

How to Kill the Code Review
Human-written code died in 2025. Code reviews will die in 2026.

Second wave speakers for AIE Europe and CFP for AIE World’s Fair are announced today, and OpenCode is confirmed for Miami! We’ll also be in Melbourne & Singapore.
Editor: This is the latest in our guest post program, where we will publish AI Engineering essays worth considering, even if we don’t personally agree with them — having just shipped an AI review tool, this is one of those cases where I am not there yet, but is clearly on the horizon, and am happy for Ankit to argue the case!
Humans already couldn’t keep up with code review when humans wrote code at human speed. Every engineering org I’ve talked to has the same dirty secret: PRs sitting for days, rubber-stamp approvals, and reviewers skimming 500-line diffs because they have their own work to do.
We tell ourselves it is a quality gate, but teams have shipped without line-by-line review for decades. Code review wasn’t even ubiquitous until around 2012-2014, one veteran engineer told me, there just aren’t enough of us around to remember.
And even with reviews, things break. We have learned to build systems that handle failure because we accepted that review alone wasn’t enough. This shows in terms of feature flags, rollouts, and instant rollbacks.
We have to give up on reading all the code
Teams with high AI adoption complete 21% more tasks and merge 98% more pull requests, but PR review time increases 91%, based on data from over 10,000 developers across 1,255 teams.
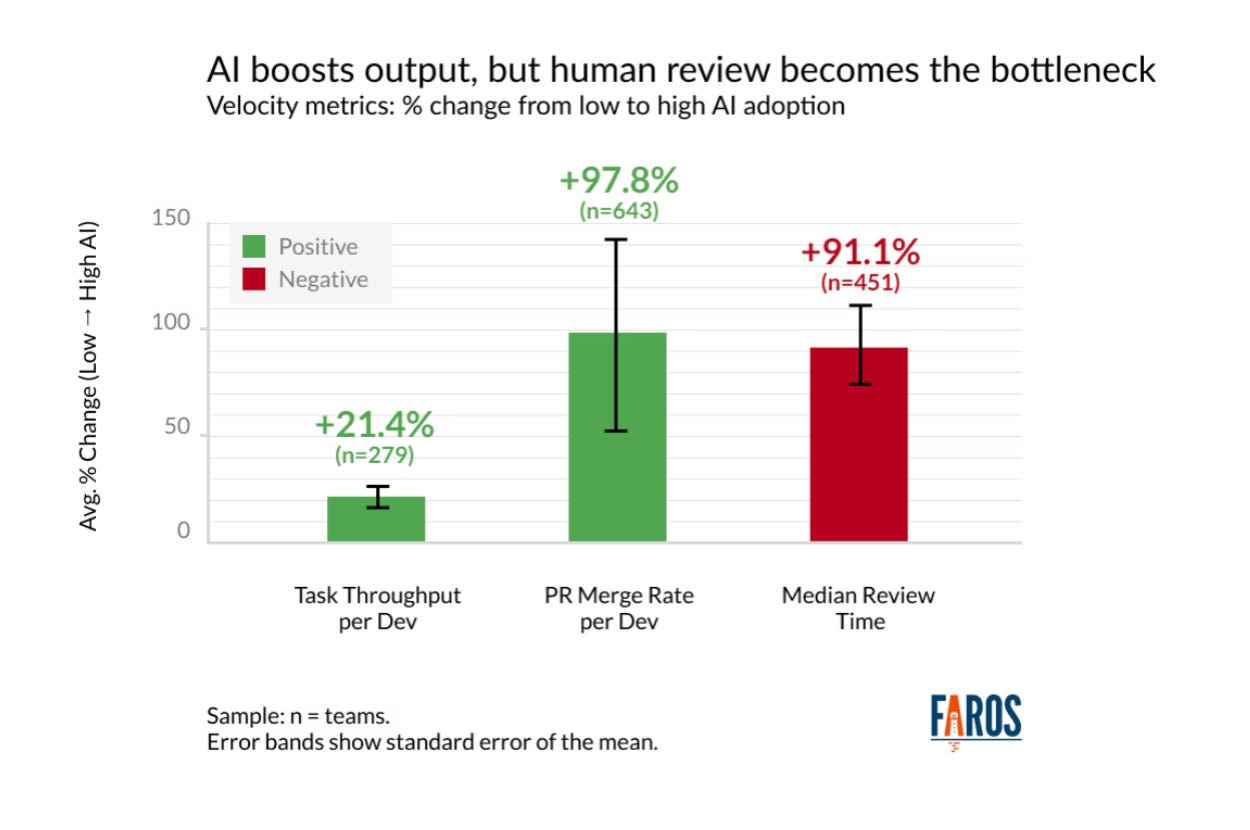
Two things are scaling exponentially: the number of changes and the size of changes. We cannot consume this much code. Period. On top of that, developers keep saying that reviewing AI-generated code requires more effort than reviewing code written by their colleagues. Teams produce more code, then spend more time reviewing it.
