

[AINews] NVIDIA GTC: Jensen goes hard on OpenClaw, Vera CPU, and announces $1T sales backlog in 2027
a quiet day lets us reflect on NVIDIA GTC 2026
It is NVIDIA GTC day again, and over his signature 2hr unrehearsed keynote, Jensen gave updates on the entire NVIDIA universe and ecosystem and celebrated his InferenceMAX champions belt. As one might expect, Blackwell and Rubin are selling very very well (some accounting is necesary), and now Vera:
The final section of the keynote was focused on OpenClaw, where Jensen went extremely hard in complimenting it and then pointed out the security issues, then pitched his solution, NemoClaw:

NVIDIA moves at impressive speed for a $4T company, and we had some of their next generation leaders on the pod to give more insight on how NVIDIA works this fast:
AI News for 3/14/2026-3/16/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
Architecture Research: Moonshot’s Attention Residuals and the Debate Around Prior Art
Moonshot’s
Attention Residualspaper was the clearest technical story in the feed: @Kimi_Moonshot introduced a replacement for fixed residual accumulation with input-dependent attention over prior layers, plus Block AttnRes to keep cross-layer attention practical. Claimed results: 1.25x compute advantage, <2% inference latency overhead, validated on Kimi Linear 48B total / 3B active; follow-up posts highlighted improved hidden-state magnitude control and more uniform gradients across depth (paper thread, paper link). The release triggered strong positive reactions from practitioners and researchers including @Yuchenj_UW, @elonmusk, @nathancgy4, and multiple visual explainers such as @eliebakouch and @tokenbender.The interesting second-order discussion was whether this is new, or “new at scale”: @behrouz_ali argued the idea substantially overlaps with prior work like DeepCrossAttention, criticizing missing citations and broader ML novelty inflation; @cloneofsimo made a similar point that Google had explored related ideas earlier, while others countered that the systems work and scaling evidence matter as much as the core intuition (context, more context). Net: the paper mattered both as an architectural proposal and as a live example of the field’s ongoing tension between idea novelty, citation quality, and frontier-scale validation.
Coding Agents, Harnesses, and Skills Infrastructure
OpenAI’s Codex momentum showed up repeatedly: OpenAI Devs promoted a Codex x Notion event, while company posts and leadership commentary emphasized fast adoption. @fidjissimo said Codex is at 2M+ weekly active users, up nearly 4x YTD, with OpenAI also building a deployment arm for enterprise rollout. @sama added that “hardcore builders” are switching to Codex, and @gdb said GPT-5.4 reached 5T tokens/day within a week and a $1B annualized run-rate in net-new revenue. Product-wise, Codex also added subagents, reinforcing the shift toward multi-agent coding workflows.
The infrastructure layer around coding agents is maturing fast: @AndrewYNg expanded Context Hub / chub, an open CLI for current API docs that now supports agent feedback loops on documentation. @AssemblyAI shipped a maintained skill for Claude Code, Codex, Cursor, and compatible agents so they can use current API patterns rather than stale training priors. @dair_ai highlighted a paper on automated extraction of agent skills from GitHub repos into standardized
SKILL.md, with claimed 40% knowledge-transfer gains. Together these point toward a new agent tooling stack: skills files, up-to-date docs, feedback channels, and repo-mined procedural knowledge.LangChain pushed further into “agent harness engineering”: @LangChain launched LangGraph CLI for terminal-based deploy/dev flows, and the ecosystem open-sourced Deep Agents, framed by @itsafiz and @simplifyinAI as an MIT-licensed recreation of the workflow behind top coding agents: planning/todos, filesystem ops, shell access, sub-agents, and context management. Internally, @Vtrivedy10 said this is also the base for production agent work and evals. The notable pattern is that teams are no longer just shipping models; they’re shipping reference harnesses.
Open-Source Agents: Hermes’ Breakout, OpenClaw Integrations, and Agent UX
Hermes Agent had a strong community cycle: hackathon projects spanned home media automation (@rodmarkun’s anime server tool), cyber tooling (@aylacroft), geopolitics/OSINT forecasting (@WeXBT), and research visualization (@t105add4_13). User sentiment was consistently that Hermes is easier to set up and more robust than OpenClaw: see @Zeneca, @fuckyourputs, @austin_hurwitz, and @0xMasonH. @Teknium also posted setup guides like enabling Honcho memory.
