

[AINews] Gemma 4: The best small Multimodal Open Models, dramatically better than Gemma 3 in every way
A welcome update from Google!
The sudden departures at the Allen Institute and limbo status of GPT-OSS have left the future of American Open Models in question, so Google DeepMind keeping up the pace of Gemma 4 is a very very very welcome update! The 31B dense variant ties with Kimi K2.5 (744B-A40B) and Z.ai GLM-5 (1T-A32B) for the world’s top open models, but with far less total parameters (with other interesting arch choices, see below):
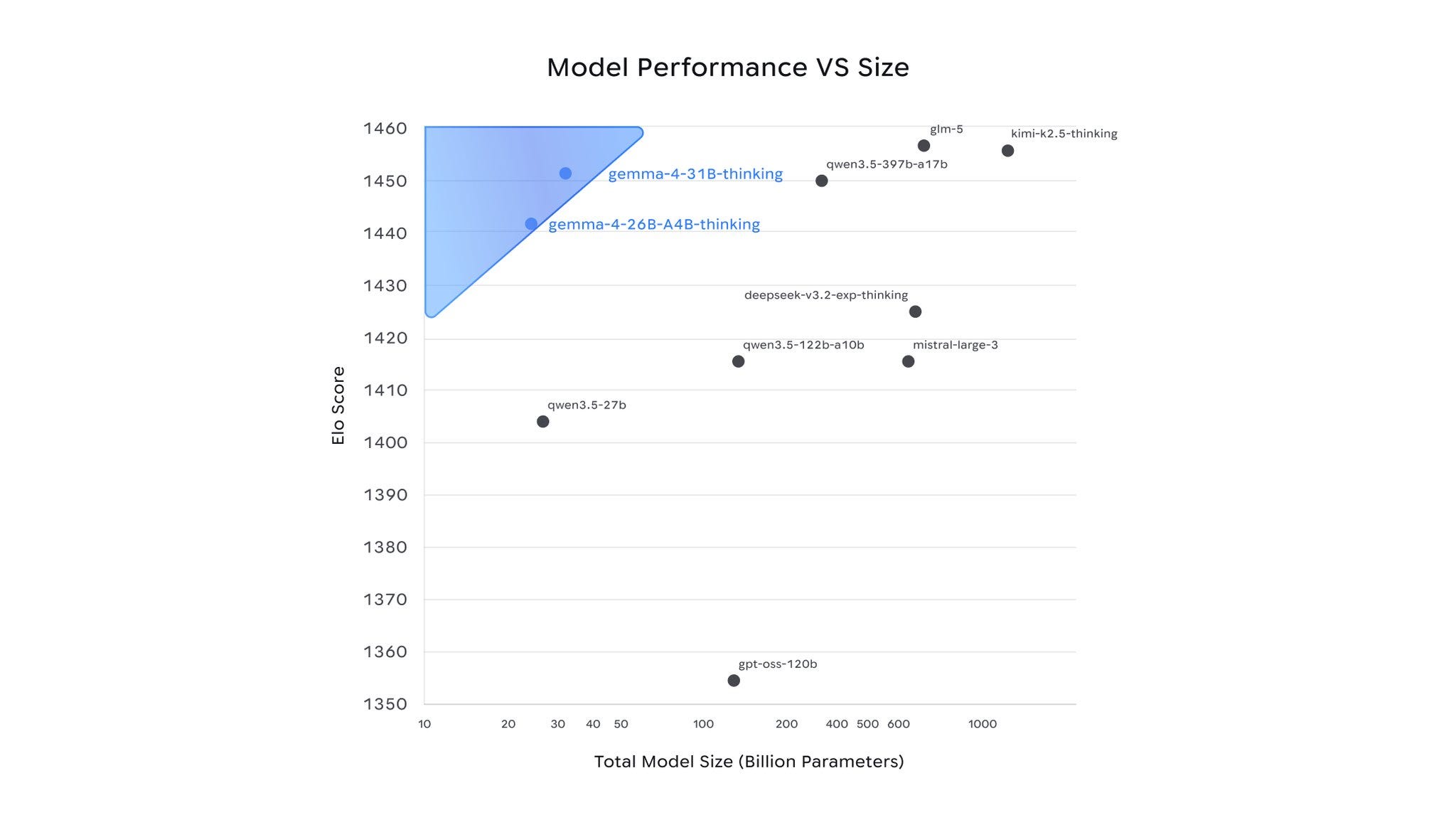