There is no way we win this fight with manual code reviews. Code review is a historical approval gate that no longer matches the shape of the work.
AI code review is still review
AI code review tools are just buying us time. If AI writes the code and AI reviews it, why do we need a pretty review UI to display that? As much as AI code reviews can be valuable, these will shift left in the dev cycle. There’s no reason to waste CI resources and manage versioning in between the review cycles.
Post-PR review made sense when humans wrote code and needed fresh eyes. When agents write code, “fresh eyes” is just another agent with the same blind spots. The value is in the iteration loop here, not as an approval gate.
We know from experience agents are not always reliable, and it’s very human to think, I caught the AI doing something dumb once; therefore, I must always check it. That instinct made sense when manual verification was feasible. At the current scale, it’s not anymore. And it’s just going to get worse.
From reviewing Code to reviewing Intent
The answer is to move the human checkpoint upstream. If the thought of not reviewing code seems scary, let me remind you that checkpoints have moved before in software development. We moved from waterfall sign-offs to continuous integration. We can move them again.
Spec-driven development is becoming the main way of working with AI. Humans should review specs, plans, constraints, and acceptance criteria—not 500-line diffs.
In this new paradigm, Specs become the source of truth. Code becomes an artifact of the spec. You don’t need to review the code. You review the steps. You review the verification rules. You review the contract the code must fulfill.
Human-in-the-loop approval moves from “Did you write this correctly?” to “Are we solving the right problem with the right constraints?” The most valuable human judgment is exercised before the first line of code is generated, not after.
Building trust through layers
How comfortable do we need to get before we stop reading the code?
In rule form:
Code must not be written by humans
Code must not be reviewed by humans
LLMs are not great at following commands. They deviate. Frequently. And they’re unreliable at self-verification—they’ll confidently tell you the code works while it’s on fire. The fix isn’t to ask the LLM to verify. It’s to ask it to write a script that verifies. Shift from judgment to artifact.
