

Factory.ai: The A-SWE Droid Army
The cofounders of Sequoia-backed Factory.ai stop by the studio to dive into the story behind one of the most successful enterprise code agent platforms. Try not to make the Star Wars joke...
Eno’s talk was standing room only in AIEWF 2024 and will be returning for the sequel at AIE 2025 on the SWE Agent track in 5 days. and at the first ever official AIE Hackathon in 2 days. Join both! and FILL OUT THE DANG SURVEY STOP LURKING.
There’s a lot of confusion remaining around A-SWE still even after our Codex episode. After leaving a while to sit, it has begun to grow on us - and it’s very convenient that the “A” stands for multiple related things:
At OpenAI it means “Autonomous” (or Agentic) - meaning fire and forget (at 60 tasks an hour), optimizing for zero-shotting tasks, no human supervision
With Factory’s GA launch the simpler “Async” is the common term - more appealing to engineers, non-blocking but allowing human collaboration
Harrison from LangChain is promoting “Ambient” agents - always-on, passive, proactive, with cron/stateful orchestration/human-in-the-loop “interrupts”
All different in nuanced ways, but A-SWE agents are now likely to be the next frontier in the code generation battle even as both Cursor and Windsurf, formerly “inner loop” synchronous agents, both launch “background” or “simultaneous” versions.
Factory has been in the A-SWE game from their beginning, and has had particular success in the enterprise, with star customers like the CEO of MongoDB singing their praises and top tier VCs from Sequoia, Lux Capital and others.
This is their story.
SWE-Bench Retired
Factory first got on our radar last year with their top tier SWE-Bench results:

but they now no longer even run the benchmark for an increasingly common litany of reasons we are hearing: it’s python-only and doesn’t match tasks in the real world.
Newer benchmarks like PutnamBench and Commit0, or SWELancer or MLEBench or PaperBench might be preferred but it is unclear if we will ever have a coding benchmark with the universal recognition that HumanEval or now SWEBench had.
These are the droids that you are looking for
Unlike products marketing themselves as “your AI teammate”, the Factory platform is built by “droids” that you can spin up. These are basically different agent personas: you can have a coding droid, a knowledge retrieval droid, a reliability droid, etc.
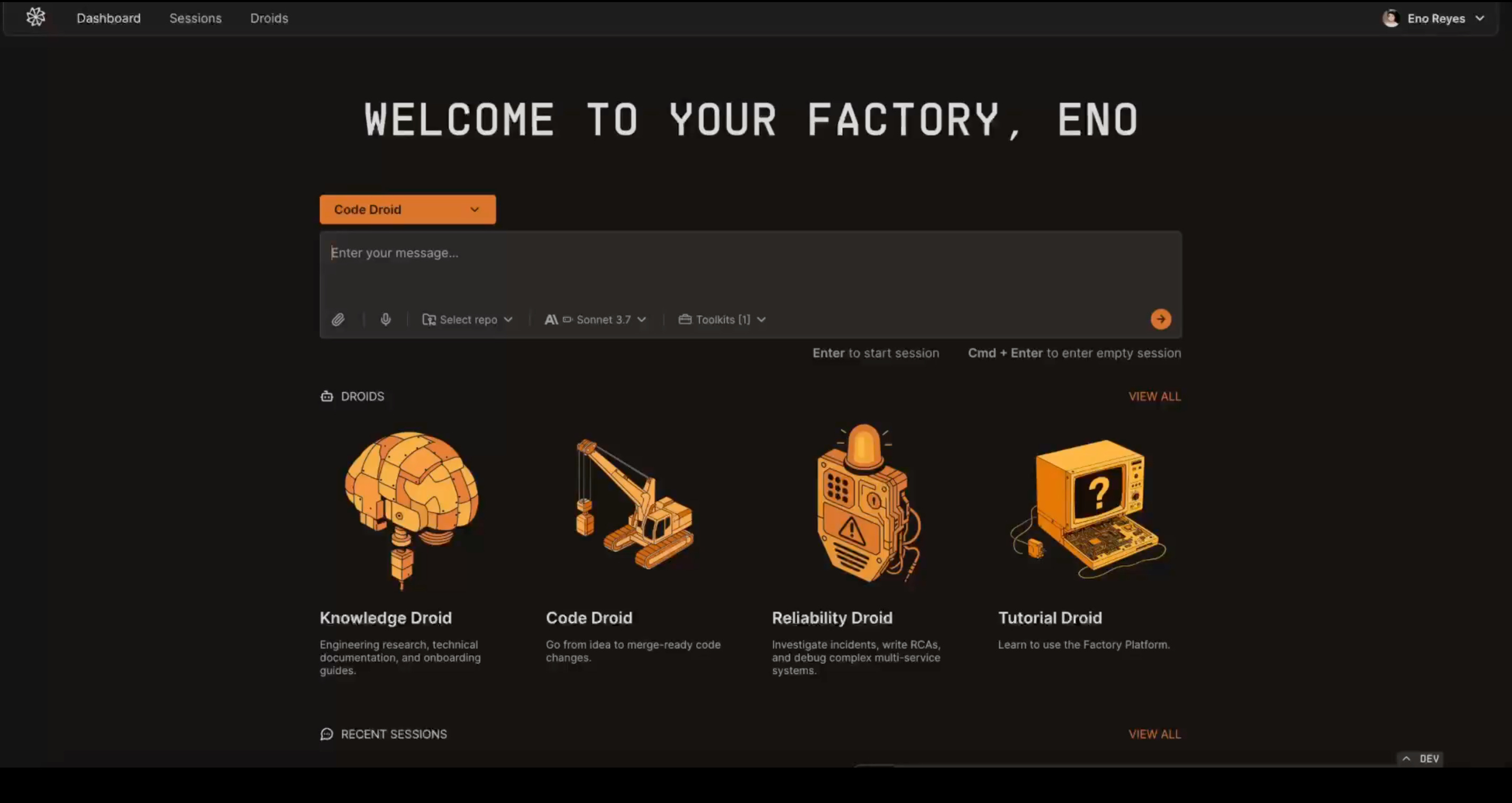
The main difference with all the other products in this space is that it supports both local and remote execution. If you want to try out the product, you have to spend 0 time setting up a remote environment (unlike Codex, Devin, etc) and can just use the Factory Bridge to allow the droid to run things in your local dev environment (please use Docker before you do this!). You can start a task locally and be very involved, and then hand it off to a remote droid and move on to the next thing rather than having the IDE as a bottleneck for execution.
Show Notes
Timestamps
[00:00:04] Introductions
[00:00:35] Meeting at Langchain Hackathon
[00:04:02] Building Factory despite early model limitations
[00:06:56] What is Factory AI?
[00:08:55] Delegation vs Collaboration in AI Development Tools
[00:10:06] Naming Origins of 'Factory' and 'Droids'
[00:12:17] Defining Droids: Agent vs Workflow
[00:14:34] Live Demo
[00:17:37] Enterprise Context and Tool Integration in Droids
[00:20:26] Prompting, Clarification, and Agent Communication
[00:22:28] Project Understanding and Proactive Context Gathering
[00:24:10] Why SWE-Bench Is Dead
[00:28:47] Model Fine-tuning and Generalization Challenges
[00:31:07] Why Factory is Browser-Based, Not IDE-Based
[00:33:51] Test-Driven Development and Agent Verification
[00:36:17] Retrieval vs Large Context Windows for Cost Efficiency
[00:36:21] Pricing model
[00:38:02] Enterprise Metrics: Code Churn and ROI
[00:40:48] Executing Large Refactors and Migrations with Droids
[00:45:25] Model Speed, Parallelism, and Delegation Bottlenecks
[00:50:11] Observability Challenges and Semantic Telemetry
[00:53:44] Hiring
[00:55:19] Factory's design and branding approach
[00:58:34] Closing Thoughts and Future of AI-Native Development
Transcript
Introductions
Alessio [00:00:04]: Hey everyone, welcome to the Latent Space podcast. This is Alessio, partner and CTO at Decibel, and I'm joined by my co-host Swyx, founder of Smol AI.
