

[AINews] Anthropic Claude Opus 4.7 - literally one step better than 4.6 in every dimension
The new SOTA model asserts its dominance.
Thursday mornings are for prestige AI launches, and while OpenAI put in a valiant effort with GPT-Rosalind and The New New Codex (with awesome computer use), there was no question who would win title story today. If you scan past AINews issues closely you would have seen the rumors of this for at least the past week, but today’s Claude Opus 4.7 launch mildly surpassed even those expectations.
The key chart is this one:
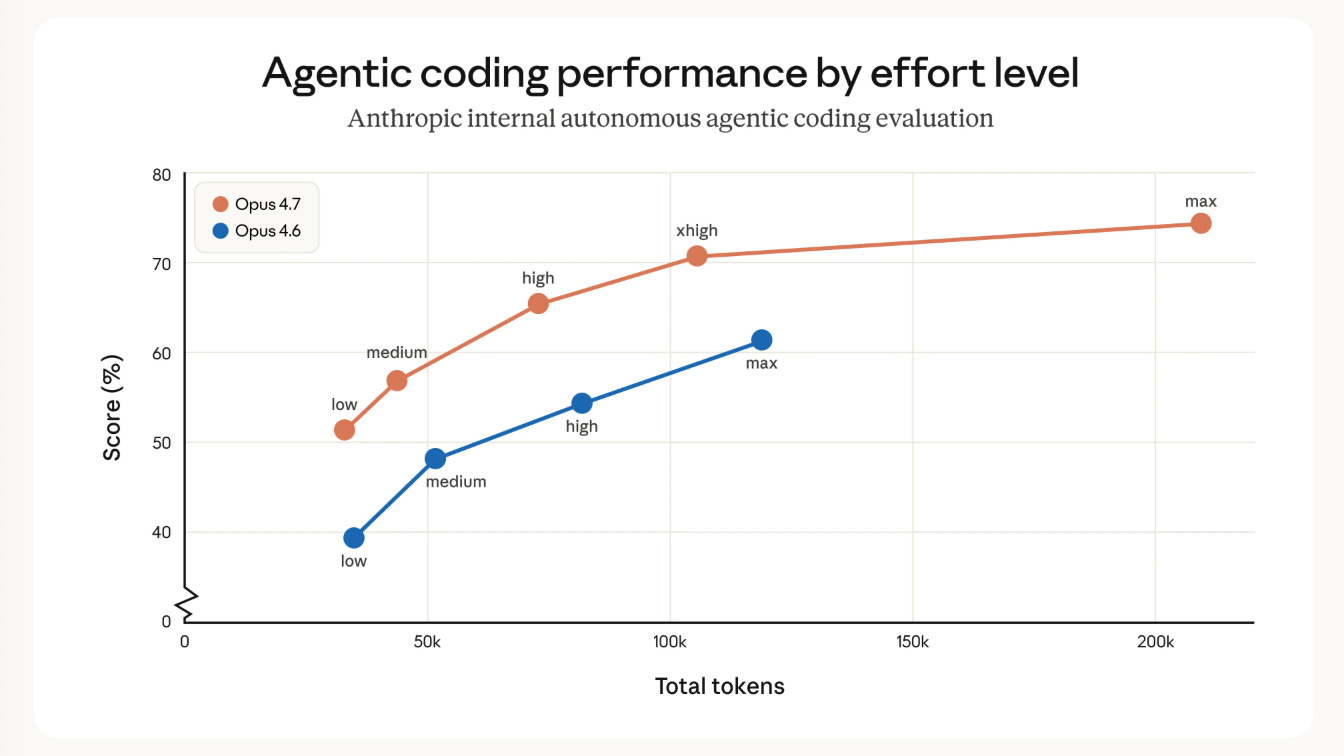
Basically 4.7-low is strictly better than 4.6-medium, 4.7-medium is strictly better than 4.6-high, 4.7-high is now better than 4.6-max, and there is a new xhigh effort level that Claude Code defaults to. While Anthropic says the new tokenizer (new pretrain?) can cause up to 35% more token usage, the overall reasoning efficiency has improved so much that overall token use is STILL down by up to 50% of their former equivalents. The true test is if default Claude Code, now 11 points higher on SWE-Bench Pro, does noticeably better in your own usecases.
The other notable capability that quite literally has to be seen to be believed, is the “substantially better vision”: Opus 4.7 has better vision for high-resolution images: it can accept images up to 2,576 pixels on the long edge (~3.75 megapixels), more than three times as many as prior Claude models. This opens up a wealth of multimodal uses that depend on fine visual detail: computer-use agents reading dense screenshots, data extractions from complex diagrams, and work that needs pixel-perfect references. More details in the focused topic summary below.
