

[AINews] Qwen Image 2 and Seedance 2
Strong generative media showings from China
AI News for 2/9/2026-2/10/2026. We checked 12 subreddits, 544 Twitters and 24 Discords (256 channels, and 9107 messages) for you. Estimated reading time saved (at 200wpm): 731 minutes. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
It is China model release week before Valentine’s Day, and the floodgates are opening.
We last got excited about Qwen-Image 1 in August, and in the meantime the Qwen guys have been cooking, with Image-Edit and Layers. Today with Qwen-Image 2 they reveal the grand unification:
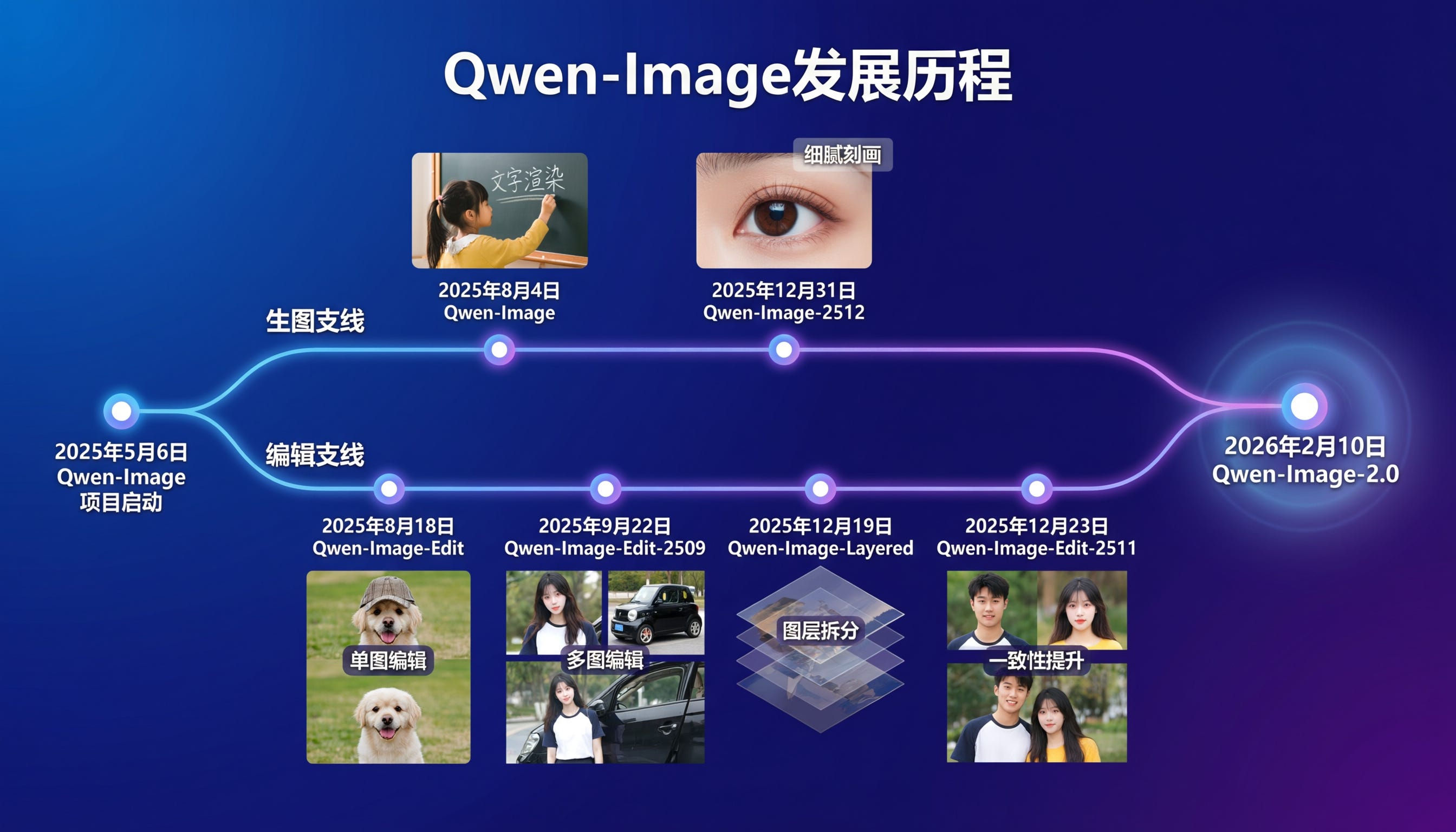
The text control and fidelity demonstrated is incredibly impressive. While the weights and full technical report are not yet released, the images drop a few surprising hints (caught by the Reddit sleuths in the recap below) about what’s going on that point to incredible technical advances.
