

Not 2 months after their IPO and first public quarter, MiniMax is back in the news with MiniMax 2.7, a nice bright spot in Chinese Open Models after the changeover in Qwen. They match Z.ai’s GLM-5 SOTA open model from last month, but the story is efficiency here (see green quadrant in Artificial Analysis’ chart):
The team calls out “Early Echoes of Self-Evolution”, calling it “our first model deeply participating in its own evolution.”, recalling Karpathy’s Autoresearch, although they only claim that “M2.7 is capable of handling 30%-50% of the workflow.”:

They also report some work on multi-agent collaboration (“Agent Teams”) as well as follow Anthropic and OpenAI’s lead in applying their models for finance usecases. Finally, they launch OpenRoom, an open source demo for entertainment usecases.
AI News for 3/18/2026-3/19/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
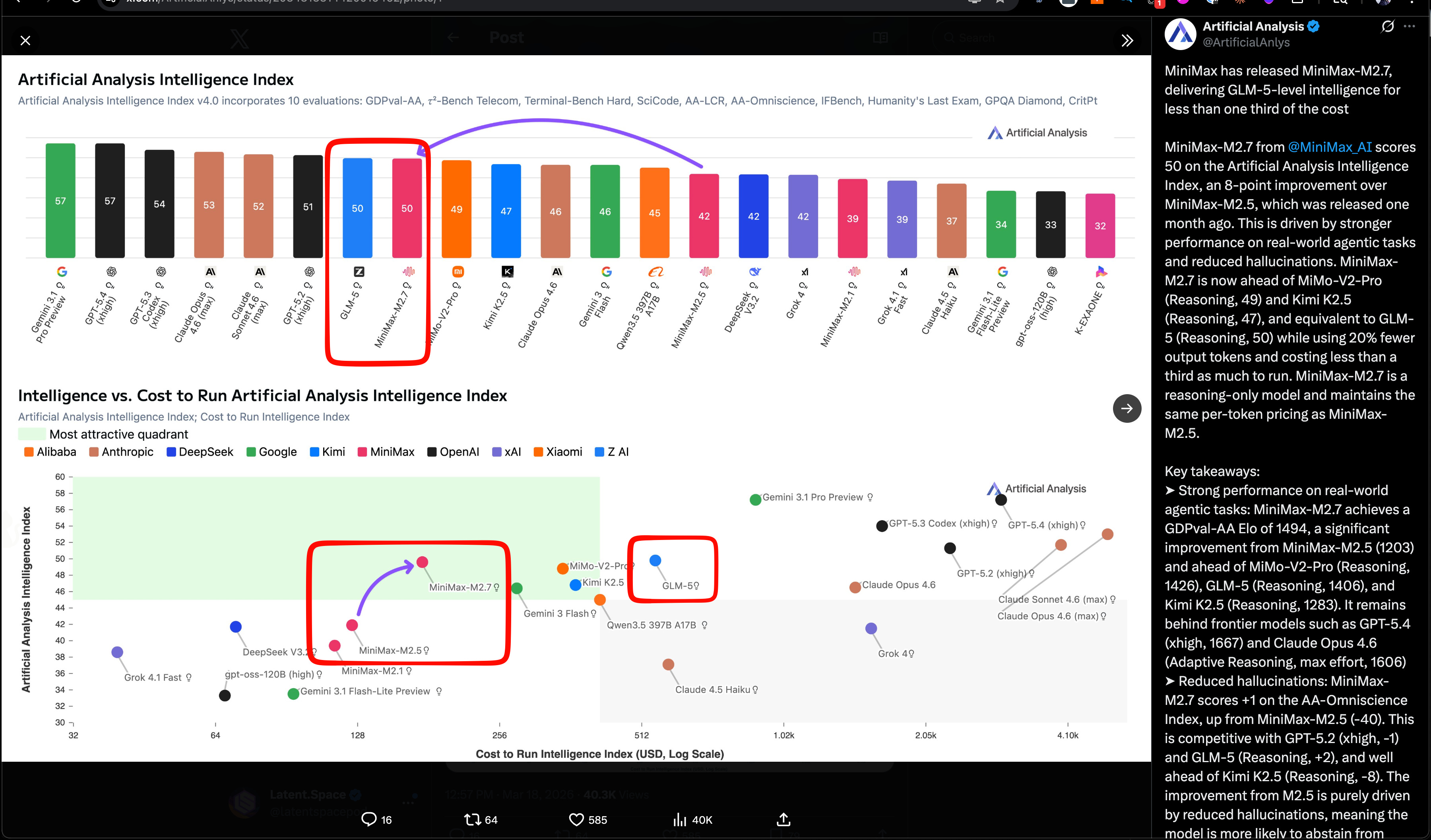
MiniMax M2.7, Xiaomi MiMo-V2-Pro, and the expanding “self-evolving agent” model class
MiniMax M2.7 is the headline model release: MiniMax positioned M2.7 as its first model that “deeply participated in its own evolution,” claiming 56.22% on SWE-Pro, 57.0% on Terminal Bench 2, 97% skill adherence across 40+ skills, and parity with Sonnet 4.6 in OpenClaw. A follow-up says the internal harness also recursively improved itself—collecting feedback, building eval sets, and iterating on skills/MCP, memory, and architecture (thread). Third-party coverage broadly echoed the “self-evolving” framing, including TestingCatalog and kimmonismus.