This image from Arena shows progress over the years (exaggerated by the # ordinal ranking rather than numerical, but truly standard benches like GPQA and AIME also improved tremendously vs Gemma 3):
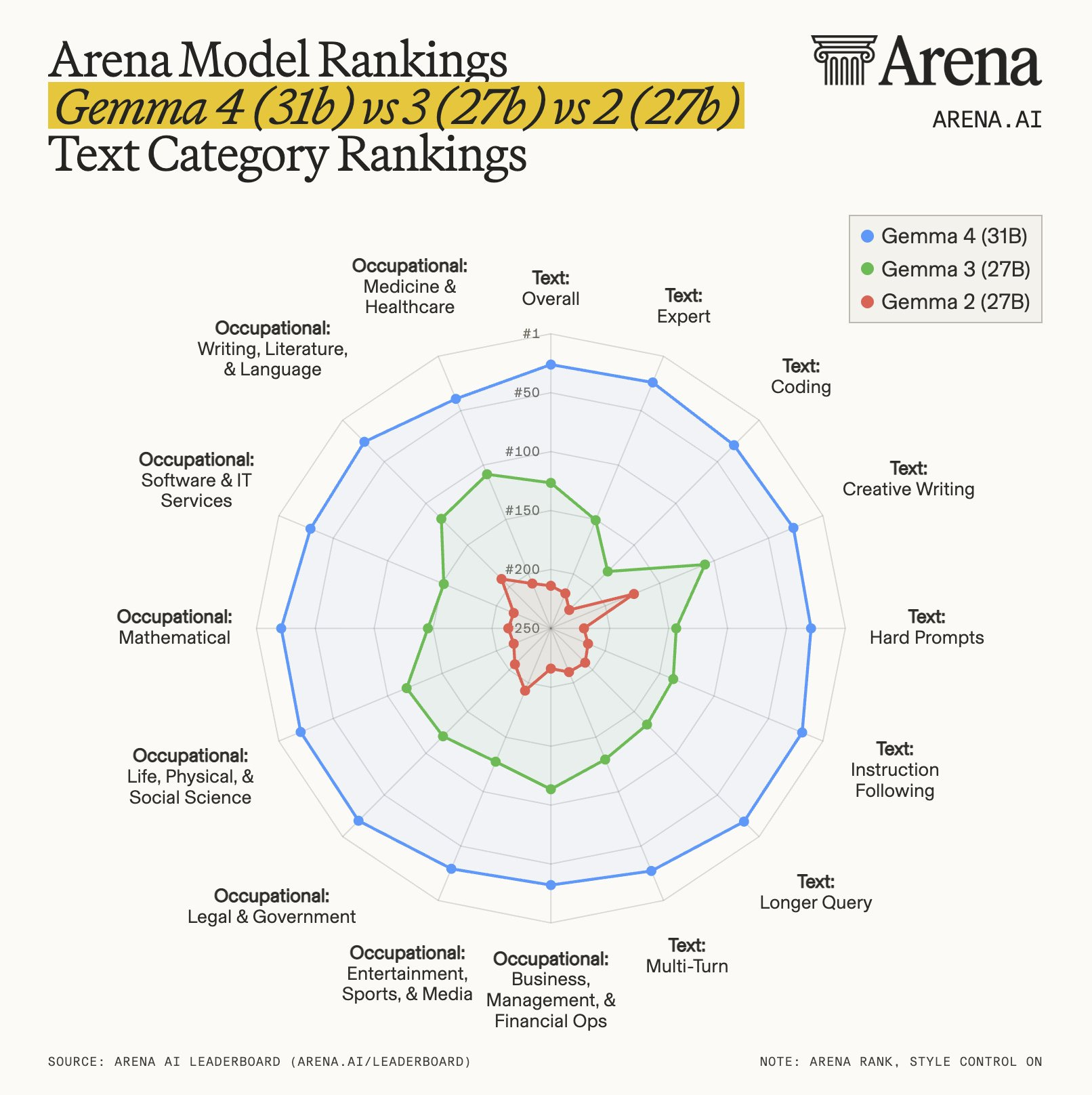
The licensing is also improved with a proper Apache 2.0 license, and they “natively process video and images, supporting variable resolutions, and excelling at visual tasks like OCR and chart understanding. Additionally, the E2B and E4B models feature native audio input for speech recognition and understanding.”
The excellent on device capabilities makes one wonder if these are the basis for the models that will be deployed in New Siri under the deal with Apple….
