


Take the 2026 AI Engineering Survey and get >$2k in credits and AIE WF tickets!
This was recorded before Railway suffered a major GCP outage on May 19, despite being a multi-AZ, multi-zone mesh ring, with HA fiber interconnects between their Metal <> GCP <> AWS, because workload discoverability was unintentionally still tied to GCP. All has been resolved with a post-mortem.
Railway did not start as an AI infrastructure company.
It was founded in 2020 years before agents became the default way people thought about deploying software. Jake Cooper, formerly at Bloomberg and Uber, started Railway with a simple obsession: the activation energy to ship something to production should be near zero. Push code, get a URL, iterate. No Docker files, no Kubernetes manifests, no Ansible scripts stacked on Ansible scripts.
For years, this was a slow grind. Railway spent its first 18 months hand-acquiring its first 100 users with Jake personally greeting every Discord signup on a second monitor.
Today, Railway has raised $124m and is growing very fast. A 35-person team supports 3 million users, adding roughly 100,000 signups a week. Their bare metal data centers have a 3-month payback period vs. renting in the cloud, with 70% margins funding aggressive cloud bursting when needed. The servers they own have actually appreciated in value as RAM prices have climbed basically meaning the value of their hardware now exceeds the capital they've raised.
From rebuilding Railway’s network overlay over a weekend to moving the vast majority of workloads onto its own bare metal data centers, Jake Cooper is trying to build a new cloud for an agent-native world. In this episode, Railway’s founder and “conductor” joins swyx and Alessio to unpack why the next era of software infrastructure is not just “Heroku but newer,” what agents need that humans did not, and why the old deployment loop of Git, PRs, CI/CD, and static cloud resources may be heading for a rewrite.
We go deep on Railway’s infrastructure stack: own-metal data centers, three-month cloud payback periods, cloud bursting, data center debt, Railpack, Nixpacks, Temporal, feature flags, Central Station, content-addressable filesystems, agent-safe production forks, and why the CLI may become more important than the canvas in an agent world. Jake also shares the founder journey behind Railway, how the company survived losing $500K/month, why it now serves millions of users with only 35 people, and why he believes the pull request is dying.
We discuss:
How Railway went from a slow six-year grind to adding 100,000 users a week
How Railway thinks about agents as the next dominant software species
Why agents need version control, observability, compute, storage, and orchestration at 1000x scale
The economics of Railway’s own-metal data centers and three-month payback
How Railway uses cloud bursting while scaling its own infrastructure
Why data center debt can be a better tool than venture debt for infra startups
Central Station, Railway’s internal system for clustering customer feedback and incidents
Why responsible disclosure and over-communication matter for platforms
Why feature flags, progressive rollouts, and shadow traffic are essential for agents
Temporal’s strengths, pain points, and why workflows matter for agents
Railpack, Nixpacks, Nix, and lazy-loaded content-addressable filesystems
Why “cattle, not pets” may change if you can clone the pets
Why Railway is building a new cloud from scratch instead of copying hyperscalers
The solo founder path, focus, writing, and how Jake thinks about company building
Railway:
Website: https://railway.com/
Jake Cooper:
Timestamps
00:00:00 Introduction: What Is Railway?
00:02:07 Jake’s Path to Railway
00:06:13 Railway’s Six-Year Growth Story
00:08:52 Rebuilding the Business After the Free Tier
00:11:17 Agents as the Next Software Platform
00:13:29 Railway’s Infrastructure Philosophy
00:15:42 Bare Metal, Cloud Economics, and the Compute Crunch
00:17:22 Cloud Bursting and Five-Cloud Networking
00:20:20 Data Center Debt and Infra Financing
00:23:31 Data Centers in Space
00:25:24 What Agents Need From Infrastructure
00:28:24 CLIs, Canvas, and Agent-Native UX
00:35:15 Central Station, Incidents, and Responsible Disclosure
00:40:30 Safe Rollouts, SRE Agents, and Production Forks
00:45:00 AI SRE, Specs, Code, and Tests
00:48:24 Self-Replicating Infrastructure and the New Serverless
00:53:18 Heroku, Temporal, and Workflow Engines
01:04:07 Railpack, Nixpacks, and Lazy-Loaded Filesystems
01:06:01 Coding Agents, Token Spend, and Roadmap Acceleration
01:10:56 The Pull Request Is Dying
01:12:28 Feature Flags and the Agent-Era SDLC
01:16:15 Cattle, Pets, and Cloning Machines
01:19:29 Solo Founder Lessons
01:24:12 Focus, GPUs, and Building a New Cloud
01:28:20 Closing Thoughts
Transcript
Alessio [00:00:00]: Hey, everyone. Welcome to the Latent Space Podcast. This is Alessio, founder of Kernel Labs, and I’m joined by Swyx, editor of Latent Space.
Swyx [00:00:10]: Hey, hey, hey. Today we’re in the studio with Jake Cooper of Railway.
Alessio [00:00:14]: Conductor of Railway.
Swyx [00:00:15]: Conductor at Railway. Yeah.
Alessio [00:00:16]: Choo-choo.
Swyx [00:00:17]: Do you actually have that anywhere, like on your business card?
Jake [00:00:20]: We call some of our volunteer moderators conductors. I don’t have a business card. We’re not that big yet. At some point I will. I got handed a nice business card from the Supermicro folks, and I was like, “Damn, this is pretty official.”
Swyx [00:00:30]: Business cards are coming back.
Jake [00:00:32]: They’re cool. They’re hip. The conductor thing is good. We’re trying to figure out what we want to call each other internally. Some people think it’s super cringe and say, “You don’t need a name for people internally.” Some people want to call each other something. We still don’t have a really good one.
Jake [00:00:55]: We’ve got New Railcrews, Trainiacs. Nothing has stuck yet.
Swyx [00:01:00]: I like Trainiac. Trainiac sounds good. Railwayians. For those who don’t know, what is Railway? Let’s give people a crisp definition up front.
Jake [00:01:09]: Railway is the easiest way to ship anything. You go to the canvas, or you talk with Claude, and you say, “Deploy a Postgres instance, deploy my GitHub repository, run this code,” and you’re off to the races.
Swyx [00:01:22]: You’ve got a nice animation on the landing page.
Jake [00:01:24]: Thank you. None of my work, by the way. They don’t let me touch the design stuff anymore.
Jake [00:01:25]: We want to make it trivially easy not just to deploy things, but to evolve applications over time. Most tooling right now stacks entropy on top of entropy: Docker, Kubernetes, Ansible scripts, and all these other things. If we can version all of your software and keep track of all the changes, then we can make it trivial to clone environments, fork into a parallel universe, get copies of production data, get copies of any services, make changes, validate them, and collapse them back in without reproducing everything across a staging environment.
The Railway Origin Story: From Uber Systems to a New Cloud
Swyx [00:02:07]: I was looking at your background: Bloomberg, Uber. Nothing immediately stands out as, “This guy is going to found the next great platform as a service.” What prepared you for Railway?
Jake [00:02:21]: It was curiosity to keep going deeper. I started out on front-end stuff, working on Wolfram Mathematica and porting it over. Then I briefly moved to Bloomberg, then toward Uber and distributed systems, taking the Jump Bikes systems and moving them to a distributed system built on top of Cadence, the pre-Temporal Temporal.
Swyx [00:02:44]: Which, by the way, I’m happy to talk about, pros and cons.
Jake [00:02:48]: Totally.
Swyx [00:02:51]: But let’s do the Railway story.
Jake [00:02:52]: It has been a continual step of wanting an experience. Whether it’s walking up to a bike, unlocking it, and having it work frictionlessly, or something else, the depth required to make that happen follows from the experience. A lot of the work I do, and a lot of the team does, is in service of that experience. We fundamentally don’t care how deep we have to go. We will swim to the bottom of the swimming pool to get the experience.
Jake [00:03:17]: I don’t have a physics PhD. I did an EECS degree. It has always been about figuring out the next step: how do we get there? That’s what led to starting Railway for that experience and then moving all the way to bare metal data centers. I was adding patches to the kernel this week to get the experience there because I can see how much better it can be.
Swyx [00:03:49]: Other patches to the Linux kernel this week?
Jake [00:03:51]: Yeah. Not upstream. Our fork.
Swyx [00:03:52]: That’s a flex. Railpack? No, this is different. This is the OS on top of Railpack?
Jake [00:03:57]: No, this is an actual kernel patch. It’s always literally: what do we have to do to get that experience? Then figure it out. Anything is figureoutable.
