

The Anatomy of Autonomy: Why Agents are the next AI Killer App after ChatGPT
Auto-GPT/BabyAGI Executive Summary, a Brief History of Autonomous Agentic AI, and Predictions for Autonomous Future

Welcome to the 12k new listeners who checked out the Segment Anything pod!
We’ve launched a new community page with our upcoming events in SF, NY and Miami (this Friday)! See you if you’re in town!
Discussions happening on Hacker News and Twitter.
“GPTs are General Purpose Technologies”1, but every GPT needs a killer app. Personal Computing needed VisiCalc, the smartphone brought us Uber, Instagram, Pokemon Go and iMessage/WhatsApp, and mRNA research enabled rapid production of the Covid vaccine2.
One of the strongest indicators that the post GPT-3 AI wave is more than “just hype” is that the killer apps are already evident, each >$100m opportunities:
Generative Text for writing - Jasper AI going 0 to $75m ARR in 2 years
Generative Art for non-artists - Midjourney/Stable Diffusion Multiverses
Copilot for knowledge workers - both GitHub’s Copilot X and “Copilot for X”
Conversational AI UX - ChatGPT / Bing Chat, with a long tail of Doc QA startups
I write all this as necessary context to imply:
The fifth killer app is here, and it is Autonomous Agents.
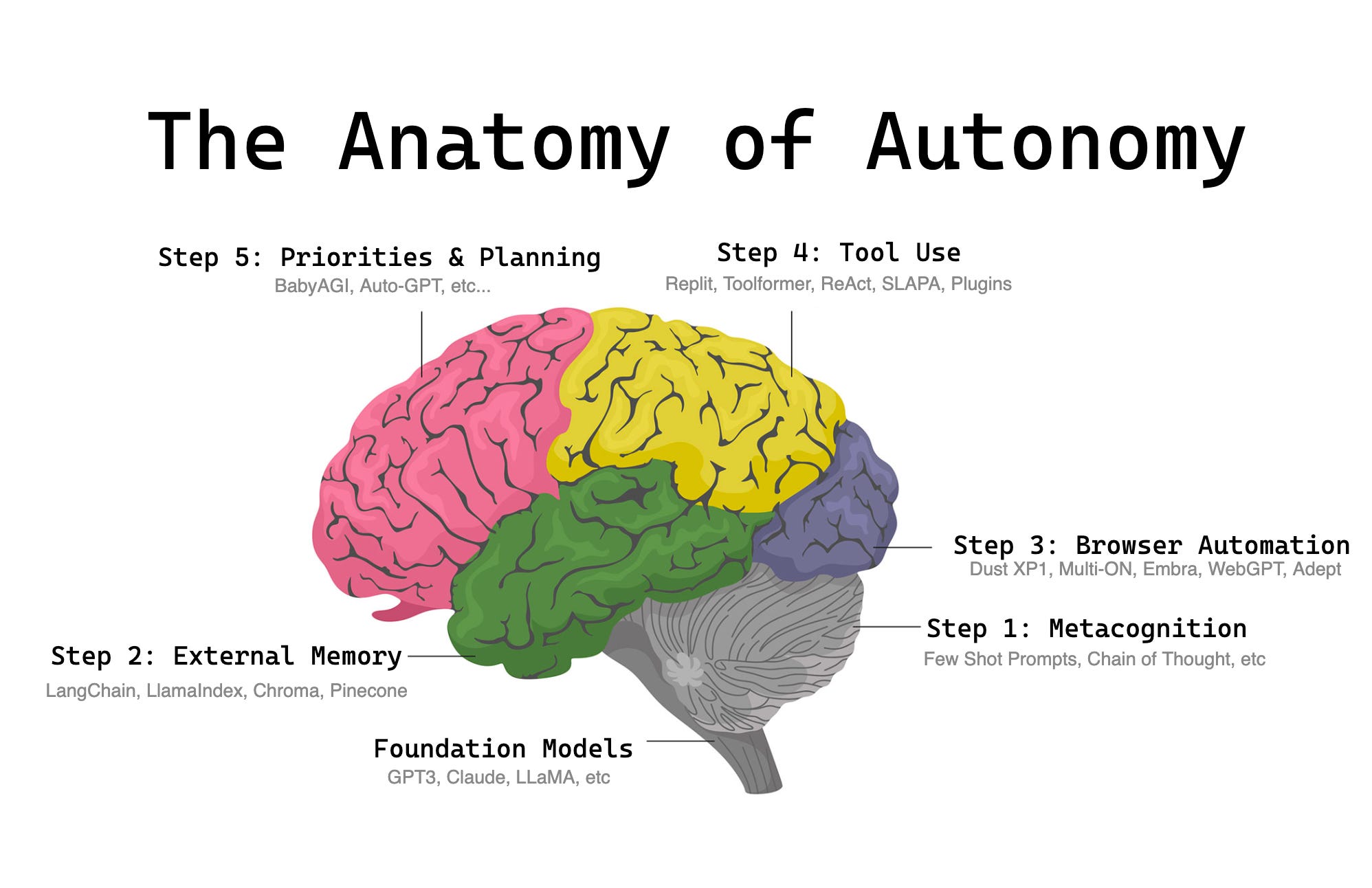
But first, as usual, let’s start with an executive summary to catch up those out of the loop.
Auto-GPT Executive Summary
Auto-GPT (and its younger sibling BabyAGI) are independently developed Python projects, open sourced March 30th and April 2nd respectively, which have caught enormous popularity, with Auto-GPT trending #1 on Twitter and GitHub in the past 2 weeks (far outpacing every other open source AI project including Segment-Anything, Stable Diffusion, and the now Sequoia-crowned $200m-valuation-LangChain).
