

[AINews] Everything is Conductor
an ultra quiet day lets us highlight a smaller trend.
If you’re interested in how AI is improving Healthcare, tune in to our first pod on it out today, and if you want to meet other top engineers in the field, apply to speak!
There’s an ongoing joke in evolutionary biology that “Everything is Crab”: the Crab form factor has independently evolved at least 7 times on earth:

The proximate cause of today’s op-ed is GitHub announcing the new GitHub App - as Oren Melamed says, “If you are code first you might wanna stay on good ol’ VS Code, but if you are agent first and GitHub first you are in for a treat!”
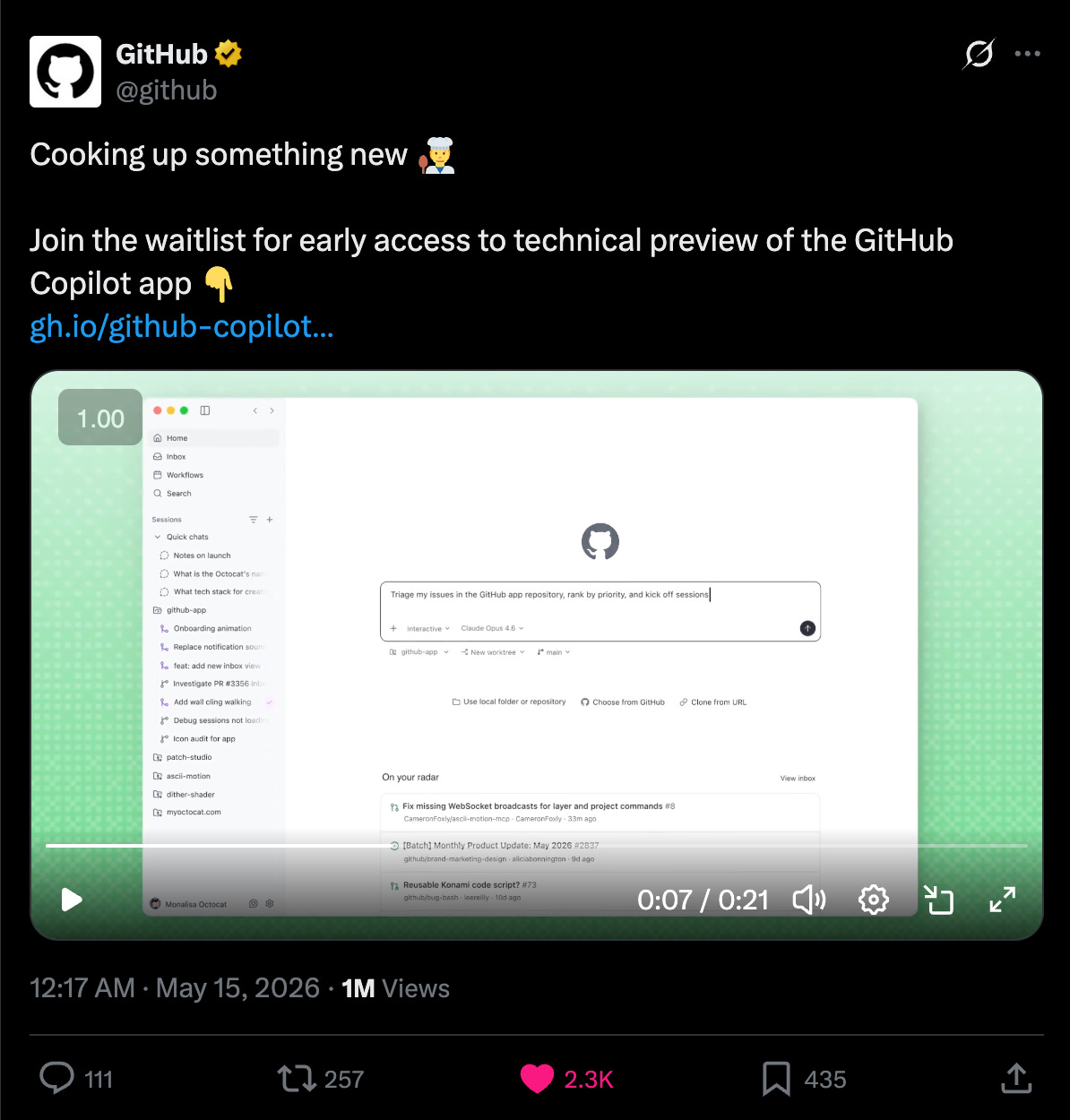
Hmm. That looks familiar…
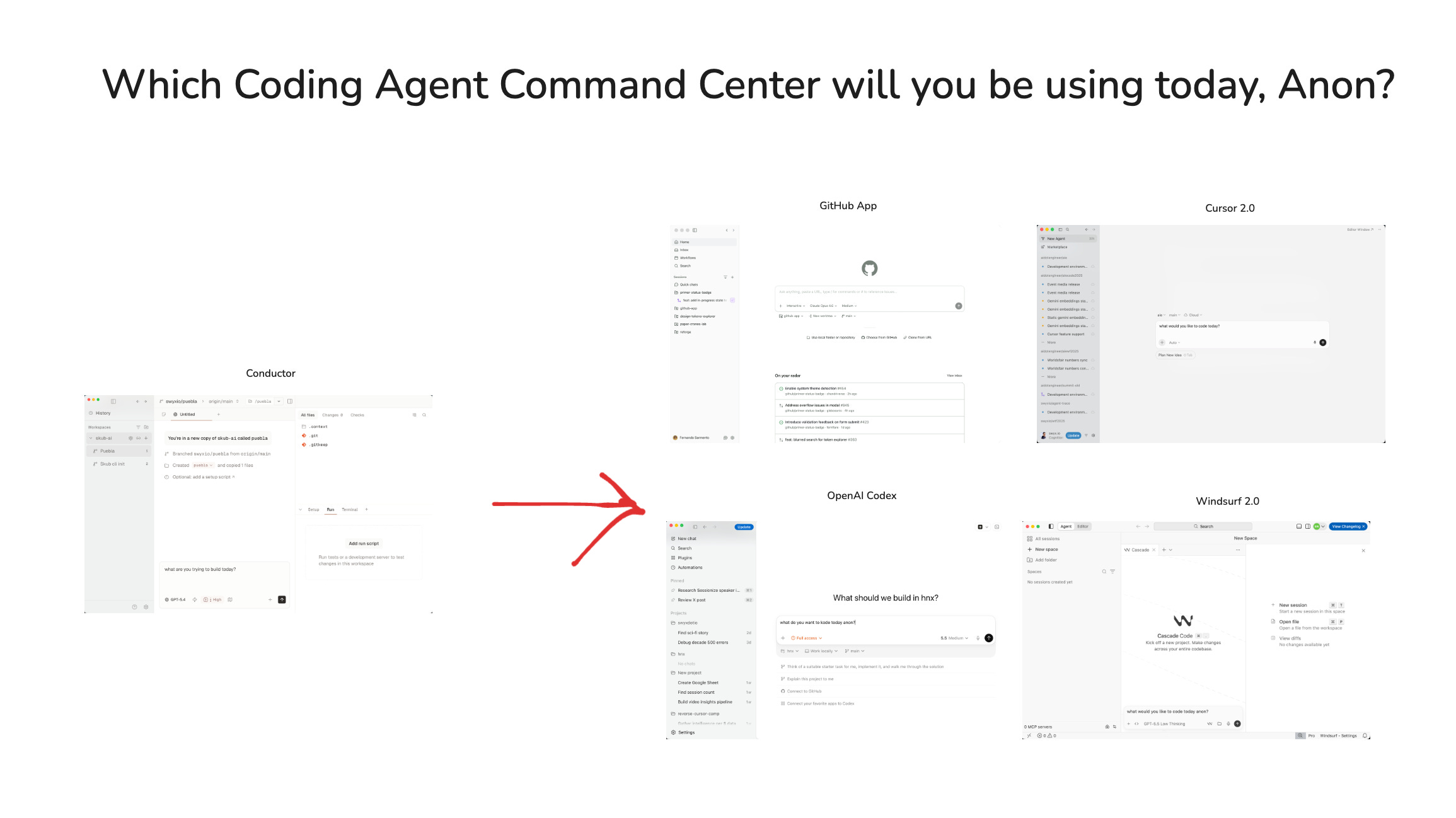
This is of course very nice for Conductor, which pioneered this form factor, and now has a loudly vocal fan in Garry Tan, the AI pilled CEO of Y Combinator:

Now for two billion dollar questions:
if you pioneered a form factor, how do you monetize it while others copy it?
what’s next after this one?
For those interested in alternate histories, here’s what happened with the Kanban board form factor that briefly trended last year:
And here is Maggie Appleton breaking down the design thinking behind GitHub Ace:
AI News for 5/13/2026-5/14/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
Coding Agent Tooling: Codex Mobile, GitHub’s New App, VS Code Multi-Agent UX, and Hermes/Codex Interop
OpenAI pushed Codex further into day-to-day workflows: the biggest product launch in this set was Codex in the ChatGPT mobile app, letting users start tasks, review outputs, approve commands, and steer execution remotely while Codex continues running on a laptop, Mac mini, or devbox. OpenAI also noted Remote SSH is now generally available for managed remote environments, and later added hooks plus programmatic access tokens for Business/Enterprise automation around the Codex loop (OpenAI, OpenAI follow-up, @OpenAIDevs on mobile workflow, @OpenAIDevs on Remote SSH, @OpenAIDevs on hooks/tokens). Separately, OpenAI published a technical writeup on the Wi`ndows sandbox for Codex, focused on the tradeoff between utility and constrained machine access for coding agents (OpenAI Devs, @gdb).
