Lots of people were excited about Andrej’s talk at YC AI Startup School today. Sadly, I wasn’t invited. Talks will be published “over the next few weeks”, by which time the talk might be deprecated. Nobody seems to have recorded fancams.
But… it’s not over. You can just do things!
Using PeepResearch™ I collated all available tweets about the talk and ordered1 them using available hints from good notetakers (credited in last slide) UPDATE: and now we have the full transcript! I’ll go thru most of the impt takeaways here and subscribers can get the full slides at the bottom.
we’ll update this to annotatethe full talk video when it’s up in a few weeks.
UPDATE: Slides are now synced with the full transcript if you want to read thru
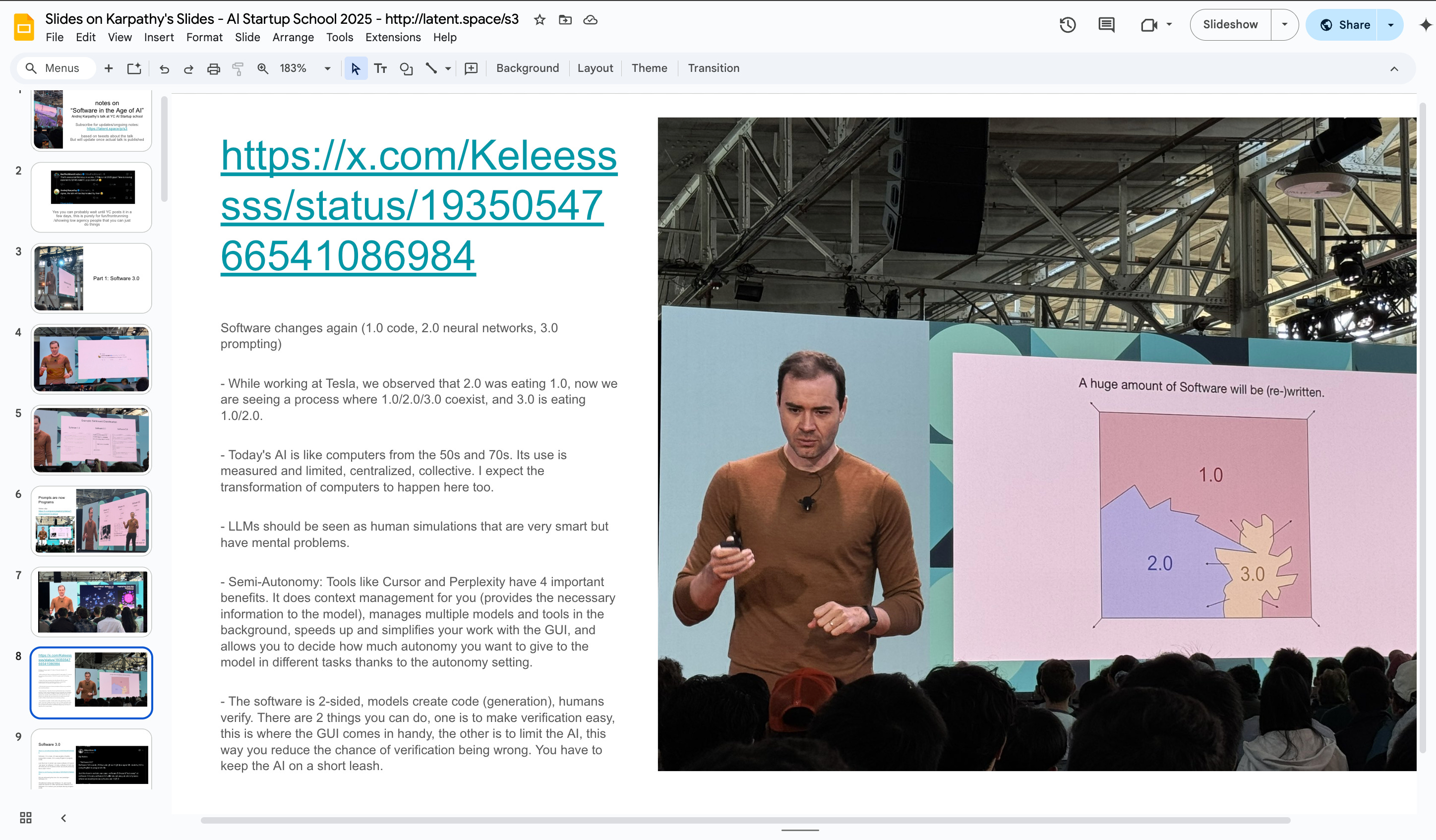
He originally wrote the Software 2.0 essay while observing that it was eating Software 1.0 at Tesla. And he’s back now to update it for Software 3.0.