OpenClaw still expanded its ecosystem despite the Hermes comparisons: @ollama announced Ollama as an official provider for OpenClaw; Comet launched an observability plugin for tracing calls/tools/costs; and there were third-party mods like NemoClaw. The broader takeaway is less “winner takes all” and more that open agents are starting to resemble classic software ecosystems: providers, memory backends, tracing, onboarding guides, and hackathon-driven extensions.
Model and Product Releases: Perplexity Computer, Gemini Embeddings, Mistral/Minimax Signals
Perplexity’s
Computerrollout was the most concrete end-user agent launch: @AravSrinivas and @perplexity_ai announced Computer on Android, then extended it so Computer can control Comet and use the local browser as a tool without connectors/MCPs, with local cookies preserved and user visibility into actions (details, implementation note). This is notable because it broadens agentic execution from cloud integrations to permissioned local browser control.Google added a foundational multimodal primitive: @Google launched Gemini Embedding 2 in public preview via Gemini API and Vertex AI, positioned as a single embedding space across text, image, video, and audio, supporting 100+ languages. This is the kind of release that may end up more consequential for production search/retrieval systems than another frontier-chat model benchmark.
Other model and release signals worth noting: @matvelloso praised gemini-3.1-flash-lite-preview on price × latency × intelligence; @QuixiAI reverse-engineered Qwen 3.5 FP8 and also got Qwen3.5-397B-FP8 running on 8× MI210 at 6 tok/s (run note); @AiBattle_ and @kimmonismus pointed to MiniMax 2.7 appearing imminent; @scaling01 surfaced Leanstral as part of Mistral Small 4; and @SeedFold launched SeedProteo for diffusion-based de novo all-atom protein design.
Systems, Inference, and Graphics: GTC, Speculative Decoding, and DLSS 5
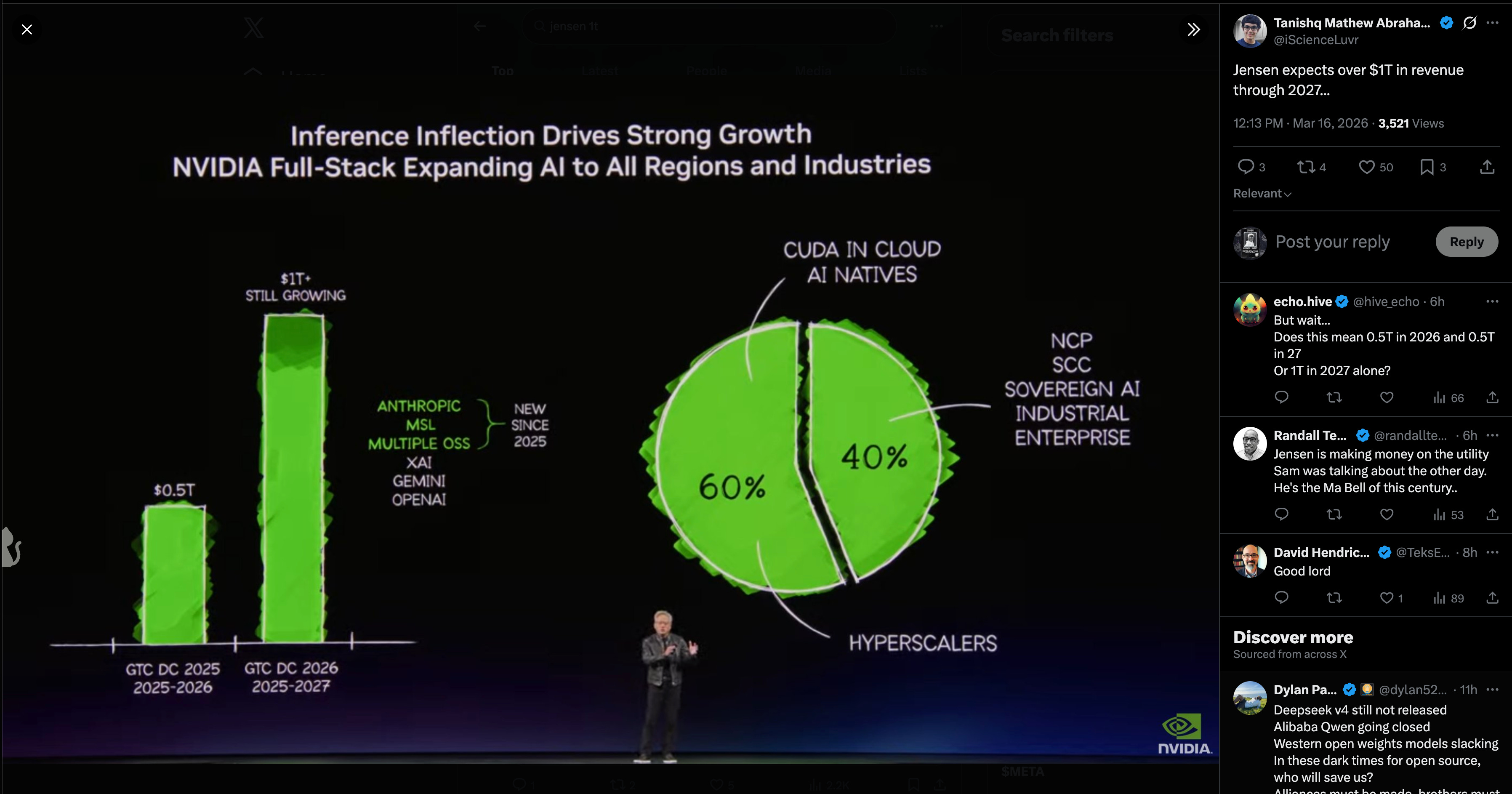
NVIDIA GTC’s message was unequivocal: the center of gravity is inference. Jensen’s framing of the “inference inflection point” was widely repeated (@basetenco quote), alongside ecosystem positioning posts from @nvidia, @kimmonismus, and others. Several infra-adjacent updates landed around the conference: vLLM’s OCI production-stack guide, and a strong systems contribution in P-EAGLE, which removes the sequential bottleneck in speculative decoding by generating K draft tokens in one pass, with reported up to 1.69x speedup over EAGLE-3 on B200 and integration in vLLM v0.16.0.
