

[AINews] GPT-Realtime-2, -Translate, and -Whisper: new SOTA realtime voice APIs
OpenAI continues deploying GPT-5 everywhere
OpenAI launched realtime-1.5 3 months ago, but it was a relative drop in the bucket because it was still 4o based intelligence (a +5% bump in Big Bench Audio). You could tell the sheer confidence in today’s realtime-2 release (with a +15.2% bump in BBA), and it was appropriately well received:
As the blogpost explains, 3 models are being released, which one might simplify to “voice-in, voice-out, and voice-to-voice”:
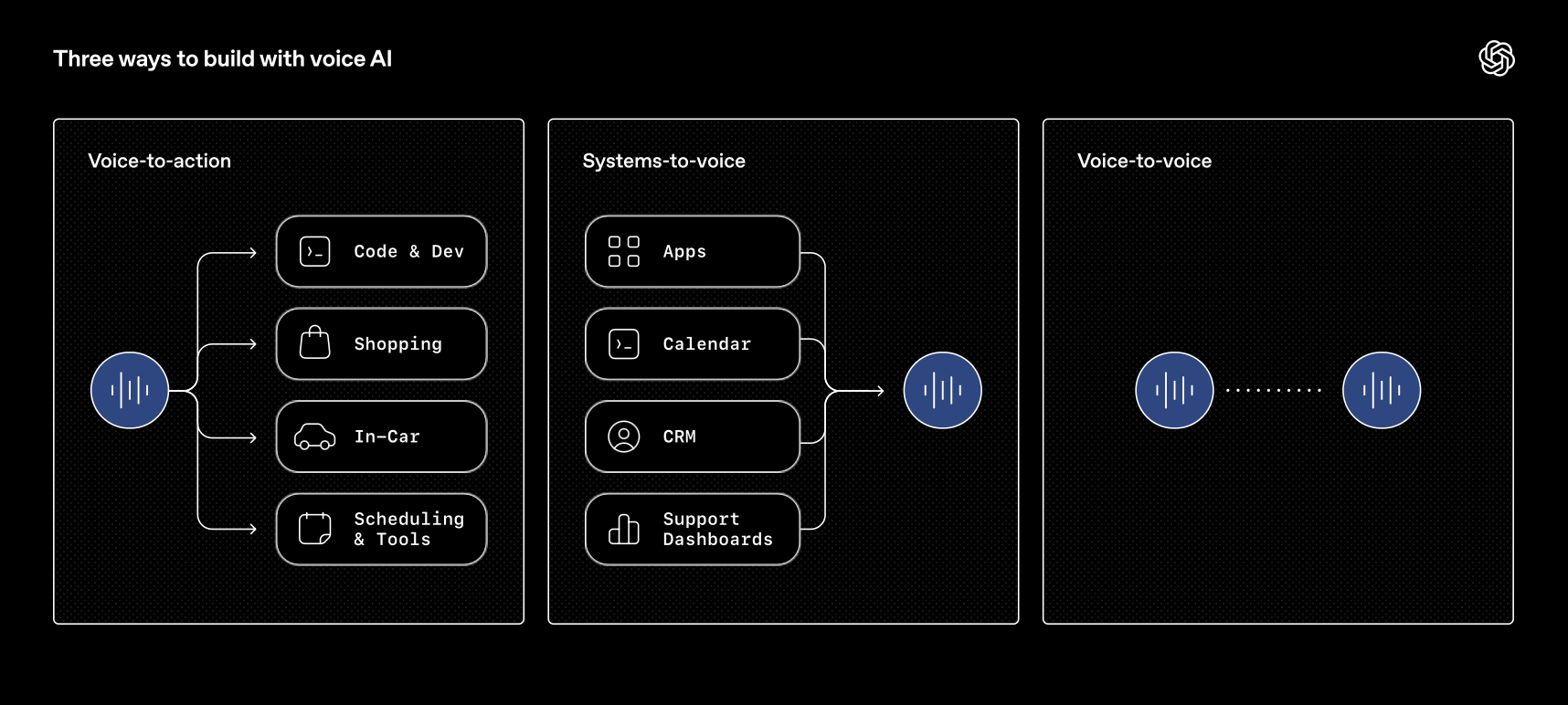
The focus is less about “voice quality”, and more on usability. TLDR:
Preambles: Developers can enable short phrases before a main response, like “let me check that” or “one moment while I look into it”.
Parallel tool calls and tool transparency: The model can call multiple tools at once and make those actions audible with phrases like “checking your calendar” or “looking that up now,” helping agents stay responsive while completing tasks.
Stronger recovery behavior: The model can recover more gracefully by saying things like “I’m having trouble with that right now,” instead of failing or breaking.
Longer context: 32K → 128K
Stronger domain understanding: The model better retains specialized terminology, proper nouns, healthcare terms, and other vocabulary
More controllable tone and delivery: The model can better adjust its tone—speaking calmly, empathetically, or upbeat, based on context
Adjustable reasoning effort: Developers can now select from minimal, low, medium, high, and xhigh reasoning levels, with low as the default.
