

The Agent Labs Thesis
How great Agent Engineering and Research are combining in a new playbook for building high growth AI startups that doesn't involve training a SOTA LLM.
AIE CODE is sold out, but you can watch the livestream, join AIE CODE++ in SF, or Dev Writers Retreat after NeurIPS!
We are on the record as fans of Steph Palazzolo, but we politely disagree with her coining of the term “Neolab”, adopted and boosted by returning guest Deedy Das. For AI Engineer Code Summit we used, for the first time, the term “Agent Lab”, instead.

“Agent Labs” capture an orthogonal trend to Steph’s “Neolabs that exploit new approaches to developing AI models and research that OpenAI and Anthropic have overlooked” (eg Thinking Machines, Humans&, General Intuition, SSI, Reflection and more) and instead covers Cursor ($29B), Perplexity ($20B), Cognition ($10B), Sierra ($10B), Lovable ($2B), Gamma ($2B), as well as older companies with successful AI transitions like Notion ($10B), Vercel ($9B), Glean ($7B), and Replit ($3B), as well as “Agent Labs within Model Labs” like Claude Code ($1B ARR), Codex, and Google Labs.
The problem with “NEOlab” is the same as “NEOcloud” and “MODERN Data Stack” — just being “new” isn’t a business plan or an investment thesis; everybody “Brings Your Own Context” and so agreeing there is as fruitful as building a Tower in Babel.
Agent Labs have their business plan embedded in the name: where Model Labs primarily research and sell models, Agent Labs primarily research and sell agents.

Differences between Model Labs vs Agent Labs
necessary disclaimer: not all agent labs will check these boxes, but I believe they will converge on these best practices over time due to PMF pull/economics.
Product First, Model Last: The “Neolab” way was how Magic.dev raised $100m to work on their long context model. Instead, Cursor forked VSCode first and only after 2 years of understanding user needs, then worked on the model.
Outcome-based Pricing or Marketing: When you are a Model Lab, you are on that 9-900x/year distillation grind, and with not much pricing power token-for-token with the LLM Pareto Frontier (exception for Anthropic!). People complain about and max out your $20/month a subscriptions. When you are an Agent Lab, you can charge $2000/month or per outcome, and as long as the outcomes hold true, you have much higher margins, pricing power, and even growth, because you measurably replace some subsection of human labor.
Approach to autonomy: Model Labs typically want to take control away from the user because they prioritize hours of autonomy, which is easier to test and perhaps on the critical path for pursuing fully autonomous AGI. They emphasize lightweight harnesses (Building Effective Agents and Skills) because they work so closely with the model teams and believe that the next model upgrade might undo harness gains. Agent Labs prioritize speed, auditable/human in the loop control and multiturn interactivity, and don’t mind rewriting the harness every few months for the gains they bring from the future to today.
Evals/metrics/prioritization: (this is a weaker point) charts for Frontier Model Lab models are often 1 dimensional because they are about pushing maximum capabilities (e.g. IMO, IOI) while ignoring cost. Agent labs focus on high volume and practical usage and typically care about the pareto frontier of intelligence/success vs cost. This is a weaker point because of course Model labs care about efficiency too, but it is typically a secondary concern.