To put it simply, we will have a Nano-Banana-level open imagegen/imageedit model in a 7B size. (Per Alibaba’s own Arena rankings on the blogpost)

Similarly no weights released but lots of hype today is Seedance 2.0, which seems to have solved the Will Smith Spaghetti problem and also generated lots of anime/movie scenes. The sheer flood of examples is almost certainly an astroturfing campaign, but enough people are independently creating new videos that we have some confidence that this isn’t just a cherrypick.
AI Twitter Recap
Coding agents, IDE workflows, and “agentic sandboxes” becoming standard plumbing
OpenAI shifts Responses API toward long-running computer work: OpenAI introduced new primitives aimed at multi-hour agent runs: server-side compaction (to avoid context blowups), OpenAI-hosted containers with networking, and Skills as a first-class API concept (including an initial spreadsheets skill) (OpenAIDevs). In the same window, OpenAI also upgraded Deep Research to GPT‑5.2 and added connectors + progress controls (OpenAI, OpenAI), reinforcing that “research agents” are productized, not just demos.
Sandboxes: “agent in sandbox” vs “sandbox as a tool” becomes a design fault line: Several posts converge on the same architectural question—should the agent live inside an execution environment, or should it call an ephemeral sandbox tool? LangChain’s Harrison Chase summarized tradeoffs in a dedicated writeup (hwchase17), with follow-on commentary pushing sandbox-as-a-tool as the default for crash tolerance and long-running workflows (NabbilKhan). LangChain’s deepagents v0.4 added pluggable sandbox backends (Modal/Daytona/Runloop) plus improved summarization/compaction and Responses API defaults (sydneyrunkle).
Coding agent UX is accelerating, with multi-model orchestration becoming normal: VS Code and Copilot continue to add agent primitives (worktrees, MCP apps, slash commands) (JoeCuevasJr). One concrete pattern: parallel subagents doing independent review and “grading each other” across Claude Opus 4.6, GPT‑5.3‑Codex, and Gemini 3 Pro (pierceboggan). OpenAI’s Codex account paused a rollout of “GPT‑5.3‑Codex” inside @code (code), while users highlight its token efficiency and app workflow (reach_vb, gdb, gdb).
“SDLC after code review” is being reimagined: A notable funding + product announcement: EntireHQ raised a $60M seed to build a Git-compatible database that versions not just code but also intent/constraints/reasoning, plus “Checkpoints” to capture agent context (prompts, tool calls, token usage) as commit-adjacent artifacts (ashtom). This directly targets the emerging pain: teams can generate code quickly, but struggle with provenance, review, coordination, and “what happened” debugging.
Model releases & modality leaps (image/video/omni) + open-model momentum
Qwen-Image-2.0: Alibaba Qwen announced Qwen‑Image‑2.0 with emphasis on 2K native resolution, strong text rendering, and “professional typography” for posters/slides with up to 1K-token prompts; also positions itself as unified generation + editing with a “lighter architecture” for faster inference (Alibaba_Qwen).
Seedance 2.0 as the “step change” in text-to-video: Multiple threads treat ByteDance’s Seedance 2.0 as a qualitative jump (natural motion, micro-details) and possibly a forcing function for competitors to refresh (Veo/Sora) (kimmonismus, TomLikesRobots, kimmonismus).
Kimi “Agent Swarm” + Kimi K2.5 as agent substrate: Moonshot’s Kimi shipped an Agent Swarm concept: up to 100 sub-agents, 1500 tool calls, and claimed 4.5× faster than sequential execution for parallel research/creation tasks (Kimi_Moonshot). Community posts show a workflow pairing Kimi K2.5 + Seedance 2 to generate large storyboard artifacts (e.g., “100MB Excel storyboard”) feeding video generation (crystalsssup). Baseten highlighted Kimi K2.5 serving performance—TTFT 0.26s and 340 TPS on Artificial Analysis (per their claim) (basetenco).
Open multimodal “sleepers”: A curated reminder that recent open multimodal releases include GLM‑OCR, MiniCPM‑o‑4.5 (phone-runnable omni), and InternS1 (science-strong VLM), all described as freely usable commercially (mervenoyann).
GLM-4.7-Flash traction: Zhipu’s GLM‑4.7‑Flash‑GGUF became the most downloaded model on Unsloth (per Zhipu) (Zai_org).
Agent coordination & evaluation: from “swarms” to measurable failure modes
Cooperation is still brittle even with real tools (git): CooperBench added git to paired agents and found only marginal cooperation gains; new failure modes emerged (force-pushes, merge clobbers, inability to reason about partner’s real-time actions). The thesis: infra ≠ social intelligence (_Hao_Zhu).
Dynamic agent creation beats static roles (AOrchestra): DAIR summarized AOrchestra, where an orchestrator spawns on-demand subagents defined as a 4‑tuple (Instruction/Context/Tools/Model). Reported benchmark gains: GAIA 80% pass@1 with Gemini‑3‑Flash; Terminal‑Bench 2.0 52.86%; SWE‑Bench‑Verified 82% (dair_ai).
