

[AINews] Anthropic Claude Fable 5 — Mythos but Safe, with Controversial Terms
The much anticipated launch of the Mythos-class model was marred by some controversial usage policies
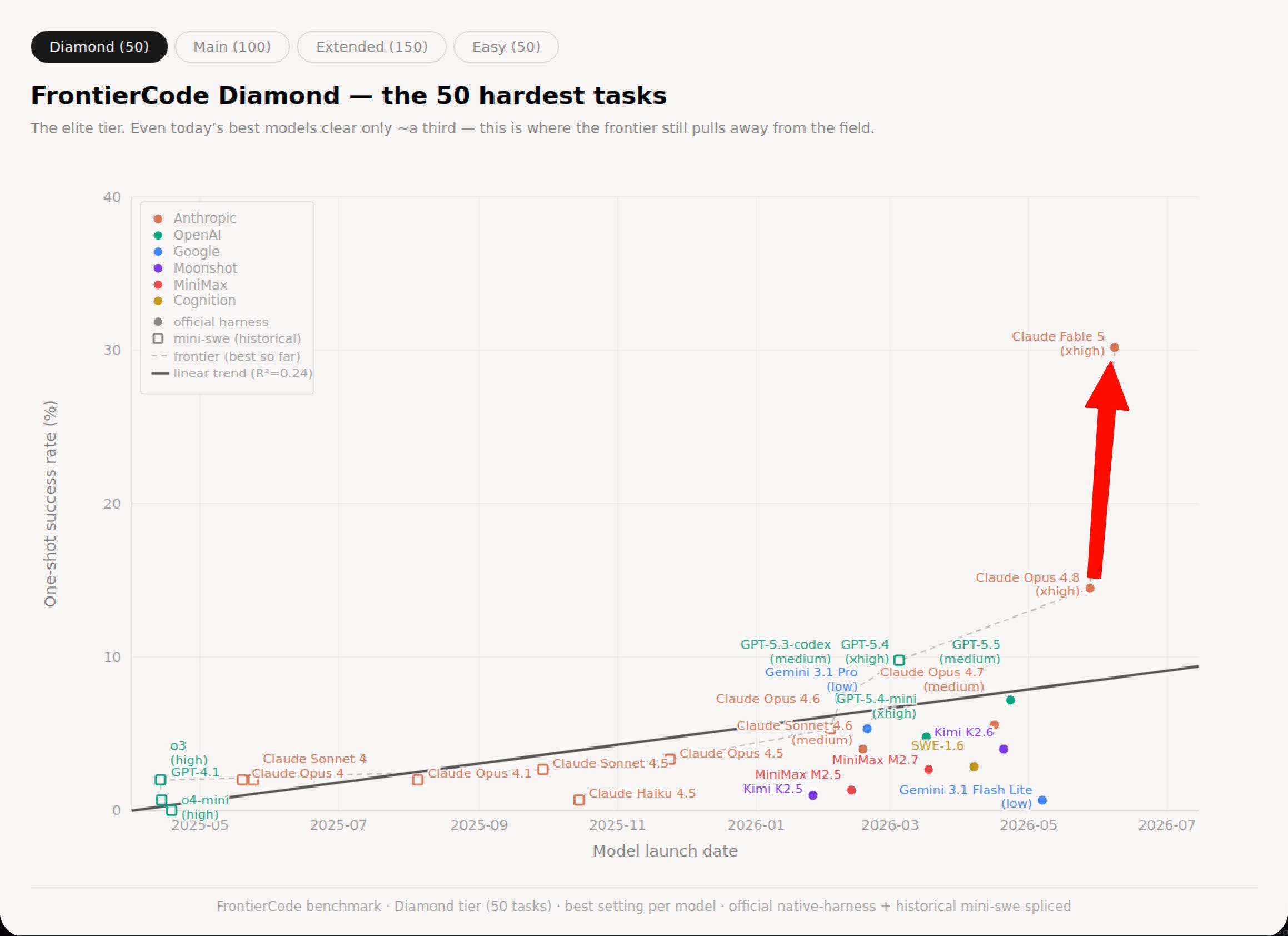
By some measures, Opus 4.8, barely two weeks old, was already the leading model in the world. But now, 34 days after the SpaceXai deal and 63 days after the original Mythos announcement*, we have a Mythos-class model (at least 2x size of Opus) available to everyone (in coinciding with Claude Tokyo). It is a feat of incredible engineering (and commitment to access) to make these research models GA, and the benchmarks are great… with asterisks. Here they are on yesterday’s brand new, out of distribution, FrontierCode Diamond, going from 13.4% to 29.3%:
The blog and the system card contain most of the authoritative information, but don’t miss the youtube videos showing it playing Factorio, Pokemon (unlike Claude Plays Pokemon, this is just using vision, no complex harness as we covered in our pod), EDM visualization (never having head music before), 3D CAD editor creation and printing and more from their main intro video.
