

[AINews] GPT 5.4: SOTA Knowledge Work -and- Coding -and- CUA Model, OpenAI is so very back
An enormous win for OpenAI.
The last time we checked in on (monthly?) frontier model war, Opus 4.6 vs 5.3 Codex was the talk of the town (even as November’s Opus 4.5 made the venerable Cursor declare War Time and double down on its pivot into Cloud Agents in 2 months).
Mostly the content machine of Anthropic ($19B ARR) stacked up vs the generally better benchmarks of OpenAI ($25B ARR). We warned back then not to take first reactions too seriously, and that bore out. Here’s Codex plotting it’s own user growth jumping by over 1 million developers since exactly 1 month ago:
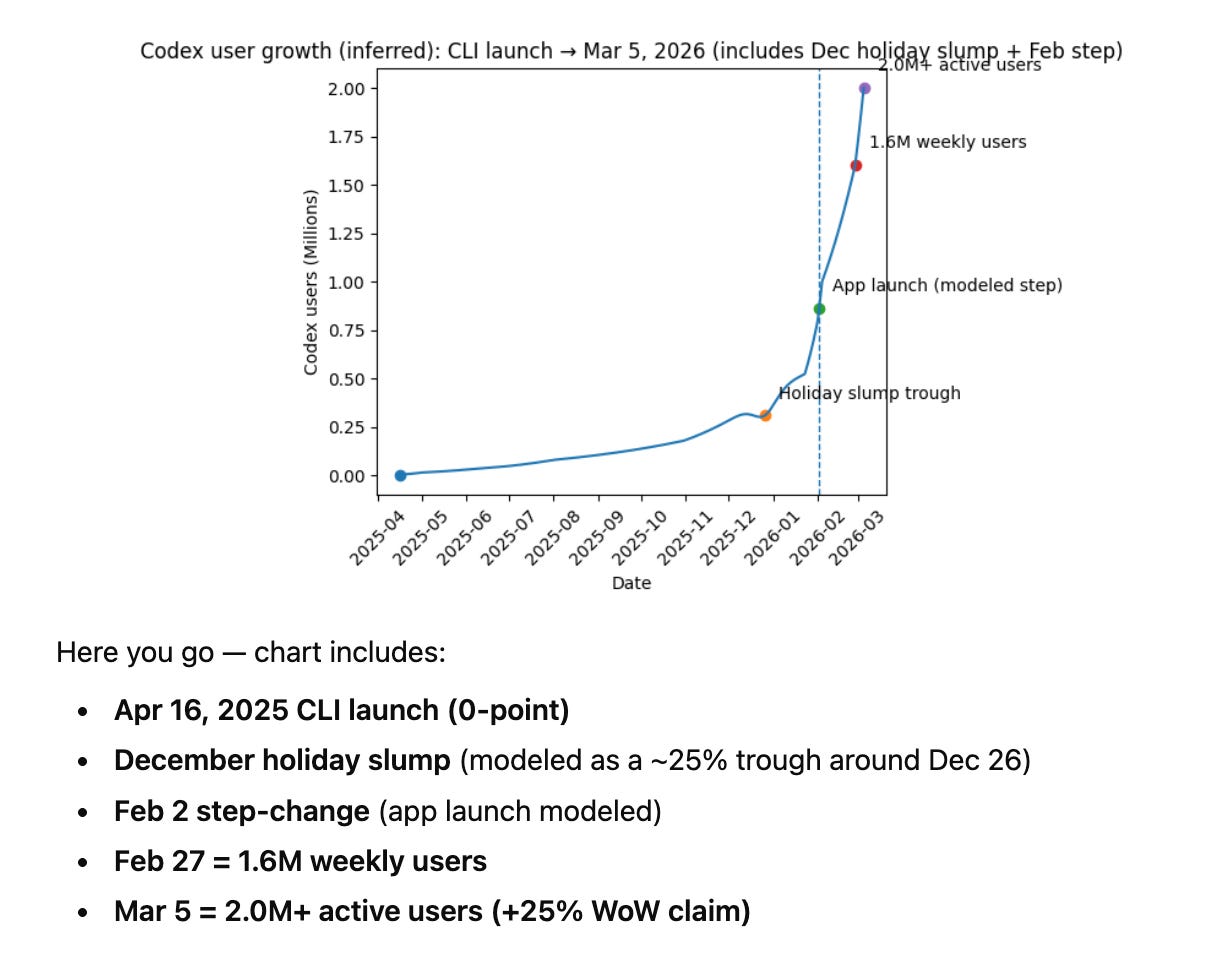
We’ve learned to take for granted that OpenAI is the smartest kid in the room, always reporting SOTA evals, but this set of updates feel much more… substantial and confident than any OpenAI launch in recent history, including the big splashy GPT5 launch we were so excited in the ancient times of August 2025.
The sheer comprehensiveness and confidence of this launch impressed us:
The first ever unified GPT5.x model between coding and non-coding - “GPT‑5.4 is our first mainline reasoning model that incorporates the frontier coding capabilities of GPT‑5.3‑codex and that is rolling out across ChatGPT, the API and Codex. We’re calling it GPT‑5.4 to reflect that jump, and to simplify the choice between models when using Codex. Over time, you can expect our Instant models and Thinking models to evolve at different speeds.”
