

Developers as the distribution layer of AGI (OpenAI Dev Day 2025, ft. Sherwin Wu and Christina Huang)
A quick recap of the 2025 OpenAI DevDay coupled with an exclusive interview with the OpenAI Platform team that shipped AgentKit and related products!
Apart from the Jony Ive and Stargate stories happening offstage, the biggest takeaway from OpenAI’s 2025 Dev Day was how the company is commited to being a proper developer and app distribution platform even as it scales a leading frontier research lab, consumer chatbot, and new social network. For a developer, the number of product names can be a little overwhelming, so we drew you a little flow chart:
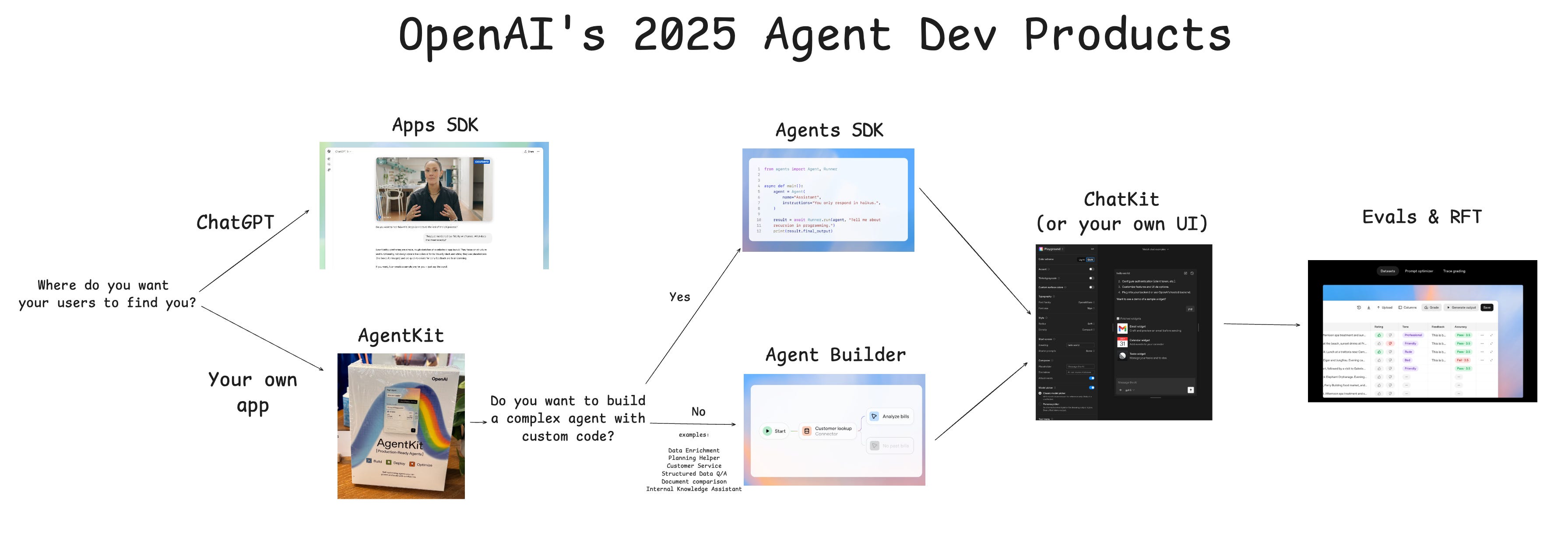
As the only podcast to deeply cover DevDay 2023 and DevDay 2024, we were very impressed by DevDay 2025 and consider it the best one yet, both in terms of on-the-ground execution and the confidence expressed in the launches. Even if you don’t have time to read through the full slate of releases, the 50 min keynote is a must watch:
One of our most popular episodes last year was with Michelle Pokrass, then of the API team, who deeply believed that APIs are the solution for developers to do the last mile of AGI distribution with OpenAI, even if AGI isn’t fully here yet, aka “API = AGI”:

And it seems like OpenAI DevDays are the company’s commitment to that mission and a thriving developer ecosystem (for those who manage to not get steamrolled).
But first, let’s get the “smaller” launches out of the way.
Models, models, and other launches
One very impressive thing about OpenAI is that they continue to not hold models back in the API. Every year there has been some excitement about a ChatGPT capability leading into a DevDay, and every year OpenAI has not disappointed by holding back some capability from API release: DevDay 2023 included GPT4 Vision, Dall-E 3, and Code Interpreter, Dev Day 2024 gave us the Realtime Voice API while everyone was still excited about it.
Dev Day 2025 gave us every frontier OpenAI API we wanted:
gpt-5 pro (model): https://platform.openai.com/docs/models/gpt-5-pro
sora-2 (model): https://platform.openai.com/docs/models/sora-2
sora-2-pro (model): https://platform.openai.com/docs/models/sora-2-pro
Video generation with Sora (docs): https://platform.openai.com/docs/guides/video-generation
Sora 2: Prompting Guide (cookbook): https://github.com/openai/openai-cookbook/blob/16686d05abf16db88aef8815ebde5c46c9a1282a/examples/sora/sora2_prompting_guide.ipynb#L7
and then some distillations we didn’t even know we wanted:
gpt-realtime-mini-2025-10-06 (model): https://platform.openai.com/docs/models/gpt-realtime-mini (70% cheaper)
gpt-audio-mini-2025-10-06 (model): https://platform.openai.com/docs/models/gpt-audio-mini
gpt-image-1-mini (model): https://platform.openai.com/docs/models/gpt-image-1-mini (80% cheaper)
Prompting some somewhat nice comments:
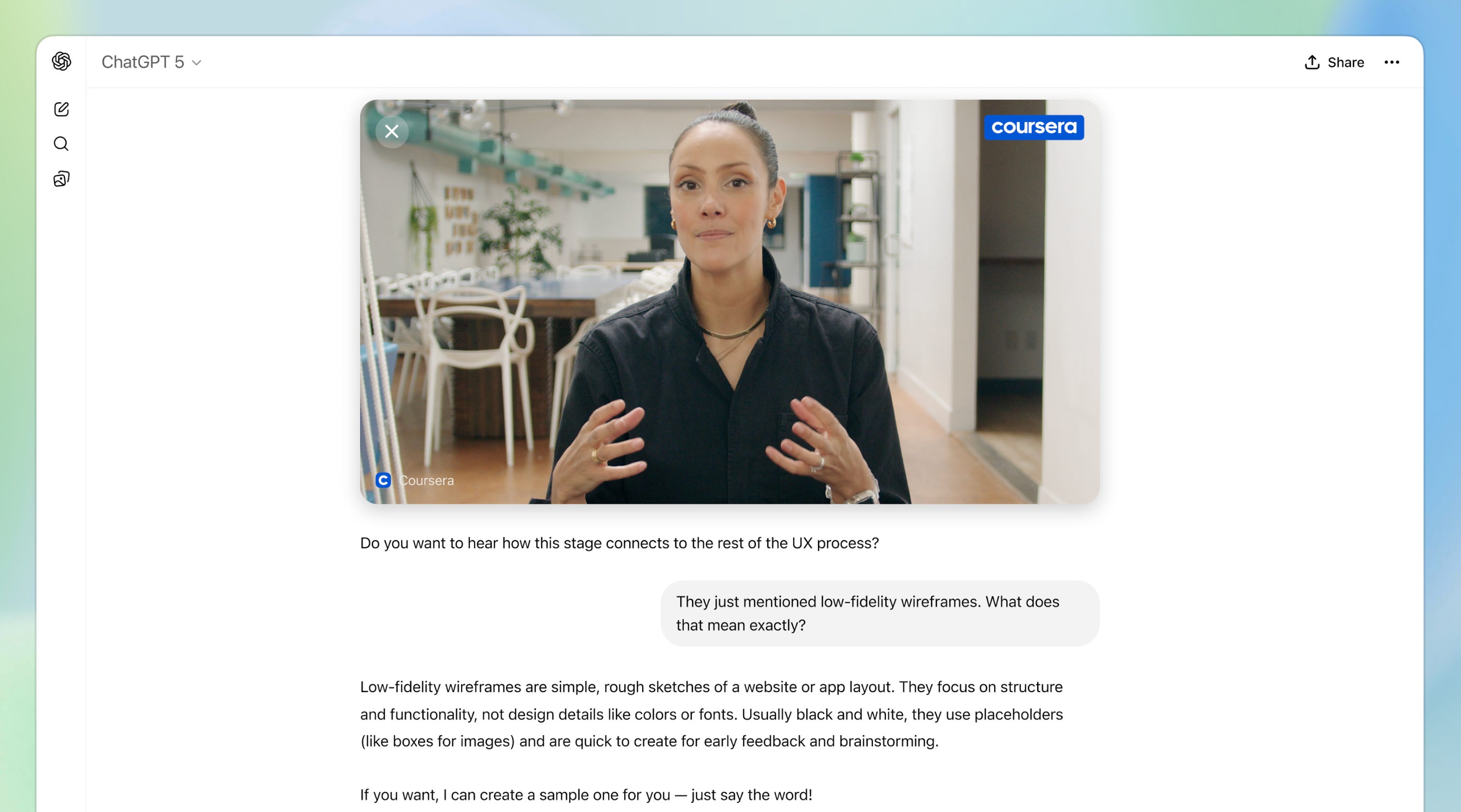
Apps in ChatGPT (Apps SDK)
“Today we’re going to open up ChatGPT for developers to build real apps inside of ChatGPT. This will enable a new generation of apps that are interactive, adaptive, and personalized that you can chat with. To build them, we are launching a new Apps SDK, now available in preview. With the Apps SDK, you get the full stack: you can connect your data, trigger actions, and render a fully interactive UI and more. The Apps SDK is built on MCP. You have full control over your backend logic and frontend UI. We’ve published the standard so anyone can integrate the Apps SDK. When you build with the Apps SDK, your apps can reach hundreds of millions of ChatGPT users.” — Sam Altman
When I first wrote Why MCP Won back in March, I didn’t expect OpenAI to adopt it so quickly, much less to now be the first to turn it into the basis of a full app store platform. I’ve been guilty before of getting too excited about ChatGPT’s attempts to be an app store, but objectively this is the best shot yet (though success is far from guaranteed). I happened to be listening to an entrepreneurship podcast telling the story of starting a $745m business the day Mark Zuckerberg launched the Facebook developer platform in 2007, and it was an interesting reminder that while the Apps SDK itself may not be the most exciting to all developers, it is very very exciting for the kind of developer that knows how to take advantage of a new app store to get abnormal distribution. In his media briefing yesterday, Greg Brockman even said that some people were able to build sustainable businesses off of Custom GPTs — while certainly not a common experience, a more full fledged App Store certainly creates more opportunity.