Both projects do not involve foundation model training or indeed any deep ML innovation; rather they demonstrate viability of applying existing LLM APIs (GPT3, 4, or any of the alternatives) and reasoning/tool selection prompt patterns in an infinite loop, to do potentially indefinitely long-running, iterative work to accomplish a high level goal set by a human user.
We do mean “high level” — Toran Richards’ original demo for Auto-GPT was “an AI designed to autonomously develop and run businesses with the sole goal of increasing your net worth”, while Yohei Nakajima coded up Jackson Fall’s viral HustleGPT prompt on ChatGPT and told it to “start and grow a mobile AI startup”. In the 2 weeks since, community members have built extensions and clones and agent managers and frameworks and ChatGPT plugins and visual toolkits and so on, with usecases in market research, test driven development, and scientific literature review.
Beyond those similarities, the projects are very different in their approaches.
BabyAGI is intentionally small, adding and stripping out LangChain, with its initial code being less than 150 lines and 10 env vars (it is now ~800LOC).
GPT4 visualizing the codebase. Other attempts. While Auto-GPT is more expansive (7300 LOC), with the ability to clone GitHub repos, start other agents, speak, send tweets, and generate images, with 50 env vars to support every vector database and LLM provider/Text to Image model/Browser.


The projects have caught the imagination of leading AI figures as well, with Andrej Karpathy calling AutoGPTs the “next frontier of prompt engineering” and Eliezer Yudkowsky approvingly observing BabyAGI’s refusal to turn the world into paperclips even when prompted.