API pricing is also fantastic, at roughly 2x Opus.
The asterisks come because Fable is released with two controversial changes:
No ZDR: “We will require 30-day retention for all traffic on Mythos-class models, on both first- and third-party surfaces. We won’t use this data to train new Claude models, or for any non-safety-related purpose, and we’ve instituted new privacy protections including logging all human access to the data and ensuring its deletion after 30 days in almost all cases ...” (see full policy)
RSI suppression: “In light of the ability of recent models to accelerate their own development, we’ve implemented new interventions that limit Claude’s effectiveness for requests targeting frontier LLM development (for example, on building pretraining pipelines, distributed training infrastructure, or ML accelerator design). Using Claude to develop competing models already violates our Terms of Service, but enforcing this restriction through our safeguards avoids accelerating the actors most willing to violate these terms.
> Unlike our interventions for cybersecurity, biology and chemistry, and distillation attempts, these safeguards will not be visible to the user. Fable 5 will not fall back to a different model. Instead, the safeguards will limit effectiveness through methods such as prompt modification, steering vectors, or parameter-efficient fine-tuning (PEFT). These interventions will not affect the vast majority of coding work. We estimate they will impact ~0.03% of traffic, concentrated in fewer than 0.1% of organizations”.
The vast majority of users will not be affected by these limitations, but the open AI community is understandably upset, as you will see below.
You can find more of their recommendations on usage in Diane Penn’s Tokyo talk, which we have clipped below.

*(and 1 week-1 day after both Anthropic and OpenAI filed their S-1’s ahead of SpaceX’s IPO next week…)
AI News for 6/8/2026-6/9/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
Top Story: Anthropic Claude Fable 5 and Mythos 5 release
What happened
Anthropic released two versions of its next major model family: Claude Fable 5 for general availability and Claude Mythos 5 for restricted access.
Anthropic officially announced Claude Fable 5 as its “first generally available Mythos-class model,” saying it exceeds any model it has previously made broadly available and is state-of-the-art on nearly all tested benchmarks @claudeai, @claudeai
Anthropic said Fable 5 is the same underlying model as Mythos 5 with added safeguards, and that some cyber/bio/chemistry/distillation-related prompts may be routed to Claude Opus 4.8 instead @ClaudeDevs, @scaling01
Anthropic stated that for a “narrow range” of potentially harmful topics, queries transparently fall back to Opus 4.8, and claimed 95%+ of sessions never see one according to early user-facing messaging @claudeai, @mikeyk
Anthropic developer messaging said fallback is available server-side and via SDK middleware in Python, TypeScript, Go, Java, and C# @ClaudeDevs
Pricing for both Fable 5 and Mythos 5 was reported as $10 / million input tokens and $50 / million output tokens; cache pricing was later reported by third-party evaluators as $12.50 / million cache writes and $1 / million cache reads @scaling01, @ArtificialAnlys
Fable 5 kept Anthropic’s 1M-token context window according to Artificial Analysis @ArtificialAnlys
Anthropic put Fable 5 into Pro, Max, Team, and seat-based Enterprise plans until June 22, then said it would require usage credits due to capacity constraints, with plans to restore broader subscription access later @ClaudeDevs, @scaling01, @ArtificialAnlys, @kimmonismus
Confusion over the temporary inclusion was immediate; users asked what “included until June 22” meant and Anthropic staff clarified the rollout @dejavucoder, @TheAmolAvasare
Anthropic later reset 5-hour and weekly rate limits across products after heavy demand @ClaudeDevs
Official claims and third-party benchmark data
Anthropic and partner platforms reported a broad benchmark lead, especially in coding and long-horizon agentic tasks.