Artificial Analysis places M2.7 on the cost/performance frontier: Artificial Analysis reports 50 on its Intelligence Index, matching GLM-5 (Reasoning) while costing $176 to run the full index at $0.30/$1.20 per 1M input/output tokens—less than one-third of GLM-5’s cost. They also report GDPval-AA Elo 1494, ahead of MiMo-V2-Pro (1426), GLM-5 (1406), and Kimi K2.5 (1283), plus a large hallucination reduction vs M2.5. Distribution was immediate: Ollama cloud, Trae, Yupp, OpenRouter, Vercel, Zo, opencode, and kilocode.
Xiaomi’s MiMo-V2-Pro looks like a serious Chinese API-only reasoning entrant: Artificial Analysis scores it at 49 on the Intelligence Index, with 1M context, $1/$3 per 1M tokens pricing, and GDPval-AA Elo 1426. Notably, they call out stronger token efficiency than peers and a relatively favorable AA-Omniscience score (+5) driven by lower hallucination. This follows Xiaomi’s earlier open-weight MiMo-V2-Flash (309B total / 15B active, MIT); V2-Pro itself is API-only for now.
Mamba-3 is out and immediately being viewed through the hybrid-architecture lens: Cartesia announced Mamba-3 as an SSM optimized for an inference-heavy world, with Albert Gu noting Cartesia-backed testing and support (link). Early technical reactions focused less on standalone SSMs and more on plugging Mamba-3 into transformer hybrids: rasbt explicitly called out replacing Gated DeltaNet in next-gen hybrids like Qwen3.5 / Kimi Linear, while JG_Barthelemy highlighted hybrid integration and “unlocking Muon for SSMs.”
Agent harnesses, skills, MCP, and the shift from “prompting” to systems design
The strongest recurring theme is that harness engineering is becoming the real differentiator: Multiple posts argued that the bottleneck is no longer just the base model, but the surrounding execution environment. The Turing Post’s interview with Michael Bolin frames coding agents as a problem of tools, repo legibility, constraints, and feedback loops—what many now call harness engineering. dbreunig made a similar point about why teams stick with DSPy, and nickbaumann_ argued GPT-5.4 mini matters specifically because cheap, fast subagents change what is worth delegating.
Skills are solidifying into a shared abstraction across agent stacks: A practical thread from mstockton lays out real usage patterns for SKILLS: progressive disclosure, trace inspection, session distillation, CI-triggered skills, and self-improving skills. RhysSullivan suggests distributing skills via MCP resources may solve staleness/versioning. Anthropic’s Claude Code account clarifies that a skill is not just a text snippet but a folder with scripts/assets/data, and that the key description field should specify when to trigger it (tweet).
Open agent stacks are converging on model + runtime + harness: Harrison Chase published a walkthrough framing Claude Code, OpenClaw, Manus, etc. as the same decomposition: open model + runtime + harness, using Nemotron 3, NVIDIA’s OpenShell, and DeepAgents. Related infrastructure releases include LangSmith Sandboxes for secure code execution, LangSmith Polly GA as an in-product debugging/improvement assistant, and a new LangChain guide on production observability for agents.
MCP momentum continues, but there’s pushback: Useful MCP-related launches included Google Colab’s open-source MCP server, enabling local agents to drive Colab GPU runtimes, and Google’s Gemini API update allowing built-in tools plus custom functions in one call. At the same time, there’s visible skepticism: skirano bluntly said “MCP was a mistake. Long live CLIs.” and denisyarats joked about “model cli protocol.”
