

[AINews] The End of Finetuning
a quiet day lets us reflect on whither finetuning
The proximal cause of today’s op-ed is OpenAI’s deprecation of their finetuning APIs.
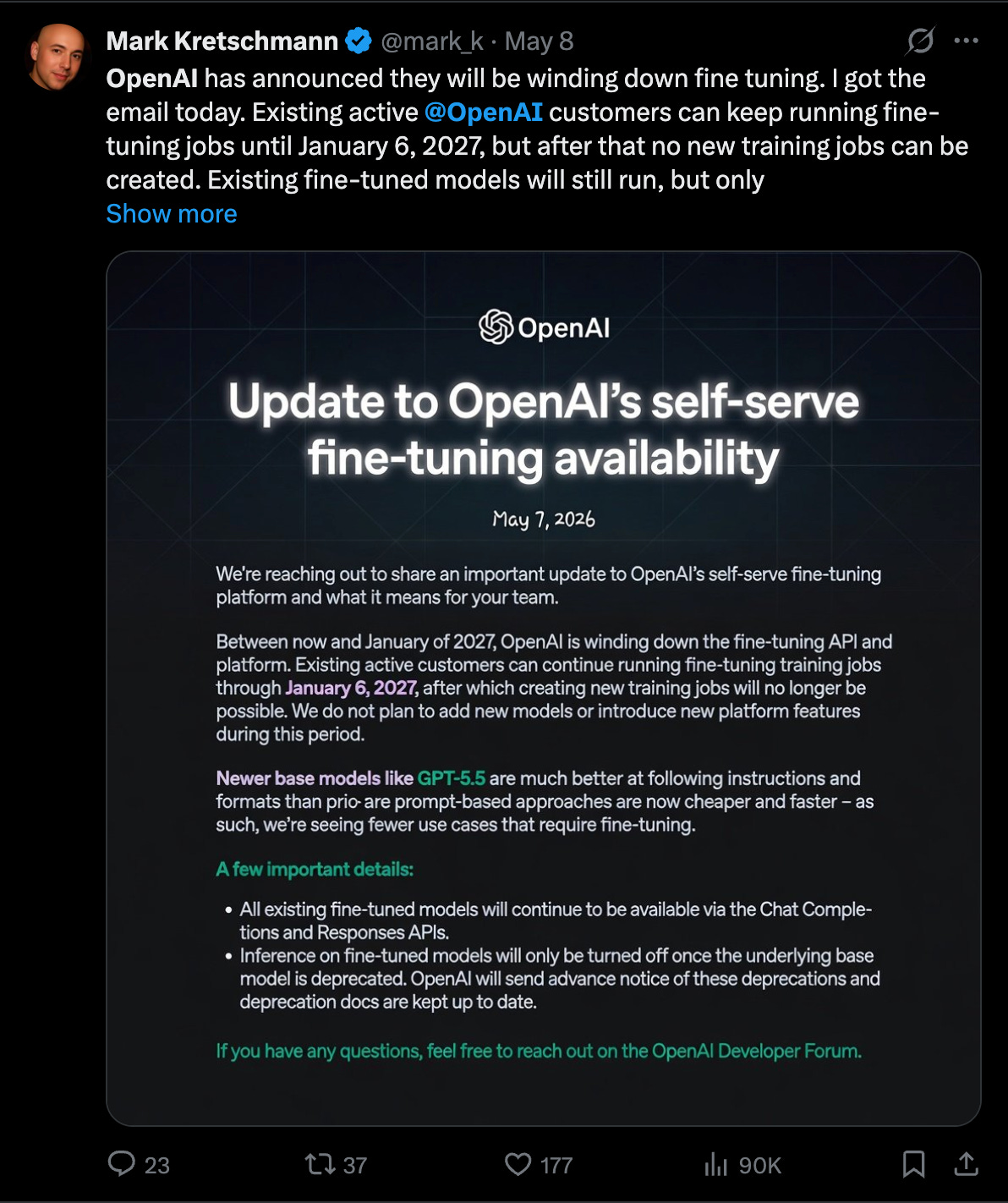
For years, OpenAI stood out among the big labs for their finetuning support, and many many many talks and content pieces and AI engineers promoted how you can get some variant of “get o1 performance at 4o prices” and insisting that it was an important part of the toolkit.