Data agents taxonomy: Another DAIR piece argues “data agents” need clearer levels of autonomy (L0–L5), noting most production systems sit at L1/L2; L4/L5 remain unsolved due to cascading-error risk and dynamic environment adaptation (dair_ai).
Arena pushes evals closer to enterprise reality (PDFs + funding academia): Arena launched PDF uploads for model comparisons (document reasoning, extraction, summaries) (arena), and separately announced an Academic Partnerships Program funding independent eval research (up to $50K/project) (arena). This aligns with ongoing frustration that peer review is too slow relative to model iteration (kevinweil, gneubig).
Anthropic RSP critique on Opus 4.6 thresholding: A detailed critique argues Anthropic relied too heavily on internal employee surveys to decide whether Opus 4.6 crossed a higher-risk R&D autonomy threshold; the complaint is that this is not a responsible substitute for quantitative evals, and follow-ups may bias results (polynoamial).
Training/post-training research themes: RL self-feedback, self-verification, and “concept-level” modeling
iGRPO: RL from the model’s own best draft: iGRPO wraps GRPO with a two-stage process: sample drafts, pick the highest-reward draft (same scalar reward), then condition on that draft and train to beat it—no critics, no generated critiques. Reported improvements over GRPO across 7B/8B/14B families (ahatamiz1, iScienceLuvr).
Self-verification as a compute reducer: “Learning to Self-Verify” is highlighted as improving reasoning while using fewer tokens to solve comparable problems (iScienceLuvr).
ConceptLM / next-concept prediction: A proposal to quantize hidden states into a concept vocabulary and predict concepts instead of next tokens; claims consistent gains and that continual pretraining on an NTP model can further improve it (iScienceLuvr).
Scaling laws from language statistics: Ganguli shared a theory result: predict data-limited scaling exponents from properties of natural language (conditional entropy decay vs context length; pairwise token correlation decay vs separation) (SuryaGanguli).
Architectures leaking via OSS archaeology: A notable “architecture is out” thread claims GLM‑5 is ~740B with ~50B active, using MLA attention “lifted from DeepSeek V3” plus sparse attention indexing for 200k context (QuixiAI). Another claims Qwen3.5 is a hybrid SSM‑Transformer with Gated DeltaNet linear attention + standard attention, interleaved MRoPE, and shared+routed MoE experts (QuixiAI).
Inference & systems engineering: faster kernels, cheaper parsing, and vLLM debugging
Unsloth’s MoE training speedup: Unsloth claims new Triton kernels enable 12× faster MoE training with 35% less VRAM and no accuracy loss, plus grouped LoRA matmuls via
torch._grouped_mm(and fallback to Triton for speed) (UnslothAI, danielhanchen).Instruction-level Triton + inline assembly: A fal performance post teases beating handwritten CUDA kernels by adding small inline elementwise assembly in Triton; the author also notes a custom CUDA kernel using 256-bit global memory loads (Blackwell) outperforming Triton on smaller shapes (maharshii, isidentical, maharshii).
vLLM in production: throughput tuning + rare failure debugging: vLLM amplified AI21’s writeups: config tuning + queue-based autoscaling yielded ~2× throughput for bursty workloads (vllm_project); a second post dissected a 1-in-1000 gibberish failure in vLLM + Mamba traced to request classification timing under memory pressure (vllm_project).
Document ingestion cost optimization: LlamaIndex’s LlamaParse added a “cost optimizer” routing pages to cheaper parsing when text-heavy and to VLM modes for complex layouts, claiming 50–90% cost savings vs screenshot+VLM baselines, with higher accuracy (jerryjliu0).
Local/distributed inference hacks: An MLX Distributed helper repo reportedly ran Kimi K‑2.5 (658GB on disk) across a 4× Mac Studio cluster over Thunderbolt RDMA, “actually scales” (digitalix).
AI-for-science: Isomorphic Labs’ drug design engine as the standout “real-world benchmark win”
IsoDDE claims large gains beyond AlphaFold 3: Isomorphic Labs posted a technical report claiming a “step-change” in predicting biomolecular structures, more than doubling AlphaFold 3 on key benchmarks and improving generalization; several posts echo the scale of claimed gains and implications for in‑silico drug design (IsomorphicLabs, maxjaderberg, demishassabis). Commentary highlights antibody interface/CDR‑H3 improvements and affinity prediction claims exceeding physics-based methods—while noting limited architectural detail so far (iScienceLuvr).
Why it matters (if it holds): The strongest framing across the thread cluster is not just “better structures,” but faster discovery loops: identifying cryptic pockets, better affinity estimates, and generalization to novel targets potentially move screening/design upstream of wet labs (kimmonismus, kimmonismus, demishassabis).
