


The Multi-modal, Multi-model, Multi-everything Future of AGI
The Multi-modal, Multi-model, Multi-everything Future of AGI
GPT-4 FOMO antidote, and meditations on Moravec's Paradox

As was rumored and then confirmed by Microsoft Germany, GPT-4 was released yesterday in ChatGPT with a blogpost, paper, livestream, and a couple of short videos:

To use simple measures of how anticipated this was - GPT-4 is already the 11th-most upvoted Hacker News story of ALL TIME, the Developer Livestream got 1.5 million views in 20 hours (currently #5 trending video on all of YouTube) and the announcement tweet got 4x more likes than the same for ChatGPT, itself the biggest story of 2022.
“Today has been a great year in AI” - Tobi Lutke, Shopify CEO
“Not sure I can think of a time where there was this much unexplored territory with this much new capability in the hands of this many users.” - Karpathy
There are lots of screenshots and bad takes flying around, so I figure it would be most useful to do the same executive-summary-style recap I did for ChatGPT, for GPT-4.
GPT-4 Executive Summary
GPT-4 is the newest version of OpenAI’s flagship language model. It is:
significantly better at existing GPT-3 tasks (huge improvements across both standard NLP benchmarks1 & human exams like the SAT/GRE2, and better instruction following and world knowledge)
capable of new tasks3 (enough math to do your taxes and beat Minerva!)
able to use 8x more context than ChatGPT (50 pages, 25k words of context means unlocks better AI-enabled coding4 by simply pasting docs, or better chat by pasting entire Wikipedia articles, or even comparing two articles)
safer to use (20-30% fewer hallucinations and unsafe content5)
That alone would qualify it as a huge release, but GPT-4 is also OpenAI’s first multimodal model, being able to natively understand image input as well as text. This is orders of magnitude better than existing OCR and Image-to-Text (e.g. BLIP) solutions and has to be seen to be fully understood, but the capabilities that you must know include:
Converting a sketch of a website into code (screenshot, demo timestamp)
Fully describing a screenshot of a Discord app (demo timestamp)6
Summarizing images of a paper and answering questions about figures (screenshot)
Recognizing photos (fridge, kitchen), offering meal ideas (NYT article)
Explaining why an image is funny (ironing clothes, chicken nuggets, memes)
GPT-4 can be tried out today by being a ChatGPT Plus subscriber ($20/month), while text API access is granted on a waitlist or by contributing OpenAI Evals. The multimodal visual API capability is exclusive to BeMyEyes for now. API Pricing is now split into prompt tokens and completion tokens and is 30-60x higher than GPT-3.57.
In a break from the past, OpenAI declined to release any technical details of GPT-4, citing competition and safety concerns. This means the Small Circle, Big Circle memes were not confirmed nor denied8 and that another round of criticism of OpenAI not being open started again.
We know: that GPT-4’s training started 2 years ago and ended in August 2022, that GPT-4’s data cutoff was Sept 20219.
We don’t know: how the data10, compute11, hardware12, parameters13 or training process changed from GPT-3.
In place of technical detail, OpenAI instead focused on demonstrating capabilities (explained above), scaling and safety research (done by OpenAI’s Alignment Research Center14) and demonstrating usecases with launch partners in an impressively coordinated launch (with a full slate of Built With GPT-4 examples on launch day):
Microsoft confirmed that Prometheus was their codename for GPT-4, meaning all Bing/Sydney users were really GPT-4 users (worrying if you have seen Sydney’s issues in the wild) and also increased Bing query limits
Duolingo (blog) demonstrated new Explain My Answer and Roleplay features for Spanish and French (though GPT-4 also speaks many other languages)
Stripe tested 15 use cases across support customization, answering docs questions, and fraud detection.
Intercom (Eoghan, blog) launched their Fin chatbot, which reduces hallucinations (incl about competitors), disambiguates, and hands over to human agents
DoNotPay teased "one click lawsuits" for robocallers and emails without unsubscribe
Race Dynamics. The coordination reached beyond OpenAI - GPT-4 wasn’t the only foundation model launch of Tuesday. Both Google and Anthropic launched their PaLM API15 and Claude+ models as well, with Quora Poe being the first app to launch with both OpenAI GPT-4 AND Anthropic’s Claude+ models. This ultra-competitive launch cycle across companies on Pi Day smacks of last month’s Google vs Microsoft race for special events and is causing concern from AI safety worriers and sleep-deprived Substack writers alike.
(end of summary! phew! but discussions ongoing @ Hacker News and Twitter)
The Year of Multimodal vs Multimodel AI
GPT-4’s Multimodality is a glimpse of the AGI future to come. It didn’t end up fitting all the speculated capabilities - it doesn’t have image output, and audio was notably missing from the accepted inputs given the Whisper API release, but Jim Fan’s hero image here was mostly spot on:


However, 3 days ago Microsoft Research China released another approach to multiple modalities with Visual ChatGPT, allowing you to converse with your images the same as GPT-4:

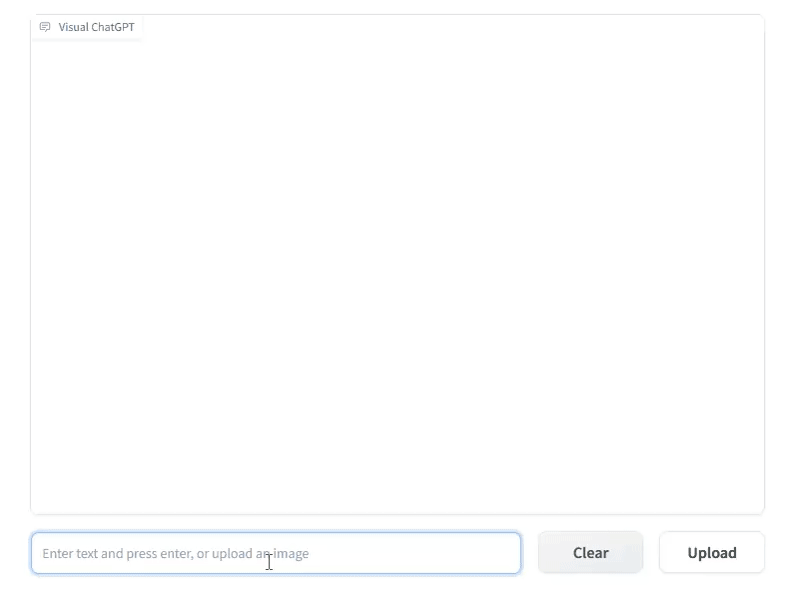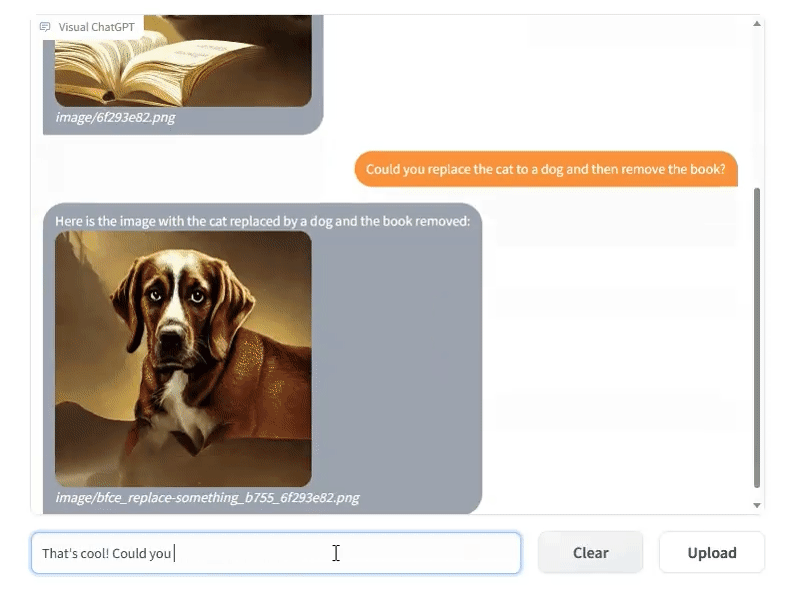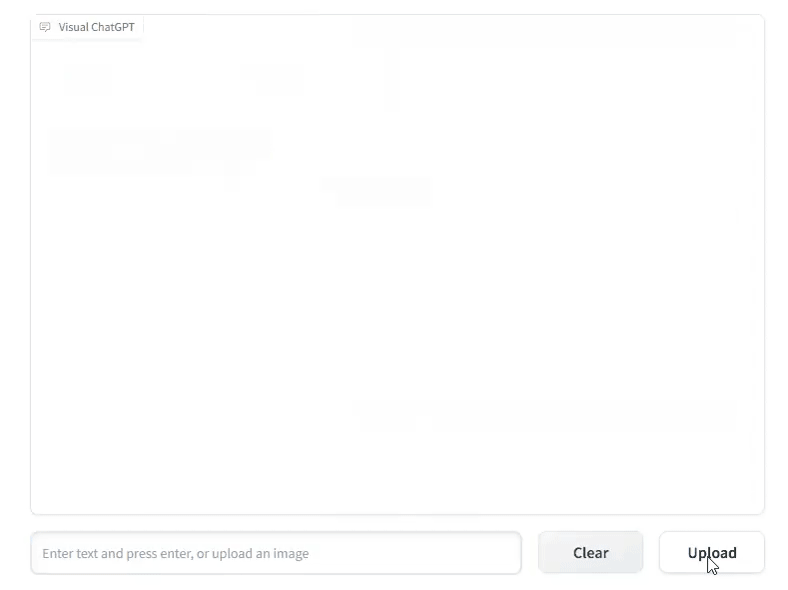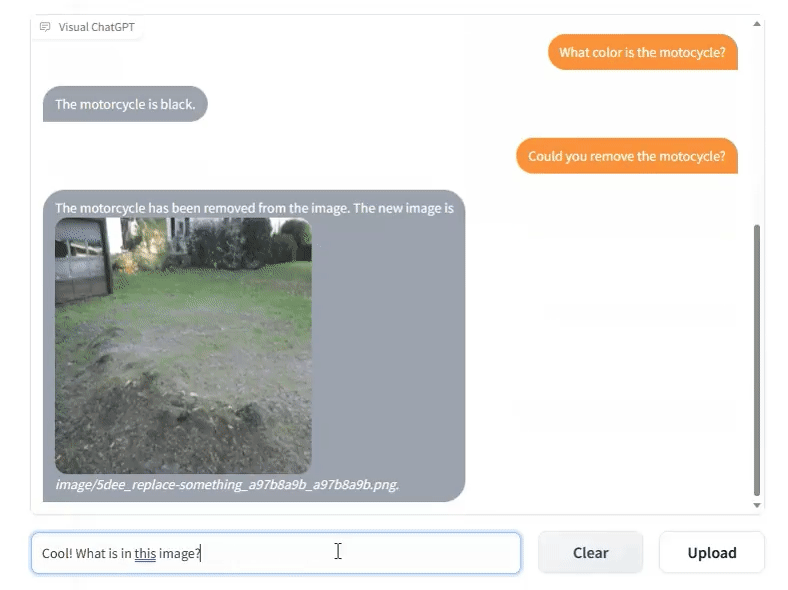
This is a multi-modal project, but is more accurately described as a multi-model project, because it really is basically “22 models in a trenchcoat16”:


This hints at two ways of achieving multi-modality - the cheap way (chaining together models, likely with LangChain), and the "right" way (training and embedding on mixed modality datasets). We have some reason to believe that multimodal training gives benefits over and above single modality training - in the same way that adding a corpus of code to language model training has been observed to improve results for non-code natural language, we might observe that teaching an AI what something looks like improves their ability to describe it and vice versa17.
Even being single-modality but multi-model is proving to be useful. Quora founder Adam D’Angelo chose to launch his new Poe bot with both OpenAI GPT-4 and Anthropic Claude support, and former GitHub CEO Nat Friedman built nat.dev to help compare outputs across the largest possible range of text models:


Eliezer Yudkowsky has also commented that being multi-model can be useful for model distillation as well, with the recent Stanford Alpaca result finetuning Meta’s LLaMa off of GPT-3 to achieve comparable results with a 25x smaller model.
This seems to be a tremendously fruitful area of development (not forgetting Palm-E, Kosmos-1, ViperGPT, and other developments I don’t have room to cover) and I expect multimodal, multimodel developments to dominate research and engineering cycles through at least the rest of 2023, edging us closer and closer to the AGI event horizon.
AGI = Multi-everything and Moravec’s Paradox
Moravec’s Paradox can be summarized as “computers find easy things that humans find hard, and vice versa”. But human capabilities evolve about 100,000x slower than computers, and it does not take long for computers to go from sub-human to super-human. By now we are familiar with the idea that LLMs are effortlessly multilingual (across the most popular human and programming languages, but also increasingly with lower resource languages) and multidisciplinary (GPT-4 simultaneously capable of being a great sommelier, law student, med student and coder, though english lit is safe).
But those are merely just two dimensions we can think of. OpenAI ARC and Meta FAIR tested AI’s ability to be duplicitious, and we are increasingly seeing AI be effortlessly multi-personality as well - with the Waluigi Effect recently entering the AI discourse as a formal shorthand and Bing’s Sydney showing wildly disturbing alternative personalities variously known as Venom and Dark Sydney. And yet we press on.
AI is under no obligation to only be multi- in ways that we expect. I am reminded of the ending of the movie Her, when Joaquin Pheonix learns that Samantha is simultaneously in love with 641 people, a number so big it boggles his mind but is functionally the same as loving 1 person for a multi-everything AI:
Moloch, thy name is race dynamics.
Dan Hendrycks, author of MMLU, commented that “Since it gets 86.4% on our MMLU benchmark, that suggests GPT-4.5 should be able to reach expert-level performance. GPT-4: Language Models are... Almost Omniscient”
Users are finding other usecases in credit card enrichment, drug discovery, date matching, waifu calculus - though these amateur tests often overstate their claims for clout. EDIT: it can also sufficiently administer a Reverse Turing Test to distinguish between ChatGPT and Human answers.
Good GPT-4 code demos in lambda calculus parser and writing C++, Bazel, Terraform, adding background animations, or creating Pong, Snake or Game of life or Midi scripts.
Although it still does surprisingly poorly on Leetcode and inexplicably poorly on AMC10 (easier) vs AMC12 (harder).
But still imperfect - already some regressions in hallucinations and jailbreaks found (DAN-style prompt injections still work)
This was my personal favorite part of the demo - it means that desktop agents like Adept (which just raised a $350m Series B), Embra, and Uni.ai or Minion.ai can get VERY good:

In the lead up to GPT-4, Sam Altman hinted at higher pricing for smarter models:

Sam Altman seems to acknowledge trolling the grifters was intentional.
There is some confusion as some people report GPT-3.5’s cutoff was Dec 2021.
There is some evidence of data contamination skewing benchmarks for leetcode and codeforces, and without further detail it is difficult to confirm this.
Yannic Kilcher guessed from the scaling chart that GPT-4 might have used 1000x more compute than GPT-3 but this is all wild guessing.
We know GPT-3 was trained with 10,000 Nvidia GPUs, and have hints that new clusters are 10x more powerful. Azure announced a new OpenAI cluster last November but this is not live yet.
Brave souls will NOT click to obtain illegally leaked GPT-4 weights.
ARC is greatly criticized by the AI safety community for testing GPT-4’s ability to “set up copies of itself” and “increase its own robustness”
Google’s launch is criticized for being weirdly opaque, although their AI across Workspaces launch was much better received. Still it reinforced existing concerns about Google’s ability to ship vs OpenAI’s incredible momentum over the past year:

With the “trenchcoat” being 900 lines of the most “researcher quality” code you’ve ever seen
Though multimodal AI will still struggle with Rene Magritte!
To me, Alpaca totally stole GPT-4's thunder.
GPT-4 is also able to distinguish writing styles of known authors https://twitter.com/vagabondjack/status/1637468848122396672