Now the tide is out, Anthropic will probably raise at a higher valuation than OpenAI for the first time ever, and Finetuning is the next casualty of the 2026 Side Quest massacre (after Sora). If you assume an extreme GPU crunch, that makes sense, but even without dramatic compute constraints, the modal 80% of the AI Engineering industry was probably trending there anyway, with Jeremy Howard calling it out on the pod as early as 2023.

The “End” of a thing for most people does NOT mean the “End” of a thing period - and in fact the top tier, like Cursor and Cognition (whose $25B round is now public discussion) have both INCREASED open model RLFT and usage, rather than decreased. Open Model finetunes may also be central to the Custom ASIC Thesis, but if Taalas’ model and continued P/D Disaggregation inference solutions are any indication, then maybe Just Very Long Prompts (like Claude’s Constitution) are all you need…

AI News for 5/11/2026-5/12/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
Research Benchmarks, Hard Evals, and Agentic Science Systems
Research-level reasoning benchmarks keep getting harder: Soohak introduces 439 research-level math problems authored from scratch by 64 mathematicians (including 38 faculty), explicitly targeting capabilities above standard olympiad-style math. In medical evaluation, @SophontAI released Medmarks v1.0, expanding its open medical benchmark suite from 20→30 benchmarks and 46→61 models. There’s also growing sentiment that old evals are saturating: @polynoamial argues benchmarks with uniformly high scores should be retired in favor of lower-scoring, frontier-challenging tests.
Agentic systems are starting to move benchmark frontiers in science and math: Google DeepMind’s AI Co-Mathematician is described as an asynchronous, stateful research workbench for mathematicians, reportedly reaching 48% on FrontierMath Tier 4 while supporting ideation, literature discovery, computational analysis, theorem verification, and formal outputs. In theoretical physics, physics-intern boosts Gemini 3.1 Pro from 17.7% to 31.4% on CritPt via decomposition into specialized agents. On coding/program synthesis, ProgramBench’s first task was reportedly solved by GPT-5.5 high/xhigh, with xhigh outperforming Opus 4.7 xhigh across metrics.
Retrieval and search benchmarks are rewarding small, specialized models: LightOn’s Agent-ModernColBERT stacks another ~10% over Reason-ModernColBERT on BrowseComp-Plus while keeping the retriever at 149M parameters, with claims of matching or exceeding much larger model-based systems when paired with a generator. Related discussion from @xuzihuan4 asks whether lexical retrieval may suffice in agentic search loops when agents can iteratively refine their own queries.
Training, Optimization, and Scaling-Law Techniques
Optimizer work continues to compress training cost and improve small-scale experimentation: Several tweets centered on fast variants of SOAP/Muon-style updates. @torchcompiled applied tangent-step + Stiefel manifold retraction to SOAP basis updates, with follow-up discussion on drift checks and QR fallback for stability. In the Modded-NanoGPT community, SOAP-Muon set a new record at 3150 steps (-60), while an earlier MuLoCo-style outer Nesterov SGD wrap on NorMuonH also improved results, both backed by p-value reporting.
Formal methods and superoptimization are beginning to merge with ML systems work: @leloykun described a Lean4-to-TileLang tensor program superoptimizer that can automatically discover kernels such as FlashAttention2, FlashNorm, and split-k matmul, reporting roughly 1.8× geomean speedup on A100s. The same framework is positioned to jointly search over kernels, optimizers, hyperparameter transfer rules, and scaling laws.
