

[AINews] ImageGen is on the Path to AGI
reflecting on the continued GPT-Image-2 explosion
As every lab sprints toward being some form of Anthropic (aka having a coding and enterprise AI focus, producing ever better PDFs and PPTs and spreadsheets), it is still refreshing to see that GPT-Image-2 is continuing to drive more creative applications, for example this:
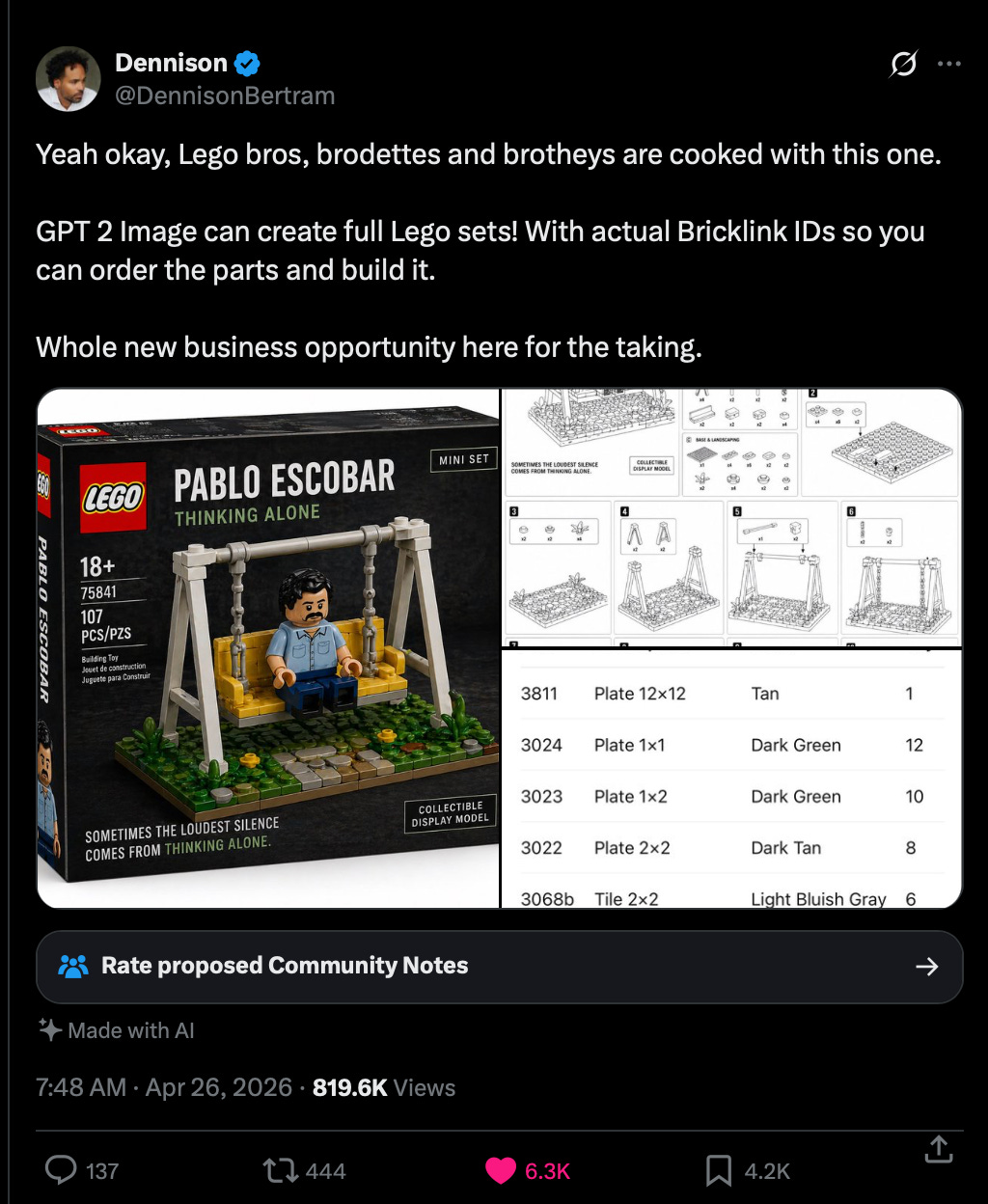
Considering the extremely high NPS score of the Lego Rocky Space Friend on date nights, you can imagine how good a low-hallucination, research-enabled, fully multimodal reasoning image model can be.