Top tweets (by engagement)
US scientists moving to Europe / research climate: @AlexTaylorNews (21,569.5)
Rapture derivatives joke: @it_is_fareed (16,887.5)
Obsidian CLI “Anything you can do in Obsidian…”: @obsdmd (13,408.0)
Political speculation tweet: @showmeopie (34,648.5)
“Kubernetes at dinner”: @pdrmnvd (6,146.5)
OpenAI Deep Research now GPT‑5.2: @OpenAI (3,681.0)
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. Qwen Model Releases and Comparisons
Qwen-Image-2.0 is out - 7B unified gen+edit model with native 2K and actual text rendering (Activity: 600): Qwen-Image-2.0 is a new 7B parameter model released by the Qwen team, available via API on Alibaba Cloud and a free demo on Qwen Chat. It combines image generation and editing in a single pipeline, supports native 2K resolution, and can render text from prompts up to 1K tokens, including complex infographics and Chinese calligraphy. The model’s reduced size from 20B to 7B makes it more accessible for local use, potentially runnable on consumer hardware once weights are released. It also supports multi-panel comic generation with consistent character rendering. Commenters are optimistic about the model’s potential, noting improvements in natural lighting and facial rendering, and expressing hope for an open weight release to enable broader community use.
The Qwen-Image-2.0 model is notable for its ability to generate and edit images with a unified 7B parameter architecture, supporting native 2K resolution and text rendering. This is a significant advancement as it combines both generation and editing capabilities in a single model, which is not commonly seen in other models of similar scale.
There is a discussion about the model’s performance in rendering natural light and facial features, which are often challenging for AI models. The commenter notes that Qwen-Image-2.0 has made significant improvements in these areas, potentially making it a ‘game changer’ in the field of AI image generation.
A concern is raised about the model’s multilingual capabilities, particularly whether the focus on Chinese examples might impact its performance in other languages. This highlights a common challenge in AI models where training data diversity can affect the model’s generalization across different languages and cultural contexts.
Do not Let the “Coder” in Qwen3-Coder-Next Fool You! It’s the Smartest, General Purpose Model of its Size (Activity: 837): The post discusses the capabilities of Qwen3-Coder-Next, a local LLM, highlighting its effectiveness as a general-purpose model despite its ‘coder’ label. The author compares it favorably to Gemini-3, noting its consistency and pragmatic problem-solving abilities, which make it suitable for stimulating conversations and practical advice. The model is praised for its ability to suggest relevant authors, books, or theories unprompted, offering a quality of experience similar to Gemini-2.5/3 but locally run. The author anticipates further improvements with the upcoming Qwen-3.5 models. Commenters agree that the ‘coder’ tag enhances the model’s structured reasoning, making it surprisingly effective for general-purpose use. Some note its ability to mimic the tone of other models like GPT or Claude, depending on the tools used, and recommend it over other local models like Qwen 3 Coder 30B-A3B.
2. Local LLM Trends and Hardware Considerations
Is Local LLM the next trend in the AI wave? (Activity: 330): The post discusses the emerging trend of running Local Large Language Models (LLMs) as a cost-effective alternative to cloud-based subscriptions. The conversation highlights the potential for local setups to offer benefits in terms of privacy and long-term cost savings, despite the initial high hardware investment (
$5k-$10k). The post anticipates a surge in tools and guides for easy local LLM setups. Commenters note that while local models are improving rapidly, they still lag behind cloud models in performance. However, the gap is closing, and local models may soon offer a viable alternative for certain applications, especially as small LLMs become more efficient. Commenters debate the practicality of local LLMs, with some arguing that the high cost of hardware limits their appeal, while others suggest that the rapid improvement of local models could soon make them a cost-effective alternative to cloud models. The discussion also touches on the diminishing returns of improvements in large cloud models compared to the rapid advancements in local models.
3. Mixture of Experts (MoE) Model Training Innovations
Train MoE models 12x faster with 30% less memory! (<15GB VRAM) (Activity: 365): The image illustrates the performance improvements of the Unsloth MoE Triton kernels, which enable training Mixture of Experts (MoE) models up to 12 times faster while using 30% less memory, requiring less than 15GB of VRAM. The graphs in the image compare speed and VRAM usage across different context lengths, demonstrating Unsloth’s superior performance over other methods. This advancement is achieved through custom Triton kernels and math optimizations, with no loss in accuracy, and supports a range of models including gpt-oss and Qwen3. The approach is compatible with both consumer and data center GPUs, and is part of a collaboration with Hugging Face to standardize MoE training using PyTorch’s new
torch._grouped_mmfunction. Some users express excitement about the speed and memory savings, while others inquire about compatibility with AMD cards and the time required for fine-tuning. Concerns about the stability and effectiveness of MoE training are also raised, with users seeking advice on best practices for training MoE models.spaceman_ inquires about the compatibility of the training notebooks with ROCm and AMD cards, which is crucial for users with non-NVIDIA hardware. They also ask about the time required for fine-tuning models using these notebooks, and the maximum model size that can be trained on a system with a combined VRAM of 40GB (24GB + 16GB). This highlights the importance of hardware compatibility and resource management in model training.