In place of modifying the Software 2.0 chart like I did, Andrej debuts a new diagram showing the patchwork/coexistence of Software 1.0/2.0/3.0, noting that “Software 3.0 is eating 1.0/2.0” and that “a huge amount of software will be rewritten”:
Andrej is still focused on prompts for programs, and we slightly disagreed back in 2023 and still do: the “1+2=3” variant of Software 3.0 is the entire reason why AI Engineers have far outperformed Prompt Engineers in the last few years and continue to do so.
Part 1: LLMs are the new computers
LLMs are like Utilities
LLMs are like Fabs
LLMs are like OSes
LLMs are like Timeshare Mainframes…
although as he argues in Power to the People, LLMs also exhibit some unusual reversal of the normal flow of expensive frontier tech:
The word I came up with to describe the (strange, unintuitive) fact that state of the art LLMs can both perform extremely impressive tasks (e.g. solve complex math problems) while simultaneously struggle with some very dumb problems. E.g. example from two days ago - which number is bigger, 9.11 or 9.9? Wrong.
…
Some things work extremely well (by human standards) while some things fail catastrophically (again by human standards), and it's not always obvious which is which, though you can develop a bit of intuition over time. Different from humans, where a lot of knowledge and problem solving capabilities are all highly correlated and improve linearly all together, from birth to adulthood.
Personally I think these are not fundamental issues. They demand more work across the stack, including not just scaling. The big one I think is the present lack of "cognitive self-knowledge", which requires more sophisticated approaches in model post-training instead of the naive "imitate human labelers and make it big" solutions that have mostly gotten us this far. For an example of what I'm talking about, see Llama 3.1 paper section on mitigating hallucinations: https://x.com/karpathy/status/1816171241809797335
For now, this is something to be aware of, especially in production settings. Use LLMs for the tasks they are good at but be on a lookout for jagged edges, and keep a human in the loop.
I like to talk explain it as LLMs are a bit like a coworker with Anterograde amnesia - they don't consolidate or build long-running knowledge or expertise once training is over and all they have is short-term memory (context window). It's hard to build relationships (see: 50 First Dates) or do work (see: Memento) with this condition.
The first mitigation of this deficit that I saw is the Memory feature in ChatGPT, which feels like a primordial crappy implementation of what could be, and which led me to suggest this as a possible new paradigm of learning here: https://x.com/karpathy/status/1921368644069765486
We're missing (at least one) major paradigm for LLM learning. Not sure what to call it, possibly it has a name - system prompt learning?
Pretraining is for knowledge.
Finetuning (SL/RL) is for habitual behavior.
Both of these involve a change in parameters but a lot of human learning feels more like a change in system prompt. You encounter a problem, figure something out, then "remember" something in fairly explicit terms for the next time. E.g. "It seems when I encounter this and that kind of a problem, I should try this and that kind of an approach/solution". It feels more like taking notes for yourself, i.e. something like the "Memory" feature but not to store per-user random facts, but general/global problem solving knowledge and strategies. LLMs are quite literally like the guy in Memento, except we haven't given them their scratchpad yet. Note that this paradigm is also significantly more powerful and data efficient because a knowledge-guided "review" stage is a significantly higher dimensional feedback channel than a reward scaler.
…
Imo this is not the kind of problem solving knowledge that should be baked into weights via Reinforcement Learning, or least not immediately/exclusively. And it certainly shouldn't come from human engineers writing system prompts by hand. It should come from System Prompt learning, which resembles RL in the setup, with the exception of the learning algorithm (edits vs gradient descent). A large section of the LLM system prompt could be written via system prompt learning, it would look a bit like the LLM writing a book for itself on how to solve problems. If this works it would be a new/powerful learning paradigm. With a lot of details left to figure out (how do the edits work? can/should you learn the edit system? how do you gradually move knowledge from the explicit system text to habitual weights, as humans seem to do? etc.).
Part 2 Summary:
Part 3: Partial Autonomy
We like the Iron Man Suit analogy — the suit extends us in two useful ways:
Augmentation: giving the user strength, tools, sensors and information
Autonomy: the suit at many times has a mind of its own- taking actions without being prompted
How can we design AI products that follow these patterns?
Part 3a: Autonomy Sliders
The Autonomy Slider is an important concept that lets us choose the level of autonomy for the context, eg:
However, there are still a lot of remaining issues. While Vibe coding MenuGen, he found that the AI speedups vanished shortly after getting local code running:
The reality of building web apps in 2025 is a disjoint mess of services that are very much designed for webdev experts to keep their jobs, and not accessible to AI.
Poor old Clerk got a NEGATIVE mention, and Vercel’s @leerob a positive one, in how their docs approaches will respectively tuned for humans vs agents.
