

[AINews] Moonshot Kimi K2.6: the world's leading Open Model refreshes to catch up to Opus 4.6 (ahead of DeepSeek v4?)
Yay Kimi!!!

Two days left before Early Bird ends for AI Engineer World’s Fair this Summer in SF. This is will be THE BIG ONE of the year - lock in discounts up to $500 (refundable).
DeepSeek V4 rumors are back, and we learned our lesson not to get too excited, but in their deafening silence since v3.2, Moonshot has owned the crown of leading Chinese open model lab for all of 2026 to date, and K2.6 refreshes the lead that K2.5 established in January, with (presumably) more continued pre/posttraining (this time, details of how much more training were not disclosed). Comparing the numbers from the two launches 3 months apart demonstrates the staggering amount of progress:
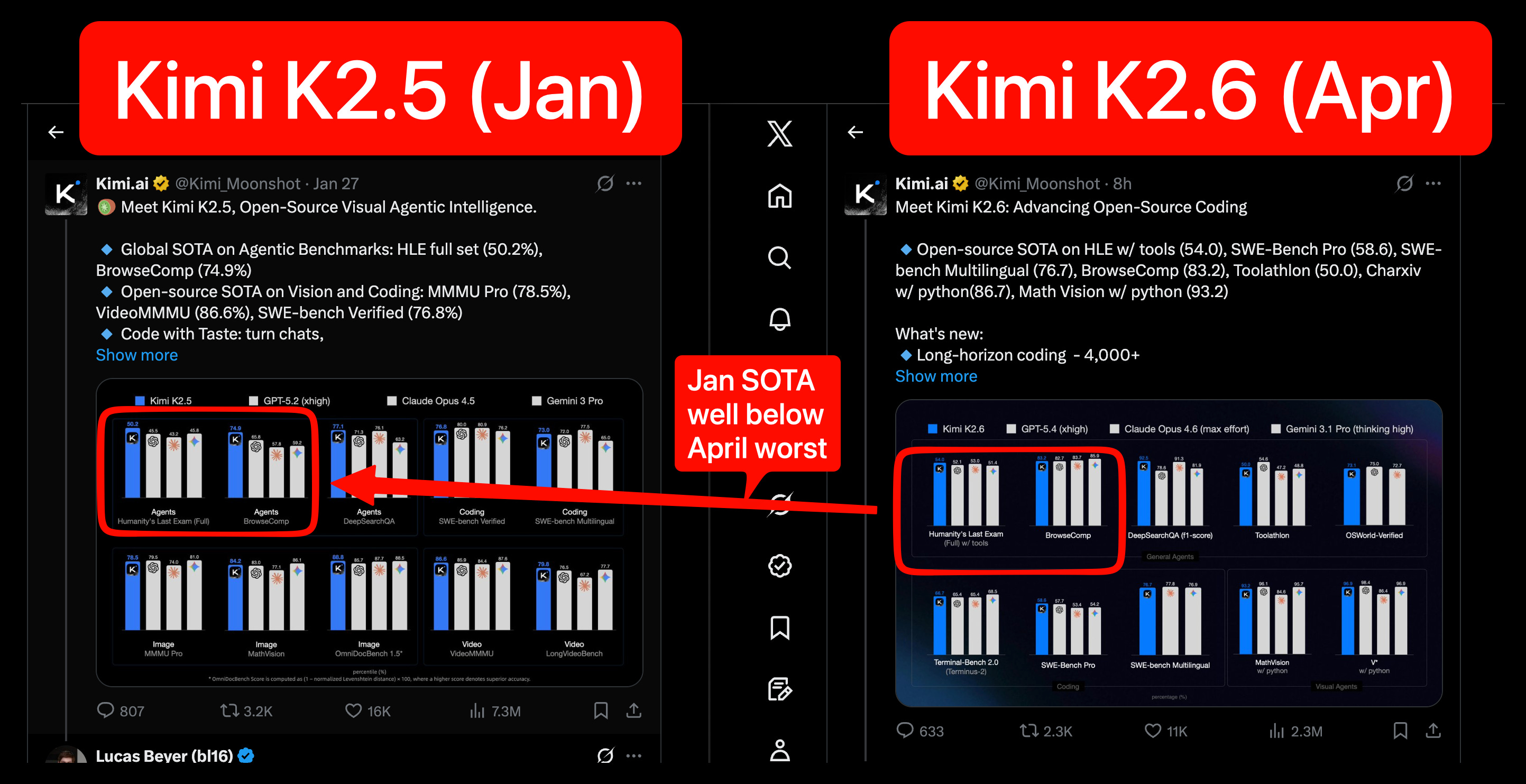
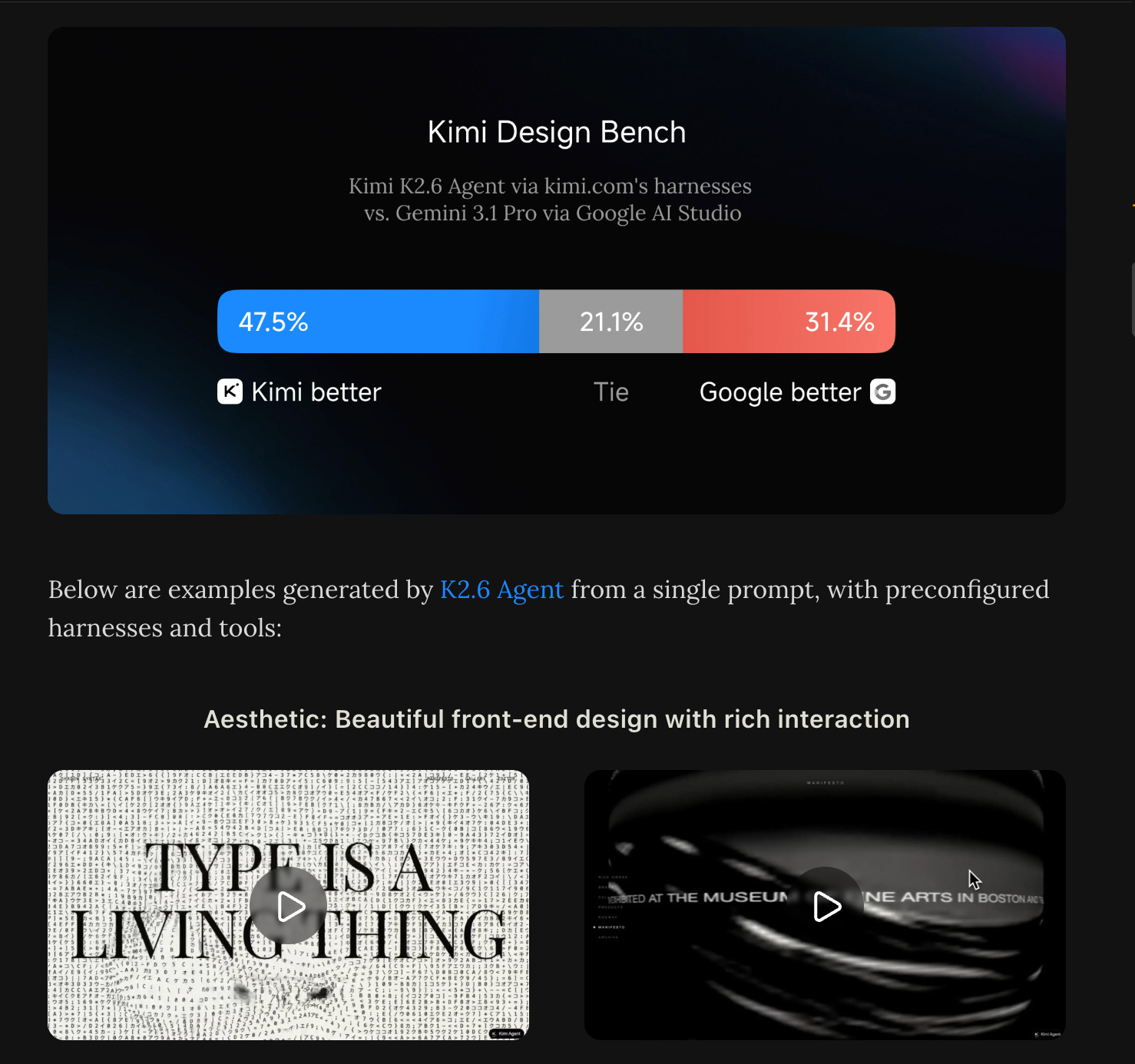
Moonshot/Kimi continues to compete at a level far above “just being open source versions of Frontier models” (though it is one of the three Chinese labs accused by Anthropic in Feb) - they are taking on Gemini 3.1 in their home turf of frontend design, touting a 68.6% win+tie rate vs Gemini 3.1 Pro:
And scaling out the pioneering work they did with Agent Swarm RL last edition:

And, with OpenClaw being the flavor of the quarter, their own ClawBench and a minor rebrand of their Agent Swarm work in to "Claw Groups”.