A Brief History of Autonomous AI
In my understanding of neurobiology, every convolution that wrinkles the brain a bit more makes us a little smarter. In a similar way, AI progresses by “convolutions”, and in retrospect our path to the present day has been obvious. I’d like to map it out:
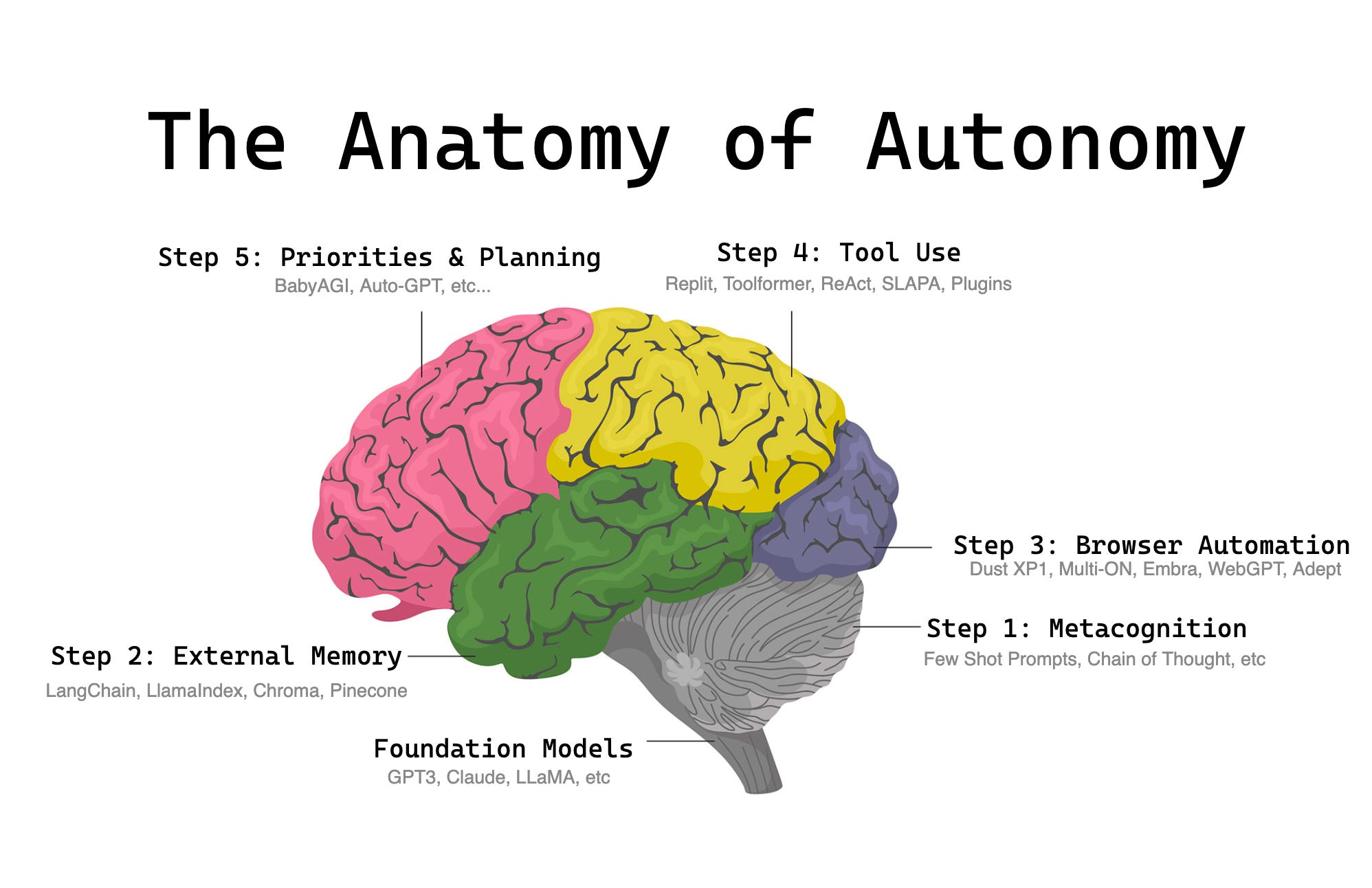
Key Autonomy Capabilities arranged in rough chronological order
Foundation models:
Everything starts with the evolution and widespread availability of massive LLMs (via API or Open Source). The sheer size of these models finally allow for 3 major features:
~perfect natural language understanding and generation
world knowledge (175B Parameters can store 320GB, which is 15 Wikipedia’s)
emergence of major capabilities like in-context learning
This leads to the rise of the early prompt engineers, like Gwern Branwern and Riley Goodside who explored creative single-shot prompts.