Part 5: Build for Agents
The bottom line is that toolmakers must realize that “there is new category of consumer/manipulator of digital information”:
1. Humans (GUls)
2. Computers (APls)
3. NEW: Agents <- computers... but human-like
Concretely: having llms.txt works because HTML is not very parseable for LLMs.
He also shouted out “Context builders” like Gitingest and Cognition’s DeepWiki, which we profiled for a lightning pod:
Closing / Recap
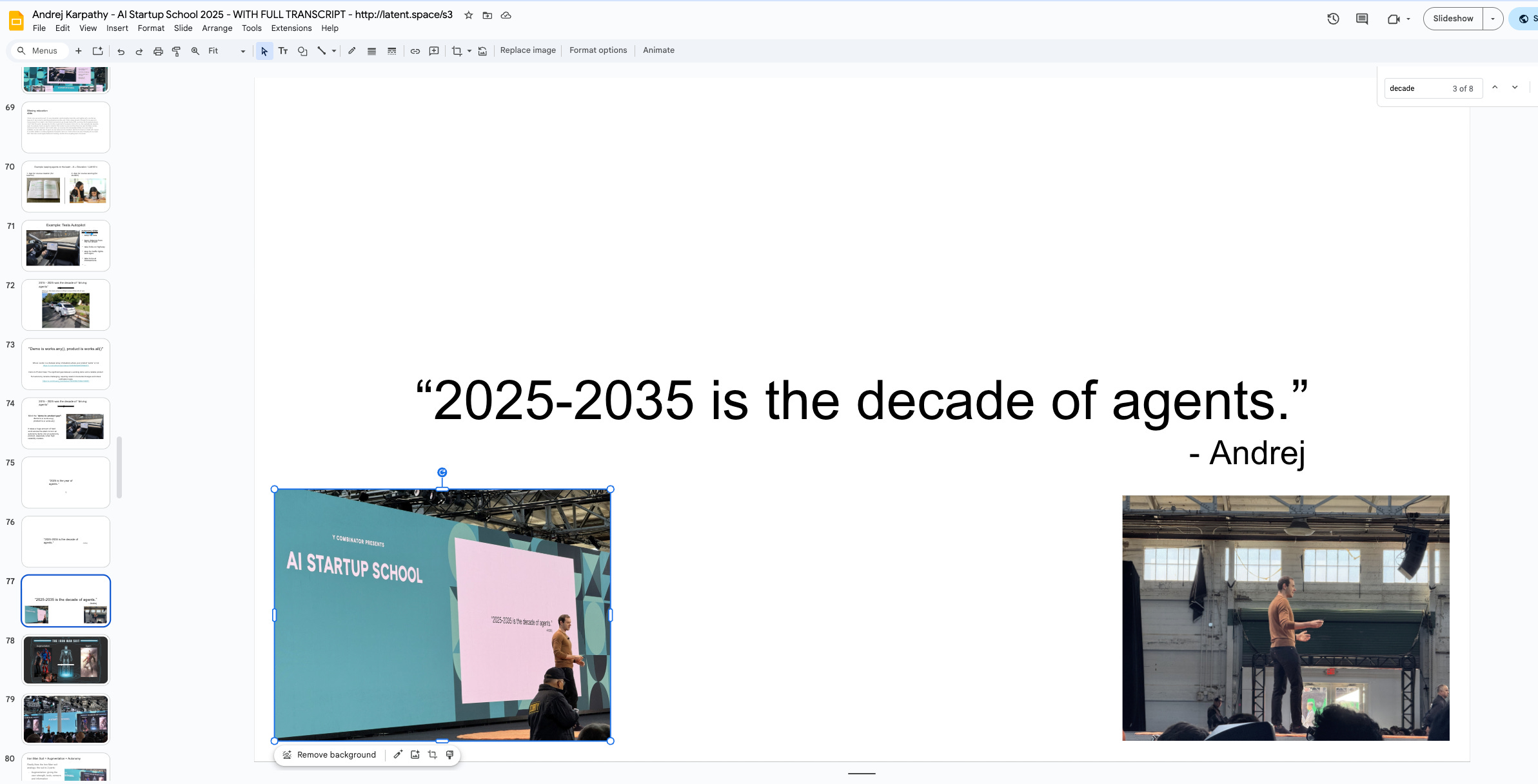
This is the Decade of Agents.
Less AGI 2027 and flashy demos that don’t work.
More partial autonomy, custom GUIs and autonomy sliders.
Remember that Software 3.0 is eating Software 1/2, that their Utility/Fabs/OS characteristics will dictate their destiny, improve the generator-verifier loop, and BUILD FOR AGENTS 🤖.
Full Slides for LS Subscribers
here :) link below
Keep reading with a 7-day free trial
Subscribe to Latent.Space to keep reading this post and get 7 days of free access to the full post archives.