The broader IDE/app ecosystem is converging on “agent-first” UX: GitHub announced a technical preview of the GitHub Copilot App, described as a desktop environment for parallel workstreams, repo/PR lifecycle management, and model flexibility (GitHub, @adrianmg, @OrenMe). VS Code shipped a new Agents window for multi-agent, multi-project workflows, browser/mobile support via vscode.dev/agents, BYOK improvements, and token-efficiency features like compressed terminal output (VS Code, remote/browser support, BYOK updates, terminal compression). On the open side, Nous/Hermes Agent added Codex runtime integration, effectively routing OpenAI-backed turns through Codex CLI/app-server and reusing ChatGPT subscription-backed execution in Hermes sessions (Nous Research, @Teknium, @HermesAgentTips). Kimi also shipped Kimi Web Bridge, a browser extension exposing human-like web interaction to Kimi Code CLI, Claude Code, Cursor, Codex, Hermes, and others (Moonshot AI).
Agent Infrastructure and Self-Improvement Loops: LangSmith Engine, SmithDB, Sandboxes, and Continual Learning
LangChain’s launch stack was the most substantive agent-infra release cluster: SmithDB is a database purpose-built for agent trace data, while LangSmith Engine consumes traces, clusters failures, identifies likely code issues, and proposes fixes/evals—turning observability into an improvement loop rather than passive inspection (@hwchase17, @caspar_br on Engine, @bentannyhill). Community commentary emphasized SmithDB’s architectural shift toward object storage and a custom storage/query path for this workload shape (@caspar_br on SmithDB, @ngates_, Chinese summary).
LangChain also announced LangChain Labs, an applied research effort around continual learning for agents, with the thesis that production traces should become training signal, evals, and targeted capability improvements over long horizons (LangChain, @jakebroekhuizen, @willccbb, Prime Intellect partnership).
Execution isolation for agents continues to mature: W&B/CoreWeave launched CoreWeave Sandboxes for isolated execution in RL, tool use, and eval workloads, explicitly testing destructive commands like
rm -rf /at scale (Weights & Biases). In a similar spirit, open-source/local dev tooling surfaced around agent debugging: @benhylak highlighted a free local agent debugging stack with traces exposed to Codex/Claude Code for automated eval authoring.
Anthropic Claude Code Restrictions and the Developer Backlash
The sharpest ecosystem reaction was to Anthropic restricting/reshaping Claude Code usage, especially for third-party wrappers and high-volume programmatic workflows. Theo’s thread became the focal point: he argued users of T3 Code were effectively hit with dramatic rate-limit reductions despite integrating through the officially supported path, and he subsequently cancelled his subscription while encouraging others to post cancellation screenshots for open-source donations (@theo initial thread, subscription cancellation, donation thread, T3 Code clarification). Other prominent builders echoed the complaint that Anthropic had effectively cut off open-source devs/apps and destabilized harnesses built around
claude -p(@theo, @andersonbcdefg).There was also a more strategic counterargument: some users argued Anthropic does not owe developers heavily subsidized flat-fee tokens for third-party apps, and that the ecosystem will likely shift toward more explicit API economics and smarter routing between expensive and cheap models (Sentdex, @tadasayy). Still, the visible churn signal was nontrivial, including users estimating meaningful ARR loss from reply-thread cancellations alone (@thegenioo, Uncle Bob Martin, Theo later). For agent engineers, the practical takeaway is straightforward: subscription-backed harnesses are not stable platform primitives; provider/model abstraction and BYOK paths look increasingly mandatory.
Robotics and Embodied AI: Figure’s 24/7 Sorting Stream and the Broader Automation Signal
Figure’s livestream dominated robotics discussion. The company first showed 8 hours of fully autonomous, unsupervised work, then extended to a 24/7 livestream, eventually reporting 24+ hours of continuous autonomous operation without failure, around human-parity throughput on small package sorting, and operation by Helix-02 running entirely onboard with automatic resets for OOD cases—explicitly claiming no teleoperation (Figure CEO Brett Adcock, 24h update, detailed technical clarifications, Day 2 livestream). The repeated “Bob, Frank, and Gary” updates were fluffier, but the core signal was sustained autonomous operation at production-like uptime.
Interpretation split between skepticism about Figure specifically and broader conviction about robotics acceleration. Some commenters argued that critics were underestimating what these demonstrations imply for near-term labor substitution, while others noted skepticism was directed more at Figure than at robotics as a category (@cloneofsimo, @iScienceLuvr, @kimmonismus). Either way, this was one of the clearest “continuous uptime” demos in the batch.