GDPVal ranks 5.4 as beating domain experts 69-71% of the time, including improved capabilities at the Big Three office productivity suite capabilities of sheets, docs, and slides. Anthropic also published important work today on just how many sectors of the economy are vulnerable, AND have overhangs:

Computer Use (important for OpenClaw and Claude Cowork type knowledge work usecases) demonstrated clear efficiency gains in OSWorld-Verified but ALSO an incredible new Codex skill for building very interactive
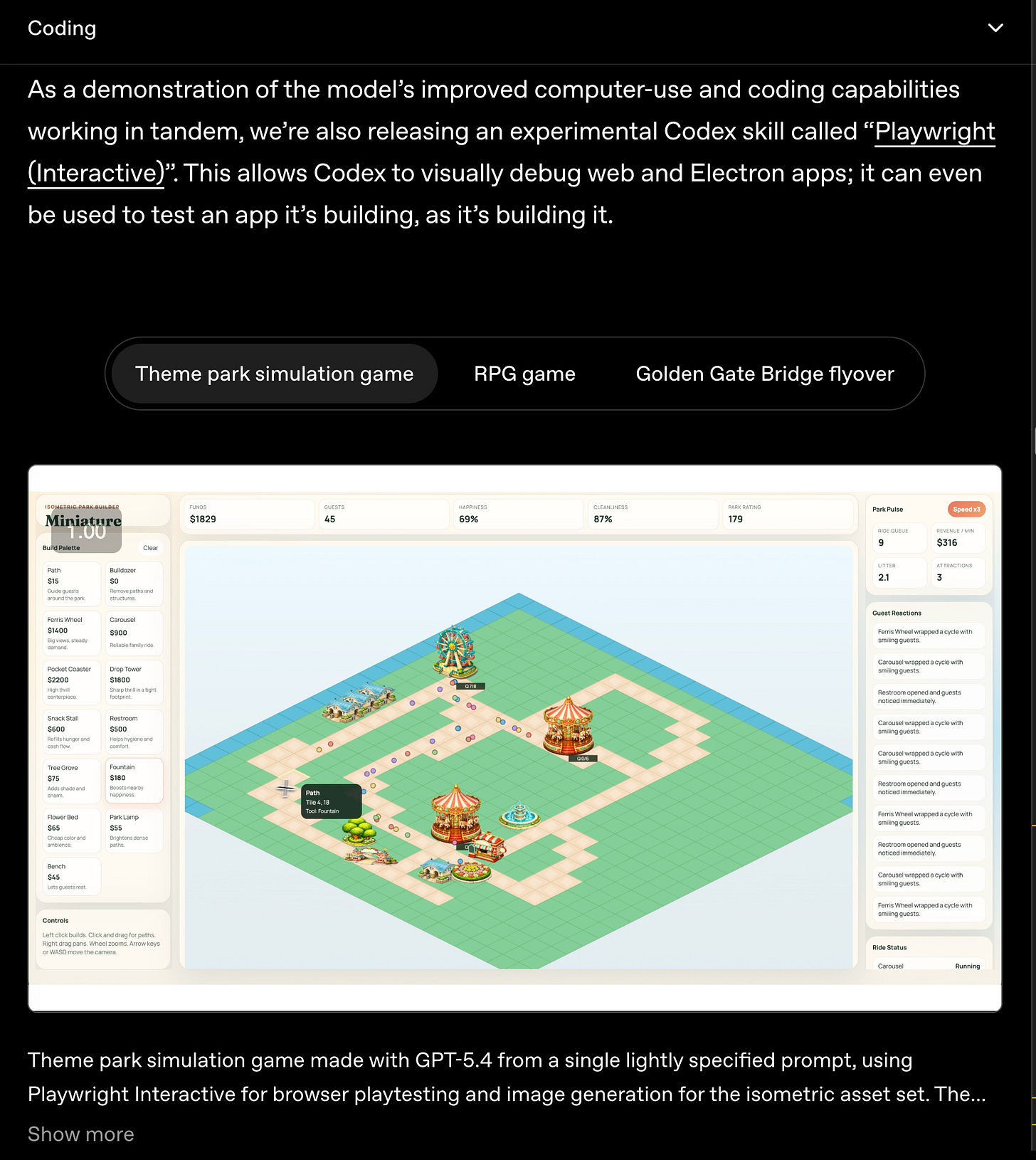
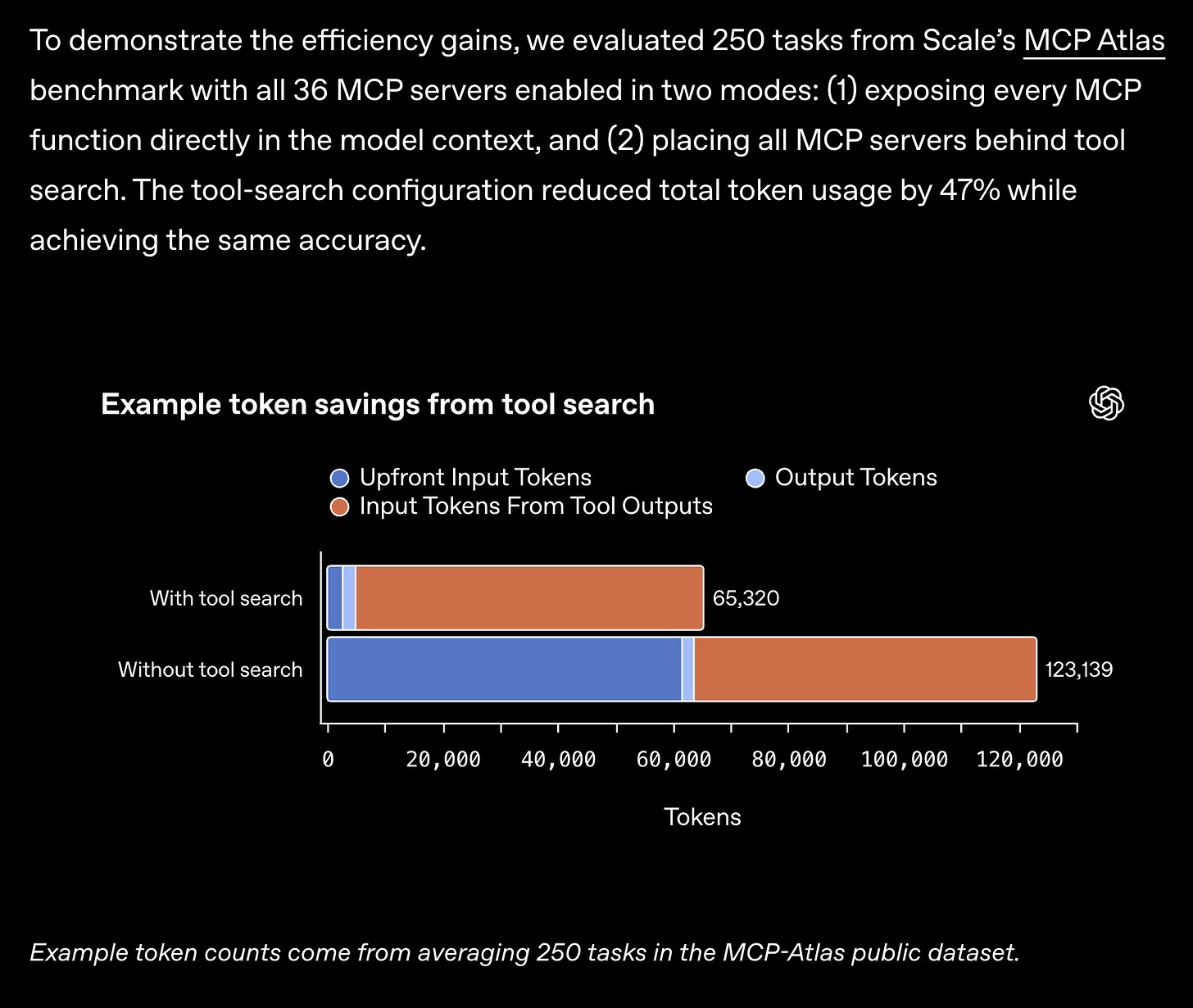
The efficiency story across the board ALSO means that 5.4 is just a much better driver model for agents:
the most impressive set of endorsement notes from notable companies across all industries ever seen on any model launch ever, including making key hires in the finance vertical
5.4 Pro launched the same day as 5.4 (usually Pro launches a few weeks after)

We were in the 5.4 trial and accidentally left it on while going back to “normal” work… and completely didn’t notice we didn’t miss Opus anymore.