I also think the technical accomplishments in making this happen should be appreciated better - from the innovative React component bundling for an iframe target solution so you can provide -any- custom UI component to your ChatGPT App, to the live data flow demonstrated by the Coursera App in the keynote, where live video state is conveyed to ChatGPT so you can do arbitrary queries as you watch.
AgentKit
First of all, the box set at Dev Day was hilarious:

But there is a LOT to unpack here and you can be easily forgiven for missing some pieces:

Latent Space pod with the AgentKit team (live at DevDay)
This is where the bulk of today’s podcast lies, as we got to sit down with Christina after her big Ben Thompson approved demo and ask her and Sherwin more about the finer points of the Agent Builder and broader AgentKit vision:
As a side note, we didn’t cover this in the pod but it is interesting that Guardrails was one of the most exciting open source AI Engineering projects 2 years ago, but since Nvidia joined the fray and now increasingly more and more developer platforms are introducing their own guardrails, they seem to be another 2023-era idea that was more of a feature than a product, like vector indexes for embeddings (Shreya has since gone up the stack to Snowglobe, a simulation engine for user testing AI products, check it out).
Guests
Sherwin Wu: Head of Engineering, OpenAI Platform https://www.linkedin.com/in/sherwinwu1/ https://x.com/sherwinwu?lang=en
Christina Huang: Platform Experience, OpenAI https://x.com/christinaahuang https://www.linkedin.com/in/christinaahuang/
Thanks very much to Lindsay and Shaokyi for helping us set up this great deepdive into the new DevDay launches!
Transcript
Alessio [00:00:04]: Hey, everyone. Welcome to the Latent Space podcast. This is Alessio from the Recurrent Labs, and I’m joined by Swyx, editor of Latent Space.
swyx [00:00:11]: Hello, hello. And we are here in the OpenAI Dev Day studio with Sherwin and Christina from the OpenAI platform team. Welcome. Thank you for having us. Yeah, it’s always good to be here. Yeah, it’s such a nice thing. We’ve covered like three of these Dev Days now, and this is like the first time it’s been like so well organized that we have our own little studio, podcast studio, in the Dev Day venue. And it’s really nice to actually get a chance to sit down with you guys. So thanks for taking the time.
Sherwin [00:00:38]: Yeah, I feel like Dev Day is always a process, and we’ve only had three of them, and we try to improve it every time. And I actually, I know for a fact that I think we have this podcast studio this time because the podcast interviews and the interviews with folks like yourselves last time went really well. And so I want to lean into a little bit more. I’m glad that we were able to have this studio for you all. We were kneeling on the ground interviewing like Michelle last year. I don’t know.
Alessio [00:01:00]: I just saw it post-production. I thought it was...
swyx [00:01:03]: We had to have people like... We had to like cordon off the area so they wouldn’t walk in front of the cameras.
Alessio [00:01:07]: Yeah, people would just come up, hey, good to... I’m like, we’re like recording.
Christina [00:01:10]: I guess if you guys have been to three, like what stood out from today or what’s your favorite part?
swyx [00:01:17]: I feel like the vibes are just a lot more confident. Like you are obviously doing very well. You have the numbers to show it. You know, I just... Every year in Dev Day, you report the number of developers. This year it’s 4 million. I think last year it was like three. And I have more questions. I’ve got that kind of stuff. But also like just like very interesting, very high confidence launches. And then also like I think the community is clearly much more developed. Like I think there’s just a lot more things to dive into across the API surface area of OpenAI than I think last year in my mind.
