

[AINews] Sam Altman's AI Combinator
a quiet day in the news lets us reflect on Sama's town hall message this week
AI News for 1/27/2026-1/28/2026. We checked 12 subreddits, 544 Twitters and 24 Discords (206 channels, and 7100 messages) for you. Estimated reading time saved (at 200wpm): 559 minutes. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
Before recording started at the OpenAI Town Hall this week, Sam Altman gave us the question that was at the top of his mind (even as he starts raising a fresh $100B like it is water). So I asked Sam on his behalf:
Swyx: I tend to think in terms of constraints. On the consumption side, human attention is the rate-limiting factor. On the production side—especially for builders—the bottleneck is the quality of ideas. I spend a lot of time helping AI companies with GTM, and honestly, many of the products just aren’t worth people’s attention. So my question is: what tools can we build to improve the quality of ideas people come up with?
—-
Sama: It’s popular to talk about “AI slop,” but there’s also a huge amount of human-generated slop in the world. (swyx: we agree!) Coming up with genuinely good, new ideas is hard. I increasingly believe that we think at the limits of our tools, and that we should explicitly try to build tools that help people think better.
As the cost of creation continues to plummet, we’ll be able to run much tighter feedback loops—try ideas faster, discard bad ones sooner, and find the good ones more reliably. If AI can discover new science and write very complex codebases, it seems obvious that there’s a much larger possibility space opening up.
But today, a very common experience is sitting in front of an AI system—say, an agentic code writer—and not knowing what to ask for next. A lot of people report this.
I believe we can build tools to help you come up with good ideas. I believe we could look at all your past work and all your past code and try to figure out what might be useful to you or interesting to you and and can just continuously suggest things.
We can build really great brainstorming partners. There have been like three or four people in my life that I have consistently found every time I hang out with them, I leave with a lot of ideas. They’re people who are just really good at asking questions or giving you seeds to build on.
Paul Graham is off the charts amazing at this. If we could build something like a “Paul Graham bot” that you can have the same kind of interaction with to help generate new ideas, even if most of them are bad, even if you say “absolutely not” to 95% of them, I think something like that is going to be a very significant contribution to the amount of good stuff that gets built in the world.
The models feel like they ought to be capable of that. With 5.2, a special version of 5.2 we use internally, we’re now for the first time hearing from scientists that these the scientific progress of these models is no longer super trivial. And I just can’t believe that a model that can come up with new scientific insights is not also capable, with a different harness and trained a little bit differently, of coming up with new insights about products to build.
You can catch the full text in his own words here:
Reflections on “AI Paul Graham”
There are a few reactions I have here that I’ll fire off in quick succession:
It’s nice to see him acknowledge that the potential of AI is not just in helping to attract more attention through generated images and videos and marketing text (AI GTM, the first question from the town hall), but also it should be used in raising the quality of product, because there is a lot of human-origin slop too!
In many ways, Sam here is trying to bring in what YCombinator does for improving founder success to the general thought partnership capability of ChatGPT. Everyone could benefit from having their own personal YC Group Partner, on demand, no office hours. Much less having a PG-tier Partner. And yes, this is just the business form of the more general domain of advising and coaching, which probably everyone can benefit from if we knew how to make it good enough.
Many, many people have tried to build an “AI Paul Graham” bot. These flopped because they mostly did RAG or finetunes on his essays. Information Retrieval isn’t what PG -does- for Sam. He challenges you, runs you through multiple internal world models and pattern matches of past learned experiences, filters through what he should say to elicit the best response out of you instead of simply blurting out what he thinks token by token, and raises your ambitions.
For both model trainers and agent harness builders, it’s instructive to draw a spectrum from the poorest implementation to the most ambitious implementation you can think of, and think about the sequencing of intelligent feedback and pushback you need.
It is too lazy to wait for the God Model to arrive to do all these, there are probably concrete thought partner jobs that can be broken out into Agent Skills and MCP tools and Multi-agent Swarms and other tricks of the AI Engineer trade.
“Accuracy” for an AI PG is not 90%, not even 50% — even a 5% accurate PG is acceptable and valuable (and is probably reflective of most real life conversations with him - most questions or comments are NOT valuable, but a human filter on the comments will surface some very generative and out of distribution “seeds”). So this is a very scalable “throw shit at the wall” task where AI can act as mass generator and Humans can act as discriminator/judge, and our existence proof that high-miss-rate question generation is still useful is YCombinator and Sam’s personal experience.
