

Note: AIE Europe is ~sold out! Tickets and limited sponsorships for AIE Miami are next — as you can see from online buzz, speakers are excited and prepping. We’ll be there!
By total coincidence, today’s main pod guest also released today’s title story:
swyx: Does remote control work for Claude Cowork yet? No. Right.
Felix: Excellent question.
swyx: Coming soon.
And today, here it is:
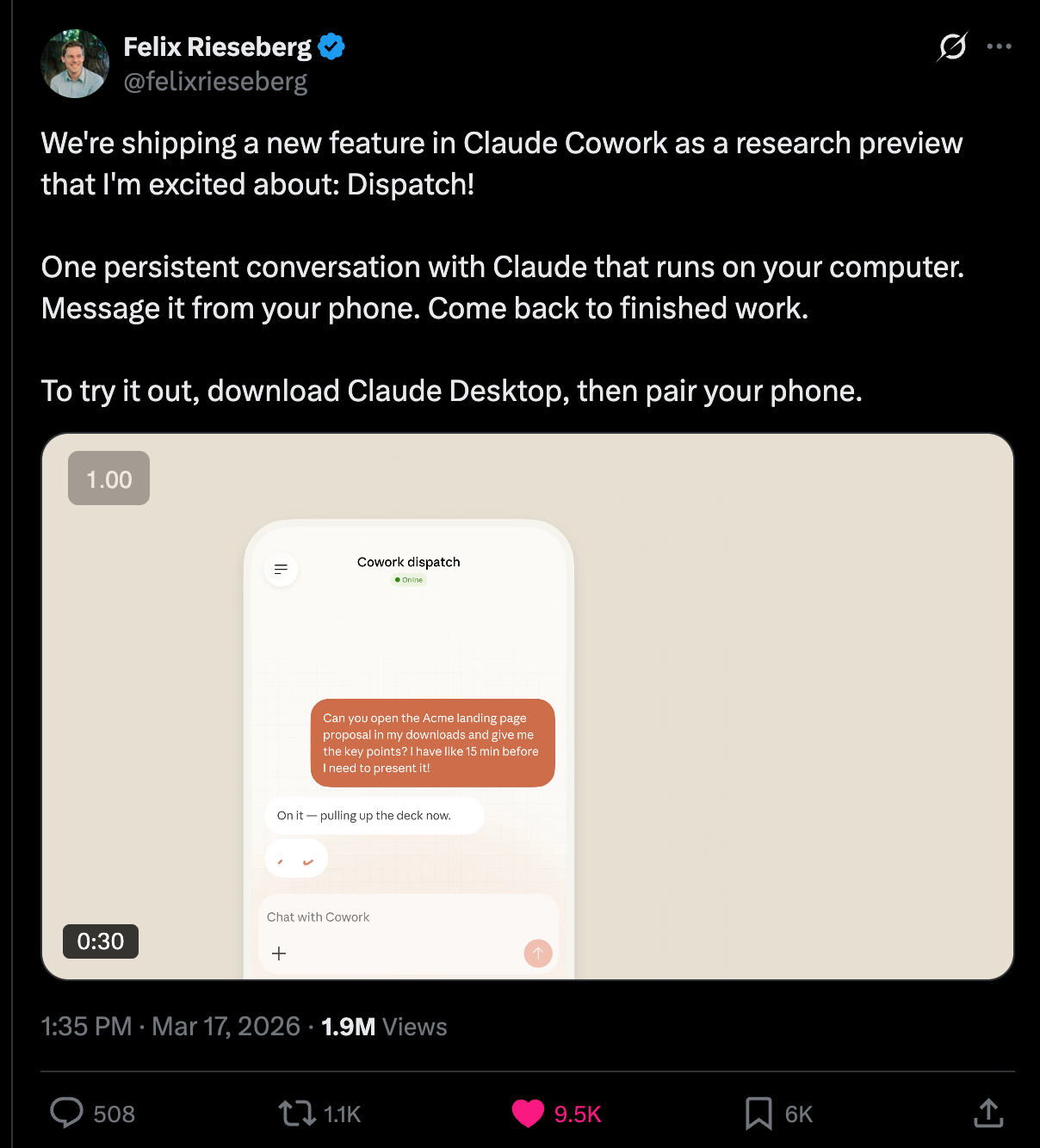
Multiple people, from SimonW to Ethan Mollick, are comparing it (favorably) to OpenClaw. As Jensen said yesterday, every company needs an OpenClaw strategy. Now Anthropic, which famously “fumbled” the Clawdbot relationship, has an answer, and it’s a pretty pretty good one.