Alessio [00:01:56]: I don’t know about you. Yeah, and we were at the OG Dev Day, which was the DALI hack night at OpenAI in 2022. And I think Sam spoke to like 30 people. So I think it’s just crazy to see the...
Sherwin [00:02:06]: Yeah, honestly, I think it’s like it’s kind of similar to this podcast studio, which is I think we’ve had a number of Dev Days now. We honestly were like slowly figuring things out as a company over time as well. And both from a product perspective and also from a like how we want to present ourselves with Dev Day. And at this point, we’ve had a lot of feedback from people. I actually think a lot of attendees will get like an email with like a chance for feedback as well. And we actually like do read those and we act on those. And like one of the things that we did this year that I really liked were all of those. Like there was like some art installations and like the little arcade games that we did, which was, you know, came up with via like engaging with the feedback.
Christina [00:02:43]: Yeah, the arcade games were so fun. I loved like the theme of all the ASCII art throughout. This is my first SF Dev Day, but I’ve been to the Singapore one. That was actually my first week there. Oh, yeah, that’s the one I spoke about. Yeah, I saw you there. That was my first week of OpenAI. So really in the deep end.
swyx [00:02:57]: Put it on a plane to Singapore. Yeah. Yeah, that’s awesome. Well, so, you know, that’s congrats on everything. And like kudos to the organizing team. We should talk about some developer API stuff. Yeah. So we’re going to cover a few of the things. You’re not exactly working on Apps SDK, but I guess what should people just generically take away? What should developers take away from the Apps SDK launch? Like how do you internally view it?
Sherwin [00:03:22]: So the way that I think about it is I actually view OpenAI since the very beginning as a company that is really valued. Kind of like opening up our technology and like bringing it out to the rest of the world. One thing we talk about a lot internally is. You know, our mission at OpenAI is to, one, build AGI, which we’re trying to do, and then, but two, you know, potentially, you know, just as important is to bring the benefits of that to the entire world. And one thing that we realized very early on is that we as a company, it’s very difficult for us to just bring it to every truly every corner of the world. And we really need to rely on developers, other third parties to be able to do this, which is, you know, Greg talked about the start of the API and like kind of how that was formulated. But that was part of, you know, that mentality, which is we. We need to rely on developers and we need to open up our technology to the rest of the world so that they can partake for us to really fulfill our mission. So the API obviously is a very natural way of doing that, where we just literally expose API endpoints or expose tools for people to build things. But now that we have, you know, ChatGPT with its 800 million weekly active users, I forgot the stat that we shared. I think it’s like now the fifth or sixth largest website in the world.
swyx [00:04:30]: And the number one and number two most downloaded on the Apple App Store.
Sherwin [00:04:35]: Oh, yeah, with Sora, yeah, yeah, but I don’t like it moves around all the time.
swyx [00:04:37]: So it’s kind of hard to celebrate and, you know, just screenshot it when it’s good.
Sherwin [00:04:40]: Yeah, we definitely screenshot it when it was good. But kind of going back to my main point is like we’ve always kind of engaged the developers as a way for us to bring the benefits of of AGI to the rest of the world. And so I view this as actually a natural extension of this. Candidly, we’ve actually been trying to do this, you know, a couple of times with the last dev day with GPT, two dev days ago with I’m sorry, two devs ago. With GPTs and plugins, which was, I think, not tied to a dev day. So I view this as like, again, we love to deploy things so iteratively and I view it as like just a continuation of that process and also engaging deeply with developers and helping them benefit from some of the stuff that we have, which which in this case is ChatGPT distribution.
Alessio [00:05:23]: And when so apps SDK is built on the MCP protocol, when did OpenAI become MCP built? I’m sure internally you must have had, you know, the signed discussions before about doing your own protocol. When did you buy into it and how long ago was that?
Christina [00:05:38]: I think it was in in March, I want to say. It’s hard for me to remember kind of like the exact.
swyx [00:05:42]: March was the takeoff of MCP.
Christina [00:05:44]: Yeah, yeah. So we built the agents SDK and we launched that alongside the responses API in early March. And I think as MCP was growing, that felt like a really and, you know, we’re building kind of a new agentic API that can call tools and just be much more powerful. MCP was kind of like the natural protocol that developers were already using.
Christina [00:06:05]: I think like in March is when we added in MCP to agents SDK first and then soon after with kind of our other.
Sherwin [00:06:11]: Yeah, I think there was like a tweet or something we did where it was like OpenAI, you know, is.
Christina [00:06:15]: Yeah, there was definitely a moment. I think there was a specific moment in a specific tweet.
Sherwin [00:06:19]: But what I will say, though, is like, and this is honestly the credit to the team at Anthropic that kind of created MCP is I really do think they treat it as an open protocol. Like we work very closely with, I think, like David and the folks on the like, you know, consortium. And they are. They are not, you know, really viewing it as this like thing that is specific to Anthropic. They really view it as this open protocol. There is like it is an open protocol. The way in which you make changes feels very open. We actually have a member of our team, Nick Cooper, who is sitting on kind of like that, that steering committee for MCP as well. And so I think they are really treating it as something that is easy for us and other companies and everyone else to embrace, which I think they should because they they do want it to be something that is very embraced by all. And so because of that, I think it makes it a little bit easier for us to. To embrace it. And honestly, it’s a great it’s a great protocol. Like, it’s very general. It’s already solved. Like, why would you make it? Yeah, yeah, it’s very general. There’s obviously still more to do with it, but it was very easy for us to, you know, integrate because of how how how streamlined and how simple it was. Yeah.
swyx [00:07:18]: My final comment on apps SDK stuff and then we’ll move to AgentKit is, you know, like I always see like in abstractly when you sort of wireframe a website or an AI app, it used to be that the initial AI integration on the website would be you have to have an API. You have the normal website and then you have a little chat bot app and now it’s kind of like inverted where there’s ChatGPT at the at the top layer and then it’s like turn out the website embedded inside of it. And it’s kind of like that inversion that I honestly have been looking for for a little bit. And I think it’s really well done, like actually all like the integrations and the custom UI components that come up. You had like Canva on the keynote there and it looks like Canva, but like you can chat with it in all your the context of your ChatGPT. That is an experience I’ve never seen. Yeah.
Sherwin [00:08:06]: And I think that that’s kind of back to the iterative like learning that we’ve had that I think was because we’ve learned a lot from plugins. So like when we launched plugins, I remember one of the feedback that we got, I don’t know if, you know, people here really remember plugins. It was like March. Oh, yeah. Twenty three. Yeah. I’m like one of the points of feedback was like, oh, you can integrate retail. We told like, you know, all these companies that you can integrate these plugins into ChatGPT, but they really didn’t have that much control over how exactly it was used. It was really just like a tool that the model could call and you were just like really bound by ChatGPT. And so I think like you can kind of see the evolution of our product with this. And like this time we realized how important it was for companies, for third party developers to really own and like steer the experience and make it feel like themselves, help them, you know, like really preserve their own brand. And so and, you know, I actually don’t think we would have gotten that learning had we not, you know, had all these other steps beforehand.
Alessio [00:08:54]: Awesome. Christina, you were the star today on stage with the agent kit demo. You had eight minutes to build an agent. You had a minute to spare. And then you.