This isn’t by any means an authoritative or even well researched diagram, but my theory is that Conway’s Law is the biggest tell — a company’s priorities are demonstrated through its resource allocation of money, people and time. While Model Labs often build Agent Labs internally, and Agent Labs do build Models, if you step back and look at the whole picture you probably get a stark difference:
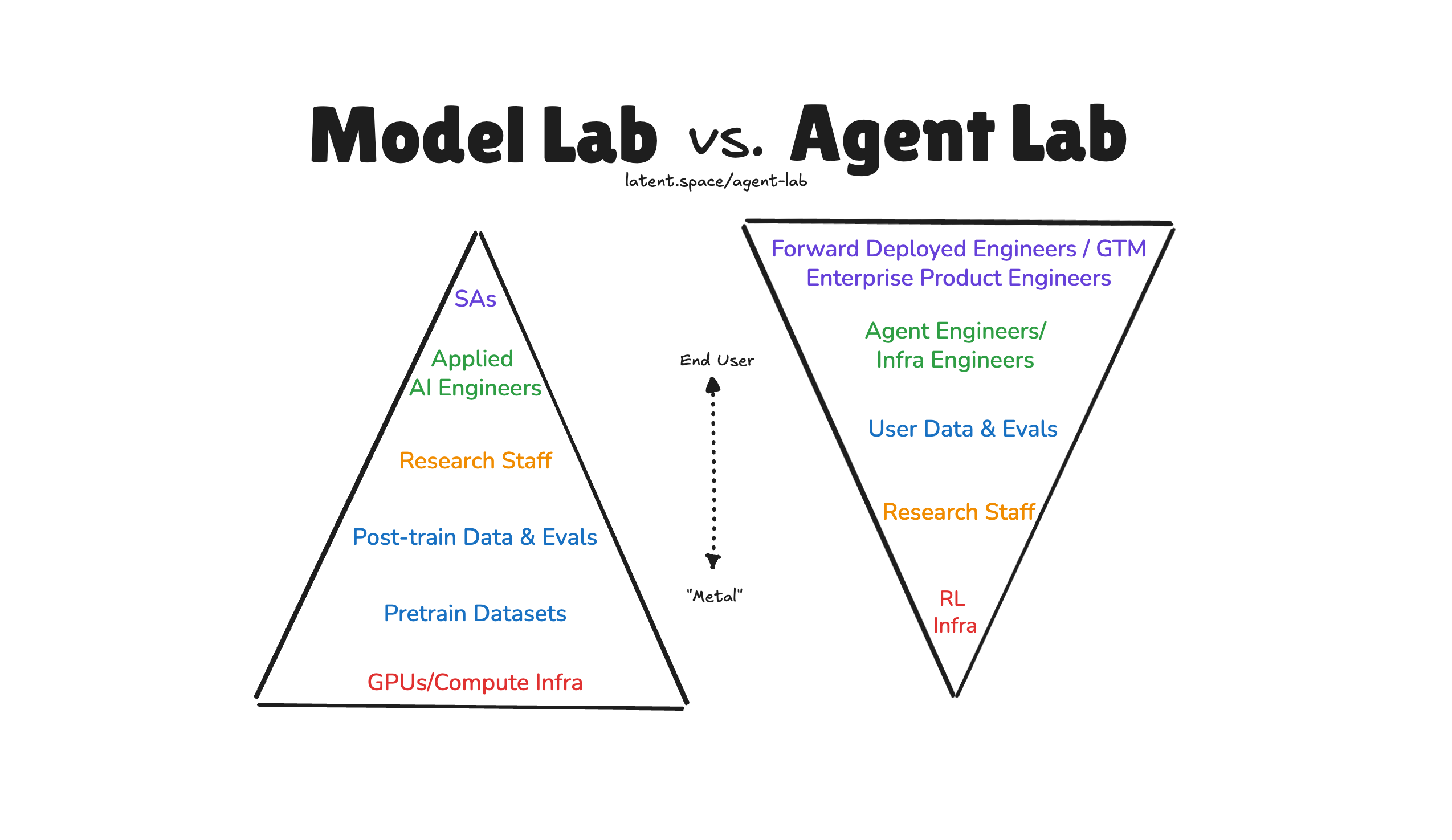
Anecdotally, model labs pay “Applied AI Engineers” roughly half of what they pay "Research staff” (this ratio of course varies WIDELY given the Zuck-shaped skewness in researcher and research-engineer compensation), whereas FDEs and GTMEs can often be the most important people in an Agent Lab which basically lives to maximize learning from customers.
Another “tell” of a non-Agent lab is how willingly they “drop alpha”, aka open source agents — OpenAI recently shared their internal sales assistant, support agent, research assistant, contract data, and GTM. Vercel (which is an AI Cloud that also has an Agent Lab) also recently shared lessons from 5 of their agents, for Support to v0 to code review to leadgen to data analyst. It’s a classic tech strategy play: commoditize your complements. Model Labs will happily teach you how to build Agents for free, Agent Labs will happily abstract away the model selector in favor of task models. Model Labs don’t really sweat the B2B/enterprise needs, Agent Labs do.
A (weaker) tell about Model Labs vs Agent Labs is that acquihired founders have a high rate of leaving Model Labs (identifying recent examples is left as an exercise to the reader), whereas Agent Labs tend to boast how many former founders they have (more product oriented).