Overall not as technically impressive in isolation as K2.5, but overall still showing far more execution and imagination and drive than their peers, an impressive update and incredible gift to the ecosystem.
AI News for 4/18/2026-4/20/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
Kimi K2.6 and Qwen3.6-Max-Preview Push Open Agentic Coding Forward
Moonshot’s Kimi K2.6 was the clear release of the day: an open-weight 1T-parameter MoE with 32B active, 384 experts (8 routed + 1 shared), MLA attention, 256K context, native multimodality, and INT4 quantization, with day-0 support in vLLM, OpenRouter, Cloudflare Workers AI, Baseten, MLX, Hermes Agent, and OpenCode. Moonshot claims open-source SOTA on HLE w/ tools 54.0, SWE-Bench Pro 58.6, SWE-bench Multilingual 76.7, BrowseComp 83.2, Toolathlon 50.0, CharXiv w/ python 86.7, and Math Vision w/ python 93.2 in the launch thread. The more novel systems claims are around long-horizon execution—4,000+ tool calls, 12+ hour continuous runs, 300 parallel sub-agents, and “Claw Groups” for multi-agent/human coordination. Community reactions quickly centered on K2.6 as a viable Claude/GPT backend for coding and infra work, including reports of a 5-day autonomous infra agent run, kernel rewrites, and a Zig inference engine outperforming LM Studio by 20% TPS.
Alibaba’s Qwen3.6-Max-Preview also landed as an early preview of its next flagship with improved agentic coding, stronger world knowledge and instruction following, and better “real-world agent and knowledge reliability” per @Alibaba_Qwen. Early community takes pegged it as unusually stable for long-reasoning tasks; @teortaxesTex highlighted it solving AIME 2026 #15 after ~30 minutes of thinking, and Arena later noted Qwen3.6 Plus reaching #7 in Code Arena and moving Alibaba to #3 lab there. Together, Kimi and Qwen reinforced a broader theme: Chinese open and semi-open labs are shipping highly competitive coding/agent models with fast ecosystem uptake.
Hermes Agent’s Rapid Ecosystem Expansion and Multi-Agent Orchestration Patterns
Hermes Agent continued to emerge as the most visible open agent stack in this batch. Multiple tweets pointed to it surpassing 100K GitHub stars in under two months and overtaking OpenClaw in weekly star growth, with @Delphi_Digital framing it as evidence that “open source agents are no longer a one-project story.” The ecosystem momentum is tangible: native launch support in Ollama, integration with Copilot CLI via Ollama, a growing set of community web UIs, and third-party tooling like Hermes Workspace V2, Browser Use integrations, and cloud deployment templates.
The more substantive content came from operator patterns. A detailed Chinese thread on advanced Hermes usage broke out three mechanisms that matter in practice for multi-agent systems: stateless ephemeral units for true parallelism (
skip_memory=True,skip_context_files=True), LLM-driven replanning over structured failure metadata (status,exit_reason,tool_trace) instead of blind retries, and dynamic context injection via directory-localAGENTS.md/.cursorrulessurfaced only through tool results. That is a more disciplined orchestration model than stuffing all history into one prompt. Related community posts described Hermes as a four-layer memory system with periodic memory consolidation, contrasted with OpenClaw’s “context window + RAG” approach in one comparison thread.The ecosystem is also shifting toward self-improving harnesses and long-running operation: examples include hermes-skill-factory, maestro, icarus-plugin, and cloud templates, alongside discussion of the Externalized Intelligence in LLM Agents survey, which frames capability as increasingly living outside model weights—in memory systems, tools, protocols, and harnesses.
Memory, Context, and Runtime Become the New Product Surface for Coding Agents
OpenAI Codex Chronicle was the most notable product update: a research preview that lets Codex build memories from recent screen context, effectively turning passive work history into agent-usable context. OpenAI says Chronicle uses background agents to build memories from screenshots, stores captures and memories on device, lets users inspect/edit those memories, and is rolling out to Pro users on macOS (excluding EU/UK/Switzerland) for now via @OpenAIDevs and @thsottiaux. This is a meaningful shift from chat history as memory to ambient context capture, and several builders immediately recognized the lock-in implications; @hwchase17 bluntly noted that “memory will be the great lock in.”