AI News for 4/14/2026-4/16/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
Top Story: Claude Opus 4.7
Anthropic officially launched Claude Opus 4.7 as its newest top-tier Opus model, positioning it as better at long-running work, coding, instruction following, self-verification, computer use, and knowledge work than Opus 4.6, while keeping list pricing unchanged at $5 / $25 per million input/output tokens according to user summaries and launch discussion [@claudeai, @kimmonismus]. The release sparked unusually active technical discussion around benchmark gains, a new tokenizer, higher image resolution support, new xhigh reasoning effort, token-cost implications, and whether Opus 4.7 is a straightforward 4.6 successor, a new base model, or a partially distilled “Mythos-adjacent” system.
Release details and product changes
Official framing. Anthropic’s launch pitch emphasized three behavioral improvements: better handling of long-running tasks, more precise instruction following, and stronger self-verification before responding [@claudeai].
Availability.
Claude platform / app reported live immediately [@dejavucoder].
Claude Code shipped day-one support and set
xhighas the default effort level [@_catwu, @_catwu].Anthropic also launched or highlighted task budgets in public beta,
/ultrareviewin Claude Code, and broader Auto mode access for Claude Code Max users [@kimmonismus].
New effort tier.
Multiple users noted a new
xhighreasoning effort mode, positioned betweenhighandmax[@scaling01, @scaling01].Cat Wu said Claude Code now defaults to
xhighfor Opus 4.7 [@_catwu].
Vision/computer use changes.
User summaries reported support for images up to 2,576 px on the long edge (~3.75 MP), described as 3x larger than previous Claude image inputs [@kimmonismus].
Anthropic employee Alex Albert highlighted “No more downscaling of high-res images” and better output taste in UI/slides/docs [@alexalbert__].
This was repeatedly linked to better computer use and screenshot-heavy workflows [@dejavucoder, @omarsar0].
Tokenizer and token economics.
Several observers discovered Opus 4.7 uses a different tokenizer from 4.6 [@natolambert, @nrehiew_].
Kimmonismus summarized Anthropic’s caveat that the same input can map to 1.0–1.35x more tokens depending on content type [@kimmonismus].
This triggered debate over whether 4.7 is effectively a new base model, a tokenizer-swapped continuation, or some kind of midtraining/distillation bridge from Mythos [@natolambert, @stochasticchasm, @eliebakouch, @maximelabonne].
Anthropic employee Boris Cherny later said they increased limits for all subscribers to offset increased token use [@bcherny, @bcherny].
Benchmarks and measurable progress
Reported benchmark gains vs Opus 4.6
The most cited launch numbers came from benchmark screenshots and summaries shared by external accounts:
SWE-bench Pro: 64.3%, with users citing roughly +11 points over Opus 4.6 [@scaling01, @kimmonismus]
SWE-bench Verified: 87.6%, roughly +7 points vs 4.6 [@scaling01, @scaling01]
TerminalBench 2.0: 69.4%, around +4 points [@scaling01, @kimmonismus]
Document reasoning: 80.6%, up from 57.1% per third-party discussion [@scaling01, @llama_index]
GDPval-AA: 1753 Elo [@scaling01, @ArtificialAnlys]
ARC-AGI-1: 92%; ARC-AGI-2: 75.83% per [@scaling01]
Artificial Analysis said Opus 4.7 launched as the new #1 on GDPval-AA, with an implied ~60% head-to-head win rate vs GPT-5.4 on that task set [@ArtificialAnlys].
Anthropic increased subscriber limits to compensate for greater token usage [@bcherny, @bcherny].
Anthropic acknowledges benchmark tradeoffs and retained MRCR in the system card “for scientific honesty,” while signaling a shift toward Graphwalks as a preferred long-context metric [@bcherny].
Vals AI said Opus 4.7 took the #1 spot on the Vals Index at 71.4%, up from a previous best 67.7%, and also ranked #1 on Vibe Code Bench, Vals Multimodal, Finance Agent, Mortgage Tax, SAGE, SWE-Bench, and Terminal Bench 2 [@ValsAI].
They separately said Opus 4.7 became #1 on Vibe Code Benchmark at 71%, versus no model above 25% when they first launched the benchmark 4.5 months earlier [@ValsAI].
Product/evals from partners and customers
Cursor said its internal benchmark jumped from 58% to 70% with Opus 4.7 [@cursor_ai, @scaling01].
A separate Cursor post said, across 500 teams, developers are tackling 68% more high-complexity tasks this year, though that was about better models generally, not solely Opus 4.7 [@cursor_ai].
Notion reportedly saw a 14% lift on internal evals with one-third of tool errors [@mikeyk].
GitHub reportedly saw similar improvements, though no hard numbers were included in the tweet thread [@scaling01].
Document understanding: progress, but mixed economics
LlamaIndex and Jerry Liu provided useful independent nuance:
LlamaIndex’s ParseBench-style comparison said Opus 4.7 massively improved charts (13.5% → 55.8%) but only slightly improved formatting (64.2% → 69.4%), content (89.7% → 90.3%), tables (86.5% → 87.2%), and regressed on layout (16.5% → 14.0%) [@llama_index].
