

[AINews] Cognition raises $1B in $26B Series D
coding is an uncapped TAM market
We last wrote about Cognition in September’s $10B Series C when Smol.ai also joined Cognition and AINews was eventually moved here to Latent Space. 8 months later, it is worth 2.5x more, and officially the largest remaining independent agent lab in AI, a thesis we mapped out last year. With official ARR disclosures (now projecting >$1B ARR by EOY) you can map out the growth, which looks oddly similar to the WTF Happened in 2025 charts (this isn’t a coincidence):
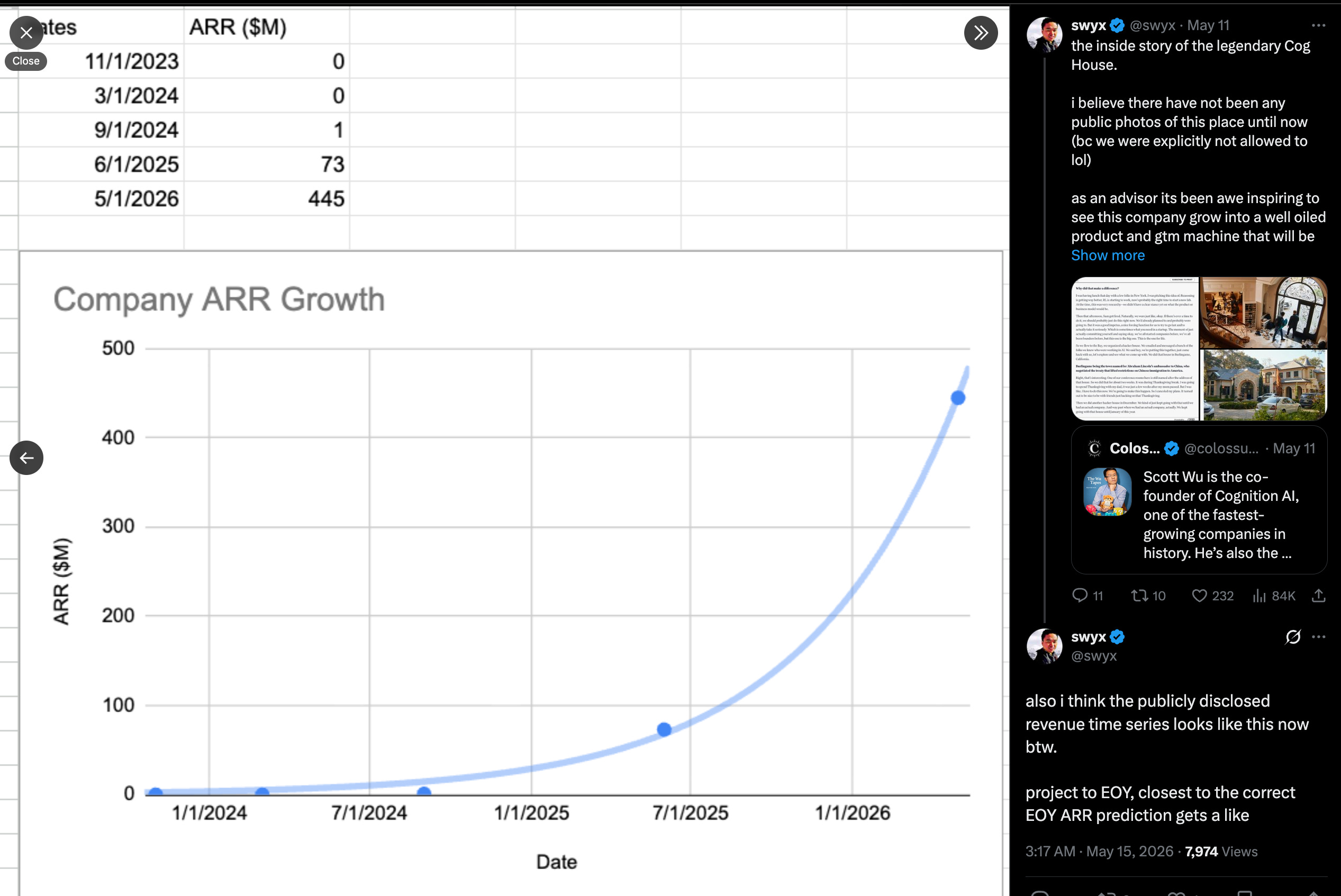
In the enterprise SaaS business, ARR is a trailing indicator of utilization, as are the logos of some of the toughest/most discerning customers in the enterprise and startup ecosystem (including Exa and Modal, featured last week)
We will release more on the Cognition podcast tomorrow.