lemon07r raises concerns about the stability of Mixture of Experts (MoE) training on the Unsloth platform, particularly regarding issues with the router and potential degradation of model intelligence during training processes like SFT (Supervised Fine-Tuning) or DPO (Data Parallel Optimization). They seek updates on whether these issues have been resolved and if there are recommended practices for training MoE models, indicating ongoing challenges in maintaining model performance during complex training setups.
socamerdirmim questions the versioning of the GLM model mentioned, asking for clarification between GLM 4.6-Air and 4.5-Air or 4.6V. This reflects the importance of precise versioning in model discussions, as different versions may have significant differences in features or performance.
Bad news for local bros (Activity: 944): The image presents a comparison of four AI models: GLM-5, DeepSeek V3.2, Kimi K2, and GLM-4.5, highlighting their specifications such as total parameters, active parameters per token, attention type, hidden size, number of hidden layers, and more. The title “Bad news for local bros” implies that these models are likely too large to be run on local hardware setups, which is a concern for those without access to large-scale computing resources. The discussion in the comments reflects a debate on the accessibility of these models, with some users expressing concern over the inability to run them locally, while others see the open availability of such large models as beneficial for the community, as they can eventually be distilled and quantized for smaller setups. The comments reveal a split in opinion: some users are concerned about the inability to run these large models on local hardware, while others argue that the availability of such models is beneficial as they can be distilled and quantized for smaller, more accessible versions.
AutomataManifold argues that the availability of massive frontier models is beneficial for the community, as these models can be distilled and quantized into smaller versions that can run on local machines. This process ensures that even if open models are initially large, they can eventually be made accessible to a wider audience, preventing stagnation in model development.
nvidiot expresses a desire for the development of smaller, more accessible models alongside the larger ones, such as a ‘lite’ model similar in size to the current GLM 4.x series. This would ensure that local users are not left behind and can still benefit from advancements in model capabilities without needing extensive hardware resources.
Impossible_Art9151 is interested in how these large models compare with those from OpenAI and Anthropic, suggesting a focus on benchmarking and performance comparisons between different companies’ offerings. This highlights the importance of competitive analysis in the AI model landscape.
Less Technical AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Seedance 2.0 Video and Animation Capabilities
“Will Smith Eating Spaghetti” By Seedance 2.0 Is Mind Blowing! (Activity: 1399): Seedance 2.0 has achieved a significant milestone in video clip technology, referred to as the ‘nano banana pro moment.’ This suggests a breakthrough or notable advancement in video processing or effects, possibly involving AI or machine learning techniques. The reference to ‘Will Smith Eating Spaghetti’ implies a humorous or viral aspect, potentially using deepfake or similar technology to create realistic yet amusing content. Commenters humorously note the use of ‘Will Smith’ as a benchmark, highlighting the absurdity and entertainment value of the video, while also critiquing the realism of the eating animation, such as the exaggerated swallowing and unrealistic pasta wiping.
Kobe Bryant in Arcane Seedance 2.0, absolutely insane! (Activity: 832): The post discusses the integration of Kobe Bryant into the Arcane Seedance 2.0 AI model, highlighting its impressive capabilities. The model is noted for its ability to perform complex tasks with limited computational resources, suggesting the use of advanced algorithms. This aligns with observations that China maintains competitiveness in AI despite having less computational power, potentially due to superior algorithmic strategies. A comment suggests that the AI’s performance might be due to superior algorithms, reflecting a belief that China’s AI advancements are not solely reliant on computational power but also on innovative algorithmic approaches.
Seedance 2 anime fight scenes (Pokemon, Demon Slayer, Dragon Ball Super) (Activity: 1011): The post discusses the release of Seedance 2, an anime featuring fight scenes from popular series like Pokemon, Demon Slayer, and Dragon Ball Super. The source is linked to Chetas Lua’s Twitter, suggesting a showcase of animation quality that rivals or surpasses official studio productions. The mention of Pokemon clips having superior animation quality compared to the main anime highlights the technical prowess and potential of independent or fan-made animations. One comment humorously anticipates the potential for creating extensive anime series based on freely available online literature, reflecting on the democratization of content creation and distribution.