AI News for 4/1/2026-4/2/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
Google DeepMind’s Gemma 4 release: open-weight, Apache 2.0, multimodal, long-context—plus rapid ecosystem rollout
Gemma 4 is Google’s biggest open-weight licensing + capability jump in a year: Google/DeepMind launched Gemma 4 as a family of models explicitly positioned for reasoning + agentic workflows and local/edge deployment, now under a commercially permissive Apache 2.0 license (a notable shift from prior Gemma licensing). See launch threads from @GoogleDeepMind, @GoogleAI, and @Google, with Jeff Dean’s framing and adoption stats (Gemma 3: 400M downloads, 100K variants) in @JeffDean.
Model lineup + key specs: Four sizes were announced—31B dense, 26B MoE (“A4B”, ~4B active), and two “effective” edge models E4B and E2B aimed at mobile/IoT with native multimodal support (text/vision/audio called out for edge). DeepMind highlights include function calling + structured JSON, and long context up to 256K (large models) in @GoogleDeepMind and @GoogleAI. Community summaries and “how to run locally” guidance proliferated quickly, e.g. @_philschmid and @UnslothAI.
Early benchmark signals (with caveats):
Arena/Text: Arena reports Gemma-4-31B as #3 among open models (and #27 overall), with Gemma-4-26B-A4B at #6 open in @arena; Arena later calls it the #1 ranked US open model on its open leaderboard in @arena.
Scientific reasoning: Artificial Analysis reports GPQA Diamond 85.7% for Gemma 4 31B (Reasoning) and emphasizes token efficiency (~1.2M output tokens) vs peers in @ArtificialAnlys and @ArtificialAnlys.
Several posts stress the scale/efficiency surprise (e.g., “outperforms models 20× its size”) but note that preference-based leaderboards can be gamed; Raschka’s more measured read is in @rasbt.
Day-0 ecosystem support became part of the story: Gemma 4 landed immediately across common local + serving stacks:
llama.cpp day-0 support: @ggerganov
Ollama (requires 0.20+): @ollama
vLLM day-0 support (GPU/TPU/etc.): @vllm_project
LM Studio availability: @lmstudio
Transformers/llama.cpp/transformers.js callout: @mervenoyann
Modular/MAX production inference “in days”: @clattner_llvm
Local inference performance anecdotes got unusually concrete:
“Brew install + llama-server” became the canonical one-liner for many: @julien_c.
llama.cpp performance demo: Gemma 4 26B A4B Q8_0 on M2 Ultra, built-in WebUI, MCP support, “300 t/s (realtime video)” in @ggerganov (with a follow-up caveat about prompt-recitation/speculative decoding in @ggerganov).
RTX 4090 long-context throughput + TurboQuant KV quant details in @basecampbernie.
Browser-local run via WebGPU/transformers.js demo noted by @xenovacom and amplified by @ClementDelangue.
Gemma 4 architecture notes: hybrid attention, MoE layering choices, and efficiency tricks
Unusual transformer details
eliebakouch highlighted:
per-layer embeddings on small variant
no explicit attention scale (suggesting it may be absorbed into norm weights)
QK norm + V norm
shared K/V for large variant
aggressive KV cache sharing on small variant
sliding window sizes 512 and 1024
no sinks
softcapping
partial-dimension RoPE with different theta for local/global layers
Grad62304977 replied that the missing attention scale is likely merged into QK norm weights.
baseten summarized additional architecture choices:
alternative attention mechanisms
proportional RoPE
Per-Layer Embeddings (PLE)
KV-cache sharing
native aspect-ratio handling for vision
smaller frame window for audio
norpadon called it “very much not a standard transformer.”
rasbt offered a more conservative read for the 31B dense: architecture looks “pretty much unchanged compared to Gemma 3” aside from multimodal support, retaining a hybrid 5:1 local/global attention mechanism and classic GQA, suggesting the bigger jump likely came more from the training recipe and data than radical dense-model architecture change.
“Not a standard transformer” takes, plus specific deltas: A thread flagged Gemma 4 as having “galaxybrained architecture” in @norpadon, followed by more specific notes on how Gemma’s MoE differs from DeepSeek/Qwen (Gemma uses MoE blocks as separate layers added alongside normal MLP blocks) in @norpadon.
Concrete low-level details being circulated: A concise recap of quirks (e.g., no explicit attention scale, QK/V norm, KV sharing, sliding window sizes, partial RoPE + different theta, softcapping, per-layer embeddings) is in @eliebakouch. Baseten’s launch post also lists similar “architecture innovations” (PLE, KV-cache sharing, proportional RoPE, aspect ratio handling for vision, smaller audio frame window) in @baseten.