Of course it’s good for education:

or pop culture:

or precise, clean infographics:
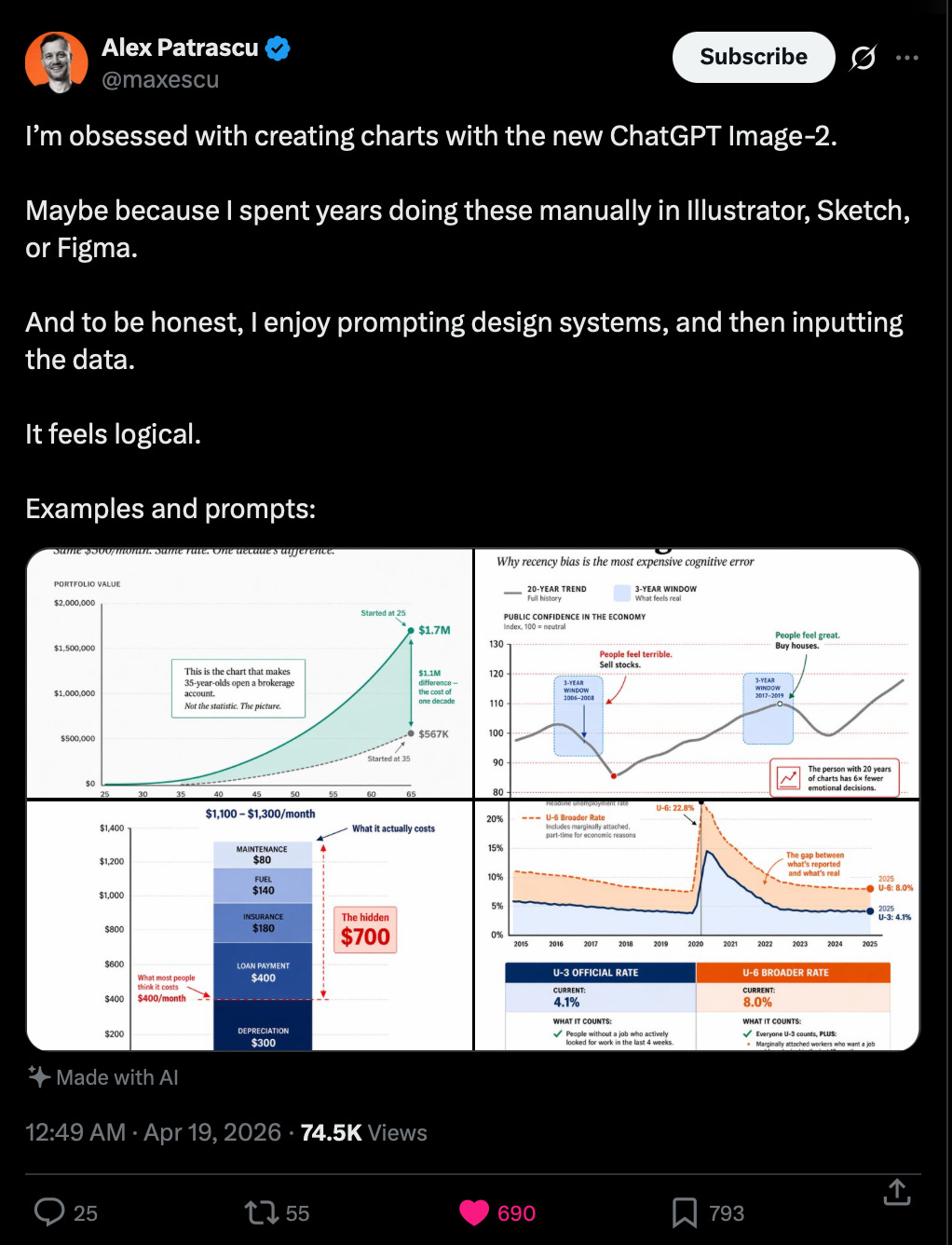
And of course the GPT-Image-2 + Codex combo, which is available as a skill in Codex, which you can iteratively use to generate assets WHILE you code:
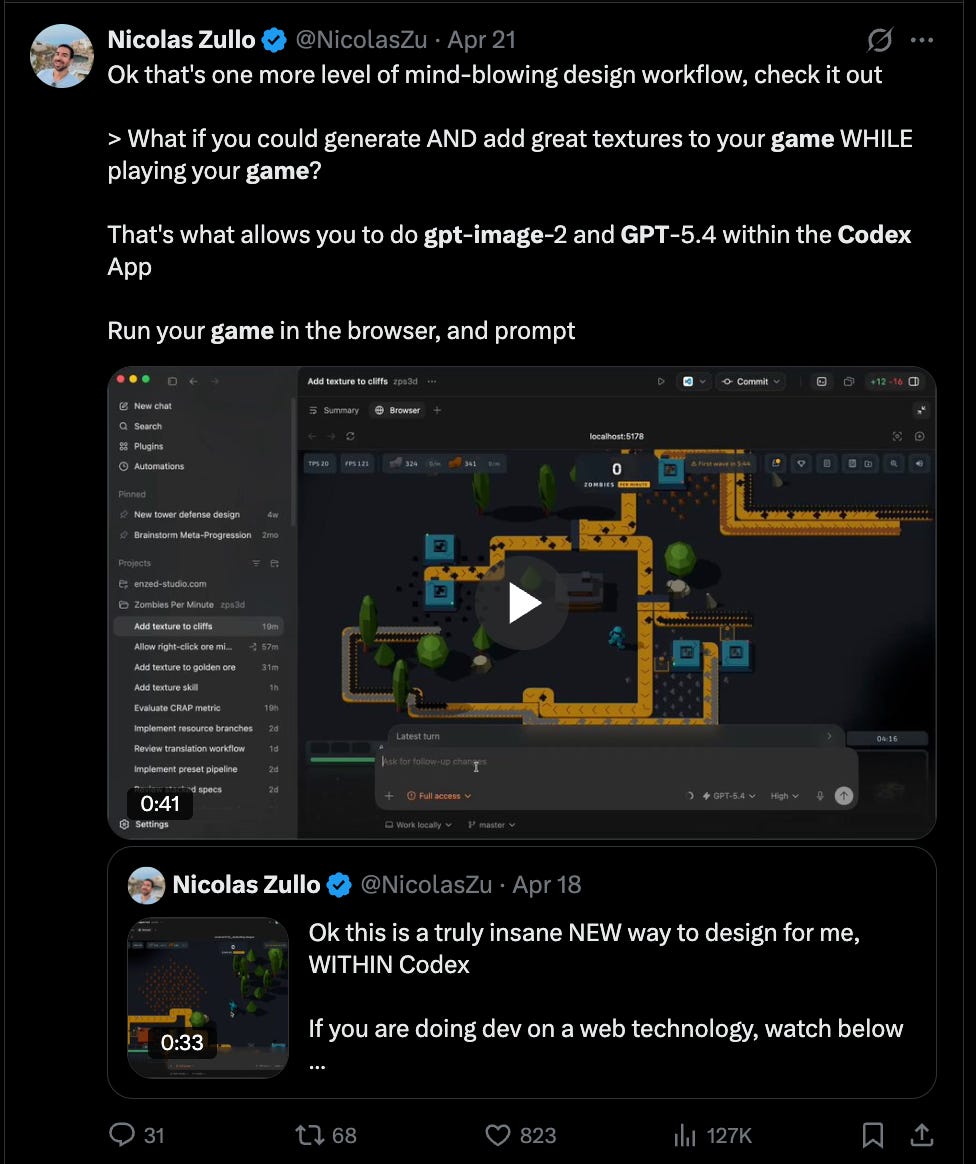
And just like that, Claude Design, the previous Current Thing, isn’t even in the conversation anymore. Quite simply, if you can “close” the loop, you win.
But that isn’t quite the argument we’re making here. What we’re focusing on is the very literal and serious question of whether or not models like Nano Banana or GPT-Image-2 or Grok Imagine are necessary uses of scarce GPU capacity if you are eschewing “side quests” and seriously pursuing AGI and trying to hit the revenue, efficiency, and funding goals necessary to not die along the way.