Swyx [00:00:11]: Hey, and today we're very blessed to have both founders of Factory AI. Welcome, Matan and Eno. My favorite story about the founding of Factory is that you met at the Langchain Hackathon. And I'm very annoyed because I was at that hackathon and I didn't start a company. I didn't meet my co-founder. You know, maybe when you want to quickly sort of retell that little anecdote, because I think it's always very fun.
Meeting at Langchain Hackathon
Matan [00:00:35]: Yeah, yeah. Both Eno and myself went to Princeton for undergrad. And what's really funny is retrospectively, we had like 150 mutual friends, but somehow never had a one-on-one conversation. If you pulled us aside and asked us about the other, we probably knew like vaguely like what they did, what they were up to, but never had a one-on-one conversation. And then at this Langchain Hackathon, you know, we're walking around and catch a glimpse of each other out of the corner of our eye, you know, go up, have a conversation. And very quickly just gets into code generation. And this was like back in 2023 when code generation was all about baby AGI and auto GPT. Like that was like the big focus point there. And both were speaking about it. Both were very obsessed with it. And I like to say it was intellectual love at first sight because basically every day since then, we've been obsessively talking to each other about AI for software development.
Swyx [00:01:25]: If I recall that Langchain Hackathon wasn't about code generation, how do you sort of get... Find the idea, maze to factory.
Eno [00:01:34]: Yeah. Basically, I think that we both came at it from slightly different angles. I was at Hugging Face working primarily on advising like CTOs and AI leaders at Hugging Face's customers, guiding them towards how to think about research strategy, how to think about what models might pop up. And in particular, we had a lot of people asking about code and code models in the context of we all want to build like a fine-tuned version on our code base. So in parallel, I had started to explore building. At the time, the concept of agent wasn't really like clearly fleshed out, but imagine basically a while loop that wrote Python code and executed on it for a different domain for finance. On my mind was how not very helpful it felt for finance and how incredibly interesting it felt for software. And then when I met Matan, I believe that he was exploring as well.
Matan [00:02:28]: Yeah, that's right. So I was at the time, I was still doing a PhD at Berkeley, technically in theoretical physics. Although for a year at that point, I had really switched over into AI research. And I think the thing that pulled me away from string theory, which I'd been doing for like 10 years into AI was really the string theory and physics and mathematics really makes you appreciate fundamentalness or things that are very general. And the fact that capability in code is really core to performance on any LLS LLM. And like loosely, the better any LLM is at code, the better it is at any downstream task, even that's like writing poetry. And I think that fundamental beauty of like how code is just core to the way that machines, you know, develop intelligence, really kind of nerd sniped me and got me to leave what I was, you know, pursuing for 10 years. And that, you know, mixed also with the fact that code is one of the very few things, especially at the time that you could actually validate. And so you could have that agentic loop where the LLM is just like, oh, I'm going to do this and then you're actually, you know, verifying in ground truth, the quality of that output. It just made it extremely exciting to pursue.
Alessio [00:03:37]: How did you guys decide that it was time to do it? Because I think maybe if you go back, the technology is like, it's cool at a hackathon, but then as you start to build a company, it's maybe like, there's a lot of limitations. How did you maybe face out the start of the company of like, okay, the models are not great today. So let's maybe build a harness around it to then now the models are getting a lot better. So it's time to like go GA as you're doing now.
Building Factory despite early model limitations
Matan [00:04:02]: And all of that, there's kind of a more quantitative answer and then a more qualitative answer. So the qualitative answer kind of building off of what I said before of, you know, it was intellectual love at first sight. I think it was also one of those things that was kind of just like, if you know, you know, we met and we got along so well. And basically like the next 72 hours, we didn't sleep. We were just like building together on initial versions of what would become factory. And when something like that happens, I think it's good to just like lean in and not really question it and overanalyze. Yet at the same time, if you do actually go and analyze, I think there are exactly, you know, the considerations that you're talking about, which is, yeah, the models at the time, which I think at the time, it was just 3.5, which was out. Certainly that's not enough to have a fully autonomous engineering agent. But very clearly, if you build that harness or you build that scaffolding around it and bring in the relevant integrations or the sources of information that a human engineer would have, it's very clear how that trajectory would get to the point where more and more of the tasks that a developer would do actually come under that.
Eno [00:05:02]: Yeah. And I think that at the time, as you mentioned, there was like baby AGI and a couple of these other concepts that had come out, which involved putting a while loop around the LLM, feeding back some context. And on the other hand, there were papers coming out, the chain of thought, self-reflection. Of course, the scaling law papers at this point had been somewhat established. And so there was kind of this clear direction where models were going to get better at reasoning. They were going to get better at having larger context windows. They were going to get cheaper at, or at least the Pareto frontier of the model capabilities was going to be expanding so that good models would get cheap. The best models might stay the same price, but they started to get really smart. And this was, I wouldn't say super obvious, but if you spent a lot of time just reading through these papers and working through, there was definitely a rumbling amongst most of the people in the community that that was going to continue to extend. And so you blend all of these together. And with kind of meeting somebody who has this kind of energy that clearly they want to build. And I think that it became really obvious that the opportunity was available. I also think that we made a lot of very solid progress on the initial demo enough to convince ourselves this was actually going to be possible. To be clear though, it was eight days from us first meeting to me dropping out of my PhD and Eno quitting his job. So there was analysis, but it was also just like, yeah, let's do it. Yeah. Pretty, pretty crazy. Like eight days. For sure. Yeah.
Alessio [00:06:32]: My first company was a hackathon project and I dropped out of school to actually found the company with one of my best friends. So the story resonates.
Swyx [00:06:39]: I think I'm doing hackathons wrong. Maybe. Like I've had, I met one girlfriend out of it. No, that was about it. Hey, that's a, you know, some people might say that's how you are. Is it still ongoing? No. I mean, it's a part of the funnel. Yeah.
What is Factory AI?
Alessio [00:06:56]: So, yeah, maybe CodeGen was not the topic of the hackathon back then, but I would say today. I mean, there's a lot of the stuff that I've talked about in the past that I want to talk about. There's the CodeGen Router event that I go to. CodeGen is part of it. There's a lot of CodeGen products. Do you guys want to just talk about what Factory is and maybe just give a quick comparison on the different products that people might have heard about and that we can kind of dive deeper?
Matan [00:07:14]: Our focus is on building autonomous systems for the full end-to-end software development lifecycle and in particular for enterprises. I think especially given the, like, so, OK, obviously code generation is very exciting. A lot of, you know, the best engineers coming out of any of the, you know, the popular systems. It's like they want to work on like RL. They want to do cool things with like GPUs, you know, training models. Code is one of the like most obvious things because it's very easy to resonate with if you're an engineer. And so that's led to a lot of the players in the space really focusing on coding in particular and on like solo developers or building a quick like zero to one project and really like that use case that appeals to that profile. And I think something that we're focused on is the relatively underserved enterprise perspective, which is there are hundreds of thousands of developers who work on code bases that are 30 plus years old. It's really ugly. It's really hairy. It's really messy. And if you made a demo video like doing some like COBOL migration, that's not very sexy. You wouldn't go viral. You wouldn't get a lot of views because it's like it's just not that visually appealing, but the value that you can provide and how much you can improve those developers lives. It's very, very dramatic. And so seeing that underserved group is kind of why we've focused our sights there.
