Planning in Large Language Models with CogEval (Momennejad et al)
Recently an influx of studies claims emergent cognitive abilities in large language models (LLMs). Yet, most rely on anecdotes, overlook contamination of training sets, or lack systematic Evaluation involving multiple tasks, control conditions, multiple iterations, and statistical robustness tests. Here we make two major contributions.
First, we propose CogEval, a cognitive science-inspired protocol for the systematic evaluation of cognitive capacities in LLMs. The CogEval protocol can be followed for the evaluation of various abilities.

Second, here we follow CogEval to systematically evaluate cognitive maps and planning ability across eight LLMs (OpenAI GPT-4, GPT-3.5-turbo-175B, davinci-003-175B, Google Bard, Cohere-xlarge-52.4B, Anthropic Claude-1-52B, LLaMA-13B, and Alpaca-7B). We base our task prompts on human experiments, which offer both established construct validity for evaluating planning, and are absent from LLM training sets.

We find that, while LLMs show apparent competence in a few planning tasks with simpler structures, systematic evaluation reveals striking failure modes in planning tasks, including hallucinations of invalid trajectories and falling in loops. These findings do not support the idea of emergent out-of-the-box planning ability in LLMs. This could be because LLMs do not understand the latent relational structures underlying planning problems, known as cognitive maps, and fail at unrolling goal-directed trajectories based on the underlying structure. Implications for application and future directions are discussed.

Mamba: Linear-Time Sequence Modeling with Selective State Spaces (Albert Gu, Tri Dao)
Foundation models, now powering most of the exciting applications in deep learning, are almost universally based on the Transformer architecture and its core attention module. Many subquadratic-time architectures such as linear attention, gated convolution and recurrent models, and structured state space models (SSMs) have been developed to address Transformers' computational inefficiency on long sequences, but they have not performed as well as attention on important modalities such as language. We identify that a key weakness of such models is their inability to perform content-based reasoning, and make several improvements.
First, simply letting the SSM parameters be functions of the input addresses their weakness with discrete modalities, allowing the model to selectively propagate or forget information along the sequence length dimension depending on the current token.
Second, even though this change prevents the use of efficient convolutions, we design a hardware-aware parallel algorithm in recurrent mode. We integrate these selective SSMs into a simplified end-to-end neural network architecture without attention or even MLP blocks (Mamba).
Mamba enjoys fast inference (5x higher throughput than Transformers) and linear scaling in sequence length, and its performance improves on real data up to million-length sequences. As a general sequence model backbone, Mamba achieves state-of-the-art performance across several modalities such as language, audio, and genomics. On language modeling, our Mamba-1.4B model outperforms Transformers of the same size and matches Transformers twice its size, both in pretraining and downstream evaluation.