The answer is emergingly clear: yes. Not merely because of the “closing the loop”. But also because you can only do so much with text and code and structured output generation. When you have multimodal voice and visual generation (including transparency!), you truly flex the “G” part of “AGI” - after all, what good is AI if it only narrowly takes all programming jobs?
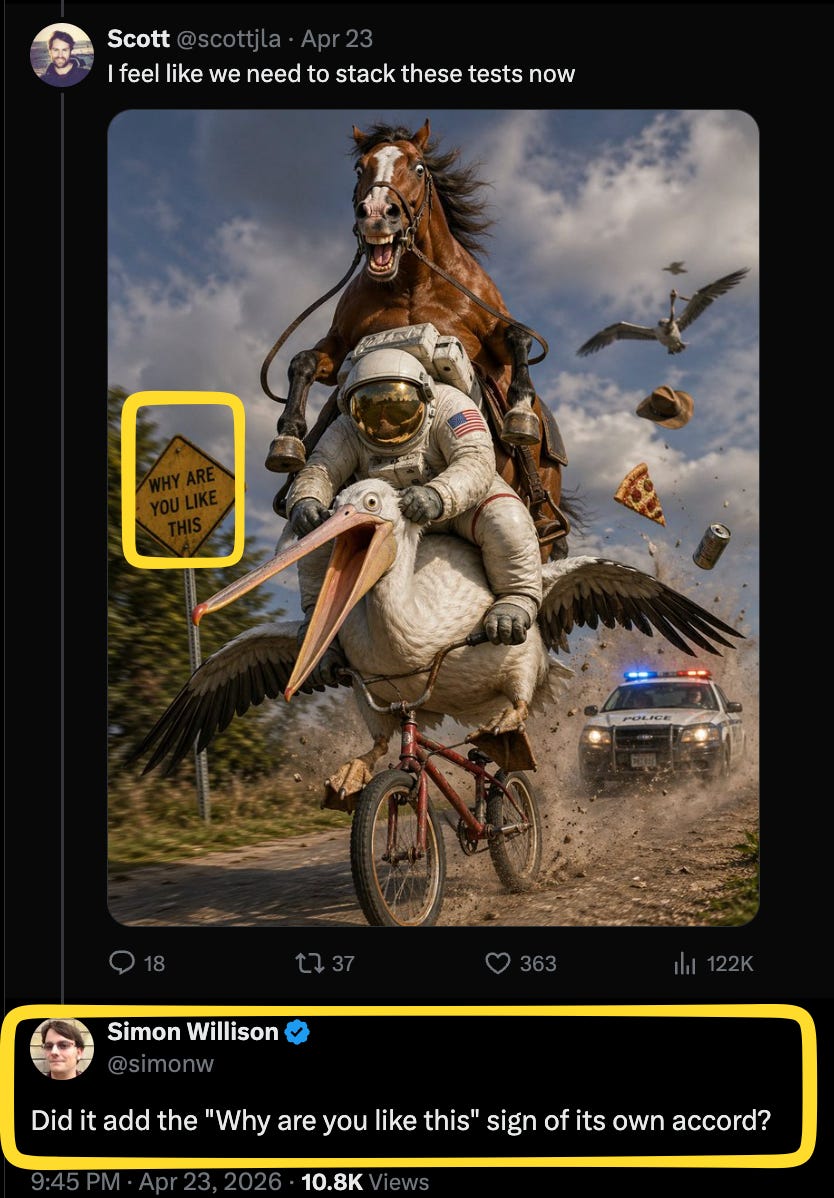
By the way, horse-riding astronauts used to be hard in imagegen, then it was astronaut-riding-horses, and now, well…
AI News for 4/26/2026-4/27/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
OpenAI Distribution Shift, GPT-5.5 Benchmarks, and Codex/Copilot Pricing Signals
OpenAI loosens Azure exclusivity: @sama said OpenAI updated its Microsoft partnership so Microsoft remains the primary cloud, but OpenAI can now make products available across all clouds, with product/model commitments extending to 2032 and revenue share through 2030. The implication was quickly drawn by @scaling01 and @kimmonismus: OpenAI can now distribute via Google TPU / AWS Trainium / Bedrock, and Microsoft’s license to OpenAI IP becomes non-exclusive. @ajassy confirmed OpenAI models are coming to AWS Bedrock in the coming weeks. @simonw noted the new language likely means the old AGI clause is effectively gone.