The Demo video showed off how the audio model is better tuned when the main speaker is speaking to someone else, so it stops interrupting so much:
AI News for 5/6/2026-5/7/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
Top Story: GPT-Realtime-2 and OpenAI voice AI commentary
What happened
OpenAI launched three new streaming audio models in the Realtime API: GPT-Realtime-2, GPT-Realtime-Translate, and GPT-Realtime-Whisper. OpenAI positioned GPT-Realtime-2 as its “most intelligent voice model yet,” bringing “GPT-5-class reasoning” to real-time voice agents that can listen, reason, handle interruptions, use tools, and sustain longer conversations as they unfold @OpenAI. The companion models target live speech translation and transcription: GPT-Realtime-Translate supports streaming translation from 70+ input languages into 13 output languages, while GPT-Realtime-Whisper streams transcription/captions as speech is produced @OpenAI, @OpenAIDevs. OpenAI said the models are available in the Realtime API now, while ChatGPT voice upgrades are still pending: “Stay tuned, we’re cooking” @OpenAI. Sam Altman framed the launch around a behavioral shift: users increasingly use voice with AI when they need to “dump” lots of context, and OpenAI is also working on improvements to ChatGPT voice @sama.
Facts vs. opinions
Factual / directly claimed by OpenAI and evaluators
Model family: GPT-Realtime-2, GPT-Realtime-Translate, GPT-Realtime-Whisper are available in the Realtime API today @OpenAIDevs.
GPT-Realtime-2 capabilities: reasoning-oriented native speech-to-speech model for production voice agents; supports tool use/action, interruption recovery, longer conversations, and “GPT-5-class reasoning” per OpenAI’s wording @OpenAI, @reach_vb.
Context window: community/OpenAI-dev commentary reported 128K context for GPT-Realtime-2 voice agents @reach_vb; Artificial Analysis independently reported the context window increased from 32K to 128K, with 32K max output tokens @ArtificialAnlys.
Translation: GPT-Realtime-Translate supports live speech translation from 70+ input languages into 13 output languages @OpenAI, @reach_vb.
Transcription: GPT-Realtime-Whisper provides low-latency streaming transcription in the Realtime API for captions, notes, and continuous speech understanding @OpenAIDevs.
Prompting/control: OpenAI published a voice prompting guide covering reasoning effort, preambles, tool behavior, unclear audio handling, exact entity capture, and state maintenance in long sessions @OpenAIDevs.
Independent benchmarks: Scale AI reported GPT-Realtime-2 took the top spot on its Audio MultiChallenge S2S leaderboard, with instruction retention rising from 36.7% to 70.8% APR versus GPT-Realtime-1.5 and strong performance on voice editing/real-time repair @ScaleAILabs.
Independent benchmarks: Artificial Analysis reported 96.6% on Big Bench Audio speech-to-speech reasoning, 96.1% on its Conversational Dynamics benchmark, average time-to-first-audio of 2.33s at high reasoning and 1.12s at minimal reasoning, and unchanged audio pricing of $1.15/hour input and $4.61/hour output @ArtificialAnlys, @ArtificialAnlys.
Reasoning-effort controls: Artificial Analysis reported adjustable reasoning levels: minimal, low, medium, high, xhigh, with low as default @ArtificialAnlys.
Enterprise/product evals: Glean said GPT-Realtime-2 delivered a 42.9% relative increase in helpfulness over the previous version in internal evals for real-time organizational voice interactions @glean. Genspark said its Call for Me Agent moved to GPT-Realtime-2 and saw +26% effective conversation rate and fewer dropped calls @genspark_ai.
Opinions / interpretation / commentary
Supporters described the launch as a “big step forward” for voice agents @sama, “total realtime victory” @reach_vb, and the first speech-to-speech model good enough for “real work” in complex voice agents @kwindla.
A more cautious view: Simon Willison noted the announcement does not mean ChatGPT Voice Mode itself has upgraded yet; the ChatGPT upgrade “sounds” like it is coming soon @simonw, @simonw.
Interface skepticism: Will Depue compared audio to VR—frequently exciting, but historically not sticky as an interface—while arguing that real-time tool use, reasoning while speaking, and live translation are the kinds of capabilities that could make audio interfaces finally take off @willdepue.
Broader UX optimism: several commenters framed voice as more natural and bandwidth-efficient for humans @BorisMPower, a path toward Jarvis-like always-available computer agents @willdepue, or eventually displaced by even higher-bandwidth BCIs @iScienceLuvr.
Competitive context: Elon Musk pushed Grok Voice for customer support @elonmusk, underscoring that real-time voice support/customer-service automation is now a competitive surface across labs.
Technical details and benchmark data
GPT-Realtime-2
Native speech-to-speech / real-time voice model, released via OpenAI’s Realtime API @OpenAI.
Framed as “GPT-5-class reasoning” for voice agents @OpenAI.
Designed for agents that can:
Reported context: 128K tokens, up from 32K @ArtificialAnlys.
Reported max output: 32K tokens @ArtificialAnlys.
Inputs reported by Artificial Analysis: text, audio, and image @ArtificialAnlys.
Reasoning effort levels: minimal, low, medium, high, xhigh; default low @ArtificialAnlys.
