

[AINews] The Inference Inflection
a quiet day lets us reflect on the growing implications of the inference age
Just as we covered World Models early this year, we’ll be releasing a short miniseries on the CPU compute/sandbox industry on the pod over the coming weeks, and it’s a good time to explain why.
In recent days:
Noam Brown: “inference compute is a strategic resource, currently undervalued”
Sam Altman: “To a significant degree, we have to become an AI inference company now.”
Taken individually, these comments might seem unremarkable normal reactions to a very successful GPT 5.5 model launch. But in context they mark a very noteworthy reaction that you, dear reader, should probably be alerted to if you aren’t already taking this extremely seriously.
The proximal trigger for today’s op-ed is Intel CEO Lip-Bu Tan’s Q1 earnings call, where he gave numbers to illustrate the rising CPU (not GPU) compute demand:

Obviously an Intel CEO has obvious incentives to talk up CPU demand, but that does not mean he is wrong:

We’ve covered this trend in our SemiAnalysis pod (edited for readability):
Doug: We are kind of right at the exact five to six year period of the refresh cycle of COVID. So in 2020 - 2021, you bought like a hundred billion [01:52:00] dollars of CPUs. And so we’re right at the natural end of life for these chips.
[01:52:04] And so usually what you do is you have this big refresh of all these chips, but what what’s been happening instead is everyone has essentially scrounged all of their budget [for GPUs] as hard as they can… Everyone’s scrounged every single dollar they could to essentially invest in as much as AI as possible and just do maintenance CapEx on CPU. Ironically, at the same time for all this Claude Code stuff is going on. where is the software gonna run? on CPUs. So I think we’re gonna see some increasing utilization as well as the fact that RL is like actually heavily used for like RL gyms.
[01:52:52] You have to simulate software and it uses a lot of CPUs. So not quite like the orders of magnitude of GPU stuff, but it’s [01:53:00] just such a big trend, we might actually be seeing a CPU shortage partially ‘cause of this refresh cycle.
[01:53:17] swyx: Yeah. Yeah. And just general production agents as well. You know, we just yeah. Even RLMs take compute and you know, OpenClaw takes more compute and, and no, it’s just different slope, but at the same direction.
[01:53:30] Doug: It’s still an up slope. Yeah. And in a slope that, to be clear, has had massive underinvestment for the last two years.
and our NVIDIA GTC coverage of Jensen’s Keynote:
[50:41] Finally, AI is able to do productive work and therefore the inflection point of inference has arrived.
AI now has to think. In order to think, it has to inference. AI now has to do. In order to do, it has to inference. AI has to read. In order to do so, it has to inference. It has to reason. It has to inference. every part of AI every time it has to think it has to reason it has to do it has to generate tokens it has to inference it’s way past training now it’s in the in the field of inference so the inference inflection has arrived at the time when the amount of tokens the amount of compute necessary increased by roughly 10,000 times.
Now when I combine these to the fact that since in the last two years the computing demand of the work has gone up by 10,000 times and the amount of usage has probably gone up by a hundred times.
People have heard me say I believe that computing demand has increased by 1 million times in the last two years. It is the feeling that we all have. It is the feeling every startup has. It’s the feeling that OpenAI has. It’s the feeling that Anthropic has. If they could just get more capacity, they could generate more tokens. Their revenues would go up. More people could use it.
The more advanced, the smarter the AI could become. We are now at that positive flywheel system. We have reached that moment. The inference inflection has arrived.
