

[AINews] Tasteful Tokenmaxxing
a quiet day lets us reflect on the top conversation that AI leaders are having everywhere.
It is Cloud Next today and Google TPUv8’s (training and inference iterations) were announced as expected, though the numbers are mindboggling, they mostly serve to reinforce the sheer hardware advantage that a decade of investment has given to GDM and any models they train and serve.
Over the last 2 days with AIE Miami concluding (Singapore is next!) the top conversations we have been hearing from AI leadership (CTOs, VPs, Founders) have all centered around the concept of “Tokenmaxxing” and how leaders want to get their teams using more AI, WITHOUT the downside of incentivizing the kinds of horrendous waste our friend Gergely Orosz described at his AIE keynote.
Dex Horthy, coiner of Context Engineering and “the Dumb Zone”, publicly retracted his extremely vibe-coding-pilled call 6 months ago and encouraged people to please read the code, citing Alex Volkov’s Z/L continuum from AIE Europe:
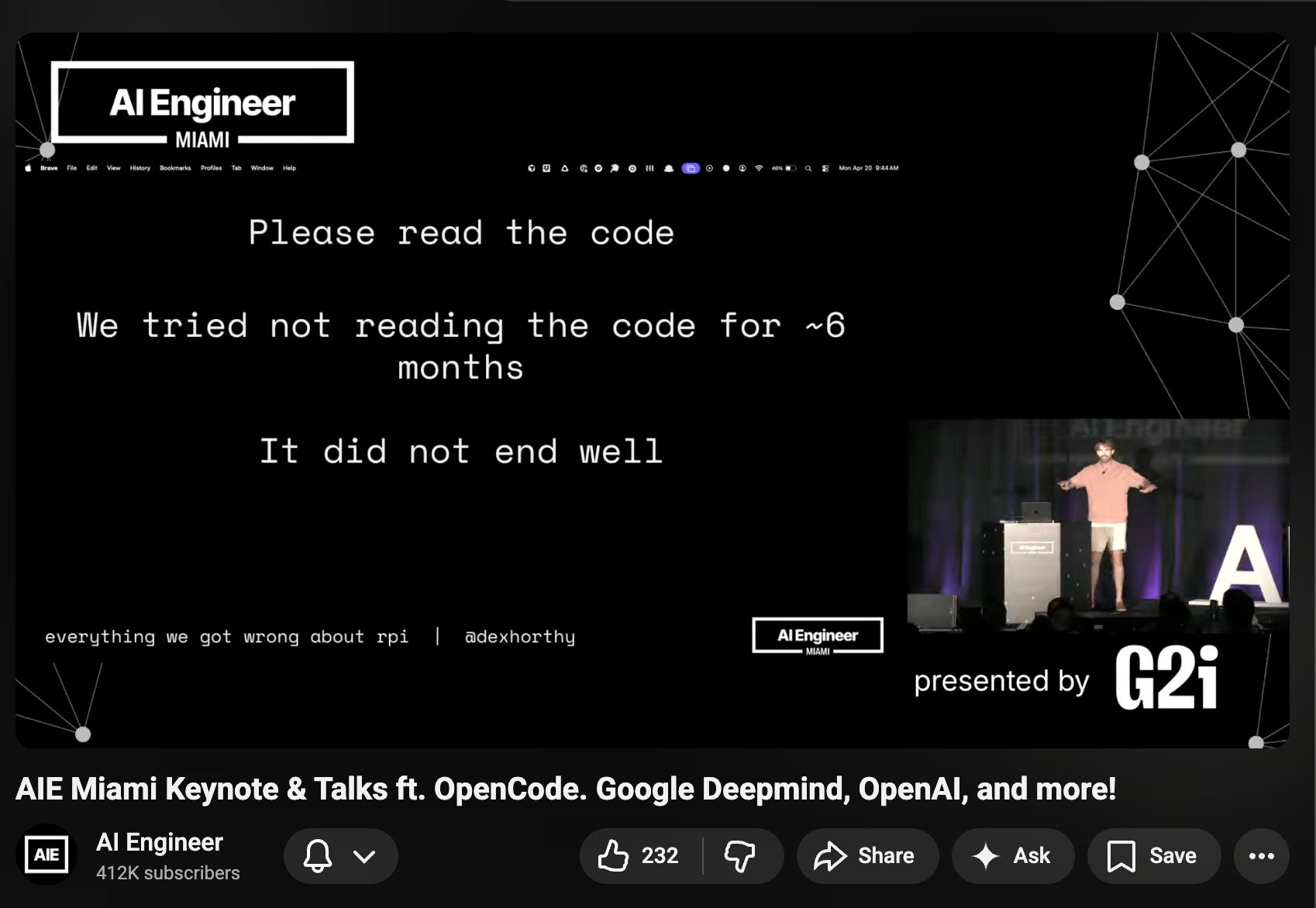
Off the record, many senior leaders I talk to are more on the Zechner side than the Lopopolo side of the Z/L spectrum — this does not mean that one side is true for every one in every situation, nor does it mean it will continue to be true with advancing model progress! To point out the most obvious, engineers and engineering leaders are the ones most setup to make a big deal out of minor architectural quality issues that sheer quantity of cheap code generation and code review might overcome.
