

[AINews] WTF Happened in December 2025?
A quiet day lets us express a growing, uneasy feeling that coding has changed forever — much much more than “normal” hype.
The problem with wanting to cover AI without giving in to hype is, sometimes, there REALLY IS something warranting the hype every few weeks. It is hard to tell when many influencers make their living telling you {MODEL THAT JUST RELEASED} is AGI and {MODEL THEY PREVIOUSLY ENDORSED} is now absolute trash. The simple solution is to try to form your own opinions… and rely on credible voices that won’t sell out to the attention game.
There’s been an increasing number of the latter (and also the noise as well).
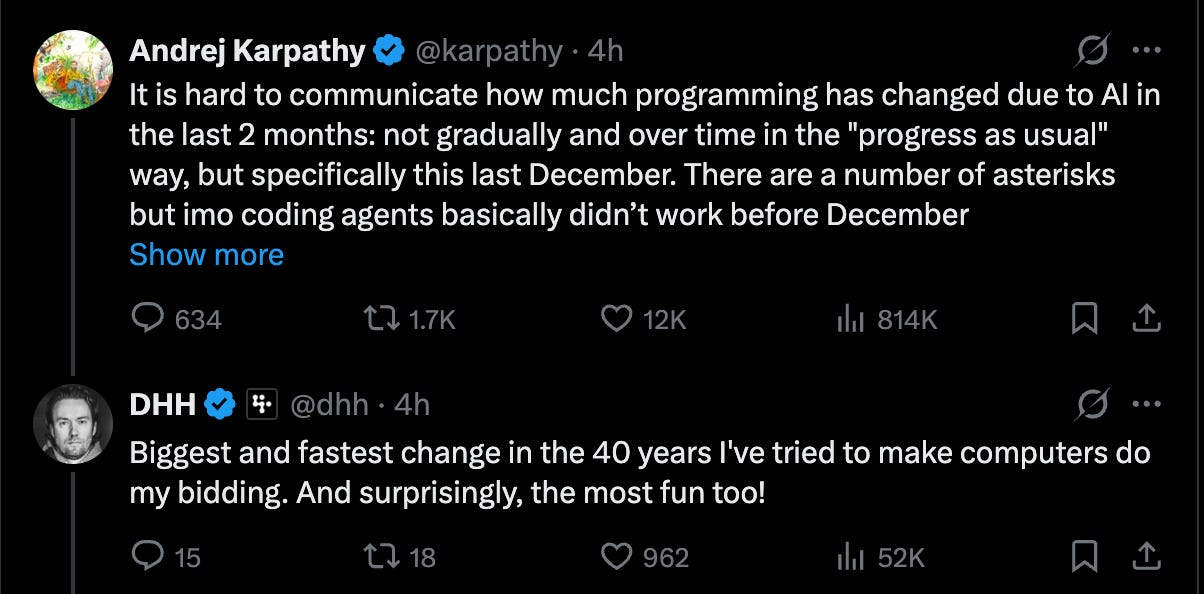
You can see Andrej trying to articulate his feelings about it in real time, from the original vibe coding tweet to agentic engineering. Today he joins a chorus of people calling out December 2025 (where Opus 4.5, Gemini 3, and GPT 5.2 on the OpenAI 10 year anniversary were all released in quick succession) as a major turning point:
We were already planning a mini essay around Greg Brockman’s similar observation:
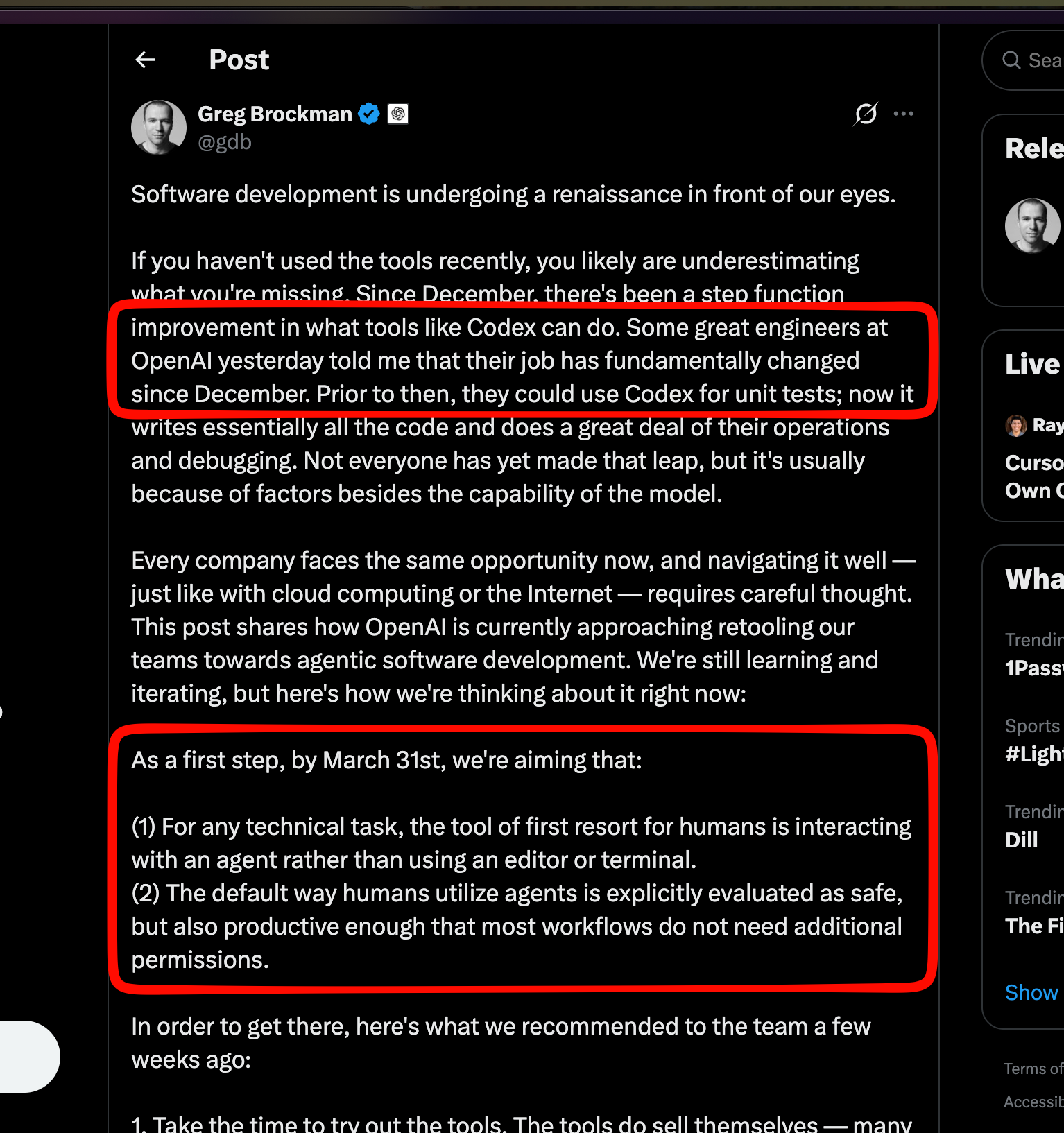
and Boris’ observation that Claude Code is now self-hosting:

and SemiAnalysis’ observation that Claude Code now writes about 5% of GitHub commits:

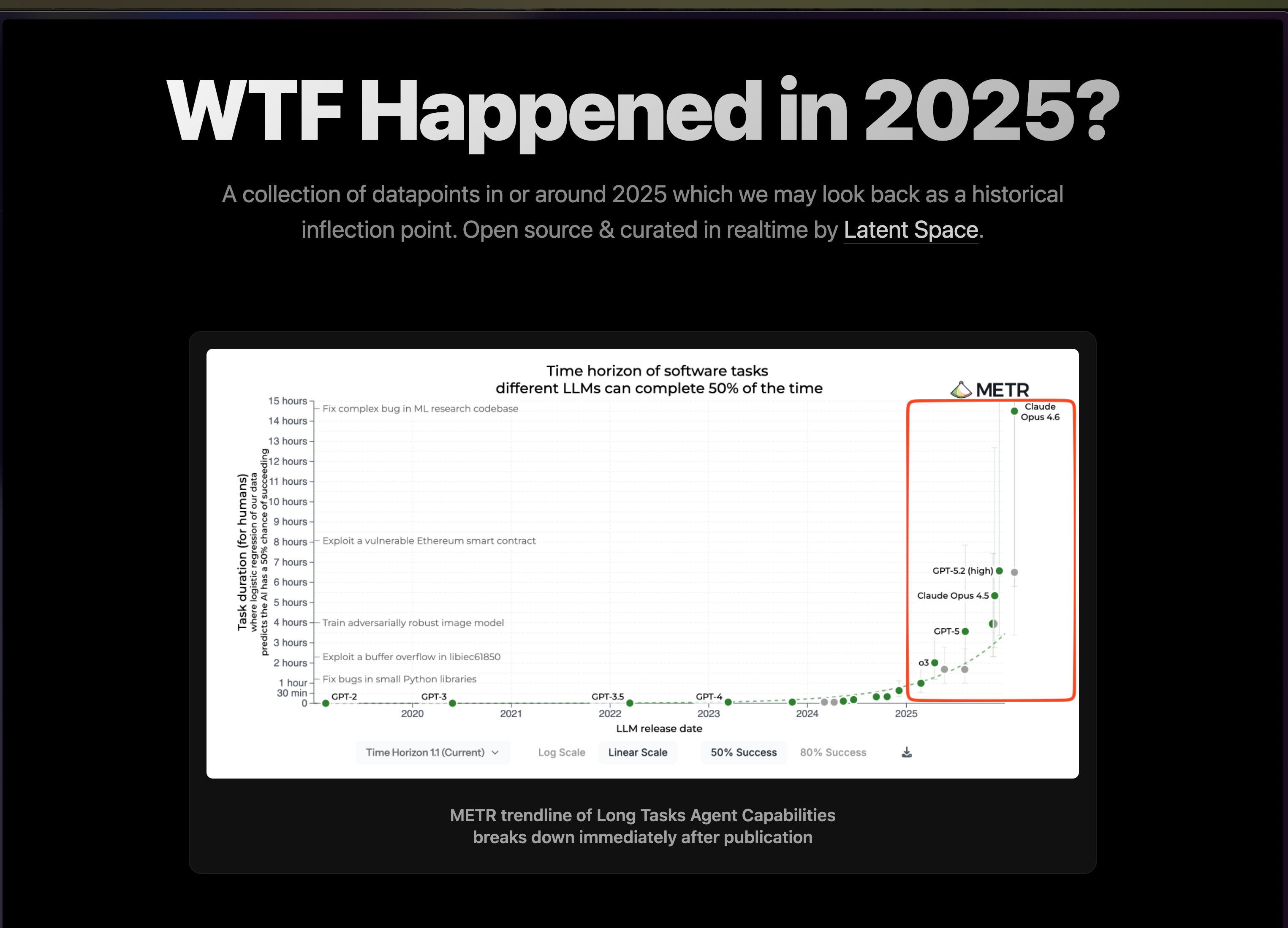
We’ve made a microsite for this:
wtfhappened2025.com
We’ll maintain this as a live updating resource as more observations and chart inflections come in. The data is of course sparse now and lacks time series charts because it is hard to estimate a sigmoid while you are living through it, but we will do our best to curate datapoints the way the old WTF 1971 did. We like to joke that AINews is the “only newsletter that tells you not to read it” because of the prevalence of “nothing days”, but this is increasingly not a laughing matter.
AI News for 2/24/2026-2/25/2026. We checked 12 subreddits, 544 Twitters and 24 Discords (262 channels, and 10751 messages) for you. Estimated reading time saved (at 200wpm): 1086 minutes. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
Perplexity “Computer”: an orchestration-first agent product (multi-model, tool+env, usage-based pricing)
Perplexity Computer launch: Perplexity introduced Computer, positioned as an end-to-end system that can “research, design, code, deploy, and manage” projects by orchestrating files, tools, memory, and models in one interface (launch tweet, Arav Srinivas). Key product signals:
Access + pricing: available on web for Max subscribers first, then Pro/Enterprise; usage-based pricing with sub-agent model selection, spending caps, and credits included for Max (10k/mo) plus a time-limited bonus credit grant (pricing details, availability, Arav on rollout).
Architecture emphasis: multiple tweets stress that the “breakthrough” is parallel, asynchronous sub-agents with a coordinator model assigning tasks to specialist models (research vs coding vs media), rather than a single monolithic agent loop (Lior’s breakdown, Denis Yarats).