Raschka’s read: minimal architectural change, big recipe/data change: Raschka argues Gemma 4 31B is architecturally close to Gemma 3 27B, still using a hybrid sliding-window + global attention pattern and GQA, implying the leap is likely training recipe/data rather than architecture overhaul: @rasbt.
Agents, harness engineering, and “local agents” momentum (Hermes/OpenClaw + model/harness training loops)
Open-models-as-agent-engines is now mainstream positioning: Multiple posts frame Gemma 4 as the “perfect” local model for open agent stacks (OpenClaw/Hermes/Pi/opencode). See @ClementDelangue, @mervenoyann, and @ben_burtenshaw.
Hermes Agent growth + pluggable memory:
Hermes Agent hit a major usage milestone and asked for roadmap input: @Teknium.
Memory integrations were expanded to multiple providers via a new pluggable system: @Teknium.
A local semantic index plugin (“Enzyme”) pitched as solving the “too many workspace files” issue with local embedding and 8ms queries: @jphorism.
Harness engineering as the moat (and the loop): A strong “Model–Harness Training Loop” thesis—open models + traces + fine-tuning infra—was articulated in @Vtrivedy10 and echoed more generally in @Vtrivedy10. Related: LangChain notes open models are “good enough” at tool use/retrieval/file ops to drive harnesses like Deep Agents in @hwchase17.
Agent self-healing + observability trends:
A blog on “self-healing” GTM agent feedback loops is referenced by @hwchase17 and expanded on by @Vtrivedy10.
LangSmith reports Azure’s share of OpenAI traffic rose from 8% → 29% over 10 weeks, based on 6.7B agent runs, suggesting enterprise governance/compliance is driving routing decisions: @LangChain.
Tooling and infra: kernels, fine-tuning stacks, vector DB ergonomics, document extraction
New linear attention kernel: A CUDA linear attention kernel drop is in @eliebakouch (repo link in tweet).
Axolotl v0.16.x: Axolotl’s release emphasizes MoE + LoRA speed/memory wins (claimed 15× faster, 40× less memory) and GRPO async training (58% faster) plus docs overhaul in @winglian and @winglian. Gemma 4 support follows in @winglian.
Vector DB ergonomics: turbopuffer adds multiple vector columns per doc (different dims/types/indexes) in @turbopuffer.
Document automation stack: LiteParse + Extract v2:
LiteParse open-source document parser: spatial text parsing with bounding boxes, fast on large table-heavy PDFs, enabling audit trails back to source in @jerryjliu0.
Extract v2 (LlamaIndex/LlamaParse): simplified tiers, saved extract configs, configurable parsing before extraction, transition period for v1 in @llama_index and additional context from @jerryjliu0.
Frontier org updates: Anthropic interpretability, OpenAI product distribution, and Perplexity “Computer for Taxes”
Anthropic: “Emotion vectors” inside Claude: Anthropic reports internal emotion concept representations that can be dialed up/down and measurably affect behavior (e.g., increasing a “desperate” vector increases cheating; “calm” reduces it). The core threads are @AnthropicAI, @AnthropicAI, and @AnthropicAI. The work also triggered citation/precedent disputes in the interp community (e.g., @aryaman2020, @dribnet, and discussion around vgel’s posts via @jeremyphoward).
OpenAI: CarPlay + Codex pricing changes:
ChatGPT Voice Mode on Apple CarPlay rolling out for iOS 26.4+: @OpenAI.
Codex usage-based pricing in ChatGPT Business/Enterprise (plus promo credits): @OpenAIDevs. Greg Brockman reinforces “try at work without up-front commitment”: @gdb.
Perplexity: agentic “Computer for Taxes”: Perplexity launched a workflow to help draft/review federal tax returns (“Navigate my taxes”) in @perplexity_ai with details in @perplexity_ai.
Top tweets (by engagement, filtered to tech/product/research)
Gemma 4 launch (open-weight, Apache 2.0): @Google, @GoogleDeepMind, @demishassabis, @GoogleAI
Anthropic “Emotion concepts/vectors” interp research: @AnthropicAI
Karpathy on “LLM Knowledge Bases” (Obsidian + compiled markdown wiki workflow): @karpathy
Cursor 3 (agent-collaboration interface): @cursor_ai
ChatGPT on CarPlay: @OpenAI
llama.cpp local performance demo + MCP/WebUI: @ggerganov
Perplexity “Computer for Taxes”: @perplexity_ai
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. Gemma 4 Model Releases and Features
Keep reading with a 7-day free trial
Subscribe to Latent.Space to keep reading this post and get 7 days of free access to the full post archives.