Today’s LS guest, Mikhail Parakhin, CTO of Shopify, had another take on the “tasteful tokenmaxxing” - you want to go for depth (e.g. do more serial autoresearch loops) than go for breadth (e.g. solve a problem by kicking off 5, 10, 50, 500 parallel runs of the LLM slot machine). Worth thinking through.
AI News for 4/21/2026-4/22/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
Open Models: Qwen3.6-27B, OpenAI Privacy Filter, and Xiaomi MiMo-V2.5
Qwen3.6-27B lands as a serious local/open coding model: @Alibaba_Qwen released Qwen3.6-27B, a dense, Apache 2.0 model with thinking + non-thinking modes and a unified multimodal checkpoint. Alibaba claims it beats the much larger Qwen3.5-397B-A17B on major coding evals, including SWE-bench Verified 77.2 vs 76.2, SWE-bench Pro 53.5 vs 50.9, Terminal-Bench 2.0 59.3 vs 52.5, and SkillsBench 48.2 vs 30.0. It also supports native vision-language reasoning over images and video. The ecosystem moved immediately: vLLM shipped day-0 support, Unsloth published 18GB-RAM local GGUFs, ggml added llama.cpp usage, and Ollama added a packaged release. Early user reports from @KyleHessling1 and @simonw were notably strong for local frontend/design and image tasks.
OpenAI quietly open-sources a practical privacy model: Multiple observers flagged OpenAI’s new Privacy Filter, a lightweight Apache 2.0 open model for PII detection and masking. According to @altryne, @eliebakouch, and @mervenoyann, it is a 1.5B total / 50M active MoE token-classification model with a 128k context window, intended for cheap redaction over very large corpora and logs. This is a more operationally interesting release than a generic “small open model”: it targets a concrete infra problem in enterprise/agent pipelines where on-device or low-cost preprocessing matters.
Xiaomi pushes agentic open models upward: @XiaomiMiMo announced MiMo-V2.5-Pro and MiMo-V2.5. Xiaomi positions V2.5-Pro as a major jump in software engineering and long-horizon agents, citing SWE-bench Pro 57.2, Claw-Eval 63.8, and τ3-Bench 72.9, with claims of 1,000+ autonomous tool calls. The non-Pro model adds native omnimodality and a 1M-token context window. Arena quickly listed MiMo-V2.5 in Text/Vision/Code evaluation, and Hermes/Nous integration followed via @Teknium.
Google Cloud Next: TPU v8, Gemini Enterprise Agent Platform, and Workspace Intelligence
Google’s infra announcements were substantial, not cosmetic: @Google and @sundarpichai introduced 8th-gen TPUs with a split design: TPU 8t for training and TPU 8i for inference. Google says 8t delivers nearly 3x compute per pod vs Ironwood, while 8i connects 1,152 TPUs per pod for low-latency inference and high-throughput multi-agent workloads. Commentary from @scaling01 highlighted an additional claim: Google can now scale to a million TPUs in a single cluster with TPU8t. The productization signal matters as much as the raw hardware: Google is clearly aligning chips, models, agent tooling, and enterprise control planes into one vertically integrated offering.