Delegation vs Collaboration in AI Development Tools
Eno [00:08:55]: I think this is a tool that was designed 20 plus years ago or has been iterated on for 20 plus years, primarily for a human being to write every line of code. When you take a tool like that and you start to introduce AI, you start to introduce additional constraints that exist just out of the nature of where you're interacting with these systems and where those systems live. So, for example, latency matters a lot when you're inside of an IDE. The cost when you are local first and your typical constraints. Consumer is on a free plan or a like $20 a month paid plan limits the amount of high quality inference you can do and the scale or volume of inference you can do per like outcome. When you are freed of a lot of these constraints, you can start to more fundamentally reimagine what a platform needs to look like in order to shift from a very collaborative workflow, which is what I think we see with most tools today, and a more delegative workflow where you are actually managing and delegating your tasks to AI systems. So, I think that the product experience of delegation is really, really immature right now. And most enterprises, though, see that as the holy grail, not like going 15% or 20% faster.
Naming Origins of 'Factory' and 'Droids'
Swyx [00:10:06]: And you call them droids? We call them droids. Is there just a story behind the naming of either factory or droids?
Matan [00:10:13]: Yeah. So, we were initially incorporated as the San Francisco Droid Company. Really? We were. Is this before you have to bleep that out in the live podcast?
Swyx [00:10:23]: Sorry?
Matan [00:10:24]: Oh, you had to bleep that out? No, no, no, no. Okay. But our legal team advised us that Lucasfilm is particularly litigious and that we should change our name. And at the time, so, at the time while we were thinking of renaming, I was still in my PhD because we incorporated like two days after we met, which was also ridiculous. But we think of renaming and I was still in some ML class at Berkeley and I was reading a paper on actor critic. In there, there was some equation that was like, you know, some function of the actor. We're just calling that Y. And so, it was like F of A equals Y. A is actor. Put the actor in there and then it's, you know, factory. Yeah. And so, that's how it originally came about. It actually works quite well also, you know, automation, that sort of thing. But, yeah. Yeah. Yeah.
Eno [00:11:09]: And also the factory method, I think, was at some point we had that written up. And then I think that inspired this line of thinking. And droids kind of remained because we felt that there was a lot of hype at the time. Around the concept of agent. But it referred to such a specific thing that everybody saw, which was this like endless while loop unreliable system that just kind of went on and on and took a bunch of actions without guidance. Yeah. And our thought process was, well, that's not really what our system looks like at all. So, even though underneath it is an agentic system, do we need to say that we're an agent company? Doesn't really make sense.
Swyx [00:11:48]: I kind of like that. Like, yeah. Actually, last year, we pushed. Even though I put you guys. You spoke last year at the World's Fair. I put you on the agent's track, but I almost didn't have an agent's track because I was like, this is so well ill-defined. And I think that instinct is good. But now the agent's wave has kind of come back the other way. And now everyone's an agent. I think like defining your own term for it and just getting out of that debate, I think, is a positive. Would you like, is it closer to a workflow, which is like, I guess, the more commonly industry accepted term now? Yeah.
Defining Droids: Agent vs Workflow
Eno [00:12:17]: No, that's a great question. I think that the original version of the droids were a lot closer to what we called workflow. So they were asynchronous and like event based, they would trigger and each one had a specific kind of deterministic, like semi deterministic. That was the original version. I think what we've grown to as the models have evolved and as our ability to build out guardrails and the system has just improved, we've gotten to the point where when you interact with droids inside the factory platform, they are relatively unbounded in the path that they take. And they're in general guided mainly by the system. And they're in general guided mainly by the concept of planning, decision making and environmental grounding. So they can stay loosely goal oriented over a long duration without needing very hard coded guardrails, but they still tend to hit their goal according to their original plan. So I think now agent actually is probably like the proper way to describe them. Sure. Yeah.
Swyx [00:13:13]: But you know, I think, I think droids have a nice ring to it.
Matan [00:13:15]: It's also funny. Our customers really, really love droids as a name. These are the droids you're looking for. I cannot tell. I cannot tell you how many times, like if, you know, with an enterprise customer, we'll do a POC and like, you know, a day later, you know, they're excited and like things go well. They'll share a screenshot and be like, these are the droids we're looking for.
Swyx [00:13:34]: And honestly, every time it's just, it's so fun. I know. And everyone thinks they're the first to make that joke. But it really is better than like agents or intern or like, you know, autonomous software. The number of human name AI products. Yeah. It's actually a pretty good insight.
Eno [00:13:50]: A hundred percent. And actually, I think we, we, to a certain extent, we're not going to be able to do that. To a certain extent, take a bit of an objection to the idea that these things are a replacement for a human being. I think that very much as we work through harder and harder problems with agents, it's become more clear that the outer loop of software development and what a software developer does, planning, talking with other human beings, interacting around what needs to get done is something that's going to continue to be very human driven. While the inner loop, the actual execution of writing lines of code or writing down the doc is probably. It's probably going to get fully delegated to agents very soon.
Alessio [00:14:25]: You just need to put Roger, Roger.
Eno [00:14:27]: Once they ask a question, when it finishes the task, we have that emoji in our Slack and use it very frequently.
Live Demo
Alessio [00:14:34]: Roger, Roger, do we want to do a quick demo?
Eno [00:14:37]: Yeah. Happy to jump in. When you land on the platform, you're presented with the opening dashboard. We try to make it really obvious that there are different droids available for key use cases that people tend to have. Of course you can always go and speak. With a default droid that can do a lot of things pretty well. But what we've learned is that there's three major use cases that people keep coming back to the platform for. The first is knowledge and technical writing. So that's going in and more of like a deep research style system that will go and do some research. It will use tools available to it, search, et cetera, and come back with either a high quality document or answers, and then you can back and forth. The code droid is really the one that's the daily driver for a lot of things. And this system allows you to actually delegate a task. I'll jump into that in a second. We can actually go through a full walkthrough and then the reliability droid. This was pretty surprising to us. The degree to which people love doing incident response, the kind of like SRE style work inside of the platform, I guess, in retrospect, it's nice because no one loves to be on call at 3am waking up being like what's happening and being able to just pass an incident description or say, Hey, something's going wrong and have a system really that can do that. It's really nice to be able to really compile all the evidence, write up an RCA, provide that for you is super high leverage. And so that's actually one of the more popular droids that people use, but I can start by just going into the code droid. And when you start a session with a droid, you're presented with this interface. It's a little different from typical where we see a lot of tools really want to focus you in on the code. Our perspective is that code is important to review when it's completed, but as the agent is working. What? What matters most is seeing what the agent is doing and having a bit of like an X-ray into its brain. So we have an activity log on the left and a context panel on the right. So you'll notice as we go through this task, that context panel starts to get updated. And I'm going to start by just doing something that's pretty common entry point. I'm going to paste a ticket into our platform. We have integrations with a bunch of different stuff, linear, JIRA, Slack, GitHub, Century, PagerDuty, you name it. We have a bunch of these integrations that are enterprise clients. We have a bunch of these integrations that our clients have wanted over time, such that you can easily pull this info in. And if I were to say something like, hey, can you help me with this ticket? And then I'm going to use my at command, which lets me easily reference code or code bases. Hey, can you help me with this ticket in factory mono? I like to be nice to them. I'd love for your help. And so you'll note that right off the bat, the droid starts working. It's doing a semantic search on part of my query in that code base. And actually, the system has access to a bunch of different tools. Here, memory, project management tools, GitHub, web search. Right now, the code droid only has search enabled by default. But you'll note that as the system starts working, it may actually want those additional tools added so that it can they can do its job.