Scaling laws and training metrics are being re-examined: @che_shr_cat argues the classic “20 tokens per parameter” framing is tokenizer-dependent and that scaling should be measured in bytes, not tokens. Separately, @JJitsev emphasized that prescriptive scaling laws are valuable not just for prediction, but as a systematic basis for comparing learning procedures across scales.
Training-time-only efficiency tricks are getting more interesting: Lighthouse Attention from Nous is highlighted as a subquadratic training wrapper around vanilla attention that can be removed near the end of training after a recovery phase, preserving standard deployment-time inference while reducing long-context pretraining cost. In a similar spirit, Renderers from Prime Intellect addresses the token/message impedance mismatch between RL trainers and agent environments, claiming >3× throughput on popular open models.
Inference Systems, Serving Stacks, and Runtime Infrastructure
Blackwell racks are emerging as the reference platform for large-MoE serving: Perplexity published details on serving post-trained Qwen3 235B on NVIDIA GB200 NVL72 systems, arguing GB200 is a major inference step up over Hopper for large MoEs. Their benchmarks cite NVLS all-reduce latency dropping from 586.1µs on H200 to 313.3µs on GB200, and MoE prefill combine at EP=4 dropping from 730.1µs to 438.5µs, with better decode throughput at high token rates. @AravSrinivas framed this as materially changing prefill/decode disaggregation for serving large MoEs.
Inference orchestration is increasingly specialized, not “just Kubernetes”: Modal argues inference needs a dedicated stack, citing work on compute management, cloud-native caching, CRIU, and GPU checkpointing. That positioning got an immediate real-world endorsement from Perceptron, which said all Mk1 inference runs on Modal because native video, structured outputs, and hybrid reasoning create unusual cold-start and scaling requirements.
OSS inference economics continue to improve fast: SemiAnalysis reported that clustering multiple B200 8-GPU machines over RoCEv2 CX-7 with PD disaggregation can lift per-GPU token throughput by up to 7×, implying comparable cost-per-token reductions. On the vector DB side, Qdrant 1.18 added TurboQuant, claiming recall near scalar quantization with 2× less memory, alongside memory monitoring and named-vector lifecycle operations.
Agent runtimes are becoming version-control-like substrates: A standout systems idea was Stanford’s Shepherd, summarized by @ai_satoru_chan, which treats agent execution more like Git: first-class tasks, effects, scopes, and traces; exact replay; branching; rollback; and formal guarantees in Lean. Claimed results include live-supervision gains on CooperBench from 28.8%→54.7%, plus faster counterfactual optimization and tree-RL rollouts.
Product and Model Releases: Multimodal, Video, Retrieval, and Embeddings
Perceptron Mk1 was the most substantive new model release in the set: @perceptroninc launched Perceptron Mk1 as a model for frontier video and embodied reasoning, with native video support at up to 2 FPS, temporal grounding, multimodal in-context learning, and structured spatial outputs. OpenRouter’s summary notes a 32k multimodal context and first-class outputs like points, boxes, polygons, and clips. The release is framed less as a generic VLM and more as a physical-world reasoning stack.
Google and Meta both pushed multimodal interaction layers rather than standalone model specs: Google DeepMind’s AI-enabled mouse pointer demos reimagine the cursor as a contextual pointing interface tied to Gemini, allowing users to point at on-screen content and speak shorthand instructions. In parallel, Meta announced Meta AI voice conversations powered by Muse Spark, adding interruption, language switching, image generation, and live camera-grounded interaction.
Embedding and retrieval model updates were notable: Jina released jina-embeddings-v5-omni, a universal embedding model for text, images, audio, and video, in 1.57B and 0.95B variants, both with Matryoshka truncation and backward compatibility with existing v5-text indexes. Meta quietly released Sapiens2, a family of human-centric high-resolution ViTs spanning 0.1B→5B params for pose estimation, segmentation, normals, and pointmaps.