Tune in to the full pod to get the full origin story, usecases, and design thinking (particularly around the technical choices of sandboxing and Electron), on today’s pod.
AI News for 3/14/2026-3/16/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
OpenAI’s GPT-5.4 Mini/Nano Release and the Shift to Small, Coding-Optimized Models
GPT-5.4 mini and nano shipped across API, ChatGPT, and Codex: OpenAI launched GPT-5.4 mini and GPT-5.4 nano, positioning them as its most capable small models yet. Per @OpenAIDevs, GPT-5.4 mini is more than 2x faster than GPT-5 mini, targets coding, computer use, multimodal understanding, and subagents, and offers a 400k context window in the API. OpenAI also claims mini approaches larger GPT-5.4 performance on evaluations including SWE-Bench Pro and OSWorld-Verified, while using only 30% of GPT-5.4 Codex quota, making it the new default for many background coding workflows and subagent fan-out.
Early reception focused on coding value, but also on pricing and truthfulness tradeoffs: Developers immediately highlighted mini’s utility for subagents in Codex, computer-use workloads, and external products such as Windsurf. However, commentary also converged on a familiar OpenAI pattern: better performance but higher price. Posts from @scaling01 note $0.75/M input and $4.5/M output for mini, with nano likewise priced above prior nano tiers. Third-party evals were mixed: Mercor’s APEX-Agents result reported 24.5% Pass@1 for mini with xhigh reasoning, ahead of some lightweight and midweight competitors on that benchmark, while BullshitBench placed the new small models relatively low on resistance to false-premise/jargon traps. OpenAI also quietly acknowledged behavior tuning issues, with @michpokrass saying a recent 5.3 instant update reduced “annoyingly clickbait-y” behavior.
Agent Infrastructure: Sandboxes, Subagents, Open SWE, and the Harness Wars
Code-executing agents are becoming the center of product architecture: Several launches point to a stack maturing around secure execution, orchestration, and deployment ergonomics rather than just better base models. LangChain introduced LangSmith Sandboxes for secure ephemeral code execution, with @hwchase17 explicitly arguing that “more and more agents will write and execute code.” In parallel, LangChain open-sourced Open SWE, a background coding agent patterned after internal systems reportedly used at Stripe, Ramp, and Coinbase. The system integrates with Slack, Linear, and GitHub, uses subagents plus middleware, and separates harness, sandbox, invocation layer, and validation. This is a notable step from “chat copilots” toward deployable internal engineering agents.
Subagents and secure execution are now first-class product features across the ecosystem: OpenAI’s Codex now supports subagents, and GPT-5.4 mini was framed by OpenAI as especially good for that use case. Hermes Agent’s v0.3.0 release is another strong signal: 248 PRs in 5 days, first-class plugin architecture, live Chrome control via CDP, IDE integrations, local Whisper-based voice mode, PII redaction, and provider integrations like Browser Use. The resulting direction is consistent across vendors: agent value increasingly depends on safe execution environments, composable skills/plugins, and workflow-native surfaces rather than raw benchmark gains alone.
Architecture Research: Attention Residuals, Vertical Attention, and Mamba-3
Attention over depth is having a moment: Moonshot’s Attention Residuals paper on arXiv triggered substantial technical discussion around “vertical attention” or attention across layers. A detailed explainer from @ZhihuFrontier frames the idea as each layer querying prior-layer states, effectively extending attention from horizontal sequence interactions to inter-layer memory. Community reactions emphasized that this is not entirely isolated: @rosinality noted ByteDance also implemented attention over depth, and @arjunkocher published an implementation walkthrough. The interesting systems claim here is that because number of layers << sequence length, some forms of vertical attention may be hidden under existing compute and impose little or no extra latency.
