

[AINews] Dreamer joins Meta Superintelligence Labs — 9 month retro of Personal Superintelligence
By now we’re pretty used to LS Pod guests going on to great success, but today’s news is fast for even us - Nat and Alex at MSL have execuhired Dreamer just days after we shipped their pod, barely 11 days after we recorded with them:
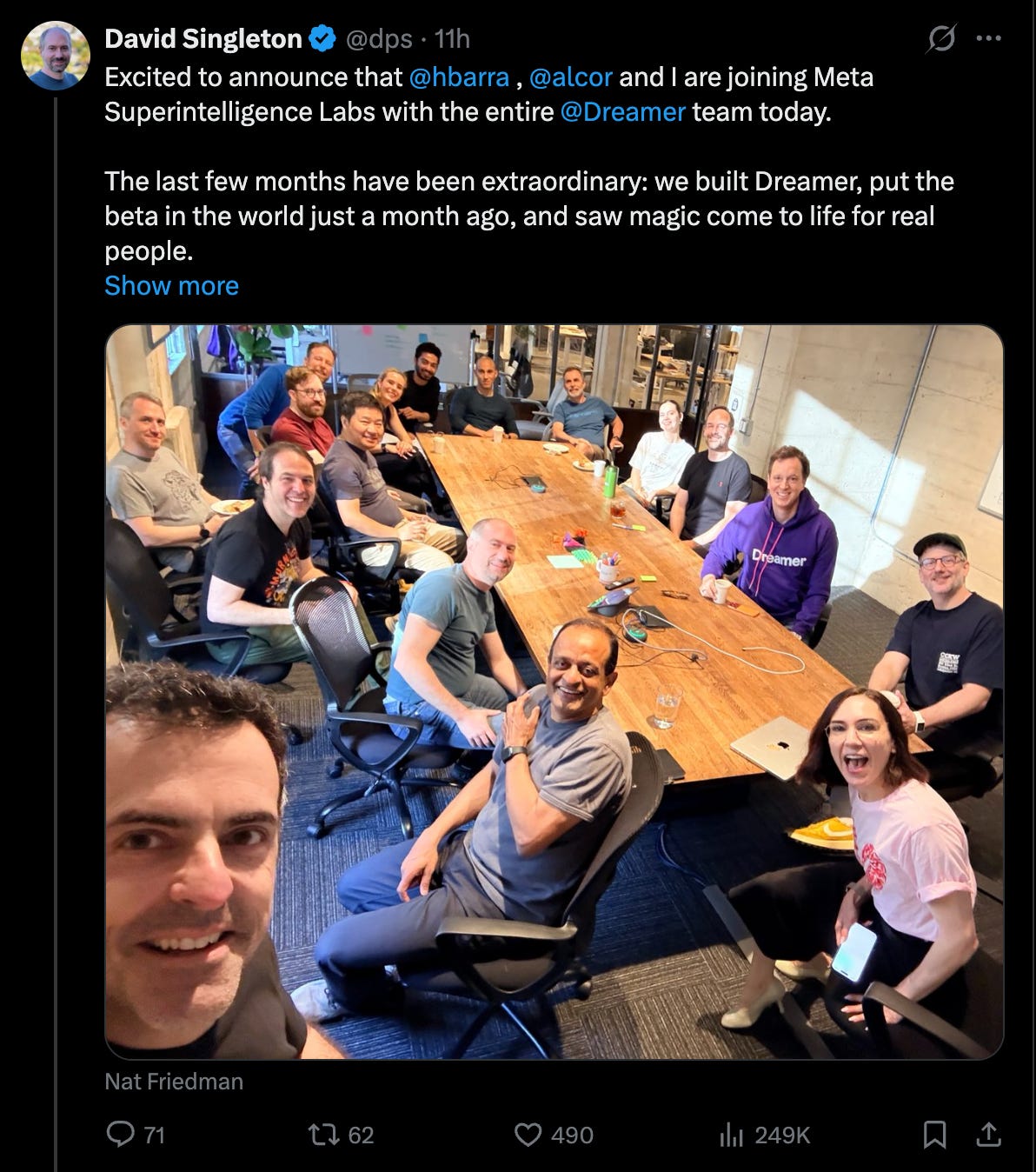
We’re surprised, but not at all disappointed. If you can’t tell from the pod, we were immediately in love with the tech and the polish, but it was always going to be a long slog to build any consumer AI business and it is a very nice thing indeed to have Team Zuck on your side to push consumer distribution.
This is also approximately the 9 month anniversary of the MSL “Personal Superintelligence” Manifesto from Zuck, which reads:
As profound as the abundance produced by AI may one day be, an even more meaningful impact on our lives will likely come from everyone having a personal superintelligence that helps you achieve your goals, create what you want to see in the world, experience any adventure, be a better friend to those you care about, and grow to become the person you aspire to be.
and,
If trends continue, then you’d expect people to spend less time in productivity software, and more time creating and connecting. Personal superintelligence that knows us deeply, understands our goals, and can help us achieve them will be by far the most useful.