AI News for 5/26/2026-5/27/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
Inference Efficiency, Serving Architectures, and Cost Curves
Inference optimization is increasingly architectural, not just kernel-level: EAGLE 3.1 improves speculative decoding robustness by stabilizing hidden-state feedback and reducing attention drift at deeper decode steps, with explicit emphasis on long-context acceptance length and real-world serving reliability; the team also highlighted collaboration with vLLM and TorchSpec. At the kernel/system layer, Perplexity open-sourced a rebuilt Unigram tokenizer that cuts CPU utilization 5–6× and reaches 63 µs at 514 tokens with zero heap allocations, while Qwen3.5 on TokenSpeed reportedly hits 580 tokens/s for agentic workloads via joint optimization across Alibaba, LightSeek, NVIDIA, Mooncake, and FlashAttention-4 contributors. Supporting libraries also improved: MaxSim v2 adds backprop and reports 10.33× faster on H200 and 11.94× on A100 versus naïve PyTorch.
Price cuts are being justified by structural KV-cache and attention changes: Several posts converged on the same theme: recent API price cuts from Chinese labs look sustainable because they reflect lower serving cost per token, not temporary subsidy. @kimmonismus summarized how DeepSeek V4-Pro uses hybrid attention with Compressed Sparse Attention and Heavily Compressed Attention to bring 1M-token KV cache to ~10% of V3.2 and single-token inference FLOPs to 27%, while still routing 49B active params out of 1.6T total. Xiaomi’s MiMo similarly reduces cache traffic using SWA plus hierarchical cache management. That was corroborated directly by @_LuoFuli, who said MiMo’s deepest input-cache-hit price cut comes from 5× cached token capacity, roughly 80% lower caching cost, and an architectural 1:7 Full:SWA sparsity ratio. The broader takeaway: long-context inference economics are now being pushed by attention design + cache hierarchy + routing, not just cheaper hardware.
Agents, Harnesses, Memory, and Continual Learning
The stack is shifting from “model quality” to “model-harness-memory fit”: A substantial cluster of tweets focused on practical agent engineering. LangChain shipped Deep Agents v0.6 with Delta Channels, cutting checkpoint storage for a 200-turn coding session from 5.3 GB to 129 MB, and also launched computer use in Fleet, plus Context Hub for versioned agent context/skills. LangSmith Engine was framed as automating the eval → diagnosis → fix loop, with multiple practitioners emphasizing its value for turning trace feedback into reusable online/offline evaluators. In parallel, @Vtrivedy10 made the clearest formulation of the day: task-harness fit matters as much as model quality, and bespoke vertical systems outperform generic harnesses by narrowing tools, prompts, and context to the task.
Continual learning is re-emerging as a product category, not just a research topic: The biggest announcement here was Trajectory’s launch: a platform for using product usage signals and agent traces to continuously post-train large agentic models, with $15M in funding and design partners including Clay, Harvey, Decagon, Mercor, and Rogo. Baseten said it supports these deployments with FP8/NVFP4 quantization and autoscaled H100 infra, including a cited overnight deployment of a 397B-parameter model. The same trend appeared in open tooling: an open-source memory-centric agent built on LangChain/LangGraph was praised by multiple builders for explicit retrieval/storage/reasoning/learning separation, and RLM’s minimal training harness shows small teams can now RL-tune long-context agents in a day on 8×A100. The throughline is that “post-deployment learning” is moving from aspiration to infra.