Enterprise Context and Tool Integration in Droids
Matan [00:17:37]: Maybe an important note there is, you know, as we deploy these droids in the enterprise, I think something that we're pretty like ideological about is everyone expects these, you know, agentic systems to perform at the level of a human right, because that's what they're always going to compare them to. But in a lot of cases, they'll have these agents just in the IDE. And that's like the equivalent of onboarding a human engineer, just like throwing them into your code base and being like, all right, like, go. But like, the reality is when you onboard a human engineer, what do you actually onboard them to? Slack, Notion, Linear, like Datadog, Sentry, PageReduce. They have all of these other information sources that they need to actually be a productive engineer. And yes, in theory, if you're like, really, really good, and you don't need contextual information, you could just work based on code. But like, that would be a lot harder. And it would probably be a lot harder. It would probably take a lot more time.
Eno [00:18:24]: 100%. And having those connections ends up being super important as it works through harder problems. Like in particular, you can see that the first thing it did after that search was reference some of the information that it found in saying, hey, this is what I found so far. It gives an initial crack at a plan, right? Presents that really clearly to you, and then goes to ask clarifying questions. So a lot of users, we believe, should not need to prompt engineer agents, right? If your time is being spent hyper-optimizing every line and question that you pass to one of these systems, you're going to have a bad time. And so a lot of what we do is to be able to format, if I say, help me with this ticket, right, there's clearly going to be some ambiguities. The system knows when you give a very detailed answer or request to follow your instructions, when you give more ambiguous requests to ask for clarification. This is actually a really tricky thing to get right in the model, but we spend a lot of time thinking about it. And so I'm just going to answer some of these questions. Are there any UI mock-ups? No. Try to imitate the other examples. Two, only preview when the button is clicked. Three, no, it's actually not implemented. Four, which specific fields must be displayed? Your choice. And five, your choice. So now I'm basically saying to it, you decide for some, giving my preferences on others.
Matan [00:19:52]: And this is really... This is really the balance of like, even, you know, delegation that will happen to non-AI is like, you know, as a good manager, you give autonomy to people that work with you when needed. But also if you're like, hey, I'm a little worried about this, or I'm going to be really strict about what I expect here, you want to extract that behavior as well. Because a lot of times, like Eno mentioned, if you give a really poor prompt and you just say, hey, go do it, it's going to go do it, but it'll probably make assumptions. And then at the end, you might not be happy, but that's just because there were some constraints in your head that you didn't actually explicitly make. So I think it's really important that you mention when you're communicating. So, yep, 100%.
Prompting, Clarification, and Agent Communication
Alessio [00:20:26]: Do you guys have like a template that you've seen work? When I'm boarded to Devon, for example, they have the fix prompt button, and then it refills it in their template, which is like, give the agent instruction on how to debug, give agent instruction on how to do this, and ask you to fill out these things. Do you guys have a similar thing where like you think for each project, these are like the questions that matter? Or is that more dynamic?
Eno [00:20:51]: No, that's a great question. And it's something that... We talk about a lot internally is it's surprising how many people are building products that have reactive like information requests, like, you know, please fill out this form to explain how to do this thing, or you need to set up this dev environment yourself manually in order for this to work. We think of trying to be proactive with a lot of this stuff. So you'll notice in the right hand corner, there's this project overview, right? And the system started to code after doing some search. So that's going to pop up while we do this. But when I click into this project overview, what you're going to see is basically a, and I'm hiding it because I'm realizing this is actually semi-sensitive. It's probably fine. We can hide that in the video. Yeah, no worries. It's totally fine for folks to see that it's a monorepo. If I scroll down, that's when we'd get in a little bit of trouble. But inside that project overview, we're actually synthesizing a bunch of what we call synthetic insights on top of the code base. And that is looking at things like how to set up your dev. What is the structure of the code base? How do important modules connect to each other? And as we index code bases, we're actually generating these insights at a much more granular level across the entire code base. We think that in general, systems should be proactive in finding that information. However, with features like memory, and we have like a .droid.yaml, you can set a bit of your guidelines. However, we also feel that it's like that XKCD about standards. A new standard. Right. Like everyone's got like a. .blank rules file. And so we ingest those automatically from all of the popular providers as well. Wow.
Project Understanding and Proactive Context Gathering
Alessio [00:22:28]: Okay. Does something like a cursor rules is complimentary because people might take this and then work on it in cursor separately? Yeah.
Eno [00:22:36]: What we found is that there are sometimes extraneous advice in those because people need to give a lot more guidance to those types of tools than they do to ours. So our system parses through and only picks the things that we don't already know.
Matan [00:22:51]: Another thing. That kind of comes to mind related to your question, and this is something we've been thinking about a lot as well, is as we have more and more enterprise customers and a lot of the developers in the enterprise are not going to be as up to date on every new model and how it changes its behavior. Something that's interesting that we're thinking about is these developers are getting familiar with factory and how to get the most out of it. And then we let's say when we upgraded from Sonnet 3.5 to 3.7, we suddenly had a lot of developers being like, hey, wait, it now does this less or does this more. What's happening? Or when they go to Gemini, let's say, and they want longer context. And so something that I think is interesting is how much of the behavior difference from the models should we act as like a shock absorber for so that they can basically, as a user, use it exactly how they've been using it before and get the same sort of output. But then also how much of that do we actually want to translate to the user? Because presumably over the next three years, the way you interact with models will change and it's not just going to be up to behavior, but it's rather like, I guess it's alpha versus. Like beta in the model. Like there's some models have like different personalities and it's just the way you prompted to get the same out of it. And then there are others where it's like, I mean, for example, like the reasoning models, they just work in a fundamentally different way. And so you as the user should know how to interact differently. So that's something that's kind of fun to wrestle with.
Why SWE-Bench Is Dead
Eno [00:24:10]: How do you evaluate the new models? We listened a lot to how the model providers actually think about building out their eval suites and in particular trying to look at things like desired behavior versus actual. And in a way that's sustainable for a small team, we don't have like, you know, a hundred million dollars to pay data providers. And so a lot of the evaluation ends up being a combination of point like task based evals. So like the AIDER has an awesome benchmark that we built on top of internally for code editing and file generation versus we also for the top level agent loop have like our own behavioral spec where we set a bunch of high level principles. We break those down into tasks, those tasks then have grades and rubrics, and then we try to run those in order to determine is the behavior suite that we like, for example, asking questions when it's ambiguous versus not asking questions, does that match up? And we also use that to optimize the prompts as well.
Swyx [00:25:09]: Just a quick question on these types of things. I think every company should have their own internal evals, right? That is not in question. And obviously that is your IP, so we can't know too much about it. But like, what is the right amount to do? What is the right amount to spend on something like this? Yeah. Because let's say we talk about SweetBench before recording, SweetBench costs like 8,000 to run. I've heard varying numbers between 8 to 15,000 to run. Yeah. That's high, but you should be able to spend some amount to ensure that your system as a whole works and doesn't regress.
Matan [00:25:38]: So like, what's a rule of thumb for like, what is the right amount to spend on this? Yeah. I mean, I think it's important to separate out the two purposes of benchmarks, which one is marketing. And like, there are so many customers that we. We have that was purely because they saw the charts and they saw big bar versus little bar and they were like, okay, we want to go with big bar, which is funny, but that's just, I mean, that's just the way things go. And so I think that motivates, I think that's actually a good thing because that motivates more resources to be put on, you know, benchmarking and evaluation. On the other hand, you know, there definitely is a risk of going like too far in that direction or like even go getting to the point where you're fine tuning just to, you know, satisfy some, some benchmark there. And so.
