

[AINews] Anthropic-SpaceXai's 300MW/$5B/yr deal for Colossus I, ARR growth is 8000% annualized
And the kingmaker picks a side.
It was Anthropic’s second annual developer event today, and the vibes were immaculate. No big model release, which some (miscalibrated) people were hoping for, but it was mostly the SpaceX partnership announcement (on track to challenge Claude’s biggest launch of all time), 3 new features for Claude Managed Agents, and a recap/reintroduction/celebration of all that has been shipped in the past 6 months:
After Elon signed off on it, possibly strategically just as his lawsuit against OpenAI is in trial, Anthropic is taking over all of Colossus 1 with surprising speed (“in the next few days”) which some estimate to be a roughly $5B/year deal, making xAI a neocloud:
The other big draw was the moderated session with the Amodei siblings, announcing the 80x growth and some commentary on US and Chinese competitors:
The trends Dario is watching:
Tiny Teams: He still thinks 2026 is the year we see a one person billion dollar company. “There is an enormous ability for one person or a tiny set of people to do a set of things that are incredible… Before, if you had an idea or vision there are so many resources you’d have to accumulate for several years in order to make that vision happen, and I think there’s a unique opportunity for single individuals or very tiny teams to do things that are incredible, where we move from the models are writing code, to the models are helping us think of software engineering as a task, to the models are helping us think of how can I build a business or economic unit as a task”.
Multiagents: “starting with a team of smart people in a room and working our way up to a ‘country of geniuses in a datacenter’”
Enterprise Services: “Claude Code helps individuals to be more productive, but we’re increasingly going to help whole teams and organizations be more productive and more than the sum of its parts”.
Bottlenecks: Claude is of course speeding up Claude, but he thinks about Amdahl’s Law - Security, Verifiability - finding the bottlenecks in software engineering and removing them/speeding up the overall process.
The rest of the mainstage sessions included:
Must know Claude Code updates:

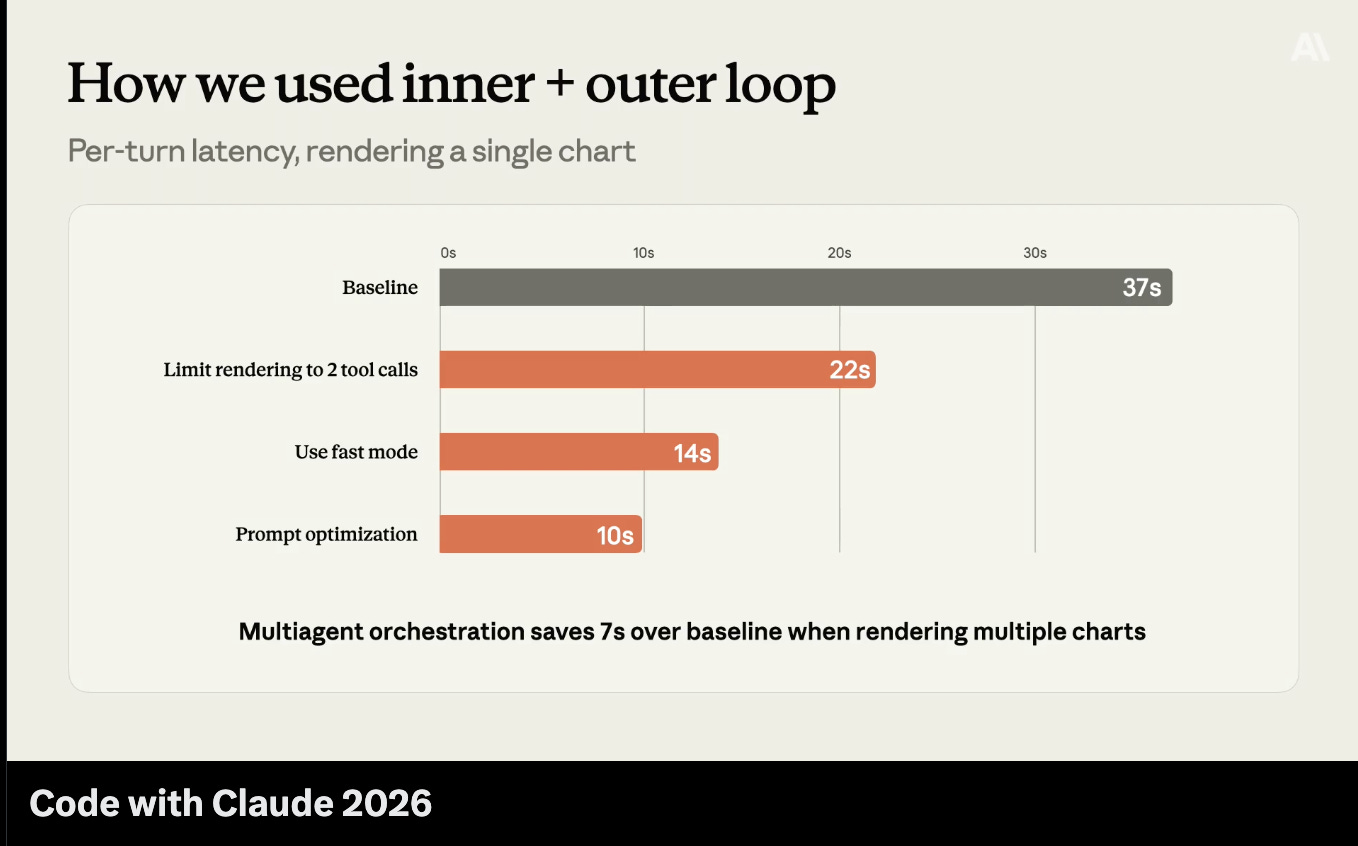
More Outcomes content on the Inner vs the Outer Loop…

… for automatic improvement of agents:
AI News for 5/5/2026-5/6/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
Top Story: Anthropic and Claude announcements/commentary