Benchmarks, Scaling Laws, and Training Methods
New benchmarks are increasingly about long-horizon, messy, real-world workflows: DeepSWE was highlighted as a SWE/agent benchmark with 113 tasks across 91 repos in 5 languages, using a minimalist bash-only harness and shorter prompts that nevertheless require 5.5× more code and touch 7 files on average than SWE-Bench Pro. In enterprise operations, Artificial Analysis and IBM launched ITBench-AA, an SRE benchmark over Kubernetes incident response where all frontier models scored below 50%; Claude Opus 4.7 led at 47%, GPT-5.5 followed at 46%, and GLM-5.1 Reasoning led open weights at 40%. Another useful reliability angle came from AgingBench, which frames deployed agent degradation as a lifespan problem caused by compression, interference, and memory updates.
Training efficiency research remains active across both theory and systems: Sakana AI’s DiffusionBlocks was one of the most technically interesting releases: it reinterprets forward passes as diffusion-like denoising steps so deep nets can be trained one block at a time, dramatically reducing memory while matching end-to-end performance across ViTs, DiTs, masked diffusion, autoregressive transformers, and recurrent-depth transformers. On the RL systems side, Snowflake introduced ZoRRo, claiming up to 3.5× faster long-context RL and 3.2× longer context windows by eliminating redundant rollout computation, alongside the specialized Arctic-Text2SQL-R2 enterprise SQL model. On the theory front, Tiberiu Musat’s preprint argues minimum neural weight norm matches minimum program length up to a log factor for fixed-precision networks, while Unified Neural Scaling Law proposes a multivariate functional form intended to extrapolate neural scaling behavior more accurately than prior fits.
Model and Modality Releases: Biology, Vision, OCR, and Embedded AI
Protein modeling had a standout day: ESMFold2 was announced as an open scientific engine for protein structure prediction and design, with strong reported results on protein interactions and antibodies, plus an accompanying atlas of 6.8B proteins and 1.1B predicted structures. The release emphasized both practical design outcomes—miniprotein binders and single-chain antibodies across five therapeutic targets—and mechanistic interpretability findings about emergent protein representations. The release was echoed by @proteinrosh and contextualized by @cgeorgiaw, who noted the atlas exceeds AlphaFold DB in scale.
A wave of smaller but practical multimodal/open releases landed: Google DeepMind shared the white paper for Gemini Embedding 2, described as a native multimodal embedding model supporting unified representations over text, image, audio, and video. NVIDIA’s LocateAnything combines Qwen2.5-3B + Moon-ViT for high-speed grounding, with a claimed 10× speedup for dense object detection. Hugging Face integrated Roboflow’s RF-DETR, positioning it as real-time detection/segmentation that outperforms YOLO-style systems. For document pipelines, Surya OCR 2 ships as a 650M model with 83.3% OLMOCR bench, 87% on an internal 91-language benchmark, and 5 pages/s on RTX 5090; LiteParse v2 rewrites parsing in Rust for up to 100× speedups and edge/browser deployment via WASM. On-device AI also got a nod with Google’s new Coral board for local speech, vision, and control demos.