Capability 1: Metacognition (self improvement of pure reasoning)
Kojima et al (2022) found that simply adding “let’s think step by step” to a prompt dramatically raised the performance of GPT3 on benchmarks, later found to be effective due to externalizing the working memory for harder tasks.
Wei et al (2022) formalized the technique of Chain of Thought prompting that further improved benchmark performance.
Wang et al (2022) found that taking a majority vote of multiple Chains of Thought worked even where regular CoT was found to be ineffective.
More and more techniques like Calibrate Before Use, Self-Asking, Recursively Criticize and Improve, Automatic Prompt Engineering, appear.
Capability 2: External Memory (reading from mostly static external data)
The capability of in-context/few shot learning could be used to cheaply update a foundation model beyond its’ knowledge cutoff date and focus attention on domain specific, private data
The constraints of limited context length lead to the need for embedding, chunking and chaining frameworks like LangChain, and vector databases like Pinecone (now worth $700m), Weaviate ($200m), and Chroma ($75m).
Another way of using natural language to access and answer questions form relational databases are the Text to SQL companies, which included Perplexity AI ($26m Series A), Seek AI ($7.5m Seed), and a long tail of other approaches including CensusGPT and OSS Insight.
Capability 3: Browser Automation (sandboxed read-and-write in a browser)
Sharif Shameem (an upcoming guest! more on a future pod) first demoed GPT-3 automating Chrome to buy Airpods in 2021.
Adept raised a Series A with an all-star team of Transformer paper authors and launching the ACT-1 Action Transformer (now with a hefty $350m Series B despite the departure of Vaswani et al)
Nat Friedman’s NatBot brought browser automation back into the zeitgeist a year later, showing how an agent can make a restaurant reservation across google search and maps from a single natural language instruction.
Dust XP1 was also released but was read-only, did not do any automation. MULTI·ON went that extra mile and is now also in the ChatGPT Plugin Store.
A nice variant of browser agents are desktop agents - Embra AI seem to be the most hyped here (though still pre launch), and Rewind AI could be next.
It would seem that Multi-modal GPT4’s visual capability would be able to greatly enable the desktop agents here, especially where no accessibility text or DOM is available.
Capability 4: Tool making and Tool use (server-side, hooked up to everything)
Search. Generated answers from memorized world knowledge, or retrieved and stuff into context from a database, will never be as up to date as just searching the web. OpenAI opened this can of worms with WebGPT, showing their solution to crawling the web, summarizing content, and answering with references (now live in ChatGPT Plugins and in Bing Chat, but replicated in the wild with Dust and others).
Writing Code to be Run. We knew that GPT-3 could write code, but it took a certain kind of brave soul like Riley Goodside to ask it to generate code for known bad capabilities (like math) and to run the code that was generated. Replit turned out to be the perfect hosting platform for this style of capability augmentation (another example here).
ReAct. Yao et all (2022) coined the ReAct pattern which introduced a delightfully simple prompt template for enabling LLMs to make reliable tool choices for Reasoning + Acting given a set of tools. Schick et al (2023) introduced the Toolformer that specifically trained a model with special tokens, but this does not seem as popular.
Multi-model Approaches. Models calling other models with capabilities they didn’t have were also being explored, with HuggingGPT/Microsoft JARVIS and VisualChatGPT.
Self-Learning. Self-Learning Agent for Performing APIs (SLAPA) searches for API documentation to teach itself HOW to use tools, not just WHEN. This approach was adapted for the OpenAPI (fka Swagger) spec for ChatGPT Plugins, which also used natural language.
Other semi-stealth mode startups that may be worth exploring in this zone are Fixie AI and Alex Minion AI.
At this point it is worth calling out that we have pretty much reached the full vision laid out by this excellent post from John McDonnell 6 months ago:

So what net new thing are we seeing in this most recent capability spurt?