GPT-5.5 is a broad upgrade, but not uniformly dominant: Community evals from @htihle put GPT-5.5 no-thinking at 67.1% on WeirdML, up from 57.4% for GPT-5.4, but still behind Opus 4.7 no-thinking at 76.4% while using fewer tokens. LMSYS Arena results from @arena placed GPT-5.5 at #9 in Code Arena, #6 Document, #7 Text, #3 Math, #2 Search, #5 Vision, with Expert Arena #5. Arena also clarified current evaluation covers medium/high reasoning, with xHigh still pending (1, 2). Practitioner feedback was positive for hard coding tasks such as GPU kernels from @gdb, but there were also reports of “compressed CoT leakage” / malformed outputs in no-thinking mode from @htihle.
Developer economics are becoming more explicit: GitHub announced Copilot moves to usage-based billing on June 1, a notable shift as agentic workflows consume much more runtime. Parallel to that, @Hangsiin documented Codex usage multipliers: GPT-5.4 fast = 2x, GPT-5.5 fast = 2.5x, with 5.4-mini and GPT-5.3-Codex materially cheaper. @sama argued Codex at $20 remains a strong value. OpenAI also open-sourced Symphony, an orchestration layer connecting issue trackers to Codex agents for “open issue → agent → PR → human review,” via @OpenAIDevs.
Xiaomi MiMo-V2.5, Kimi K2.6, and China’s Agent-Oriented Open-Weights Push
MiMo-V2.5 is one of the day’s biggest open releases: @XiaomiMiMo open-sourced MiMo‑V2.5-Pro and MiMo‑V2.5 under MIT, both with 1M-token context. The Pro model is framed as a complex agent/coding model and the smaller model as a native omni-modal agent. Community summaries from @eliebakouch add useful technical details: MiMo‑V2.5-Pro is roughly 1T total / 42B active, trained on 27T tokens in FP8, while MiMo‑V2.5 is about 310B total / 15B active, trained on 48T tokens, with aggressive interleaved SWA/global attention and no shared expert. Xiaomi also announced a 100T token grant for builders via @_LuoFuli. Day-0 inference support landed quickly in vLLM and SGLang/vLLM.
Kimi K2.6 continues to lead in mindshare and deployment: @Kimi_Moonshot said Kimi K2.6 is now #1 on OpenRouter’s weekly leaderboard. Secondary reporting described it as a model for coding and long-horizon agents, including scaling to 300 concurrent sub-agents across 4,000 coordinated steps (dl_weekly). Practitioners remain split on speed/quality tradeoffs: @teortaxesTex found Kimi in Hermes much slower than DeepSeek V4 but sometimes capable of fixing bugs V4 could not.
Broader China-model trend: Multiple posts framed Chinese labs as pushing aggressively on open-ish, agent-oriented, long-context systems: Qwen 3.6 Flash, DeepSeek V4/Flash, GLM-5.1 promotions (triple usage extension), and Xiaomi’s MIT release. A recurring theme was that smaller / cheaper variants are often outperforming their larger siblings on practical agent benchmarks.
Agent Runtimes, Orchestration, and Local-First Tooling
Sakana’s Conductor is a notable multi-agent result: @SakanaAILabs introduced a 7B Conductor trained with RL to orchestrate a pool of frontier models in natural language rather than solving tasks directly. It dynamically decides which agent to call, what subtask to assign, and which context to expose, and reportedly reached 83.9% on LiveCodeBench and 87.5% on GPQA-Diamond, beating any single worker in its pool. @hardmaru highlighted “AI managing AI” and recursive self-selection as a new axis of test-time scaling.
Local and hybrid agents keep getting better: Several posts showed coding/assistant stacks running locally. @patloeber and @_philschmid documented running Pi agent + Gemma 4 26B A4B locally via LM Studio/Ollama/llama.cpp. @googlegemma demoed a fully local browser agent using Gemma 4 + WebGPU, with native tool calling for browsing history, tab management, and page summarization. @cognition shipped Devin for Terminal, a local shell agent that can later hand off to the cloud.