Swyx [00:26:20]: Like we were saying before. Yeah. Like you guys don't bother competing on sweet bench anymore because it does not, not that relevant.
Matan [00:26:26]: Yeah, that and also like just in the enterprise, the use cases are pretty different than those represented in something like sweet bench. So we do have pretty rigorous internal, internal benchmarks as well. But I think also there's a certain extent to which like the, the vibe based or the sentiment based internally actually matters a lot because who has like a more intimate understanding of the behaviors of these models than the people who work on it. Yeah. We kind of have to be able to be able to be able to be able to begin to, you know, facilitate every single day, like working with them and building with them because I mean, we use factory internally every single day. And so when we switch a model, we very quickly get a sense of how things are changing. Definitely.
Eno [00:27:00]: And I think that those task-based evals tend to be the ones where it's most critical that we hill climb continuously on versus the, the top level evals. They change so much with the new model providers that we try to make sure that they have some degree of consistent behavior, that the feel is smart, but the top level agent is actually the one who's able to do the work that they need to do. not that responsible for what most people call quality. That ends up being, is it fast, accurate, and high quality code edits? Does it call tools with the right parameters? Is the tool design such that that model can easily fit into it? And we have noticed a lot of really interesting behaviors with as the new models that have a lot heavier RL on post-training related to their own internal agentic tools. So for example, Sonnet 3.7 clearly has, it smells like clod code, right? Same with Codex. It very much impacted the way that those models want to write and edit code such that they seem to have a personality that wants to be in a CLI-based tool. What's interesting is how do we combat the preferences that RL brings into the product? For example, search with CLI. CLI is like grep and glob. But what if you gave it a search tool that was way better than grep or glob at finding precisely what you wanted, but the model just really loves to use grep? They're going to fight each other. And so our evals have to figure out how do we make sure that as we build tools that are better than what maybe the model providers have in their slightly more toy examples, that the models use those with their full extent. And that's actually been a very interesting novel challenge to us that only started happening in the last three to six months as these new models have come out.
Model Fine-tuning and Generalization Challenges
Alessio [00:28:47]: Does that make you want to do more reinforcement fine tuning on these models? Like kind of take more of that matter into your own hands?
Eno [00:28:55]: I definitely think that it's an interesting idea, but our take in general is that freezing the model at a specific quality level and freezing the model at a specific data set just feels like it's lower leverage than continuing to iterate on all these external systems. And it also feels like this is a bug. Like we spoke with a bunch of the research labs, and I don't think that they actually want this type of behavior. What it is ultimately is it's a reduction in generalization.
Swyx [00:29:23]: Cool. Anything else to see on the demos? Oh, yeah. I mean, we can... It's still coding.
Eno [00:29:28]: Yeah, yeah. So you can see here that we're running... Oh, because you gave it like a whole bunch of things. Yeah. So I actually gave it like quite a large project to do to execute live in front of us. Got to earn its keep. Yeah. Yeah. This is why this delegation style flow, we see as like really different, where in general, we expect the answer or output of this to just be correct, right? It's running code. It's iterating on code. It's making edits to a bunch of different files. It's going to have to run pre-commit hooks and test all this stuff. I think that this is a big difference in workflow, right? Where we've just had a podcast conversation. Meanwhile, the agent is working on my behalf. This is probably going to be mergeable at the end of this. It's ideally going to create a pull request and we can check in on it. But I think that this difference is like, what would I be doing right now? I think today, a lot of people just like open up their phone maybe and start browsing or they go context switch to a different task. But the real power is unlocked when you start to realize this is the main thing that I'm going to be doing is only delegating these types of tasks. And so you start jumping to, okay, while this is happening, let me go and kick off another task and another one and another one. And so you start jumping to, okay, while this is happening, let me go and kick off another task and another one and another one. And so being cloud native, being able to parallelize these, like I'm only sharing one tab, but if I just open another one and started right now, we support that natively. I think that this feels a little bit more like how people are going to work, where you maybe start the day setting off a bunch of tasks in motion, and then you spend the rest of it on maybe harder intellectual labor, like thinking about which of these is actually highest priority to execute on.
Why Factory is Browser-Based, Not IDE-Based
Matan [00:31:07]: And this actually goes into something that Ina was mentioning a little bit before, but also like a question that I'm sure everyone, when they see this is going to ask, which is, why is this browser based? Why is this not in the IDE? Like I'm used to coding in the IDE. And the kind of higher level answer here is that, and Ina was alluding to this before, like the last 20 years, the IDE was built for this world where developers are writing every single line of code. And something I think everyone can agree on is that over the next few years, what it means to be a software developer is going to change dramatically. Now, some people disagree, and some people say there will be no more software engineers. Some people say there will be, everyone's going to be a software engineer and everywhere, in between. But the reality is very clearly in the next few years, the amount of lines of code written by a human will go down, like the percentage of code written by humans will go down. And our take is that it is very unlikely that the optimal UI or the optimal interaction pattern for this new software development where humans spend much less time writing code, I think it's very unlikely that that optimal interaction pattern will be found by iterating from the optimal pattern when you wrote 100% of your code, which was the IDE. Internally, we talk a lot about the Henry Ford quote, which is, you know, if you ask people what they want, they would say faster horses. And for us, the analogy here is like, can you iterate your way from a horse to a car? And there's like this very grotesque, like ship of Theseus, you can imagine of like trying to turn a horse into a car. It doesn't really look pretty. And our take is, you know, even though the world was built for horses at a certain point in time, right? Like there were stables everywhere throughout a city, you were used to feeding this thing and, you know, taking it with you everywhere. And it is kind of a higher barrier to entry to start introducing this new means of transportation in this analogy. We are taking that more ambitious angle of like, everything is going to change about software development. And in order to find that optimal way of doing it, you do need to think from scratch, think from first principles about what does that new way to develop look like? And to give some early answers that we are pretty clear about is the time developers spend writing code is going to go way down. But in turn, the time that they spend understanding and planning is going to go way up. And then also the time that they spend testing so that they can verify that these agents that they delegated to did indeed do the task correctly, that's going to go way up. The promise of test driven development is going to finally be delivered with this world of AI agents that are working on software development. Because now, if you do want to delegate something like this, while you're doing a podcast and come back later, ideally, you don't even need to check their work and you just merge the PR. But how do you do that with conference? You need to be really sure that the tests that you put up and said, hey, you know, Droid, you're not going to be done until you pass all of these tests. If you wrote those tests well, then you can. All right, great. Pass the test. Let's merge it. I don't even need to
Test-Driven Development and Agent Verification
Swyx [00:33:51]: go in and see how it did everything. I mean, sometimes you do have to break the tests because you're changing functionality. Yeah. Yeah. There's a whole bunch of hard problems, but I just wanted to cap off the sort of visual component of the thing. There's one thing you haven't shown, which is like there's like a built in browser. So like I have a Next.js project here that I'm running. Yeah. The conference website, it's spun it up. When I tried it out in ChatGPT Codex, it didn't work out of the box and they didn't have a browser
Eno [00:34:16]: built in. So it's nice that you have that kind of stuff. No, for sure. Like being able to view like HTML, SVG, et cetera, on demand is super nice. And I think it's pretty much wrapped up. It actually finished these changes. I think it's like roughly 12 files that it edited, created. And so, you know, right after this, because of the GitHub tool, I would just say, go ahead and
Swyx [00:34:36]: create a pull request. Okay. And then it'd be good. Amazing. Yeah. Good stuff. And you even, like a little 43% of context size use. That's actually not that much given that
Eno [00:34:44]: this is factory's own code base. Yeah. And this is actually a large mono repo. I think the big thing that I'd love for people to try out is like, look at how efficient it is. It's able to really execute on precisely what it needs to edit with a relatively lower token usage than other agentic tools. Obviously, if you're just getting autocomplete, that's going to be a little bit more expensive, but compared to other agents where you get like five credits, it takes a while to execute on anything. I think they'll see a better experience with factory.