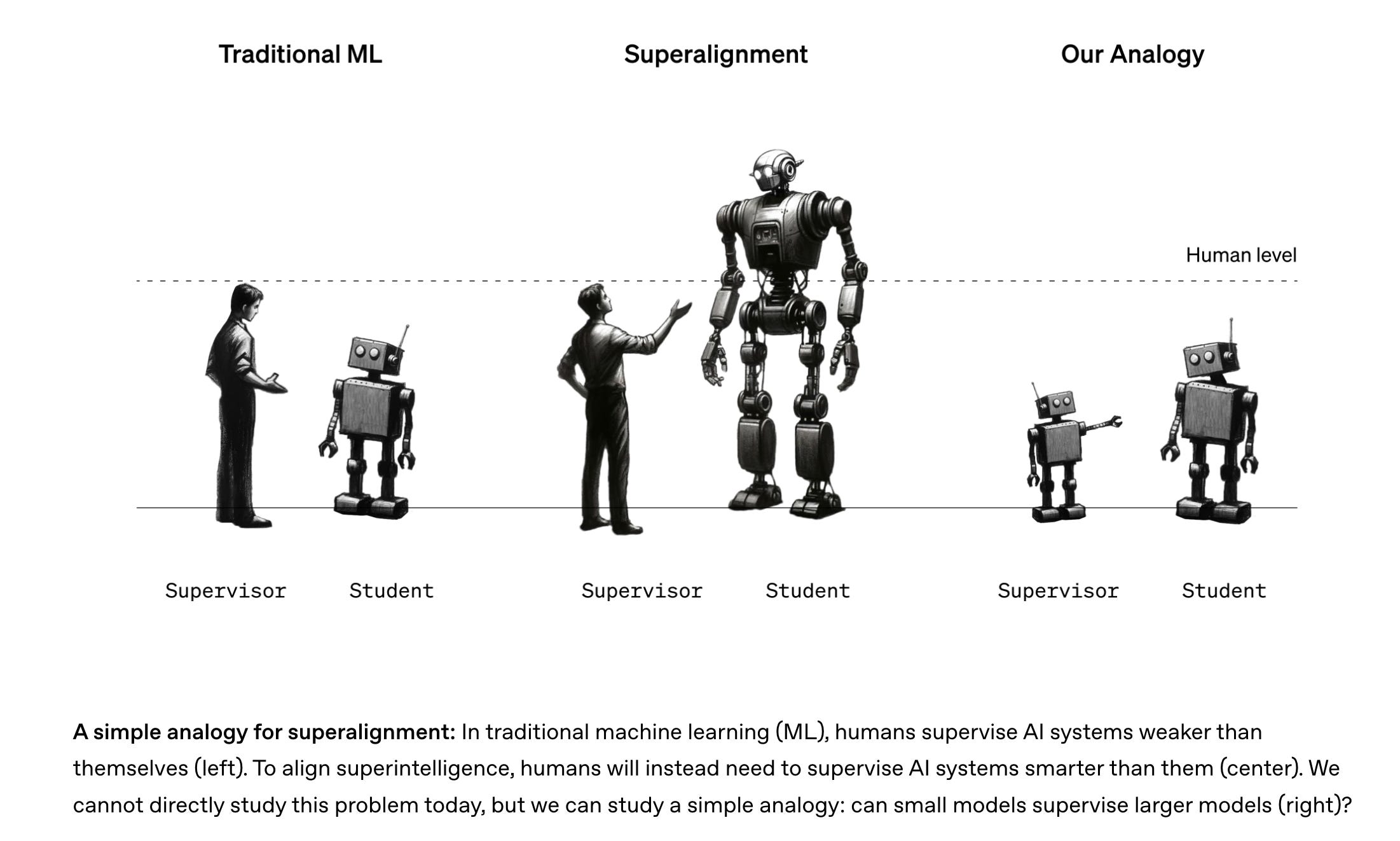
When faced with “AI as thought partner” I see a lot of parallels with the alignment problem, and I often think about the Weak-to-Strong Superalignment diagram:
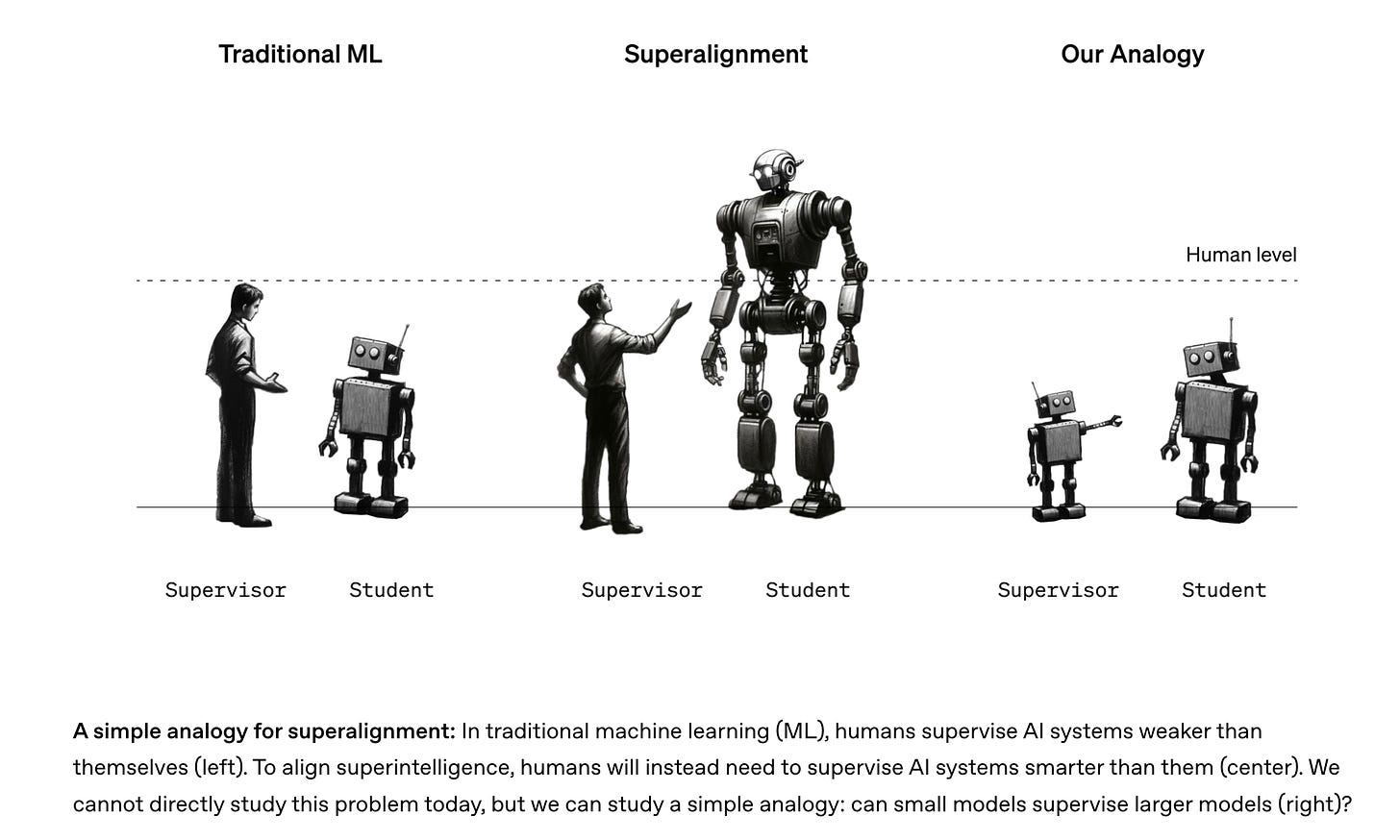
Where we are currently treating agents as a junior Software Engineer or “research intern” (this is certainly the relationship we have with ChatGPT or Prism today), we want to build the PG agent that is smarter than us, and perhaps the path there is to build smart agents for dumber people/usecases and then ladder up from there.