Rewatch the Dreamer walkthrough and observe how Sidekick is your personal intelligent agent-of-agents whose main job is the latter sentence:
This execuhire (our term for these licensing+hire-but-not-acquire deals) comes after the $2B Manus acquisition in December, also done in a matter of 10 days, which had similarly impressive tech and decent distribution, though perhaps with less of an “OS” and ecosystem heavy emphasis as Dreamer.
Combining the two teams makes for one of the most formidable consumer agent labs on Earth, and it is pretty clear what kind of talent Nat Friedman is in the market for (if you give him a pass for Vibes). If you are savvy enough… you should be able to tell what other kinds of companies might be up next. (register your predictions in the comments!)
AI News for 3/20/2026-3/23/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
Claude Computer Use, Agent Harnesses, and the Shift From “Codegen” to Full Workflow Automation
Anthropic pushed computer use onto the desktop: Claude can now control the mouse, keyboard, and screen to operate arbitrary apps in a macOS research preview via Claude Cowork and Claude Code, a notable widening of the agent surface beyond APIs and browser sandboxes. The launch landed alongside strong community reactions about not needing a laptop for many tasks anymore and why Anthropic may have skipped acquiring broader external agent stacks in favor of owning the full “do anything on your computer” loop (Claude announcement, Felix Rieseberg, Yuchen Jin, Alex Albert).
The agent stack is converging on long-running, parallel, tool-rich workflows: multiple tweets pointed to a maturing harness layer around coding and ops agents: Hermes Agent momentum and ecosystem curation (awesome-hermes-agent, Teknium tips, open-source vibe shift); T3 Code adding integrated browser and terminal capabilities (T3 Code browser integration, Theo on open-sourcing T3 Code); Command Center and similar orchestration tools for many-agent parallel execution from one workspace (Jimmy Koppel); and Parchi / BYOK workflows for very long-running autonomous tasks (0xSero, Qwen3.5-REAP in Parchi).
Operational reality is now the bottleneck, not just model IQ: several practitioners complained that newer top models can be too eager, over-agentic, or delegated to weaker subagents, hurting real coding workflows; this showed up in complaints about GPT-5.2 Pro subagents, Claude browser/computer use fragility, and the broader critique that superficial parallelization often becomes “slop theater” rather than throughput gains (Mikhail Parakhin, Sarana, Jeremy Howard, bentlegen). A recurring theme: the winning products will likely be those that close the loop with traces, evals, incidents, and production feedback, not just generate code (LangSmith “close the loop”, PlayerZero summary).
Research on Self-Improving Agents, RL Post-Training, and Benchmark Generation
Meta-affiliated work on self-improvement advanced beyond fixed meta-procedures: Hyperagents / DGM-H extends the Darwin Gödel Machine idea by allowing agents to improve not only task behavior but also the procedure that generates future improvements. The claim is that these meta-level improvements transfer across domains including coding, paper review, robotics reward design, and Olympiad grading, addressing a key limitation of prior self-improving systems that kept the self-improvement loop itself hand-authored (Jenny Zhang).
Meta also presented a broader RL post-training unification story: RLLM = RL + LM-as-RM trains a language-model reward model on-policy from the policy’s own outputs, aiming to unify post-training over easy-to-verify, hard-to-verify, and non-verifiable tasks. The notable claim is that using a generative LM reward model can improve reward quality across task classes compared with more brittle bespoke reward setups (Jase Weston).
Benchmark and environment generation is scaling up fast: WebArena-Infinity claims a dramatic reduction in browser environment construction cost—from months of grad-student labor to under 10 hours and <$100 per environment—while producing harder, verifiable browser-use tasks where strong open-source models now score below 50% despite doing much better on legacy WebArena/OSWorld. This matters because RL for agents increasingly needs automatically generated, high-authenticity environments rather than a handful of handcrafted testbeds (Shuyan Zhou).
Topical RL synthesis remained popular, though less novel: a high-engagement overview from The Turing Post catalogued 16 RL variants spanning RLHF, RLAIF, RLVR, process rewards, self-feedback, and critique-based methods—useful as a taxonomy, but the more technically significant tweets this cycle were about how RL environments and reward models are being industrialized (Turing Post RL list).
World Models, JEPA, Mechanistic Interpretability, and Emerging Training Theory
JEPA/world-model work had one of the stronger technical showings of the day: LeWorldModel claims stable end-to-end JEPA training directly from pixels with no teacher-student tricks, no EMA, and no heavy heuristics: 15M params, 1 GPU, and <1 second planning, with follow-on summaries emphasizing ~48–50× planning speedups and competitive performance against prior world-model baselines. This attracted attention because JEPA-style methods have often been seen as fragile or trick-heavy; these results argue for a much simpler training recipe (Lucas Maes, Randall Balestriero, RobotsDigest).