Swyx [00:04:10]: Would you send the patch upstream, or does it not fit other use cases?
Jake [00:04:13]: Maybe. We have to work out the experience internally. It has to do with the storage layer we’re building for some of the agentic stuff. Maybe it’ll be useful upstream, but it’s deeply useful for us internally.
Open Source, Forks, and Non-Deterministic Versioning
Swyx [00:04:29]: You mentioned open source before. How do you think about starting from open source, and then coding agents letting you do a lot more from forks of it?
Jake [00:04:38]: GitHub’s original sin is that it’s almost a series of broken pointers. You have this thing, then you clone it, and now you’ve lost the whole upstream. How do we make it trivial for people to modify really small pieces of it?
Jake [00:04:51]: We think of Git in a discrete sense: I’ve either made a change and merged upstream, or I haven’t. What would it look like if it were percentage-based, a little more non-deterministic, or a stream of changes that users traverse as a percentage rolled out in general and then rolled all the way up?
Jake [00:05:13]: We have the open-source kickback program and let you deploy templates because we want to make it trivial for people to version these shards over time. It solves a large problem around authentication, authorization, and security. NPM has a way to define, “Don’t take any new packages.” The ideal end state is that you roll out progressively to users with the minimum impact zone and continue rolling up. JPMorgan should probably be the last one on the patch line, for all our sakes, because our money and livelihoods are there.
Jake [00:05:53]: It’s okay if Johnny Vibe Coder gets a broken patch because there’s so much entropy in the system that the rubber has to meet the road at some point. You have to test at varying levels.
The Long Grind: First Users, Free Tier, and Making the Business Work
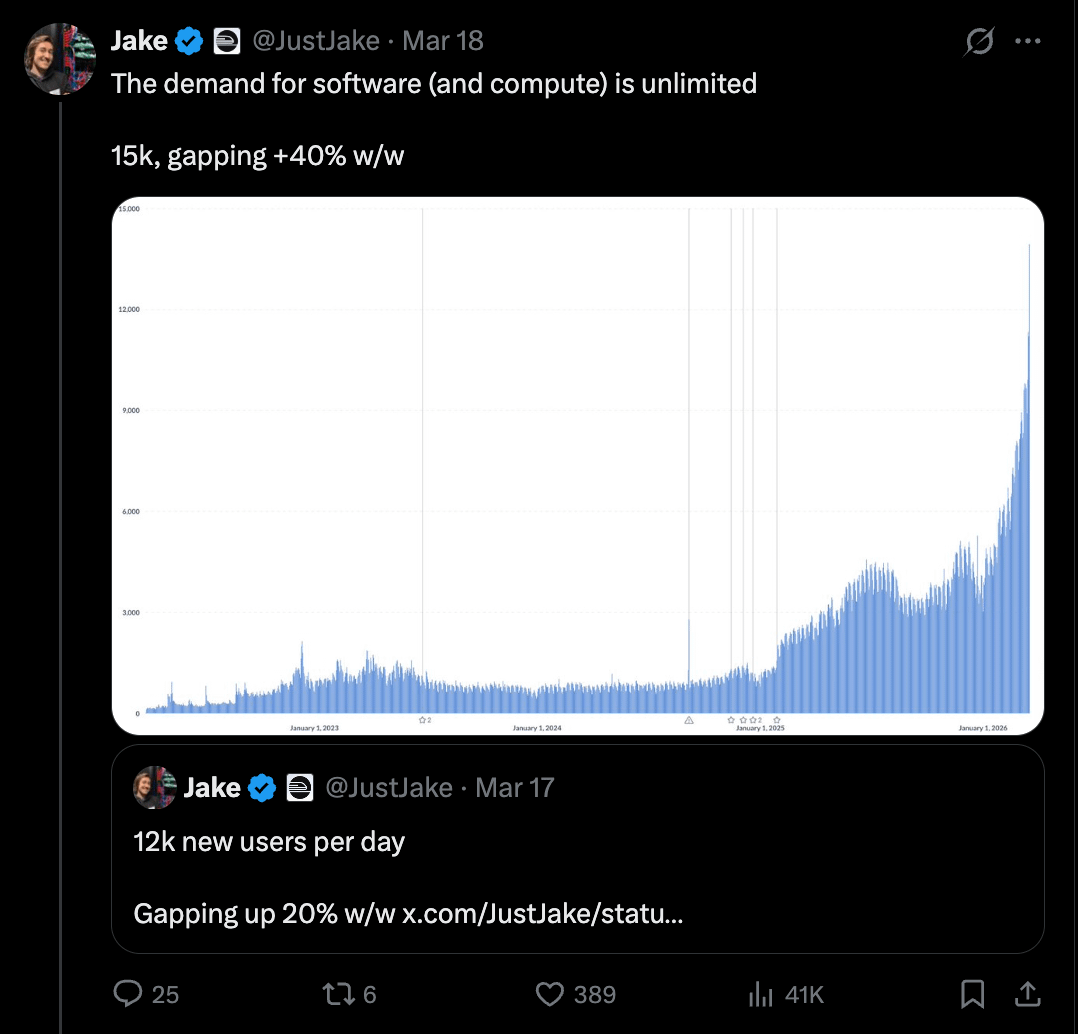
Swyx [00:06:13]: I wanted to pull up this glorious chart, which is your usage or number of daily signups?
Jake [00:06:22]: Daily signups, I think.
Swyx [00:06:24]: You started six years ago. It was a slow grind, and now you’re on a rocket ship. You say, “Don’t doubt your fight and don’t quit.” Maybe pick out certain points that were key inflections for the company.
Jake [00:06:40]: At the start, it’s about getting your first 100 users, hell or high water. We had a website and a support link. The support link was the Discord channel. I had notifications on with two monitors: the monitor I was working on and the other monitor with Discord. If anybody came in, I was immediately like, “Hey, how’s it going?” It was rare, so getting those first 100 users to come back was the start.
Jake [00:07:14]: Then you build a consultancy factory because users want all these things. You have to go back to the board and ask, “What is the actual product offering I want to build on top of this?”
Jake [00:07:28]: VCs want charts that always go up and to the right, but in reality you don’t necessarily want charts that look like that. For us, there have been periods of expansion where we add features to test use cases, and periods of compaction where we ask, “If the experience we have is good, how do we make it significantly better?” Maybe we strip out features that don’t fit our ICP anymore.
Jake [00:07:57]: The boom from 2022 to 2023 came from the free tier. Everybody under the sun was using it.
Swyx [00:08:09]: A lot of Reddit bots and Discord bots.
Jake [00:08:12]: And crypto miners. When you build an open product on the internet where anybody can sign up, the internet is a horrible place with so many things. You go through periods of asking, “How do I reach as many people as possible?” Then, “How do I fit the exact use case for the people who really matter and are really excited about this specific thing?”
Jake [00:08:39]: Then there was a two-year period of making the actual business work. During the free-tier era, we were losing about half a million dollars a month.
Swyx [00:08:59]: On a $20 million bank account.
Jake [00:09:02]: On a $20 million bank account with maybe $50,000 a month in revenue. That’s a horrible business. I don’t know how anybody invested. But you have to go through it and say, “We have an experience people love, but the business has to work.”
Jake [00:09:17]: There are two schools of thought. You can run the horrible business all the way up with bad margins, or you can go back and make it work. We’ve always wanted a super lean team. We’re 35 people right now. It’s very small.
Swyx [00:09:36]: Supporting three million already?
Jake [00:09:38]: Yeah. We’re adding 100,000 users a week right now, so it’s growing fast. We don’t want to add headcount for the sake of headcount or throw bodies at problems. We want to build systems. It’s hard to build systems during expansion because you’re adding things to the system because people are asking for them or things are breaking.
Jake [00:10:00]: We had to cut off the free users for a little while, rebuild the business, and make sure it worked. We want to reach as many people as possible because software is important. It’s become difficult to create things in the physical world, so it’s important to make it easy for people to build in the virtual world and have access to creation. But there are legs to that journey.
Jake [00:10:30]: You can see divots in the charts. If you follow between 2025 and 2026, it’s either summer or winter. People go on holiday with family.
Swyx [00:10:50]: It affects that much?
Jake [00:10:51]: Yeah. It’s kind of B2C and kind of B2B. People are shipping constantly, then they stop. Our activation curve now shows more people activating on weekdays because we have more business users, so it smooths out over time.