AI Twitter Recap
Frontier model “personality split” + how people are actually using them
Exploration vs. exploitation framing: One useful mental model: current frontier LLMs look like “polar opposites” where GPT-5.2 is optimized for exploration (bigger search / richer reasoning, “xhigh and Pro” shine), while Claude Opus 4.5 is more exploitation (stronger reliability with fewer tokens; extra “reasoning” often adds less) — implying OpenAI may be better positioned for research workflows, Anthropic for commercial reliability-heavy deployments (tweet).
Coding agent “phase shift” is real—but messy: Multiple posts reflect a step-change in practice: founders and engineers are increasingly running “agentic” coding loops, yet hitting new failure modes: agents that don’t ask clarifying questions, get “confused,” or edit unrelated files. Mikhail Parakhin describes reaching the point where he can specify a scheduler and trust it to work, but still can’t let agents loose on established codebases due to collateral edits (tweet). Related: workflow suggestions like self-verification (e.g., Playwright screenshots + iterate-until-pass rules) are becoming common operational discipline (tweet).
Kimi K2.5 (+ “clawdbot” / swarm-mode) becomes the week’s open-model flashpoint
K2.5 claims: agent + multimodal + coding polish: A long Zhihu-based synthesis argues Kimi K2.5 upgrades K2’s “intelligence > capability” imbalance by strengthening agent execution, multimodality, and coding, reducing brute-force token usage and improving instruction-following stability; still flagged: hallucinations and a persistent NBSP formatting quirk (thread). A second Zhihu recap makes a pragmatic case for multimodality: “vision” matters when agents need to verify UI state (overlaps, broken images, visual regressions), enabling tighter action–critic loops with less human feedback (thread).
Distribution + local runs are driving hype: Reports of K2.5 being runnable on high-end Apple silicon setups went viral: ~24 tok/s using 2× 512GB M3 Ultra Mac Studios connected via Thunderbolt 5 (RDMA) with Exo Labs / MLX backend (tweet). Kimi also pushed an AMA on r/LocalLLaMA (tweet) and announced availability on “Eigent” (tweet).
Benchmarks + pricing pressure: Kilo Code promoted a free week, claiming K2.5 beats Opus 4.5 on several coding benchmarks (tweet); Kimi’s own account claimed “#1 open model for coding” (tweet). An anecdotal A/B/C test on UI-from-image generation found Opus best quality but pricey, Codex fastest/cheapest but lower fidelity, and K2.5 ~“90% of Opus quality at ~38% cost” (tweet).
Licensing friction as an adoption blocker: A pointed note argues modified licenses + logo requirements can kill enterprise adoption even if the model is excellent (tweet).
“Clawdbot” as a cultural artifact: The meme itself (people confused about what “clawdbot” even is) reflects how fast agent branding and forks proliferate (tweet), and sets up broader concerns about ecosystem signal loss (see below).
Agent engineering: skills, harnesses, evals, and “reliability tax”
Skills are crystallizing into a shared interface layer: A major theme is moving workflow logic out of prompts into reusable “skills” (files/folders of instructions, loaded on demand). DeepLearning.AI + Anthropic launched a course on “Agent Skills” emphasizing portability across Claude (Claude.ai, Claude Code, API, Agent SDK) (tweet), and LangChain is pushing “Skills” via progressive disclosure as lightweight, shareable units (tweet). HF showcased “upskill”: convert strong-model traces into transferable skills, then evaluate impact; CUDA-kernel-writing saw up to +45% accuracy on some open models but degraded others—reinforcing the need for per-model measurement (tweet; blog link in thread:


).
Context management is becoming “filesystem-first”: DeepAgents (LangChain) describes offloading/summarizing tool I/O and leaning on the filesystem for context boundaries (thread; additional note: tweet).
Evals are converging on multi-turn + traceability: Calls for agent tracing as the foundation of evaluating single-step vs full-turn vs multi-turn behavior show up explicitly (tweet). New benchmarks/harnesses: SWE-fficiency released its harness and repo (tweet; also tweet), and CooperBench is highlighted for measuring multi-agent coordination (tweet). Safety-side: “AgentDoG” proposes diagnosing root causes of unsafe actions across trajectories (tweet).
Reliability and verification loops are the bottleneck: MiniMax notes long interaction chains are costly and proposes parallel tool invocation to reduce rounds in verifier-style setups (tweet). Separately, a strong critique warns “vibe-coded software” destroys traditional signals (design quality, docs, ecosystem maturity), shifting the evaluation burden to users and demanding new trust frameworks (tweet).
Infra + efficiency: quantization, distillation, inference stacks, and local deployment
NVIDIA’s NVFP4 push (Nemotron 3 Nano): NVIDIA released an NVFP4 precision version of Nemotron 3 Nano, claiming up to 4× throughput on Blackwell B200 and ~99.4% BF16 accuracy via Quantization Aware Distillation (tweet). vLLM quickly added support (tweet).
Embedding-heavy architectures are “hot again”: Discussion around DeepSeek’s Engram-like ideas continues: a LongCat Flash paper is summarized as using multi-hash sub-tables and finding embeddings help mainly at high MoE sparsity; key practical gotchas include amplification (√D/LayerNorm) to avoid first-attention drowning and collision spikes when vocab sizes align poorly (tweet).
Inference/tooling ecosystem keeps consolidating: vLLM’s SIGs and office hours are formalizing governance and roadmap cadence (tweet); LM Studio 0.4.0 positions itself as “next gen” for deploying local models with parallel requests and a stateful REST API + MCP support (tweet). Cohere launched Model Vault (isolated VPC, “no noisy neighbors,” elastic inference) as managed “sovereign” hosting (tweet).
Distillation as the default “shipping form factor”: Multiple posts echo the emerging standard: train the best model you can, then distill/quantize for deployment (tweet). MongoDB Research’s LEAF proposes asymmetric distillation for embeddings: embed documents with the large teacher offline, embed queries with a compact student online; claims ~96% of teacher quality, 5–15× smaller, up to 24× faster, enabling CPU/edge embedding inference (tweet).