Anthropic had a dense news cycle centered on compute, Claude Code limits, and agent platform direction.
Officially, Anthropic announced a new compute partnership with SpaceX that will “substantially increase” capacity and immediately translate into higher limits for Claude products: @claudeai said the deal boosts compute enough to raise usage limits, followed by specifics from @claudeai: Claude Code’s 5-hour rate limits are doubled for Pro, Max, Team, and seat-based Enterprise; peak-hours limit reductions are removed for Pro and Max; Opus API rate limits are substantially increased.
xAI framed the deal as Anthropic getting access to Colossus 1 via SpaceXAI for “additional capacity for Claude” @xai, while Anthropic CTO Tom Brown added that Claude inference would be ramped up on Colossus “in the next few days” @nottombrown.
The company also ran its “Code with Claude” event, with a livestreamed keynote and sessions on Claude Code, GitHub-scale usage, and managed agents @ClaudeDevs, prompting substantial real-time commentary from developers and observers @simonw, @latentspacepod.
Around this, discourse branched into four themes:
(1) compute bottlenecks were more severe than many assumed, reportedly due to unexpected usage growth;
(2) users welcomed the 5-hour limit increase but questioned unchanged weekly limits;
(3) people debated whether Anthropic’s new managed-agent features like memory/“Dreaming” and rubrics/“Outcomes” are real product differentiation or commoditizable harness features; and
(4) Anthropic’s safety/governance positioning continued to attract both praise and criticism, including claims from critics that some Anthropic employees project “only we can be trusted with AGI,” and counterclaims from Anthropic-adjacent voices that the more common internal view is closer to “no one can be trusted with AGI” than “only us” @aidan_clark, @kipperrii.
Official facts and confirmed details
Anthropic announced a SpaceX compute partnership to increase capacity @claudeai.
Effective immediately, Anthropic says it is:
Doubling Claude Code’s 5-hour rate limits for Pro, Max, Team, and seat-based Enterprise
Removing peak-hours limit reduction on Claude Code for Pro and Max
Substantially increasing API rate limits for Opus models
Source: @claudeai
Anthropic linked an official explainer on the higher usage limits and the SpaceX compute deal @claudeai.
xAI’s announcement described the arrangement as SpaceXAI providing Anthropic access to Colossus 1 for additional Claude capacity @xai.
