

How Open Source is eating AI
Why the best delivery mechanism for AI is not APIs

Translations: Chinese
The GPT-2 cycle took 6 months:
In Feb 2019, OpenAI announced GPT-2, but also said it was too dangerous to release in full, and restructured from nonprofit to capped-profit
By August, it had been cloned in the open by two master’s students as OpenGPT-2
By November, OpenAI released their 1.5B parameter model, after a cautious staged release process
The GPT-3 cycle took 10 months:
May 2020: OpenAI released GPT-3 as a paper and a closed beta API in June 2020.
Jul 2020: EleutherAI forms as the truly open alternative to OpenAI
Sep 2020: Grants Microsoft “exclusive license for GPT-3”
Jan 2021: EleutherAI released The Pile, their 800GB dataset
Mar 2021: EleutherAI released their open GPT-Neo 1.3B and 2.7B models
Nov 2021: OpenAI takes the waitlist off their API
May 2022: Meta released OPT-175B for researchers (with logbook! and an open license)
Jun 2022: Yandex releases YaLM-100B under an Apache-2 license
Jul 2022: HuggingFace releases BLOOM-176B under a RAIL license
The Text-to-Image cycle took 2? years (Nov 2022 edit: a fuller 10 year history including GANs is here):
Jun 2020: OpenAI blogs about Image GPT
Dec 2020: Patrick Esser et al publish Taming Transformers for High-Resolution Image Synthesis (aka VQGAN, a sharp improvement on 2019’s VQVAEs)
Jan 2021: OpenAI announces results from the first DALL-E and open sources CLIP
May 2021: OpenAI releases finding that Diffusion Models beat GANs on Image Synthesis
Dec 2021: the CompVis group publish High-Resolution Image Synthesis with Latent Diffusion Models together with the original CompVis/latent-diffusion repo
Dec 2021: OpenAI publishes GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
Mar 2022: Midjourney launches its closed beta
Apr 2022: OpenAI announces DALL-E 2 with a limited “research preview”
May 2022: Google releases their Imagen paper (implemented in PyTorch in 3 days)
Jul 2022: DALL-E 2 available as an open beta (with waitlist) via OpenAI’s UI/API
Jul 2022: Midjourney also announces a fully-open beta via their Discord
Aug 2022: Stable Diffusion 1.4 publicly released, under OpenRAIL-M license. Models & Code from CompVis + Runway, Funding from Stability AI to scale up compute
Sep 2022: OpenAI takes the waitlist off DALL-E 2
UPDATE Oct 2022 : Stable Diffusion 1.5 released by Runway, with some controversy
UPDATE Nov 2022: Stable Diffusion 2.0 released by Stability
The timelines above are highly cherrypicked of course; the story is much longer if you take into account the longer development history starting from the academic papers for diffusion (2015) and transformer models (2017) and older work on GANs. See also the research origins of Stable Diffusion from RunwayML and Emad’s description of the CC12M breakthroughs in Dec 2021 in his chat with Elad Gil.
But what is more interesting is what has happened since: OpenAI’s audio-to-text model, Whisper, was released under MIT license in September with no API paywall. Of course, there is less scope for abuse in the audio-to-text domain, but more than a few people have speculated that the reception to Stable Diffusion’s release influenced the open sourcing decision.
Dreambooth: Community Take The Wheel
Sufficiently advanced community is indistinguishable from magic. Researchers and well funded teams have been very good at producing new foundational models (FM), but it is the open source community that have been very good at coming up with productized use cases and optimizing the last mile of the models.
The most quantifiable example of this happened with the recent Dreambooth cycle (finetuned text to image with few shot learning of a subject to insert in a scene).