Mechanistic interpretability continues to mature from “vibes” into reverse engineering: a thread summarizing Anthropic’s “On the Biology of a Large Language Model” framed current mech interp as uncovering circuits and internal features with a level of specificity that would have sounded implausible a decade ago, while also cautioning that traced circuits need not correspond to what the model can explicitly verbalize about its own reasoning (summary thread).
Training theory and optimizer scaling also got attention: Antonio Orvieto’s thread argued that optimization theory for adaptive methods explains much of known LLM hyperparameter scaling and can suggest transfer rules without brute-force sweeps, while follow-up discussion highlighted optimizer dependence and implications for Muon-style setups (Orvieto, giffmana reaction, leloykun follow-up). This is one of the more useful undercurrents of the day: people are trying to replace empirical scaling folklore with derivations.
Document Parsing, Retrieval, and Search Infrastructure Became More “Agent-Native”
Document parsing is becoming a serious systems layer, not a side utility: Google Devs and LlamaIndex highlighted a workflow combining LlamaParse + Gemini 3.1 Pro for extracting structured data from difficult financial PDFs, claiming roughly 15% accuracy gains on brokerage statements and complex tables. Separately, LlamaIndex’s new LiteParse targets a lighter-weight parsing path with URL and stream support and no VLM dependency, specifically pitched as something agents can call cheaply and quickly (Google Devs, Jerry Liu, LiteParse).
Search/retrieval infra for coding agents improved materially: Cursor shipped Instant Grep, advertising regex search over millions of files in milliseconds, with a technical writeup on the indexing/algorithm tradeoffs. For agentic coding this kind of primitive matters more than another tiny model gain; search latency directly shapes whether agents can iterate over large repos fast enough to be useful (Cursor announcement, blog link).
Late interaction / multi-vector retrieval is having a moment: the Weaviate/LightOn discussion argued that late interaction systems finally look practical for broader deployment, especially for code and reasoning-heavy retrieval. The core argument: token-level multi-vector representations can still be cheaper and more reusable than full cross-encoders, while materially improving recall and ranking quality for agentic workloads (Connor Shorten podcast, softwaredoug, Amélie Chatelain).
Model and Product Releases: Sakana Chat, MiniMax Plans, Luma Uni-1, NVIDIA Kimodo, and More
Sakana AI made the biggest concrete product launch in the set: it launched Sakana Chat for Japanese users, backed by a new Namazu alpha model family, described as post-trained open models tuned to reduce upstream bias and better reflect Japanese context and values. Sakana positioned this as both a consumer product and a demonstration of culturally localized post-training; the supporting technical blog also tied into its prior work using ensembles plus novelty search to extract narratives from 1.1M social posts in a Yomiuri collaboration on information operations analysis (Sakana Chat, Namazu alpha, Hardmaru on the OSINT workflow).
MiniMax continued to push productization hard: it introduced a flat-rate “Token Plan” covering text, speech, music, video, and image APIs under one subscription, explicitly pitching predictable all-modality billing and compatibility with third-party harnesses. This is notable not because subscription packaging is flashy, but because multimodal API consumption has become operationally annoying enough that simplifying pricing is itself product differentiation (MiniMax Token Plan).
Generative media shipped notable artifacts: Luma’s Uni-1 was pitched as a model that “thinks and generates pixels simultaneously,” while NVIDIA’s Kimodo drew strong engagement as a promptable motion/timeline model trained on 700 hours of mocap, supporting both human and robot skeletons and available on Hugging Face (Luma Uni-1, Kimodo).
Other release notes worth flagging: Hugging Face Kernels 0.12.3 added support for Flash-Attention 4 via
cutlass.cutekernels (Sayak Paul); TRL v1.0.0 claimed up to 44× VRAM savings for long-sequence training with AsyncGRPO on the way (Amine Dirhoussi); and AI2’s MolmoPoint GUI targeted VLM-based GUI automation with grounding tokens rather than coordinate regression, reporting 61.1 on ScreenSpotPro (HuggingPapers).
Top Tweets (by engagement, filtered for technical relevance)
Claude computer use launch: Anthropic’s desktop control feature was the most consequential product release in the set and one of the clearest signs that mainstream assistants are moving from “answering” to operating software directly (announcement).
Cursor Instant Grep: highly engaged because it addressed a real systems bottleneck for coding agents—repo-scale search latency—not just another benchmark increment (Cursor).
Luma Uni-1: major engagement around a model that collapses reasoning and image generation into one product surface, though details remain sparse in the tweet itself (Luma Labs).
Sakana’s narrative intelligence / OSINT workflow: one of the more substantial applied-AI posts, combining LLM ensembles, novelty search, hypothesis generation, and human verification over 1.1M posts (Sakana).
JEPA / LeWorldModel: strong engagement for a compact world model recipe that is much simpler and faster than many expected, and thus potentially more reproducible by ordinary labs (LeWorldModel).
Hyperagents / DGM-H: among the most technically interesting research posts because it targets meta-level self-improvement, not just better task execution (Hyperagents).
Keep reading with a 7-day free trial
Subscribe to Latent.Space to keep reading this post and get 7 days of free access to the full post archives.