

[AINews] Claude Sonnet 4.6: clean upgrade of 4.5, mostly better with some caveats
Anthropic notches another W.
AI News for 2/16/2026-2/17/2026. We checked 12 subreddits, 544 Twitters and 24 Discords (261 channels, and 11323 messages) for you. Estimated reading time saved (at 200wpm): 1096 minutes. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
Despite a lot of rumors of a “Sonnet 5”, Anthropic opted to launch Sonnet 4.6 today, bumping their cheaper workhorse model up to match Opus 4.6, touting some preference wins from Sonnet to 4.5 Opus and a 1m token context, though generally lagging in usual benchmarks, and on GDPVal-AA (explained in our podcast with them) it uses 4.5x more tokens so the all-in cost can be higher than Opus in some tasks. The API platform tools and the Excel integrations also got minor upgrades.

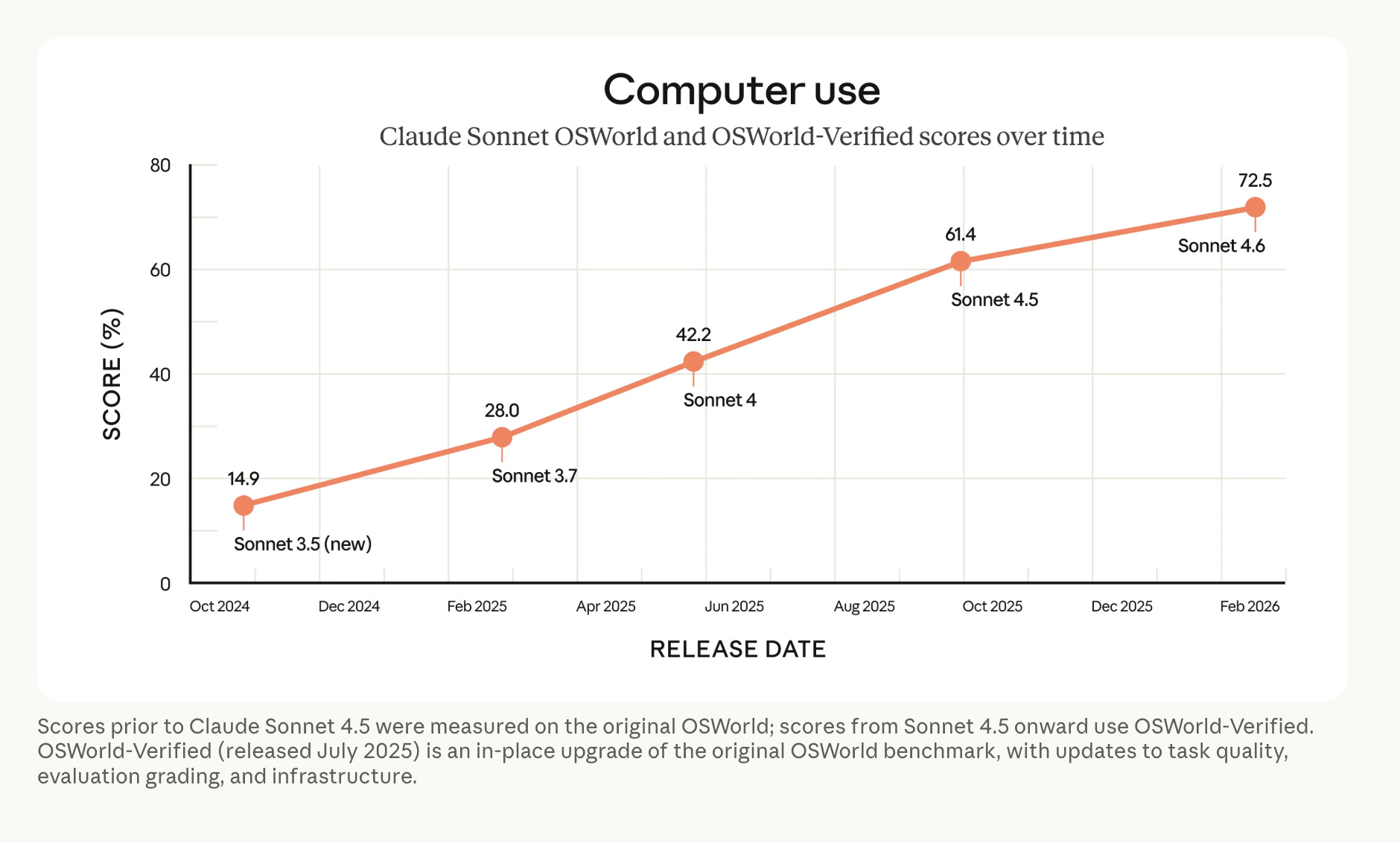
Some of the key highlights are the long term improvements in Computer Use, first launched in Oct 2024, which was at launch completely slow and so inaccurate as to be impractical, but now is productized as Claude Cowork, which has anecdotally seen more successful adoption than OpenAI’s equivalent Operator and Agent iterations.