Anthropic CTO Tom Brown said Claude inference would start ramping on Colossus within days @nottombrown.
Anthropic product/eng lead Amol Avasare clarified that weekly limits were not increased yet because only a small percentage of users hit weekly limits, while a much larger percentage hit 5-hour limits; more changes may come as compute lands @TheAmolAvasare, @TheAmolAvasare.
Anthropic/Claude held a Code with Claude event with sessions including keynote, Claude Code updates, GitHub-scale usage, and managed agents @ClaudeDevs.
Anthropic’s Alex Albert promoted the event and later summarized the announcement as “More chips, more Claude” @alexalbert__, @alexalbert__.
The dedicated Claude Code account reiterated the limit increase for Pro/Max/Team @claude_code.
Compute details and scale claims
Several tweets added quantitative claims about the scale of the SpaceX/xAI arrangement. These are not from Anthropic’s main announcement tweets, but they were widely circulated:
@arohan cited “more than 300 megawatts of new capacity” and “over 220,000 NVIDIA GPUs within the month.”
@scaling01 claimed Colossus 1 includes ~150,000 H100s, 50,000 H200s, and 30,000 GB200s.
@Yuchenj_UW repeated the 220,000 GPU figure and added an unverified claim that Anthropic had committed $200B on Google TPUs.
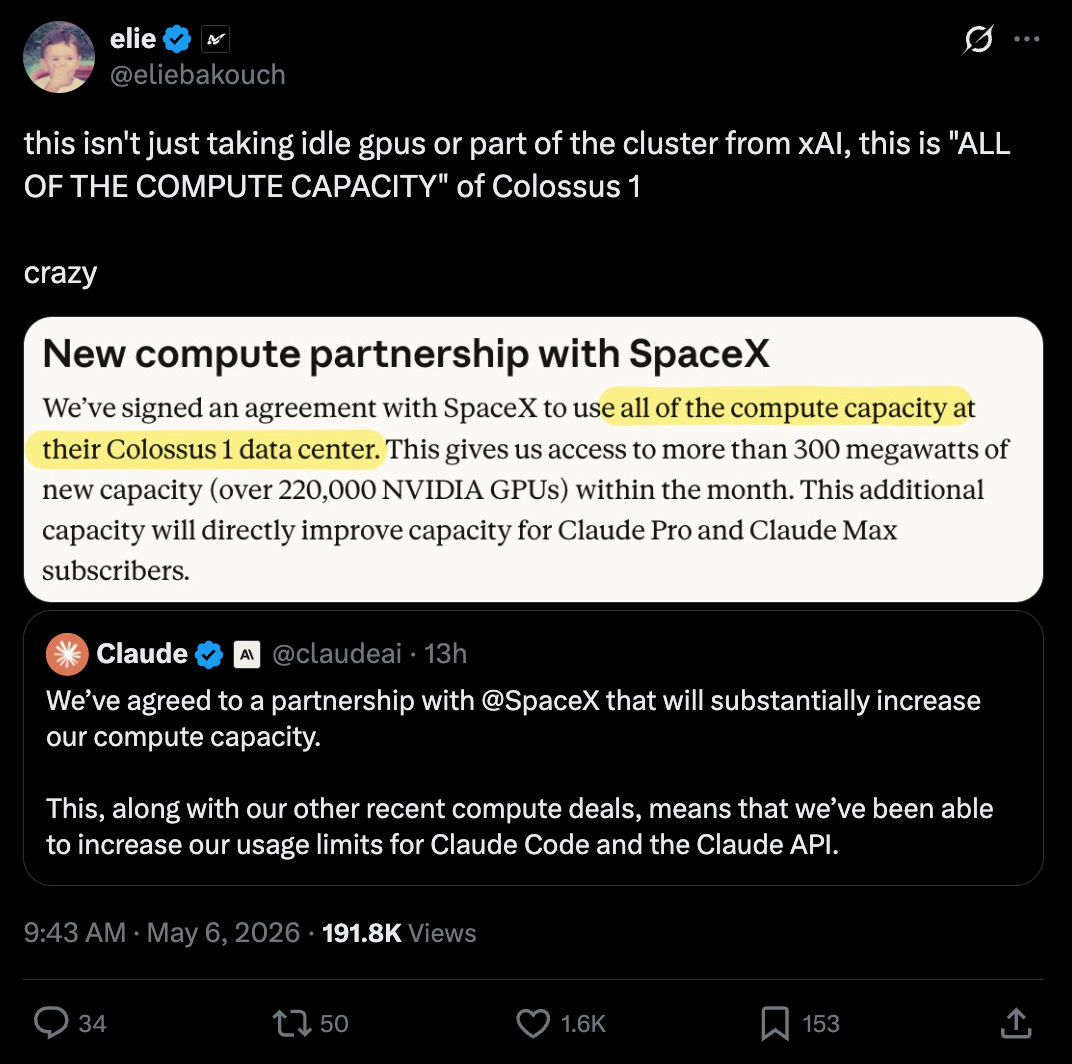
@eliebakouch interpreted the deal as Anthropic getting effectively all of Colossus 1 capacity, not just idle GPUs.
Elon Musk later said SpaceXAI was comfortable leasing Colossus 1 because xAI had already moved training to Colossus 2 @elonmusk, and @eliebakouch claimed Colossus 2 is already at ~500k Blackwells.
These numbers are best treated as partly official-adjacent but not fully canonized in Anthropic’s own announcement thread. The broad factual takeaway is stronger than the exact inventory breakdown: Anthropic secured a very large, near-term external inference capacity expansion.
Evidence the bottleneck was real
A recurring interpretation was that Anthropic’s constraint had genuinely been compute, not merely pricing or product design.
@kimmonismus asked during/after the livestream whether Anthropic was doubling Claude Code rate limits at no extra charge.
@kimmonismus later summarized remarks from a Dario/Daniela interview: usage grew ~80x unexpectedly, which purportedly caused the compute shortage, and the SpaceX deal is the first major attempt to address it.