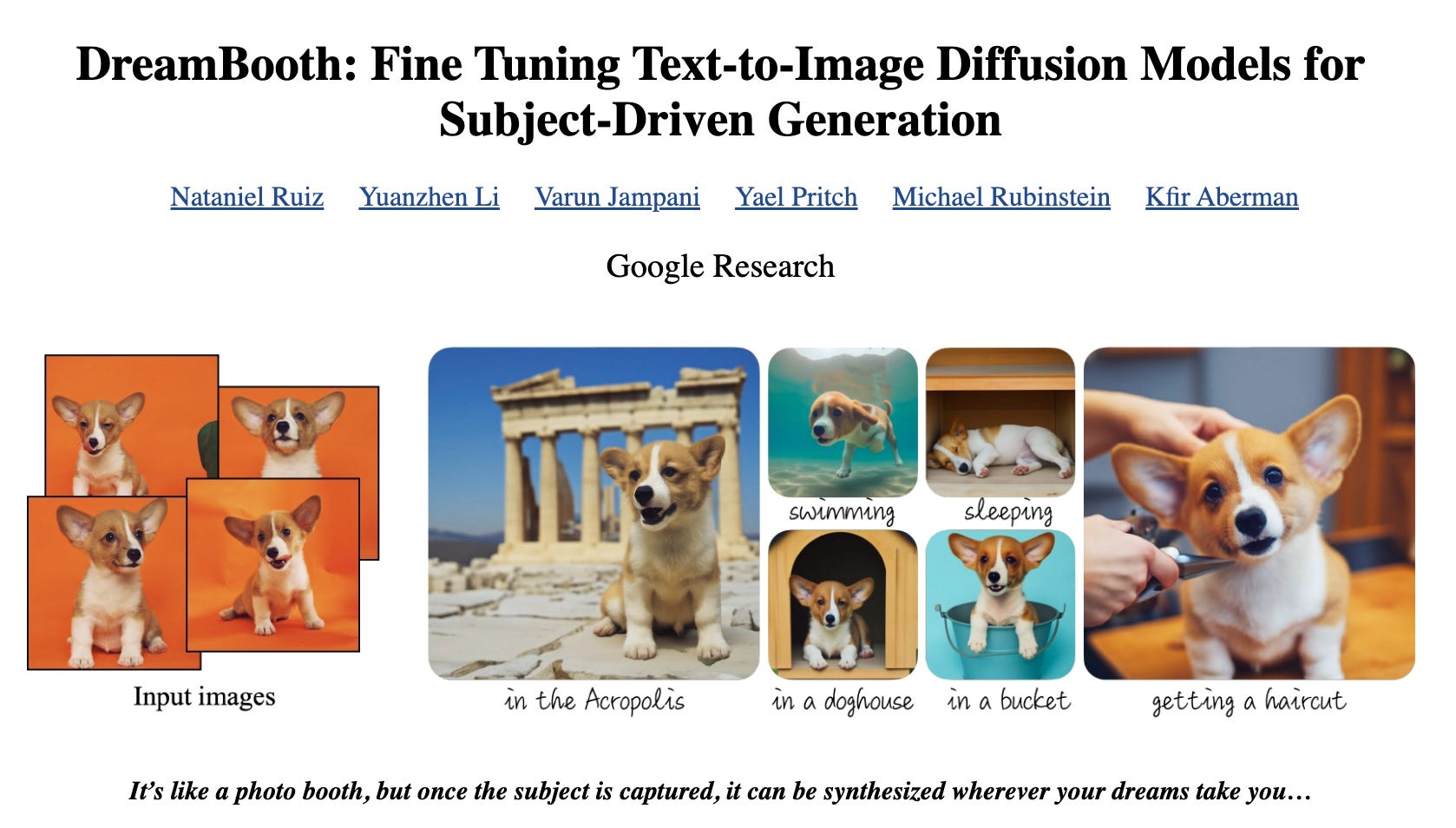
Dreambooth is an attractive target for optimization because it doesn’t just involve downloading a model and running it, it also requires you to run finetuning training on your sample images, but the original port required so much memory that it was infeasible for most people to run in on their machines.
Well, that, and also the Corridor Digital guys made it go viral on YouTube:
Timeline in tweet form:
For those counting along at home, that’s an open source port in 12 days and then a 79% reduction in system requirements in the subsequent 25.
Edit from the future: on Oct 8 this dropped again to 8GB.
Most of this optimization happened on GitHub between Xavier Xiao (a generative models and optimization PhD from Singapore working at AWS AI), and Shivam Shrirao (a Senior Computer Vision Engineer based in India), with help from Matteo Serva from Italy. Both were unaffiliated to the original Dreambooth team.
The low hanging fruit is gone, causing some to worry about diminishing returns, but some proofs of concept exist for getting Stable Diffusion itself down small enough to run on a phone (down from 10GB and 5GB before - consumer cards have 6-12GB and iDevices have unified memory).
This would probably be the holy grail of Open Source AI model optimization, because then image generation is effectively unconstrained by cloud economics and the profit motive.
Oct 2022 update: an open source impl is here: https://github.com/madebyollin/maple-diffusion
What Open Source Does that Researchers Don’t
While Stable Diffusion arrived the latest out of the 3 new text-to-image models, there were lots of community advances that have helped Stable Diffusion leap far ahead of the competing image-to-text models Midjourney and DALL-E in terms of mindshare and applications.