Jerry Liu separately said Opus 4.7 is “quite good at tables,” better on charts, and strongest on content faithfulness, but expensive for OCR-like use at ~7¢/page vs their agentic mode at ~1.25¢/page and cost-effective mode around ~0.4¢/page [@jerryjliu0].
This is one of the clearest examples of independent evaluation tempering launch optimism: broad capability improved, but specific enterprise document pipelines may still prefer specialized stacks on cost/performance grounds.
Opinions / interpretations
“This is a distilled version of Mythos” [@eliebakouch].
“This is a new base model because the tokenizer changed” [@natolambert].
“Anthropic artificially kept cyber scores low during training” is partly factual insofar as users quote the system card language about differentially reducing some capabilities, but broader claims about “nerfed Mythos” are interpretation [@scaling01, @Yuchenj_UW].
“Benchmarks don’t do it justice” and “actual usage is massively improved” are subjective but widely repeated by hands-on users [@mweinbach, @jeremyphoward].
“System prompt has lobotomized the model” is a user complaint about behavior changes, not an established fact [@theo].
Different perspectives
Supportive: meaningful real-world upgrade
A large portion of technical users argued this is a substantial iteration, especially given more frequent release cadence.
Scaling01 repeatedly pushed back on “mid update” takes, noting the jump from around 80% to almost 90% on SWE-bench Verified and emphasizing this would have looked huge in prior release cycles [@scaling01, @scaling01, @scaling01].
Alex Albert highlighted better async work, more predictable effort levels, better image handling, and stronger taste in UI/docs [@alexalbert__].
Michael Weinbach said after just two prompts that behavior and instruction following were “pretty massive” improvements [@mweinbach].
Jeremy Howard said it was the first model that “gets” what he’s doing and praised its willingness to discuss rather than bulldoze ahead [@jeremyphoward, @jeremyphoward].
Cat Wu explicitly advised users to treat it like an engineer you delegate to, not a pair programmer you micromanage, suggesting Anthropic sees it as stronger in autonomous execution [@_catwu].
Neutral / analytical: strong update with tradeoffs
Some of the best commentary was technical and mixed.
Kimmonismus called it a “solid upgrade” focused on Anthropic’s core buyer priorities: agentic coding reliability, vision for computer-use agents, and knowledge work—but also “obviously shy to Mythos” [@kimmonismus].
Artificial Analysis validated the GDPval-AA gain and #1 ranking, but did not frame it as an across-the-board blowout [@ArtificialAnlys].
LlamaIndex and ParseBench results suggested noticeable but uneven document gains with real pricing constraints [@llama_index, @jerryjliu0].
Skeptical / critical: regressions, token inflation, and UX concerns
There was also substantial pushback.
Multiple users said long-context performance looked worse, especially on MRCR / needle-in-a-haystack-style metrics [@scaling01, @nrehiew_, @eliebakouch, @kimmonismus].
Anthropic’s Boris Cherny replied that MRCR is being phased out because it overweights distractor-stacking tricks and that Graphwalks is a better applied-reasoning signal; he gave numbers showing Graphwalks 38.7% → 58.6% from 4.6 to 4.7 [@bcherny, @scaling01].
Tokenizer changes led to complaints about Opus becoming a “token guzzler” and potentially raising effective costs despite flat list pricing [@dejavucoder, @madiator].
Yuchen said Claude web only exposed “Adaptive” or non-thinking, with no explicit force-thinking toggle, which for some users made non-coding tasks feel worse in practice [@Yuchenj_UW].
Mikhail Parakhin similarly said first impressions on non-coding replies were “dumber” because he couldn’t force reasoning [@MParakhin].
Theo sharply criticized the new system prompt as “lobotomized,” and later suggested trying the model in T3 Chat “without the lobotomized system prompt” [@theo, @theo].
Safety / governance angle
Scaling01 highlighted a system-card statement that Anthropic experimented with efforts to differentially reduce cyber capabilities during training [@scaling01].
At the same time, users noted Opus 4.7 still scores higher than 4.6 on some exploitation-related evaluations like Firefox shell exploitation, and has prompt-injection robustness close to Mythos [@scaling01, @scaling01].
One user hyperbolically said “Opus is going to be a bioweapon risk at this pace,” reflecting the ongoing tendency to conflate general capability jumps with worst-case misuse narratives [@scaling01].
Claude Code workflow guidance from Anthropic
Cat Wu’s thread is a useful operational signal for engineers:
Delegate, don’t micromanage [@_catwu]
Put full goal + constraints + acceptance criteria up front [@_catwu]
Tell the model how to verify changes; encode testing workflows in
claude.mdor skills [@_catwu]
That strongly suggests Anthropic optimized toward autonomous task loops where explicit validation is central.
Examples of progress in practice
Keep reading with a 7-day free trial
Subscribe to Latent.Space to keep reading this post and get 7 days of free access to the full post archives.