We have tuned the Twitter recap below to include more datapoints, but really that’s all that you truly need to know.
AI Twitter Recap
Top Story: Sonnet 4.6 launch
What happened (timeline + headline claims)
Anthropic launched Claude Sonnet 4.6 as an upgrade to Sonnet 4.5, positioning it as their most capable Sonnet model with broad improvements across coding, computer use, long-context reasoning, agent planning, knowledge work, and design, plus a 1M-token context window (beta) [@claudeai]. Early chatter preceded the announcement (“Sonnet 4.6 incoming!”) [@kimmonismus], then the launch triggered a wave of benchmark callouts, tooling/platform integrations (Cursor, Windsurf, Microsoft Foundry, Perplexity/Comet, etc.), and mixed early user feedback about quality and reliability.
Official announcement + feature list + 1M context (beta) [@claudeai]
Anthropic employee framing: “approaching Opus-class… insane jump over 4.5” [@alexalbert__]
Independent eval org update: Sonnet 4.6 leads GDPval-AA ELO (agentic knowledge work), with much higher token use than 4.5 [@ArtificialAnlys]
Pricing claim: “same pricing as Sonnet 4.5” [@kimmonismus]
Post-launch “regression?” report: hallucinated function names / broken structured outputs; later “seems fixed” [@rishdotblog], [@rishdotblog]
Factual / checkable claims
Sonnet 4.6 is described by Anthropic as a full upgrade across multiple capability areas and includes a 1M token context window in beta [@claudeai].
Benchmark datapoints cited:
79.6% SWE-Bench Verified, 58.3% ARC-AGI-2 (as posted) [@scaling01].
“Users preferred Sonnet 4.6 over Opus 4.5 59% of the time” [@scaling01].
“Sonnet 4.6 the best model on GDPval” (claim) [@scaling01].
Artificial Analysis (independent benchmarking org) claims:
Sonnet 4.6 reached GDPval-AA ELO 1633 (in “adaptive thinking mode” and “max effort”), and is #1 on their GDPval-AA leaderboard but within the 95% CI of Opus 4.6 [@ArtificialAnlys].
Token usage to run GDPval-AA: Sonnet 4.6 used 280M total tokens (vs Sonnet 4.5 58M); Opus 4.6 used 160M in equivalent settings [@ArtificialAnlys].
Sonnet 4.6 improved aesthetic quality of generated docs/presentations relative to 4.5 on GDPval-AA outputs [@ArtificialAnlys].
Tooling update: Anthropic web search/fetch tools now execute code to filter results; reported effect: +13% accuracy on BrowseComp with 32% fewer input tokens when enabled (as posted) [@alexalbert__].
Opinions / interpretations (what’s not settled)
“Approaching Opus-class capabilities… insane jump” [@alexalbert__] is qualitative framing (though consistent with some benchmark movement).
“Near human-level computer use” extrapolation [@alexalbert__] depends strongly on which “computer use” evals + harnesses + task distributions are used.
“Warmer and kinder… smarter and more overcaffeinated” is pure UX vibe [@sleepinyourhat].
“Taste is off the charts” / SVG skyline anecdote is subjective (but points to improved design/visual generation) [@scaling01].
Post-launch reliability concerns (“hallucinations everywhere… 4.6 crapping the bed”) are anecdotal reports from a specific workflow, though notable because they compare to 4.5 on the “same tasks” [@rishdotblog].
Technical details extracted (numbers, benchmarks, systems implications)
Core model/product knobs surfaced in tweets
Context window: 1M tokens (beta) [@claudeai].
Pricing: “same pricing as Sonnet 4.5” [@kimmonismus] (no $/tok quoted directly in these tweets, but note RundownAI cites “Sonnet pricing [$3/$15 per mil tokens]” as context [@TheRundownAI]).
Search/fetch tool change: pre-context filtering via executable code; +13% BrowseComp accuracy, -32% input tokens [@alexalbert__].
Systems read: this is an explicit shift toward tool-side “compute before context”—spending tool compute to reduce prompt budget and improve signal-to-noise in retrieved context.