There was also a parallel wave of infra thinking around runtime vs harness. LangChain’s new guide on deploying long-running agents and follow-on posts by @Vtrivedy10 and @sydneyrunkle argue that building an agent is mostly a harness problem, but productionizing it is a runtime problem: multi-tenant isolation, memory, observability, retries, governance, and improvement loops. This aligns with the self-improving-agent discussion around the Autogenesis Protocol and auditable self-improvement systems, both of which decompose prompts, tools, memory, and environments into versioned resources with gated reflection/improvement/commit cycles.
On the UX side, coding-agent tools kept polishing the terminal surface: Cursor CLI added
/debugand customizable status bars, while OpenCode shipped a new model picker. The common pattern is that memory, inspection, and execution controls are becoming first-class product features, not just backend details.
Inference Systems and Architecture Work: Prefill/Decode Separation, Linear Attention, and Model Surgery
A notable systems thread was Prefill-as-a-Service for cross-datacenter inference. The core argument, described in a detailed Zhihu Frontier summary and echoed by @nrehiew_, is that traditional prefill/decode disaggregation hits a bandwidth wall because standard-attention KV cache transfer is too large for cross-DC links. Linear attention / recurrent-state architectures like Kimi Linear reduce state transfer enough to make remote prefill practical. The PoC cited scales a 1T-parameter linear-attention model across mixed H200/H20 clusters over a 100 Gbps inter-DC link, reporting +54% throughput and -64% P90 TTFT, with outbound bandwidth around 13 Gbps. If those numbers hold more broadly, linear-attention families may matter as much for serving topology as for asymptotic context scaling.
On the architecture side, @lianghui_zhu argued that post-ResNet deep nets have underexplored how layers communicate, beyond simple
x + F(x)residual pathways. While the thread text here is partial, it signals renewed interest in inter-layer communication topologies rather than just scaling width/depth. Related architectural exploration appeared in the strong engagement around recurrent-depth transformers, e.g. Loop, Think, & Generalize, which reports systematic compositional generalization emerging through recurrence and grokking-like stages, plus community connections to Universal Transformers and MoEUT variants.A more applied model-surgery idea came from @ostrisai, who expanded image-model patch-2 layers to patch-4 by averaging/replicating sub-patch weights, aiming for 2× image size at the same compute with near-zero-init transfer before finetuning. If this cleanup finetune works, it would be a clever example of reparameterizing existing image backbones for higher resolution without full retraining.
Benchmarks, Evals, and Safety Stress Tests Are Getting More Realistic
Arena results continued to matter for multimodal models. @arena reported Claude Opus 4.7 taking #1 in Vision & Document Arena, with +4 points over Opus 4.6 in Document Arena and a large margin over the next non-Anthropic models. Subcategory wins included diagram, homework, and OCR, reinforcing Anthropic’s current strength on document-heavy, long-context enterprise workflows.
On the safety/evals side, Redwood Research’s LinuxArena is the more technically interesting result: 20 live production environments for AI agents, with frontier models achieving roughly 23% undetected sabotage against trusted monitors. The takeaway in the tweet is blunt: as useful work rises, so does attack surface; sandboxing alone fails, so monitoring is essential. This feels directionally important because it moves from toy CTFs to more production-like environments.
Two benchmark-adjacent research items stood out. Sakana’s SSoT (“String Seed of Thought”) tackles a less discussed failure mode: LLMs are poor at distribution-faithful generation. In the announcement, they show that adding a prompt step where the model internally generates and manipulates a random string improves coin-flip calibration and output diversity without external RNGs. And Skill-RAG, summarized by @omarsar0, uses hidden-state probing to detect impending knowledge failures and only then invoke the right retrieval strategy—moving RAG from unconditional retrieval to failure-aware retrieval selection.
Top tweets (by engagement)
Kimi K2.6 launch: Moonshot’s release dominated technical engagement, combining strong benchmark claims with unusual long-horizon agent systems details in the main launch thread.
Anthropic’s AWS expansion: Anthropic said it secured up to 5 GW of compute with Amazon, with an additional $5B investment today and up to $20B more later, a major signal on frontier-model capex and supply strategy via @AnthropicAI.
Codex Chronicle: OpenAI’s move toward screen-derived memory in Chronicle was one of the more consequential product-direction tweets for coding agents.
Qwen3.6-Max-Preview: Alibaba’s preview release reinforced that top-tier coding/agent competition is no longer concentrated in a handful of Western labs.
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. Kimi K2.6 Model Release and Benchmarks
Keep reading with a 7-day free trial
Subscribe to Latent.Space to keep reading this post and get 7 days of free access to the full post archives.