Mamba-3 strengthens the case for inference-first hybrid architectures: The other major architecture release was Mamba-3, presented by @_albertgu and @tri_dao as the latest step in making linear/state-space models more competitive in the hybrid era. The emphasis is explicitly on inference efficiency, not replacing transformers outright. Together summarized it as a MIMO variant that improves model strength at similar decode speed, with claims of strongest performance among linear models and fastest prefill+decode at 1.5B. Tri Dao also pointed to inference-heavy RL and long-rollout workloads as especially fertile ground for such architectures. The broader takeaway from both Attention Residuals and Mamba-3 is that labs are still searching for ways to relax the full-transformer bottleneck without sacrificing too much ecosystem compatibility.
GTC: NVIDIA’s Agent Push, Open Models, and the Infrastructure Thesis
GTC messaging centered on inference, agents, and the “token factory” worldview: Multiple posts reflected Jensen Huang’s framing of future computers as systems for “manufacturing tokens”, with inference now driving the next capacity wave. This showed up in product and ecosystem announcements: LangChain said its frameworks crossed 1B downloads and joined the NVIDIA Nemotron Coalition; @ggerganov highlighted Nemotron 3 Nano 4B support in llama.cpp; and Hugging Face’s @jeffboudier recapped a range of open NVIDIA drops spanning reasoning models, robotics datasets, and world models.
Open and enterprise agent tooling dominated side announcements: H Company released Holotron-12B, an open multimodal model built with NVIDIA for computer-use agents. Perplexity announced Comet Enterprise, bringing its AI browser to enterprise teams with rollout controls and CrowdStrike Falcon integration. NVIDIA’s broader business thesis also got amplified: @TheTuringPost highlighted Jensen’s remark that the often-cited $1T AI infra opportunity only covers a subset of the stack through 2027, reinforcing that the industry is still very early in inference infrastructure buildout.
Open-Source Tooling, Local Agents, and Developer Stack Upgrades
Local/private agent workflows keep improving: Hugging Face shipped an hf CLI extension that auto-detects the best local model/quant for available hardware and spins up a local coding agent. Unsloth launched Unsloth Studio, an open-source web UI to train and run 500+ models locally across Mac/Windows/Linux, with claims of 2x faster training using 70% less VRAM, GGUF support, synthetic data tooling, tool calling, and code execution. Ollama added web search/fetch plugins and headless launch support for OpenClaw workflows, while also showing up as a provider in CodexBar.
The “open coding agent” ecosystem is becoming legible: There’s increasing convergence on patterns: model-agnostic harnesses, structured skills, filesystem/state abstractions, and ephemeral cloud or local execution. LangChain’s Deep Agents was described as an MIT-licensed, inspectable replica of the Claude Code style of agentic harness. Hermes Agent’s plugin system and local-model friendliness pushed it into the same conversation. This is one of the clearer trends in the dataset: the frontier is no longer just open-weight models, but open harnesses and runtime layers for actually deploying agents.
Top tweets (by engagement)
OpenAI small-model launch: @OpenAIDevs on GPT-5.4 mini/nano was among the day’s most consequential technical announcements, especially for coding-agent workloads.
Cursor’s RL-based context compaction: @cursor_ai said it trained Composer to self-summarize through RL instead of prompting, cutting compaction error by 50% and enabling harder long-horizon coding tasks.
Mamba-3 release: @_albertgu and @tri_dao marked one of the most important architecture updates in sequence modeling this cycle.
Unsloth Studio: @UnslothAI had one of the strongest open-source product launches, aimed squarely at local training/inference practitioners.
Kimi Attention Residuals: @Kimi_Moonshot drove much of the architecture discussion, with follow-on analysis around vertical attention and inter-layer memory.