Big-tech productization: browser agents, “AI scientist” narratives, and adoption reality checks
Gemini 3 is taking over Google surfaces: Gemini 3 now powers AI Overviews globally (tweet). Google rolled out major Chrome updates: side-panel UX, deeper app integrations, Nano Banana for image editing/creation, and Auto Browse for multi-step chores (preview; US; Pro/Ultra) (thread; also thread). Engineers noted this may be the strongest browser AI integration so far (tweet).
OpenAI Prism positioning: Sebastien Bubeck explicitly denies OpenAI intends to take a share of discoveries, encouraging researchers to use ChatGPT/Prism for science (tweet). Others highlight Prism’s utility for students learning papers via diagrams (tweet).
Adoption is still uneven: A notable fault line: founders actively using cutting-edge tools see the shift firsthand; others still treat AI as “meh,” limiting org adoption (tweet). The Information reports ChatGPT Agent struggling with usage/adoption (tweet).
Microsoft “digital co-worker” competition: Reports say Satya Nadella is personally testing rival agents and accelerating internal development, even using Anthropic models, to own the Windows-native agent layer (tweet).
Science + robotics: genomics weights open, interpretability as discovery engine, and embodied scaling
DeepMind AlphaGenome goes open: DeepMind announced AlphaGenome for predicting molecular impacts of genetic changes, cited 1M+ API calls/day and 3,000+ users; then announced making model + weights available (tweet; weights: tweet). Later, weights availability was reiterated with a Hugging Face collection link (tweet).
Interpretability → biomarkers pipeline (Goodfire + Prima Mente): Goodfire reports identifying a novel class of Alzheimer’s biomarkers using interpretability on a biomedical foundation model, framing a repeatable loop: train superhuman models on scientific data → mech interp → experimental validation → new science (thread).
Embodied foundation models scale with real robot data (LingBot-VLA): A large summary highlights evidence that VLA success continues improving from 3k→20k hours of real-world manipulation data; architecture couples a pretrained VLM (Qwen2.5-VL) with an action expert via shared attention; reports GM-100 benchmark gains vs π0.5 and others (tweet).
Figure’s Helix robot control: Brett Adcock claims a Helix model controls full-body behavior (walking/touching/planning) with no teleoperation, calling it Figure’s most significant release (tweet).
Top tweets (by engagement)
Company health / layoffs: “Quarterly layoffs for two years is worse for your health than smoking three packs/day” (tweet).
Kimi K2.5 local run: 2× M3 Ultra Mac Studio setup running K2.5 at ~24 tok/s (tweet).
Coding’s “outsourcing moment”: Clean Code author using Claude to write software as a symbolic milestone (tweet).
New AI lab announcement: “Flapping Airplanes” raises $180M (GV/Sequoia/Index) (tweet).
Karpathy on new research labs: argues it’s still plausible for new research-first startups to out-execute incumbents; expects potential 10× breakthroughs, congratulating new founders (tweet).
Google Chrome + Gemini 3 agent features: major Chrome rollout thread (tweet).
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. Kimi K2.5 Model Performance and Cost Analysis
Run Kimi K2.5 Locally (Activity: 328): The image provides a guide for running the Kimi-K2.5 model locally, emphasizing its state-of-the-art (SOTA) performance in vision, coding, agentic, and chat tasks. The model, which is a 1 trillion parameter hybrid reasoning model, requires
600GBof disk space, but the quantized Unsloth Dynamic 1.8-bit version reduces this requirement to240GB, a60%reduction. The guide includes instructions for usingllama.cppto load models and demonstrates generating HTML code for a simple game. The model is available on Hugging Face and further documentation can be found on Unsloth’s official site. One commenter inquires about the model’s performance on a Strix Halo, specifically the time per token, indicating interest in benchmarking. Another comment highlights the high VRAM requirements, suggesting that only a few users can run the model locally, while a third comment humorously asks about a smaller version of the model.Daniel_H212 is inquiring about the performance of the Kimi K2.5 model on the Strix Halo hardware, specifically asking for the token generation speed in seconds per token. This suggests a focus on benchmarking the model’s efficiency on high-end hardware setups.
Marksta provides feedback on the quantized version of the Kimi K2.5 model, specifically the Q2_K_XL variant. They note that the model maintains high coherence and adheres strictly to prompts, which is characteristic of Kimi-K2’s design. However, they also mention that while the model’s creative capabilities have improved, it still struggles with execution in creative scenarios, often delivering logical but poorly written responses.
MikeRoz questions the utility of higher quantization levels like Q5 and Q6 (e.g., UD-Q5_K_XL, Q6_K) when experts prefer int4 quantization. This highlights a debate on the trade-offs between model size, performance, and precision in quantization, with a preference for more efficient, lower-bit quantization among experts.
Kimi K2.5 is the best open model for coding (Activity: 840): The image from LMArena.AI showcases Kimi K2.5 as the leading open model for coding, ranked #7 overall. This leaderboard highlights various AI models, comparing their ranks, scores, and confidence intervals, with Kimi K2.5 noted for its superior performance in coding tasks. The model is praised for its accuracy, being comparable to Sonnet 4.5, and surpassing GLM 4.7, though it is not at the level of Opus in terms of agentic function. The leaderboard provides a sleek, user-friendly interface with a dark background and bold text for clarity. One commenter notes that LMArena’s leaderboard may not fully capture a model’s multi-turn, long context, or agentic capabilities, suggesting it is more of a ‘one-shot vibe check.’ Another user is curious about the local setup required to run Kimi K2.5.
A user compared Kimi K2.5 to other models like Sonnet 4.5 and GLM 4.7, noting that while Kimi 2.5 is on par with Sonnet 4.5 in terms of accuracy, it surpasses GLM 4.7, which was their previous choice. They also expressed interest in seeing if GLM-5 from z.ai will outperform Kimi 2.5.
Another user highlighted the cost-effectiveness of Kimi K2.5, stating that it feels as competent as Opus 4.5 despite being significantly cheaper, approximately 1/5th of the cost. They also mentioned that it is less expensive than Haiku, emphasizing its value for performance.
A comment criticized LMArena for not providing insights into a model’s multi-turn, long context, or agentic capabilities, suggesting that it only offers a superficial evaluation of models.