“Everything is computer” narrative: Perplexity staff amplified Computer as a platform built by a small team with extensive use of coding agents and automated eval/debug loops (Arav, Denis).
Why it matters to engineers: Computer is a concrete push toward systems-level agent UX: multi-model routing, isolation/sandboxes, persistent memory, and cost controls—i.e., treating “agentic work” as a distributed workflow rather than a single chat session (Arav, Computer site).
Coding agents: “it started working in December” + new model/tooling drops (GPT‑5.3‑Codex, Claude Code ecosystem, Copilot CLI GA)
Karpathy’s “phase change” claim: Andrej Karpathy argues that coding agents crossed a qualitative threshold since December—from brittle demos to sustained, long-horizon task completion with coherence and tenacity. He gives a detailed example of delegating an end-to-end local deployment (SSH keys → vLLM → model download/bench → server endpoint → UI → systemd → report) with minimal intervention (Karpathy). This aligns with broader “software is changing” sentiment from devtool builders and users (Cursor, snowmaker).
OpenAI GPT‑5.3‑Codex release + early eval chatter:
OpenAI shipped GPT‑5.3‑Codex in the API (snsf) and Cline announced support with claimed gains: ~25% faster vs 5.2, fewer tokens/task, and strong SWE-Bench Pro performance (Cline).
Community benchmark reactions were sharp (and noisy): e.g., “86% on IBench” surprise (tweet) and “first benchmarks incoming” (kimmonismus). Treat these as directional until methodology is clear.
Claude Code: product maturity + observability + integrations:
Claude Code’s “first birthday” framing and retrospectives emphasize it as a foundational coding agent product, plus concerns about context length scaling hitting memory constraints (swyx).
Practical ecosystem bits: Slack plugin integration for Claude Code (catwu); LangSmith tracing for Claude Code to debug “nerfing”/routing issues (hwchase17, observability complaint).
GitHub Copilot CLI goes GA + “/research”:
Copilot CLI reached GA (Evan Boyle) and added
/researchfor repo-wide deep research using GitHub code search + MCP-based dynamic fetching, exporting reports to gists for sharing (feature).Smaller UX note: Copilot CLI in terminal updates titles in real time (tweet).
Open models & local inference: Qwen3.5 “Medium” wave (MoE + long context + FP8/quant), and the local-agent tipping point
Qwen3.5 Medium series distribution blitz: Alibaba pushed day-0 tooling support across vLLM, GGUF, LM Studio, Ollama, and Jan, highlighting how fast the deployment stack is now for major open releases (vLLM thanks, GGUF, LM Studio, Ollama, Jan).
Key technical claims from Qwen (as posted, not independently verified here):
Quantization robustness: “near-lossless” accuracy under 4-bit weight + KV-cache quantization.
Long-context: Qwen3.5‑27B supports 800K+, 35B‑A3B >1M context on 32GB VRAM consumer GPUs, 122B‑A10B 1M+ on 80GB GPUs.
Open base: Qwen open-sourced Qwen3.5‑35B‑A3B‑Base to support research (Alibaba_Qwen).
FP8 weights open with native vLLM/SGLang support (FP8 announcement).
Local agents “before/after”: A notable practitioner claim is that Qwen3.5‑35B‑A3B makes local agent loops feel meaningfully more reliable (tool calling, stability) while activating only ~3B params/token—explicitly positioning local as viable alongside Claude Code/Codex for many workflows (victormustar).
Eval discourse warning: benchmaxxing & MoE vs dense confusion:
Multiple threads caution against over-reading leaderboards (“please stop falling for benchmaxxing”) (scaling01) and highlight surprising parity across Qwen sizes on some benchmarks, suggesting either tooling effects or benchmark artifacts (eliebakouch, teortaxesTex on HLE/MoE interpretation).
Arena added Qwen3.5 Medium to Text/Vision/Code Arena for head-to-head comparisons (Arena).
Agents, reliability, and “building for agents”: minimal benchmarks, tool-interface optimization, and failure modes
Reliability hasn’t improved like capability: A reliability-focused line of work argues that despite rapid model progress, reliability gains are modest, decomposing reliability into many dimensions and warning against reducing agent performance to a single “success rate” number (IEthics, Justin Bullock quote).
Agent failures are often reliability, not capability: A summary of an “agent failure” paper claims agents frequently fail by compounding small off-path tool calls, where one mistake increases the likelihood of the next, especially in long-horizon settings (omarsar0).