Christina [00:09:03]: Yeah, I wasn’t sure, honestly, I was like, let’s do a little bit less testing and maybe we, I don’t know how much time I killed on that. I was extremely stressed when the download came in.
Sherwin [00:09:14]: I was like, if a UI bug is what like takes the demo down, I’m going to be so sad.
Christina [00:09:17]: I think it was a full screen, yeah, like focus thing. I heard the window wasn’t in focus or something, yeah.
Alessio [00:09:23]: Maybe you want to introduce agent kit to the audience.
Christina [00:09:26]: Yeah, so we launched agent kit today, full set of solutions to build, deploy and optimize agents. I think a lot of this comes from working with API customers and realizing how hard it actually is to take, to build agents and then actually take them into production. Hard to get kind of that confidence and the iterative loop and writing prompts, optimizing them, writing evals, all takes a lot of expertise. And so kind of taking those learnings and packaging them into a set of tools that makes it a lot easier and kind of intuitive to know what you need to do. And so there’s a few different building blocks. That can be used independently, but they’re kind of stronger together because you then get the whole end to end system and releasing that today for people to try out and see what they build.
swyx [00:10:13]: Yeah, so I find it hard to hold all the building blocks in my head, but actually chronologically, it’s really interesting that you guys started out with the agent SDK first, and then you have agent builder, you have a connector registry, you have chat kit, and then you have the eval stuff. Am I missing any major components?
Sherwin [00:10:32]: Those are the main moving parts, right? Yeah, I think that’s it. And then, I mean, we also still have the RFT fine tuning API, but we technically group it outside of the agent kit umbrella.
swyx [00:10:42]: Got it, got it, got it. Yeah, so it’s weird how it develops, and it’s now become the full agent platform, right? And I think one thing that I wasn’t clear about when I was looking at the demo was, it’s very funny because what you did on stage was build a live chat app for Dev Day’s website.
Christina [00:11:02]: Yeah, did you get a chance to try it out?
swyx [00:11:03]: Yeah, I tried to try it out. It was awesome. And actually, I kind of wanted to ask how to deploy it. Where’s the merch? Yeah, exactly. I was like, where’d you click the merch? Anyway, and this is very close to home because I’ve done it for my conferences, and it’s a very similar process. But I think what was not obvious is how much is going to be done inside of agent builder. I see there are some actually very interesting nodes that you didn’t get to talk about on stage, like user approval. That’s a whole thing. And like transform and set state, like there’s kind of like a Turing complete machine in here.
Christina [00:11:35]: Yeah. Yeah, so I mean, I think again, like this is the first time that we’re showing agent builder, and so it’s definitely the beginning of what we’re building. And human approvals, like one of those use cases that we want to go pretty deep on, I think. The node today that I showed is pretty simple, like binary approval. Approve rejects. It’s similar to kind of what you’d see for MCP tools of approving that an action can take place. Yeah. But I think what we’ve seen with much more complex workflows from our users is that it’s actually quite advanced, like human in the loop interactions. Sometimes these could be over the course of weeks, right? It’s not just kind of simple approval for tool. There’s actual decision making involved in it. And I think as we work with those customers, we definitely want to continue to go deeper onto those use cases, too.
Alessio [00:12:21]: Yeah. What’s the entry point? So are developers also supposed to come here and then do the two-code export? Yeah. Or just segment the use cases? Yeah.
Christina [00:12:31]: So I think the two reasons that you would come to Agent Builder are one, kind of more as a playground, right? To kind of model and iterate on your systems and write your prompts and optimize them and test them out. And then you can export it and run it in your own systems using Agents SDK, using kind of other models as well. The second would be kind of to get all of the benefits of us deploying that for you, too. So you can kind of use maybe like natural language to describe what type of agent you want to build. Model it out. Bring in subject matter experts so that you really have this canvas for iterating on it and getting feedback. You know, building data sets and kind of getting feedback from those subject matter experts as well. And then being able to deploy it all without needing to handle that on your own. And that’s a lot of the philosophy around how we’re building it with ChatKit as well, right? You can kind of take pieces of it. You can have a more advanced integration where it’s much more customized. But you also get a really natural path of going live. With really kind of easy defaults as well. Yeah.
Alessio [00:13:32]: Do you see it as a two-way thing? So I build here. I go to code. Then maybe I make changes in code. And then I bring those changes back to the agent builder.
Christina [00:13:41]: I think eventually that’s definitely what we want to do. So maybe you could start off in code. You could bring it in. We’ll also probably have like ability to, you know, run code in the agent builder as well. And so I think just a lot of flexibility around that.
Sherwin [00:13:54]: The one thing I’d say, too, is a lot of the demos. The demos that we showed today I think were like, you know, aired on the side of Simplicity just so that the audience could kind of see it. But like if you talk to a lot of these customers, like they’re building like pretty complex. Like you got to like zoom out on that canvas quite a bit to kind of like see the full flow. And then for us, you know, we were kind of like working with a lot of customers who are doing this. And then, you know, if you turn that into like an actual agent SDK like file, it’s like pretty long. And so we saw a lot of like benefit from having the visual set up here, especially as the set up grows longer and longer. It would have been a little difficult to kind of showcase this. Yeah. You can do it in eight minutes. Right. Yeah. You can do it in eight minutes. But like even with some of the presets that we have on the site. Yeah, exactly. So one of the things. Yeah. Yeah.
Christina [00:14:33]: One of the things that we launched today as well alongside just like the canvas is a set of templates that we’ve actually gathered from our engineers who are working in the field with customers directly of like the kind of common patterns that they have in our own basically like playbooks when we’re working with customers on customer support, document discovery. And so kind of publishing those as well.
swyx [00:14:54]: Data enrichment. Yeah. Yeah. Planning helper, customer service, structured data Q&A, document comparison. That’s nice. Internal knowledge assistant. Yeah. Yeah. Yeah.
Christina [00:15:01]: And I think like we just plan to add more to those as we can kind of build those out.
swyx [00:15:06]: I always wonder if there should be, so you’re not the only agent builders, but obviously by default of being an open AI, you are a very significant one. Any interest in like a protocol or like interop between different open source implementations of this kind of pattern of agent builder?
Sherwin [00:15:23]: I think we’ve thought about it. Especially around, I’d say agents SDK. I would actually say maybe even like zooming out a bit more from just this is like, yeah, we were also sitting here and kind of like observing like things being made over and over again. Even like besides like agent workflows, we’re kind of launching what the industry is trying to do with responses, like what we’ve done with responses API, like stateful APIs. And so, you know, obviously we were the first one to launch responses API, but like a couple of other people have kind of adopted, I think Grok has it in their API. I think I saw LMSYS just did something recently in walls, but not, you know, not everyone. And so, unfortunately I don’t have a great answer today of like yes or no, but we are kind of like assessing everything and trying to see like, hey, you know, there has been a lot of value with MCP, with hopefully with our commerce protocol as well. ACP, yeah, that’s the, I definitely did not forget the name.
Sherwin [00:16:20]: And so like even thinking about like what we want to do with agents. Yeah. So I think that’s kind of like the same thing with the agent workflow, the portability story around that, as well as the portability, I’d say even of like responses API would be great if, you know, that could be a standard or something. And developers don’t need to, you know, like build three different stateful API integrations if they want to use different models. Yeah.