Benchmarks and what they suggest (with caveats)
SWE-Bench Verified 79.6% (posted) [@scaling01].
Interpretation: SWE-Bench Verified is sensitive to harness, timeouts, repo setup, and tool reliability. Still, 79.6% is “frontier-tier” in the common discourse.
ARC-AGI-2 58.3% (posted) [@scaling01].
Also see longitudinal claim: “141 days… 13.6% to 60.4% on ARC-AGI-2” (Sonnet line progress, presumably 4.5→4.6 or earlier→now) [@scaling01].
Preference eval: “preferred over Opus 4.5 59%” [@scaling01].
GDPval-AA (Artificial Analysis): ELO 1633, #1 but statistically overlapping Opus 4.6; token usage 280M for Sonnet 4.6 vs 58M for Sonnet 4.5; cost to run GDPval-AA “just ahead of Opus 4.6” (because of token usage) [@ArtificialAnlys].
Important implication for engineers: “Best” may be bought with more thinking tokens, which impacts latency and spend; a router may pick 4.6 selectively.
Vending-Bench Arena strategy claim: with 1M context, Sonnet 4.6 uses a “capacity-first then profitability pivot” plan [@felixrieseberg].
This is a rare example of a behavioral shift attributed to long-context planning capacity, but it’s still a single benchmark anecdote.
Cost/latency + throughput signals
Engineers are explicitly noticing that frontier labs “blast millions of tokens… scaffold like a skyscraper” [@scaling01], aligning with Artificial Analysis’ disclosure that Sonnet 4.6 needed ~4.8× the tokens of Sonnet 4.5 on GDPval-AA [@ArtificialAnlys].
Cursor’s note: Sonnet 4.6 better on “longer tasks” but “below Opus 4.6 for intelligence” [@cursor_ai] suggests practical routing: Sonnet 4.6 as default long-horizon workhorse; Opus as max-capability.
Different perspectives in the dataset
Strongly positive / “this is a big jump”
Anthropic-side: “most capable Sonnet… full upgrade… 1M context” [@claudeai] and “approaching Opus-class… jump… insane” [@alexalbert__].
Benchmark boosters: SWE-Bench/ARC-AGI-2 callouts [@scaling01], GDPval best-model claim [@scaling01], “crushes Gemini 3 and GPT-5.2 on Vending-Bench 2” [@scaling01].
Practitioners: “beast for real-world work… computer usage” [@kimmonismus], “computer use standout… more consistent over long sessions” [@mikeyk].
Neutral / adoption & positioning notes
“no Sonnet 5” reaction [@dejavucoder] reflects expectations management rather than capability.
Cursor’s measured product note (better than 4.5, below Opus 4.6) [@cursor_ai].
Artificial Analysis: #1 GDPval-AA but within CI of Opus 4.6 + disclosure that it uses more tokens [@ArtificialAnlys].
Negative / skeptical / “something broke”
Reliability regression report: hallucinated function names in agent workflows; structured output errors; “4.5 still works great” [@rishdotblog]. Follow-up: “Whatever this was seems fixed!” [@rishdotblog].
Cost sensitivity: “Sonnet and Slopus… munching through my credits” [@scaling01], plus later “price hurts” / cost follow-ups (not fully detailed in provided snippet) [@scaling01].
A comparative take in infra/product terms: “50% more expensive than xhigh and 228% over 5.2 codex… vast improvement over 4.5” [@teortaxesTex]—this frames Sonnet 4.6 as improved but potentially cost-inefficient vs alternatives depending on workload.
Context: why Sonnet 4.6 matters (engineering implications)
Long-context is becoming “operational,” not just a spec.
The launch pushes a 1M token window into the Sonnet tier [@claudeai]. But Artificial Analysis’ disclosure that Sonnet 4.6 used 280M tokens to run GDPval-AA in “adaptive thinking/max effort” configs [@ArtificialAnlys] is a reminder: long-context + long-think can silently move your budget envelope. Expect more routing, summarization, context management, and “retrieve then filter” patterns (consistent with the new search/fetch filtering improvement [@alexalbert__]).Agent performance claims are increasingly harness-dependent.
GDPval-AA uses an agentic harness (shell + browsing loop), and Sonnet 4.6’s lead is reported under a specific setup (“adaptive thinking mode”, “max effort”) [@ArtificialAnlys]. Cursor’s note that it’s better on longer tasks but below Opus for raw intelligence [@cursor_ai] reinforces that “best model” is not a scalar; it’s workload × harness × budget.Computer use is becoming a marquee capability, and Sonnet is being pushed there.