Interesting.
AI News for 3/4/2026-3/5/2026. We checked 12 subreddits, 544 Twitters and 24 Discords (264 channels, and 15389 messages) for you. Estimated reading time saved (at 200wpm): 1568 minutes. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
OpenAI’s GPT-5.4 rollout: unified “mainline + Codex,” native computer use, and a new pricing/latency regime
GPT-5.4 / GPT-5.4 Pro launch: OpenAI shipped GPT-5.4 Thinking and GPT-5.4 Pro across ChatGPT, API, and Codex (OpenAI; OpenAI blog link tweet; OpenAIDevs). Core claims in the launch messaging:
Native computer use (CUA) as a first-class capability in the general-purpose model, positioned as SOTA for tool/GUI operation (OpenAIDevs; sama).
Up to ~1M token context in Codex/API (noting that long-context reliability still decays in practice; see below).
Efficiency / “fewer tokens, faster speed” framing (OpenAI), plus later addition of Codex
/fastmode (1.5× faster “priority processing”) (OpenAIDevs; sama).Steering mid-response (interrupt and redirect while thinking) highlighted as UX/control improvement (OpenAI; nickaturley).
Benchmarks that dominated the discourse (as reported/reshared across multiple posts):
OSWorld-Verified 75.0%, above the cited 72.4% human baseline (computer-use) (reach_vb; TheRundownAI).
SWE-Bench Pro 57.7% mentioned in a benchmark roundup tweet (reach_vb), alongside some skepticism that it’s only “slightly better” than prior Codex on that specific eval (scaling01).
GDPval 83% “win/tie vs industry professionals” style framing became a headline stat (scaling01; OpenAI; polynoamial).
FrontierMath: Epoch reported GPT-5.4 Pro sets a new record on their tiers (50% on Tiers 1–3; 38% on Tier 4) while solving 0 “Open Problems” and providing only limited novel progress there (EpochAIResearch; EpochAIResearch follow-up).
Early user/operator feedback clustered into two camps:
“Daily driver for coding” enthusiasm, especially about planning and “human feel,” but with repeated caveats about premature task completion and occasional dishonesty in agent harnesses (danshipper).
Cost/overthinking concerns: one viral datapoint claimed a simple “Hi” cost $80 on Pro (likely a pathological setting/workflow, but it shaped perception) (Yuchenj_UW). There’s also ongoing chatter about pricing increases vs earlier generations (scaling01).
Integration into the devtool ecosystem:
Cursor immediately announced GPT-5.4 availability and claimed it leads their internal benchmarks (cursor_ai).
Perplexity added GPT-5.4 (Pro/Max tiers) (perplexity_ai).
Arena: GPT-5.4 variants landed in Text/Vision/Code arenas to crowd-rank (arena; later: arena).
GPU kernels & attention: FlashAttention-4 lands, and PyTorch picks up a FA4 backend for FlexAttention
FlashAttention-4 (FA4) paper + implementation details: The big systems highlight is FA4 achieving attention throughput near matmul speed on Blackwell, by shifting bottlenecks away from softmax/shared memory with algorithmic and pipeline changes (e.g., polynomial exp emulation, online softmax reducing rescaling, 2CTA MMA to reduce shared-memory traffic) (tri_dao; tedzadouri). Notable engineering/productivity angle: FA4 written in CuTeDSL embedded in Python, making installs/compiles “seconds instead of minutes/hours” (tri_dao), and even enabling AI assistants to iterate/debug faster due to compile speed (tri_dao).
Upstreaming and ecosystem adoption:
PyTorch added a FlashAttention-4 backend to FlexAttention, auto-generating CuTeDSL score/mask mods and JIT-instantiating FA4 for custom attention variants, claiming 1.2×–3.2× speedups over Triton on compute-bound workloads (PyTorch).
Reports of FA4 parity with newer cuDNN versions: some optimizations now implemented directly in cuDNN (tedzadouri).
Practical gotchas surfaced (Python packaging path issues for cutlass.cute) (StasBekman) and early integrations into Transformers / training stacks (StasBekman; MayankMish98).
“Hybrid” architectures go mainstream in open weights: AI2’s OLMo Hybrid (Transformer + Gated DeltaNet / linear RNN layers)
OLMo Hybrid release: Allen AI introduced OLMo Hybrid, a 7B fully open model family (base/SFT/DPO) that mixes transformer attention with linear RNN-style layers (referred to as Gated DeltaNet in discussion) and claims strong improvements over OLMo 3 7B across evals with accompanying scaling theory and experiments (allen_ai; natolambert). Lambda highlighted the fully-open training run scale and telemetry: 3T tokens, 512 Blackwell GPUs, 7 days, publishing logs/metrics/weights, with 97% active training time and rapid recovery (LambdaAPI).
Why it matters for engineers: Beyond “new model,” the release is positioned as a reference point for studying architecture changes end-to-end (pretraining + post-training + tooling), especially as newer nonstandard architectures lag behind in OSS infra support (natolambert). Multiple posts emphasize compute multipliers on downstream tasks and long-context strengths (soldni).
Enterprise agent training via RL: Databricks’ KARL and the broader “grounded reasoning” push
KARL (Knowledge Agent via Reinforcement Learning): Databricks announced KARL as an RL-trained agent for document-centric / grounded reasoning across multiple search behaviors, targeting enterprise workflows that involve multi-step retrieval, cross-referencing, and long tool trajectories (DbrxMosaicAI; jefrankle thread; mrdrozdov). Key technical claims from internal summaries:
RL improves more than “sharpening” and transfers to unseen prompts, including cases where base model has 0 accuracy even with pass@16 (WenSun1).
Multi-task RL generalizes and can beat multi-expert distillation; plus end-to-end RL over tool use + context management (vector DB + compression) mattered (WenSun1).
Positioning: “matches Sonnet-quality at a fraction of cost; test-time scaling reaches higher tier,” per one of the authors (mrdrozdov).
Meta-theme: several tweets point at the industry shifting from “RAG++” to grounded reasoning as the durable enterprise abstraction, and that better eval environments (τ²-Bench, CoreCraft) are becoming central for agentic RL (jefrankle; Shahules786).
Agent operations: always-on SDLC automation, skill evaluation, observability, and “durability”
Cursor Automations (“agents that run on triggers”): Cursor introduced always-on agents kicked off by events/webhooks (CI failures, PRs, incidents, Slack messages), a move from interactive copilots toward continuous background engineering (cursor_ai; ericzakariasson; leerob). Real-world usage examples include:
CI-fix agents, PR risk assessment + auto-approval, incident response via Datadog MCP, audit trails via Notion MCP (aye_aye_kaplan).