Christina [00:16:38]: And I think that’s one of the, so it’s not exactly a protocol, but one of the things that we launched today with evals too is ability to use like third party models as well and kind of bring that into one place. And so I think definitely kind of see where the ecosystem is at, which is, you know, using multi-models and kind of having.
swyx [00:16:55]: Third party models as in non-open air models? Yeah.
Sherwin [00:16:57]: Yeah. It’ll work with evals starting today. Yeah. Okay. Got it. We have a really cool setup with open router where we’re working with them and then you can bring your open router setup. And then with that, you can actually, you know, you write your evals using our data sets tool or user data set tool to create a bunch of evals. And you’d actually be able to hit a bunch of different model providers. Yeah. You know, take your pick from wherever, even like open source ones on together and see the results in our product.
swyx [00:17:24]: Yeah. That’s awesome. Speaking more about evals, right? Like I think I saw somewhere in the release docs that you basically had to expand the evals products a little bit to allow for agent evals. Maybe you can talk about like what you had to do there.
Sherwin [00:17:41]: Yeah.
Christina [00:17:43]: Yeah.
Sherwin [00:17:43]: I was going to say, so the, I actually think agent evals is still a work in progress. Yeah. I think we’ve like made maybe 10% of the progress that we need here. For example, I think we could still do a lot more around multimodal evals. But the main progress that we made this time was kind of allowing you to take traces. So the agent SDK has like really nice traces feature where if you run, if you define things, you can have like a really long trace. Allowing you to use that in the evals product and be able to grade it in some way, shape or form over the entirety of what it’s supposed to be doing. I think this is step one. Like I think it’s good to be able to do this. But I think our roadmap from here on out is to, you know, really allow you to break down the different parts of the trace and allow you to eval and like kind of like measure each of those and optimize each of those as well. A lot of times this will involve human in the loop as well, which is why we have the human in the loop component here too. But if you kind of look at our evals product over the last year, it’s been very simple. It’s been much more geared towards this like simple prompt completion setup. But obviously, as we see people doing these longer agentic traces, like, you know, how do you even evaluate a 20 minute task correctly? And it’s like, it’s a really hard problem. We’re trying to set up our evals product and move in that way to help you not only evaluate the overall trajectory, but also individual parts of it. Yeah.
swyx [00:19:01]: I mean, the magic keyword is rubrics, right? Everyone wants LM as judge rubrics. Yeah. Yeah.
Sherwin [00:19:07]: Yeah.
swyx [00:19:08]: Obviously where this will go. Okay, great. Yeah. The other thing I think online, I see the developer community very excited about is sort of automated browser. So, you know, we have automated prompt optimization, which is kind of evals in the loop with prompts. What’s the thinking there? Where’s things going?
Christina [00:19:22]: Yeah. So, we have automated prompt optimization, but again, like, I think this is an area that we definitely want to invest more in. We, I think, did a pretty big launch of this when we launched GPT-5 actually, because we saw that it was pretty difficult as new models come out to kind of learn all the quirks about a new model. Yeah, the prompt optimization. Right. There’s like, we have a big prompting guide, right, for every model that we launch. And I think building out a system to make that a lot easier. We definitely want to tie that in like completely with evals. We should be able to kind of improve your prompts over time, improve your agents over time as well if they’re kind of made in the agent builder based on the evals that you’ve set up. And so, I think we see this as like a pretty core part of the platform of basically suggested improvements to the things that you’re building.
Sherwin [00:20:05]: I actually think it’s a really cool time right now in prompt optimization. I’m sure you guys are seeing this too. It’s like not only there are a lot of products kind of like gearing around this, so like kind of what we’re thinking about. But I also think like there’s a lot of interesting research around this. Like GEPA with like the Databricks folks are actually doing really cool stuff around this. We’re obviously not doing any of the cool GEPA optimization right now in our product. But we’d love to do that soon. And also, it’s just an active research area. So like, you know, whatever Matei and the Databricks folks like might think about next, what we might, you know, think about internally as well. Whatever new prompt optimization techniques come out, I think we’d love to be able to have that in our product as well. And yeah, and it’s interesting because it’s coming at a time when people are realizing that prompt. You know, like I feel like two years ago people were like, oh, at some point prompt, like prompting is going to be dead. No. Like, you know, and it’s like, you know. It’s gone up. Yeah, yeah, yeah. And if anything, it is like become more and more entrenched. And I think that, you know, there’s this interesting trend where like it’s becoming more and more important. And then there’s also interesting cool work being done to like further entrench like prompt optimization. And so that’s why I just think it’s like a very fascinating, you know, area to follow right now. And also was an area where I think a lot of us were wrong two years ago. Because if anything, it’s only gotten better. It’s only gotten more important.
swyx [00:21:16]: Yeah. I would say like what Shunyu used to work at OpenAI and now is an MSL. We call this kind of like zero gradient fine tuning or zero gradient updating because you’re just tweaking the prompts. But like it is so much prompt that is actually like you end up with a different model at the end of it.
Sherwin [00:21:33]: There’s a lot of like things that make it more practical to just like even from our perspective, like we have a fine tuning API. And like it is extremely difficult for us to run, you know, and serve like all of these different snapshots. Like, you know, Laura’s great MSL just, you know, sorry, Thinking Labs just published. John Schulman just had a cool blog post about this. But like, man, it is like pretty difficult for us to like manage all of these different snapshots. And so if there is a way to like hill climb and yeah, do this like zero gradient like optimization via prompts, like, yeah, I’m all for it. And I think developers should be all for it because you get all these gains without having to do any of the fancy fine tuning work.
swyx [00:22:10]: Since you are part of the API team, you know, you lead the API team. And since you mentioned Thinky, I got to throw a cheeky one in there. What do you think about the Tinker API?
Sherwin [00:22:21]: yeah, it’s a good one. So it’s actually funny. When it launched, I actually DMed John Schulman. And I was like, wow, we finally launched it.
swyx [00:22:28]: Because you used to work with him.
Sherwin [00:22:29]: Yeah. Yeah. So we, it’s actually funny. So at, yeah, so right when I joined OpenAI, like this has actually been, I think, a passion project of John’s. Like he’s been talking about doing something in this. Like in this shape for a while, which is like a truly like low level research, like fine tuning library. And so we actually talked about it quite a bit when he was at OpenAI as well. It’s actually funny. I talked to one of my friends who said that when he was at Anthropic, he also, you know, worked on this idea for a bit.
swyx [00:23:01]: He’s a man on a mission.
Sherwin [00:23:03]: Yeah. I mean, John’s like so great in this regard. He’s like so purely just like interested in the impact of this because it’s, one, it’s like a really cool problem. And then two, it also empowers builders. And researchers, like you saw all the researchers who like express all this love for Tinker because it is a really great, great product. And so I’m just really happy to see that they shipped it. And I think he was really happy to kind of get it out there in the world as well. Yeah.
swyx [00:23:26]: This is probably, this is very much a digression. But like it’s weird, as someone passionate about API design, that it took this long to find a good fine tuning API abstraction, which is effectively all he wanted. He was like, guys, like I don’t want to worry about all the infra. Like I’m a researcher. I just want these four functions. And I think it’s kind of interesting. Yeah.