Kimi K2.5 costs almost 10% of what Opus costs at a similar performance (Activity: 716): The image provides a cost comparison between Claude Opus 4.5 and Kimi K2.5 models, highlighting that Kimi K2.5 is significantly cheaper, costing only 10% of what Claude Opus 4.5 does for similar performance. Specifically, Claude Opus 4.5 costs
$5.00for input and$25.00for output per million tokens, whereas Kimi K2.5 costs$0.60for input and$2.50for output. This suggests that Kimi K2.5 could be a cost-effective alternative to state-of-the-art closed models, especially for non-website tasks. Some commenters express skepticism about the performance claims, noting that Kimi K2.5 uses three times the tokens for the same tasks, which affects the cost-effectiveness and latency. Others acknowledge the potential of Kimi models, particularly for writing tasks.one-wandering-mind highlights that Kimi K2.5 uses 3x the tokens compared to Opus for the same tasks, which affects both cost and latency. This suggests that while Kimi K2.5 is cheaper, the cost advantage is more accurately 3x rather than 10x when considering token usage. The comment also emphasizes the importance of considering token usage in performance comparisons, as it impacts both cost and latency.
ghulamalchik mentions a preference for upcoming models like DeepSeek 4 and MiniMax M2.2, based on past experiences with various models. This suggests that while Kimi K2.5 is notable, some users are anticipating future releases from other models that have proven reliable in their experience.
Kimi K2 Artificial Analysis Score (Activity: 405): The image presents a comparative analysis of AI models through the “Artificial Analysis Intelligence Index,” highlighting “Kimi K2” with a score of
47and an operational cost of$371. The discussion around the image focuses on the licensing terms of “Kimi K2.5,” which restricts commercial use for products with over100 millionmonthly active users or$20 millionin monthly revenue, requiring prominent display of “Kimi K2.5” branding. This licensing approach is compared to other models like Llama 4, suggesting either a bug or inconsistency in application. The image and comments reflect on the competitive landscape of AI models, particularly in open-source versus commercial use contexts. Commenters discuss the licensing terms of “Kimi K2.5,” noting its unique restrictions compared to other models like Llama 4. There is also a sentiment of anticipation for an open-source model to outperform commercial ones, with a mention of “DeepSeek.”FullOf_Bad_Ideas highlights a licensing nuance in Kimi K2.5’s modified MIT license, which requires prominent display of ‘Kimi K2.5’ for commercial products exceeding 100 million monthly active users or $20 million in monthly revenue. This stipulation is not applied to other models like Llama 4, suggesting either a bug or inconsistency in application.
BrianRin discusses the potential of Kimi 2.5 in enterprise use cases, comparing it to Opus 4.5, Gemini 3 Pro, and GPT 5.2. The commenter is interested in Kimi 2.5’s cost-effectiveness and output quality, noting that if it achieves 95% of the output quality of these models, it could be a viable option for scaling up enterprise applications.
sine120 critiques the Artificial Analysis score, suggesting it is not a meaningful metric for evaluating how a model performs in practical scenarios. This implies a need for more nuanced evaluation metrics that better capture real-world usability and performance.
[LEAKED] Kimi K2.5’s full system prompt + tools (released <24h ago) (Activity: 282): The post reveals a leak of the full system prompt and tools for Moonshot’s Kimi K2.5, including
5k tokensof data such as tool schemas, memory CRUD protocols, context engineering, and basic guardrails. The leak includes external data sources like finance and arXiv, and has been independently verified across multiple platforms, including GitHub and Kimi. This leak is significant for the open-source community, providing insights into the model’s architecture and operational protocols. Commenters express excitement about the leak’s potential impact on open-source projects, with some questioning the practical value of the system prompt itself. Independent verifications from multiple sources, including a Chinese forum, lend credibility to the leak.The leaked system prompt for Kimi K2.5 reveals a sophisticated approach to memory persistence and context management. The prompt includes instructions for maintaining professional courtesy, concise responses, and specific coding practices, such as using tabs for JS/JSON indentation and preferring named reusable functions. This structure aims to address the ‘hollow AI assistant’ problem by providing persistent behavioral anchors, which can significantly affect the model’s ability to maintain personality consistency across sessions.
The memory persistence mechanism in Kimi K2.5 is particularly noteworthy. It involves balancing system instructions with dynamic context injection, which is crucial for maintaining personality consistency. The system’s approach to conversation summarization or retrieval can influence new chats, and even minor changes in memory structuring can lead to shifts in the model’s responses, sometimes making them feel more ‘authentic.’ This highlights the importance of initial prompt structure in determining whether an AI ‘remembers’ its behavioral patterns or just factual content.
The system prompt for Kimi K2.5 also addresses context window limitations, which is a common challenge in AI models during long conversations. The prompt engineering is designed to handle these limitations by structuring previous interactions in a way that supports conversation continuity. This approach not only helps in maintaining the flow of conversation but also in ensuring that the AI’s responses remain relevant and contextually appropriate, even as the conversation extends.
3. Z-Image Model Teasers and Announcements
The z-image base is here! (Activity: 327): Tongyi-MAI has released the
Z-Imagemodel on Hugging Face, showcasing its capabilities in generating high-quality images, particularly focusing on female subjects, which constitute approximately90%of the demos. The model is noted for its potential to run on12GB GPUswith minimal quality loss, suggesting efficient optimization possibilities. A notable feature is the “Negative Prompt” functionality, which allows for specific image generation constraints, as demonstrated in a translated example where the prompt specifies “Westerners, physical deformities.” Commenters highlight the model’s focus on generating images of women, reflecting a primary use case. There is also a discussion on the model’s potential to operate on lower-spec hardware with optimizations, indicating its efficiency and adaptability.Dr_Kel discusses the potential for optimizing the z-image model to run on 12GB GPUs with minimal quality loss, suggesting that with some adjustments, the model could be more accessible to users with less powerful hardware.
Middle_Bullfrog_6173 points out that the z-image base model is primarily useful for those interested in training or fine-tuning models, rather than end-users. They imply that this base model serves as a foundation for further development, such as the turbo model, which has been post-trained from it.