@czajkadev explicitly interpreted the update as proof that compute was the bottleneck.
@theo separately argued the industry problems are “not just money, it’s about compute,” which fits the Anthropic story even though it’s a broader point.
@scaling01 generalized from this deal to a macro thesis: frontier labs are compute constrained enough to rent datacenters from competitors.
This is one of the strongest factual/market signals in the dataset: Anthropic’s user-facing rate limits moved materially only after a major compute deal.
Product implications: Claude Code, API, and managed agents
Anthropic’s practical user impact is clear:
Claude Code power users get more usable burst capacity over a 5-hour window.
Peak-time throttling is eased for Pro/Max.
Opus API users get higher rate limits, which matters for agent workloads and production integrations.
The event also highlighted Anthropic’s broader platform ambitions around agents. While the primary official tweets here are mostly about the event itself, commentary points to features such as:
Dreaming = memory / cross-session context
Outcomes = rubrics / grading / objective tracking
agent orchestration / managed agents direction
Commentary:
@RichNwan argued Anthropic is “building out their managed agents platform” with Dreaming and Outcomes, but questioned whether these are meaningfully differentiated versus open harnesses.
@eliebakouch saw these as important for power users, especially for preserving the main agent’s context window and using separate graders to manage quality/safety/reward hacking.
@latentspacepod quoted Anthropic speakers emphasizing verification, “routines are higher-order prompts,” and the idea that the remaining gap is often deployment/operationalization, not raw capability.
That last point aligns Anthropic with the broader shift from “one-shot chatbot” to structured agent systems with memory, decomposition, grading, and verification.
Different opinions in the discourse
1) Positive / supportive
A large set of replies treated this as a win for users and evidence Anthropic is responding aggressively.
@alexalbert__: “More chips, more Claude.”
@_sholtodouglas: “More compute -> straight to you.”
@kimmonismus highlighted doubled limits and raised Opus API caps.