This serves as a useful generalizable roadmap for how open sourcing other forms of AI (music, biology, language models) might create new opportunities.

In rough order of increasing technical skill required:
Improving documentation
The original CompVis README wasn’t very beginner friendly
The community came together to create:
R*tard guides (4chan lingo, don’t ask) and regular guides
Sharing prompts
Prompt engineering is an acquired skill that is still turning up surprising results like this and this in GPT3 land 3 years after release; it means LLMs have a large latent space of abilities (not just results), that we are still only beginning to explore.
Every community now has ingrained ways of sharing prompts, and from then we can build up prompt galleries that significantly reduce the latency of promptfinding (from >30s to <300ms, 2 orders of magnitude!) and therefore learning curve of prompt engineering.
In this way the community is also figuring out known hard problems like how to generate realistic hands and the importance of negative prompting.
Creating new UIs and improving accessibility
Since Stable Diffusion is “just” a python script, people can build their own UIs to suit their own purposes, without being shackled to Stability AI’s own Dreambooth.
AUTOMATIC1111 has emerged as the leading community web UI, with a large range of features encoding the community discovered wisdom on SD usage
Since the ML community has a Windows bias, the open source community has implemented a ton of tricks to make it run on M1 Macs and maybe iPhones (as shown above).
SD UIs are usually standalone apps, but new delivery modes unlock more casual usage as part of existing workflows, inside Photoshop, Figma, GIMP, and even VR.
Creating new usecases by extending existing features in creative ways
I am unclear on who invented Inpainting and Outpainting techniques first (it was first hinted at in the DALL-E announcement, but really became widespread once open source UIs like this were created for it)
Remixing with other tooling/techniques is another source of ripe innovation
“Reverse prompt engineering” aka using image to prompt (with CLIP Interrogator)
Using txt2mask to augment inpainting
Multiple postprocessing steps including using Real-ESRGAN, TECOGAN, GFPGAN, VQGAN, and more (e.g. “hires fix” in automatic1111)
Creating a GRPC server (for communicating with Stability AI)
Preparing for new modalities like txt2music, music2img
Optimizing the core
(as discussed above) minimizing memory for Stable Diffusion and Dreambooth
Improving speed on Stable Diffusion by 50%
A fun but important tangent - most of this AI/ML stuff is written in Python, which is comically insecure as a distribution mechanism. This means the rise of “Open Source AI” will also come with increasing need for “Open Source AI Security”.
The Future of Open Source AI
This whole journey is reminiscent of how open source ate Software 1.0:
Version Control: From Bitkeeper to Git
Languages: From Java toolchain to Python, JavaScript, and Rust
IDEs: From [many decent IDEs] to VS Code taking >60% market share
Databases: From Oracle/IBM to Postgres/MySQL
Anders Hejlsberg, father of 5 languages from Turbo Pascal to TypeScript, famously said that no programming language will be successful in future without being open source. You can probably say the same for increasingly more of your stack.
It is tempting to conclude that the same sequence will happen in Software 2.0/3.0, but a few issues remain.
Issue 1: Economic Incentives
To the economics minded, the desire to release foundation models as open source is counterintuitive. Estimates for the cost of training GPT-3 run between $4.6 to $12 million, excluding staff costs and failed attempts (some startups now claim to get it down to 450k). Even Stable Diffusion’s impressive $600k cost (Emad has hinted the real number is much lower, but also said they spent 13x that (2m a100 hours) for experimentation) isn’t something to sneeze at or give away without a plan for making back the investment.
Taking OpenAI’s trajectory of monetizing through APIs, everyone understood what the AI Economy was shaping up to look like:

(arguable if Research > Infra, I made them about parity with each other, but just humor me here)
But Stability AI’s stated goals as a non-economic actor is both pressuring down the economic value of owning proprietary Foundational Model research, and expanding the total TAM of AI overall:

This is known as Stan Shih’s Smiling Curve model of industry value distribution, also discussed widely by Ben Thompson.
The big shoe to drop is how exactly Stability intends to finance itself - the $100m Series A bought some time, but the ecosystem won’t really stabilize until we really know how Stability intends to make money.
Response from Emad: “Business model is simple, scale and service like normal COSS but with some value add twists.”