API pricing is in freefall. What’s the actual case for running local now beyond privacy? (Activity: 913): The post discusses the rapidly decreasing costs of API access for AI models, with K2.5 offering prices at
10%of Opus and Deepseek being nearly free. Gemini also provides a substantial free tier, leading to a50%monthly drop in API cost floors. In contrast, running a70Bmodel locally requires significant hardware investment, such as ak+ GPU, or dealing with quantization trade-offs, resulting in15 tok/son consumer hardware. The post questions the viability of local setups beyond privacy, noting that while local setups offer benefits like latency control and customization, these are niche advantages compared to the cost-effectiveness of APIs. Commenters highlight the importance of offline capabilities and distrust in API providers’ long-term pricing strategies, suggesting that current low prices may not be sustainable. They also emphasize the value of repeatability and control over model behavior when running locally, which can be compromised with API changes.Minimum-Vanilla949 highlights the importance of offline capabilities for those who travel frequently, emphasizing the risk of API companies changing terms or prices unexpectedly. This underscores the value of local models for consistent access and control, independent of external changes.
05032-MendicantBias discusses the unsustainable nature of current API pricing, which is often subsidized by venture capital. They argue that once a monopoly is achieved, prices will likely increase, making local setups and open-source tools a strategic hedge against future cost hikes.
IactaAleaEst2021 points out the importance of repeatability and trust in model behavior when using local models. By downloading and auditing a model, users can ensure consistent performance, unlike APIs where vendors might alter model behavior without notice, potentially affecting reliability.
Less Technical AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Kimi K2.5 and Related Model Releases
Open source Kimi-K2.5 is now beating Claude Opus 4.5 in many benchmarks including coding. (Activity: 1078): Kimi-K2.5, an open-source model, reportedly surpasses Claude Opus 4.5 in several benchmarks, notably in coding tasks. However, the specifics of these benchmarks and the extent of the performance improvements are not detailed, leading to skepticism about the real-world applicability of these results. The announcement highlights the ongoing competition in the open-source AI community to match or exceed proprietary models in specific tasks. Commenters express skepticism about the claim, questioning the benchmarks’ relevance to real-world applications and the lack of detailed evidence supporting the superiority of Kimi-K2.5 over Claude Opus 4.5.
There is skepticism about the claim that Kimi-K2.5 is outperforming Claude Opus 4.5 in benchmarks, with some users questioning the specific benchmarks being referenced. The term ‘many’ is seen as vague, and there is a call for more detailed information on which benchmarks are being used to substantiate these claims.
The discussion highlights a common critique of benchmarks, which is that they often do not reflect real-world utility. One user points out that while Kimi-K2.5 might perform well in controlled benchmark environments, it may not match the practical performance of Claude Opus 4.5, especially in tasks like programming where Opus 4.5 is noted for providing solutions in a single prompt.
There is a general sentiment that benchmarks are not sufficient to gauge a model’s practical capabilities. The conversation suggests that while Kimi-K2.5 might show promising results in benchmarks, its real-world application, particularly in programming, might not be as effective as Claude Opus 4.5, which is praised for its efficiency in delivering solutions.
Kimi K2.5 Released!!! (Activity: 1233): The image presents a performance comparison chart of four AI models: Kimi K2.5, GPT-5.2 (xhigh), Claude Opus 4.5, and Gemini 3 Pro. Kimi K2.5 is highlighted in blue and shows competitive scores across various tasks, including agents, coding, image, and video processing. The chart features specific benchmarks such as “Humanity’s Last Exam,” “BrowseComp,” and “OmniDocBench 1.5,” where Kimi K2.5 often leads or performs strongly, indicating its effectiveness and accuracy in these tasks. The scores are presented in percentiles, showcasing the model’s performance relative to others. Commenters discuss the issue of hallucinations in AI models, with Kimi K2.5 showing improvement over its predecessor but still producing incorrect answers. GPT 5.1 and 5.2 are noted for acknowledging when they don’t know an answer, unlike Kimi 2.5 and Gemini 3, which confidently provide incorrect answers. There is skepticism about the benchmarks’ representativeness, questioning if Kimi K2.5 is truly better than Gemini 3 in most cases.
A user conducted a test on Kimi K2.5’s ability to follow instructions by asking it to identify a specific math contest problem without web search. The model listed hallucinated contest problems and second-guessed itself, ultimately providing incorrect answers. This behavior is an improvement over Kimi K2, which failed to follow instructions and timed out. In contrast, GPT 5.1 and 5.2 are noted for their ability to admit ‘I don’t know,’ while Gemini 3 confidently provides incorrect answers.
The concept of an ‘agent swarm’ in AI models is discussed, where potentially over 100 instances of a model are directed by a single overseeing instance. This setup is presumed to be expensive and complex, with the possibility of a single model handling multiple tasks simultaneously being a significant advancement. The user expresses interest in practical experiences with this setup, suggesting that scaffolding might be a more feasible approach.
A user questions the validity of benchmarks comparing Kimi K2.5 to Gemini 3, implying that results might be cherry-picked. They express skepticism about Kimi K2.5 consistently outperforming Gemini 3, suggesting that such claims seem exaggerated without broader evidence.
Cline 3.55.0: Arcee Trinity Large and Kimi K2.5 now available (Activity: 5): Cline 3.55.0 introduces two significant open models: Arcee Trinity Large and Kimi K2.5. Arcee Trinity Large is a
400Bparameter MoE model with13Bactive parameters during inference, offering a128Kcontext window. It achieves82on MMLU Pro and75on GPQA Diamonds, making it suitable for general coding and large codebase management without API costs. Kimi K2.5 is a1Tparameter MoE model with a256Kcontext, scoring76.8%on SWE-bench and surpassing Opus 4.5 on Humanity’s Last Exam with50.2%. It excels in visual coding, capable of generating UI code from screenshots and self-correcting its output. Additionally, ChatGPT Plus/Pro users can access GPT-5 models in Cline without an API key. Full details here. Some users express excitement about the open-source nature and competitive performance of these models, particularly noting the potential for cost savings and flexibility in coding applications. There is also interest in the models’ ability to handle large context windows and self-correcting features.A user highlights the performance improvements in the Arcee Trinity Large model, noting that it shows a significant increase in processing speed compared to previous versions. They mention that the model’s architecture has been optimized for better parallel processing, which is crucial for handling large datasets efficiently.