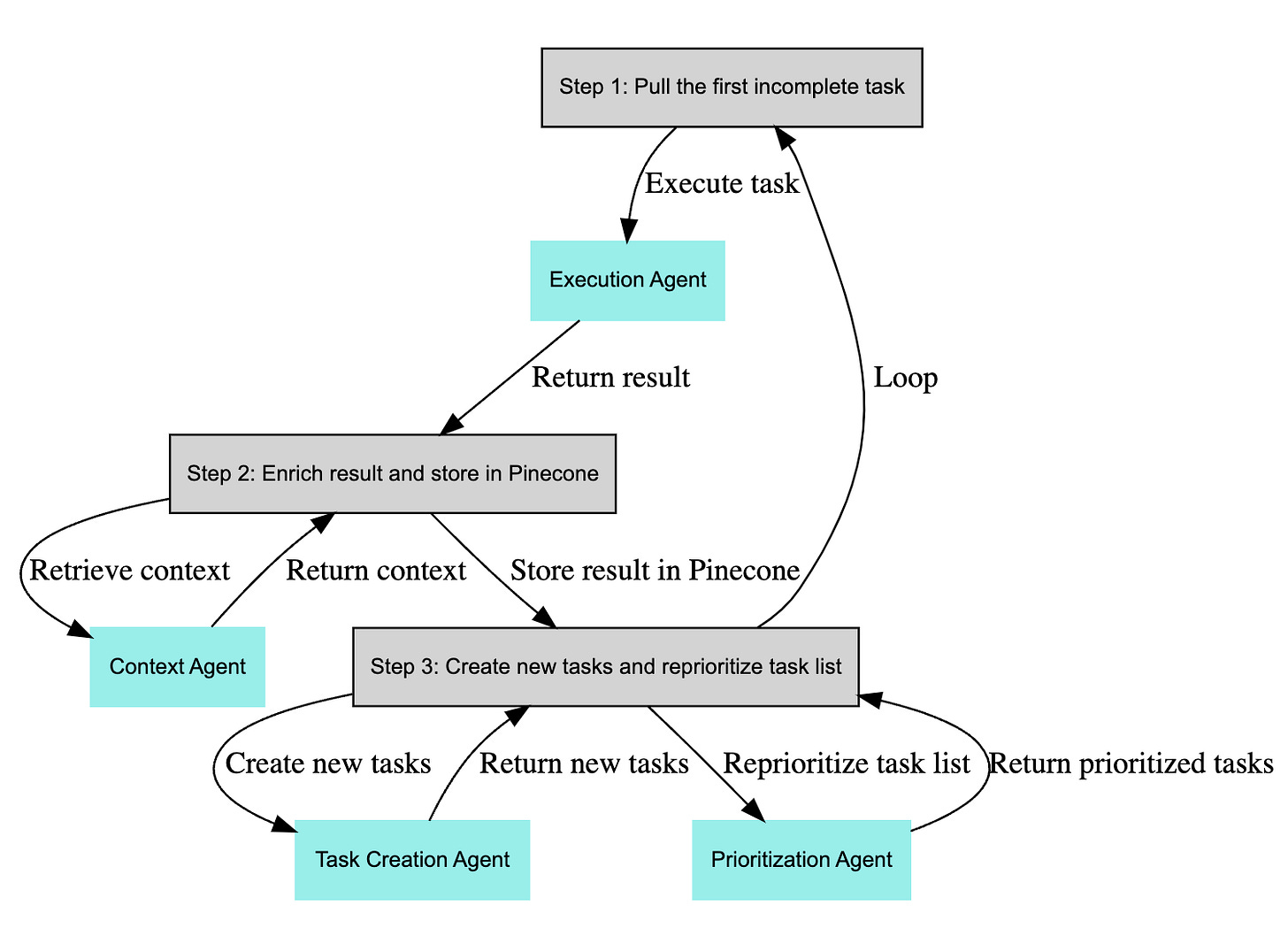
I think the clue is in the 4 agents that naturally evolved in BabyAGI (scroll up for diagram):
The “context agent” (Capability 1 + 2) could be a much smarter version of the data augmented retrieval that both LlamaIndex and Langchain are working on. Yohei added the need for “relevant (task) context” which may be slightly different than the classic semantic similarity algorithms offered by the vector databases.