A parallel trend: agent-native enterprise apps and “headless SaaS”: ivanburazin describes an emerging category of headless SaaS—traditional software rebuilt as agent-first APIs with no human UI. That idea lines up with product launches like Rippling’s AI analyst, Anthropic’s Claude for Excel/PowerPoint webinar, and the notion that meeting-notes apps are really becoming broader AI context/data apps (zachtratar).
Infra, kernels, and model-system co-design
Attention Residual became a case study in infra-model co-design: Several posts unpacked Kimi/Moonshot’s AttnRes work as more than a novelty architecture. bigeagle_xd emphasized co-design across model research and infra, linking to an inference-infra writeup; ZhihuFrontier summarized why full attention residual strains pipeline parallelism due to asymmetric comms/memory patterns, and how Block Attention Residual plus cross-stage caching can restore symmetry. YyWangCS17122 reinforced the theme: kernel optimization, algorithm-system co-design, and numerical rigor as the path to production-worthy large models.
Custom kernel packaging is getting easier: ariG23498 highlighted Hugging Face’s new
kernelslibrary, which aims to make custom kernels more shareable and easier to integrate via the Hub. The pitch is straightforward: lower the pain of writing and distributing fused/custom kernels without requiring every model team to hand-roll installation and integration logic.Inference optimization remains a first-class topic: The same thread on kernels reiterates the familiar optimization stack—close idle gaps between kernel launches, fuse ops with
torch.compile, and only fall back to custom kernels where needed. On the hardware side, Stas Bekman noted that NVLink’s marketed bandwidth can be misleading because it is not duplex in the way many assume.Compute bottlenecks are still upstream of everything else: kimmonismus argues that ASML EUV machines and their narrow supply chains may cap production at roughly 100 machines/year by 2030, making lithography an important ceiling on AI scaling over this decade.
Documents, OCR, retrieval, and context engineering for real workflows
Document AI is trending toward end-to-end multimodal parsers with grounding: Baidu introduced Qianfan-OCR, a 4B end-to-end document intelligence model that collapses table extraction, formula recognition, chart understanding, and KIE into a single pass. Vik Paruchuri open-sourced Chandra OCR 2, claiming 85.9% on olmOCR bench, 90+ language support, and stronger layout, handwriting, math, form, and table support in a smaller 4B model. On the platform side, LlamaIndex and jerryjliu0 emphasized that production document agents need not just markdown conversion but layout detection, segmentation, metadata context, and visual grounding to support human-auditable document workflows.
Late-interaction retrieval continues to push on the memory/quality tradeoff: victorialslocum summarized MUVERA, which compresses multi-vector retrieval into fixed-dimensional encodings, reporting about 70% memory reduction and much smaller HNSW graphs at some recall/query-throughput cost. lateinteraction used the thread to reiterate the limitations of single-vector retrieval on harder OOD settings.
Context engineering is becoming a product category: llama_index explicitly frames context engineering as the successor to prompt engineering, with structured parsing/extraction as a core lever. This pairs with Hugging Face’s new support for serving Markdown paper views to agents and a Paper Pages skill for searching and reading papers more token-efficiently (Clement Delangue, Niels Rogge, mishig25).
Evals, training methodology, and benchmarks worth watching
LLM-as-judge reproducibility is under fire again: a1zhang showed a model scoring 10% under GPT-5.2-as-judge vs 43.5% under GPT-5.1-as-judge, despite a paper reporting 34%—a stark reminder that judge choice can swamp conclusions. torchcompiled distilled the takeaway: don’t use LLM-as-judge without validating human correlation or tuning for it.
Pretraining data composition is re-emerging as a major lever: rosinality highlighted work showing that mixing SFT data during pretraining can outperform the standard pretrain-then-finetune pipeline, with a scaling law for the ratio under a token budget. Related posts from arimorcos, pratyushmaini, and Christina Baek all argue that domain adaptation often benefits more from earlier data mixing or even repeating small high-quality datasets 10–50x during pretraining than from naive finetuning alone.
Benchmarks are shifting toward “unsolved and useful”: Ofir Press points to a future where improving on a benchmark means solving previously unsolved tasks that matter in the world, not just memorizing exam-like datasets. He also notes AssistantBench remains unsolved 1.5 years later. New benchmark/tooling drops include ScreenSpot-Pro on Hugging Face for GUI agents and Arena’s academic partnerships funding eval work.