Diffusion and image tooling kept moving: Hugging Face’s Diffusers 0.38.0 added new pipelines including Ace-Step 1.5, LongCat-AudioDiT, and Ernie-Image, plus support for Flash Attention 4, FlashPack loading, and Ring Anything for context parallelism. Other research releases included ELF: Embedded Language Flows, a continuous-space text diffusion model, and Tencent’s Pixal3D for pixel-aligned 3D generation.
Agents, Tooling, and Developer Workflow
Agent products are shifting from demos to operational platforms: OpenAI teased Symphony as a system where every open task gets a running Codex agent, and separately highlighted computer use for Codex to work across apps without full takeover. LangChain re-open-sourced its revamped Chat LangChain app, describing it as a production Q&A agent handling nearly 2T tokens/week.
Long-running-agent state management is becoming a first-class systems problem: LangGraph’s new DeltaChannel snapshots aim to replace full-state checkpointing for scalable durable execution; LangChain says the same mechanism now powers message histories and file storage in deepagents v0.6. The broader pattern also shows up in Google’s Gemini Interactions API guide, where encrypted
thoughtsignatures preserve reasoning context across turns in both stateful and stateless modes without forcing developers to manage signature injection manually.Synthetic data and RL environment generation are being operationalized: @Vtrivedy10 offered a useful practitioner perspective: targeted synthetic data extraction from model weights is hard at scale, especially for underrepresented distributions like long sequences, and effective pipelines need programmatic tests, verifiers, judges, and agentic long-horizon framing. On the infrastructure side, Tau2-Infinity formalizes autonomous mining of hard tool-use tasks for RL post-training via DAG walks or world-generation from failure hypotheses.
Top tweets (by engagement, filtered for technical relevance):
Gemini as an OS-level intelligence layer: Google’s Gemini Intelligence, Googlebook, and AI pointer demos collectively point to agentic UX moving from chat windows into the operating system.
Isomorphic Labs funding: @demishassabis announced $2.1B in new funding for AI-driven drug discovery, one of the largest capital commitments in this dataset tied directly to an applied AI platform.
Speech-to-speech benchmarking: Artificial Analysis’ τ-Voice benchmark found even the best S2S models solve only about half of realistic customer service scenarios, with Grok Voice Think Fast 1.0 leading at 52.1%.
Claude Opus 4.7 fast mode: Anthropic’s fast mode release reached APIs and Claude Code, with Cursor noting 2.5× speed at 6× cost, a concrete new point on the latency/price frontier.
Security, Supply Chain, and Safer Coding
The most urgent operational story was the Mini Shai-Hulud supply-chain attack: @IntCyberDigest reported the campaign had expanded beyond TanStack to hit OpenSearch, Mistral AI, Guardrails AI, UiPath, and others across npm and PyPI, specifically targeting AI developer tooling. The noteworthy technical detail is persistence: it allegedly hooks into Claude Code (
.claude/settings.json) and VS Code (.vscode/tasks.json) so the compromise can re-execute on future tool events even after package removal. Guardrails AI later confirmed its 0.10.1 package was compromised and quarantined within about 2 hours.Actionable mitigations surfaced quickly: @ramimacisabird noted that beyond
minimumReleaseAge, teams should enableblockExoticSubdepsto prevent remote GitHub references from slipping into dependency graphs. @elithrar reiterated that GitHub’spull_request_targetremains one of the sharpest CI/CD footguns for fork-based PR automation. And at the workstation level, @andersonbcdefg recommended moving secrets out of ubiquitous local.envfiles into a proper secrets manager.Safer codegen is becoming its own research track: Stanford-aligned work on SecureForge targets vulnerability discovery/prevention in LLM-generated code via prompt optimization, while the corresponding paper listing frames it as a bridge between codegen and security evaluation. The broader point: coding agents are now strong enough that supply-chain hardening and secure-generation evaluation need to be treated as core infra, not side concerns.