Active learning may see a return to favor as autonomous “context agents” actively surface things they don’t know for prioritization
The “execution agent” calls OpenAI, or any other foundation model, and could optionally make or use any provided tools to accomplish a task (Capability 3 + 4)
The “task creation agent”, well, creates tasks, but must not hallucinate and must self criticize and learn from previous tasks (Capability 1 + 2). Challenging, but not outside the bounds of simple common sense benchmarks.
And the last agent is the “prioritization agent”. Ah! A new task!
That leads us to identify…
Capability 5: Planning, reflexion, and prioritization
Shinn et al (2023) showed that Reflexion - an autonomous agent with dynamic memory and self-reflection, could dramatically improve on GPT-4 benchmarks.
Shoggoth the Coder won the recent ChatGPT Plugins Hackathon as an independent agent capable of proposing and submitting PR fixes to open source projects.
Meta’s Simulacra paper showed the entertaining potential of autonomous NPC agents interacting with each other in a game-like setting.
Regardless of use case, autonomous agents will be expected to plan further and further ahead, prioritizing task lists, reflecting on mistakes and keeping all relevant context in memory. The “Sparks of AGI” paper specifically called planning out as a notable weakness of GPT-4, meaning we will likely need further foundation model advancement before this is reliable.
The recent LangChain Agents webinar discussion also highlighted the need for the ability to stack agents and coordinate between them.
In the Latent Space Community, AI virtual software developer platform e2b is already discussing the potential of having fleets of AI developer workers.
Why Autonomous AI is the Holy Grail
What makes software valuable to humanity? In both my investing and career advice, I am fond of encouraging people to develop a “theory of value of software”.3
One of the clearest value drivers4 of software is automation. The one currency we all never have enough of is time, and the ability to obsolete human effort, whether by clever system design, hiring someone else, or programming a machine, both frees up our time and increases our ability to scale up our output by just doing more in parallel. In fact this can be regarded as a core definition of technology and civilization:
“Civilization advances by extending the number of operations we can perform without thinking about them” — Alfred North Whitehead.
The relationship betwen automation and autonomy is subtle but important:
ChatGPT doesn’t do anything without your input, but once you punch the right prompts in, it can do an awful lot of research for you, especially with Plugins
AutoGPTs by default require you to enter a goal and hit “yes” to approve each step it takes, but that is incrementally easier than having to write responses
AutoGPTs also have limited (run for N steps) and unlimited (run forever) “continuous modes” which are fully autonomous but very likely to go wrong and therefore have to be closely monitored
We’ve just explained that technological and civilization advance requires us to be able to do things without thinking about them, so clearly full autonomy with as much trust and reliability as possible is the ultimate goal here. Let a thousand agents bloom! AI Assistants is where most people start, but Josh Browder is working on AI Lawyer, Replika is working on AI Waifu, I want AI Junior Developers and AI Video and Podcast and Newsletter Editors, Karpathy wants us to keep going with the AI C-Suite.
Fortunately, we don’t have to reason out every step of this progression from first principles, because the Society of Automotive Engineers established a shorthand for this almost a decade ago:

I’ll assume you are familiar with some of the self driving car discourse5, but it's time to understand that self-driving AI agents in 2023 are just about where self-driving cars were in ~2015. We are beginning to have some intelligence in the things we use, like Copilot and Gmail autocompletes, but it's very lightweight and our metaphorical hands are always at ten and two.
In the next decade, we'll want to hand over some steering, then monitoring, then fallback to AI, and that will probably map our progress with autonomous AI agents as well.
Edit from May 2023: we found out from our upcoming podcast guest Itamar Friedman of Codium that they had already done some thinking on 6 levels of Autonomous Code Integrity. Check them out!