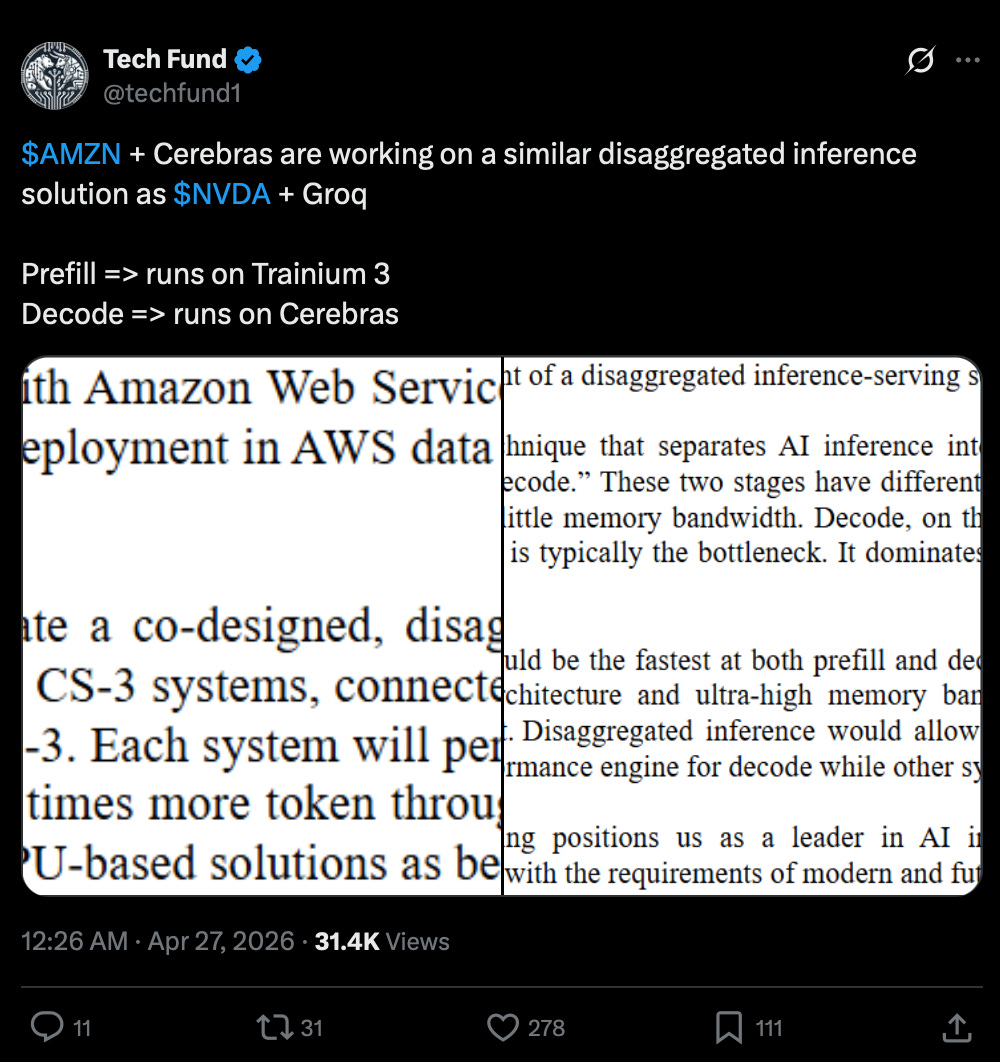
Apart from the CPU demand, the inference inflection has also resulted in unprecedented reshaping of GPU workloads as well. Prefill/Decode disaggregation is now the norm, with Nvidia buying Groq, Intel-Sambanova, and even Amazon jumping in on a similar Cerebras bandwagon that OpenAI and Cognition had previously struck:
AI News for 4/28/2026-4/29/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
Coding Agents Become Platforms: Codex, Cursor SDK, and VS Code Harness Upgrades
OpenAI is turning Codex from a coding tool into a general work surface: the strongest product signal today was not just usage enthusiasm, but the steady expansion of capabilities around persistent context, tools, integrations, and team rollout. OpenAI highlighted Codex for broader knowledge-work tasks like research synthesis, spreadsheets, and decision tracking in addition to code (OpenAI, follow-up, follow-up); launched Codex-only seats with $0 seat fee for eligible Business/Enterprise customers through end of June (OpenAIDevs); and added integrations like Supabase (coreyching) and a Figma plugin that turns implementation plans into FigJam boards (OpenAIDevs). Community posts also pointed to app-server usage, and richer agent workflows (gdb, aiDotEngineer).