Issue 2: Licensing
According to the most committed open source advocates, we’ve been using the word wrong in this entire essay. Strictly speaking, a project is only open source if it has one of the few dozen OSI approved licenses. Meanwhile, virtually none of the “open source AI” models or derivatives here have even bothered with a license, with sincere questions completely ignored:
https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/24
https://github.com/divamgupta/diffusionbee-stable-diffusion-ui/issues/5
Oct 2022 edit: InvokeAI is a notable exception, MIT licensed
Stable Diffusion itself was released with a new CreativeML Open RAIL-M license (RAIL stands for Responsible AI, created by an independent team), which governs the model weights (the thing you spend $600k to obtain) with certain sections compatible with OSI-approved licenses, but also with use case restrictions that are not. If you have ever dealt with legal departments and OSI people, you know that won’t fly and the opinions are mixed with no legal precedents to rely on.
StabilityAI has demonstrated seriousness that you are clear to use its products for commercial purposes, even publicly supporting Midjourney in using Stable Diffusion, but when the stakes are someday 1000x higher than this, the legal details start to matter.
Note from Carlos Muñoz Ferrandis, AI Counsel at HuggingFace: “Meta released OPT175 (LLM), BB3 (chatbot) and SEER (computer vision) with a license similar to a RAIL (including use-case restrictions) and for research purposes only (2 variants of the license depending on the model).”
OpenAI Whisper is the first instance I am aware of where model, weights, and code have all been released under a straightforward, “honest-to-god open source”, MIT license.
Correction from Emad: “All of the models we have backed except stable diffusion have been MIT released, eg OpenCLIP that took 1.2 million A100 hours.”
Time sensitive Note: if you’re serious about licenses, GitHub and the Open Source Institute are organizing discussions and a panel on Oct 18. You can also contact Luis Villa, general counsel of Tidelift.
Issue 3: What gets “Open Sourced”?
OSI approval aside, another wrinkle we have intentionally ignored until the very end of this essay is the actual nature of what “open sourcing” even means.
In a typical Software 1.0 context, “open source” would mean that the codebase is open source, but not necessarily details around the infrastructure setup nor the data accumulated/operated on by the code. In other words, open code does not mean open infra nor open data (though in practice at least some rudimentary guide on how to self-host is expected though not required).
With Software 2.0, the data collection becomes really important and starts to dominate the code (which is reduced to model architecture). Open datasets like ImageNet helped to train an entire generation of ML engineers, most notably powering Kaggle competitions and of course the ImageNet challenge itself (where AlexNet and CNNs pushed the entire field to converge to deep learning). With semi-homomorphic encryption, you could even occlude the data to create systems like Numerai - not strictly open, but open enough that a bored data scientist might play with the fake numbers and make some side cash. Still, the norm was very much not to offer open weights, as that is the most expensive thing to train.
With Software 3.0 and known scaling curves due to Chinchilla, LLMs and FMs become onetime, large investments undertaken on a single large corpus behalf of humanity.
The “Open Source AI” movement is tackling it a few different ways:
Open Datasets: For example, LAION-5B, and The Pile. These datasets have been modified for Waifus (sigh… dont ask), Japanese, Chinese, and Russian.
Open Models: Usually released by research papers - if enough detail is given, people can reimplement them in the wild as happened with GPT3 and Dreambooth
Open Weights: This is the new movement begun first by EleutherAI’s GPT-Neo and GPT-J (thanks Stella Biderman), then HuggingFace’s BigScience (that released BLOOM), then applied to text-to-image by Stability AI, and continued with OpenAI Whisper (the economics of which are discussed in Issue 1)
Open Interface: aka not just provided an API to call, as OpenAI had been doing with GPT3, but actually giving direct access to code so that users can modify and write their own CLIs, UIs and whatever else they wish.
Open Prompts: users (like Riley Goodside) and researchers (like Aran Komatsuzaki) sharing prompt technique breakthroughs that unlock latent abilities in the FM.

The exact order of these will vary based on substance of the advancement and contextual variation, but this feels right?
An Open Source AI Institute?
It is probably true that the Open Source Initiative is not set up to consider all these dimensions in “open source” AI, and the one of the most foundational initiatives for an open source AI culture is to create a credible standard with expectations, norms, and legal precedent. This is Hugging Face and Stability AI’s opportunity, but perhaps there have already been other initiatives doing so that I just havent come across yet.
Related Reads
Most of my notes are taken in public; watch this repo for live updates to my thinking
This was a very helpful overview, thank you. 100%, with open source, the doors get blown "open" in these early waves of experiments, widening the range of uses, but also bottlenecks to widen (UX, upskilling) and gaps (e.g. security) to seal, across all the worldbuilding unfolding among a growing legion of "no names".
EleutherAI's GPT-Neo and GPT-J models, code, and weights was released under an MIT license and GPT-NeoX-20B was released under an Apache 2.0 license. These are open source licenses and substantially predate Whisper and BLOOM, which you credit as being the first.