In the following decade, we’ll develop enough trust in our agents that we go from a many-humans-per-AI paradigm down to one-human-per-AI and on to many-AIs-per-human, following an accelerated version of the industrialization of computing from the 1960s to the 2010s since it is easier to iterate on and manipulate bits over atoms.
There will be two flavors, or schools of thought, on autonomous AI:
The Jobs School: AI Agents that augment your agency, as “bicycles for your mind”
The Zuck School: AI Algorithms that replace your agency, hijacking your mind
We’ll want to try our best to guide our efforts to the former, but we won’t always succeed.
Related Reads
LangChain’s take on Autonomous Agents
Misc Observations I couldn’t put anywhere
I will perhaps expand these in future, or not, but happy to discuss each in comments.
Despite needing prompt templates, tool selection, memory storage and retrieval, and orchestration of agents, neither Babyagi nor AutoGPT use LangChain. EDIT: LangChain’s docs now have some implementations.
The new FM “Bitter Lesson” - Every time we try to finetune foundation models to do a certain task, software engineers can write abstractions on top to do it less efficiently but faster.
ReAct/SLAPA > Toolformer/Adept ACT-1
there’s families of transformers and alternative architectures (H3, fwd-fwd algo) but nobody can name any that have stuck
Academic research of deep reinforcement learning for agents seems trapped in games?
MineDojo, Deepmind DreamerV3, GenerallyIntelligent Avalon
CICERO diplomacy is notable because did NOT use deep RL?
Semantic search has been less of a killer product. why?
Backend GPT has not led anywhere. why?
“wen AI Agents” easier to discuss than “wen AGI”
all the open source winners are new to open source lol? is “open source experience” that valuable?
Why do people all use pinecone to store like 10 things in memory
Safety - no more AGI off switch with autonomous agents
AGI Moloch means have fun staying poor = have fun staying safe
we’re calling for the wrong kinds of pause:
pause on fleets of workers until we have extremely well developed constitutions and observability?
Predictions
there will be “AI Agent platforms”
with tools all enabled → Zapier and fixie well placed
there will be “AI Agent fleets”
especially if “idempotent”, readonly
custom research into the 4 kinds of agents
“context agent” → active learning
execution agent is most straightforward but need to do its job well
task creation → problems: hallucination, omission
prioritization agent
will need to do DAGs
spawn on command
Actor model / Agent Oriented Programming?