@TheRundownAI summarized it as a straightforward user benefit.
@DannyLimanseta liked the cross-company cooperation and hoped Anthropic’s caution might be balanced by SpaceXAI’s optimism.
@AmandaAskell reacted positively to the announcement’s symbolism.
2) Mixed / pragmatic
These takes welcomed the change but focused on operational details and remaining limitations.
@btibor91 and @kimmonismus immediately noted the likely caveat: weekly caps unchanged.
@TheAmolAvasare answered this directly.
@sbmaruf reported still seeing rate limits after the change, implying rollout and reliability tuning were ongoing.
@zachtratar asked for patience during staged rollout.
3) Competitive / strategic critique
A different cluster viewed the announcement through the OpenAI-vs-Anthropic product war.
@scaling01 argued Anthropic blundered its growth advantage by waiting too long, possibly conceding billions in ARR to OpenAI.
@Yuchenj_UW read the move as Dario getting aggressive because of OpenAI Codex’s growth.
@arohan joked that “Big tech has become a claude wrapper,” pointing to Claude’s developer mindshare.
@dejavucoder saying “claude is down, saint tibo please reset codex limits” captured the practical reality of multi-homing among coding tools when one service is capacity constrained.
4) Governance / safety / culture critique
This is the deepest philosophical disagreement.
@aidan_clark criticized what he says he repeatedly hears from Anthropic colleagues: a belief they alone should be trusted to build AI.
@kipperrii partially agreed the “only we can be trusted” framing would be bad, but argued the real majority view is closer to “no one can be trusted with AGI” while still personally trusting Anthropic more than others.
@elonmusk offered a surprising endorsement after meeting Anthropic leaders.
@Yuchenj_UW called this reversal ironic given prior criticism of Anthropic.
@teortaxesTex mocked the rapid détente between Musk/xAI and Anthropic.
@teortaxesTex also argued it is inconsistent to warn others about AI risk while building powerful closed systems such as “Mythos.”
@goodside, while not directly about Anthropic governance, contributed to the broader moral/AI norms debate that often clusters around Anthropic.
Commentary on Claude model performance and comparisons
Though no major new Claude model appears in these tweets, Claude remained a reference point in product and eval discourse.
@giffmana compared “Opus 4.6,” ChatGPT Pro, and Muse Spark on a mathematical disagreement. His take:
Opus 4.6 confidently defended a wrong proof (“gaslit”)
ChatGPT Pro reconciled the formulas correctly but without interpretation
Muse Spark did both well
This is anecdotal, but it’s one of the more concrete comparative qualitative model reports in the set.
@kimmonismus summarized a Substack analysis claiming GPT-5.5 is basically tied with Claude Mythos Preview on cyber, perhaps more cost-efficient, while Mythos is only slightly ahead on some general benchmarks and SWE-bench Pro; he questioned why Mythos remains secretive.
@AssemblyAI noted support for structured JSON from Claude 4.5+ models in its gateway.
@OpenRouter/TencentHunyuan listed Claude Code among major apps driving Hy3 usage, showing Claude’s importance in the coding-tool ecosystem even when third-party models are used behind the scenes.
These comments don’t establish hard model ranking, but they do show Claude is still a primary benchmark in coding-agent workflows and that advanced users increasingly compare model + harness + limits + reliability, not just base intelligence.
Claude Code and harness engineering context
A notable background thread across the dataset is that many engineers now think agent performance is heavily dependent on the harness—system prompts, tools, middleware, decomposition strategies, and model-specific tuning.
Relevant non-Anthropic commentary:
@masondrxy: same model, same task, very different scores depending on prompts/tools/middleware; 10–20 point jumps on tau2-bench.
@LangChain: harness profiles for OpenAI, Anthropic, and Google models.
@jakebroekhuizen: distinguishes temporal harness evolution as models improve from lateral tuning across model families.
@Vtrivedy10: argues a tailored harness can outperform default Codex/Claude Code on many tasks; usable context windows are still effectively 50–100k for many agent designs.
@kieranklaassen: “If you cannot get your work done [in] the Claude CLI, Claude will not be able to work for you.”