Performance work is shifting from model latency to agent-loop systems engineering: OpenAI said moving Codex-style workflows to WebSocket mode on the Responses API keeps state warm across tool calls and cuts repeated work, yielding up to 40% faster agentic workflows (OpenAIDevs, reach_vb, pierceboggan). VS Code shipped a parallel stack of harness improvements: semantic indexing across workspaces, cross-repo search, chat session insights, skill context, remote control for Copilot CLI, and a prompt/agent evaluation extension aimed at refining prompts, skills, and instructions (pierceboggan, pierceboggan, code). The throughline is that coding-agent UX is now dominated by memory, retrieval, harness quality, and tool orchestration—not just raw model intelligence.
Cursor is making an explicit platform play: the new Cursor SDK exposes the same runtime, harness, and models that power Cursor for use in CI/CD, automations, and embedded agents inside products (cursor_ai, starter projects, customer examples). This is notable because it shifts Cursor from seat-based IDE product toward programmable agent infrastructure, a framing captured well by @kimmonismus. Taken together with Codex app-server and VS Code harness work, the category is clearly converging on headless agent runtimes + programmable harnesses + usage-based economics.
Agent Harness Engineering, LangGraph/Deep Agents, and Production AgentOps
Harnesses are emerging as a first-class optimization layer: multiple posts converged on the idea that model quality alone is insufficient; the harness around the model often determines production performance. The clearest research example was Agentic Harness Engineering, which makes harness evolution observable via revertible components, condensed execution evidence, and falsifiable predictions. Reported gains: Terminal-Bench 2 pass@1 from 69.7% to 77.0% in ten iterations, beating a human-designed Codex-CLI baseline at 71.9%, while also transferring across model families and reducing token use on SWE-bench Verified by 12% (omarsar0). Related work on HALO describes recursively self-improving agents using trace analysis to patch harness failures, claiming AppWorld improvement from 73.7 to 89.5 on Sonnet 4.6 (samhogan).
LangChain’s Deep Agents product line is leaning into model-specific harness tuning and deployability: new Harness Profiles let teams version per-model prompts, tools, and middleware, with built-in profiles for OpenAI, Anthropic, and Google models (LangChain_OSS, LangChain, Vtrivedy10). LangChain also pushed DeepAgents Deploy, a low-code deployment path using a small set of markdown/config files and LangSmith-backed tracing (hwchase17). The broader message from LangChain staff was consistent: open harnesses, open evals, and OSS-friendly model mixes matter because closed models are becoming too expensive for many agent workloads (hwchase17, Vtrivedy10).
Cloudflare continued to flesh out its “agents as software” stack with ideas like execution ladders and, more concretely, making agents able to become Cloudflare customers—create accounts, register domains, start paid plans, and get tokens for deployment (threepointone, Cloudflare). This is a meaningful sign that vendors are starting to expose business workflows directly to agents rather than treating them as passive copilots.
Model Releases and Benchmarks: Mistral Medium 3.5, Granite 4.1, Ling-2.6, and Open-Model Price Pressure
Mistral Medium 3.5 was the day’s most debated model release. Early commentary pegged it as a dense 128B model (scaling01), with Unsloth describing it as a vision reasoning model that can run locally on roughly 64GB RAM and publishing GGUFs/guidance (UnslothAI). Reaction split sharply: some criticized its 128K context, architecture choices, and pricing versus large Chinese open MoEs (eliebakouch, scaling01), while others argued Mistral is making a deliberate enterprise reliability/instruction-following bet rather than chasing raw benchmark spectacle (kimmonismus).
IBM Granite 4.1 added three new open-weight, Apache 2.0 non-reasoning models—30B, 8B, 3B—with a strong emphasis on openness and token efficiency (ArtificialAnlys). The standout claim is that Granite 4.1 8B used only 4M output tokens on the Artificial Analysis Intelligence Index, versus 78M for Qwen3.5 9B, while scoring 61 on the AA Openness Index. Intelligence lags stronger peers, but the family looks aimed squarely at enterprise/edge deployments where cost and transparency matter more than leaderboard position.