Agents as the New Interface to Deployment
Swyx [00:11:17]: Was there a point where you started prioritizing AI development or agent development?
Jake [00:11:24]: We’ve prioritized agentic as a top-of-funnel thing. Over the last six months, we’ve deeply prioritized agentic as a mechanism to build and deploy things because we believe the curve is so steep and that is how people will build and deploy software.
Jake [00:11:42]: It almost fundamentally doesn’t matter whether this is dot-com or not because we’re all on the internet anyway. If agents are going to deploy a bunch of things and we hit an inference wall at some point, we’ll fix those problems. The dominant species over the next 10 years is that we’ve moved from assembly to C to C++ to JavaScript to words. You’re going to need to close that loop.
Swyx [00:12:13]: When you say this is dot-com, did you mean buying the domain, or the general case?
Jake [00:12:17]: I mean the dot-com era, when companies had a huge run-up because people understood the internet was important. Then they hit bottlenecks, fundamental laws of physics, math didn’t work, and everybody came back down to earth. But it didn’t matter because the internet became so impactful. If you operate on a long enough time horizon, you should build these things anyway because you can see where it’s going.
Jake [00:12:45]: That’s where I think a lot of agent stuff is. You get to a point where you’re running thousands of agents in parallel. What is the inference cost? What is the compute cost? How do you make that efficient? How do you coordinate all this? We have issues coordinating humans; we don’t even have good tooling for that. Now we have to figure out how to get agents to coordinate, safely version changes, and know when to raise their hand for someone to intervene. Otherwise it becomes an interrupt factory.
Railway’s Infrastructure Thesis: Network, Compute, Storage, and Metal
Swyx [00:13:19]: Let’s go right into the technical side. What are the core infrastructure or architectural beliefs of Railway that allow you to do what you do?
Jake [00:13:29]: The primitives matter a lot for us. We need network, compute, storage, and orchestration around it. You need control over a lot of those things. We’ve talked a lot about how we don’t really use Kubernetes because we want higher-order control to place workloads in very specific places.
Jake [00:13:48]: The reason is that you have to be very efficient with agents: memory reuse and all these other things, or you’re going to massively blow up your cost structure. Being able to rack and stack your own servers and build your own metal unlocks performance and cost. Experiences where you’re running 1,000 agents in parallel are not massively cost prohibitive.
Jake [00:14:13]: Token use and compute use are blowing up. Over time, those things have to get a lot more efficient. You can get a lot of margin to make those experiences solid by building your own metal. That’s all in service of offering a differentiated experience to as many people as humanly possible.
Swyx [00:14:51]: You have a data center in Singapore.
Jake [00:14:53]: Yeah. We have two in every other region now. In Singapore, we’re adding a second one in Q3.
Swyx [00:14:58]: What’s it like? I’ve never built a data center. Do you go to Equinix and say, “I want some slots?”
Jake [00:15:05]: Yeah. Equinix. You basically go and say, “I want power and I want a cage.” They say, “Great, here’s what it’s going to be.” You rent the cage for a period of time, fill it with racks and servers, and hook up internet to it. That’s all the pieces.
Swyx [00:15:36]: Then you handle everything else.
Jake [00:15:37]: You handle everything else.
Swyx [00:15:39]: What’s the math versus clouds doing it for you?
Jake [00:15:43]: If we rented in the cloud, our payback period when we go to metal is about three months.
Swyx [00:15:50]: Which is crazy.
Jake [00:15:51]: It’s nuts. That’s four years of depreciated hardware. You’re going to see a lot of this compute crunch because hyperscalers are buying up a lot of stuff. We’re working directly with OEMs, resellers, and people building these machines: Supermicro, Dell, and others.
Jake [00:16:11]: Upstream, there’s a bunch of supply pressure. When we raised our last round, between deploying capital for servers and now, the amount of money we’ve raised is less than the amount of money we have in the bank plus the value of the servers because the servers have appreciated as RAM has gone up. It’s nuts how valuable hardware has become.
Jake [00:16:50]: If you look at hyperscalers, they deployed around $80 billion of capital expenditures this year, and next year will be more. That’s a massive infrastructure build-out. You look at that and think it’s crazy that they’re spending way more than the Manhattan Project. But if every person is going to run dozens or hundreds of agents in parallel, you have no conceptual idea how much compute is required to make that experience happen, even if you’re deeply efficient and sharing resources. And that doesn’t even count inference.
Swyx [00:17:22]: How do you plan the build-out? The growth chart is so vertical. Are you usually at 100% utilization as soon as racks are live? How far ahead are you planning?
Jake [00:17:33]: We still maintain cloud presence for bursting. We work with AWS, GCP, and a few other clouds. We can rent, and then the moment we get space or power, we compact those workloads off the cloud. We started on the clouds, then built a system to migrate to our own metal. There’s nothing that says you can’t continually do that again, and that’s exactly what we do. We never want to be compute constrained.
Jake [00:18:09]: At the start of the year, we actually became compute constrained because one upstream provider wasn’t able to give us quota at the rate we needed, and the hardware was slower. I spent a weekend rebuilding our entire network overlay so we could straddle five clouds: Oracle, AWS, ourselves, GCP, and one other one. We can do more than that now.
Jake [00:18:38]: We got into a spot where we were trying to pack instances tight because we couldn’t get enough compute. That led to a few reliability issues, which are now past us. I made a tweet pointing out that it’s becoming harder and harder to acquire compute at the rate these models need to acquire compute. We got bit by it.
Swyx [00:19:15]: How do you think about pricing knowing you might not have your own metal available at all times? Are you pricing assuming you need extra margin if you end up going into the cloud?
Jake [00:19:26]: Because we’ve built out our metal data centers, our margins on metal are around 70%. We can deeply subsidize the cloud business if we want to scale at a reasonable rate. We have a few levers: metal, which makes the margins; cloud burst; debt to buy servers; and venture capital. It’s an interesting operational problem: how much cash do we have, how much should we raise, how quickly can we deploy it, and can we scale revenue as quickly as we scale compute?
Jake [00:20:05]: If we continue making it trivially easy for people to build and deploy, then the faster we close that loop and the more operationally excellent we are with capital, the faster the business can scale. It’s almost a straight linear deployment rate.
Financing Infrastructure: Hardware Debt, VC, and Operational Leverage
Swyx [00:20:20]: I think infra startups raising debt is a tool people don’t utilize enough or know enough about. What can you tell us about that? Is it secured against your CPUs?
Jake [00:20:32]: It’s secured against our hardware.
Swyx [00:20:37]: What rates do you get? Who are the lenders?
Jake [00:20:39]: We pay prime plus a spread, and we can refinance any of the debt as rates go down. The terms are pretty good. The unfortunate thing is that Twitter has no nuance, so people say, “Venture debt bad.” But as with all things, there are specific tools and areas where you can be deliberate instead of using one tool as a hammer. Venture capital is not the hammer for everything. You have to explore and figure out what works.
Swyx [00:21:12]: VC is usually the most expensive financing you can get.
Jake [00:21:15]: Yeah. I also think people think about VC incorrectly from a capital-raising perspective. Most people think, “How do I raise as much money as possible from whoever is probably the best I can get at that time?” That’s close to right, but what we’ve tried to do is figure out what unfair advantage we can buy with that equity.
Jake [00:21:34]: It’s the most expensive equity you’re going to give away at that point in time, assuming the company keeps getting better. How do you use it to work with someone stellar who complements you? In the seed stage, I had never started a company. Ray Tonsing had good advice, and I could text him all the time. He was really fast. Awesome.
Jake [00:22:01]: Then with John and Erica at Unusual, they said, “You roughly know what you’re doing building a product. We’ll mostly leave you alone and be available for advice.” Amazing. Then we got to Series A and the business was an operational tire fire because we didn’t know how to scale a business. Work with Erica, and Jordan is over at Redpoint, so bonus.
Jake [00:22:28]: Now we’ve raised from TQ and FPV as we’re moving into enterprises. Every step of the way, we’ve asked: who can we partner with at this specific time to unlock the next section of the journey? I don’t know enterprise sales. As an engineer, I can eyeball what features we might need, and we have wonderful people internally who can help. But you want boardroom dynamics where everyone is aligned and asking, “How do we win this?” instead of bickering about strategy.
Data Centers in Space and the Physics of Compute
Swyx [00:23:31]: You had a tweet about data centers in space. Why no data centers in space?
Jake [00:23:37]: It’s not “no data centers in space.” My hot take is that I think it is solvable. I’ve just never seen anybody solve it.