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. Unsloth Studio Launch and Features
Unsloth announces Unsloth Studio - a competitor to LMStudio? (Activity: 998): Unsloth Studio has been announced as a new open-source, no-code web interface for training and running AI models locally, potentially challenging the dominance of LMStudio in the GGUF ecosystem. It is compatible with
Llama.cppand offers features such as auto-healing tool calling, Python and bash code execution, and support for audio, vision, and LLM finetuning. The platform supports GGUFs and runs on Mac, Windows, and Linux, with capabilities for SVG rendering, synthetic data generation, and fast parallel data preparation. Installation is straightforward viapip install unsloth. More details can be found in the Unsloth Documentation. Some users question the characterization of LMStudio as the ‘go-to’ for advanced users, suggesting alternatives like vLLM or llama.cpp. Others express excitement over the UI’s capabilities, particularly for training and data preparation.danielhanchen highlights the extensive feature set of Unsloth Studio, noting its capabilities such as auto-healing tool calling, Python and bash code execution, and support for multiple operating systems including Mac, Windows, and Linux. The tool also offers advanced functionalities like SVG rendering, synthetic data generation, and fast parallel data preparation, making it a comprehensive solution for various AI tasks. More details and installation instructions are available on GitHub.
sean_hash points out the convenience of having both fine-tuning and inference capabilities integrated into a single tool like Unsloth Studio. This contrasts with the current need to use multiple projects to achieve the same functionality, highlighting Unsloth Studio’s potential to streamline AI development workflows.
Specter_Origin expresses appreciation for Unsloth Studio’s open-source nature, contrasting it with the closed-source LM Studio. This openness could be a significant advantage for developers who prefer transparency and the ability to modify the tool according to their needs.
Introducing Unsloth Studio: A new open-source web UI to train and run LLMs (Activity: 579): Unsloth Studio is a new open-source web UI designed to train and run large language models (LLMs) locally on Mac, Windows, and Linux. It claims to train over
500+ modelsat twice the speed while using70% less VRAM. The platform supports GGUF, vision, audio, and embedding models, and includes features like model comparison, self-healing tool calling, and web search. It also offers auto-creation of datasets from formats like PDF, CSV, and DOCX, and allows for code execution to enhance LLM output accuracy. Models can be exported to formats such as GGUF and Safetensors, with auto-tuning of inference parameters. Installation is facilitated viapip install unsloth. GitHub and documentation are available for further details. Commenters are enthusiastic about Unsloth Studio as a fully open-source alternative to existing platforms, highlighting its accessibility for fine-tuning models, especially for users with less expertise. There is anticipation for upcoming support for AMD, which is expected to broaden its usability.A user highlights the importance of making fine-tuning accessible, noting that Unsloth Studio provides an easy way to fine-tune models, which has been a challenge since the release of LLaMA 2. This accessibility could potentially revive the ‘golden age of fine-tunes’, making it easier for those with less expertise to engage in model customization.
Another user points out a technical issue encountered during installation, where an OSError due to insufficient disk space occurred while downloading a large
torchpackage. This highlights a common challenge in AI/ML projects related to managing dependencies and system resources, suggesting that atomic installation of components might be necessary to lower the entry barrier.An AMD representative expresses readiness to support the upcoming official AMD support for Unsloth Studio, indicating potential improvements in compatibility and performance for AMD hardware users. This collaboration could enhance the usability of Unsloth Studio across different hardware platforms.