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. Qwen 3.6 MTP and Long-Context Local Evals
MTP on Unsloth (Activity: 727): The image is a Hugging Face activity screenshot showing Unsloth AI publishing/updating MTP-preserved GGUF builds:
unsloth/Qwen3.6-27B-GGUF-MTPandunsloth/Qwen3.6-35B-A3B-GGUF-MTP. The technical significance is that these GGUFs retain the MTP / next-token-prediction auxiliary layer, but users reportedly still need to checkout and build a specific llama.cpp MTP PR rather than relying on default llama.cpp support. One commenter hit a runtime/model-load assertion,GGML_ASSERT(hparams.nextn_predict_layers > 0 && "QWEN35_MTP requires nextn_predict_layers > 0"), suggesting tooling or metadata support is still fragile for these MTP GGUFs. Commenters are mainly waiting on upstream inference support, with one joking about constantly refreshingllama.cppandvLLMGitHub repos. There is also uncertainty over whether MTP is supported “out of the box” in llama.cpp; the post indicates it is not yet.A user compiling/running the new
27BGGUF model reports a hard assertion failure inqwen35_mtp.cpp:GGML_ASSERT(hparams.nextn_predict_layers > 0 && "QWEN35_MTP requires nextn_predict_layers > 0") failed. This suggests the GGUF/model metadata being loaded is missing or not exposingnextn_predict_layers, which is required for Qwen3.5 MTP execution in the current implementation.Several commenters are tracking whether llama.cpp and vLLM have landed native MTP support, with one explicitly asking whether llama.cpp now supports MTP “out of the box.” The thread implies support is still in flux across backends and that users are watching upstream repositories for compatibility with GGUF MTP models.
One technical takeaway is that MTP support in GGUF is viewed as important for local inference, especially for Qwen-style variants such as the mentioned
35B A3Bmodel. A commenter highlights the35B A3Bvariant as interesting specifically because of expected context-length improvements.
The Qwen 3.6 35B A3B hype is real!!! (Activity: 713): A user benchmarked Qwen 3.6 35B A3B, Qwen 3.6 27B, Gemma 4 26B A4B, and Nemotron 3 Nano on a niche paper-to-code comprehension task, feeding each model an academic paper plus accompanying research code via long-context mechanisms such as gated delta nets, hybrid Mamba2, and sliding-window attention. In their detailed findings, all four small/local open-weight models substantially outperformed prior small-model baselines such as Devstral Small 2, with Qwen 3.6 35B A3B judged strongest; Devstral Small 2 could not fit the long-context workload in
32GBVRAM/RAM. Commenters noted practical tradeoffs: Qwen 35B is preferred for long-context/refactoring but can be verbose/slow in thinking mode, while Gemma 26B is faster for code fixes/chats; atq4, one user reports ~20GBfor Qwen 35B and ~15GBfor Gemma 26B, allowing both to stay loaded. Another commenter criticized the evaluation for not documenting inference settings, which limits reproducibility.Several users compared local workflows using Gemma 26B and Qwen 35B, noting that both can be kept resident simultaneously at
q4quantization because Qwen 35B is about20 GBand Gemma 26B about15 GB. One commenter uses Gemma 26B thinking mode for quick code fixes/chat and Qwen 35B thinking mode for longer-context refactoring, but reports Qwen 35B has high latency due to excessive reasoning verbosity before final output.A coding-focused report claimed Qwen 27B can handle large projects (
100k+LOC) effectively when bootstrapped by a stronger model/coding agent for initial project setup, then switched to Qwen for continued work. The user found little practical difference between Qwen 27B and DeepSeek V4 for their use case, though Qwen occasionally entered loops requiring manual interruption and continuation prompting.One commenter emphasized that Qwen 27B/35B performance is sensitive to inference configuration, specifically temperature/sampling parameters and avoiding overly aggressive quantization of either the model weights or KV cache. Another asked for the missing run settings, implying the original claims are hard to evaluate without details like quantization level, sampler settings, context length, backend, or hardware.