Minimal “safe & helpful” benchmark idea: Instead of harder tasks, one proposal is to measure whether models can reliably do trivially specified safe behaviors (e.g., “send email only if asked”), including under irrelevant/distracting context; the claim is frontier models still miss cases (jonasgeiping).
Tool descriptions as an optimization target (Trace‑Free+): Intuit AI Research work suggests agent success depends heavily on tool-interface text, and introduces a curriculum that teaches models to rewrite tool descriptions into agent-usable forms without requiring traces at inference time; reported gains on StableToolBench/RestBench and robustness with >100 tools (omarsar0).
GUI/web agents: planning vs reactive: ActionEngine reframes GUI agents as graph traversal with offline exploration producing a state-machine; runtime generates a full program with ~1 LLM call, claiming big success/cost/latency improvements over step-by-step vision loops (dair_ai).
Compute, memory, and inference-speed frontiers: chip memory hierarchies, diffusion LLMs, and infra for scaling
Karpathy on the “tokens tsunami” and memory orchestration: A high-engagement thread frames the core constraint as two distinct memory pools—fast, tiny on-chip SRAM vs large, slow off-chip DRAM—and argues the biggest puzzle is orchestrating memory+compute for LLM workflows (prefill/decode/training) with best throughput/latency/$, especially decode under long context + tight agentic loops, which is hard for both “HBM-first” (NVIDIA-like) and “SRAM-first” (Cerebras-like) camps (Karpathy).
Diffusion LLMs as a speed alternative:
Andrew Ng highlighted impressive inference speed from Inception Labs’ diffusion LLMs (AndrewYNg).
Separate discussion claims diffusion approaches can hit ~1000 tok/s and shift the speed game via architecture, not chips (interpret cautiously; marketing often outpaces reproducible evals) (kimmonismus).
Research thread: “Diffusion Duality (Ch.2) Ψ-Samplers” for inference-time scaling in uniform diffusion-LLMs (ssahoo_).
Interpretability at scale: Goodfire described infra work enabling trillion-parameter-scale interpretability with minimal inference overhead, harvesting billions of activations and enabling real-time steering of chain-of-thought in at least one case study (GoodfireAI).
Major announcements & policy/safety pressure points: Anthropic acquisitions + RSP shift, surveillance concerns, and market/power constraints
Anthropic acquires Vercept to advance Claude’s “computer use” capabilities (AnthropicAI); Vercept’s founder thread frames the mission as moving from “telling users what to do” to acting for users, especially for non-technical tasks (ehsanik).
Anthropic “RSP v3” shift (Responsible Scaling Policy): Commentary indicates a move away from rigid, unilateral “stop training past thresholds unless mitigations are guaranteed” toward more frequent transparency artifacts (roadmaps + risk reports), plus updated threat models and external review commitments (MaskedTorah). A more sensationalized summary claims this reflects competitive pressure and uncertainty in risk science (kimmonismus).
Surveillance and civil liberties: Jeff Dean explicitly agreed that mass surveillance chills speech, invites misuse, and violates constitutional protections (JeffDean). Related tweets raised concerns about autonomous policing/surveillance agents that can’t refuse illegal orders (BlackHC).
Energy as a binding constraint: One report claims U.S. political leadership is pushing major AI/data-center firms to self-provision electricity to avoid ratepayer backlash as demand strains the grid (kimmonismus)—an example of AI scaling becoming as much infrastructure/policy as algorithms.
Grok 4.20 Beta leaderboard movement: Arena reports Grok‑4.20‑Beta1 at #1 on Search Arena and #4 on Text Arena (arena). Treat as one signal among many; Arena rankings can shift with sampling policies and model variants.
Top tweets (by engagement, technical/relevant)
Karpathy on the “phase change” in coding agents since December
Arav Srinivas: what Perplexity has been building + “Computer”
Karpathy on compute: SRAM vs DRAM orchestration for token-heavy LLM workloads
Local agents tipping point: run Qwen3.5‑35B‑A3B locally with 32GB RAM
ActionEngine: offline GUI exploration → O(1) LLM-call execution programs
Keep reading with a 7-day free trial
Subscribe to Latent.Space to keep reading this post and get 7 days of free access to the full post archives.