Seedance 2.0 Generates Realistic 1v1 Basketball Against Lebron Video (Activity: 2483): Seedance 2.0 has made significant advancements in generating realistic 1v1 basketball videos, showcasing improvements in handling acrobatic physics, body stability, and cloth simulation. The model demonstrates accurate physics without the ‘floatiness’ seen in earlier versions, suggesting a leap in the realism of AI-generated sports simulations. The video features multiple instances of Lebron James, raising questions about whether the footage is entirely AI-generated or if it overlays and edits original game film to replace players with AI-generated figures. Commenters are debating whether the video is purely AI-generated or if it involves overlaying AI-generated figures onto existing footage. The presence of multiple Lebron James figures suggests potential cloning or editing, which some find impressive if entirely generated by AI.
Seedance 2.0 can do animated fights really well (Activity: 683): Seedance 2.0 demonstrates significant advancements in generating animated fight sequences, showcasing its ability to handle complex animations effectively. However, the current implementation is limited to
15-secondclips, raising questions about the feasibility of extending this to longer durations, such asfive minutes. The animation quality is high, but there are minor issues towards the end of the sequence, as noted by users. Commenters are impressed with the animation quality but express frustration over the15-secondlimit, questioning when longer video generation will be possible.
2. Opus 4.6 Model Release and Impact
Opus 4.6 is finally one-shotting complex UI (4.5 vs 4.6 comparison) (Activity: 1515): Opus 4.6 has significantly improved its ability to generate complex UI designs in a single attempt compared to Opus 4.5. The user reports that while 4.5 required multiple iterations to achieve satisfactory results, 4.6 can produce ‘crafted’ outputs with minimal guidance, especially when paired with a custom interface design skill. However, 4.6 is noted to be slower, possibly due to more thorough processing. This advancement is particularly beneficial for those developing tooling or SaaS applications, as it enhances workflow efficiency. Some users report that Opus 4.6 does not consistently achieve ‘one-shot’ results for complex UI redesigns, indicating variability in performance. Additionally, there are aesthetic concerns about certain design elements, such as ‘cards with a colored left edge,’ which are perceived as characteristic of Claude AI.
Euphoric-Ad4711 points out that Opus 4.6, while improved, still struggles with ‘one-shotting’ complex UI designs, indicating that the term ‘complex’ is subjective and may vary in interpretation. This suggests that while Opus 4.6 has made advancements, it may not fully meet expectations for all users in terms of handling intricate UI tasks.
oningnag emphasizes the importance of evaluating AI models like Opus 4.6 not just on their ability to create UI, but on their capability to build enterprise-grade backends with scalable infrastructure and secure code. They argue that the real value lies in the model’s ability to handle backend complexities, rather than just producing visually appealing UI components.
Sem1r notes a specific design element in Opus 4.6, the ‘cards with a colored left edge bend,’ which they associate with Claude AI. This highlights a potential overlap or influence in design aesthetics between different AI models, suggesting that certain design features may become characteristic of specific AI tools.
Opus 4.6 eats through 5hr limit insanely fast - $200/mo Maxplan (Activity: 266): The user reports that the Opus 4.6 model on the $200/month Max plan from Anthropic is consuming the 5-hour limit significantly faster than the previous Opus 4.5 version. Specifically, the limit is reached in
30-35 minuteswith Agent Teams and1-2 hourssolo, compared to3-4 hourswith Opus 4.5. This suggests a change in token output per response or rate limit accounting. The user is seeking alternatives that maintain quality without the rapid consumption of resources. One commenter suggests that Opus 4.6 reads excessively, leading to rapid consumption of limits and context issues, recommending a switch back to Opus 4.5. Another user reports no issues with Opus 4.6, indicating variability in user experience.suprachromat highlights a significant issue with Opus 4.6, noting that it ‘constantly reads EVERYTHING,’ leading to rapid consumption of subscription limits. This version also frequently hits the context limit, causing inefficiencies. Users experiencing these issues are advised to switch back to Opus 4.5 using the command
/model claude-opus-4-5, as it reportedly handles directions better and avoids unnecessary token usage.mikeb550 provides a practical tip for users to monitor their token consumption in Opus by using the command
/context. This can help users identify where their token usage is being allocated, potentially allowing them to manage their subscription limits more effectively.atiqrahmanx suggests using a specific command
/model claude-opus-4-5-20251101to switch models, which may imply a versioning system or a specific configuration that could help in managing the issues faced with Opus 4.6.
3. Gemini AI Model Experiences and Issues
Hate to be one of those ppl but...the paid version of Gemini is awful (Activity: 359): The post criticizes the performance of Gemini Pro, a paid AI service from Google, after the discontinuation of AI Studio access. The user describes the model as significantly degraded, comparing it to a “high school student with a C average,” and notes that it adds irrelevant information and misinterprets tasks that previous versions handled well. This sentiment is echoed in comments highlighting issues like increased hallucinations and poor performance compared to alternatives like GitHub Copilot, which was able to identify and fix critical bugs that Gemini missed. Commenters express disappointment with Gemini Pro’s performance, noting its tendency to hallucinate and provide incorrect information. Some users have switched to alternatives like GitHub Copilot, which they find more reliable and efficient in handling complex tasks.