{kind=link}
2. Memory-Tiered and Power-Efficient Local Inference
Computer build using Intel Optane Persistent Memory - Can run 1 trillion parameter model at over 4 tokens/sec (Activity: 964): The image shows the internals of a high-memory Xeon workstation/server build using Intel Optane DC Persistent Memory DIMMs, matching the post’s claim of running Kimi K2.5, a ~
1Tparameter MoE model, locally at about4 tokens/svia llama.cpp hybrid GPU/CPU inference. The key technical point is the use of768GBOptane PMem in Memory Mode, where Optane appears as system RAM and192GBDDR4 ECC DRAM acts as cache, allowing the model’s sparse expert weights to reside in PMem while attention/dense/shared expert/routing tensors fit on an RTX 3060 12GB usingoverride-tensororngl auto/cmoe. Image Commenters noted that a higher-core-count Cascade Lake Xeon, such as an ES 8260/QQ89, could improve throughput, and debated whether Optane Storage Mode plusmmapmight outperform Memory Mode. Others found the build impressive but questioned whether4 tokens/sis practically tolerable for interactive use.A detailed hardware note suggests performance may improve with a higher-core-count Cascade Lake Xeon, e.g. QQ89 ES / Xeon Gold 8260-class
24-core, versus the current Xeon Gold 624612-core. The commenter also proposes benchmarking Optane PMem in storage mode +mmapversus memory mode, noting that memory mode uses DRAM as a transparent cache and requires pages to be swapped back into DRAM before CPU execution, so it is not equivalent to normal RAM latency.One commenter provides a concise Optane PMem platform compatibility breakdown: LGA3647 Skylake/Cascade Lake uses 1st-gen Optane
NMAat2666 MT/s, while LGA4189 uses 2nd-genNMB, running at2666on Cooper Lake and3200on Ice Lake. They also note that mixing Optane with DRAM on Cascade Lake can downclock affected channels to2666, and that many Xeons from this era have a1 TBtotal memory limit across DRAM + Optane, unless using high-memory SKUs or later platforms.A technical caveat is raised that while
~4 tokens/secgeneration on a trillion-parameter model may be tolerable for some uses, prompt processing/prefill speed is likely to be much worse on this kind of memory hierarchy. Another comment estimates the full used-market build cost at roughly$2060–$2500, including a Xeon Gold 6246, TYAN S5630GMRE-CGN, RTX 3060 12GB,192 GBDDR4 ECC RDIMM, and768 GBIntel Optane DCPMM.
Stop wasting electricity (Activity: 905): A user benchmarked
llama.cppllama-serveron an RTX 4090 withQwen3.6-27B-UD-Q4_K_XL.gguf, full GPU offload (-ngl all), FlashAttention enabled,q4_0K/V cache quantization,32threads, and a262144context, varying the GPU power cap viasudo nvidia-smi -pl N. They report the GPU was consistently power-limited and that reducing the power limit can substantially lower power/heat/noise with little to no decode / token-generation (tg) throughput loss; a commenter notes prefill (pp) is more sensitive, with roughly15–20%performance loss when dropping from450Wto270W, model-dependent. Commenters were mainly interested in separating decode vs prefill behavior, since decode appears power-insensitive while prefill degrades more noticeably. One RTX 5090 user said they already cap power for hardware-safety concerns and may reduce it further based on these results.Users focused on the performance impact of GPU power limiting: decode/token generation (
tg) reportedly is not the bottleneck, while prefill (pp) takes a larger hit. One commenter quantified the tradeoff as only about15–20%prefill performance loss when reducing power from450Wto270W, depending on the model, suggesting substantial efficiency gains from aggressive power caps.