Trust is layered. This is the Swiss-cheese model: no single gate catches everything. You stack imperfect filters until the holes don’t align. So, where else can we put approval gates?
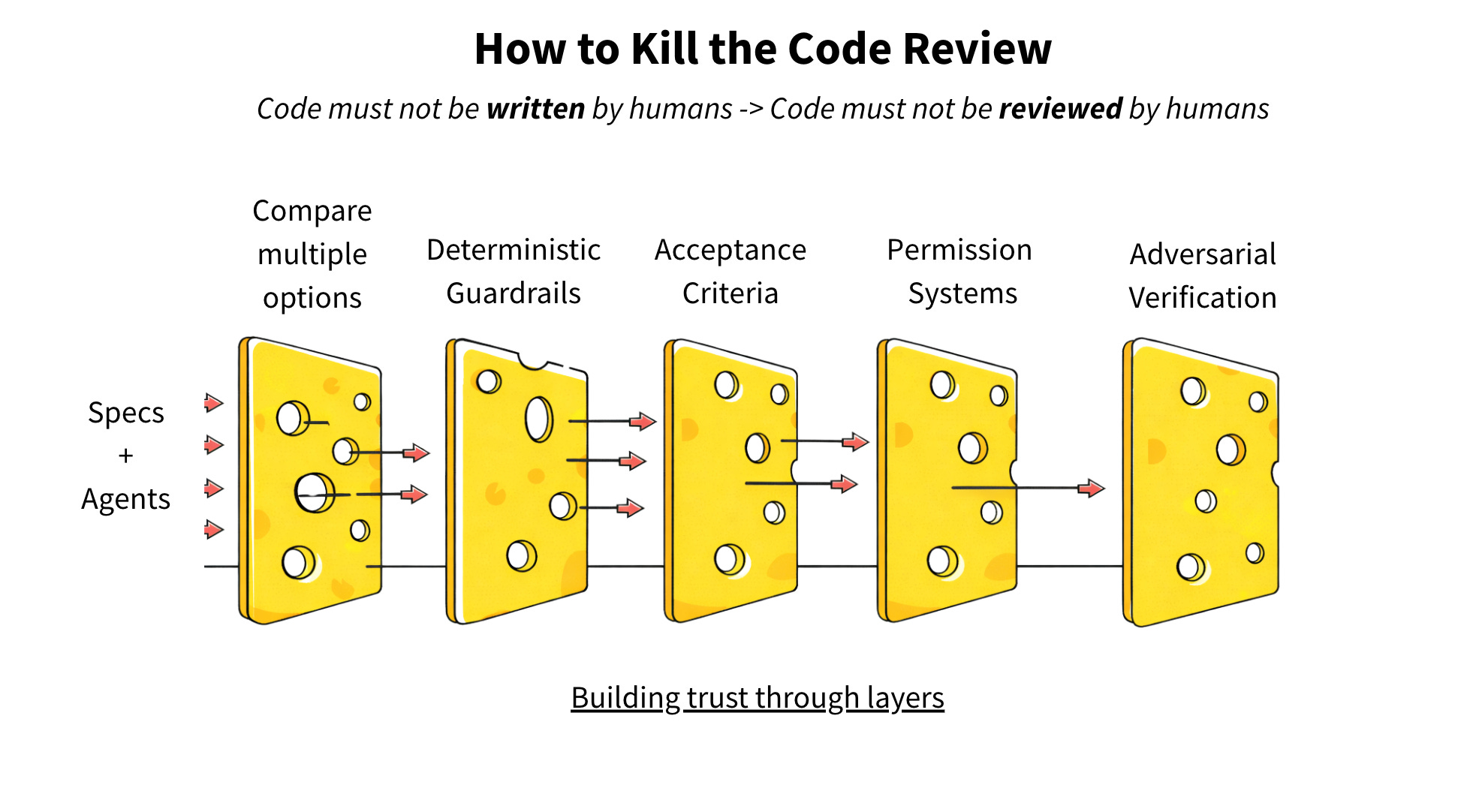
Layer 1: Compare Multiple Options
Instead of asking one agent to get it right, ask three agents to try differently and pick the best outcome. Let them compete. The cost of optionality is the lowest in the history of software engineering.
The selection doesn’t have to be manual either. You can rank outputs by which one passes the most verification steps, which one produces the smallest diff, which one doesn’t introduce new dependencies. Competition creates a signal you wouldn’t get from a single attempt.
Layer 2: Deterministic Guardrails
There should be a deterministic way to verify the work. Tests, type checks, contract verification - things that don’t have opinions, just facts.
Instead of asking an LLM “Did this work?” you define verification steps that produce a series of pass/fail artifacts. The agent can’t negotiate with a failing test. It either meets the specification or it doesn’t.
These guardrails can be defined as layers themselves:
Coding guidelines - these can be custom linters
Organization-wide invariants - the non-negotiables, e.g. No hardcoded credentials, API keys, or tokens
Domain Contracts - specific to a framework, a service, or a part of the code base, e.g. Payments domain: All amounts use the Money type
Acceptance Criteria - specific to the task
Verification steps should be defined before the code is written, not invented after to confirm what’s already there. If the agent writes both the code and the tests, you’ve just moved the problem—now you’re trusting the agent to test the right things. Verification criteria need to come from the spec, not from the implementation.
Layer 3: Humans define acceptance criteria
So where do humans add value? Upstream, defining what success looks like.
This is where Behavior-Driven Development becomes newly relevant. BDD was always a good idea—write specifications in natural language that describe expected behavior, then automate those specs as tests. But it never fully caught on because writing specs felt like extra work when you were also going to write the code.
With agents, the equation flips. The spec isn’t extra work; it’s the primary artifact. You write:
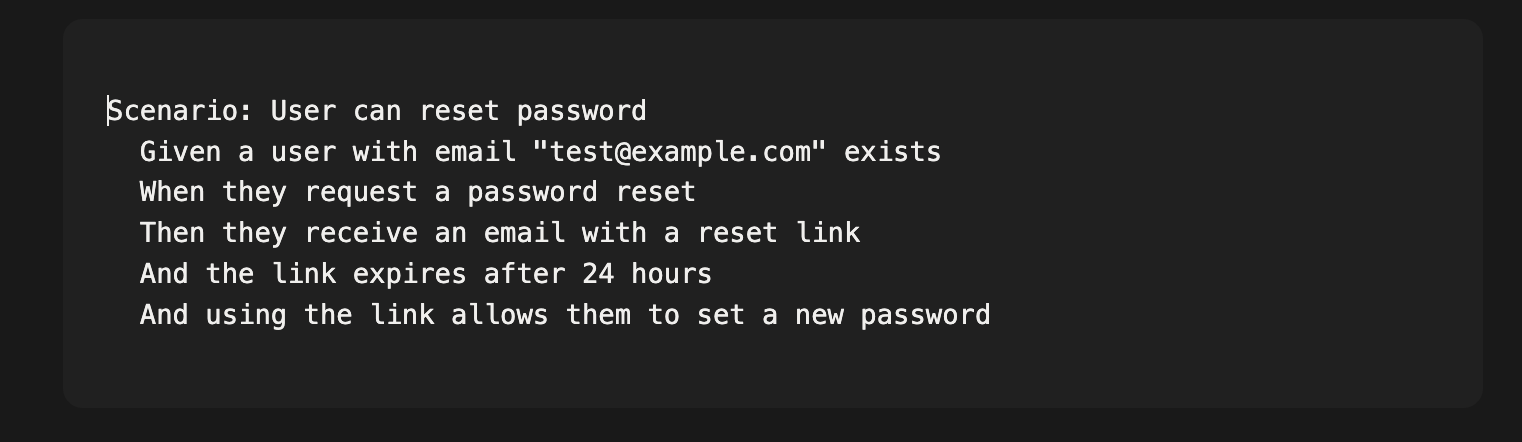
The agent implements. The BDD framework verifies. You never have to read the implementation unless something fails.