2. Qwen3.5-9B Document Benchmark Results
Qwen3.5-9B on document benchmarks: where it beats frontier models and where it doesn’t. (Activity: 295): The image compares the performance of Alibaba’s Qwen3.5-9B and OpenAI’s GPT-5.4 on document AI benchmarks. Qwen3.5-9B ranks #9 with a score of
77.0, excelling in “Key Information Extraction” and “Table Understanding,” while GPT-5.4 ranks #4 with a score of81.0, leading in other areas. The benchmark results highlight Qwen3.5-9B’s superior performance in “OmniOCR” but its lag in “OmniDoc” and “IDP Core.” This aligns with the detailed breakdown in the post, where Qwen models outperform in OCR and VQA tasks but fall behind in table extraction and handwriting OCR. One commenter suggests that AI technology is reaching a functional ceiling, indicating that current models are sufficient for many tasks and can run efficiently on less powerful hardware. Another comment anticipates interesting comparisons with GLM-OCR, while a third notes the potential energy efficiency of using smaller Qwen models for tasks that can tolerate longer processing times.Qwen3.5-9B’s performance: The model demonstrates competitive performance against larger frontier models, particularly in document processing tasks. Its ability to run efficiently on lower-end hardware, such as ultrabooks, highlights its energy efficiency and accessibility for broader applications. This suggests a shift towards optimizing smaller models for specific tasks rather than relying solely on larger, more resource-intensive models.
Energy efficiency and reasoning: The Qwen3.5-9B model is noted for its energy efficiency, especially in tasks requiring extended reasoning. Compared to larger models like Gemini or GPT, Qwen3.5-9B offers a more sustainable option if processing time is not a critical factor. This positions it as a viable alternative for applications where energy consumption is a priority.
Model variants and benchmarks: There is curiosity about the absence of larger Qwen model variants, such as the 27B dense and 35B MoE, in the benchmarks. This absence raises questions about the comparative performance and potential advantages of these larger models in specific tasks, suggesting a need for further exploration and benchmarking of these variants.
3. Mistral Small 4 and DGX Station Availability
Mistral Small 4:119B-2603 (Activity: 1057): Mistral Small 4 is a hybrid AI model with
119 billion parametersand a256k context length, integrating Instruct, Reasoning, and Devstral capabilities. It supports multimodal input and features an efficient architecture that reduces latency by40%. The model includes advanced features like speculative decoding and 4-bit float quantization, optimized for tasks such as general chat, coding, and document analysis. It is available under an Apache 2.0 license for both commercial and non-commercial use. More details can be found on the Hugging Face page. Commenters humorously note the shift in scale, with120 billion parametersnow considered ‘small’, reflecting the rapid evolution in AI model sizes and capabilities.The Mistral Small 119B model is being compared to the Qwen3.5-122B-A10B model, with a focus on parameter activation. Mistral activates 6.5 billion parameters, whereas Qwen3.5 utilizes 10 billion, which may explain why Mistral does not outperform Qwen3.5 overall. This highlights the importance of parameter activation in model performance.
DGX Station is available (via OEM distributors) (Activity: 418): The image depicts a high-performance workstation, likely the NVIDIA DGX Station, which is now available through OEM distributors. This machine is designed for AI and deep learning applications, featuring advanced cooling and performance capabilities. The DGX Station is equipped with NVIDIA’s latest technology, making it a ‘dream machine’ for many in the AI community. The discussion highlights its availability through distributors like Dell and Exxact, with prices reportedly in the
85-90k USDrange. The concept of ‘coherent memory’ is mentioned, which refers to a memory architecture that allows for efficient data sharing between CPUs and GPUs, potentially enhancing performance in AI workloads. There is a discussion about the pricing and availability of the DGX Station, with some users noting discrepancies in Dell’s product listings. The concept of ‘coherent memory’ is also questioned, indicating a curiosity about its implications for GPU performance.The DGX Station is priced between
85-90k USD, as noted by users observing current market listings. This pricing positions it as a high-end machine, likely targeting enterprise or research institutions rather than individual consumers.The DGX Station, despite its high cost and advanced capabilities, lacks a video output unless an additional card is installed. This design choice highlights its focus on computational tasks rather than traditional graphical output, aligning with its role as a data center or AI research tool rather than a consumer-grade product.
The concept of “coherent memory” in the DGX Station is questioned, with users speculating whether it allows full memory access to the GPU, similar to the DGX Spark. This feature would be significant for tasks requiring large datasets and high-speed processing, emphasizing the machine’s suitability for AI and machine learning applications.