Swyx [00:23:49]: You said, “How are you going to dissipate that much heat in a vacuum?” You’re making a physics claim.
Jake [00:23:55]: I haven’t seen anybody prove how you’re going to dissipate that much heat in a vacuum. It doesn’t mean it’s not possible. It just means nobody has brought it up yet.
Swyx [00:24:05]: Astrophage.
Jake [00:24:06]: I don’t know what that is.
Swyx [00:24:07]: The Martian thing. Okay, you’re very logical.
Jake [00:24:09]: It could work. A lot of people are putting the cart before the horse. They say, “We’re going to put data centers in space.” Okay, but how? “We have time to figure it out.” It’s like in The Martian where they ask how they’re going to intercept something and say, “We’ll figure it out.”
Swyx [00:24:36]: Making a bet on human invention is weird because you blind trust that it can be solved. But with physics, there are first-principles bounds you can put on it. Maybe not. Maybe you’re asking to travel time or break a fundamental thermodynamic law.
Jake [00:24:57]: I don’t know how VCs do this either. How do you know what’s not possible and a grift versus what’s possible but sounds completely insane? “We’re going to put data centers in space.” Coin flip as to which it is, and I guess you’ll know in 10 years. That’s one cycle.
What Agents Need: Versioning, Observability, and 1,000x Scale
Swyx [00:25:23]: Moving back to agents. The branching, fast spin-up, and orchestration you do feels like pre-work that happened to be exactly what agents want. What do agents want differently than humans?
Jake [00:25:37]: They want the ability to version things. It’s not that different; it materializes slightly differently. Agents want a way to test changes incrementally. Engineers have feature flags. Is there a reason agents can’t use feature flags? I don’t think so.
Jake [00:25:54]: They want version control. Can we use Git or not Git? That one is up in the air. I think something outside Git will emerge for how we version these things over time. They need observability. You need to query what happened, when it happened, which steps failed, traces, logs, metrics, and all the rest. They need network, compute, and storage. They need to write files, save files, iterate on files, and snapshot file systems.
Jake [00:26:25]: A lot of what humans needed is in line with what agents need. Branching and forking are not different; we’re just moving 1,000 times quicker. It can look like you need something massively different, but what you need is something massively better than what existed. You need orchestration massively better than Kubernetes. You need networking probably better than Envoy. It goes all the way down the stack.
Jake [00:26:55]: If the workload profile doesn’t change so much as it gets massively compressed because you need thousands of these things, what assumptions change? etcd is going to melt. You need to replace it with something. You can go all the way down the stack and say, “That part has to change, that part has to change, and that part has to change.”
Jake [00:27:19]: The interesting thing about the super-exponential curve is that you have to build systems where you can rip out those parts at any time because a new bottleneck might emerge. You get good at parallel agents, and a different part of the system breaks. So it’s similar to what humans needed, but at 1,000x scale.
Jake [00:27:55]: How do you do code review in the age of agents?
Swyx [00:28:00]: You throw more agents at it.
Jake [00:28:01]: You don’t. But then who reviews for CVEs and all these other things?
Swyx [00:28:07]: More agents.
Jake [00:28:08]: And that’s how we hit the inference wall. You can continually throw agents at the problem, but I think there’s a limit to the number of agents you can throw at a problem.
CLI, Agent Handles, and Closing the Loop
Swyx [00:28:24]: You already had a CLI before it was cool. How is the shape of what you’re exposing changing, if at all?
Jake [00:28:28]: CLIs have always been cool. The CLI changes because we think about how to give Claude, Codex, ChatGPT, or any model a handhold.
Jake [00:28:50]: A CLI is a single command: deploy, get logs, and so on. Things that were prohibitively annoying to humans are not annoying to agents. They’re nice. If I handed you a CLI with 40 arguments and 600 flags, you’d think, “I’m never going to use all of this.” But if you hand it to an agent, it says, “This is excellent. I have so many handles to work with.”
Jake [00:29:24]: If you’re going to expose things to agents that way, you want as many handles as possible where they can get information, query dynamic information, and close the loop quickly. Most problems right now are about how to close the loop as quickly as possible. Where does the agent get stuck, and how can you remove that?
Jake [00:29:49]: Telemetry is important. If you can tell where the agent gets stuck from the CLI and say, “12% of people deviate from the happy path because of this, and now I add this argument and drive it down to 2%,” you massively increase the rate of loop closure.
Jake [00:30:03]: That’s how we think about not just the CLI, but every point in the dashboard. It’s a user journey: I hear about Railway. I get something deployed. I get my first green build or aha moment. I see an endpoint, logs, whatever. Then I iterate. The iteration loop is indefinite. The user wants to deploy a new thing, a Postgres instance, change code, and keep iterating.
Jake [00:30:36]: If you focus on the iteration loops and what’s blocking them from closing quickly, one thing we say internally is: you never want to be waiting on compute anymore. You always want to be waiting on intelligence. If you’re waiting on compute, there’s a bottleneck that needs to be destroyed because eventually that bottleneck becomes so large that another workflow emerges to change it.
Jake [00:31:04]: We’ve built a product where you push code, build it, and so on. But I fundamentally believe the push-pull loop is going away. We’ll get to a point where you make a small change in production, that change is versioned across your infrastructure, you’re working alongside copy-on-write versions of your database and infrastructure, and then you merge it in and it’s instantaneously live. That’s the holy grail of loops. The push-pull-rebuild thing is a point of friction that we’re removing entirely.
Canvas as Output: Dashboards, Context Anchors, and Hyperstructures
Swyx [00:31:43]: It’s incredibly fast. If anyone hasn’t tried it, that fast feedback is great. My hot take is that Railway was famous for its canvas, which visualizes your infrastructure and lets you manipulate it visually. But that was for humans. For the next phase of growth, Railway CLI is more important than canvas.
Jake [00:32:05]: The canvas is funny because it’s a mechanism to show changes over time. You’re right that previously we used it a lot as an input. Moving forward, its goal is more like an output. You would go to the canvas, make changes, see them, and watch your infrastructure evolve. Now agents have access to the CLI and can make those changes. So the canvas becomes an output: what information does the human need at this moment to make suitable decisions about control requests? Do I approve this or not?
Jake [00:32:57]: It also has to be an anchor for your context, a port in the storm. Think of it like layers in a file system. You start with a project, then drill down into services, then into a function or code, because you want to represent the entire thing not just in your head, but in the canvas. Other people can share that representation, think on the same wavelength, and move quickly.
Jake [00:33:33]: A lot of organizations get in trouble as they scale because all the context lives in someone’s head. “How does this microservice work?” “I have no idea; go ask this person.” Then you have whole categories of products built around context discovery. A lot of that melts away if you have a solid hierarchy and can infinitely nest services, code, context, and everything else all the way down. That’s what lets you build these structures over time.
Jake [00:34:18]: It’s also what lets us build what I’ve called hyperstructures: things that are way bigger. You look at the Golden Gate Bridge and ask, “How did we build that?” There’s a meme that we lost the technology. To some extent, yes, because the coordination that built those things evolved and changed. We lost some of the art of building structure as we jammed everything into Slack.
Swyx [00:34:52]: But you jam everything in Discord.
Jake [00:34:53]: Same point. It doesn’t matter. It’s message passing and interrupts, message passing and interrupts.
Swyx [00:35:00]: So you’re arguing there should be something better and more structured than Slack?
Jake [00:35:04]: Yeah. For sure. I think Slack is awful, and Discord is awful too.
Central Station: Context Routing, Support, and Incident Clusters
Swyx [00:35:09]: This is the equivalent of my mom test. What have you done that has your solution to this?
Jake [00:35:15]: Internally, we’ve built a tool called Central Station that aggregates all the context from our users. Every piece of feedback, every customer support item, everything gets aggregated into clusters. If an incident is brewing, we can determine how many users are affected and break off a discussion based on that.
Jake [00:35:40]: That is more helpful than long-running channels where you’re trying to decide which channel to put something in. If you can dynamically aggregate information and dynamically route it to the right person based on context, it works better. We know internally that these four people are close to networking. If we see a networking thing, we can drill it down to those four people. If it’s with this part, we can look at the commits. This is no longer a manual process internally.
Jake [00:36:13]: If you go to station or help.railway.com, that’s why we built it. We wanted to scale with a massive amount of leverage by aggregating feedback.
Swyx [00:36:27]: This is built in-house?
Jake [00:36:28]: Yep.