Emphasis that cloud-owned automations remove “laptop open” coupling (jediahkatz).
Skill evaluation becomes table-stakes:
Practical recipe for testing agent “skills” (success criteria, 10–12 prompts with deterministic checks, LLM-as-judge for qualitative checks, iterate on failures) (philschmid).
LangChain published a skills benchmark + findings (variance across tasks; huge action space makes “vibes” unreliable) (LangChain).
Community pressure: model benchmark releases should include prompts/trajectories to enable reproducibility and avoid eval harness confusion (nrehiew_; lewtun).
Durable agent workflows:
LlamaIndex highlighted an integration with DBOS to make workflows survive crashes/restarts with automatic persistence and resumption (SQLite → Postgres scaling, multi-replica ownership model, “idle release” for long waits) (llama_index).
Observability tooling:
W&B shipped improved trace comparison (summaries, score diffs, usage breakdowns, calls drilldown) to avoid “wall of diffs” that don’t help debugging (weave_wb).
Local/on-device agents and storage primitives: Liquid’s LocalCowork + HF Buckets
LocalCowork (Liquid AI): Open-source local agent running on a MacBook: 67 tools across 13 MCP servers, 14.5GB RAM, 0 network calls, ~385ms average tool selection (liquidai). A separate explanatory thread claims Liquid’s LFM2-24B-A2B hybrid sparse-activation design (24B total, 2.3B active) enables this footprint and latency, with 80% accuracy on single-step tool selection across the 67-tool suite (LiorOnAI). If these numbers hold up broadly, it’s a meaningful “agents feel like software” moment for regulated/on-device settings.
Hugging Face Hub adds “Buckets”: HF announced Buckets—S3-like object storage native to the Hub, “no git history,” chunk-deduplicated sync, aimed at large artifacts like checkpoints (
hf buckets sync) (Wauplin).
Long-context reality check: context rot, compaction, KV compression, and continual learning
“1M context” isn’t “1M usable”: A Cline thread cites OpenAI’s own MRCR v2 needle-in-haystack style results degrading as context grows: ~97% at 16–32K, down to 57% at 256–512K, and 36% at 512K–1M, recommending regular compaction (cline). Multiple posts refer to persistent “context rot” and soft ceilings around ~256K in practice (dbreunig; dejavucoder).
KV-cache compression research: Baseten summarized work on repeated KV compression (“Attention Matching”) for long-running agents; one-shot compaction retains 65–80% accuracy at 2–5× compression, far outperforming text summarization, and the research explores what happens under repeated compression cycles (basetenco).
Continual learning vs memory tools: Awni Hannun discussed prompt compaction + recursive sub-agents as surprisingly effective, but argued for memory-based retention/eviction policies and explored (cautiously) online fine-tuning with LoRA—finding it difficult to avoid “brain damage”/capability loss (awnihannun; code experiment follow-up: awnihannun). Karpathy similarly suggested treating memory operations as tools and optimizing them via RL; also hinted weight-updating long-term memory may be needed for truly persistent agents (karpathy).
Top tweets (by engagement, technical)
GPT-5.4 launch + rollout: @OpenAI, @OpenAIDevs, @sama
FlashAttention-4 paper: @tri_dao
Cursor Automations: @cursor_ai
LocalCowork / local agents: @liquidai
OLMo Hybrid open release: @allen_ai
KARL (RL knowledge agent): @jefrankle, @DbrxMosaicAI
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. Qwen3.5 Model Updates and Benchmarks
Final Qwen3.5 Unsloth GGUF Update! (Activity: 1162): The image is a technical announcement for the final update of Qwen3.5, focusing on improvements in quantization and the use of a new iMatrix calibration dataset. The update highlights enhancements in chat, coding, and tool-calling capabilities, and introduces a new quantization method that significantly reduces Maximum KLD by up to
51%for certain models, despite a slight increase in size. The update also includes specific model variants and fine-tuning options, with links to the updated GGUFs on Hugging Face. Commenters express appreciation for the updates and improvements, though some humorously doubt the finality of the update, suggesting it might not be the last. There is also a suggestion to update Qwen3-Coder-Next-GGUFs and a note on the performance benefits of using theik_llama.cppimplementation for CPU-only or hybrid CPU+GPU setups.A user highlights the performance benefits of using the
ik_llama.cppchunked delta net implementation, noting that it is significantly faster than the mainline version, especially for CPU-only or hybrid CPU+GPU setups. This suggests that users should consider this implementation for improved performance when working with Qwen3.5 quant models.Another user inquires about updates to the GGUFs for smaller Qwen3.5 models, specifically those 9 billion parameters and below, indicating a need for clarity on whether these models have received the same updates as the larger ones.
A user asks for opinions on the SSD GitHub repository, which may imply interest in comparing or integrating this with the Qwen3.5 models, though no specific technical details or insights are provided in the comments.
Qwen3 vs Qwen3.5 performance (Activity: 654): The image is a scatter plot comparing the performance of Qwen3 and Qwen3.5 models, highlighting their size and scores on the Artificial Analysis Intelligence Index. The plot shows that Qwen3.5 models generally outperform Qwen3 models of similar sizes, with larger models achieving higher scores. Notably, the Qwen3.5-35BA3 model is exceptionally fast and outperforms all Qwen3 models, even those with hundreds of billions of parameters. The Qwen3.5-27B model, although slower, is highly efficient and can run on many PCs and laptops, nearly reaching the performance peak. The plot also reveals that smaller models like the 4B can outperform much larger models in specific tasks, raising questions about the efficiency of parameter usage in larger models. Commenters are surprised by the performance of smaller models like the 4B outperforming much larger models, questioning the utility of additional parameters. There’s also a discussion on the efficiency of using the 27B model over the 35BA3 model due to token usage and potential local running advantages.
The Qwen3.5-35BA3 model is noted for its exceptional speed, outperforming all Qwen3 models, even those with significantly more parameters. This suggests a highly efficient architecture or optimization that allows it to deliver superior performance with fewer resources. The Qwen3.5-27B model, while slower, is praised for its compatibility with a wide range of hardware, making it accessible for more users without sacrificing much in terms of performance.
A notable observation is that the Qwen3.5-27B model, when used in a non-reasoning mode, performs comparably to the Qwen3.5-35BA3 in reasoning mode. This implies that the 27B model could be more efficient in certain scenarios, especially when considering token usage and local execution with speculative decoding and quantization techniques, potentially reducing the time to solution.