Developer Platforms, Enterprise Controls, and Coding-Agent Productization
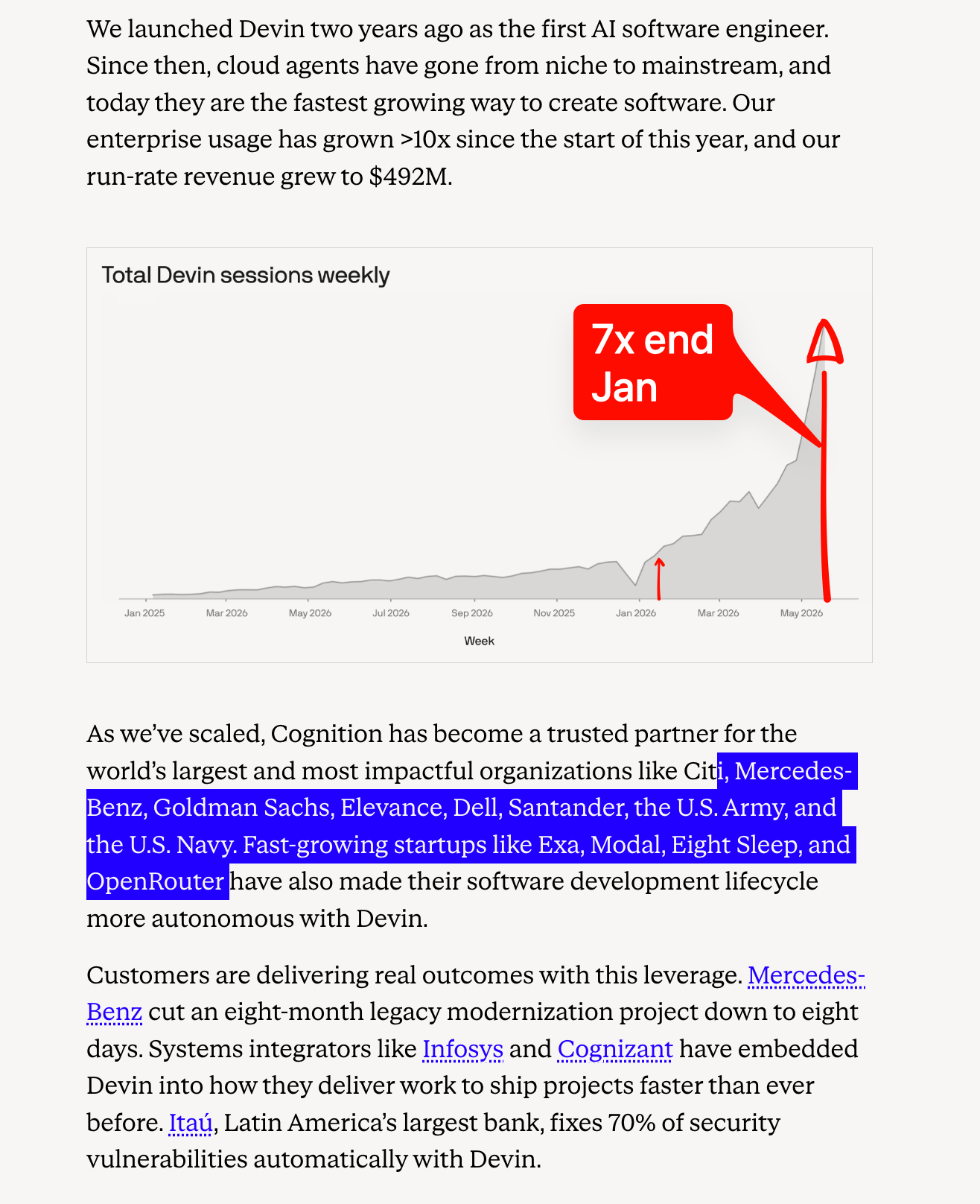
Coding agents are consolidating into full product stacks with enterprise controls: OpenAI continued tightening Codex’s product surface: GPT-5.2 and GPT-5.3-Codex are being sunset in Codex in favor of GPT-5.5, while enterprise features now include private MCP connectivity over outbound-only HTTPS, Workload Identity Federation, and expanded Admin API controls for spend alerts, allowlists, retention policies, and hosted tool management. OpenAI also published a concrete case study on self-improving tax agents with Codex, centered on tracing reviewer corrections back into evals and fixes.
Competition in coding agents is now visibly about reliability, workflow breadth, and enterprise adoption: Claude Code shared a reliability/performance update and easier bug-report capture, while GitHub kept pushing the “agentized IDE” direction with Copilot Dev Days and MCP positioning. The biggest commercial datapoint was Cognition: >$1B raised at a $26B valuation, enterprise usage up >10× YTD, and $492M run-rate revenue, paired with a growing customer list and strong endorsements from users like Exa. Meanwhile, smaller infra/product moves suggest the ecosystem is broadening: Cua Driver for Windows brings background computer use to Windows agents; Cloudflare’s agent platform was repeatedly praised for “fractional computing” economics; and Grok Build’s worktree support targets multi-agent code swarms at repo scale.
Top tweets (by engagement)
Cognition’s scale-up: Cognition announced >$1B raised, $26B valuation, and $492M run-rate revenue, one of the clearest signals yet that coding agents are converting into large enterprise businesses.