Sherwin [00:23:44]: Yeah.
Alessio [00:23:44]: Cool. Before the OpenAI comms team barges in the room. I know. So what feedback do you want from people like the agent builder? For example, the thing I was surprised by was the if-else blocks not being natural language and using the common expression language. I’m sure that’s something already on your roadmap. What are other things where you’re kind of like at a fork that you would love more input on?
Christina [00:24:06]: I think like one of the things that we spent a lot of time discussing was this. I think like one of the things that we spent a lot of time discussing was like whether we want kind of more of like the deterministic workflows or more LLM driven workflows. And so I think like getting feedback on that. Honestly, having people model existing workflow. A lot of what we did was kind of work with our team on, especially with engineers who are working with customers, like modeling the workflows that already exist in the agent builder and like what gaps exist, like what types of nodes are really common and how can we like add those in. I think that was that would be like the most helpful feedback to get back. And then like, you know, I think that’s kind of what we did. And then as we expand kind of from just like chat based, like right now, the initial deployment for agent builders through chat kit, we plan on kind of releasing more standalone like workflow runs as well. And kind of the types of like tasks that people would like to use in that type of API.
swyx [00:24:59]: So like more modalities, for example.
Christina [00:25:02]: Yeah, I mean, I think like for sure, like more modalities like, you know, I think kind of voice would be is already something that a lot of people have talked to us about. Even today at Dev Day. So I think modalities for sure, but also more like the logical nodes of what can’t be expressed today. Yeah.
swyx [00:25:20]: Well, you know, you’re building a language, right? You have common expression language, which I never heard of prior to this. I thought this was this Python, this is JavaScript. And then there was like a whole link in there. Was that a big decision for you guys? You know?
Christina [00:25:34]: I think that was more just kind of like a way that we thought we could kind of represent a mix of like the variables and I don’t know, like conditional statements. Yeah.
swyx [00:25:41]: The other thing I’ll also mention is that you let once you so there’s a trope in developer tooling where like anything that can be that can store state will eventually be used as a database, including DNS. So to be prepared for your state store to become a database. I don’t know if there’s like any limits on that because people will be using it.
Sherwin [00:26:01]: It’s actually funny. I’d heard this quote before and there’s definitely some truth to it. I don’t know if our stateful APIs have become a database just quite yet. But like, who knows? Like, you know.
swyx [00:26:12]: I mean, conversation. Well, you charge for it. You charge for assistance. Storage.
Sherwin [00:26:16]: Yeah. The storage. Yeah. Yeah. Right. So there’s some limit on that. But like. Yeah. But it’s very cheap. It’s like I remember we priced it like.
Christina [00:26:21]: I think if you wanted to kind of like dump all your data somewhere. I don’t know. This is like the most like transforming it all into this shape. It’s like useful. It’s easy. Best place for it. But yeah.
Sherwin [00:26:30]: But also, please don’t do this because I think it’ll put quite a bit of strain on on Benton and our input team and what we try and do. So, yeah.
Alessio [00:26:37]: How do you think about the MCP side? So you have open AI first party connectors. You have third party preferred, I guess, servers, you will call them. And then you have open ended ones. Do you see the that part of registry like functionality expanding or do you see most of it being user driven? Auth is like the biggest thing. Like if you add Gmail and Calendar and Drive, you have to like auth each of them separately. There’s not like a canonical auth. What’s the thinking there?
Christina [00:27:03]: Yeah. I mean, I think definitely for the registry. That’s why we want to make it a lot easier for like companies to kind of manage what they’re like. Developers have access to managing kind of the configurations around it. And I think in terms of like first party versus third party, like we want to support both of those. We have some direct integrations and then anyone can kind of create MCP servers. I think we want to make that a lot easier to like establish kind of private links for for companies to use those internally. So I think like just really excited about that ecosystem growing. Yeah.
Sherwin [00:27:35]: I think one of the coolest things observed, too, is just I actually think we as an industry are still trying to figure out the ideal shape of connectors. So, I mean, part of why I think the 1P connectors exist, too, like we end up storing quite a bit of state. It’s like a lot of work for us. But like by having a lot of state on our side, we call them sync connectors. We can actually end up doing a lot more creative stuff on our side when you’re chatting with ChatGPT and using these connectors to kind of boost the quality of how you’re using it. Right. Like if you have all the data there, you can do all this like re-ranking. You can like we can put in a vector store if you want to put it anywhere else. Whereas and so there’s some inherent tradeoffs here where like you put in a lot of work to get these like 1P connectors working. But because you have the data, you can do a lot more and get higher quality. But then but then the question is like, oh, my God, there’s like such a long tail of other things, which is where the MCP and like the third party connectors come in. But then you have the tradeoff of like you’re beholden to like the API shape of the MCP creator. It might actually work well, might not work well with with the models. And then what happens if it doesn’t work well? Then you kind of have to like, you know, you’re kind of like at the mercy. Of this and MCP. But by the way, it’s like really great because it already does some layer of standardization. But my senses are still going to be more evolving here. And I think, you know, we want to support both of them because we see value in both right now, especially working with working with developers. You want to have kind of like all options kind of on the table here. But it will be interesting to see how see how this evolves over time.
Alessio [00:28:54]: Yeah. When I saw about three, four months ago when you launched the forum for like signing with chat GPT interest. I think to me, that’s kind of like the vision where I log in. And I have the MCPs tied in and then I sign in with chat GPT somewhere and I can run these workflows in that app where I’m logging in. So, yeah, I think Sam, you know, said in an interview that is chat GPT is like your personal assistant. So I think this is like a great step in that direction. Yeah. I think there’s a lot more to go in that in that direction.
swyx [00:29:22]: But so far, no plan on like chat GPT or opening as IDP. Right. Which is a different role in the in the off ecosystem. Yeah.
Sherwin [00:29:31]: It’s interesting because. So direct answer is like no plans right now, of course. But I actually think we currently have some version of this, which is our partnership with Apple. Because with Apple, you can actually sign in to your chat GPT account. And some of that identity does carry with you into your iOS experience with Siri. Right. Like if you if you I don’t know if you’ve actually used this, the Siri integration. I actually use it quite a bit. But if you sign into your chat GPT account, the Siri integration will actually use your subscription status to decide. What type of model to use when it when it passes things over to chat GPT. And so if you’re, you know, just a free user, you get, you know, the free model. But if you’re a plus or pro subscriber, you get routed to GPT-5, which is I think what they.
Christina [00:30:17]: I think we also recently announced the partnership with Kakao.
Sherwin [00:30:19]: Oh, yeah. Kakao is another one. Yeah.
Christina [00:30:20]: Where I think it’s a similar thing where you can sign in with chat GPT. Kakao is one of the largest like messenger apps in Korea and kind of interact with Kakao directly there. Yeah.
Sherwin [00:30:31]: I mean, Sam’s been talking about it for a while. It’s a very compelling vision. We obviously want to be very thoughtful with how we do it.
swyx [00:30:36]: I mean, you know, now you have a social network, you have a developer platform. My you know, my chat GPT account is very, very valuable. Yeah. Yeah, exactly. OK. So and then on the other side of the office, something I was really interested to look at and I couldn’t get a straight answer. Is there some form of bring your own key for AgentKit? Like when I when I expose it to the wider world, obviously, like I mean, by default, I’m paying for all the inference. But it’d be nice for that to have a limit. And then if you want more, you can bring your own key.