Swyx [00:36:29]: I remember helping out on this one with Angelo in 2023. You scale a lot with a very small team.
Jake [00:36:38]: Yeah. We’re about 10 times bigger now.
Swyx [00:36:40]: You have your full developer code here? Very cool.
Jake [00:36:44]: If you go to railway.com/stats, we expose this as a pub-sub-able thing. It’s all real-time metrics. There’s a way to get it as JSON somewhere if you care.
Jake [00:37:01]: We’re big on trying to build everything in public and talk about what we’re working on. We’ve had issues in the past, and we’ll say, “Here’s how we’re fixing these things.” We’ve gotten compliments and flak for incident reports. We’re always trying to make them better and talk with people.
Incidents, Disclosure, and Progressive Rollouts
Swyx [00:37:20]: You had a big one recently. I liked that it was scoped to 3,000. You presumably used Central Station. Talk through what happened and how you address it internally as a team.
Jake [00:37:38]: Internally, this one really sucked. It had to do with an upstream provider that didn’t do the behavior it said it documented, which is unfortunate given they wrote the RFC for how the behavior should work. We rolled those things out, and Central Station caught it initially when a couple users said caches weren’t invalidating. We turned it off immediately.
Jake [00:38:03]: When you roll out to a large user base of three million people, you get a lot of disparate behaviors. We tested in staging and had tests, but we hit an edge case. We’ve hardened those systems, and now we can make that better. But it was a tough one.
Swyx [00:38:39]: I always wonder how private disclosure is supposed to work if people find an issue. Are they supposed to contact you first? When you run a platform, these things will happen. What channels should people pursue to quietly resolve it before it becomes a bigger incident?
Jake [00:38:59]: There’s responsible disclosure. We err on the side of over-disclosing and letting you know something is wrong versus having your provider gaslight you. We’ve erred on sharing those things more publicly, even if they impact a small subset of users. That’s a decision we’ve made internally. We have four values. One is honor. The honorable thing is to notify people to the widest degree at which they may have been affected or there was an issue, and then confront it head-on: why did it happen, what can we do better?
Swyx [00:39:45]: Not the whole user base. That’s because of incremental rollouts and other things?
Jake [00:39:50]: Yeah. Progressive rollouts.
Swyx [00:39:54]: That should be the norm at all large platforms.
Jake [00:39:58]: It should. A variety of companies do this. There’s the quote that Meta runs 10,000 different versions of Meta. To our earlier point about agents, they need the same thing. They need shadow traffic and all these other things. We’ve built so much ceremony around production being sacred that we need to make it trivially easy to test different behaviors in a safe environment. Then you can make mistakes in a safe environment.
Safe AI SRE: Customer Agents, Forked Environments, and Production Parity
Alessio [00:40:30]: Do you see a world where these things get automatically caught, not necessarily by your agent, but by your customer’s agent? The cache invalidation issue seems easy to check if you know to look for it.
Jake [00:40:44]: It’s hard because to determine it, we almost need to hook into your observability infrastructure. That’s why we have the template loop on the platform: so you can roll things out progressively. You can roll out to Johnny Vibe Coder initially, or push a shard that someone consumes at their own leisure. Or you can roll it out over weeks: 0.1% of people, 1% of people, early adopters, then all the way up. That’s the non-deterministic version control we talked about earlier.
Jake [00:41:30]: I believe that’s where most things should go, because most companies end up building staged rollout systems in-house. It’s the same thing built again and again at every company. There’s a massive opportunity to consolidate developer debt.
Alessio [00:41:45]: You should have a free tier. Model providers give free tokens if you let them use the data. You could give free compute if someone is the number-one shard that goes out and lets you plug into their observability.
Jake [00:41:55]: We do that. That’s why we talked about the impact on 3,000 people. We start with lower-impact people. Larger companies on the platform are last to receive those rollouts so they have a version of the platform that’s deeply stable.
Alessio [00:42:16]: I have three services, so I’m sure I get the first rollout. You can nuke my thing at any time. There are all these SRE agent companies. Observability people also want agents that fix upstream problems. You have your own agent in the canvas now. How do you see that playing out?
Jake [00:42:39]: It’s the stacking entropy problem. If you don’t have primitives to make iteration in production safe, it becomes difficult. If you’re an observability provider saying, “Here’s the fix to this error,” assume 80% are good and make sense. But in the last 20% long tail of complex issues, if you let somebody stamp it, you create an opportunity for an incident.
Jake [00:43:08]: That’s why forked environments are important. People have staging, but it always drifts from production. You need primitives, workflows, and experience built first-party on the platform so you can fork any service at any point in time.
Jake [00:43:33]: I think of the canvas as a sheet of transparency paper. The agent is a little guy you push up into the canvas. It should say, “I need to copy that service and that service so I can test these two things.” It gets a read-only copy of production. Anything that’s PII gets marked as a transform when we clone the database, create a copy-on-write version, or read from it. Then the agent makes changes and asks, “Does this actually work?” as close to production as possible.
Jake [00:44:22]: That’s how close you have to be, or you get massive drift. The system becomes unstable. You see this with massive systems built on Docker for local, Kubernetes for production, and a specific thing for something else. That complexity slows developers and becomes unstable at scale, making it hard to iterate. We want to compress that way down and say, “As close to prod as possible is where we want to be.”
From AISRE Skeptic to Agent Believer
Swyx [00:45:00]: I was texting Erica for questions, and she says you were originally not a believer in AISRE. Have you come around on it?
Jake [00:45:10]: I flipped, but I’m still not a believer in AISRE if you don’t have the primitives to make it safe. If you unleash AISRE on production infrastructure without safe primitives for copying volumes and making sure things are fine, it’s going to nuke your production database. It’s not a matter of if, but when. I’m a big believer in making those loops safe.
Jake [00:45:33]: I was a deep AI skeptic until 2023. In 2024, I thought, “Maybe I can roughly make this thing do it.” In 2025, I thought, “Now I can hold this.” Over winter break, everybody came back saying, “It’s almost impossible to hold this.”
Swyx [00:46:01]: Did you see this on the Claude docs? CloudBot? OpenCloud?
Jake [00:46:06]: It’s gotten to a point where it’s harder to hold it wrong than to hold it right. There’s a scene in Avengers where Vision picks up Thor’s hammer and says it’s terribly well-balanced. It self-balances and works well. I’m a deep believer at this point that this will be the dominant species: assembly, C, C++, JavaScript, words.
Swyx [00:46:35]: It feels like a big jump.
Jake [00:46:37]: It is. But it’s not like you abandon CPU-based discrete logic and move straight to fuzzy logic. You need both. Your skills should call code or applications or some static structure. You can use skills to distill what the procedure should be or how the code should act.
Jake [00:47:02]: I’m coming to a thesis: you need three points. You need a clear spec defining the system, the code, and the tests. When you say it out loud, if you’ve been in engineering long enough, you’re like, “Of course. That’s an RFC, tests, and code.” But they all matter. Having them together lets them reinforce each other: the spec and tests match, but the code doesn’t, so reconcile it. Or the tests and code match but the spec doesn’t, so reconcile that. That’s the iteration loop.
Jake [00:47:41]: That’s why you’re seeing people talk about software factories, docs, and reconciliation. Some of that is architectural astronomy if you don’t implement it, but that loop is where most things will end up.
Swyx [00:48:07]: For listeners, we’ve been talking about this on the pod for three years: the holy trinity of specs and tests. Itamar Friedman from Qodo is the reference if people want to look it up.
Self-Modifying Infrastructure and the End of Push-Pull-Rebuild
Swyx [00:48:18]: One thing I want to mention on the OpenCloud idea is self-modification. I don’t know how Railway would support it, but I have my OpenClaw, and I just tell it it has the Railway CLI and can do whatever. In theory, whatever capabilities or new infra it needs, it can call the Railway CLI, provision it, and add it to itself. The agent can modify its own infra.
Jake [00:48:45]: It’s nuts. I have a loop set up where you put the Railway CLI on top of something that runs on Railway. You’re authenticated as whatever the current box is, and you can make any changes to it. Then you call Railway deploy, and it deploys itself.
Jake [00:49:04]: It’s like: “I need to spin up this instance of this environment. I already exist in this environment. Excellent, I have access to a Postgres instance now.” That’s where we want to go with agentic, self-replicating infrastructure. That’s your loop: iterate in production. You continue making changes. If it works, merge it upstream. If it doesn’t, throw it away.
