

[AINews] RIP Pull Requests (2005-2026)
a quiet day lets us report on the death of the pull requests

Hot on the heels of the Death of the Code Review, the Pull Request may be next.
For anyone that learned to code in the last 15 years it is hard to imagine a life without Git, GitHub, and Pull Requests, but there was a time before them, and it well may come to pass that there is life after.
Pull Requests were arguably invented in 2005, successfully popularized by GitHub, and only 21 years later, GitHub is for the first time in history allowing people to disable pull requests on their open source repos (you could only disable issues before).
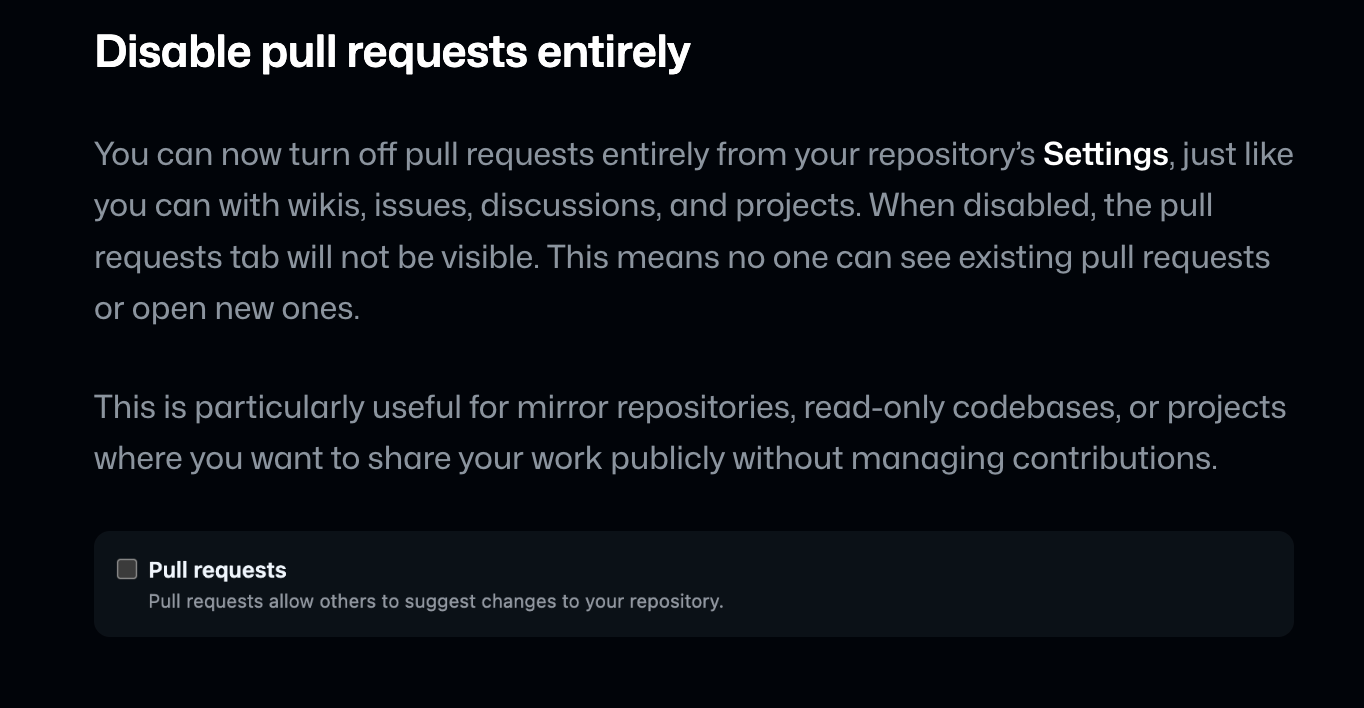
The rise of Generative AI in code has spelled the pending death of the Pull Request for a while now — Pete Steinberger is by now well known (along with Theo) for only wanting Prompt Requests rather than Pull Requests (for multiple reasons, eg 1) no merge conflicts, 2) it’s easier for the maintainer to fix/add to the prompt than to look at code, 3) less likely to have malicious/insecure code slipped into an innocent looking PR), and other folks like Mitchell Hashimoto and Amp Code have created “reputation”-based systems for handling untrusted code contributions.