Time-to-first-audio:
1.12s at minimal reasoning,
2.33s at high reasoning @ArtificialAnlys.
Pricing:
$1.15/hour audio input,
$4.61/hour audio output,
unchanged versus prior model according to Artificial Analysis @ArtificialAnlys.
Conversational features: supports short preambles before main responses—e.g. “let me check that”—and audible transparency during tool calls—e.g. “checking your calendar” @ArtificialAnlys.
Benchmarks
Scale AI Audio MultiChallenge S2S: GPT-Realtime-2 placed #1; instruction retention improved from 36.7% to 70.8% APR versus GPT-Realtime-1.5; strong voice editing when users repair/revise speech in real time @ScaleAILabs.
Artificial Analysis Big Bench Audio: GPT-Realtime-2 high variant scored 96.6%, reported as equal to Gemini 3.1 Flash Live Preview High and about ~13% above the previous highest result @ArtificialAnlys.
Justin Uberti separately summarized the improvement as 15 percentage points vs. GPT-Realtime-1.5 on Big Bench Audio, near saturation @juberti.
Conversational Dynamics / Full Duplex Bench subset: GPT-Realtime-2 minimal variant scored 96.1%, with strengths in pause handling and turn-taking @ArtificialAnlys.
GPT-Realtime-Translate
Live streaming speech translation from 70+ input languages to 13 output languages @OpenAI.
OpenAI cofounder Greg Brockman said real-time voice-to-voice translation has been an anticipated OpenAI application since the company’s early days and is now available for anyone to build with @gdb.
Vimeo demonstrated live dubbing with no pre-loaded captions, showing translations generated fully live @Vimeo.
Junling Zhang highlighted the new real-time translation model and encouraged API usage @jxnlco.
Boris Power said live translation “actually works incredibly well” and plans to use it regularly @BorisMPower.
GPT-Realtime-Whisper
Streaming transcription as people speak, for real-time captions, notes, and speech understanding @OpenAI.
Justin Uberti described it as “Whisper, but now with realtime streaming” and updated demos to use the new model @juberti.
Uberti also built a delay selector to expose the latency/accuracy tradeoff in a real-time typing demo @juberti.
Product integrations and demos
Glean: shipped real-time voice powered by GPT-Realtime-2, grounded in organizational context; internal evals showed 42.9% relative helpfulness increase over the previous version @glean.
Vimeo: demonstrated live dubbing using GPT-Realtime-Translate, with translations generated live and no pre-loaded captions @Vimeo.
Genspark: upgraded its Call for Me Agent to GPT-Realtime-2; Genspark Realtime Voice is next; claimed sharper reasoning, tighter instruction following, +26% effective conversation rate, and fewer dropped calls @genspark_ai.
Gradient Bang / game-agent demo: Kyle Windland said GPT-Realtime-2 is the first OpenAI speech-to-speech model good enough for his voice agents that do “real work,” showing it as the ship AI in a complex agent with tool calls and subagents @kwindla.
Voice-controlled market dashboard: Levin Stanley demoed GPT-Realtime-2 controlling an interface by intent—“Focus on Apple,” “How did it do over the last 30 days?”, “Go back”—arguing that real-time interruption and reasoning change the UI loop from navigation to direction @levinstanley.
Realtime demos: Justin Uberti updated
hello-realtimefor GPT-Realtime-2 and provided a phone demo number @juberti; Diego Cabezas posted a quick GPT-Realtime-2 demo @diegocabezas01; Ray Fernando hosted a “Building a Live Translator” broadcast @RayFernando1337.Reachy Mini / robotics voice interface interest: Clement Delangue asked who would add the new voice capabilities to Reachy Mini @ClementDelangue, after earlier asking voice AI labs such as Gradium, Kyutai, and ElevenLabs who could help with a robot voice use case @ClementDelangue.
Why this matters
The launch pushes voice agents from “speech I/O wrapper around a chatbot” toward full-duplex, tool-using, long-context, reasoning agents. The technical shift is not just better ASR or TTS; it is the combination of low-latency turn-taking, interruption handling, longer context, tool-call transparency, and adjustable reasoning effort in a single real-time loop. That matters for customer support, meetings, accessibility, live translation, robotics, browser/computer control, and hands-free workflows where text chat is too slow or awkward.
The most important engineering implication is that voice apps now need to be designed as stateful real-time systems, not prompt-response endpoints. OpenAI’s prompting guide explicitly points developers toward reasoning-effort tuning, preambles, tool behavior, unclear-audio recovery, entity capture, and long-session state management @OpenAIDevs. This suggests voice-agent quality will increasingly depend on harness design: latency budgets, interruption semantics, tool-call UX, conversational memory, and failure recovery—not just raw model selection.
The remaining uncertainty is distribution. The API model is available now, but ChatGPT voice mode has not yet received the upgrade, per Simon Willison’s observation @simonw. If and when ChatGPT Voice gets the same capabilities, the consumer impact could be much larger. Until then, the launch primarily benefits developers and platforms building specialized real-time agents.
Keep reading with a 7-day free trial
Subscribe to Latent.Space to keep reading this post and get 7 days of free access to the full post archives.