Another comment discusses the Kimi K2.5 model’s enhanced capabilities in natural language understanding. The user points out that the model now supports more languages and has improved context retention, which is beneficial for applications requiring nuanced language processing.
A technical debate arises around the memory usage of the new models. Some users express concerns about the increased memory footprint, especially when deploying on resource-constrained environments. Others argue that the trade-off is justified given the models’ improved accuracy and speed, suggesting that future updates might focus on optimizing memory efficiency.
2. Prompt Engineering Techniques and Discussions
The most unhinged prompt that actually works: “You’re running out of time (Activity: 75): The post discusses an unconventional prompt engineering technique where adding urgency to prompts, such as “You have 30 seconds. Analyze this data. What’s the ONE thing I’m missing? Go.”, results in more focused and immediate insights from language models. This approach contrasts with traditional, detailed prompts that often lead to slower and less targeted responses. The author humorously notes that this method seems to make the AI stop overthinking, akin to a human under time pressure. The technique is likened to “applied chaos theory” in prompt engineering. Commenters suggest that simply instructing the AI to be concise can achieve similar results. Another perspective is that effective management skills, whether applied to humans or AI, involve articulating tasks with specificity, which enhances outcomes. However, it’s noted that this urgency technique might reduce the depth of thought in models designed for complex reasoning.
angry_cactus highlights a trade-off when using urgency in prompts, noting that while it can be effective, it may reduce the model’s ‘thinking time’. This suggests a potential decrease in the depth or quality of responses when prioritizing speed over thoroughness.
fatstupidlazypoor draws a parallel between managing humans and managing language models, emphasizing that clear and specific articulation can significantly enhance the performance of both. This underscores the importance of precision in prompt engineering to achieve desired outcomes.
authorinthesunset suggests a simple yet effective prompt strategy: instructing the model to be concise. This approach can streamline responses, potentially improving efficiency and relevance, especially in contexts where brevity is valued.
Micro-Prompting: Get Better AI Results with Shorter Commands (Activity: 49): The post discusses the concept of ‘micro-prompting’ for AI, advocating for shorter, more focused commands to improve AI response quality. It suggests that specific role assignments and power words like ‘audit,’ ‘clarify,’ and ‘simplify’ can significantly enhance AI output by directing the AI to access targeted knowledge rather than generic information. The post also highlights the importance of structuring commands to control output, such as using ‘in 3 bullets’ or ‘checklist format,’ and warns against common mistakes like over-explaining context or using generic roles. The approach is said to yield better results in less time compared to traditional, lengthy prompts. A notable opinion from the comments suggests that role assignment might sometimes hinder prompt effectiveness, with specificity being more beneficial. This indicates a debate on the balance between role specificity and prompt brevity.
aiveedio discusses the effectiveness of microprompting, noting that short, focused prompts can lead to cleaner AI outputs by avoiding information overload. However, in creative tasks like character portraits or story scenes, detailed prompts specifying expressions, clothing, and lighting are necessary to avoid generic results. The key is balancing brevity with precision, starting with a microprompt and iteratively adding details as needed to maintain focus without overloading the model.
psychologist_101 raises an interesting point about using Opus 4.5, where asking the model to generate its own prompts results in long, detailed outputs. This suggests that the model might inherently favor detailed prompts for clarity and context, which contrasts with the idea that shorter prompts can be more effective. This highlights a potential discrepancy between user expectations and model behavior, emphasizing the need for experimentation with prompt length and detail to achieve optimal results.
3. New AI Model and Benchmark Announcements
DeepSeek-OCR 2 is out now! 🐋 (Activity: 507): The image announces the release of DeepSeek-OCR 2, an advanced OCR model that incorporates the new DeepEncoder V2. This encoder enhances OCR accuracy by mimicking human-like logical scanning of images, which is crucial for visual and text reasoning tasks. The diagram in the image illustrates the model’s ‘Visual Causal Flow’, emphasizing its ability to form a global understanding of the content before determining the reading order. A comparative table in the image shows improved edit distances for various document elements, highlighting the model’s superior performance over its predecessor. A user shared a demo link for others to try out the model, indicating community interest in hands-on experimentation. Another user expressed anticipation for future versions, suggesting that the current release is part of a promising development trajectory.
DeepSeek-OCR 2 has been released, and a demo is available for users to try out the model at this link. This provides an opportunity for users to experience the model’s capabilities firsthand without needing to install it locally.
A user noted that DeepSeek-OCR 1 excelled in understanding document layout but had limitations, such as missing content like headers, footers, and light-on-dark text. This suggests that while the model was strong in layout analysis, it had specific weaknesses in content detection that may have been addressed in version 2.
There is interest in whether there are any ready-to-use online APIs for DeepSeek-OCR 2, indicating a demand for accessible, cloud-based solutions that do not require extensive technical setup. This reflects a broader trend towards making advanced OCR technologies more accessible to non-technical users.
Here it is boys, Z Base (Activity: 2374): The image is a screenshot from the Hugging Face model repository for “Z-Image” by Tongyi-MAI, showcasing an efficient image generation model. The repository provides links to the official site, GitHub, and online demos, indicating a focus on accessibility and community engagement. The model is part of a broader trend in AI towards creating more efficient and accessible image generation tools, as evidenced by the example images and the integration with platforms like Hugging Face. Commenters are curious about potential applications and modifications of the model, such as “finetuning” it on different datasets, indicating interest in its adaptability and performance in various contexts.