This matters because some of Anthropic’s platform moves—memory, grading, managed agents—can be read as Anthropic productizing parts of the harness. That helps explain the central debate: are these defensible platform primitives, or just first-party packaging of patterns that open frameworks can clone?
Broader context: why this matters
Inference, not just training, is now a frontier bottleneck.
The news was not a new model launch; it was a capacity launch. That is increasingly common at the frontier.Compute markets are becoming fluid and strategic.
Anthropic partnering with SpaceX/xAI infrastructure undercuts simplistic narratives that each frontier lab sits only atop its own vertically integrated stack.Developer product share is sensitive to reliability and limits.
Claude appears to have strong developer affinity, but rate limits and outages push users toward Codex/Cursor/others quickly.The battleground is shifting from base models to agent systems.
“Code with Claude,” managed agents, Dreaming, Outcomes, and the surrounding discourse all point toward the next layer of competition being memory, orchestration, evals, and workflow integration.Anthropic’s brand remains bifurcated.
It is simultaneously:admired for product quality and safety seriousness,
criticized for paternalism or perceived exclusivism,
and now seen as more commercially aggressive on compute than before.
Bottom line
Anthropic’s news was less about a flashy new model and more about a structural reality: Claude demand had outrun available compute, and Anthropic responded by striking a major external infrastructure deal and immediately easing key user limits @claudeai, @claudeai. The most important technical/economic signal is that capacity, rate limits, and agent-product ergonomics are now as strategically important as leaderboard deltas. The main open questions are whether Anthropic can convert this capacity into sustained product momentum, whether its managed-agent features are truly differentiated, and whether its safety/governance posture helps or hinders its standing as competition with OpenAI, Google, xAI, and open-model ecosystems intensifies.
Infrastructure, inference, and systems
OpenAI and partners released MRC (Multipath Reliable Connection), an open networking protocol for large AI training clusters, already deployed on OpenAI’s biggest supercomputers @OpenAI, @OpenAI. Commentary emphasized multipath routing, microsecond failover, and the shift of networking into a primary frontier bottleneck @kimmonismus, @gdb.
Perplexity said it built an in-house inference engine, ROSE, covering models from embeddings to trillion-parameter LLMs, and uses CuTeDSL to accelerate specialized kernel development on Hopper and Blackwell @perplexity_ai.
vLLM + Mooncake presented a strong systems result for agentic workloads with reusable prefixes: 3.8x throughput, 46x lower P50 TTFT, 8.6x lower end-to-end latency, and cache-hit improvement from 1.7% to 92.2%, scaling to 60 GB200 GPUs @vllm_project.
Unsloth + NVIDIA published three training optimizations claimed to make home-GPU LLM training ~25% faster: packed-sequence metadata caching, double-buffered checkpoint reloads, and faster MoE routing @UnslothAI.
NVIDIA work on lossless speculative decoding inside RL was highlighted as giving up to ~2.5x faster end-to-end RL at 235B scale and ~1.8x faster rollout throughput at 8B without changing policy distribution @TheTuringPost.
Baseten launched Frontier Gateway as managed infra/API/auth/rate-limit/billing for closed-weight labs; Poolside reported going from kickoff to production in 7 weeks, with P50 TTFT 146ms for Laguna XS.2 and 605ms for Laguna M.1 @tuhinone, @poolsideai.
Benchmarks, evals, and agent harnesses
ProgramBench asks whether language models can rebuild programs from scratch, extending beyond repair-style SWE tasks @ComputerPapers, with Ofir Press arguing benchmarks are “treasure maps” that specify the future we want @OfirPress.
Terminal-Bench 2.1 patched 28/89 tasks in TB2.0; rankings held but absolute scores moved by up to 12 points, a useful reminder that agent benchmark maintenance materially matters @terminalbench, @ekellbuch.
OBLIQ-Bench emerged as a major IR benchmark release focused on hard first-stage retrieval, where current retrievers fail to surface subtly relevant documents from large corpora @dianetc_, with strong endorsements from IR researchers @lateinteraction, @nlp_mit, @LightOnIO.