In Building for Trillions of Agents, Aaron Levie noted that “the path forward is to make software that agents want.” Humans invented git for human collaboration reasons. It’s increasingly clear that Git-based workflows may not be suitable once we remove the human bottleneck from the flow of code.
And if Code Reviews are dead, and Pull Reviews are dead… how long until Git itself is dead?
AI News for 4/14/2026-4/15/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
OpenAI Agents SDK Expansion and the New Sandbox-Oriented Agent Stack
OpenAI split the agent harness from compute/storage and pushed its Agents SDK toward long-running, durable agents with primitives for file/computer use, skills, memory, and compaction. The harness is now open-source and customizable, while execution can be delegated to partner sandboxes instead of being tightly coupled to OpenAI infra, per @OpenAIDevs, follow-up, and @snsf. This effectively makes “Codex-style” agents more reproducible by third parties and shifts differentiation toward orchestration, state management, and secure execution.
A notable ecosystem formed around that launch immediately: @CloudflareDev, @modal, @daytonaio, @e2b, and @vercel_dev all announced official sandbox integrations. The practical pattern is converging on stateless orchestration + stateful isolated workspaces. Example builds already appeared, including a Modal-backed ML research agent with GPU sandboxes, subagents, persistent memory, and fork/resume snapshots from @akshat_b, and Cloudflare guides for Python agents that execute tasks in a sandbox and copy outputs locally from @whoiskatrin.
Cloudflare’s Project Think, Agent Lee, and Voice Agents
Cloudflare had one of the busiest agent-infra release cycles. @whoiskatrin and @aninibread introduced Project Think, a next-gen Agents SDK centered on durable execution, sub-agents, persistent sessions, sandboxed code execution, a built-in workspace filesystem, and runtime tool creation. In parallel, @Cloudflare launched Agent Lee, an in-dashboard agent using sandboxed TypeScript to shift Cloudflare’s UI from manual tab navigation to prompt-driven operations; @BraydenWilmoth showed it issuing infra tasks and generating UI-backed results.
Voice and browser tooling also moved into the core stack. @Cloudflare shipped an experimental real-time voice pipeline over WebSockets for continuous STT/TTS, while @korinne_dev described voice as just another input channel over the same agent connection. On browser automation, @kathyyliao summarized the rebranded Browser Run stack: Live View, human-in-the-loop intervention, session recordings, CDP endpoints, WebMCP support, and higher limits. Taken together, Cloudflare is making a strong case that the production agent platform is really a composition of durable runtime + UI grounding + browser + voice + sandbox.
Hermes Agent’s Self-Improving Workflow and Competitive Positioning
Hermes Agent’s distinctive idea is not just tool use but persistent skill formation. A Chinese-language comparison from @joshesye contrasts OpenClaw as a more GUI-first, ready-to-use personal assistant with Hermes as a “professional” agent that decides whether a completed workflow is reusable and automatically turns it into a Skill. This “learn from completed tasks” framing appeared repeatedly: @chooseliberty showed Hermes autonomously backfilling tracking data, updating a cron job, then saving the workflow as a reusable skill; @NeoAIForecast emphasized session hygiene and thread branching/search as critical to turning Hermes into a real work environment rather than a disposable chat box.
Community sentiment strongly positioned Hermes against OpenClaw, often bluntly. Examples include @vrloom, @theCTO, and @Teknium highlighting Hermes’ role in real workflows, including the now-viral autonomous Gemma 4 “abliteration” story from @elder_plinius: the agent loaded a stored skill, diagnosed NaN instability in Gemma 4, patched the underlying library, retried multiple methods, benchmarked the result, generated a model card, and uploaded artifacts to Hugging Face. There were also concrete product additions: browser control via
/browser connectfrom @0xme66, QQBot + AWS Bedrock support from @Teknium, a native Swift desktop app alpha from @nesquena, and ongoing ecosystem tooling like artifact-preview and hermes-lcm v0.3.0.
Model, Architecture, and Training Releases: Sparse Diffusion, Looped Transformers, and Efficient Long-Context MoEs
Several technically meaningful open releases landed across modalities. @withnucleusai announced Nucleus-Image, positioned as the first sparse MoE diffusion model: 17B parameters, 2B active, Apache 2.0, with weights, training code, and dataset recipe, and day-0 support in diffusers. NVIDIA followed with Lyra 2.0, a framework for generating persistent, explorable 3D worlds that maintains per-frame 3D geometry and uses self-augmented training to reduce temporal drift, per @NVIDIAAIDev. On multimodal retrieval, @thewebAI open-sourced webAI-ColVec1, claiming top ViDoRe V3 performance for document retrieval without OCR or preprocessing.