Christina [00:31:07]: Yeah. I mean, we don’t have something like that yet. But I think, yeah, it’s definitely an interesting area, too. Yeah.
Sherwin [00:31:14]: It doesn’t do it out of the box today. But, you know, developers have been asking about it for forever. Like it’s a really cool concept because then as a developer, you especially any developer, you don’t need to bear the burden of inference. Yeah.
swyx [00:31:26]: I think like when you get into the business of like agent builders that are publicly exposed, where you have like an allowance. Yeah. You know, there’s a list of domains like this is this is the it rhymes with this exact pattern of like someone has to bear the cost. And sometimes you want to mess around with like the different levels of responsibility. Yeah.
Sherwin [00:31:43]: I will say in general, like if you kind of look at our roadmap, we engage a lot with developers. We kind of hear what are the pain points and we try and build things that address it. And, you know, ideally, we’re prioritizing in a way that’s that’s helpful. But, yeah, we’ve definitely heard from a good number of developers that like the cost is we’re like all of the like copy paste your key solutions. Right now, which are like huge security issues like hazards because developers don’t want to bear the burden of of inference. You know, hopefully we make the cost cheaper.
Christina [00:32:08]: So it’s the models keep getting cheaper. Yeah. Hopefully that helps.
Sherwin [00:32:12]: But but what we realize is as we make it cheaper, you know, the demand for that goes up even more and you end up still spending quite a bit. But yeah, so we definitely heard this from a lot of developers and it’s definitely something top of mind. Yeah.
Alessio [00:32:23]: Do you see this as mostly like an internal tools platform, though? Like to me, like you’ve been doing a big push on like the more forward deployed engineering thing. So it’s almost like, hey, we needed to build this for ourselves as we sell into these enterprises might as well open it up to everybody. What drives drive building these tools? Like you think of people building tools to then expose or mostly on the internal side? Yeah.
Christina [00:32:45]: I mean, it’s so like I think, again, our first deployment is ChatKit, which is kind of one of it’s intended to be for external users. But I think one of the things that we also did see a lot as we were working with customers is that a lot of companies have actually built some version of an agent builder internally. Right. To kind of manage prompts internally, to manage templates that they’re sharing across, you know, the different developers that they have, maybe the different product areas. And we were seeing that kind of like over and over again as well and really wanted to build a platform so that this is not, you know, an area that every company needs to invest in and like rebuild from scratch. But that they can kind of have a place where they can manage these templates, manage these prompts and really focus on the parts of agent building that is more unique to their business.
Sherwin [00:33:29]: It is interesting, too. Like from a deployment perspective, it is like it has spanned both internal and external use cases, right? Like kind of like these internal platforms, people will use it for like data processing or something, which is an internal use case. But if you saw some of the demos today, like there have been a huge number of companies that are trying to do this for external facing use cases as well. Customer service is one template in here. Customer service, the like ramp use case.
Christina [00:33:52]: We use this internally and externally. Like our customer support, help.openair.com is already powered on AgentKit and then various other like internal use cases.
Sherwin [00:34:00]: And one of the things that I actually think the team has done a really great job of, so like Tyler, David and Jiwon on the team, they built the, especially the ChatKit components, they built it to be like very consumer grade and like very polished. Like you kind of look at that, there is like a whole grid of like the different widgets and things that you could create there. Like ideally people see it and they see it as like these very polished like consumer grade ready external facing things versus like, you know, you think of internal tools and like the UI is always like the last thing that people care about. Yeah. So like you really, you know, push the team. And I think they did a really great job of making the ChatKit experience like really, really consumer grade. And it should feel almost like ChatGPT and with like really buttery smooth animations and like really responsive designs and all of that. Yeah.
Christina [00:34:43]: I think your point on widgets is like definitely like really resonates, right? Because ChatKit, it handles the chat UX, but we’re also just building like really visual ways for you to represent like every action that you want to take. And that is definitely like very high polished.
Sherwin [00:34:59]: Yeah. And when working with customers, like those have been the most helpful customers for us to work with because, you know, when Ramp is thinking about, you know, how, what they want to publicly present to people, like they have a pretty high bar as they should, as well as, you know, all the other customers that have been iterating on it. And so that kind of feedback from our customers has really helped us up level the general product quality of the launch that we had today as well.
swyx [00:35:19]: Yeah. Would you ever, would you open source ChatKit?
Sherwin [00:35:25]: Talked about it. We’ve talked about it. There are a bunch of trade offs. Yeah.
Christina [00:35:30]: I think so. So ChatKit itself is like an embeddable iframe. And so I think the actual. Oh, it’s an iframe. Yeah. And so that helps us keep it like evergreen. Right. So if you are using ChatKit and we come up with new, I don’t know, a new model that reasons in a different way, right, or a kind of new modalities that you don’t actually need to rebuild and like pull in new components to use it in the front end. I think there’s parts of, you know, widgets, for example, that is much more like a language and can definitely is something that is easier to explore that for, as well as kind of the design system that we’ve built for ChatKit. But I think like as part of, yeah, the actual iframe itself, I think there’s a lot of value in that being, yeah, more evergreen. Yeah. More evergreen experience that is pretty opinionated.
swyx [00:36:13]: Like there’d be no point in being open source. Right. Yeah. You want the.
Christina [00:36:16]: Then you don’t get the benefits of it.
swyx [00:36:18]: You know, being Stripe alums, like Stripe Checkout, like it’s, it’s all optimized for you to like.
Christina [00:36:23]: So I’m not a Stripe alum, but Kristina is. Right. And the team actually is the team that built.
Sherwin [00:36:28]: Stripe Checkout.
Christina [00:36:29]: Yeah. So it’s very similar philosophically. Right. So Stripe, you know, can build elements and checkout and not every business needs to rebuild, right, the pieces that are really common. And I think we see the same with chat. We see chat being built over and over again. Especially when you’re building a website. Especially as we kind of come up with new, you know, modalities, like reasoning, everything. It’s not really something that is easy to keep up to date. And so we should just do that and leave kind of the hard parts of building agents again to.
Alessio [00:37:02]: Yeah. To the developers. Does it feel, I mean, I know WordPress is like a bad connotation in a lot of circles, but to me it almost feels like the WordPress equivalent of like chat is like, hey, this is like drop in thing. And then you have all these different widgets. Do you see the widget becoming a big kind of like developer ecosystem where people share a widget? Is that kind of like a first party thing? And then what’s like the M4 versus widget forest? No, exactly. I mean, it’s kind of like it seems great for people that are like in between being technical and like not really being technical enough. Yeah. Yeah.
Christina [00:37:35]: Yeah. I mean, I think that’s a big part of building widgets, right? Like it’s already kind of in the language that is very consumer friendly. You can use in our widget builder already. You can kind of use AI to create those widgets and they look pretty good. I don’t know if you guys have gotten a chance to try that out yet, but definitely see kind of, I don’t know, a forest.