Claude Code reliability push: Anthropic’s ClaudeDevs posted a high-engagement update on responsiveness, reliability, and better feedback collection—evidence that product quality and trust are now central battlegrounds.
Sakana AI’s DiffusionBlocks: @hardmaru drew major attention to block-wise training that can match end-to-end performance while dramatically lowering memory requirements.
ESMFold2 release: @alexrives announced one of the day’s most substantive science releases: open protein modeling at atlas scale with therapeutic design implications.
OpenAI enterprise controls + MCP: @OpenAIDevs on private MCP and related admin/security updates reflects where frontier APIs are competing for large-org adoption.
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. Low-Bit Local AI on Consumer Hardware
PrismML just released Binary and Ternary Bonsai Image 4B: 1-bit/ternary text-to-image diffusion transformers that can even run 100% locally in your browser on WebGPU. (Activity: 759): PrismML released Binary and Ternary Bonsai Image 4B, described as
1-bit/ternary text-to-image diffusion-transformer variants with ~3GBcheckpoints, Apache-2.0 licensing, and a WebGPU browser demo (HF collection, demo). The post compares them to FLUX.2 Klein 4B at ~16GB; a top technical comment claims Bonsai Image is primarily a quantized/post-trained derivative of FLUX.2 Klein 4B, with insufficient attribution outside the whitepaper. The main debate is attribution/branding: one commenter argues PrismML is rebranding quantized/fine-tuned base models as “Bonsai” while minimizing credit to original labs, comparing it to releasing a quant of Qwen as a new model. Another commenter asks whether it can run on CPU with16GBRAM, but no technical answer is provided in the supplied comments.A commenter alleges PrismML’s “Bonsai-Image” is not a newly trained base model, but a binary/ternary quantization of
FLUX.2 Klein 4Bwith additional post-training to recover quality. They argue the project’s HF demo/model pages and GitHub omit clear attribution to the original FLUX model/team, with the original model reportedly mentioned only in the whitepaper.A technical usability note says the browser/WebGPU model requires roughly
~2 GBto download, which is relevant for fully local inference despite the 1-bit/ternary compression claims. Another user asks whether it can run on CPU with 16 GB RAM, but no concrete benchmark or compatibility answer is provided in the thread.
Got tired of OOM errors on my 4GB GPU. Wrote a custom Rust bare-metal engine and hit 66.8 TPS with a 4B model (BitNet 1.58b on RTX 3050). (Activity: 390): OP claims a custom Rust/C++ LLM inference engine, Cluaiz, runs
prism-ml/Bonsai-4B-ggufwith1.58-bitquantization on an RTX 3050 4GB, reaching66.8 tokens/s, and reports~30–33 TPSfor Gemma/Qwen 4B variants without OOM via dynamic KV-cache management. No reproducible repo or benchmark artifacts were provided in the post yet; commenters pointed to the apparent project links (GitHub, site) and questioned vague claims like “direct-to-silicon” access, noting this may simply mean ahead-of-time native compilation rather than any unusual GPU/driver-level mechanism. The attached Reddit video could not be independently accessed due to RedditHTTP 403restrictions. Top comments were strongly skeptical, characterizing the writeup and repo language as pseudo-technical/AI-generated and arguing the stated achievements amount to basic native compilation plus a single-machine demo. Commenters also challenged the project’s licensing/copyright wording under Apache 2.0 and asked for concrete implementation details behind the claimed low-level hardware access.Commenters challenged the technical claims in the linked repo (github.com/cluaiz/cluaiz, cluaiz.com), arguing that descriptions like “direct silicon access”, “bare-metal engine,” and “copyrighted Apache licensed software” appear to be marketing or LLM-generated pseudo-technical language rather than concrete implementation details. One commenter asked whether “direct silicon access” merely means ahead-of-time native compilation in Rust, rather than any real low-level GPU programming beyond normal CUDA/driver APIs.
Several commenters argued that the claimed outcome should be compared against existing tooling, especially llama.cpp, which already supports low-memory inference and quantized models on consumer GPUs. The critique was that OOM issues on a
4GBRTX 3050 are often solvable through proper llama.cpp configuration rather than writing a new engine, so the claimed66.8 TPSwith a4BBitNet 1.58b model needs reproducible benchmarks and configuration details to be meaningful.