Jake [00:49:37]: How do you make throwaway copies trivial to spin up and super cheap? The era of “I have an AWS instance with four vCPU and 16 gigs of RAM” is going to get destroyed. If you do that for agents, you need a thousand of those machines. It’s prohibitively expensive compared with what we’ve spent a ton of time figuring out: the atomic unit of deploy, whether you call it isolates, sandboxes, or something else. Only pay for what you use, spin up instantaneously, and close the loop as quickly as possible.
Jake [00:50:15]: If the system can self-replicate safely and say, “This is my environment, I’m making these changes,” it can come back with, “Does this look good? This is a new state of infrastructure given this prompt. I think I’ve solved it.” Then you go back and say, “Actually, it looks different.” It does the loop again. Then you say, “Cool. Apply.”
Swyx [00:50:38]: That’s retroactively obvious, which is the most useful kind. Any other comments on agent deployment on Railway?
Jake [00:50:51]: It’s getting better every day. I’m on X or Twitter. You can always yell at me about the parts not working as well as they should, because plenty of things should work way better.
The New Serverless: Stateful, Long-Running, Pay-for-What-You-Use Linux
Swyx [00:51:04]: At this stage, when people want massively or embarrassingly parallel compute, they usually talk serverless. I feel like there’s a new serverless compared to the previous five years of serverless. You’re in that new bucket. Do you have comparisons or philosophical differences you want to call out?
Jake [00:51:31]: It’s somewhere in between. It’s the ability to run stateful, long-running workflows or executions.
Swyx [00:51:42]: Vercel has Fluid Compute, Cloudflare has some container thing, Google has App Runner and others.
Jake [00:51:55]: That’s where everything is roughly going, and it’s why we’ve been working on this for six years. We believe users need access to a computer: a box that speaks Linux. They need to deploy what they want. Other systems change the surface area of what you can build. For us, users need a computer and need to deploy anything they truly want. That’s why we’ve focused on the primitives: network, compute, storage. If we give you those and expose them so you can run things indefinitely, that’s where we believe it’s going.
Jake [00:52:43]: Twitter has no nuance, so everyone says “servers” or “serverless.” It’s always somewhere in the middle: I want to run it for a long time, but I don’t want to provision the resource statically or pay for things I’m not using. That’s been our thesis from day one: pay only for what you use, run it indefinitely, and it is full Linux.
Swyx [00:53:12]: That’s why I like the naming of Fluid. It’s fluid. Flexible.
Heroku, Focus, and Carrying the Torch Without Becoming the Past
Swyx [00:53:18]: Another milestone is the Heroku official deprecation. You’re one of the presumptive new Herokus. “New Heroku” has been a category for as long as I’ve been in developer tooling. It’s finally happening. What was that like? Any behind-the-scenes of, “This is the moment”?
Jake [00:53:42]: You have people where you’re like, “You were running stuff on here? You, as this company?” It’s crazy that names you would know are running on it and now coming to us saying, “We want to move a lot of this off.”
Swyx [00:54:00]: Any behind-the-scenes on why Salesforce let Heroku stagnate?
Jake [00:54:05]: I can only guess. It’s hard when it’s not your business. Salesforce’s business is to build a great CRM. That’s their focus. Then you acquire a compute business as an offshoot. A lot of early Meta people talk about focus. Boz has a write-up about how in the early days of Meta they had no money, so they were forced to focus. Then they turned on the money tree and had no reason not to split their focus.
Jake [00:54:52]: But that dilutes your product. You get offshoots where you ask, “Is this the focus of the business?” If it’s not core, it languishes. A lot of companies get in trouble when they split focus because they’re fighting a multi-front war, not just externally but internally for alignment. Where are we going? What are we doing? What is our purpose?
Jake [00:55:24]: If you’re Salesforce-built and mission-driven, you want to work on Salesforce. Heroku is off to the side. It’s not core to the business. Getting resources, budget, focus, and alignment internally becomes hard. It was a matter of time.
Swyx [00:56:06]: Kudos for them to call it out instead of leaving it unknown.
Jake [00:56:12]: Their release was a little odd. They called it out, but they didn’t say they were shutting it down. Behind the scenes, I think they issued messages to people saying they should close accounts and that they were going to deprecate and remove things over time.
Jake [00:56:30]: It’s crazy because some of my first deployment experiences were on Heroku. You start with dragging things into an FTP server, then you try to get a deploy working, and then it’s Heroku. It was the on-ramp for us. But the wheel turns. New things emerge. We’re happy to carry the torch for a lot of that. But we don’t want to be the new Heroku. We want to be the way people build and deploy software, and ultimately the way people monetize software over time.
Swyx [00:57:19]: It’s still a big crown to be the new Heroku. There are 50 companies that fought for that.
Jake [00:57:23]: Everybody is holding some portion of it. We’re happy to support people and companies. The platform works differently. The game loop is similar, but we’ve been dogmatic about where these things are going: primitives, agents, fan-out. Some things fit; some workflows need to change. We have an approximation of Heroku pipelines with the environment system. It’s exciting. We’ve got a ton of people we can support, and it’s growing a lot.
Temporal, Workflow Engines, and State Machines
Swyx [00:58:12]: I have one more technical question about Temporal. I’ve sold my shares. You’re a power user and one of our earliest customers. I met you through Temporal. You built on Temporal. You have complaints. This may be the most neutral and informed conversation anyone will hear about Temporal without someone working at the company.
Jake [00:58:39]: That’s fair. I’ve used Temporal for almost 10 years because of Cadence at Uber.
Swyx [00:58:52]: Give people a sense of what Cadence was at Uber.
Jake [00:58:57]: Cadence was the precursor to Temporal. It powers trip actions, rides, when you rent a Jump bike or scooter or car. You’re running workflows for a period of time and saying, “This ride will run indefinitely until it finishes.” You attach information: you paused in this zone, so add this charge to the bill. When you end the trip, the workflow is done. That experience was powered by Cadence at the time.
Swyx [00:59:34]: I used to say it’s like programming the entire user journey top-down as one function.
Jake [00:59:39]: It’s a powerful idea and important. It’s also important for the next phase of the agentic journey. You want an agent to do a specific task, be complete or incomplete on that task, and move on to the next thing. You need a way to manage workflows dynamically.
Jake [00:59:59]: Temporal was always great in theory, and great when you got it working the way you wanted in production. But it required you to model the entire journey in your head. If you didn’t, you could cause issues where replaying the state of the workflow causes non-determinism.
Swyx [01:00:25]: Because it works on deterministic workflow history.
Jake [01:00:28]: Exactly. I describe it as a jet engine. If you know how to operate it and run it, it’s great. But you can’t hand it to people trying to build complicated things if they don’t have the whole state in their head.
Jake [01:00:48]: We run our whole deployment pipeline on top of it. That’s a reasonably complicated workflow: pre-commit hooks, signaling, queuing, and all the rest. We ran into the same thing at Uber. As you express a large workflow, it gets more complicated, with more states in the state machine that you have to map back to the workflow.
Swyx [01:01:15]: It’s a lot of ifs.
Jake [01:01:16]: Exactly. At Uber, we built a system for doing the state machine and testing it. We’ve started to build some of those things here because it’s grown heavily. It’s not quite love-hate. When it works well, it works super well. But if someone who doesn’t have full context puts something into the system that invalidates state or causes non-determinism, or spins off a ton of activities, you have to keep track of underlying SRE knobs like activity slots. Those should scale with memory, vCPU, and so on. It becomes a bear to scale.
Swyx [01:02:10]: You need a capable sysadmin running things behind the scenes. If you moved off, what would you do?
Jake [01:02:19]: We’d build our own workflow engine. We have a few internally that we’ve worked on.
Swyx [01:02:27]: This is one of those classes of things you typically wouldn’t vibe code, but I’m wondering if you can.
Jake [01:02:33]: I still don’t think you should vibe code it. You still want to run decent tests to make sure it works.
Swyx [01:02:39]: Timo didn’t invent that from scratch either. There are libraries you can run. On top of that, it’s just a state machine that you have to map out. Ultimately, you define the instructions you want and run them through a state machine.
Jake [01:03:00]: It’s very doable. Workflow stuff is interesting. Restate is doing neat stuff here.
Swyx [01:03:10]: You’re tied into JavaScript. Are you a JavaScript maxi?
Jake [01:03:13]: Internally, we have TypeScript, Rust, and Go. We don’t add more languages. Actually, we have a little C because we write BPF code and hooks. But those are the languages.
Swyx [01:03:28]: Is this for sidecars?