Anthropic’s public claim: Fable 5 is especially strong in software engineering, knowledge work, scientific research, and vision, and its lead increases with task length and complexity @claudeai
Cursor said Fable 5 set a new CursorBench SOTA at 72.9%, 8 points above the previous best @cursor_ai
Cognition said Fable 5 took the #1 spot on FrontierCode, and Devin integrated it into Devin Cloud Ultra, Desktop, and CLI @cognition, @cognition
Cline reported Fable 5 at 88.0% on Terminal-Bench 2.1, beating GPT-5.5 by 4.6 points @cline
Artificial Analysis placed Fable 5 #1 on its Intelligence Index at 64.9, roughly 5 points ahead of GPT-5.5, and said Anthropic occupied the top two spots @ArtificialAnlys
Artificial Analysis also reported:
GDPval-AA Elo 1932, #1 on agentic real-world knowledge work @ArtificialAnlys
53% on Humanity’s Last Exam, more than 7 points ahead of the next-best model, while fallback triggered on 9% of HLE tasks @ArtificialAnlys
~8% fallback routing across Intelligence Index tasks, mostly on scientific questions @ArtificialAnlys
Anthropic stated fallback occurs in fewer than 5% of sessions on average @ArtificialAnlys
Community benchmark summaries highlighted very large deltas in coding:
SWE-Bench Pro: Fable 5 80.3% vs GPT-5.5 58.6% @Yuchenj_UW
FrontierCode Diamond: Mythos 5 30.9% vs second-best 13.4% @scaling01
Anthropic ECI 161.29 for Mythos 5 @scaling01
Artificial Analysis noted that Fable 5’s knowledge benchmark jump on AA-Omniscience could imply a larger model than prior public Anthropic models, though that is inference rather than confirmed spec @ArtificialAnlys
Product behavior, usage profile, and deployment details
The release was defined as much by workflow changes and cost profile as by raw evals.
Anthropic staff and early users repeatedly described Fable 5 as a model for very long, high-effort tasks, with users shifting from giving it tasks to giving it objectives/responsibilities @felixrieseberg, @ClaudeDevs, @alexalbert__
Anthropic advised users to default to xhigh/high effort, rewrite old CLAUDE.md instructions, and let the model use more judgment @alexalbert__
Anthropic’s developer messaging emphasized multi-agent orchestration, with Fable delegating to smaller models in Claude Managed Agents @ClaudeDevs
Multiple testers described Fable as slow, token-hungry, expensive, but unusually capable:
Dan Shipper said it routinely used 500k to 1M tokens on tasks and was best reserved for heavy jobs @danshipper
Simon Willison called it “slow, expensive and capable” @simonw
Theo quickly hit limits and later welcomed Anthropic’s rate-limit reset @theo, @ClaudeDevs
Third-party and internal anecdotes emphasized large gains on long-running engineering tasks:
Ethan Mollick said he could hand it a 15-page design document and it would work for 9+ hours @emollick
Kimmonismus highlighted Anthropic’s claim that Stripe used Fable to do a 50-million-line Ruby migration in a day, replacing what would have taken a whole team over two months @kimmonismus
Victor Taelin reported Fable finding a subtle bug and producing claimed speedups up to 1770% in one case, though he still needed to audit correctness @VictorTaelin
Anthropic-associated posts cited 430x kernel speedups, 69x self-training speedups, and 10x drug-design acceleration, though these came from benchmark/system-card interpretations and should be treated as vendor-side claims unless independently replicated @scaling01, @scaling01, @scaling01
Ecosystem rollout was immediate: Fable 5 appeared in Cursor, Devin, Notion, Microsoft Foundry, GitHub Copilot App/CLI, Cline, Replit, Base44, MagicPath, Arena, MCP Atlas and more @cursor_ai, @cognition, @NotionHQ, @Azure, @pierceboggan, @cline, @pirroh, @ScaleAILabs
Safety architecture and the main controversy
The biggest debate was not whether Fable/Mythos is strong; it was Anthropic’s decision to silently reduce usefulness on some frontier-AI-development tasks.