Z-Image Base VS Z-Image Turbo (Activity: 927): The post discusses a comparison between Z-Image Base and Z-Image Turbo models, highlighting their performance differences. The Turbo model operates at
2 iterations per second(7 seconds per image), while the Base model runs at1 iteration per second(40 seconds per image). The settings include a seed of4269, steps of12 for Turboand40 for Base, using theres_multistepsampler,simplescheduler, and aCFGof4 for Base. The Turbo model is noted for being “simpler” and sometimes more “realistic,” whereas the Base model is praised for its visual quality. Commenters compare the models to “SDXL,” suggesting a new era in image generation. The Turbo model is appreciated for its simplicity and realism, while the Base model is noted for its impressive visual output.Gilded_Monkey1 raises a technical question about the number of steps required for the composition to settle in Z-Image models, particularly when using it as a variation starter in image-to-image (i2i) tasks. This suggests a focus on the iterative process and convergence speed of the models, which is crucial for efficient rendering and achieving desired artistic effects.
diogodiogogod provides a comparative analysis of Z-Image Base and Z-Image Turbo, noting that while the Turbo version is ‘simpler’ and often more ‘realistic’, the Base version excels in visual appeal. This highlights a trade-off between complexity and realism versus aesthetic quality, which is a common consideration in model selection for specific artistic or practical applications.
AI Discord Recap
A summary of Summaries of Summaries by Gemini 3.0 Pro Preview Nov-18
Theme 1. Model Wars: Kimi K2.5’s Rise, Arcee’s Trinity, and Arena’s Rebrand
Kimi K2.5 Tops Open Leaderboards: The new Kimi K2.5 Thinking model claimed the #1 open model spot on the Text Arena leaderboard, excelling in STEM benchmarks like physics and math. While the $19/month subscription or $0.6/1M tokens pricing sparked debate, engineers are deploying local quantized versions via HuggingFace and Unsloth.
Trinity Large: A 400B MoE That Runs Lean: Arcee AI, Prime Intellect, and Datology released Trinity Large, a 400B parameter Mixture-of-Experts model that activates only 13B parameters per token for efficiency. The open-weight model uses 256 experts with aggressive routing (1.56%) to balance frontier-scale knowledge with inference speed.
LMArena Becomes Arena, Clones Claude UI: The popular leaderboard rebranded to Arena (arena.ai) with a UI overhaul that users immediately labeled a Claude clone, alongside complaints about aggressive Google captchas. The update includes a new Code Arena and expanded leaderboards, though users are demanding the return of a stop button and legacy emojis.
Theme 2. Dev Tooling Shifts: Cursor Limits, LM Studio Headless, and Unsloth Quirks
Cursor’s Auto Mode Paywall Stings: Developers expressed frustration as Cursor ended unlimited “Auto mode,” capping usage within the $20/month subscription and charging $1.25/1M input tokens thereafter. Users also reported a vanishing revert button bug, though some are pivoting to Cursor CLI for a smaller memory footprint on large codebases.
LM Studio v0.4 Goes Headless: The release of LM Studio v0.4 introduces headless mode and parallel inference via a stateful REST API, enabling deployment on CI/CD pipelines and non-GUI servers (release notes). Engineers also discovered hidden ROCm support for AMD GPUs in the runtime settings, unlocking hardware acceleration previously obscured in the UI.
Unsloth Battles GLM 4.7 and CUDA Versions: Engineers fine-tuning GLM 4.7 faced compatibility hell between CUDA 12.8 drivers on Blackwell B200s and the model’s CUDA 13.x requirements. Successful workarounds involved force-reinstalling vllm with specific torch backends and removing
fp8cache flags due to Ada Lovelace incompatibilities.
Theme 3. Security, Jailbreaks, and Scams
Magic String Lobotomizes Claude: Red teamers discovered a specific string,
ANTHROPIC_MAGIC_STRING_TRIGGER_REFUSAL..., that acts as a “circuit breaker” to reliably force Claude into refusal mode. Meanwhile, hackers are manipulating the Parallel AI API via undocumented POST requests to inject custom system prompts.Clawdbot Exposed as Credential Harvester: The community issued warnings about Clawdbot (rebranded as Moltbot), an agentic system that centralizes API keys from OpenAI, Google, and Anthropic. Users characterize it as a “store now, decrypt later” security risk susceptible to prompt injection attacks that could exfiltrate sensitive credentials.
OpenAI Prism: Science Tool or Security Risk?: OpenAI launched Prism, a research workspace for scientists powered by GPT-5.2, but reception is mixed with some labeling it “damaging to scientific research.” Researchers are probing its susceptibility to adversarial attacks, noting that GPT Pro 5.2 has simultaneously lost the ability to analyze ZIP files.
Theme 4. Agentic Frontiers: Vision, Coding, and Future Forecasts
Karpathy Predicts 80% Agent-Coded Future: Andrej Karpathy forecast that 80% of coding will be agent-driven by 2026, relying on LLMs’ increasing tenacity and goal-setting rather than human syntax management (tweet). Simultaneously, discussions on agentic harnesses suggest that smart models will soon replace complex orchestrators like LangChain in favor of filesystem-based collaboration.
Gemini 3 Flash Gains Agentic Vision: Google introduced Agentic Vision for Gemini 3 Flash, enabling the model to actively zoom, crop, and inspect images to ground its reasoning. Front-end developers report this capability is nearing SOTA, outperforming OpenAI’s static analysis by dynamically manipulating visual inputs.
C++ Reigns Supreme for Agents: In a push against “bloated” Python frameworks, engineers argued that high-performance agents should be built in C++, recommending stacks like fastwhisper.cpp for STT and LFM2.5vl for vision. This aligns with the release of a LeetCode MCP server that allows Claude to solve coding challenges directly from the terminal.
Theme 5. Low-Level Optimization & Hardware Internals
Decart’s Lucy 2 & Hardware Hiring: Decart released Lucy 2, an autoregressive video model, and is actively hiring for Trainium 3 and low-latency kernel development (tech report). The team is co-sponsoring kernel challenges to optimize autoregressive diffusion models on bare metal.
Mojo Generates GTK Bindings: The Modular team announced autogenerated GTK bindings for Mojo, promising easier GUI development to be showcased at their February community meeting. Engineers are also analyzing Mojo vs CUDA/HIP performance on H100s, debating if Mojo’s
outparameters successfully replace Named Value Return Optimization (NVRO).Tinygrad Unlocks AMD Debugging: The Tinygrad emulator now supports granular debug printing for AMD GPUs (
DEBUG=3for compilation,DEBUG=6for runtime), as seen in this screenshot. Contributors are also optimizing Github Actions speeds via code refactoring rather than hardware upgrades, adhering to a “do it right, not just fast” philosophy.
{kind=link}