2. Qwen 3.5/3.6 Local Model Releases and Coding Tests
Qwen3.5 35B A3B uncensored heretic Native MTP Preserved is Out Now With the Full 785 MTPs Preserved and Retained, Available in Safetensors, GGUFs. NVFP4, NVFP4 GGUFs and GPTQ-Int4 Formats (Activity: 602): llmfan46 released
Qwen3.5-35B-A3B-uncensored-heretic-v2-Native-MTP-Preserved, a decensored derivative ofQwen/Qwen3.5-35B-A3Bmade with Heretic v1.3.0 / Magnitude-Preserving Orthogonal Ablation-style edits targetingattn.o_proj,attn.out_proj, andmlp.down_proj, while preserving all785native MTP tensors. The model card reports refusals reduced from92/100to14/100, KL divergence0.0487vs base, and MMLU dropping only from84.12%to83.72%over7,021questions; releases include Safetensors, GGUF, NVFP4, NVFP4 GGUF, and GPTQ-Int4 variants. The author argues Qwen3.5 and Qwen3.6 both use theqwen35architecture but are tuned for different regimes—Qwen3.5 for general assistance, Qwen3.6 for agentic/coding—and notes abliteration KL/quality behavior differs substantially between the families. Commenters appreciated the unusual availability of an NVFP4 GGUF build, with one noting they could not find comparable releases even from Unsloth. Another tester agreed with the author’s positioning, describing Qwen3.6 as closer to “3.5 coder+” rather than a simple across-the-board successor to Qwen3.5.One commenter highlighted the practical value of the NVFP4 GGUF build, noting that this format is hard to find elsewhere: “I seriously can’t find anyone else doing that, not even Unsloth.” This is technically relevant because NVFP4 GGUF availability can matter for users targeting newer NVIDIA-oriented low-precision inference workflows while still using GGUF-based runtimes.
A tester compared Qwen3.5 and Qwen3.6, arguing that 3.6 feels more like “3.5 coder+” than a straightforward general upgrade. They suggested the short time between releases makes a broad capability leap unlikely, implying 3.6 may be more specialized toward coding rather than a simple successor to 3.5.
Okay 27B made me a believer (Activity: 541): OP reports that a
27BQwen-family model used via Opencode generated a near-complete HTML5 Breakout-style game in one shot from three reference files describing console APIs, gamepad controls, and a TypeScript shader. The output was immediately playable, with working controls, sound, metadata, save/stat/heartbeat API integration, and only required one follow-up for customization plus one glitch fix; a commenter recommends enabling MTP/speculative decoding with2–3draft tokens for speed. Another heavy user says the model performs best below64Kcontext, degrades noticeably past64K, and “really drops off” after128K, recommending periodic summarization-to-file and session resets for long agentic coding tasks. Commenters characterize the dense27Bas unusually strong for local coding—near-Sonnet class for web-app one-shots—while one user found35B A3Bless capable despite its size/routing advantages. The main caution is that long-context agentic runs can induce loops or “stupidity,” so users should manage context aggressively.A commenter recommended enabling MTP/speculative decoding for better throughput, suggesting an MTP value of
2or3as a practical speed/quality tradeoff. This is a deployment-level optimization rather than a model-quality claim, useful for users running the 27B model locally.One user reported that the 27B model’s effective reasoning quality drops noticeably with long contexts: best below
64Ktokens, degraded past64K, and “really drops off after128K.” Their workaround for long-horizon agentic tasks is to periodically summarize state into a file, restart the harness/session, and reload the summary to recover model quality and avoid loops.A benchmark operator said Qwen 27B was such an outlier that they rechecked their methodology, placing it roughly on par with GPT-5.2 or Sonnet 4.5 in their rankings while noting it struggles at larger context sizes, likely due to parameter-count limits. They linked their data at gertlabs.com/rankings.
Keep reading with a 7-day free trial
Subscribe to Latent.Space to keep reading this post and get 7 days of free access to the full post archives.