Jake [01:03:32]: No. It’s for the networking stack, volumes, and things like that. We use TypeScript a lot because it powers the dashboard, but we’re moving a lot of workflow stuff off the dashboard stack and into the infrastructure stack.
Railpack, Nixpacks, and Content-Addressable Filesystems
Swyx [01:04:00]: Cool. Any other technical infrastructure stuff? Railpacks?
Jake [01:04:07]: We built an engine for determining dependencies based on source code. It’s called Railpack. We built the first version, Nixpacks, on top of Nix, and then we moved.
Swyx [01:04:17]: People have been trying to get me to adopt Nix and NixOS for four years. Is it ever going to be a thing?
Jake [01:04:23]: I don’t know. We’re excited about it, but it has pain points. Think of it as a stack of versioned binaries at specific slices in time. If you want version X and version Y, you bloat the package space, which blows up image size and makes real-world workloads difficult.
Swyx [01:04:53]: But you content-address it and cache it. In theory, there are optimizations.
Jake [01:05:00]: In theory, yes. But with a large enough user base and disparate enough machines, you run into a problem Meta described in the XFAAS paper, their internal serverless system. It becomes difficult at scale unless you break out specific runtimes.
Jake [01:05:24]: We didn’t want to do that because we wanted to truly allow you to deploy anything. That was our initial thing with Nix. But we’ve moved toward interesting work around content-addressable file systems that can lazy-load anything from any point and page it into memory.
Swyx [01:05:48]: Amazing.
Jake [01:05:49]: The future is very bright. It’s crazy, and it’s going to be nuts.
Coding Agent Spend, Roadmaps, and Token ROI
Swyx [01:05:54]: Founder journey stuff?
Alessio [01:05:56]: Your cloud usage: you tweeted you’re going to spend $300K this month?
Jake [01:06:01]: I think we got to $200K.
Alessio [01:06:02]: Coding agents?
Jake [01:06:03]: Yeah.
Swyx [01:06:04]: Across the company?
Alessio [01:06:05]: You only have 35 people, so I’m sure they’re not all spending $10K a month. What’s the distribution?
Jake [01:06:10]: I think I’m at about $25K. We have power users all the way down. We came back from winter break, and I basically said, “If you’re writing code by hand, you’re doing this wrong.” The tools are good enough now that you can move extremely quickly. There are issues and pain points, but you should be reviewing the code you are writing instead of writing it by hand.
Jake [01:06:40]: Architectural patterns matter more now than ever, but you shouldn’t spend your time generating code you would write. If you know how to write it, ask the agent to write it and reconcile it until it looks like you would have written it yourself.
Jake [01:06:58]: People misconstrue my propensity to push people toward agents as connected to our growth and some reliability bumps. They’re not necessarily related. The tools are good enough to move extremely quickly and build things way larger than you could before.
Jake [01:07:19]: To the earlier point about cooling data centers in space: I don’t know. But with software, you can ask, “How would I build block storage from scratch? How would I do these things?” I have ideas because I have history and have read papers. Let me work them out and build massive test benches with thousands of tests, because those are now free to author. If you’re not using AI systems to speed-run your roadmap and reconcile your existing system onto the future, you’re missing a large point of what’s happening.
Alessio [01:08:12]: What’s the path to spending $3 million a month? Is it bound by ideas and things customers can absorb?
Jake [01:08:19]: For most companies, it’s bound by deployment at this point. That’s why we’ve seen a massive boom in users and companies, from Fortune 50s down, asking how to get developers to move faster. You’ll probably hit your CFO before any technical limits because they’ll look at the eye-watering amount of money spent on tokens. Inference costs have to come down, but we’re inference constrained now. There will be price discovery around what makes sense for an org to adopt.
Jake [01:09:06]: I think you’ll end up with the F1 driver concept. If someone is really adept at these things, it makes sense to put them in a $3 million car. If they’re not, it probably doesn’t make sense. You’ll take a few people and say, “You can drive the F1 car. We need to go in this direction. Figure out if it works and prototype it.”
Jake [01:09:33]: We’ve done some of that and vastly accelerated our roadmap. We thought we’d ship something in a few years; now we can probably ship it in a few months because we validated it and don’t have to build it incrementally. We can skip steps and move toward our vision.
Alessio [01:09:58]: A lot of people are realizing the roadmap doesn’t always have a business impact, so they say tokens are too expensive. But if your roadmap were built to make more money by the time you built it, you’d have token pricing for it, the same way you do with sales. You’d spend a billion dollars on sales if you knew you would get $2 billion of revenue.
Jake [01:10:19]: Exactly. A naive way to measure this is the percentage of tokens that end up in production. If you can measure impact because those tokens end up in production, that’s awesome. But the burden of proof will rise. Internally, we have a growing number of pull requests that haven’t merged. The question becomes: how do you get this into production? It’s about how quickly you can build and deploy software, which is exciting because that’s our whole thing.
The SDLC Shift: Prompt Requests, Feature Flags, and Safe Rollouts
Swyx [01:10:56]: The SDLC is changing. One thesis is that the pull request is dying. It’s going to be the prompt request. Beyond that, code review is also kind of dying if you have all the other systems in place. What else is changing about the SDLC?
Jake [01:11:19]: The AISRE and the tools to make it happen. AISRE is pie-in-the-sky aspirational. What does it take to get an AISRE? What tools do you need to build?
Swyx [01:11:32]: You should expose your tooling to customers at some point. The Central Station command center.
Jake [01:11:39]: We have it for template maintainers. Template maintainers can deploy and maintain templates, and they get feedback. We’re going to expose those things incrementally.
Swyx [01:11:51]: Clustering around incidents. Everyone has a version of that, but I don’t think anyone has solved it.
Jake [01:11:56]: I won’t say we’ve solved it internally, but it’s gotten so good that we can see incidents forming pretty quickly. At some point, those will be things either someone else builds or we build. We’ve always built things purpose-built for us. If it makes sense to make it useful for users, monetize it, or turn that loop into a profit center instead of a cost center, we want to do that.
Jake [01:12:28]: Pull request is definitely dying.
Swyx [01:12:29]: Do you do first-party feature flagging and incremental rollout stuff?
Jake [01:12:34]: We have a feature-flagging engine we built internally and will eventually roll out.
Swyx [01:12:38]: I don’t see it as a user. How come you didn’t give us what you have?
Jake [01:12:43]: We have to beta test it. We care a lot about the quality of the things. There’s plenty we’ve used internally that doesn’t make it all the way through the journey because it fails. It works for one service but not multiple services. We’d have to build it for multiple services and know that if we released it, we’d rebuild it again and again. Some things are worth that, but many inform the roadmap.
Jake [01:13:18]: We don’t want to dilute the experience by saying, “This works, but only for this service,” unless it’s a core initiative. Over the next few months, we’ll roll out things that work for a single service, then multiple services, then multiple services across the environment. You have to be deliberate. Otherwise you create broken disparate experiences and support load because people ask how to use the feature.
Jake [01:13:52]: It’s the earlier expansion and compaction pattern. You expand the company to get features, then compact and smooth them out so the experience is stellar. You told me in the hallway, “It’s gotten so much better.” Internally we’re saying, “This part really sucks. We need to make it significantly better.”
Swyx [01:14:11]: I can attest to that over the last three years watching you build Railway. For listeners, feature flagging is a huge part of Uber culture. So much so that they have too many feature flags and another thing to remove feature flags. Facebook has Gatekeeper. Agents are going to need this. It’s fundamental to incremental rollouts. OpenAI acquired Statsig. GPT-5 is routing and flagging through different models.
Jake [01:14:56]: It’s super important. If the software development lifecycle is going to change because we’re doing things 1,000 times faster and 1,000 times more concurrently, what becomes important at scale?
Jake [01:15:16]: Before I started Railway, I built a feature-flagging product and tried to sell it. It was an easier version of LaunchDarkly. I ran into a problem: anyone small enough to adopt your technology doesn’t care about feature flags, and anyone large enough to need feature flags needs so much scale that you have to build out all the infrastructure. I scrapped it.
Jake [01:15:42]: But what is old is new again. Companies are trying to move quickly, but you can’t YOLO a vibe-coded thing straight into production. You need to say, “Here’s my blast radius, my impact, and I want to shadow it for these users.” Feature flags. You’re going to need the tools larger companies built to maintain their structures. Everything gets compressed by 1,000x so everybody can build those structures quickly.