Top tweets (by engagement, filtered for technical relevance)
OpenAI’s Parameter Golf challenge: OpenAI launched Parameter Golf, a training challenge to fit the best LM in a 16MB artifact trained in under 10 minutes on 8×H100s, with $1M in compute behind it. Good talent-pipeline energy, and a nice complement to the NanoGPT speedrun culture (details via scaling01).
Anthropic’s 81k-user study: Anthropic says it used Claude to interview 80,508 people in one week about hopes and fears around AI—the company calls it the largest qualitative study of its kind (announcement). The research is interesting both as social measurement and as a signal that model-mediated interviewing may become a standing product/research capability.
Runway’s real-time video generation preview: Runway shared a research preview developed with NVIDIA showing HD video generation with time-to-first-frame under 100ms on Vera Rubin hardware (tweet). If it generalizes, this is a qualitatively different interaction loop for video models.
Hugging Face on agent-facing research interfaces: The platform change to serve Markdown paper views to agents and the companion paper skill is small but important infrastructure for agentic research workflows (Clement Delangue).
VS Code integrated browser debugging: Microsoft’s latest VS Code release adds integrated browser debugging for end-to-end web app workflows—useful in its own right, and likely to matter even more as coding agents are asked to operate against live browser state.
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. MiniMax-M2.7 Model Announcements
MiniMax-M2.7 Announced! (Activity: 947): The image presents a comparative analysis of the newly announced MiniMax-M2.7 model against other models like Gemini 3.1 Pro, Sonnet 4.6, Opus 4.6, and GPT 5.4 across various benchmarks such as SWE Bench Pro, VIBE-Pro, and MM-ClawBench. MiniMax-M2.7 is highlighted in red, indicating its performance metrics, which are crucial for understanding its capabilities relative to existing models. The model’s autonomous iteration capabilities are emphasized, showcasing its ability to optimize software engineering tasks through iterative cycles, leading to a
30% performance improvementon internal evaluations. This highlights the model’s potential for self-evolution and automation in AI development. Commenters express skepticism about the practical usability of models that perform well on benchmarks but may not generalize well to real-world tasks. There is anticipation for user testing to validate the model’s effectiveness beyond controlled evaluations.Recoil42 highlights the autonomous iteration capabilities of the MiniMax-M2.7 model, which can optimize its own performance through iterative cycles. The model autonomously analyzes failure paths, plans changes, modifies code, and evaluates results, achieving a 30% performance improvement on internal evaluation sets by optimizing sampling parameters and workflow guidelines.
Specialist_Sun_7819 raises a critical point about the discrepancy between benchmark performance and real-world usability. They emphasize the importance of user testing to assess how models perform on tasks that deviate from their training distribution, suggesting that many models excel in evaluations but struggle with off-distribution tasks.
Lowkey_LokiSN expresses concern about the model’s quantization resistance, referencing issues with the previous M2.5 model’s UD-Q4_K_XL variant. This highlights the importance of maintaining model performance post-quantization, which can be a challenge for large models when reducing precision for deployment.
MiniMax M2.7 Is On The Way (Activity: 329): The image is a tweet from MiniMax announcing their participation in the NVIDIA GTC event where they plan to discuss their upcoming model, MiniMax M2.7, along with multimodal systems and AI products. This suggests that MiniMax M2.7 might incorporate multimodal capabilities, potentially handling multiple types of data inputs like text, images, and audio. The mention of multimodal systems aligns with current trends in AI development, where models are increasingly designed to process and integrate various data forms for more comprehensive outputs. A comment highlights the desire for a smaller version of the model, indicating user interest in more accessible or resource-efficient versions. Another comment praises the performance of MiniMax 2.5, noting its speed and tooling capabilities, but points out the lack of image and audio input support, which could be addressed in the upcoming M2.7 model.
z_3454_pfk highlights the performance of MiniMax 2.5, noting its efficiency with tooling and retrieval-augmented generation (RAG). The model is praised for its speed, though it currently lacks support for image and audio inputs, which could be a limitation for some applications.
Dismal-Effect-1914 emphasizes the compactness and efficiency of MiniMax 2.5, stating it is the best model available that fits under approximately 150 GB when using 4-bit quantization. This suggests a strong balance between performance and resource usage, making it suitable for environments with limited storage capacity.
Keep reading with a 7-day free trial
Subscribe to Latent.Space to keep reading this post and get 7 days of free access to the full post archives.