Enterprise agents became a first-class Google product surface: @GoogleDeepMind and @Google launched Gemini Enterprise Agent Platform, framed as the evolution of Vertex AI into a platform for building, governing, and optimizing agents at scale. It includes Agent Studio, access to 200+ models via Model Garden, and support for Google’s current stack including Gemini 3.1 Pro, Gemini 3.1 Flash Image, Lyria 3, and Gemma 4. Related launches included Workspace Intelligence GA as a semantic layer over docs/sheets/meetings/mail, Gemini Enterprise inbox/canvas/reusable skills, Agentic Data Cloud, security agents with Wiz integration, and Gemini Embedding 2 GA, a unified embedding model across text, image, video, audio, and documents.
Agents, Harnesses, Traces, and Team Workflows
The “agent harness” abstraction is hardening across vendors: OpenAI introduced workspace agents in ChatGPT, shared Codex-powered agents for teams that can operate across docs, email, chat, code, and external systems, including Slack-based workflows and scheduled/background tasks. Google made a parallel enterprise move with Gemini Enterprise Agent Platform, while Cursor added Slack invocation for task kick-off and streaming updates. The pattern is converging: cloud-hosted agents, shared team context, approvals, and long-running execution rather than single-user chat.
Developer ergonomics around harness/model independence improved: VS Code/Copilot rolled out bring-your-own-key/model support across plans and business/enterprise, enabling providers like Anthropic, Gemini, OpenAI, OpenRouter, Azure, Ollama, and local backends. This is strategically important because, as @omarsar0 noted, most models still seem overfit to their own agent harnesses. Cognition’s Russell Kaplan made the complementary business case: enterprise buyers want model flexibility and infrastructure that spans the full SDLC, not attachment to one lab.
Traces/evals/self-improvement are becoming the core agent data primitive: The strongest thread here came from LangChain-adjacent discussion. @Vtrivedy10 argued that traces capture agent errors and inefficiencies, and that compute should be pointed at understanding traces to generate better evals, skills, and environments; a longer follow-up expanded this into a concrete loop involving trace mining, skills, context engineering, subagents, and online evals. @ClementDelangue pushed for open traces as the missing data substrate for open agent training, while @gneubig promoted ADP / Agent Data Protocol standardization. LangChain also teased a stronger testing/evaluation product direction via @hwchase17.
Post-Training, RL, and Inference Systems
Perplexity and others shared more of the post-training playbook: @perplexity_ai published details on a search-augmented SFT + RL pipeline that improves factuality, citation quality, instruction following, and efficiency; they say Qwen-based systems can match or beat GPT-family models on factuality at lower cost. @AravSrinivas added that Perplexity now runs a post-trained Qwen-derived model in production that unifies tool routing and summarization and is already serving a significant share of traffic. On the research side, @michaelyli__ introduced Neural Garbage Collection, using RL to jointly learn reasoning and KV-cache retention/eviction without proxy objectives; @sirbayes reported a Bayesian linguistic-belief forecasting agent matching human superforecasters on ForecastBench.
The “minimal editing” problem in coding models got a useful benchmark treatment: @nrehiew_ presented work on Over-Editing, where coding models fix bugs by rewriting too much code. The study constructs minimally corrupted problems and measures excess edits with patch-distance and added Cognitive Complexity; it finds GPT-5.4 over-edits the most while Opus 4.6 over-edits the least, and that RL outperforms SFT, DPO, and rejection sampling for learning a generalizable minimal-editing style without catastrophic forgetting. This is one of the more practical post-training/eval contributions in the set because it targets a failure mode engineers actually complain about in production code review.
Inference efficiency work remained highly active: @cohere integrated production W4A8 inference into vLLM, reporting up to 58% faster TTFT and 45% faster TPOT vs W4A16 on Hopper; the details include per-channel FP8 scale quantization and CUTLASS LUT dequantization. @WentaoGuo7 reported SonicMoE throughput gains on Blackwell—54% / 35% higher fwd/bwd TFLOPS than DeepGEMM baseline—while maintaining dense-equivalent activation memory for equal active params. @baseten introduced RadixMLP for shared-prefix elimination in reranking, with 1.4–1.6x realistic speedups.
Top tweets (by engagement)
OpenAI workspace agents: @OpenAI launched shared, Codex-powered workspace agents for Business/Enterprise/Edu/Teachers.
Qwen3.6-27B release: @Alibaba_Qwen announced the new open 27B dense model with strong coding claims and Apache 2.0 licensing.
Google TPU v8: @sundarpichai previewed TPU 8t / 8i, with training/inference specialization.
Flipbook / model-streamed UI: @zan2434 showed a prototype where the screen is rendered as pixels directly from a model rather than traditional UI stacks.