Swyx [00:35:15]: Yeah. When you started saying things like, oh, we can pull in from Notion, we can pull it from Slack, like that sounded like a lot of context. You're going to have to do pretty efficient rag to do
Matan [00:35:26]: this, right? Like, I guess it's not even rag, it's just retrieval. Yeah. Yeah. I mean, but there is the temptation. And I remember maybe a year ago, there was really a lot of hype on large context because, right, it's the dream of you can be super lazy and just throw in your whole code base, throw in everything at it. Which is what Cloud Core does, right? Right. Yeah, exactly. But I think the one downside of that is, okay, great. Like, if you do have billion token context window model, you throw it all in there, it's still going to be more expensive. The reason why retrieval is so important for us is because even if there is a model that's going to have these larger context windows, and certainly over time, we're going to get larger context windows, you still want to be very cost efficient. And this is something that our customers care a lot about. And they see a lot of the value in the effort that we put in on retrieval, because they'll see like, wait, this was a huge mono repo, and I gave it all this information. But then I see for each actual call, you're really good at figuring out what do I actually need, as opposed to just like
Retrieval vs Large Context Windows for Cost Efficiency
Alessio [00:36:17]: throw the whole repo in and pray that it works. You mentioned the credits, what's the pricing
Pricing model
Matan [00:36:21]: model of the product? We're fully usage based. So the tokens, I think for us, it's really important to like, respect the users and their ability to understand what what this stuff means. And so I think like all the stuff around like credits, and it just kind of obfuscates what's actually happening under the hood. And so I think it's really important to understand what's happening under the hood. And I actually think that we get better users, the more they understand what tokens are and how they're used, you know, in each back and forth.
Eno [00:36:46]: Yeah, so it's a direct bill through to the, we call them standard tokens, and it's benchmarked off of the standard models that we have. So like right now, when you get access to the platform, your team would pay like a small fixed price for just access. Every additional user is another like very small fixed price. And then the vast majority of the spend would be on usage, of the system. And so I think that this is just nicely aligned where you get a sense of how efficient it is about the token usage. This is a big reason why we've tried really hard to make it more token efficient. And then you can track, of course, in the platform, how you're using it. And I think that a lot of people like to not only see just like raw usage, and this kind of gets into like tracking success, something that a lot of people do by maybe like number of tabs that you accepted or chat sessions that ended with code. For us, we try to like track the number of tabs that you accepted. And then we try to look a little bit further and say, look, you use this many tokens, but, you know, here are the deliverables that you got. Here are the pull requests created. Here's merged code. We help enterprise users look at things like code churn, which it turns out the more AI generated code you have, if the, you know, if the platform isn't telling you the code churn, there's a reason for that. Code churn meaning amount of code deleted versus added? Yeah, it's basically a metric that
Enterprise Metrics: Code Churn and ROI
Matan [00:38:02]: tracks when you, it's kind of like a variability in a given line of code. It's very imperfect like some people, some people will say like the difference between code churn and like refactored code is like somewhat arbitrary because it's a time period at which, okay, if I merged some line and then I changed that line, if you change that line in a shorter period, it'll churn versus a longer
Eno [00:38:25]: period. It'll count as like refactoring, which is like a little. So generally in enterprise code bases, if you merge a line of code and then change that code within three weeks, it's because something was wrong with that code. Generally, it's not always true, but it's not always true.
Matan [00:38:38]: But it's a useful metric. It averages out because sometimes it's like, wait, what if you just had like an improvement or, you know, some, some change that wasn't about quality, but like is
Eno [00:38:47]: code churn up bad? Yes. Because what it tends to be is that in a, in very high quality code bases, you'll see 3%, 4% code churn when they're at scale, right? This is like millions of lines of code in poor code bases or poorly maintained code bases or early stage companies that are just changing a lot of code. So it's like, okay, I'm going to change this. I'm going to change this. I'm going to change this a lot at once. You'll see numbers like 10 or 20%. Now, if you're at Lassian and you have 10% code churn, that's a huge, huge problem because that means that you're just wasting so much time. If you're an early stage startup, code churn is less important. This is why we don't really like report that to every team, just enterprises.
Swyx [00:39:27]: Any other like measurements are popular that, I mean, you know, this is nice that I'm hearing about code churn, but like what else are enterprise VPs, events, CTOs, what do they look at?
Matan [00:39:38]: I think the biggest thing, because there's so many tricks and different dances you can do to like justify ROI. Number of commits, lines of code, DORA metrics are usually popular. And at the end of the day, like what we, we initially went really hard in all the metric stuff. What we found is that oftentimes if they liked it, they wouldn't care. And if they didn't like it, they wouldn't care. And so at the reality, like at the end of the day, no one really cares about the metrics. What people really care about is like developer sentiment. When you're kind of playing that game at the end of the day, if you want to do a metric, you're going to have to do a lot of work. You're going to have to do a lot of work. You're going to have to talk to developers and ask if they feel more productive, or if you're a large enterprise and you want to justify ROI, the biggest thing that we've seen and like, that's allowed us to deploy very quickly in enterprises is pulling in timelines on things. So there's this one very large public company that we work with and pulling in just a large migration task from taking four months to taking like three and a half days. That is the best ROI there. You don't need to measure this or that, like, like we had something that was going to be delivered in the next quarter and we could get done this week with no downtime. Like that is, you know, music to a VP of engineering's ears. And so that's what we tend to focus on is like pulling in deliverables or increasing the
Executing Large Refactors and Migrations with Droids
Swyx [00:40:48]: scope of what you can get done in a quarter. In order to achieve a very large refactor, like you just described, do we use that same process you just saw or is there more setup?
Eno [00:40:57]: I think that the workflow for, let's say, a migration is probably one of the most common. I can even give a very concrete example. Let's say you are the administrative service of a large, European nation, right? Like Germany or Italy. And you have a hospital system that runs on like a 20-year-old Java code base. Now, a company wants to come in and big four consulting firm or something like that says, we would like to transform this entire code base to Java 21. It's going to take X amount of time, a couple months. And, you know, by the end, you'll be on a relational database. You'll be into the future, right? On Java 21. When that typically happens, you kind of have to almost break down what that means from a, like, human perspective first, to then map it to how it works on our platform. You'll have a team of anywhere from four to 10 people come in and you have a project manager who is going to work with engineers to analyze the code bases, figure out all the dependencies, map that out into docs, right? First analysis and overview of the code base. The next is a migration strategy and plan. The third is like timelines. And you're going to scope all this out. What do you do next? Well, you go to a project management tool like Jira. And so you take those documents and a human being translates that out. We've got two epics over the next two months. This epic will have these tickets. That epic will have these tickets. And then you find out the dependencies and you map those out to humans. Now, each of these humans are now operating such that one after the other, they're knocking out their work, mainly in parallel, but occasionally pieces have to connect, right? One person misses, and now the whole project gets delayed about a week. And so this interplay of, of understanding, planning, executing on the migration incrementally, and then ultimately completing. Now there's a handoff period. There's docs of the new artifacts that we've created. There's all this information. You map that over to a system like ours. One human being can say, please analyze this entire code base and generate documentation, right? And that's one pass, one session in our platform. Analyze each of the modules. We already do a lot of this behind the scenes, which makes this a lot easier. And then you have the next step, which is to go to the and actually generate an overview of what the current state is. You can now pull those docs in with real code and then say, what's the migration plan, right? If there's some specific system, you can pull in docs. And then when you have this, our system connects with linear Jira. It can create tickets, just create the epic ticket, this whole process out and figure out which are dependencies and which can be executed in parallel. Now you just open up an engineer in every browser tab, right? And you execute all of those tasks at the same time, and you as a human being just review the code changes, right? This looks good. Merge. Did it pass CI? Okay, great. Onto the next one. This looks good. Merge. So a process that typically gets ultimately bottlenecked, not by like skilled humans writing lines of code, but by bureaucracy and technical complexity and understanding now gets condensed into basically how fast can a human being delegate the tasks appropriately. So it happens outside of like one session, like what we just saw, which would be like a couple of sessions. And then you have a process that's one of those tasks, but the planning phase, that's really where we see enormous condensation of time.