Mistral Small 4 | Mistral AI (Activity: 323): Mistral Small 4 is a multimodal AI model with
119 billion parametersand a256k context window, utilizing a Mixture of Experts (MoE) architecture with128 experts. It is designed to optimize performance across reasoning, multimodal processing, and coding tasks, allowing configurable reasoning effort. Released under the Apache 2.0 license, it supports both text and image inputs, aiming for efficient enterprise deployment with reduced latency and improved throughput over its predecessor, Mistral Small 3. More details can be found in the original announcement. Commenters are intrigued by the model’s6.5B active parameters, comparing its inference cost to Qwen 3.5 35B-A3B, but with a larger expert pool. Concerns were raised about Mistral’s tool calling issues in previous versions, particularly with hallucinating function signatures and dropping parameters. The model’s performance on agentic tasks and context quality beyond32kare key areas of interest.RestaurantHefty322 highlights the competitive positioning of Mistral Small 4, noting that its
119Bparameters with6.5Bactive parameters align its inference cost with models like Qwen 3.5 35B-A3B, but with a larger expert pool. This could challenge Qwen’s dominance in the~7Bactive parameter tier, especially if Mistral has improved its tool calling capabilities, which were problematic in Devstral 2 due to issues like hallucinating function signatures and dropping parameters in multi-step chains.The discussion touches on the importance of text and code quality at the
6-7Bactive parameter range for local deployments, with a particular interest in how Mistral Small 4 handles context quality beyond32k. This is a critical area where smaller MoE models often struggle, despite having longer advertised context lengths.RepulsiveRaisin7 expresses skepticism about Mistral Small 4’s improvements over Devstral 2, which was perceived as lagging behind competitors. The comment reflects a broader concern about whether Mistral Small 4 can offer tangible advantages over existing models like Qwen, especially given its size and the competitive landscape.
Mistral 4 Family Spotted (Activity: 687): The Mistral 4 family introduces a hybrid model that integrates capabilities from three distinct model families: Instruct, Reasoning (formerly Magistral), and Devstral. The Mistral-Small-4 model features a
Mixture of Experts (MoE)architecture with128 expertsand4 active, totaling119 billion parameterswith6.5 billion activated per token. It supports a256k context lengthand accepts multimodal input (text and image) with text output. Key functionalities include configurable reasoning effort, multilingual support, and agentic capabilities with native function calling. The model is open-sourced under the Apache 2.0 License. Mistral-Small-4 is designed for both speed and performance, offering a large context window and vision capabilities. Commenters are enthusiastic about the model’s capabilities, particularly its position in the120 billion parameterrange, comparable to models like gpt-oss-120B and Qwen-122B. There is anticipation for its performance and potential applications.The Mistral 4 model is a hybrid architecture that integrates capabilities from three distinct model families: Instruct, Reasoning (formerly Magistral), and Devstral. It features a mixture of experts (MoE) with 128 experts and 4 active, allowing for 119 billion parameters with 6.5 billion activated per token. The model supports a 256k context length and accepts multimodal input, including both text and images, with text output. It also offers configurable reasoning effort, enabling a switch between fast instant replies and more computationally intensive reasoning modes.
Mistral 4 is designed to be highly versatile, supporting multilingual capabilities across dozens of languages and offering advanced agentic functionalities with native function calling and JSON output. It is optimized for speed and performance, maintaining strong adherence to system prompts. The model is released under the Apache 2.0 license, which allows for both commercial and non-commercial use and modification, making it accessible for a wide range of applications.
The model’s integration with llama.cpp is underway, as indicated by a pull request on GitHub. This suggests that Mistral 4 will soon be supported by llama.cpp, a popular framework for running large language models efficiently. This integration is likely to enhance the model’s accessibility and usability for developers looking to leverage its capabilities in various applications.