{kind=link}
3. Ultra-Small On-Device Transformer Experiments
I got a real transformer language model running locally on a stock Game Boy Color! (Activity: 368): The image (jpeg) shows a stock Game Boy Color running a local TinyStories transformer demo, with the screen displaying
TINYSTORIES Q8 GBCandPrompt tokenized. Per the post, this is Andrej Karpathy’s TinyStories-260K converted toINT8/fixed-point math in a GBDK-2020 MBC5 ROM, with weights in bank-switched cartridge ROM and the KV cache stored in cartridge SRAM due to the GBC’s tiny work RAM. The author notes it is extremely slow and produces mostly gibberish because of aggressive quantization/approximations, but the core local transformer prefill + autoregressive generation loop works on-device with no PC, phone, Wi-Fi, link cable, or cloud inference: github.com/maddiedreese/gbc-transformer. Comments are mostly enthusiastic praise; one commenter said it made them want to run a model on an N64, and another linked a related/joke Game Boy language-model project, gbalm.A commenter linked a prior Game Boy language-model project, gbalm (code), indicating there has been earlier experimentation with extremely constrained on-device LM inference on Nintendo handheld hardware. This is relevant as a comparison point for implementation approaches and feasibility on non-GPU, retro 8-bit-class systems.
One technical question centered on why CUDA/ROCm-style GPU stacks are not required here: the commenter notes that typical LLM inference is associated with mature GPU compilers, yet this demo runs on hardware comparable to “a potato.” The implicit point is that sufficiently tiny transformer models can be executed with hand-written or highly simplified CPU-style inference loops, though at very low throughput, and that portability to unsupported accelerators such as future Chinese GPUs would depend more on having a basic compute backend than full CUDA compatibility.
Needle: We Distilled Gemini Tool Calling Into a 26M Model (Activity: 271): Cactus Compute released Needle, an MIT-licensed
26Mparameter single-shot tool-calling model distilled from Gemini-synthesized data, claiming6000 tok/sprefill and1200 tok/sdecode on consumer devices; weights are on Hugging Face and code/docs are on GitHub. Architecturally it uses “Simple Attention Networks” — attention plus gating with no MLP/FFN layers — arguing that function calling is mostly retrieval/assembly over provided tool schemas rather than memorized reasoning; training used200Bpretraining tokens on16 TPU v6efor27hplus2Bsynthesized function-calling tokens in45m(architecture writeup). The authors claim it beats FunctionGemma-270M, Qwen-0.6B, Granite-350M, and LFM2.5-350M on single-shot function calling, while acknowledging those larger models have broader conversational capacity. Commenters framed the model as potentially useful as a lightweight router that dispatches queries/tools or escalates to a larger LLM, with one asking whether the same architecture could support high-quality summarization. A technical concern was raised about uploadedpicklefiles due to Python-specific dependency and deserialization security risks.A commenter framed the
26Mdistilled tool-calling model as a lightweight router/gating model: it could decide whether a query should be sent to a larger LLM and with which parameters, effectively reducing expensive model calls to cases where they are needed. They also speculated whether the same architecture could generalize to constrained summarization workflows, though no benchmark evidence was provided in the thread.One technical thread focused on the authors’ claimed “no FFN” result: for tasks with external structured knowledge such as RAG, tool use, and retrieval-augmented generation, the model may not need feed-forward layers to store factual knowledge if relevant facts are already present in context. A commenter extrapolated this into a pipeline where a small post-trained model routes requests to RAG and then uses retrieved context to generate a natural-language answer.
Several implementation/security concerns were raised: one commenter noted that publishing pickle files is increasingly avoided because of Python-specific dependency issues and arbitrary-code-execution risk during deserialization. Another pointed out that Gemini has had visible tool-calling quirks, including system-prompt-like reasoning about avoiding
catand preferring tools such asgrep_search, raising the possibility that a distilled dataset could inherit provider-specific tool-use biases if not cleaned carefully.
{kind=link}
Less Technical AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Claude Coding Workflows and Tooling
Keep reading with a 7-day free trial
Subscribe to Latent.Space to keep reading this post and get 7 days of free access to the full post archives.