Open-weight competitive pressure continues to intensify: Ant OSS’s Ling-2.6-flash was cited as ~107B MoE, MIT-licensed, with 61.2 SWE-bench Verified and strong math scores (nathanhabib1011); Ling-2.6-1T also landed with day-0 vLLM support (vllm_project). Meanwhile, Tencent Hunyuan open-sourced Hy-MT1.5-1.8B-1.25bit, a 440MB, fully offline translation model for phones covering 33 languages, 1,056 translation directions, and claiming parity with commercial APIs / 235B-scale models on standard MT benchmarks via aggressive 1.25-bit quantization (TencentHunyuan). On the market side, multiple posts underscored how rapidly pricing is falling for capable open models, e.g. Qwen 3.5 Plus at $3/M output tokens (MatthewBerman) and MiMo-V2.5 Pro shifting the Pareto frontier in Code Arena at $1/$3 per M tokens (arena).
Inference, Kernels, and MoE Systems: FlashQLA, vLLM on Blackwell, torch.compile, and GLM-5 Serving
Qwen’s FlashQLA is a notable long-context kernel release: Alibaba introduced FlashQLA, high-performance linear attention kernels on TileLang, reporting 2–3× forward and 2× backward speedups, especially for small models, long-context workloads, and tensor-parallel setups. The design centers on gate-driven automatic intra-card CP, algebraic reformulation, and fused warp-specialized kernels (Alibaba_Qwen, benchmark thread). It is explicitly positioned for agentic AI on personal devices, which fits a broader trend of long-context optimization migrating from cloud-only infra to edge-friendly runtimes.
vLLM and Blackwell co-design is landing real throughput wins: vLLM reported #1 output speed on Artificial Analysis for DeepSeek V3.2 at 230 tok/s, 0.96s TTFT and also strong results on Qwen 3.5 397B using DigitalOcean serverless inference on NVIDIA HGX B300, with optimizations including NVFP4 quantization, EAGLE3 + MTP speculative decoding, and per-model kernel fusion (vllm_project). SemiAnalysis separately highlighted gains from vLLM 0.20.0 and MegaMoE kernels for DeepSeek v4 Pro on GB200 (SemiAnalysis_). This is one of the clearer examples of hardware/software/model co-design translating into publicly visible latency numbers.
More engineers are sharing the “middle layer” details between models and GPUs: a useful thread on torch.compile broke down Dynamo → pre-grad → AOT autograd → post-grad → Inductor, including where to inject custom FX passes for inference optimizations (maharshii). John Carmack posted a reminder that GPU library performance remains extremely path-dependent and notchy, noting a 10× regression in
torch.linalg.solve_exwhen going from 511×511 to 512×512, apparently due to a different internal path withCudaMalloc/Free(ID_AA_Carmack, follow-up). Zhipu AI also published a good serving postmortem on GLM-5, detailing KV cache race conditions, HiCache synchronization bugs, and LayerSplit, which reportedly improved prefill throughput by up to 132% for long-context coding-agent serving (Zai_org).
Research Signals: Knowledge Probes, Web-Agent Benchmarks, Multimodal/Science Infrastructure
Incompressible Knowledge Probes (IKP) is one of the more provocative research threads**: @bojie_li claims that factual knowledge accuracy over 1,400 questions / 188 models / 27 vendors gives a strong log-linear signal of model size (R² = 0.917 on open-weight models from 135M to 1.6T params). The paper argues factual capacity does not compress over time the way some “reasoning compresses” narratives suggest, and uses the fitted curve to estimate closed-model sizes. Whether one buys the estimates or not, the work is valuable as a reminder that black-box evals still leak architecture-scale information.
Keep reading with a 7-day free trial
Subscribe to Latent.Space to keep reading this post and get 7 days of free access to the full post archives.