Sherwin [00:37:53]: If you haven’t tried out the widget studio and the demo like apps as well. Yeah.
swyx [00:37:59]: You got a custom domain like widget.studio. It’s cool.
Sherwin [00:38:02]: I actually don’t know how we got that. Yeah.
Christina [00:38:04]: Everything’s in chatkit.studio. And then we have like the playground there so you can try out what chatkit would look like with all the customizations. We have chatkit.world, which is a fun site we built. I was like spinning the globe for a while this morning. It was like a fidget spinner.
swyx [00:38:18]: I think Kasia also like uploaded some of her solar system stuff and all the demos as well. Yeah.
Christina [00:38:24]: And then that’s where like the widget builder. Yeah.
swyx [00:38:26]: So it’s really come together. It’s taken like almost more than a year to like come together and like build all this stuff, but it’s coming together. It’s like really interesting.
Sherwin [00:38:34]: Yeah. Yeah. It’s something that we like- You definitely planned all of this upfront. Oh yeah. Yeah. We have the master plan from three years ago. No. But like I think, especially on this stuff, I think there was like an arc of a general like, you know, platform that we did want to kind of build around. And it takes a while to build these things. Obviously, Codex helps speed it up quite a bit now. But yeah, I will say it does seem great to kind of like start to have all the pieces start fitting together. Yeah. I mean, you saw we launched evals and we had the fine tuning API for a while and we laid all the groundwork for some of the stuff over the last year. And we’re hoping that we can eventually, you know, make it into this full feature platform that’s helpful for people.
swyx [00:39:11]: I think you have. Since you did the Codex mention, maybe a quick tip from each of you on Codex power user tools or tips.
Sherwin [00:39:23]: So there’s actually a funny one that one of the new grads has, I think, like taught our team in general. And I think this is like a point for like just how like new grads and younger, you know, generation people are actually more AI native. So one of them is to like really lean into like- Yeah. Like push yourself to like trust the model to do more and more. So like I feel like the way that I was using Codex. And so for me, it’s usually for my personal projects. They don’t let me touch the code anymore. But you give it like small tasks. So you’re like not really trusting it. Like I view it as like this like intern that like I really don’t trust. But what a lot of the like, so we had an intern class this year. What a lot of the interns would do is just like full YOLO mode, like trust it to like write the whole feature. And it like it doesn’t work. It doesn’t work for worse. It like doesn’t work sometimes. But like, I don’t know, like 30, 40% of the time, it’s just like one-shots it. I actually haven’t tried this with like Codex, GBD-5 Codex. I bet it probably like one-shots it even more. But one tip that I’m like starting to like, I feel like undo this, like relearn things here is to like really lean into like the AGI component of it and just like really let the model rip and like kind of trust it. Because a lot of times they can actually do stuff that surprises me. And then I have to like readjust my priors. Whereas before I feel like I was in this like safe space of like I’m just treating this, I’m giving this thing like a tiny bit of rope. Yeah. And because of that, I was kind of limiting myself with how effective I could be.
swyx [00:40:44]: Like, sure, but okay. But also, is there an etiquette around submitting effectively, you know, vibe-coded PRs that someone else now has to review, right? And it’s like, it can be offensive.
Sherwin [00:40:55]: Well, we have Codex who reviews now.
swyx [00:40:56]: Okay. It actually reviews itself. Does Codex approve its own PRs a lot more than humans? It doesn’t get approved then.
Christina [00:41:02]: I was going to say, I think like the Codex PR reviews are actually one of like the things that my team like very much relies on. I think they’re very, very high quality reviews. Yeah. On the Codex PR side, like for the visual agents builder, we only started that probably less than two months ago. And that wouldn’t be possible without Codex. So I think there’s definitely a lot of use of Codex internally and it keeps getting better and better. And so, yeah, I think people are just finding they can rely on it more and more. And it’s not, you know, totally vibe-coded. It’s still, you know, checked and edited, but definitely has a kicking off point. And I think I’ve heard of people on my team, it’s like on their way to work, they’re like kicking off like five Codex tasks because the bus takes 30 minutes, right? And you get to the office and it kind of helps you orient yourself for the day. You’re like, okay, now I know the files. I have the rough sense. Like maybe I don’t even take that PR and I actually just like still code it. But it helps you just context switch so much faster too and be able to like orient yourself in a code base.
Sherwin [00:42:01]: There are so many meetings nowadays where I have like one-on-ones with engineers and I walk into the room, they’re like, wait, wait, wait, give me a second. I got to kick off my like Codex thing. I’m like, oh, sorry. We’re about to enter async zone.
Christina [00:42:10]: It’s almost like your notes, right? You’re like, let me.
Sherwin [00:42:12]: And they’re like typing like, okay, now we can start our one-on-one because now it’s great. Yeah.
swyx [00:42:16]: Cool. We’re almost out of time. I wanted to leave a little bit of time for you to shout out the Service Health Dashboard because I know you’re passionate about it. Well, tell people what it is and why it matters. Yeah.
Sherwin [00:42:27]: So this is a launch that we actually didn’t, you know, it didn’t get any stage time today, but it’s actually something I’m really excited about. So we launched this thing called the Service Health Dashboard. You can now go into your usage or like your settings account and kind of see the health of your integration with our OpenAI API. And so this is scoped to your own org. So basically if you have an integration that’s running with us doing a bunch of, you know, tokens per minute or a bunch of queries, it’s now tracking each of those responses, looking at your token velocity, TPM that you’re getting, the throughput, as well as the responses, the response codes. And so you can see kind of like a real-time personal SLO for your integration. The reason why I care a lot about this is obviously over the last year, we’ve spent a lot of time thinking about reliability. We had that really bad outage last December, you know, longest, like three, four hours of my life, and then had to, you know, talk to a bunch of customers. We haven’t had one that bad since, you know, knock on wood. We’ve done a bunch of work. We have an Infer team led by Venkat, and they’ve been working with Jana on our team, and they’ve just been doing so much good work to get reliability better. And so we actually... Yeah. Again, knock on wood. We think we’ve got reliability in a spot where we’re, like, comfortable kind of putting this out there and kind of, like, letting people actually see their SLO. And hopefully, you know, it’s, you know, three, four, soon to be five nines. But the reason why I cared a lot about it is because we spent so much time on it, and we feel confident enough to kind of have it behind a product now. Five nines is like two minutes of outage or something. Yeah, yeah. We’re working to get to five nines. What? What does an extra nine take?
Sherwin [00:44:08]: It’s exponentially more work. So, you know, and then... But, like, we always... We were, you know, in the last couple weeks, we were talking about, like, hitting three nines and then hitting three and a half nines and then hitting four nines. But, yeah, it’s exponentially more work. I could go for a while on the different topics, but...
swyx [00:44:25]: We’ll have to do that in a follow-up. I mean, that’s all... That’s the engineering side, right? Yes, yes, yes. Like, you’re serving six billion tokens per minute.
Sherwin [00:44:32]: We actually zoomed past that. Yeah, that’s the... That’s outdated. Yeah. But, yeah, it’s been crazy, though, the growth that we’ve seen.
Alessio [00:44:39]: Awesome. I know we’re out of time. It’s been a long day for both of you, so we’ll let you go, but thank you both for joining us.