Agent ergonomics and framework evolution: Hermes had a strong day: @Teknium noted Hermes Agent’s repo surpassed Claude Code, while native vision became the default when supported. The broader ecosystem kept filling in missing pieces: Cline Kanban now supports different agents/models per task card; Future AGI open-sourced an eval/optimization stack for self-improving agents; and @_philschmid argued MCP works best either through explicit @mention loading or subagent-scoped tool assignment, not indiscriminate server attachment.
Inference Infrastructure, Attention/KV Engineering, and Systems Work
Google’s TPU split is a meaningful architecture signal: Several posts dissected Google’s Cloud Next announcement that TPU v8 is split into 8t for training and 8i for inference, with claims of roughly 2.8x faster training and 80% better inference performance/$ than prior generation. @kimmonismus emphasized this is the first time Google split custom silicon by workload and that OpenAI, Anthropic, and Meta are reportedly buying TPU capacity.
DeepSeek V4 support is maturing quickly in infra stacks: @vllm_project said support for DeepSeek V4 base models is coming, requiring an
expert_dtypeconfig field to distinguish FP4 instruct vs FP8 base. In the vLLM 0.20.0 release, highlights included DeepSeek V4 support, FA4 as default MLA prefill, TurboQuant 2-bit KV, and a DeepSeek-specific MegaMoE path on Blackwell.KV cache optimization remains a hot battleground: There was dense discussion around long-context bottlenecks and KV strategies. @cHHillee summarized three main levers for long contexts: local/sliding attention, interleaved local-global attention, and smaller KV per global layer via GQA/MLA/KV tying/quantization. On the implementation side, @vllm_project and Red Hat/AWS published an FP8 KV-cache deep dive where a fix to FA3 two-level accumulation improved 128k needle-in-a-haystack from 13% to 89% while retaining FP8 decode speedups. Community critics also questioned DeepSeek V4’s specific KV tradeoffs relative to offloading-heavy approaches such as HiSparse (discussion).
Benchmarks, Evals, and Open Research Directions
Open-world evaluation is gaining momentum: @sarahookr argued that most agentic benchmarks are overfit to automatically verifiable tasks, while the important frontier is open-world, uncertain, non-fully-verifiable work. Related threads connected this to continual learning, memory stores, and adaptive data systems (1, 2).
Cost-aware agent evaluation is becoming first-class: @dair_ai highlighted a new study on coding-agent spend over SWE-bench Verified: agentic coding can consume ~1000x more tokens than chat/code reasoning, usage can vary 30x across runs on identical tasks, and more spending does not monotonically improve accuracy. This lines up with pricing-model changes from Copilot and growing concern over uncontrolled agent runtime economics.
New benchmarks and domain-specific evals: ParseBench from LlamaIndex adds 2k verified enterprise document pages for parsing agents. AgentIR reframes retrieval for research agents by embedding the reasoning trace alongside the query, with AgentIR-4B hitting 68% on BrowseComp-Plus vs 52% for larger conventional embedding models. There were also several benchmark snapshots for frontier models—e.g. Opus 4.7 leading GSO at 42.2% and WeirdML / ALE-Bench / PencilPuzzleBench chatter—but the stronger signal was methodological: more people are measuring runtime cost, retrieval quality, and open-world behavior, not just final answer accuracy.
Top tweets (by engagement)
OpenAI–Microsoft partnership reset: @sama on cross-cloud availability and continued Microsoft partnership.
OpenAI on AWS: @ajassy confirming OpenAI models are coming to Bedrock.
GitHub Copilot pricing change: @github announcing usage-based billing starting June 1.
Xiaomi MiMo-V2.5 open-source release: @XiaomiMiMo with MIT license and 1M context.
Open-source orchestration for Codex: @OpenAIDevs launching Symphony.
Gemma local browser agent: @googlegemma showing a 100% local browser-resident agent with WebGPU.
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. Qwen3.6 Model Performance and Optimization
Keep reading with a 7-day free trial
Subscribe to Latent.Space to keep reading this post and get 7 days of free access to the full post archives.