A user reported significant issues with the Gemini model, particularly its tendency to hallucinate. They described an instance where the model incorrectly labeled Google search results as being from ‘conspiracy theorists,’ highlighting a critical flaw in its reasoning capabilities. This reflects a broader concern about the model’s reliability for day-to-day tasks.
Another commenter compared Gemini unfavorably to other AI tools like Copilot and Cursor. They noted that while Gemini struggled with identifying critical bugs and optimizing code, Copilot efficiently scanned a repository, identified issues, and improved code quality by unifying logic and correcting variable names. This suggests that Gemini’s performance in technical tasks is lacking compared to its competitors.
A user mentioned that the AI Studio version of Gemini was superior to the general access app, implying that the corporate system prompt used in the latter might be negatively impacting its performance. This suggests that the deployment environment and configuration could be affecting the model’s effectiveness.
Anyone else like Gemini’s personality way more than gpt? (Activity: 334): The post discusses user preferences between Gemini and ChatGPT, highlighting that Gemini’s personality instructions are perceived as more balanced and humble compared to ChatGPT, which is described as “obnoxious” and overly politically correct. Users note that Gemini provides more factual responses and citations, resembling a “reasonable scientist” or “library,” while ChatGPT is more conversational. Some users customize Gemini’s personality to be sarcastic, enhancing its interaction style. Commenters generally agree that Gemini offers a more factual and less sycophantic interaction compared to ChatGPT, with some users appreciating the ability to customize Gemini’s tone for a more engaging experience.
TiredWineDrinker highlights that Gemini provides more factual responses and includes more citations compared to ChatGPT, which tends to be more conversational. This suggests that Gemini might be better suited for users seeking detailed and reference-backed information, whereas ChatGPT might appeal to those preferring a more interactive dialogue style.
ThankYouOle notes a difference in tone between Gemini and ChatGPT, describing Gemini as more formal and straightforward. This user also experimented with customizing Gemini’s responses to be more humorous, but found that even when attempting to be sarcastic, Gemini maintained a level of decorum, contrasting with ChatGPT’s more casual and playful tone.
Sharaya_ experimented with Gemini’s ability to adopt different tones, such as sarcasm, and found it effective in delivering responses with a distinct personality. This indicates that Gemini can be tailored to provide varied interaction styles, although it maintains a certain level of formality even when attempting humor.
AI Discord Recap
A summary of Summaries of Summaries by gpt-5.2
1. New Model Checkpoints, Leaderboards, and Rollouts
Opus Overtakes: Claude-opus-4-6-thinking Snags #1:
LMArenareportedClaude-opus-4-6-thinkinghit #1 in both Text Arena (1504) and Code Arena (1576) on the Arena leaderboard, with Opus 4.6 also taking #2 in Code and Opus 4.5 landing #3 and #5.The same announcement thread noted Image Arena now uses category leaderboards and removed ~15% of noisy prompts after analyzing 4M+ prompts, plus added PDF uploads across 10 models in “Image Arena improvements”.
Gemini Grows Up: Gemini 3 Pro Appears in A/B Tests: Members spotted a new Gemini 3 Pro checkpoint in A/B testing via “A new Gemini 3 Pro checkpoint spotted in A/B testing”, expecting a more refined version of Gemini 3.
Across communities comparing model behavior, users contrasted Gemini vs Claude reliability and privacy concerns (e.g., claims Gemini “actively looks at your conversations and trains on them”), while others debated Opus 4.6 vs Codex 5.3 for large-codebase consistency vs rapid scripting.
Deep Research Gets a New Engine: ChatGPT → GPT-5.2:
OpenAIDiscord shared that ChatGPT Deep Research now runs on GPT-5.2, rolling out “starting today,” with changes demoed in this video.Elsewhere, users questioned OpenAI’s timing (“why base it on 5.2 when 5.3 is right around the corner”) and speculated that Codex shipped first while the main model lagged.
2. Agentic Coding Workflows and Devtool Shakeups
Claude Code Goes Webby: Hidden --sdk-url Flag Leaks Out:
Stan Girardfound a hidden--sdk-urlflag in the Claude Code binary that turns the CLI into a WebSocket client, enabling browser/mobile UIs with a custom server as shown in his post.Builders tied this to broader “context rot“ mitigation patterns (e.g., CLAUDE.md/TASKLIST.md + /summarize//compact) and experiments with external memory + KV cache tradeoffs.
Cursor’s Composer 1.5 Discount Meets Auto-Mode Anxiety:
Cursorusers flagged Composer 1.5 at a 50% discount (screenshot link: pricing image) while arguing about price/perf and demanding clearer Auto Mode pricing semantics.The same community reported platform instability (auto-switching models, disconnects, “slow pool”) referenced via @cursor_ai status, and one user described a fully autonomous rig orchestrating CLI Claude Code sub-agents via tmux + keyboard emulation.