Jake [01:16:07]: That’s exactly where we are: compressing the software development lifecycle, then expanding it and adding more new things.
Cattle, Pets, and Clonable Infrastructure
Swyx [01:16:15]: Another term that comes to mind for newer developers is “cattle, not pets.” People treat production like a pet. It has a name. You baby it and keep it alive. With cattle, you can mass farm, roll out, portion parts out, and kill them.
Jake [01:16:37]: I think that might change. You can move toward having pets as long as you have a cloning machine for your pets.
Swyx [01:16:52]: Yeah.
Jake [01:16:52]: If you can snapshot every single thing at every frame, it doesn’t matter if something gets obliterated because you have a snapshot of it. The things we’ve built right now are designed to block changes from the hermetically sealed DevOps line. You have to write a Dockerfile because you need a specific cut of the file system.
Jake [01:17:14]: What if you had the whole file system? What if you snapshot it and lazily load the entire file system? Then you get around this problem entirely. You don’t need the ceremony of Dockerfiles, Ansible scripts, or other things. You can iterate, snapshot, ask if it’s the right loop or state, and then merge it into production. Merge the file system.
Swyx [01:17:45]: Why not?
Jake [01:17:46]: It’s going to be fun.
Swyx [01:17:47]: This is a whole other can of worms, but if you cataloged the stateful things in a VM and developed dedicated solutions for each, you can cut the problem down a lot. It’s surprising people weren’t trying until now.
Jake [01:18:04]: It has always been surprising to me because these are the things we would work on. It’s obvious.
Swyx [01:18:11]: At first principles, you need them. Everyone needs them in theory. Then the big clouds don’t do them, so you assume it’s impossible.
Jake [01:18:18]: Exactly. You think, “Meta has all the people writing eBPF code, and they’re doing something with them.” But you need that kind of work to solve these problems. Whatever is required, however deep we have to go, we’ll go all the way down to the kernel’s TCP/IP stack if needed. If we need to modify something to make it work for the mental model of the universe moving forward, we’ll do it and keep going down.
Swyx [01:18:52]: That sounds fun.
Jake [01:18:53]: It’s so much fun. I have to peel myself away from fun, interesting problems to make sure we can scale the company in a way that works. There are so many fun problems: getting information from customers to support to the person who built the thing internally, safe iteration, context from the dashboard to users, drilling down to the infrastructure layer, and managing orchestration as a real-time operating system versus a feedback control system. It’s just so fun.
Solo Founder Lessons: Obsession, Writing, and Focus
Swyx [01:19:29]: Speaking of the founder side, you’re famously outside the YC/SF consensus. You go to YC, get a co-founder, and do all these things. You did none of that.
Jake [01:19:40]: None.
Swyx [01:19:45]: In the elevator you said a co-founder makes sense if one person is the tech person and the other is the biz dev person. But you have to contain those multitudes yourself. How do you do it?
Jake [01:19:58]: I try to get eight hours of sleep.
Swyx [01:20:11]: Is there a balance: 50/50, 30/30/30? What’s the mental model as a solo founder?
Jake [01:20:17]: There’s no balance. You have to think about all these things and be obsessed with them. Be obsessed with how people think about your product from a go-to-market perspective, and be obsessed with the kernel-level change that makes a user’s SSH connection never drop. I want a universe where you can snapshot everything and it feels like iterating on a VM.
Jake [01:20:47]: You have to be obsessed at every layer of the stack. That’s what makes it easier for me. Some people are obsessed with different portions of the company journey, and if you can segment those lines well and be clear about ownership, you’ll have a good time.
Jake [01:21:12]: I said two is the worst number of co-founders because you have no tiebreak. You disagree, and how do you resolve it?
Swyx [01:21:38]: Usually someone is CEO, so they have the tiebreaker.
Jake [01:21:43]: Totally. It’s hard every way you cut it. It’s hard if you get help, and it’s hard if you do it yourself. Running things is hard, but it’s so rewarding and fun.
Swyx [01:21:56]: What have you found useful? A coach? Any advice that has been helpful?
Jake [01:22:01]: I like to write a lot. I get in trouble a lot for my Twitter. I once said if you’re working weekends, you’re messing up your planning. I’ve gone back and forth on that because right now we’re at an extenuating time where it makes sense to work more. The goals are clear in my mind. If you have the vision and know where you’re going, work harder to distill that vision and do those things.
Jake [01:22:33]: If you’re not certain and need clarity, disconnect and take your weekends seriously. Write about where you are, what you want to do, where you want to go, and what problems you’re solving.
Jake [01:22:56]: Writing is important. I don’t love the word meditation, but whatever gets you into mental clarity is important when you’re trying to say, “We’re here and need to be here,” or “We’re here and I think we need to be in this general space for this to work.”
Jake [01:23:22]: Disconnect, hang out with people you love, and work hard when you’re working. I try to work sunup to sundown, Monday to Friday, all out. I disconnect on Saturday and come back Sunday afternoon to write, plan the week, and do everything else. It works well for me.
Jake [01:23:43]: Another hot take: most advice should be digested and thrown out the window. If it’s helpful, it’ll come back. You’ll learn it through experience. We have made failure very expensive as a society, and it makes it difficult for people to walk off the paths.
GPUs, Focus, and the Dominant Role of Agents
Swyx [01:24:03]: Anything you haven’t tweeted and gotten in trouble with that you want to preview to the world?
Jake [01:24:12]: The agent stuff is crazy. It’s going to be the dominant way people do pretty much everything, provided we can get the inference required for that to happen. Over the next 10 years, you’ll see a fundamental shift in how people think about authoring the logic in their head.
Swyx [01:24:36]: One way of phrasing it is: if Allbirds can become a GPU provider, so can Railway.
Jake [01:24:44]: I think there’s a lot of “everyone becomes a GPU provider” that is actually not becoming a GPU provider. You’re defined more by the things you don’t do than the things you do, because it’s easy to say yes to a lot of things.
Jake [01:24:56]: Anthropic is amazing and moving into different zones. They’re moving into Figma-like things.
Swyx [01:25:09]: As we’re recording, Mike Krieger was on Figma’s board, they removed him Monday, and then they launched this today.
Jake [01:25:18]: Things move fast right now. But agents are going to be the way people operate.
Swyx [01:25:25]: So your answer is focus: no GPUs for now, but never say never.
Jake [01:25:27]: Focus. We will not do GPUs now, but we 100% will do GPUs at some point in the future. That’s not me leaking our roadmap because we don’t have plans to do GPUs. It’s just a function of needing FLOPS at some point. If you’re fully vertically integrated and want to make it trivial for people to iterate, build, and deploy, you need access to this core piece of fundamental logic.
A New Cloud From First Principles
Swyx [01:25:57]: Presumably your own data center traffic is a minority of your workload right now, but is there a point where it’s a majority or you turn off public clouds?
Jake [01:26:10]: At some point, we got to 100% data center: our own data centers. Right now, the vast majority of what exists on our platform is on our bare-metal data centers.
Swyx [01:26:21]: So you’re already there.
Jake [01:26:23]: Yeah. The transition was completed at some point, and then we grew so fast that we had to scale back on that. It got to 100% on the Datadog dashboard and then divoted back into the 90s because we were adding capacity.
Swyx [01:26:45]: You’re literally building a new independent cloud, and people assume that could never happen post-AWS.
Jake [01:26:53]: It’s hard. We’re going to figure out a bunch of things to make sure the platform is deeply reliable. But you have to break ground on new things when you decide to build a cloud from scratch but not copy the hyperscalers.
Jake [01:27:10]: We’ve been deliberate about inventing our own infrastructure from scratch based on reading a ton of papers, while promising ourselves we wouldn’t copy someone else’s homework. If we copy someone else, we lose. You become them over time. You need a core thesis for why this business needs to exist now.
Jake [01:27:33]: For us, the activation energy required to deploy something in production on hyperscalers is far too high. We believe it should be instantaneous. There should be no friction between your thought and the reality that comes out and that you can share with friends. That’s what we’re building toward at every layer of the stack. If we have to go down to energy, we’ll go down to energy.
Jake [01:27:58]: It matters for giving people access to this tooling. It’s gated not just for citizen developers who are now vibe coding. You have multiple layers: citizen developer, front-end developer, back-end developer, DevOps person, and more. Those layers need to disappear so people can just ship.
Swyx [01:28:20]: Amazing. That’s the future of cloud.
Jake [01:28:22]: Awesome. Thanks for coming on. Thank you for having me. It’s been wonderful.