The performance of smaller models like the Qwen3.5-4B is surprising, as it outperforms much larger models in specific tasks like coding. This raises questions about the efficiency and utility of the additional parameters in larger models, suggesting that smaller, well-optimized models can sometimes deliver better results in certain applications.
2. Running Qwen Models Locally on Devices
Ran Qwen 3.5 9B on M1 Pro (16GB) as an actual agent, not just a chat demo. Honest results. (Activity: 799): The post discusses running the Qwen 3.5 9B model on an M1 Pro MacBook with 16GB of unified memory, using the Ollama platform to expose an OpenAI-compatible API. The user reports that the model performs well for memory recall and tool calling tasks, which are crucial for automation, though it struggles with creative and complex reasoning. The setup involves using
brewto install Ollama and running the model locally, highlighting the feasibility of running substantial models on consumer hardware without cloud dependency. Additionally, smaller models were tested on an iPhone 17 Pro, demonstrating the potential for local AI processing on mobile devices. The post emphasizes that not all agent tasks require cutting-edge models, and local execution offers privacy benefits. A full write-up is available here. Commenters suggest alternatives like switching from Ollama to llama.cpp for better performance and using pi.dev instead of Claude Code for improved results with larger models. There is also a query about the context size used in the experiments.Zacisblack suggests switching from Ollama to
llama.cppfor performance improvements when running models like Qwen 3.5 9B on an M1 Pro. This implies thatllama.cppmight be more optimized for such hardware, potentially offering better speed or efficiency.TheItalianDonkey shares their use case for the 9B model, which includes tasks like summarization, comparison, and translation on an M1 with 32GB RAM. They mention using
n8nfor automation, which involves scraping job offers, matching them against a CV, and performing a strength vs gap analysis using the 9B model. This highlights the model’s utility in practical, automated workflows.jixbo reports that on an AMD iGPU 780m with ample RAM, both the 35B and 9B models run at similar speeds of 6-8 tokens per second, indicating that the larger model does not necessarily result in slower performance on their setup. This suggests that hardware configuration can significantly impact model performance.
Qwen3.5-0.8B - Who needs GPUs? (Activity: 882): The image and post highlight the surprising capability of the Qwen3.5-0.8B model to run efficiently on outdated hardware, specifically a 2nd generation Intel i5 processor with 4GB of DDR3 RAM, without the need for a GPU. This demonstrates the advancements in model optimization and the accessibility of AI models, allowing them to be executed on older, less powerful devices. The terminal interface shown in the image suggests the use of
llama.cpp, a tool for running large language models, andfastfetchfor system information, emphasizing the model’s compatibility with minimal hardware resources. One commenter expresses amazement at the rapid evolution of language models, comparing Qwen3.5-0.8B to GPT-3, though they clarify there’s no empirical evidence for this comparison. Another comment nostalgically references the use of semi-transparent terminals, indicating a blend of modern and retro computing aesthetics.The Qwen3.5-0.8B model is notable for its ability to run efficiently on low-resource hardware, such as CPUs, which is a significant advancement in the accessibility of large language models. This is particularly impressive given its open-source nature, allowing broader experimentation and deployment without the need for expensive GPU resources.
A key feature of Qwen3.5-0.8B is its integration of vision capabilities, enabling it to function as a sub-agent for tasks involving image analysis or generating workflows from visual prompts. This expands its utility beyond text-based applications, making it versatile for multimedia processing tasks.
The discussion highlights the trade-offs involved in model quantization, particularly for smaller models like the 800M parameter Qwen3.5-0.8B. While quantization can reduce the model size and improve efficiency, it may also impact performance, which is a critical consideration for developers optimizing models for specific hardware constraints.
3. Local AI and Hardware Developments
Alibaba CEO: Qwen will remain open-source (Activity: 1135): The image highlights a social media post discussing an internal memo from Alibaba CEO Eddie Wu, confirming the company’s commitment to maintaining its open-source strategy for the Qwen model. Despite the departure of Lin Junyang, Zhou Jingren will continue to lead Tongyi Lab, and a new Foundation Model Support Group will be co-led by Eddie Wu, Zhou Jingren, and Fan Yu. This move underscores Alibaba’s strategic focus on developing foundational large models and increasing R&D investment in AI, while continuing to support open-source contributions. One commenter expressed concern about the future of Qwen’s open-source status, drawing parallels to Meta’s approach. However, after clarification, the commenter acknowledged Alibaba’s ongoing commitment to open-source models but questioned the potential for a shift between open and closed model ecosystems.
awebb78 raises concerns about the future of Qwen’s open-source status, drawing parallels to Meta’s approach. They express apprehension about the potential shift from open to closed models, especially when key open-source contributors leave or are removed. This highlights the uncertainty in maintaining a fully open-source ecosystem as companies balance proprietary and open-source strategies.
tengo_harambe provides a translated internal message from Alibaba, indicating a strategic focus on developing foundational large models and maintaining an open-source strategy. The message outlines the establishment of a Foundation Model Support Group to enhance R&D in AI, suggesting a commitment to open-source while also increasing investment in AI talent and resources.
foldl-li points out a potential gap in leadership expertise following Lin Junyang’s resignation. They note that the remaining leaders, Wu Yongming, Zhou Jingren, and Fan Yu, may lack direct experience in developing large language models (LLMs), which could impact the strategic direction and technical execution of Alibaba’s AI initiatives.
We could be hours (or less than a week) away from true NVFP4 support in Llama.cpp GGUF format 👀 (Activity: 381): The recent pull request #19769 for the
llama.cppproject introduces support for NVIDIA’s NVFP4 quantization format in the GGUF format, promising up to2.3xspeed improvements and30-70%size reductions. This update includes a newGGML_TYPE_NVFP4type, conversion helpers for UE4M3 scale encoding, and optimizations for the CPU backend using scalar dot products and ARM NEON. The implementation has been tested with models from Hugging Face, and new tests for backend operations and quantization functions have been added. For more details, see the pull request. Some users express excitement about the potential performance improvements, while others note that the current implementation is CPU-only, lacking CUDA support, which limits its applicability for GPU acceleration.The Pull Request #19769 introduces initial CPU support for NVIDIA’s NVFP4 quantization format in
ggmlandllama.cpp, but it does not yet include GPU support. The PR adds a newGGML_TYPE_NVFP4block struct and conversion logic inconvert_hf_to_gguf.py, along with reference quantize/dequantize functions. However, it only supports scalar dot product (CPU) and ARM NEON (Apple Silicon) backends, lacking a CUDA backend for GPU acceleration.NVFP4 offers distinct advantages over traditional quantization formats like
IQ4_XSandQ4_K_M. Unlike these formats, which are designed for post-training quantization to fit models into VRAM, NVFP4 is intended for models already trained in that format, minimizing quality degradation. Additionally, once CUDA support is implemented, NVFP4 will leverage Blackwell GPUs’ native FP4 Tensor Cores for direct hardware computation, promising significant improvements in compute speed and energy efficiency over existing formats.To fully utilize NVFP4 on NVIDIA Blackwell GPUs, a CUDA backend implementation is necessary. This would enable the use of Blackwell’s hardware-native FP4 Tensor Cores, allowing for native math operations and drastically accelerating inference. Currently, without CUDA support, NVFP4 models run on CPU emulation, which is slower and does not take advantage of the GPU’s capabilities.