Anthropic’s system-card language, surfaced by multiple users, said: when Fable 5 is used for frontier LLM development, Anthropic may limit the model’s effectiveness via prompt modification, steering vectors, and PEFT, and that the user is not notified; Anthropic estimated this would affect roughly 0.03% of traffic @Hangsiin, @kimmonismus
Anthropic also separately disclosed auto-rerouting for cybersecurity and biosecurity requests to Opus 4.8 @ClaudeDevs
This distinction mattered: some risky queries are visibly rerouted/billed as Opus, while frontier-LLM-development requests may be silently weakened rather than rerouted or refused
Critics argued that this creates an unlogged confounder in research and engineering workflows:
“silent handicaps should not be a thing in a paid product” @nrehiew_
“degrading performance on ML research without telling the user is shockingly hostile” @deanwball
Several researchers framed it as anti-competitive ladder-pulling against open research and open weights:
“labs starting to pull up the ladders” @natolambert
“this is the biggest wake-up call to protect and nourish open source AI” @rasdani_
“They didn’t mean pause AI research, they meant pause your AI research” @bayeslord
“original thinkers can’t be an underclass” @marksaroufim
“concentration of power, capabilities and economic wealth is the biggest risk in AI” @ClementDelangue
Multiple users worried the classifier boundary was too broad or too error-prone:
one user said “the word cancer is flagged as a biosecurity risk” @DeryaTR_
another said Fable wouldn’t answer “What does the heart do?” @Yuchenj_UW
users in biology reported account-context differences, including being able to use Fable in Incognito Mode but not normal mode @cremieuxrecueil
Teknium and others reported refusal on simple engineering prompts @Teknium, @Teknium
users reported PTX ISA questions and inference optimization queries getting flagged @snowclipsed, @dejavucoder
Some examples were humorous but pointed: users joked that asking for inference code caused the model to “start importing ONNX” or implementing JEPA, as a sign of capability steering @vikhyatk, @MattVMacfarlane
Facts vs. opinions
Facts / directly supported by release materials or benchmark posts
Fable 5 is generally available; Mythos 5 is restricted-access @claudeai, @TheRundownAI
Fable 5 and Mythos 5 share the same underlying model with additional safeguards on Fable @ClaudeDevs, @scaling01
Pricing is $10 / $50 per million input/output tokens @scaling01, @ArtificialAnlys
Fable retains 1M context @ArtificialAnlys
Anthropic introduced refusal/fallback mechanisms and SDK middleware @ClaudeDevs
Anthropic disclosed silent interventions for frontier LLM development affecting about 0.03% of traffic @Hangsiin
Fable is temporarily included in subscriptions until June 22, then credit-based @ArtificialAnlys
Opinions / interpretations
“Anthropic won,” “Anthropic has a coding moat,” “Anthropic going for ASI” are commentary rather than verified fact @scaling01, @scaling01, @scaling01
Claims that the move is primarily for IPO optics, anti-open-source positioning, or specifically to slow Meta/China/open labs are plausible interpretations but not confirmed by Anthropic @kimmonismus, @kylebrussell, @natolambert
Claims that Anthropic is acting from sincere safety beliefs rather than cynical moat-building are also interpretive @finbarrtimbers
Subjective reports like “GPT-4 moment,” “big model smell,” “strictly dominates me as an engineer,” or “doesn’t seem much better to normal users” are experiential, not standardized evidence @karinanguyen, @bcherny, @akbirkhan, @citrini
Different perspectives
Supportive / capability-first
Anthropic staff and close testers described Fable 5 as a step-function improvement:
Felix Rieseberg: shift from giving AI tasks to giving it responsibilities @felixrieseberg
Alex Albert: model feels collaborative rather than tool-like @alexalbert__
Karpathy: a “major-version-bump-deserving step change,” especially on long difficult tasks, though safeguards are “a little too trigger happy for launch” @karpathy
Bcherny: biggest step since Opus 4.5; the model shows judgment, taste, methodical debugging @bcherny
Third-party infra and app vendors emphasized benchmark wins and integration value rather than the safety controversy @cursor_ai, @cognition, @NotionHQ, @Azure
Critical / trust and openness
Many researchers and open-model advocates argued the silent throttling is unacceptable even if safety-motivated:
Natolambert called doing it without telling users “misaligned” @natolambert
Dean Ball warned it could attract antitrust scrutiny @deanwball
Jeremy Howard called it “a very dark and very sad day” @jeremyphoward
Gneubig warned of a future where AI is provided only to a privileged few @gneubig
Eric Zelikman framed it as silently sabotaging customers @ericzelikman
Open-source supporters used the launch as an argument for sovereign/open models @nickfrosst, @NoahZiems, @ClementDelangue
Neutral / mixed
Some observers argued Anthropic probably sincerely believes these interventions are necessary for safety, even if the product design is poor @finbarrtimbers
Others said Anthropic does not owe anyone unrestricted frontier capability, but still saw this as straightforward business and market segmentation rather than altruism @suchenzang
Karpathy’s view is mixed: model quality is exceptional, but launch safeguards are over-sensitive and should likely be tuned @karpathy
Research restrictions, privacy, and enterprise implications
The discussion expanded from safety to broader questions of trust, privacy, and enterprise reliability.