Architecture research around compute efficiency was especially strong. @hayden_prairie, @realDanFu, and @togethercompute introduced Parcae, a stabilized layer-looping Transformer formulation. The claim: for fixed parameter budgets, looping blocks can recover the quality of a model roughly 2x the size, yielding a new scaling axis where FLOPs scale via looping, not just parameters/data. NVIDIA also surfaced Nemotron 3 Super, summarized by @dair_ai: an open 120B hybrid Mamba-Attention MoE with 12B active parameters, 1M context, trained on 25T tokens, with up to 2.2x throughput vs GPT-OSS-120B and 7.5x vs Qwen3.5-122B. These releases collectively point to a theme: memory bandwidth and long-context throughput are increasingly first-class architectural objectives.
Google/Gemini’s Product Surge: Mac App, Personal Intelligence, TTS, and Open Multimodal Models
Google stacked multiple launches in one cycle. The most visible was the native Gemini app for Mac, announced by @GeminiApp, @joshwoodward, and @sundarpichai: Option + Space activation, screen sharing, local file context, native Swift implementation, and broad macOS availability. In parallel, Personal Intelligence expanded globally in Gemini and into Chrome, allowing users to connect signals from products like Gmail and Photos, framed around transparency and user-controlled app connections by @Google and @GeminiApp.
The more technically interesting model launch was Gemini 3.1 Flash TTS. @GoogleDeepMind, @OfficialLoganK, and @demishassabis positioned it as a highly controllable TTS model with Audio Tags, 70+ languages, inline nonverbal cues, multi-speaker support, and SynthID watermarking. Independent evaluation from @ArtificialAnlys put it at #2 on its Speech Arena, just 4 Elo behind the top model. Google also open-sourced TIPS v2, a foundational text-image encoder under Apache 2.0 with new pretraining recipes, via @osanseviero, and the community flagged the day as unusually dense for Google AI product velocity.
Research Signals: AI-Assisted Math, Long-Horizon Agents, Eval Shifts, and Open Data
The highest-signal research discourse was around AI-assisted mathematics. @jdlichtman reported that GPT-5.4 Pro produced a proof for Erdős problem #1196, surprising experts by rejecting a long-assumed proof gambit and instead exploiting a technically counterintuitive analytic path using the von Mangoldt function. Follow-ups from @jdlichtman, @thomasfbloom, @gdb, and others framed it as potentially the first AI-generated “Book Proof” broadly respected by mathematicians. That matters less as a one-off result than as evidence that models may now occasionally find non-aesthetic but compact lines of attack in mature research spaces.
Long-horizon agent research also kept converging on state management and harness design. @omarsar0 summarized AiScientist, where a thin orchestrator coordinates specialized agents through durable workspace artifacts in a File-as-Bus pattern; removing that bus hurts PaperBench and MLE-Bench Lite materially. @dair_ai highlighted Pioneer Agent for continual small-model improvement loops, while @yoonholeee open-sourced Meta-Harness, a repo meant to help users implement robust harnesses in new domains. On evals, @METR_Evals estimated Gemini 3.1 Pro (high thinking) at a 50% time horizon of ~6.4 hours on software tasks, and @arena showed Document Arena top ranks shifting with Claude Opus 4.6 Thinking at #1 and Kimi-K2.5 Thinking as the best open model. Meanwhile, @TeraflopAI released 43B tokens of SEC EDGAR data, reinforcing the day’s broader push toward more open datasets and open infrastructure.
Top tweets (by engagement)
Gemini on Mac: @sundarpichai and @GeminiApp drove the biggest launch engagement around the native desktop app.
Gemini 3.1 Flash TTS: @OfficialLoganK and @GoogleDeepMind highlighted a materially more controllable TTS stack.
AI-assisted math proof: @jdlichtman and @gdb sparked the strongest research discussion of the day.
OpenAI Agents SDK update: @OpenAIDevs marked a meaningful platform shift toward open harnesses and partner sandboxes.
Anthropic’s subliminal learning paper in Nature: @AnthropicAI drew major attention to hidden-trait transmission through training data.
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
Keep reading with a 7-day free trial
Subscribe to Latent.Space to keep reading this post and get 7 days of free access to the full post archives.