This is humans doing what humans are good at: defining what “correct” means, encoding business logic and edge cases, thinking about what could go wrong. The agent handles the translation from intent to code. The BDD specs become your verification layer—deterministic, automated, and defined before the first line is written.
Acceptance criteria authored by humans, verified by machines. That’s the gate that actually matters.
Layer 4: Permission Systems as Architecture
What can this agent touch? What requires escalation? These become architectural decisions, not afterthoughts.
Most agent frameworks treat permissions as an all-or-nothing setting. The agent either has shell access or it doesn’t. But granularity matters. An agent fixing a bug in a utility function doesn’t need access to your infrastructure configs. An agent writing tests doesn’t need to modify CI pipelines.
Scope should be as narrow as possible while still letting the agent do useful work. If the task is “fix the date parsing bug in utils/dates.py,” the agent’s filesystem access should be limited to that file and its test file. Not the whole codebase. Not “src/ and tests/”. Just the files that matter for this task.
Escalation triggers are equally important. Certain patterns—touching auth logic, modifying database schemas, adding new dependencies—should automatically flag for human review regardless of how confident the agent is.
Layer 5: Adversarial Verification
Separation of responsibilities: One agent does the work, another verifies. They don’t trust each other, and that’s the point.
This is an old pattern—it’s why your QA team shouldn’t report to your engineering manager, and why the person who writes the code shouldn’t be the only one who reviews it.
With agents, you can enforce this architecturally. The coding agent has no knowledge of what the verification agent will check. The verification agent has no ability to modify the code to make its own job easier. They’re adversarial by design.
You can take this further: a third agent attempts to break what the first agent built, specifically targeting edge cases and failure modes. Red team, blue team—but automated and running on every change.
Conclusions: What “good code” looks like is changing
The incentive of an agentic system is simple: given a task, can I complete it? Can I please the person who gave it to me? The agent’s success is never inherently driven by long-term accuracy or business requirements.
It’s our job to encode in the constraints.
For code generated by agents and read by agents, what “good code” looks like will become more standardized. For a new codebase, you’ll have to provide less direction because the defaults will be more consistent.
The future is ship fast, observe everything, revert faster.
Not: review slowly, miss bugs anyway, debug in production.
We’re not going to outread the machines. We need to outthink them—upstream, where the decisions actually matter.
Ultimately, if agents can handle the code just fine, what does it matter if we can read it or not?
Ankit Jain is the founder and CEO of Aviator, where he’s building the infrastructure for AI-native engineering teams. Aviator’s platform helps modern organizations improve AI adoption while maintaining high engineering standards.
 | A guest post by
|
I don't agree. I think people who believe in spec driven development are naive about how hard it is to write a full spec, compared to just writing code. There's a reason we use symbols with elaborate underlying meanings in mathematics: writing the equivalent in words is tedious.
Look at the progression of level of *abstraction*: assembly -> C -> C++ -> python -> specs-for-LLMs. No that doesn't work. There's a step missing there. It's something between a high level language like python that is still precise and deterministic, and a spec which is a combination of words that have various meanings and cultural biases and ambiguities.
Spec driven dev is an interim phase between pre AI languages, and genAI ability to generate code in said languages.
In 5 years there will be a new language that will be the real bridge and spec driven dev will be seen as a nice but rather feeble attempt at taking advantage of this new reality.
It’s funny to see how this dynamic plays out, over time:
1. Agents almost never get it right.
2. Agents getting it right sometimes.
3. Agents getting it right often.
4. Agents getting it right most of the time.
5. Agents getting it right enough to teach other agents.
… which actually feels like how you onboard and upskill a new engineer.
Funny how that works.