Multiple tweets highlight “computer use” progress and near-human-level framing [@alexalbert__], and deployments like Perplexity’s Comet browser agent explicitly default to Sonnet 4.6 for Pro users [@comet].Release risk: small serving/config changes can look like “model regressions.”
The reported post-launch hallucination spike across Opus 4.6 and Sonnet 4.6 [@rishdotblog]—and then “seems fixed” [@rishdotblog]—reads like a potential routing, toolchain, system prompt, or safety-layer change rather than weights. For teams: pin versions where possible, run canary evals, and monitor structured output validity + tool-call correctness separately from “chat quality.”
Other Topics (standard coverage)
Open models & independent benchmarking (Qwen/GLM/Seed/Aya, etc.)
Artificial Analysis deep breakdown of Qwen3.5-397B-A17B (397B total / 17B active MoE, Apache 2.0, 262K ctx, native multimodal); big gains on agentic evals, but hallucination rate still high by their metric [@ArtificialAnlys].
GLM-5 cited as strong open model on WeirdML and other benches (48.2% WeirdML; comparisons to Opus/gpt-* claims) [@htihle], plus GLM-5 technical report highlights: DSA adoption, async RL infra, agent RL algorithms [@Zai_org].
ByteDance “Seed-2.0” announced (agent/reasoning/vision; “no distillation”; CN-only initially) [@TsingYoga].
Cohere Labs launched Tiny Aya: 3.35B open multilingual model family (70+ languages; “runs on a phone”), with claims of training on 64 GPUs and a detailed report [@nickfrosst], [@_akhaliq], [@mziizm].
Agents, harnesses, memory, and long-horizon infrastructure
“Agent World Model (AWM)” proposes fully synthetic executable environments (1,000 envs, 35,062 tools, 10,000 tasks, SQL-backed state, verification code) for RL tool-use agents [@dair_ai].
Lossless Context Management (LCM) / Volt claims: deterministic hierarchical DAG compression with lossless pointers; on OOLONG, “beats Claude Code at every context length 32K→1M” (reported) [@dair_ai], amplified [@omarsar0].
Moltbook multi-agent “society” study: 2.6M LLM agents, 300k posts, 1.8M comments; macro “culture” stabilizes, micro influence ~noise; critique of “just add agents” assumptions [@omarsar0].
LangChain “Harness Engineering” theme: traces → eval mining → self-verification loops; TerminalBench positioning [@Vtrivedy10], plus LangSmith Insights scheduling [@LangChain].
Open-sourcing an agent runtime (“Hankweave”) focused on removing context, maintainability, and reusable blocks across models [@hrishioa].
Systems & inference optimization (kernels, scheduling, throughput)
Carmack proposes OS-like GPU job preemption via UVM paging + MPS shim, aiming for seconds-scale task switching (acknowledges thrash risk) [@ID_AA_Carmack].
Moondream MoE kernel: 2.6% faster by tuning launch config to real routing distributions; kernel ~37% runtime [@vikhyatk].
Together-style “ThunderAgent” / “program abstraction” for end-to-end agent workflow scheduling; claims up to 3.9× faster rollout/serving without quality tradeoff (as posted) [@ben_athi], plus explanation thread [@simran_s_arora].
Frontier product moves: Codex, Grok, “computer use” competition
Codex usage report: users trying (and failing) to hit limits; heavy parallel agent usage within subscription windows [@theo].
OpenAI infra hiring pitch (agent orchestration, sandboxes, observability) [@gdb].
Grok 4.20 / 4.x discussion includes launch notices and architecture claims, plus highly polarized political framing by Elon [@kimmonismus], [@elonmusk], with critics calling performance weak vs “Flash” models [@teortaxesTex].
Robotics, video/image generation, and multimodal research
Unitree humanoid performance discourse (claims of distributed coordination, terrain adaptation, safety spacing, multi-DOF manipulation) [@ZhihuFrontier].
“Perceptive Humanoid Parkour” (depth-perception long-horizon traversal) [@zhenkirito123].
ByteDance BitDance: 14B AR image generator predicting binary visual tokens; claims FID 1.24 on ImageNet 256 [@iScienceLuvr], plus author promo [@multimodalart].
“Sphere Encoder” few-step image generation in spherical latent space; Meta/Goldstein thread with details including 65K latent dims for ImageNet and <5-step refinement [@tomgoldsteincs].
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
Keep reading with a 7-day free trial
Subscribe to Latent.Space to keep reading this post and get 7 days of free access to the full post archives.