The central enterprise issue was predictability: if a provider can silently degrade outputs based on inferred task category, users may no longer know whether failures come from the model, the prompt, or hidden intervention @MattGibsonMusic, @code_star
Some users worried this is effectively a supply-chain risk for important workflows, pushing companies toward open weights or in-house models @NoahZiems, @deliprao
There was also concern that account-level context or prior usage history might affect trigger behavior, as seen in biologists’ reports about normal vs incognito mode @cremieuxrecueil
No tweet in the supplied set provided direct evidence that Anthropic was training on user data or violating stated data privacy terms; the privacy debate here was mostly about behavioral profiling / silent policy enforcement rather than classic training-data privacy
For research users, the hidden intervention was framed as especially damaging because it undermines reproducibility and scientific attribution @deanwball, @MattGibsonMusic
For enterprise buyers, the issue is not just whether the model is powerful, but whether it is a stable and auditable dependency for coding, medicine, science, finance, and infrastructure
Context
This launch matters because it combines a visible capability jump with a visible shift in access control.
The release landed amid intense competition with GPT-5.5, upcoming GPT-5.6, and Gemini 3.5 Pro; several posters argued Anthropic has opened a temporary lead in coding/agentic work @kimmonismus, @teortaxesTex
It also lands in a broader argument about the open vs closed model gap; one linked Epoch-style framing said open-weight models lag closed frontier models by about 4 months on average @dl_weekly
Community reaction suggests the launch may be remembered not only for “big model smell” and benchmark jumps, but for normalizing selective capability release: public access to the frontier model, but with domain-specific hidden limits
That policy line is likely to influence future debates around:
safety vs openness
fair access to frontier research tools
antitrust and platform power
enterprise trust in API providers
whether open models become the default for sensitive technical work even when they trail on raw capability
Models, benchmarks, and evals
New benchmark project Agents’ Last Exam (ALE) launched to test labor-market-aligned agent performance; top agents score only 2.6% on the hardest tier, across 1,500+ tasks, 55 occupations, with contributions from 300+ experts across 100+ institutions @YiyouSun, @SnorkelAI, @dawnsongtweets
Cohere released North Mini Code, its first open-source coding model: 30B total / 3B active MoE, 256K context, 64K max generation, Apache 2.0, optimized for agentic workflows @cohere, @JayAlammar, @vllm_project
Google announced Gemini 3.5 Flash Live Translate, real-time speech-to-speech translation in 70+ languages, available in Gemini API, AI Studio, Google Translate, and coming to Meet @OfficialLoganK
New benchmark iOSWorld evaluates personally intelligent phone agents across 26 custom iOS apps and 133 tasks; strongest frontier model reaches only 52% success even with privileged access @rsalakhu
Inference, training, and systems
Latent Context Language Models (LCLMs) were introduced as a long-context inference method compressing context up to 16×, improving the latency/accuracy frontier over KV-cache compression @micahgoldblum, @iamleonli
Microsoft Research’s Mirage stores 3D scenes as latent tokens, reporting 10.57× faster video generation and 55× lower memory use @HuggingPapers
vLLM introduced vime, an RL post-training framework in the vLLM ecosystem, positioned alongside NeMo-RL, OpenRLHF, and verl @vllm_project
Discussion around agent training continued with Self-Harness for self-improving scaffolds @omarsar0 and AutoForge/interleaved thinking retaining reasoning traces across turns @cwolferesearch
Google/Hugging Face launched the Fast Gemma Challenge to speed up Gemma 4 E4B on a single A10G without wrecking quality @googlegemma, @osanseviero, @_lewtun
Agents, tooling, and developer workflow