Less Technical AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. AI Model and Tool Innovations
INCREDIBLE STUFF INCOMING (Activity: 483): The image presents a slide from a presentation on the NVIDIA Nemotron 3 Ultra Base model, which is approximately
500Bin size. It claims to be the “Best Open Base Model” with5Xefficiency and high reasoning accuracy. The slide includes bar graphs that compare the performance of Nemotron 3 Ultra against other models like GLM and Kimi K2 across various benchmarks, including Peak Throughput, Understanding MMLU Pro, Code HumanEval, Math GSM8K, and Multilingual Global MMLU. The Nemotron 3 Ultra is highlighted for its superior performance in these categories. Commenters express skepticism about the benchmarks, noting that NVIDIA does not specify which GLM model is used for comparison and that the Kimi K2 model is relatively old, being eight months old. There is also a critique of the presentation technique, suggesting that starting the graph at60%exaggerates the performance gap.elemental-mind points out the ambiguity in NVIDIA’s announcement, noting that they don’t specify which GLM model is being referred to. They highlight that the Kimi K2 model, if it’s the base version, is comparable to MiniMax M2.1 and GLM-5-no-reasoning in terms of intelligence, suggesting that the comparison might not be as impressive as it seems.
FullOf_Bad_Ideas clarifies the distinction between base models and their finetuned counterparts. They suggest that the models being compared are likely Kimi K2 Base 1T and GLM 4.5 355B Base, rather than the more advanced K2.5 or GLM 5, which are instruct/reasoning finetunes. This distinction is crucial for understanding the performance and capabilities being discussed.
ThunderBeanage expresses skepticism about the relevance of Kimi K2, describing it as outdated. They doubt that the GLM model mentioned is the latest GLM 5, implying that the comparison might not reflect the current state-of-the-art models. This skepticism highlights the importance of specifying model versions in performance discussions.
2. AI in Creative and Entertainment Applications
Showing real capability of LTX loras! Dispatch LTX 2.3 LORA with multiple characters + style (Activity: 932): The post discusses the creation of a LORA model using LTX 2.3, trained on approximately
440 clipsfrom the game Dispatch, each with121 frameson average. The model includes over6 characterswith distinct voices and styles, achieved by assigning each character a unique trigger word and detailed captions. The training was conducted using the musubi fork by akanetendo25 and involved splitting clips withpyscene, converting them to24 fps, and using a custom captioning tool. The dataset was divided into HD and SD groups based on clip length, and training involved31GB VRAMusage with4 blockswap. The model was trained to64 rankto accommodate the complexity of the data, and checkpoints were made every500 steps. The author notes that LTX, while not as visually strong as WAN, offers significant potential for pre-visualization in game development. One commenter expressed skepticism about WAN 2.5 being open source, while another praised the dedication involved in training with440 clips, noting the clean results.Lars-Krimi-8730 inquires about the technical details of training the LTX 2.3 LORA model, specifically asking about the trainer used, settings, captioning methods, and resolution. This indicates a keen interest in the reproducibility and technical setup of the model training process.
Anxious_Sample_6163 highlights the use of 440 clips in the training process, which suggests a significant level of dedication and effort in data preparation. This number of clips implies a robust dataset that likely contributes to the model’s performance and cleanliness.
SvenVargHimmel asks about the training duration on a
5090GPU, which points to interest in the computational resources and time efficiency of the model training process. This question is relevant for understanding the scalability and feasibility of training similar models.
oldNokia Ultrareal. Flux2.Klein 9b LoRA (Activity: 541): The post announces a retrained version of the Nokia 2MP Camera LoRA, named OldNokia UltraReal, designed to replicate the aesthetic of mid-2000s phone cameras. Key features include a soft-focus plastic lens effect, a washed-out color palette, and digital artifacts like JPEG compression and chroma noise, all trained on the author’s Nokia E61i photo archive. The model is available for download on Civitai and Hugging Face. One commenter humorously notes that Nokia cameras historically lacked the dynamic range depicted in the model. Another suggests training the model on
qwen-imagefor further enhancement, while a third expresses enthusiasm for the LoRA and shares a personal project involving frame injection.jigendaisuke81 suggests training the model on
qwen-image, indicating interest in exploring how the model performs with different datasets or architectures. This could imply a focus on enhancing image generation capabilities or testing the model’s adaptability to various image styles.Striking-Long-2960 mentions an interest in ‘frame injection in Wan2GP’, which suggests a technical exploration of integrating frames into generative models. This could involve manipulating or enhancing image sequences, potentially for video or animation purposes, using the LoRA model.