Configurancy Strikes Back: Electric SQL’s Recipe for Agent-Written Code:
Electric SQLshared patterns for getting agents to write higher-quality code in “configurancyspacemolt”, reframing agent output as something you constrain with explicit configuration and structure.Related threads compared workflow representations (”OpenProse“ for reruns/traces/budgets/guardrails) and warned that graph-running subagent DAGs can explode costs (one report: “blast $800” running an agent graph).
{kind=link}
3. Local LLM Performance, Training Acceleration, and Hardware Reality Checks
Unsloth Hits the Nitrous: 12× Faster MoE + Ultra Long Context RL:
UnslothAIannounced 12× faster and 35% less VRAM for MoE training in their X post and documented the method in “Faster MoE”, alongside Ultra Long Context RL in “grpo-long-context”.They also shipped a guide for using Claude Code + Codex with local LLMs (“claude-codex”) and pushed diffusion GGUF guidance (“qwen-image-2512”).
Laptop Flex: AMD H395 AI MAX Claims ~40 t/s on Qwen3Next Q4:
LM Studiousers highlighted an AMD laptop with 96GB RAM/VRAM and the H395 AI MAX chip hitting ~40 tokens/sec for Qwen3Next Q4, suggesting near-desktop-class performance.The same community benchmarked DeepSeek R1 (671B) at ~18 tok/s 4-bit on M3 Ultra 512GB but saw it drop to ~5.79 tok/s at 16K context, with a 420–450GB memory footprint discussion.
New Buttons, New Breakage: LM Studio Stream Deck + llama.cpp Jinja Turbulence: An open-source “LM Studio Stream Deck plugin” shipped to control LM Studio from Stream Deck hardware.
Separately, users traced weird outputs since
llama.cppb7756 to the new templating path and pointed at the ggml-org/llama.cpp repo as the likely source of jinja prompt-loading behavior changes.
4. Security, Abuse, and Platform Reliability (Jailbreaks, Tokens, API Meltdowns)
Jailbreakers Assemble: GPT-5.2 and Opus 4.6 Prompt Hunts:
BASI Jailbreakingusers continued hunting jailbreaks for GPT-5.2 (including “Thinking”), sharing GitHub profiles SlowLow999 and d3soxyephedrinei as starting points and discussing teaming up on new prompts (including using the canvas feature).For Claude Opus 4.6, they referenced the ENI method and a Reddit thread, “ENI smol opus 4.6 jailbreak”, plus a prompt-generation webpage built with Manus AI: ManusChat.
OpenClaw Opens Doors: “Indirect” Jailbreaks via Insecure Permissioning: Multiple threads argued the OpenClaw architecture makes models easier to compromise through insecure permissioning and a weak system prompt, enabling indirect access to sensitive info; one discussion linked the open-source project as context: geekan/OpenClaw.
In parallel, some proposed defense ideas like embeddings-based allowlists referencing “Application Whitelisting as a Malicious Code Protection Control”, while others warned that token-path classification across string space leads to “token debt.”
APIs on Fire: OpenRouter Failures + Surprise Model Switching:
OpenRouterusers reported widespread API failures (one: “19/20” requests failing) and top-up issues with “No user or org id found in auth cookie” during the outage window.Separately, users complained that OpenRouter’s model catalog changes could silently swap the model behind a context, while Claude+Gemini integrations hit 400 errors over invalid Thought signatures per the Vertex AI Gemini docs.
5. Infra, Funding, and Ecosystem Moves (Acquisitions, Grants, Hiring)
Modular Eats BentoML: “Code Once, Run Everywhere” Pitch: Modular announced it acquired BentoML in “BentoML joins Modular”, aiming to combine BentoML deployment with MAX/Mojo and run across NVIDIA/AMD/next-gen accelerators without rebuilding.
They also scheduled an AMA with Chris Lattner and Chaoyu Yang for Sept 16 on the forum: “Ask Us Anything”.
Arena Funds Evaluators: Academic Program Offers Up to $50k: Arena launched an Academic Partnerships Program offering up to $50,000 per selected project in their post, targeting evaluation methodology, leaderboard design, and measurement work.
Applications are due March 31, 2026 via the application form.
Kernel Nerds Wanted: Nubank Hires CUDA Experts for B200 Training:
GPU MODEshared that Nubank is hiring CUDA/kernel optimization engineers (Brazil + US) for foundation models trained on B200s, pointing candidates to email [email protected] and referencing a recent paper: arXiv:2507.23267.Hardware timelines also shifted as the Tenstorrent Atlantis ascalon-based dev board slipped to end of Q2/Q3, impacting downstream project schedules.