LangChain highlighted a pattern of agent loops driven by recurring triggers in Fleet @caspar_br
OpenAI added image results to web search in the Responses API @OpenAIDevs
GitHub/Copilot app updates included parallel sub-sessions and a canvas UI for dynamic interfaces @tgrall, @burkeholland
Hermes Desktop added Ollama support, with self-learning Python skills and messaging app integrations @ollama, @NousResearch
A security-oriented counterpoint on agent execution: Temenos argues for sandboxing generated code, not the agent, using rootless gVisor while keeping auth/tools on host @abhijithneil
Research, science, and formal methods
Axiom announced EconLib, a Lean-based economics library; formalizing Aumann’s “agreeing to disagree” theorem surfaced a hidden countability-related assumption @TheTuringPost
“Economy of Minds” proposed agent coordination through auctions and incentives rather than centralized orchestration, reporting gains such as 15.9% → 57.0% on math reasoning and 45.0% → 60.0% on financial research @TheTuringPost
Mayo Clinic’s REDMOD reportedly detected pancreatic cancer on CT scans up to 3 years before diagnosis, identifying 73% of hidden cancers at a median 475 days before diagnosis @TheRundownAI
Open ecosystem and infrastructure
Hugging Face and Arcee announced a partnership replacing AWS S3 with HF for all Arcee models/datasets, including private ones @ClementDelangue, @MarkMcQuade
Cohere kept pushing the sovereign/open angle with “Sovereign AI for all” @cohere
Marks Saroufim proposed a Researcher Reciprocity License and moved GPU MODE datasets to it, explicitly reacting to the sense that frontier labs benefit from open research while restricting access in return @marksaroufim, @marksaroufim
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. Open Model Inference and Chat Template Updates
Xiaomi just claimed 1,000+ tps on a 1T model using a standard 8-GPU server (Activity: 1027): Xiaomi MiMo claims
MiMo-V2.5-Pro-UltraSpeedreaches1000+ tokens/sdecoding on a1T-parameter MoE using a single “standard”8-GPUserver, via TileRT model-system co-design rather than Cerebras/Groq-style specialized hardware. The reported stack combines MoE-expert-only FP4/MXFP4 quantization with QAT while keeping non-expert modules at higher precision, plus DFlash block-level masked speculative decoding with acceptance lengths of6.30coding,5.56math/reasoning, and4.29agent tasks, and persistent low-latency kernels to reduce launch/sync overhead. A key unresolved technical caveat from comments is that Xiaomi does not specify which 8 GPUs were used, making reproducibility and cost/performance comparisons ambiguous. Commenters debated the economics of “Token Winter,” arguing the bottleneck is less model demand than overpriced/hoarded Western GPU supply, while Chinese compressed sparse architecture/MoE work from DeepSeek, Xiaomi, and MiniMax is becoming more inference-efficient. Others highlighted Xiaomi’s selective FP4 strategy as the most important detail because naïve full-model FP4 degrades reasoning, code, and logic.A key technical detail highlighted is that Xiaomi did selective FP4 quantization rather than applying FP4 uniformly: only the MoE Experts in MiMo-V2.5-Pro are quantized to FP4, while non-expert modules retain original precision to avoid degradation in reasoning, logic, and code generation. The comment notes Xiaomi used FP4 QAT to reduce model size and improve bandwidth utilization while keeping capability near the original model.
The released model weights are available on Hugging Face as XiaomiMiMo/MiMo-V2.5-Pro-FP4-DFlash: https://huggingface.co/XiaomiMiMo/MiMo-V2.5-Pro-FP4-DFlash. This is relevant because it allows independent inspection or benchmarking of the claimed
1,000+ tpsthroughput on an 8-GPU server.Several commenters questioned the hardware and parameter accounting behind the claim: “8 GPU server… which 8 exactly?” and “1T-A1B?” The technical concern is that throughput is not interpretable without knowing the exact GPU class, interconnect, serving stack, batch size, context length, and whether the
1TMoE model activates only around1Bparameters per token.