Swyx [00:44:14]: We just talked about your pricing, your, your just usage base, but you tempted to have forward deployed engineers that just like the current meme right now to execute these large
Matan [00:44:23]: things. Yeah. So I think this is something we definitely do a little bit of for our larger customers, just because, you know, like we said at the beginning, this is the way we think software development will look. And it's an entirely new behavior pattern. And I think it would be, a little naive to just be like, Hey, we have this new way of doing things, go figure it out yourselves. Right. So we definitely go in and, you know, help show them how to do this. So like in this migration example that I was mentioning before, we worked with them like side by side, but just us and like two of their engineers showed them how to do it. They were like, they saw the light, if you will. And then they ended up being the internal influencers within their org teaching everyone else how to do it. But if you want to change behavior, you can't just assume that the product is going to be so good that everyone's going to, you know, immediately get it. Because with developers, you know, we need to know who we're selling to and developers have very efficient ways of working that they've built out over the last 20 years. And we want to make sure that we accommodate that and earn their trust and slowly bring them into this new way of building. And to do that, we need to extend that olive branch and, you know,
Model Speed, Parallelism, and Delegation Bottlenecks
Alessio [00:45:25]: come meet them where they are, show them how they can do new things. We did an episode with Together AI maybe a year ago or so. And we were talking about what inference speed actually we needed. And they always say, you know, we need to know how to do it. And we're like, you know, we always argued we need to get to like 5,000 tokens a second. And we're chatting whether or not that makes sense because people cannot really read it. As you think about Factory, how much do you think you're like bound by the speed of these models? Do you know, like if the models were like a lot faster, would you just complete things quicker? Would you like maybe fan out more
Matan [00:45:57]: in parallel? Like what are like the limits of the models today? I want to let you know, answer this, but immediately every time this thing comes up, I always just think about the memory that Chrome tabs take, which is like, you know, I don't know, I don't know, I don't know, I don't know, I don't know, like it's never enough and you always want more, but then it's also, it lets you be lazier.
Eno [00:46:12]: Yeah. But anyway, I want to. Yeah, no, for sure. And I think that the, this is kind of a funny question. It kind of has two directions. It's like practically, would this make a big difference on someone who knows and loves and uses our platform on a daily basis? I think it would probably improve the quality of life such that, yeah, definitely faster tokens would be awesome. I think that actually where this impacts is for those who haven't yet made the jump from collaboration to delegation. So if you are used to very high latency, high feedback experiences, then that speed difference and seeing like most of that delegation happened very quickly and then being able to immediately jump in, I think feels very nice. And so for the larger enterprise deployments where they start to familiarize themselves with how this works and the migrations, I don't think this actually makes a big difference because most of the bottleneck ends up being, like I mentioned, almost like bureaucratic. In nature, but for the average developer, I think this improves the user experience to the point
Matan [00:47:12]: where it would feel very magical. So I think we could get a lot faster. It probably wouldn't change what's possible, but it would really, really change like ease of adoption for people
Eno [00:47:23]: who maybe aren't as in the weeds on AI tools. And if you combine the latency with a cost reduction as well, I do think that cost is one of the reasons why we haven't so greatly scaled out. Like originally we had a lot of techniques that would generate, a lot of stuff in parallel, and we still know how to do that. And we're very excited to, to bring that. But right now we don't do it because it's cost prohibitive and the quality Delta is not
Swyx [00:47:48]: enough to justify the cost increase. I have a kind of a closing question. If you're, if you don't mind, this is a more or less, you're asking you on like a limiting factor. It's basically four questions in one. So what do you see as your limiting factor right now in terms of models, basically like what capabilities would really help you? Um, hiring, what skills are really hard to hire customers? Like what, you know, do you really want to unlock that? You're like, it's like weirdly not working, but like you have an ICP, which is a more enterprise doing well, but like, you know, what, what's like the next one. And then like finally dev tooling, like what do you wish existed that you had to build for yourself or you just feel
Eno [00:48:25]: like could be a lot better. Yeah. I'll maybe I'll do models and dev tool and you can take hiring and, uh, and customers. I mean, I'm thinking right off the bat, probably the biggest thing is models that have been post-trained on more general agentic trajectories over very long timespans. That feels like something that is, there's an effort for that right now. But what I mean is an hour or two hours or three hours of seriously working on a hard problem such that the model knows how to keep that long-term goal-directed behavior the whole time. That is something that I assume we'll get. And I think that's something that we'll get. I think that's something that we'll get.
Swyx [00:49:07]: Yeah. OpenAI has put out that like a operator benchmark. Yeah. That was that they had a human
Eno [00:49:12]: testers, like actually try for two hours and give up. Yeah. Did you see that one? Yeah. Yeah. I mean, I think that that's exactly the type of work that we want to see taken further because that I would
Swyx [00:49:22]: argue is probably one of the bigger blockers. I would say like, would you ever do that yourself? I don't see you guys as customizing your own models a lot, but you work with the frontier labs,
Eno [00:49:33]: right? But like, is there a point where you would just be like, Hey, screw it. Like we'll do it. We are currently building benchmarks with a lot of the post-training techniques very much in mind right now. And so I don't know what exactly at this point in time, how much we're going to commit to that, but for sure we will be using those benchmarks for our own internal goals. And if we need to use them later on for post-training, I think that there's a lot of compatibility. And then maybe for dev tools, since I'll just, I'll just jump that one. Yeah. It is still surprising to me that, uh, uh, observability, it remains like very challenging.
Observability Challenges and Semantic Telemetry
Swyx [00:50:11]: Really? There are like 80 tools out there.
Eno [00:50:12]: No, I, for sure. And Langsmith is actually fantastic. Like we use Langsmith. Are you guys a Langchain shop? Uh, we don't use Langchain, but we just use Langsmith. Um, and, and Langsmith is awesome.
Swyx [00:50:21]: See the hackathon is his ROI for Harrison.
Eno [00:50:24]: No, like they've been fantastic and that's been cool. But I think that there is, it's really tricky to deal with enterprise customers where you can't see their code data at all, but you're trying to build a product where you can do it. You can improve the experience. And a lot of it is actually subjective. It's like, I don't like the way this code looks. That remains something very unclear to us is how do you build almost like semantic observability into your product? Uh, I think amplitude and, uh, and stat SIG and a lot of the feature flag companies actually are closer to this than the existing tools.
Swyx [00:50:57]: Like product analytics, actually, really, it's more about like observe if they still,
Eno [00:51:00]: if they're on the platform, like basically anything other than up and down, uh, thumbs, right? Yeah. And like, and like, what was the user's intent when they entered into this session, right? It's the type of thing where you almost need LLMs in the observability itself.