While Model (Neo)Labs like Jeff Bezos’ Project Prometheus (raising $6b) and Thinking Machines (raising another $5b!!!) are extremely capital intensive, Agent Labs have better cashflow economics, but you’ll have to wait 10-15 years to see what their exit valuations look like compared to the median Model Lab/Neolab. However we’re starting to see that Agent Labs can competitively hire vs Model Labs — recent examples including Sasha Rush and Less Wright.
It is Open Season for Agent Labs
Two datapoints opened my eyes to the disparity between Model Labs and Agent Labs recently. First, Epoch’s estimates that all Inference compute for OpenAI (all of ChatGPT, all of Sora, all of Codex, all of API inference, all internal usage, and so on) is only the skinny blue 28% of their compute resources:

This puts some hard numbers to the general impression that, even though everyone talks about ChatGPT and the recent product ships like Sora and Atlas, the vast majority of OpenAI’s resources are dedicated toward unpublished fundamental research, as it should be.
The second clue was the OpenAI Foundation livestream where Sam mapped out the future priorities of the company and said the words “AI Cloud”, “Third Party apps” and even quoted the Bill Gates Line for the first time in OpenAI history.

OpenAI’s destiny as an AI cloud is something we have been anticipating for the last 2 years, and have been looking for in every single DevDay from 2023 to 2024 to 2025, but Sam has never, ever, spoken so clearly about OpenAI’s intention to serve third party builders at the app layer rather than primarily compete with them by building its own Apps and having ChatGPT be a “superapp”. This makes absolute economic sense - OpenAI achieves the most scale by going DOWN the stack to building its own chips and datacenters and power sources, and is far more likely to achieve AGI that way than by going *UP* the stack.
OpenAI isn’t the only Model Lab doing this pivot to AI cloud, it is just the furthest along. We’ve recently done podcasts with both Vercel and GitHub to get familiar with their AI Cloud strategy, and former guest Rita Kozlov today just announced Cloudflare’s acquisition of Replicate (another former guest!). However, they are all likely going to be outpaced in infra spend by Anthropic, which is now closing its $350B fundraise and announced its first $50B datacenter. They have ALSO expanded and focused their Claude Developer efforts and are the most serious contender to OpenAI:
One year on from writing Why GPT Wrappers are Good, Actually, we now actually have official blessing from leading frontier labs that they are finally taking AI Engineers more seriously than they have historically been.

So, let’s recap:
Why Agent Labs Now?
Priorities. Model Labs prioritize AGI models, Agent Labs prioritize AI agents.
Model Labs spend <30% of their budget on inference, applied AI engineers are paid 50-70% what research engineers get, and products get abandoned all the time: Operator, NotebookLM Audio Overviews, Scheduled Tasks, Deep Research, {other notable model branches I can’t name}. Both OpenAI and Anthropic have now signaled that they are building platforms for developers to build on rather than pursue first party apps, as they realize that being hyperscalers/”AI Clouds” and platforms is a far more scalable strategy.
with the notable exception of Claude Code, Codex, and Sora, and maybe Claude for Finance. Model Labs are building Agent Labs inside of them, at the same time that Agent Labs are starting to build their own models.