berlinbaer highlights the technical achievement of the LoRA model in replicating specific visual effects, such as ‘blown out highlights with their blue-red color shift’. This suggests a focus on the model’s ability to accurately mimic complex photographic effects, which might be challenging to achieve through simple prompting alone.
3. AI and Employment Impact
Antrophic CEO says 50% entry-level white-collar jobs will be eradicated within 3 years (Activity: 2162): Anthropic CEO predicts that
50%of entry-level white-collar jobs will be eliminated within the next three years due to advancements in AI technologies. This statement highlights the rapid integration of AI in the workplace, potentially replacing tasks traditionally performed by humans, even when AI solutions like copilot may not yet match human expertise in quality and accuracy. The prediction underscores a significant shift in the job market, emphasizing the need for adaptation and skill evolution among the workforce. A notable comment highlights a personal experience where AI is being used to perform tasks inadequately, leading to errors and incorrect conclusions. This reflects a broader concern about the premature reliance on AI in professional settings, potentially undermining human expertise and job security.Due_Answer_4230 highlights a practical issue with AI integration in workplaces, where AI tools like Copilot are being used to replace human work, even when they perform poorly. This results in errors and incorrect conclusions, yet management may prefer AI for its speed, undermining skilled workers who have invested years in developing their expertise.
Stahlboden references a prediction from a year ago that AI would write 100% of code, noting that while this hasn’t fully materialized, AI’s role in coding has significantly increased. This reflects a broader trend of AI’s growing capabilities in technical fields, suggesting a potential future where AI could dominate certain tasks.
Environmental_Dog331 points out the lack of solutions from AI leaders regarding job displacement due to AI advancements. The comment underscores the challenge of creating new jobs at a pace that matches AI-driven job losses, highlighting a critical gap in strategic planning for workforce transitions.
NBC News survey finds Americans hate AI even more than ICE (Activity: 1146): An NBC News survey reveals that only
26%of voters have a positive view of AI, while46%hold negative views, making AI less favorable than most topics except the Democratic Party and Iran. This reflects a broader skepticism towards AI, despite its widespread use and potential as a productivity tool. The survey highlights a disconnect between AI’s perceived capabilities and its actual utility, particularly in replacing jobs that require significant industry knowledge. Commenters note a paradox where frequent AI users still harbor resentment due to overhyped claims about AI’s capabilities, particularly its potential to replace white-collar jobs. There’s a consensus that while AI is a powerful tool, it is not yet capable of replacing jobs requiring deep industry knowledge.TimeTravelingChris highlights the gap between AI’s potential and its current practical applications, noting that while AI can be a powerful productivity tool, it is not yet capable of replacing jobs that require significant industry and company knowledge. The commenter emphasizes the importance of validating AI outputs, as the technology still has notable gaps when scrutinized closely.
AlexWorkGuru discusses the disparity between AI’s potential as demonstrated by labs and the everyday experiences of users, which often involve frustrating interactions with basic AI implementations like chatbots and automated phone systems. This gap contributes to a credibility issue for AI, as the companies promoting it are often those that users already distrust, exacerbating negative perceptions.
bjxxjj points out that public perception of AI is heavily influenced by negative associations such as job layoffs and surveillance, rather than practical applications like educational chatbots. This suggests that survey results on AI sentiment may be skewed by the specific aspects of AI that respondents are considering.
AI Discords
Unfortunately, Discord shut down our access today. We will not bring it back in this form but we will be shipping the new AINews soon. Thanks for reading to here, it was a good run.
Discord doing stupid shit? Most unsurprising thing in the read.