On the graphics side, DLSS 5 dominated reactions: NVIDIA positioned it as the biggest graphics leap since real-time ray tracing, with strong reactions from @ctnzr, @GeForce_JacobF, and Digital Foundry-linked discussion. The key technical claim is fully generative neural rendering / relighting with original geometry/assets preserved, pushing visual fidelity materially forward in real time. Not directly an LLM story, but very much part of the broader trend toward neuralized runtime systems.
AI in Science, Healthcare, and Security
The most substantive science/health post was Microsoft’s GigaTIME thread: @AnishA_Moonka summarized work from Microsoft, Providence, and UW where a model predicts multiplex immunofluorescence-style spatial proteomics from a $5 pathology slide, trained on 40M cells, applied to 14,256 patients across 51 hospitals, producing ~300k virtual protein maps and surfacing 1,234 validated associations. The thread claims the model is open-source and argues this could democratize cancer immune profiling at scale.
Other technically meaningful science/safety items: @GoogleResearch described a study evaluating LLMs on high-temperature superconductivity reasoning, claiming curated closed-system models outperform web-heavy setups for scientific work; @AISecurityInst evaluated seven frontier models on cyber ranges for autonomous attack capability; and @askalphaxiv highlighted LeCun’s Temporal Straightening for Latent Planning, where straightening latent trajectories improves planning stability by making Euclidean distance better track reachable progress.
Top tweets (by engagement)
Healthcare foundation-model impact: GigaTIME pathology → spatial proteomics thread was the highest-signal high-engagement technical post.
Architecture innovation: Moonshot’s Attention Residuals release drew exceptional engagement and broad expert discussion.
Coding agent product momentum: @sama on Codex growth and @gdb on GPT-5.4 API ramp were the clearest demand-side signals.
Open agent ecosystem: Ollama becoming an OpenClaw provider was one of the largest open-agent infra announcements by engagement.
Agent knowledge infrastructure: @AndrewYNg on Context Hub stood out as a concrete proposal for agent-to-agent documentation sharing.
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
Keep reading with a 7-day free trial
Subscribe to Latent.Space to keep reading this post and get 7 days of free access to the full post archives.