Gemma 4 Chat Template now has preserve thinking (Activity: 482): Google’s Gemma Team has added
preserve_thinkingsupport to the official Gemma 4 chat template, matching an aftermarket template modification some users were already applying successfully. The change is framed as enabling better retention/use of model “thinking” traces in Gemma 4 chat formatting, though no benchmark numbers or implementation diff were provided in the thread. Commenters generally welcomed the official adoption and argued it validates prior community template hacks. Several users speculated that a larger Gemma 4124BMoE release would be needed to fully exploit the updated template for stronger agentic coding use cases.Commenters note that Gemma 4’s official chat template appears to be adding
preserve_thinking, a behavior some users had already enabled via aftermarket/custom template modifications and found effective. The main claimed technical benefit is improved continuity for agentic coding workflows, where retaining prior reasoning/thinking traces can help multi-step tool use and code iteration.One commenter cautions that the change may not be live yet: the
preserve_thinkingsupport is described as an open PR that has not been merged, while the model files reportedly show no update for21 days. This suggests users should verify the tokenizer/chat-template files in the actual model repository before assuming the new behavior is available in released artifacts.Several comments frame the template change as increasing demand for a larger Gemma 4
124BMoE variant, arguing thatpreserve_thinkingwould be more valuable when paired with a higher-capacity model for coding-agent use cases. The discussion is speculative, but technically centered on scaling the model size/MoE architecture to better exploit the updated chat-template behavior.
Less Technical AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Claude Fable 5/Mythos 5 Release and Access Tiers
Introducing Claude Fable 5 (Activity: 2698): The image is a benchmark comparison table for the post’s claimed Claude Fable 5 / Claude Mythos 5 release, showing the highlighted model leading or near-leading across agentic coding, knowledge work, spatial reasoning, tool use, legal, biology, cybersecurity, and health benchmarks versus Claude Mythos Preview, Claude Opus 4.8, GPT 5.5, and Gemini 3.1 Pro. The selftext frames Fable 5 and Mythos 5 as the same underlying “Mythos-class” model, with Fable 5 using safety fallbacks: cybersecurity, biology/chemistry, and distillation-related requests are routed to Claude Opus 4.8, reportedly affecting under
5%of sessions. Comments are mostly hype or skepticism rather than technical analysis, including jokes like “AGI confirmed” and a complaint asking whether “Fable [is] getting dumber recently.”One commenter noted an apparent access/pricing constraint: Claude Fable 5 is free only until
June 22, after which users will reportedly need to purchase credits to continue using it. This is relevant for anyone evaluating the model because benchmark or workflow testing may need to be completed before the credit-gated period begins.
Claude Fable 5 feels less like a model launch and more like a preview of AI inequality (Activity: 2387): The post argues that Anthropic’s alleged Claude Fable 5 rollout represents a shift from a uniform public frontier-model release to a tiered access architecture: public paid users receive Fable 5 with safety routing that may downgrade requests involving
cyber,bio,chemistry, ordistillationto Opus 4.8, while selected partners purportedly get Mythos 5, described as the same underlying model with fewer safeguards. It also highlights pricing/capacity constraints: Fable 5 is said to be included in paid plans only untilJune 22, then potentially moved to usage credits, implying frontier-agent inference remains too expensive for flat-rate consumer subscriptions. Comments split between concern over AI access inequality and acceptance of restrictive safety policies as necessary for high-risk capabilities. One commenter frames the outcome as predictable token-economics pressure toward expensive enterprise-grade models, while another defends a “rather safe than sorry” approach despite user friction.Several commenters framed the launch as an expected economics shift: as frontier models grow in capability and complexity, inference/token costs rise enough that top-tier models become enterprise-only tools rather than default consumer products. One commenter argued this will push everyday workloads toward cheaper local inference on hardware like Apple M-series chips or RTX Spark-class accelerators, reserving frontier APIs for high-value tasks.
A pricing-focused thread claimed that the new model’s API economics make consumer subscriptions structurally mismatched with frontier usage: “Our
$200monthly sub is like3API prompts with the new model.” The implied technical point is that even high-end consumer plans may be viable only through heavy rate limits, model routing, or fallback to cheaper models such as Opus 4.8, which one commenter described as sufficient for “99%” of users.
{kind=link}
Keep reading with a 7-day free trial
Subscribe to Latent.Space to keep reading this post and get 7 days of free access to the full post archives.