Harvey launched LAB, an open-source, long-horizon legal agent benchmark covering 1,200 tasks across 24 practice areas, with support/commentary from LangChain, Baseten, Artificial Analysis, and others @saranormous, @ArtificialAnlys.
A major theme across multiple tweets was that harness engineering is a first-class variable, often worth 10–20 points on agent benchmarks even with the same base model @masondrxy, @LangChain, @Vtrivedy10.
Model releases and model performance
Zyphra released ZAYA1-8B, a reasoning MoE with <1B active parameters, open-weight under Apache 2.0, claiming strong math/reasoning efficiency and proximity to much larger systems with test-time compute @ZyphraAI, @ZyphraAI. Commentary praised its architecture/post-training stack and AMD partnership @teortaxesTex, @eliebakouch.
Google’s Gemma 4 moved the open-model Pareto frontier in Code Arena: Gemma-4-31B #13, Gemma-4-26B-A4B #17 among open models @arena, @_philschmid.
Google’s DFlash draft model for Gemma-4 was described as one of the best draft models they’ve trained, especially strong in coding and math @jianchen1799.
Qwopus3.6-35B-A3B-v1 claimed 162 tok/s on a single RTX 5090, targeting strong one-shot frontend/web generation on consumer hardware @KyleHessling1.
DeepSeek commentary was mixed: fundraising talks reportedly target a $45B valuation led by a major Chinese state-backed semiconductor fund @jukan05, while evaluators debated weak WeirdML performance for V4-Pro versus GLM/Kimi/open competitors @htihle, @teortaxesTex.
Agents, tools, and developer workflows
Cursor added context usage breakdowns across rules, skills, MCPs, and subagents to help debug context issues @cursor_ai, and described bootstrapping future Composer generations with earlier Composer models @cursor_ai.
Cognition shipped Devin Review and Quick Review / SWE-Check in Windsurf 2.0, explicitly targeting the new bottleneck of reviewing AI-generated code @cognition, @ypatil125.
OpenAI promoted Codex subagents, framing them as a way to split work across specialized agents and merge results back into one answer @reach_vb.
Nous/Hermes continued to push a highly pluggable local agent stack: plugin expansion, community docs, Windows/WSL2 setup guidance, and use-case aggregation @Teknium, @witcheer, @NousResearch.
Perplexity added Finance Search to its Agent API with licensed data, live market data, and citations, claiming best cohort accuracy and lowest cost per correct answer on FinSearchComp T1 @perplexity_ai, @AravSrinivas.
Google’s Gemini API added multimodal retrieval to File Search using
gemini-embedding-2for PDFs and images in a single retrieval pipeline @_philschmid.
Robotics, multimodality, and research notes
Genesis AI introduced GENE-26.5, describing a full-stack robotics program with a robotics-native foundation model, human-like hand, data glove, and simulator; the model is trained across language, vision, proprioception, tactile, and action @gs_ai_, @theo_gervet.
Meta FAIR released NeuralBench, an MIT-licensed unified benchmark framework for NeuroAI with 36 EEG tasks and 94 datasets, with MEG/fMRI support planned @hubertjbanville, @JeanRemiKing.
Sander Dieleman published a long technical post on flow maps, learning the integral of a diffusion model for faster sampling and related tricks @sedielem.
François Fleuret sketched a speculative recipe for stronger systems: latent diffusion-like reasoning + real recurrent state + world-model pre-pretraining @francoisfleuret, generating useful discussion on whether diffusion-style reasoning extrapolates the right way @willdepue, @jeremyphoward.
HeadVis was introduced as a new interpretability tool for studying attention heads @kamath_harish.
Microsoft Research work on agent-readable interpretability proposed “Agentic-imodels,” where coding agents evolve models that are interpretable to other LLMs; reported gains on 65 tabular datasets and downstream BLADE improvements from 8% to 73% @dair_ai.
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
Keep reading with a 7-day free trial
Subscribe to Latent.Space to keep reading this post and get 7 days of free access to the full post archives.