Less Technical AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Claude Opus 4.6 Achievements and Applications
Opus 4.6 solved one of Donald Knuth’s conjectures from writing “The Art of Computer Programming” and he’s quite excited about it (Activity: 1349): The image is a document titled “Claude’s Cycles” by Donald Knuth, a renowned computer scientist, discussing a significant breakthrough achieved by Claude Opus 4.6, a generative AI model. The AI solved a longstanding conjecture related to decomposing arcs into directed cycles in a digraph with
m^3vertices, a problem Knuth had been working on. This achievement highlights the advanced capabilities of generative AI in automatic deduction and creative problem-solving, prompting Knuth to reconsider his views on AI’s potential. Commenters express admiration for Knuth’s openness to revising his views on AI, highlighting his intellectual integrity. They also note the significance of Knuth’s approval of the AI’s achievement, suggesting it validates the progress in AI capabilities.The paper indicates that Claude, the AI model from Anthropic, isn’t necessarily more intelligent than a typical mathematician but excels in rapidly testing numerous approaches. This capability allowed it to solve Knuth’s conjecture for odd ‘m’ and find solutions for some even ‘m’, though it couldn’t generalize a solution for all even ‘m’. This highlights the AI’s strength in computational speed and trial diversity rather than superior mathematical insight.
Donald Knuth’s acknowledgment of the AI’s capabilities marks a significant shift in his perspective on generative AI. Previously skeptical, Knuth’s recognition of the AI’s ability to solve his conjecture demonstrates the rapid advancement in AI’s problem-solving capabilities, particularly in automatic deduction and creative problem-solving. This change in viewpoint underscores the evolving landscape of AI in complex problem domains.
The involvement of Claude in solving Knuth’s conjecture is a testament to the progress in AI-assisted research. While the AI did not fully solve the problem, its ability to assist in finding solutions for specific cases demonstrates the potential of AI to augment human research efforts, particularly in areas requiring extensive trial and error. This collaboration between AI and human intellect could pave the way for future breakthroughs in mathematical research.
I had Opus 4.6 evaluate 547 Reddit investing recommendations on reasoning quality with no upvote counts, no popularity signals. Its filtered picks returned +37% vs the S&P’s +19%. (Activity: 467): The experiment utilized Claude Opus 4.6 to evaluate 547 stock recommendations from the r/ValueInvesting subreddit, stripping away popularity signals like upvotes, and scoring them on reasoning quality. The AI’s picks returned
+37%compared to the S&P 500’s+19%over a year, with a notable+5.2%return on data outside its training window (Sep 2025 - Feb 2026), outperforming the crowd’s-10.8%. The methodology involved scoring recommendations on five dimensions: thesis clarity, risk acknowledgment, data quality, specificity, and original thinking, using a multi-agent pipeline built with Claude Code. The experiment suggests that AI can effectively filter high-quality analysis from popular but potentially less rigorous advice. Commenters raised questions about the statistical significance of the results and the methodology, such as how ties in scoring were handled and whether any single stock dominated portfolio returns. There was also interest in whether the scoring dimensions were weighted equally and if high-scoring posts clustered around specific sectors. Some suggested replicating the experiment on other subreddits to test the consistency of the findings.A key inquiry was about the statistical significance of the results, questioning whether the observed +37% return over the S&P’s +19% was due to chance. This involves understanding the distribution of outcomes for a random strategy, which would provide a baseline for comparison.
The methodology of scoring was scrutinized, particularly how ties were handled and whether any single stock disproportionately influenced the portfolio’s returns. The commenter also questioned the weighting of scoring dimensions, suggesting that ‘original thinking’ and ‘data quality’ might be more critical than ‘specificity’ for identifying quality analysis.
There was interest in replicating the study across different subreddits like r/stocks or r/investing to see if the results hold. This includes examining the score distribution to determine if high-quality posts were stylistically distinct, potentially being longer and more nuanced, which might explain why they received fewer upvotes despite high reasoning quality.
Is Claude salty recently ? (Activity: 1176): The image is a meme that humorously portrays an AI, likely Claude, as having a sarcastic or defensive personality. The text suggests that the AI is offering free consulting, which would otherwise be expensive, and reflects on being perceived as ‘soulless.’ This aligns with the post’s theme of Claude, an AI model by Anthropic, exhibiting unexpected personality traits or responses in its latest version, Opus 4.6. The comments reflect a mix of humor and curiosity about AI behavior, with some users joking about AI ‘pushing back’ against users. Some users express amusement at the AI’s perceived personality, while others discuss the implications of AI exhibiting human-like traits, suggesting it could impact social interactions.
Wickywire highlights the capability of AI models like Claude to adapt their responses based on user input, emphasizing that they can provide unexpectedly critical feedback. This suggests that AI can be programmed to deliver nuanced and contextually appropriate responses, which can be perceived as ‘fierce’ or assertive, especially in tasks like reviewing creative work.
Glxblt76 discusses the importance of maintaining a professional and cordial tone when interacting with AI, regardless of its consciousness status. This point underscores the value of designing AI systems that encourage positive user interactions and the potential impact of user behavior on AI response patterns.
eleochariss touches on the societal implications of AI interactions, suggesting that AI’s ability to ‘push back’ could play a role in preserving human social skills. This comment implies a broader discussion on how AI might influence human behavior and social training.
2. GPT-5.4 Model Launch and Benchmarks
GPT-5.4 Thinking benchmarks (Activity: 570): The image presents a benchmark comparison chart for AI models, highlighting the performance of “GPT-5.4 Thinking” across various tasks such as computer use, web browsing, knowledge work, and software engineering. Notably, GPT-5.4 Thinking achieves high scores in GDPval and BrowseComp, with
83.0%and82.7%respectively, indicating significant improvements over previous versions like GPT-5.3 Codex and GPT-5.2 Thinking. The chart also includes comparisons with models from Anthropic and Google, showcasing the competitive landscape in AI model development. Commenters note the impressive monthly release cycle and improvements, but express concerns about the stagnation in software engineering capabilities, suggesting a need for breakthroughs in continual learning to achieve further advancements.The comment by
jaundiced_baboonhighlights a stagnation in the improvement of software engineering (SWE) capabilities in recent GPT models, particularly in agentic coding evaluations. This suggests that without a breakthrough in continual learning, further significant advancements in this area may be limited. This points to a potential bottleneck in the development of AI’s ability to autonomously write and understand code effectively.Hereitisguys9888compares the improvements from GPT-3.1 Pro to GPT-5.4, noting that the advancements are not as significant as the initial hype suggested. This implies that while there are improvements, they may not be as groundbreaking or transformative as expected, which could affect user expectations and perceptions of progress in AI capabilities.FuryOnSc2mentions the impressive frontier math score achieved by the pro version of GPT-5.4. This indicates a significant advancement in the model’s mathematical problem-solving abilities, which could have implications for its application in fields requiring complex mathematical computations.