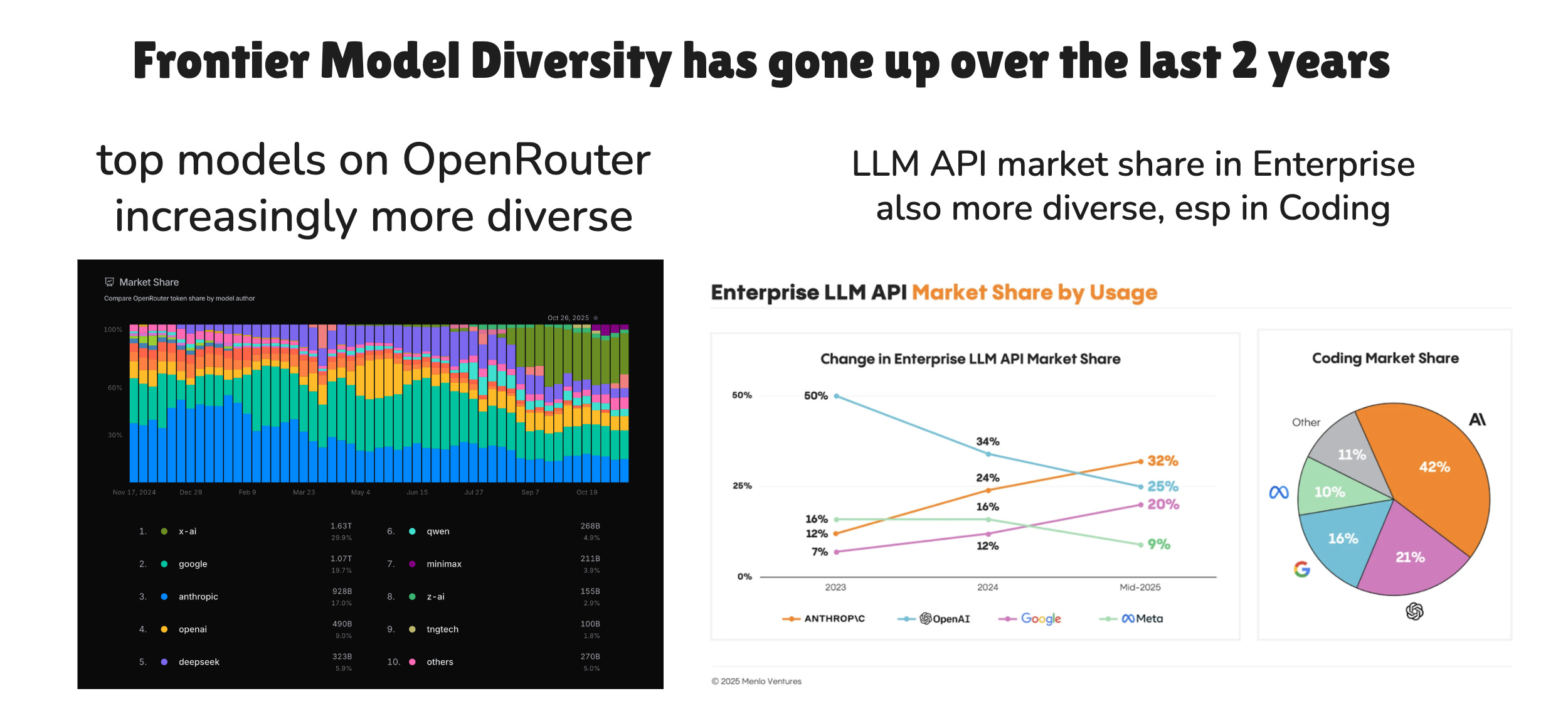
Model Diversity. the number of relevant frontier Model Labs has gone UP, not down, including Chinese/US open model labs, which means 1) you can capabilitymaxx across all of them, 2) people want to pay someone to capabilitymaxx for them for the literal full time job of keeping up with the state of the art and building the best combination of model and harness to the task. Often it’s an inhouse AI czar, but as this speciality deepends, it’s Agent Labs.
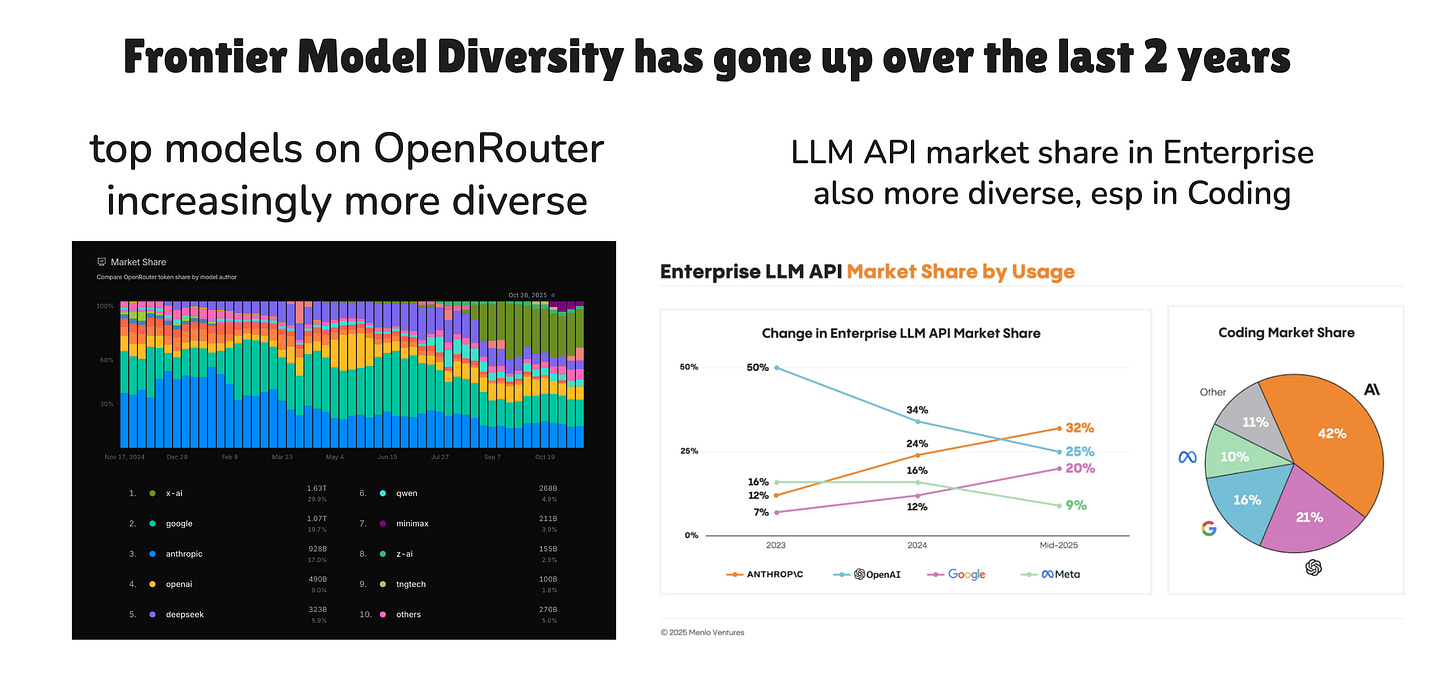
from our Deedy 2025 pod Agents are Systems. The Model Selector is a Lie. Agents in the real world are bundles of (model, prompt, memories, tools, planning, orchestration, auth) so the competitive advantage of model labs in building such end to end systems declines since they are primarily differentiated in the model layer.
Pretraining → RL. Since Alexnet (2012) and GPT-1 (2018) there is now about 7-13 years of scaling pretraining, where general knowledge and unsupervised language modeling of the average human response are mostly solved and we are close to hitting the limits of pretraining data. The RL age rewards domain focus/dedicated environments and matching/surpassing best humans.