OpenAI Privacy Filter: @scaling01 and others highlighted OpenAI’s new open-source PII detection/redaction model on Hugging Face.
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. Qwen 3.6 Model Releases and Benchmarks
Qwen 3.6 27B is out (Activity: 2576): Qwen 3.6 27B, a new language model, has been released on Hugging Face. This model features
27 billion parametersand is designed to improve upon previous iterations with enhanced performance benchmarks. A quantized version is also available, Qwen3.6-27B-FP8, which allows for more efficient deployment in environments with limited computational resources. The release includes detailed benchmark results, showcasing its capabilities across various tasks. The community is expressing excitement about the release, with some users highlighting the significance of the model’s performance improvements and the availability of a quantized version for broader accessibility.Namra_7 shared a benchmark image for Qwen 3.6 27B, which likely includes performance metrics such as inference speed, accuracy, or other relevant statistics. However, the specific details of the benchmarks are not described in the comment itself.
challis88ocarina mentioned a quantized version of Qwen 3.6 27B available on Hugging Face, specifically in FP8 format. Quantization can significantly reduce the model size and improve inference speed, making it more efficient for deployment without a substantial loss in accuracy. The link provided leads to the Hugging Face model repository for further exploration.
Eyelbee posted another image link, which might contain additional visual data or performance metrics related to Qwen 3.6 27B. However, the comment does not provide specific insights or details about the content of the image.
Qwen3.6-27B released! (Activity: 895): Qwen3.6-27B is a newly released dense, open-source model that excels in coding tasks, outperforming its predecessor, Qwen3.5-397B-A17B, on major coding benchmarks. It features strong reasoning capabilities across both text and multimodal tasks and offers flexibility with ‘thinking’ and ‘non-thinking’ modes. The model is released under the Apache 2.0 license, making it fully open-source and accessible for community use. More details can be found on their blog, GitHub, and Hugging Face. The comments reflect excitement and admiration for the Qwen team, with users expressing eagerness to utilize the model on their hardware and suggesting the team’s contributions are monument-worthy.
ResearchCrafty1804 highlights the impressive performance of Qwen3.6-27B, noting that despite having only 27 billion parameters, it surpasses the much larger Qwen3.5-397B-A17B model on several coding benchmarks. Specifically, it achieves scores of 77.2 on SWE-bench Verified, 53.5 on SWE-bench Pro, 59.3 on Terminal-Bench 2.0, and 48.2 on SkillsBench, outperforming the larger model by significant margins in each case.
bwjxjelsbd comments on the competitive landscape, expressing satisfaction that Alibaba is advancing with Qwen models after META’s perceived setbacks. The commenter hopes for continued competition and transparency, suggesting that META should open-source their Muse family models to maintain a healthy competitive environment.
Qwen3.6-35B becomes competitive with cloud models when paired with the right agent (Activity: 848): The post discusses the significant improvement in benchmark performance of the Qwen3.6-35B model when paired with the
little-coderagent, achieving a78.7%success rate on the Polyglot benchmark, placing it in the top 10. This improvement highlights the impact of using appropriate scaffolds, suggesting that local models may underperform due to harness mismatches. The author plans to test further on Terminal Bench and GAIA for research capabilities. Full details and benchmarks are available on GitHub and Substack. Commenters express surprise at the performance gains from scaffold changes, questioning the validity of benchmarks that don’t control for such factors. There’s also interest in using pi.dev for its extensibility in harnessing models.DependentBat5432 highlights a significant performance improvement in Qwen3.6-35B when changing the scaffold, noting a jump from
19%to78%. This raises concerns about the validity of benchmark comparisons that do not control for such variables, suggesting that scaffold choice can dramatically affect model performance.Willing-Toe1942 reports that Qwen3.6, when used with pi-coding agents, performs almost twice as well as opencode. This comparison involved tasks like modifying HTML code and searching online resources for documentation, indicating that the choice of agent can significantly enhance the model’s effectiveness in practical coding scenarios.
kaeptnphlop mentions the strong performance of Qwen-Coder-Next when paired with GitHub Copilot in VS Code, suggesting potential for further exploration with other tools like little-coder. This implies that integrating Qwen models with popular coding environments can leverage their strengths effectively.
Keep reading with a 7-day free trial
Subscribe to Latent.Space to keep reading this post and get 7 days of free access to the full post archives.