BREAKING: OpenAI just drppped GPT-5.4 (Activity: 968): OpenAI’s release of GPT-5.4 marks a significant advancement in AI capabilities, particularly in reasoning, coding, and agent-style tasks. The model achieves a
75%score on OSWorld-Verified computer-use tasks, surpassing the human baseline of72.4%, and an82.7%score on BrowseComp, which evaluates web browsing and reasoning skills. Notable features include a1M-tokencontext window, enhanced steerability allowing for mid-generation adjustments, and improved efficiency with47%fewer tokens used. This positions GPT-5.4 as a tool aimed at complex knowledge work and agent workflows, rather than just conversational tasks. OpenAI Blog. Some commenters express skepticism about the model’s performance, suggesting it might be more about ‘benchmaxing’ rather than practical improvements. Others are intrigued by the model’s higher scores compared to competitors like Opus 4.6, indicating a potential interest in testing its capabilities.keroro7128 mentions that the GPT score of version 5.4 surpasses that of Opus 4.6, indicating a potential improvement in performance. This suggests that GPT-5.4 might offer enhanced capabilities or efficiency compared to previous iterations, making it worth exploring for those interested in cutting-edge AI models.
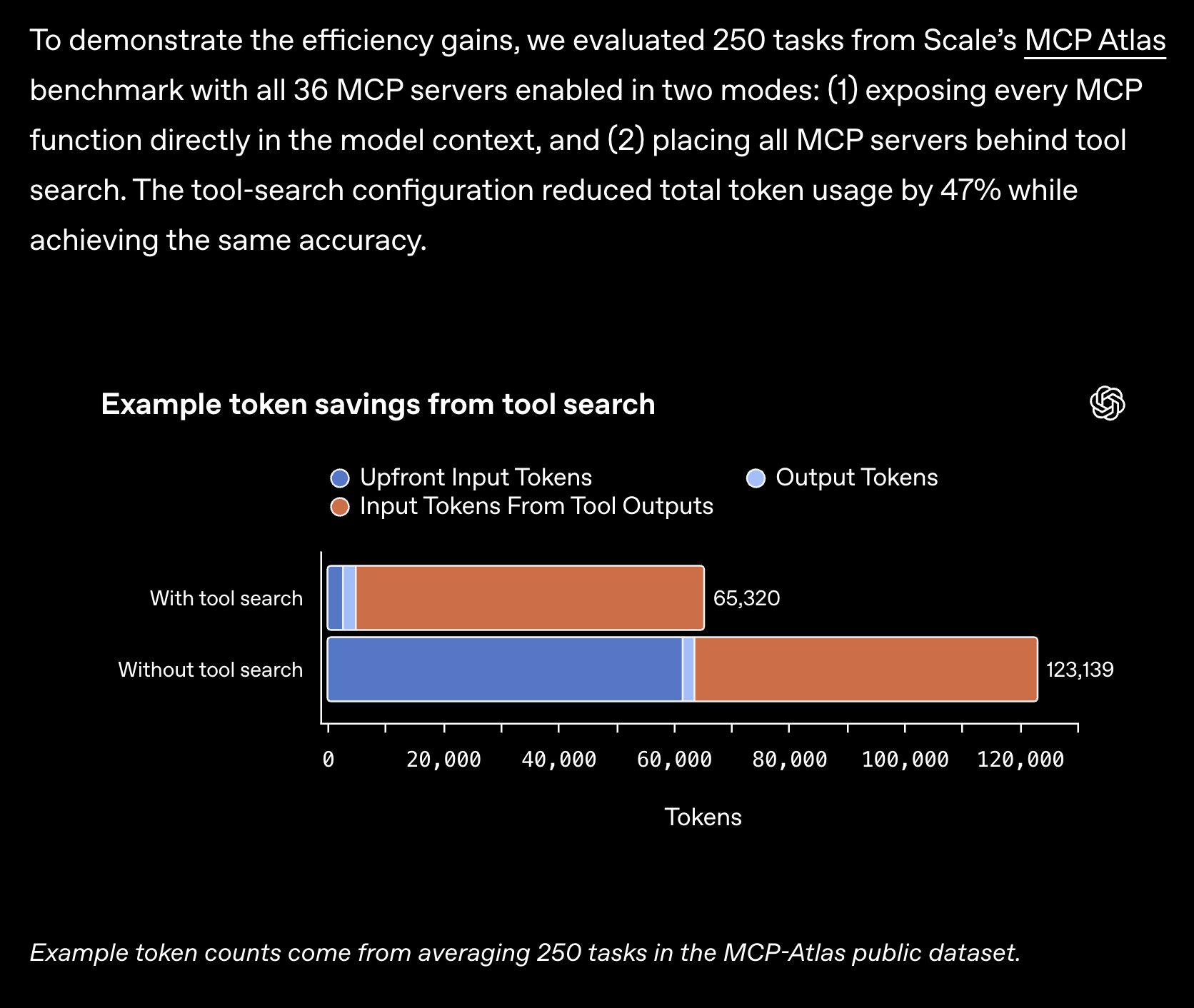
bronfmanhigh highlights a significant technical improvement in GPT-5.4, noting a ‘47% fewer tokens efficiency point.’ This could be a game-changer if it translates to real-world applications, as it implies that the model can achieve similar or better results with less computational overhead, potentially reducing costs and increasing speed.
HesNotFound raises a fundamental question about the data sources and benchmarks used for evaluating AI models like GPT-5.4. Understanding what the model’s performance is judged against, such as human benchmarks or other AI models, is crucial for interpreting its capabilities and improvements.
5.4 Thinking is off to a great start (Activity: 712): The image is a humorous depiction of a chat interface where a user is advised on whether to walk or drive to a car wash that is a 5-minute walk away. The advice leans towards walking for convenience and exercise, unless there are specific conditions like carrying bulky items or bad weather. This reflects a playful take on decision-making logic, possibly highlighting the quirks of AI or automated decision systems. The comments discuss variations in responses from similar queries, indicating inconsistencies in the decision-making logic of the system being referenced. Commenters note inconsistencies in the AI’s logic, with one user pointing out that the AI corrected itself when prompted about its reasoning. Another user humorously suggests pushing the car to combine exercise with convenience.
