

Why "Prompt Engineering" and "Generative AI" are overhyped
How Stable Diffusion 2.0 and Meta's Galactica demonstrate the two heresies of AI

"Prompt Engineering" and "Generative AI" are all the rage.
So... why do the founders of OpenAI, Stability AI, and others hate those terms?
We’ll develop some insight in to what’s after prompts and generative AI, by exploring recent events.
Stable Diffusion 2.0
Stable Diffusion 2.0 was released yesterday to a lot of excitement. Apart from added upscaling, inpainting, and depth-guidance features, a lot of the emphasis on how SD2 is better than SD1 centered on the FID and CLIP score profile improvements:

But the users actually trying it out had a different response:
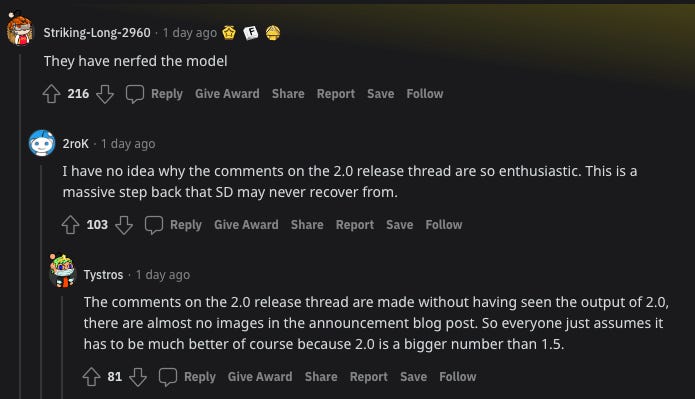

The primary changes have been explained on Reddit and Twitter, but the biggest change was switching from OpenAI’s CLIP-L14 model (from Jan 2021) to LAION’s OpenCLIP Vit-H14 (from Sep 2022 - polar bear Hong Kong UFO teaser image from LAION - extra context from huggingface, trained on LAION-5B from March 2022). So we went from a black box where attribution (e.g. how much of “greg rutkowski” did we use in generating this image?) was impossible, to a more interrogable situation with CLIP retrieval (and Have I Been Trained), but also a lot of existing expectations were shattered1.
Of course, most Stable Diffusion users don’t care about the precise details so much as the results that it can generate, so people spent their Thanksgiving dutifully generating SD1 vs SD2 comparisons:



If you looked closely and couldn’t decide if SD2 was better than SD1, you weren’t alone. It should not be overlooked that the SD2.0 release announcement’s big hero image was a landscape image, subtly hinting that perhaps that is where Stability is advertising its capabilities, perhaps diverting attention from areas (NSFW, celebrities, modern artists that could sue Stability AI) that might have become worse.
That said:
the task of deciding if a generated image is “better” or “worse” is quite subjective and hard to quantify across a literally infinite unbounded latent space - FID scores being the best we have so far.
prompts are a moving target - the same prompt generates different things in SD1 vs Midjourney 3 vs Midjourney 4 vs Dall-E 2 vs SD2 - and users will discover new magic keywords and best practices (more heavily using negative prompts, though they were already a thing in SD1 - UPDATE: more from Minimaxir on 29 Nov) that subjectively improve results. So perhaps SD2 initially looks “worse” than SD1, but then improves as users learn how to wield it better.
It’s most likely that SD2 will just be treated as a completely different model than a strict superset of SD1. Some SD apps have already “reverted to SD1”, and I expect SD2 to be offered as one of a growing list of “SD variants” (tracked on my repo since this is a fast moving list).
“Prompt Engineering” is a Product Smell
User frustration is understandable, but the discovery that prompts “break” when you switch models should not surprise anyone remotely technical. It is tacit, incidental complexity that arises out of our inability to know/communicate what it is we really want, and the model’s inability to infer our intent from low-bandwidth text2.
This is an annoyance at the hobbyist level, but a severe risk at the business level.
If you are making AI products based on “hours/days/weeks” of prompt engineering, your IP is liable to go poof3 when the next hot AI model comes out 3 months later.
Worse still, your IP can be leaked through prompt injection (for now only a GPT concern, but SD2 is incrementally better at text rendering, and it’s not hard to imagine SD3 or hybrid models achieving full text rendering, which can leak prompt IP)
or just embarrass you by exposing clumsy attempts at engineering politically correct output
In the initial GPT-3 rush, Karpathy anointed prompt engineering as “Software 3.0”, but the recent vibe has shifted:
“Prompt programming is when telling them what you want is hard and relies on arcane conjurations like "trending on artstation | unreal engine | super high res".
Software 3.0 is when the obvious request just works.”
— Gwern Branwen
And:
“I don’t think we’ll still be doing prompt engineering in five years…
I just hope it’s not figuring out how to hack the prompt by adding one magic word to the end that changes everything else. What will matter is the quality of ideas and the understanding of what you want. So the artist will still do the best with image generation but not because they figured out to add this one magic word at the end of it. Because they were just able to articulate it with a creative eye that I don’t have.“
And:
“Prompt Engineering is like rearranging the deck chairs on the Titanic.
The sooner people can join @ylecun and me in recognizing that true intelligence isn’t coming from #GPT-3 alone, the better.”
And a more evenhanded take:
“The act of continuously iterating on a prompt to have a model provide an objectively desired response is implicitly acknowledging the model is failing.
As models become more generally intelligent, they will be capable of aligning with desired output without humans contorting our input.
…
And, fwiw, we’ve seen this before: Prompting is almost like a kind of hyperparameter tuning. The hyperparameter tuning that was once was required to get traditional ML to be useful with sklearn has largely fallen by the wayside as the models themselves have gotten better.
The fact that adding keywords like Let’s Think Step By Step, adding “Greg Rutkowski”, prompt weights, and even negative prompting are still so enormously effective, is a sign that we are nowhere close to perfecting the “language” part of “large language models”. To reiterate a theme from the very first post that kicked off this newsletter, prompts as a brittle arcane art of “spellcasting” is unsustainable.
Completely eliminating prompting is essentially solving a constrained subset of the alignment problem, which is AGI-Hard - however, we may be able to hide prompting in clever ways:
An underappreciated element of the success of GitHub Copilot (podcast here) is that product development took ~a few months to figure out the right form factor: zero-shot, in-IDE, context-aware autocomplete with no buttons to press for the default experience, and an explorable pane of alternatives on demand.
Nathan Baschez’s Lex.page takes the similar approach for text - except that generations are triggered with a ++ keypress, but beyond that there is no separate prompt textbox.
My lesson from these two examples is that it might be possible to make prompting “invisible” by making it part of the UI, and finetuning output for as much of the writer’s context as possible to make it more useful. Latency matters, and cost matters, which are wonderful because these tend to be “regular engineering” type problems rather than AI problems.
“Generative AI” is underselling the potential
Generative AI is certainly a buzzword that has led to some great memes:



But the funny thing is it is leading to some real revenue: the whisper numbers for Jasper, which recently announced their $1.5b Series A, stand at $80m ARR, with Midjourney at $50m ARR and Stability at $40m ARR.4
Still, it can be a very heretical observation that the term “Generative AI” is not well loved by its primary beneficiaries.
This might disappoint the tech landscape chart making cottage industry (Base10, Sequoia, a16z) - while generative AI has had a banner year, the business world has far more usecases for decreasing entropy than increasing it5. The world has had enough of the “haha! everything you just read was written by AI! isn’t that cute! gotcha!” bait and switch and we already have a deep distrust of real images from official government and media sources without any need for increased suspicion due to AI fakery.
The most prominent case of the “Generative AI” backlash coincidentally also happened this past week, with Meta’s Galactica model released to much hype and then taken down in 3 days:
One could argue that it was simply too ambitiously productized and marketed; Metaphor Search, which was launched just the prior week, experienced no such blowback because it limited itself to predicting links rather then generating answers. We do not have space for an in-depth discussion on the facts and ethics of Galactica, but further interesting debates are on HN1, HN2, and Twitter.
The fact that Language Models Hallucinate is fun for those new to them, but tiring and a basically permanent fact of life for people working with generative models, requiring very kludgy and expensive cascades of models and a “Judge” model of models for error correction. Solving hallucination (and adding physics, theory of mind, conceptual composition, etc) is again AGI-hard and therefore uninteresting to the pragmatist.
As Generative AI crests the Gartner Cycle peak and falls due to already obvious flaws, it may be worth paying attention to the builders who are focusing on other ways of productizing language models: Agentic AI and RLHF.
CTAs
Liked this post? Help share it on Twitter (for now…)


Leading to a predictable reactionary movement, with one flaw - Stability is likely the out-of-bounds marker for what is venture backable in generative AI.
One of my most fun AI experiences recently was attending a Prompt Battle at the first OpenAI hackathon in SF, and the MC laughing at all our obviously-Stable-Diffusion-flavored prompts, reminding us “hey, word order doesn’t matter in Dall-E!”. We had all unknowingly internalized principles of prompt engineering skewed by our own experience.
It’s overly alarmist to say that all the IP gets invalidated in the next model, and to some extent this is what being early in any new tech looks like; you have to take dumb risks and do things that don’t scale in order to have the length and breadth of experience you need to know things others don’t and build something lasting. By the time the AI product playbook is obvious, it may be too late to start positioning for it — because of the hundreds of founders already searching the latent AI product space without requiring any long term game plan before they begin.
I don’t believe the Copilot number of $100m ARR, since GitHub itself only recently passed $1b ARR, but you could do a Fermi estimate with some public numbers - hundreds of thousands of users, 50% paying, $100/year/user, works out to at least $10m/year.
Acknowledged that “Generative AI” does not directly equate to “increasing entropy” - there are great ways to use “generative AI” to summarize and extract. Arguably diffusion models simply “make entropy useful” by reducing it with CLIP guidance - which isn’t everything, but also isn’t nothing.
Great article!
Great article! But to what extend is it not possible to make the argument in reverse? The fact that LLMs suck at language (as you illustrate with the arcane prompting), but can still create valuable results in the right context, could also point to immense potential value for each small improvement in language ability right? MJv4 didn't have a fundamental improvement in language ability, just fine tuning on user results. But it still lead to a significantly better model.