Research, Benchmarks, and Open Models: Diffusion LMs, Time-Series FMs, Mechanistic Interpretability, and RL/Search
A few technically significant model/research releases stood out:
Zyphra’s ZAYA1-8B-Diffusion-Preview claims a 4.6–7.7x decoding speedup versus autoregressive generation with limited quality loss, making the usual case that diffusion LMs enable cheaper rollouts and richer generation modes (Zyphra).
Datadog’s Toto 2.0 released 5 open-weights time-series forecasting models from 4M to 2.5B params under Apache 2.0, claiming #1 on BOOM, GIFT-Eval, and TIME and, more importantly, evidence that scaling laws may finally hold cleanly for TSFMs (Datadog, @atalwalkar, @ClementDelangue).
Goodfire’s interpretability post argued that Llama uses a geometric “shape-rotating calculator” / Fourier-feature-like mechanism for arithmetic, with steering-based evidence rather than pure post-hoc description (GoodfireAI, follow-up).
On RL/search and optimizer-style progress, several threads were notable: a survey framing LLM RL as rollout engineering across Generate / Filter / Control / Replay rather than just PPO-vs-GRPO (The Turing Post); Pedagogical RL using privileged information to actively find useful rollouts (Souradip Chakraborty, @lateinteraction); and Prime Intellect’s autonomous optimizer search on the nanoGPT speedrun benchmark, where Opus 4.7 reached 2930 steps and GPT-5.5 2950, beating the 2990 human baseline after ~10k runs / ~14k H200 hours (Prime Intellect, @eliebakouch). Also noteworthy: Kimi K2.6 was reported as #1 open-weight model on Finance Agent Benchmark V2 (Moonshot AI), and Ring-2.6-1T got day-0 vLLM support as an open release (vLLM).
Top Tweets (by engagement)
OpenAI’s Codex mobile launch was the clearest product winner by engagement and practical relevance: remote control/review of running coding-agent sessions from ChatGPT mobile (OpenAI).
Theo’s Claude Code backlash threads captured the strongest developer sentiment shift around platform risk and subscription-backed agent workflows (@theo, @theo donations thread).
Figure’s autonomous humanoid sorting livestream remained one of the most discussed embodied-AI demos, especially once it crossed the 24-hour mark with detailed claims about onboard policy execution and no teleop (Brett Adcock).
GitHub’s Copilot App and LangChain’s Engine/SmithDB/Labs were the most important non-OpenAI tooling launches for agent engineers this cycle (GitHub, LangChain, @hwchase17).
Prime Intellect’s autonomous optimizer-search result is worth watching as a concrete example of coding agents being looped into open-ended ML optimization, not just app dev (Prime Intellect).
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. Qwen 3.6 Local Inference Speedups and Quantization
Multi-Token Prediction (MTP) for Qwen on LLaMA.cpp + TurboQuant (Activity: 514): A patched llama.cpp fork adds Multi-Token Prediction (MTP) support for Qwen plus TurboQuant, reporting
21 tok/s→34 tok/son a MacBook Pro M5 Max 64GB, with a claimed90%MTP acceptance rate; note the raw speedup is ~62%, not40%. Code is published atAtomicBot-ai/atomic-llama-cpp-turboquant, with GGUF MTP quantizations for Qwen 3.6 27B/35B in theAtomicChat/qwen-36-udt-mtpHF collection. Commenters questioned the TurboQuant framing, arguing it is often slower thanf16,q8, orq4; one noted a TurboQuant PR to llama.cpp was rejected because existing Q4 KV-quant rotation support already covered most benefits, with gains mainly at Q3 where quality degradation becomes a concern. Others asked for quality/eval data, since higher speculative/MTP acceptance and tokens/s do not alone establish output parity.Several commenters argued that TurboQuant is not generally faster in llama.cpp, with one noting it can be slower than
f16,q8, orq4. A prior TurboQuant PR to llama.cpp was reportedly rejected because llama.cpp already implements rotations forQ4KV-cache quantization, where standardQ4was faster and showed little gain; TurboQuant may only help aroundQ3, but with notable quality degradation.Users distinguished between speed, quality, and context tradeoffs: MTP without TurboQuant was suggested for speed, while standard
Q4_1orQ4_0quantization was recommended for longer context/quality retention. One commenter questioned whether TurboQuant had any Mac-specific advantage, implying the benefit is hardware- or workload-dependent rather than broadly useful.A commenter recommended using dflash instead of built-in MTP, claiming it is
30–40%faster. They also mentioned that a pull request for this already existed, suggesting the implementation work may duplicate prior llama.cpp integration efforts.
Keep reading with a 7-day free trial
Subscribe to Latent.Space to keep reading this post and get 7 days of free access to the full post archives.