5th agent - reflection? metalearning?
there will be “AI social networks”
subreddit simulator
orchestration and the cyborg problem
sarahcat observation is correct
swyx commentary on cyborg nodes would be amazing
Are level 5 agents AGI-hard?
hard as self driving cars - perpetually 5 years away - uber & apple gave up
must know when to yield to humans
easy to require confirm for destructive actions, but sometimes unclear
“Interesting non-obvious note on GPT psychology is that unlike people they are completely unaware of their own strengths and limitations. E.g. that they have finite context window. That they can just barely do mental math. That samples can get unlucky and go off the rails.” Etc. karpathy
must solve prompt injection (hey @simon)
will probably need to self improve statefully
principal agent problem
we dont know how to prioritize humans, and you want to eval bot ability to prioritize? good luck
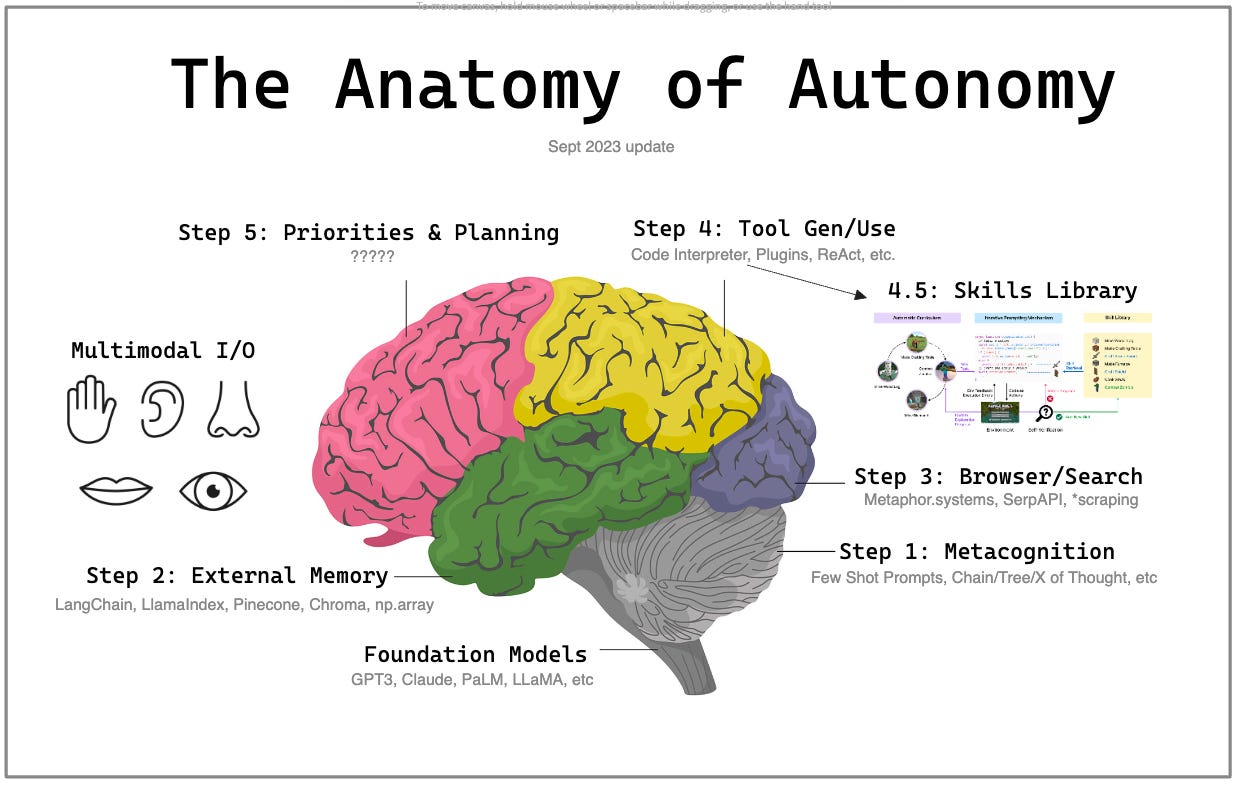
(Update): Sept 2023 update
As we learned more about how people build agents, and what the valuable parts of the stack are, I updated the chart based on a @karpathy tweet.
The title of an influential recent OpenAI paper, but also an actual concept in the study of technology — something your humble correspondent first learned about in research for the Tech Strategy chapters of my book 3 years ago. Worth internalizing.
Dr. Katalin Kariko’s story of perseverance is worth a full listen, if you haven’t heard the story.
Theory of Theory of Value of Software: If you set out with the goal to understand what makes some lines of code more valuable than other lines of code, and try to make predictions by running your theories through lots and lots of data while reducing your “loss”, the idea is that you’ll be better able to invest your time, money, and creativity in more rewarding directions than people who don’t take the same effort.
I am not yet ready to publish my full list, but software value drivers include: Demand and Supply Aggregators, Production-ready frameworks for underspecified Standards, “Shadow IT” to circumvent internal politics and byzantine rules, systems of record (Zawinswyx’s Law), and also replacing people and manual processes.
Sidenote: if you are excited about a self driving car future, you must visit San Francisco and befriend someone with access to the Cruise apps. There’s ~200 of these fully self-driving all over the city every night. The future is very close!
https://twitter.com/mcraddock/status/1645779894670950400/photo/1
A bit bigger map of LLM + Prompt Enginnering
Great deconstruction plus love the wordplay on anatomy of autonomy