Swyx [00:51:13]: Are you saying they've actually done it or amplitude could do it?
Eno [00:51:16]: That's where I would like to see it.
Swyx [00:51:18]: Yeah. As far as I understand, it hasn't really, yeah.
Alessio [00:51:20]: Yeah. Because mostly everything is kind of like span based. They're like all the observability products are, we started trace, but not at the, yeah, exactly. Not, not in the like semantic direction. Yeah. Yeah. So for you, that's kind of solved in a way. It's like the actual traces is like, you can get that information anywhere.
Eno [00:51:38]: Yeah. Our team comes from like Uber and all these amazing places where they, they know how to do that part. I think the more tricky thing is when human beings have like messy intents that are natural language, how do you really classify and understand when users are having a good time versus when they're having a bad time? Okay. That's hard.
Swyx [00:51:56]: Great. Hiring and customers.
Matan [00:51:58]: Yeah. So maybe I'll start with customers. So we've been at it for just over two years now. Yeah. So I think the first like year and a half was really, really focusing in on the product and what is the, the interaction pattern that works for the enterprise. And over the last 90 days, the deployments that we've had with like the large enterprise and fortune 500 has been exploding. It's been going really well. It's very exciting. How are they mostly finding you? So this is a good point. This is part of why we're doing more podcasts is because so far we really just relied on word of mouth, like working well with one enterprise. And then, you know, they're at some CEO dinner, they mentioned it to someone else, which by the way, like, that's why we have the conference to like, we put all the C the VPs in one room. Totally. And so like, it's worked really well, but I think when every one of those conversations ends up leading to a happy customer, that means you need to increase top of funnel. And so accordingly, we're really putting fuel on the fire for our go to market for, you know, fortune 500 large enterprises, which is obviously it's a very exciting thing to do where the team has been pumped. I mean, there was a particular day in January of this year where one of those large enterprises basically had the magic moment of like, if I was the only one at my company using this, I would still tell them to like, have me use this instead of hiring like three engineers for myself. One of the biggest moments for us where it was like, people in the enterprise are really getting dramatic value out of factory. And that kind of kicked off this really like the last 90 days has just been a whirlwind. So getting to more of these fortune 500 companies is kind of top of mind for us right now, to that end. You know, as you serve. Fortune 500 customers, it becomes important to have a larger go to market team, both on the sales side, the customer success side, and then also, of course, on the engineering side. So we are very much hiring.
Hiring
Swyx [00:53:44]: Yeah, I think like everyone's hiring. It's just like, what are you finding that's hard to hire?
Matan [00:53:48]: Oh, I see. Like the particular roles? Yeah. Yeah. So what's the rate limiter here? I think a big rate limiter is like, for us going to these fortune 500 companies, one of the most important things is having both that ability to. To, you know, talk to the CIO, VP of engineering and have that sales presence, but then also the ability to be sitting side by side with some of their developers and jumping into the platform, jumping into their use cases and having that. So you need like a hundred, you know, basically, like literally our profile, actually our profile when we're like looking for this role is like, is this a junior Eno or not? Like that's,
Eno [00:54:23]: that's basically the, the, the template there. Yeah. I don't know about that, but I definitely think that if you are highly, highly technical, that you want to be a founder, you want to move into a role where you are interfacing with CIOs, CTOs, like this, we have like three maybe of these roles that are probably going to be the most important like roles in our go-to-market team. And so I think that's a huge opportunity for anyone interested in what we've talked about.
Matan [00:54:52]: We joke that this person would basically be my best friend because any trip we go to, to fly to a customer, they'd be there with me, you know, talking to whoever is the buyer, as well as, you know, the, the, the, the, the, the, the, the, the, the, the, the, the, the, the, the, the, the, the, the啤l-in-lắ� , so they said like, oh, and we're all like the so I'm also I guess hiring a best friend.
Alessio [00:55:06]: thought that's what AI was going to be for . Just to wrap, I think we're all fans of your guys' design and kind of like brand Vi- Speaking of best friends. Who does your thing?
Factory's design and branding approach
Matan [00:55:19]: Yeah. So a huge privilege of, you know, Faktor has been working with my older brother, Cal who who joined us, he, you know, moved from, he was in New York for five years. He moved He actually, even before he moved, he's the one who designed our logo way back when. And, you know, he's been a part of Factory from the very beginning. And it's been an absolute pleasure working with him from the brand design, the marketing design, and then, of course, the product and the platform itself. I cannot recommend enough working with a sibling.
Swyx [00:55:49]: Sure. I mean, you know, not all of us are lucky to have that. What do you learn from working with a designer like that? I think a lot of technical people listen to us, want to build a startup, but they don't have the polish that you have. They don't have the hype.
Matan [00:56:03]: Yeah, I think a big part of this is like one of our core operating principles is like embracing perspectives. And so Cal is not an engineer. And I think what's great is a majority of our team are engineers. And having that ability to come in with that design perspective, and then also the engineering perspective. And like, bash those two things together until we get something perfect out of it. That has been really, really important. I think it's a lot of times, it's kind of easy to fall victim to, oh, I'm building, like, I'm the profile who I'm building for. So I know what's best. And that obviously works a lot of the time. But sometimes there are some like core design tenets that you just might not think of if you're building for yourself. So I think that's been, that's been pretty important there.
Eno [00:56:42]: Yeah, and we do live in a very AI native company or operate in a very AI native company. So being able to have some of those set principles that are then consumable by our own agents, right design systems, and consistency, I think it's pretty surprising the degree to which even like droids can actually imitate a brand voice and style that Cal created for us. And so a lot of that comes from not just the droids doing that, from our entire team of product engineers are all incredibly thoughtful about what they're putting in front of users. And I think that they're able to bring a lot of that into
Swyx [00:57:22]: And I think that they're able to bring a lot of that into it in a way that feels like safe and on brand.
Matan [00:57:49]: Yeah, yeah, I think it's important for us because not only is this, you know, incredibly transformational, but it's also like, these are people that we spend all of our time with. And we want to make sure that while we're doing it,
Swyx [00:57:57]: it's like right next to the Caltrain, you can like advertise out of your window.
Matan [00:58:02]: Yeah, no one, no one peek in though. There's a lot of a lot of secrets in there.
Swyx [00:58:07]: It's pretty sweet. Cool. I mean, you know, I'm very excited for your talk. You know, like we touched on a few things I'm interested in, right? Like we're seeing tiny teams is a topic that I'm seeing, like, you know, one person can do a lot more. So like, the average team size is really shrinking. The interaction of AI design and engineers. That's also another thing I'm exploring. Like, I think we're really trying to like push the frontier. And then obviously, there's always like the Swyx and stuff, which is always ongoing. So like, yeah, there's a lot of interesting work going on.
Closing Thoughts and Future of AI-Native Development
Matan [00:58:34]: And one interesting addendum there, there are sometimes individuals who weren't even really developers, who will use factory and have more usage than in 100 person enterprise. Yeah. Which is crazy to see. Yeah. Yeah. Yeah. Yeah. Yeah. Just in how people use these tools, whether it's like for that design or for that, like small, small team use case. It's pretty fascinating.
Swyx [00:58:55]: There's an AI native attitude that like is going to set people apart if they're just open to it. But then also like they're maybe not, they don't drink too much Kool-Aid. I think there's a medium there.
Alessio [00:59:05]: Thank you guys for coming on. This was fun. Thanks for having us.
Matan [00:59:08]: Thank you guys for having us. This was awesome.