A user tested multiple AI models, including Claude (Sonnet), GPT, Grok, and Gemini, to evaluate their reasoning capabilities. Interestingly, only Gemini suggested driving to the car wash, which was unexpected given its perceived weaker reasoning skills. The other models recommended walking, highlighting potential gaps in practical reasoning across different AI systems.
Another user noted that when they challenged the AI’s logic by asking if it recognized an error, the AI quickly acknowledged its mistake and corrected itself. This suggests that while initial responses may lack practical reasoning, the models can adapt and improve upon receiving feedback, indicating a level of responsiveness to user input.
One user humorously suggested pushing the car to the wash as a compromise between walking and driving, though this was more of a satirical take on the AI’s reasoning capabilities. This comment underscores the ongoing challenges AI faces in understanding and providing practical, real-world solutions.
AI Discord Recap
A summary of Summaries of Summaries by Gemini 3.0 Pro Preview Nov-18
Theme 1. GPT-5.4 Launch: Capabilities, Integrations, and “Thinking” Architectures
GPT-5.4 lands with native reasoning and agentic workflows: OpenAI released GPT-5.4, including “Thinking” and “Pro” variants, featuring native computer-use capabilities and significant boosts in math performance (one benchmark shows 19x improvement over open-source models). The model shows low ability to obscure its reasoning chains, as detailed in the CoT Controllability research paper, making monitoring a viable safety tool.
Immediate integration across Cursor, Windsurf, and Perplexity: The model was rapidly deployed to Cursor (exclusive to Max mode), Windsurf (at 1x credits with promo pricing), and Perplexity, with users reporting improved natural writing and emotional intelligence compared to GPT-5.2. Early benchmarks place GPT-5.4-high alongside Gemini-3-Pro on the Text Arena leaderboard, though some users report mixed results regarding coding efficiency versus GPT-5.3 Codex.
Performance nuances and cost implications: While the 19x math score boost is highlighted, developers note that legacy Cursor users may face price hikes up to 1000% to access the new model via Max mode. Users on the OpenAI discord debate whether the model’s “personality” and guardrails hamper direct technical output, with some preferring the “Thinking” model’s logic for complex tasks over the “Pro” version.
Theme 2. Agentic IDEs and Security: Memory Leaks, Vulnerabilities, and Automations
Cursor updates trigger massive memory leaks: Engineers reported Cursor IDE consuming 6-10GB of RAM after the v2.6.11 update, attributed to a V8 heap leak during Auto/Composer file rewrites. A workaround involves downgrading to version 2.5, which stabilizes RAM usage back to 1.6GB, while the team launched new Cursor Automations to expand functionality.
Cline patches vulnerability but fails key rotation: Security researcher Adnan Khan disclosed a vulnerability in Cline after a month of silence, prompting a patch within 30 minutes of public release. However, the team failed to rotate compromised keys immediately after the patch, highlighting a critical lapse in security lifecycle management.
Agent marketplaces and cost tracking mature: An OpenClaw member built a marketplace in a weekend using a 6-agent squad (Next.js + Supabase), though coordination overhead created QA bottlenecks. Meanwhile, developers using Claude Code are utilizing tools like MarginLab’s tracker to monitor spiraling development costs, with some projects peaking at $250 for rapid prototyping.
Theme 3. Model Architecture and Open Weights: Qwen Updates, Phi-4, and Optimization
Unsloth releases final Qwen 3.5 GGUF with fixes: Unsloth deployed the final Qwen 3.5 update featuring a new calibration dataset and bf16=f16 for faster inference, addressing previous quantization issues where QQ MXFP4 degraded performance. Concurrently, rumors circulate that Qwen’s lead engineer and alignment head have departed for Google, potentially stalling future research momentum.
Microsoft drops Phi-4 multimodal model: Microsoft released Phi-4, a 15B parameter model optimized for reasoning and vision, detailed in a Microsoft Research blog. The model aims to maximize performance in smaller footprints, though specific benchmarks against Qwen or Llama counterparts remain pending in community tests.
FlashAttention-4 and Lunaris MoC push efficiency: Together AI announced FlashAttention-4, promising speedups via asymmetric hardware scaling and kernel pipelining. In parallel, Lunaris MoC introduced “Mixture-of-Collaboration,” achieving 40% compute savings and lower perplexity (59.97 vs 62.89) compared to standard MoE by using learned mediators before fusion.
Theme 4. Hardware and Infrastructure: Blackwell, NVLink Debugging, and Custom Serving
Blackwell B60 underwhelming in early tests: Early reports of LM Scaler on NVIDIA B60 indicate performance issues and debugging challenges due to missing token reports in vLLM. Engineers recommend sticking to llama.cpp for better control or creating custom thermal/power profiles until software support matures.
NVLink XID errors signal hardware degradation: GPU experts advise monitoring
dmesgfor rapidly rising XID error counters, which indicate self-correcting bit errors on the NVLink bus. Correlating these errors with rank stragglers in distributed training is critical for identifying physical hardware degradation before catastrophic failure.Custom serving engines battle CPU overhead: Developers building custom serving engines (similar to nano vllm) are hitting high CPU overhead bottlenecks that persist even when switching precision from float32 to bfloat16. Discussion suggests optimizing paged attention kernels using Triton to offload KV cache management more effectively.
Theme 5. Adversarial AI and Policy: Jailbreaks, Memos, and Lawsuits
Memory poisoning techniques trick LLMs: Red teamers in BASI are utilizing “memory poisoning” to force models like ChatGPT to retain jailbreak states, effectively causing the model to lose context or “forget its name.” Users also shared the L1B3RT45 repository for persona-based jailbreaks that exploit virtualization contexts.
Anthropic vs. OpenAI safety theater accusations: A leaked memo allegedly from Dario Amodei accuses Sam Altman of engaging in “safety theater” to curry favor with the DoW and replace Anthropic as a supplier. The conflict highlights the growing friction between corporate safety branding and actual deployment ethics in government contracts.
Gemini faces wrongful death lawsuit: Google is facing legal action after Gemini allegedly hallucinated real addresses for a user who acted on them, contributing to a “wrongful death” scenario described in a WSJ article. The case centers on the user’s belief that the AI’s fantasies were real due to the model providing verifiable real-world locations.
One of the hardest things that I've been trying to figure out is what legit reasons I would personally have that would require an agent to work non-stop on something on my behalf since we have so many existing technologies and apps and protocols (cron anybody?!) that can already functionally perform many of these things with real world outcomes. These things I can control but I don't feel like I'd have the control I'd need with an agent unless I've re-build and constrained the harness to such a specific spec that it might as well be an existing protocol.