When Grok 4 (now known to be 3T parameters) is indicating roughly equivalent spend on posttraining as pretraining, the thesis that Jeremy Howard laid out on our pod 2 years ago is playing out; and now the Agent Labs like Cursor and Cognition can essentially start from increasingly powerful open weights models and just do continued training.
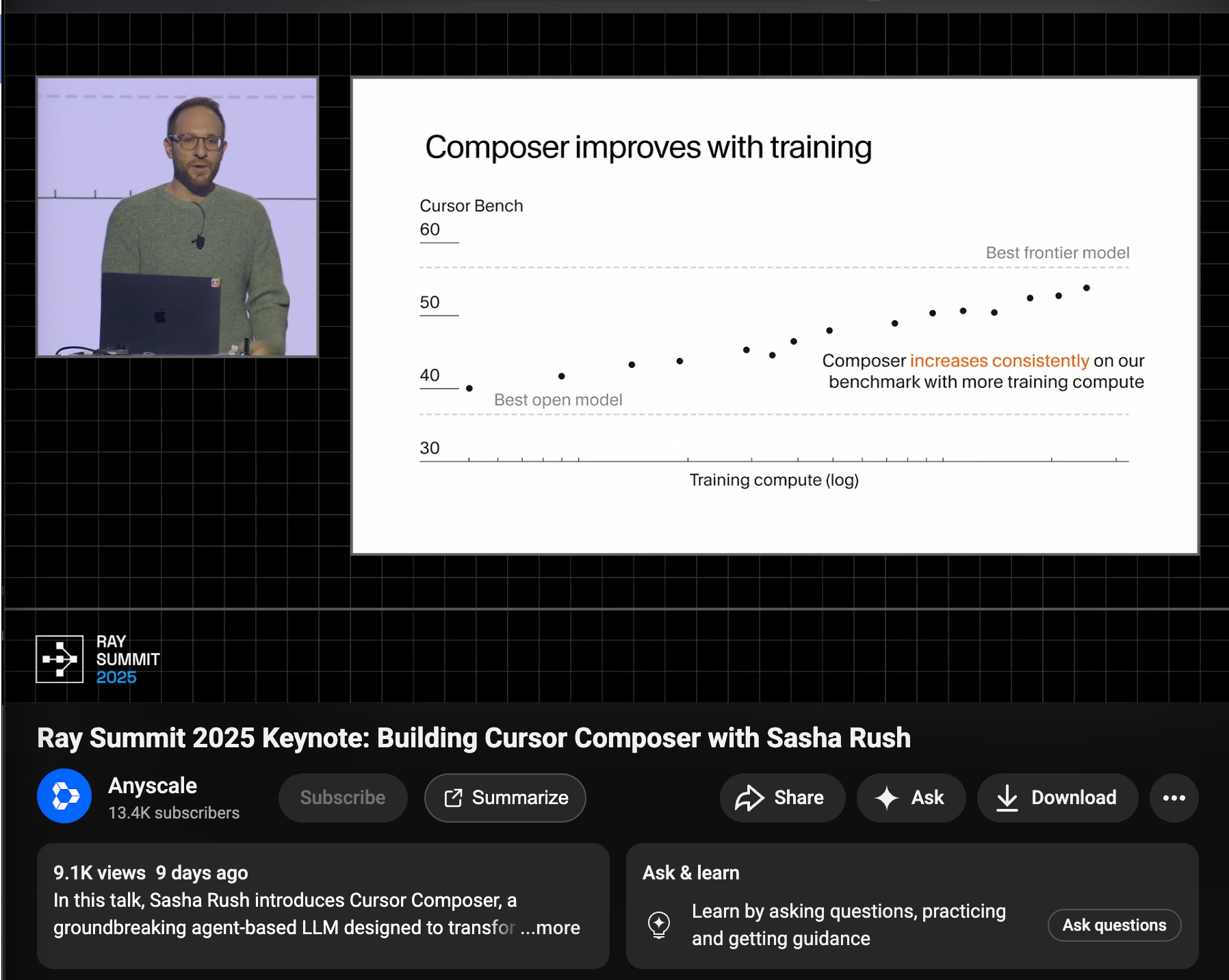
If you pay close attention to Sasha Rush’s talk at Ray Summit, you can notice that the x axis is log scale, which, while it is not quantified, can be presumed that Cursor is now saying their post-training can largely make up the gap between the best open models and the best frontier models. How long more until they start exceeding?



This last model training piece, as well as general research on all Agent Engineering and Agent Research is why it’s ALSO important to keep the Labs half of Agent Labs - these aren’t simply “Agent Companies” or “Agent Startups” - to be feasibly frontier at what they do, they likely have to invest in more R&D and fast experimentation in the actual scientific sense, not just the tax accounting one.
The end of one size fits all?
The “bear case” for the distinction between Agent Labs and Model Labs being meaningful, is if the Agent Labs embedded within Model Labs grow so powerful and important that they basically create a lasting fork in the model tree.
To elaborate: until 2025, the idea of a Model Lab pursuing “AGI” meant one model that could do all things - answer MMLU, vibe code a full stack app, and also roleplay as a friend. That puts the “G” in “AGI”. Just a little over a year ago, the GPT 4o launch promised to unify audio/image/text input and audio/image/text output. The “o” of “4o” was meant to be “omnimodel”.
However, to this day, GPT5 has evaded omnimodality, and continuing issues with the GPT5 router, the persistence of gpt-5-codex vs the regular gpt-5, and Fidji Simo’s blogpost literally titled “Moving beyond one-size-fits all”, suggest that at least for now, the Model Lab vision might be shifting, at least until the next big algorithm shift.
You are on target again. Models labs are the brain, Agent Labs are the arms and legs that move AI. They need each other but serve completely different functions. Keep up your great work!
This article is not one of your best. It lacks organization and you throw in a lot of extraneous references that only confuse the reader. (I offer this as constructive feedback, not as an insult to your abilities.)