


Thanks to the over 17,000 people who have joined the first AI Engineer Summit! A full recap is coming. Last call to fill out the State of AI Engineering survey! See our Community page for upcoming meetups in SF, Paris and NYC.
This episode had good interest on Twitter and was discussed on the Vanishing Gradients podcast.
Fast.ai’s “Practical Deep Learning” courses been watched by over >6,000,000 people, and the fastai library has over 25,000 stars on Github. Jeremy Howard, one of the creators of Fast, is now one of the most prominent and respected voices in the machine learning industry; but that wasn’t always the case.
Being non-consensus and right
In 2018, Jeremy and Sebastian Ruder published a paper on ULMFiT (Universal Language Model Fine-tuning), a 3-step transfer learning technique for NLP tasks:
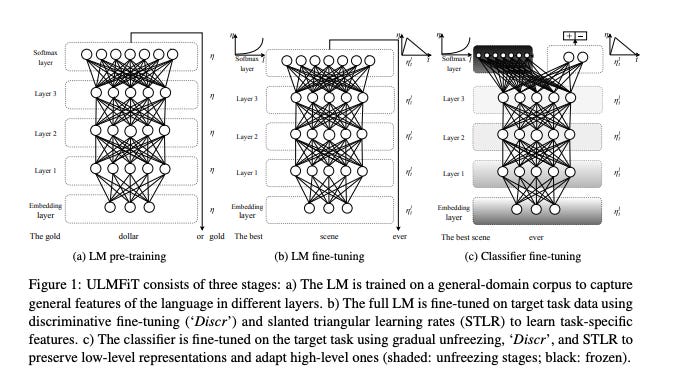
The paper demonstrated that pre-trained language models could be fine-tuned on a specific task with a relatively small amount of data to achieve state-of-the-art results. They trained a 24M parameters model on WikiText-103 which was beat most benchmarks.

While the paper had great results, the methods behind weren’t taken seriously by the community:
“Everybody hated fine tuning. Everybody hated transfer learning. I literally did tours trying to get people to start doing transfer learning and nobody was interested, particularly after GPT showed such good results with zero shot and few shot learning […] which I was convinced was not the right direction, but who's going to listen to me, cause as you said, I don't have a PhD, not at a university… I don't have a big set of computers to fine tune huge transformer models.”
Five years later, fine-tuning is at the center of most major discussion topics in AI (we covered some like fine tuning vs RAG and small models fine tuning), and we might have gotten here earlier if Jeremy had OpenAI-level access to compute and distribution. At heart, Jeremy has always been “GPU poor”:
“I've always been somebody who does not want to build stuff on lots of big computers because most people don't have lots of big computers and I hate creating stuff that most people can't use.”
This story is a good reminder of how some of the best ideas are hiding in plain sight; we recently covered RWKV and will continue to highlight the most interesting research that isn’t being done in the large labs.
Replacing fine-tuning with continued pre-training
Even though fine-tuning is now mainstream, we still have a lot to learn. The issue of “catastrophic forgetting” and potential solutions have been brought up in many papers: at the fine-tuning stage, the model can forget tasks it previously knew how to solve in favor of new ones.
The other issue is apparent memorization of the dataset even after a single epoch, which Jeremy covered Can LLMs learn from a single example? but we still don’t have the answer to.

Despite being the creator of ULMFiT, Jeremy still professes that there are a lot of open questions on finetuning:
“So I still don't know how to fine tune language models properly and I haven't found anybody who feels like they do.”
He now advocates for "continued pre-training" - maintaining a diversity of data throughout the training process rather than separate pre-training and fine-tuning stages. Mixing instructional data, exercises, code, and other modalities while gradually curating higher quality data can avoid catastrophic forgetting and lead to more robust capabilities (something we covered in Datasets 101).
“Even though I originally created three-step approach that everybody now does, my view is it's actually wrong and we shouldn't use it… the right way to do this is to fine-tune language models, is to actually throw away the idea of fine-tuning. There's no such thing. There's only continued pre-training.
And pre-training is something where from the very start, you try to include all the kinds of data that you care about, all the kinds of problems that you care about, instructions, exercises, code, general purpose document completion, whatever. And then as you train, you gradually curate that, you know, you gradually make that higher and higher quality and more and more specific to the kinds of tasks you want it to do. But you never throw away any data….
So yeah, that's now my view, is I think ULMFiT is the wrong approach. And that's why we're seeing a lot of these so-called alignment tax… I think it's actually because people are training them wrong.
An example of this phenomena is CodeLlama, a LLaMA2 model finetuned on 500B tokens of code: while the model is much better at code, it’s worse on generic tasks that LLaMA2 knew how to solve well before the fine-tuning.
In the episode we also dive into all the places where open source model development and research is happening (academia vs Discords - tracked on our Communities list and on our survey), and how Jeremy recommends getting the most out of these diffuse, pseudonymous communities (similar to the Eleuther AI Mafia).
Show Notes
Jeremy’s Background
fastec2 (the underrated library we describe)
Can LLMs learn from a single example?
the Kaggle LLM Science Exam competition, which “challenges participants to answer difficult science-based questions written by a Large Language Model”.
Timestamps
[00:00:00] Intros and Jeremy’s background
[00:05:28] Creating ULM Fit - a breakthrough in NLP using transfer learning
[00:06:32] The rise of GPT and the appeal of few-shot learning over fine-tuning
[00:10:00] Starting Fast.ai to distribute AI capabilities beyond elite academics
[00:14:30] How modern LMs like ChatGPT still follow the ULM Fit 3-step approach
[00:17:23] Meeting with Chris Lattner on Swift for TensorFlow at Google
[00:20:00] Continued pre-training as a fine-tuning alternative
[00:22:16] Fast.ai and looking for impact vs profit maximization
[00:26:39] Using Fast.ai to create an "army" of AI experts to improve their domains
[00:29:32] Fast.ai's 3 focus areas - research, software, and courses
[00:38:42] Fine-tuning memorization and training curve "clunks" before each epoch
[00:46:47] Poor training and fine-tuning practices may be causing alignment failures
[00:48:38] Academia vs Discords
[00:53:41] Jeremy's high hopes for Chris Lattner's Mojo and its potential
[01:05:00] Adding capabilities like SQL generation through quick fine-tuning
[01:10:12] Rethinking Fast.ai courses for the AI-assisted coding era
[01:14:53] Rapid model development has created major technical debt
[01:17:08] Lightning Round
AI Summary (beta)
This is the first episode we’re trying this. Here’s an overview of the main topics before you dive in the transcript.
Jeremy's background and philosophies on AI
Studied philosophy and cognitive science in college
Focused on ethics and thinking about AI even 30 years ago
Believes AI should be accessible to more people, not just elite academics/programmers
Created fast.ai to make deep learning more accessible
Development of transfer learning and ULMFit
Idea of transfer learning critical for making deep learning accessible
ULMFit pioneered transfer learning for NLP
Proposed training general language models on large corpora then fine-tuning - this became standard practice
Faced skepticism that this approach would work from NLP community
Showed state-of-the-art results on text classification soon after trying it
Current open questions around fine-tuning LLMs
Models appear to memorize training data extremely quickly (after 1 epoch)
This may hurt training dynamics and cause catastrophic forgetting
Unclear how best to fine-tune models to incorporate new information/capabilities
Need more research on model training dynamics and ideal data mixing
Exciting new developments
Mojo and new programming languages like Swift could enable faster model innovation
Still lots of room for improvements in computer vision-like innovations in transformers
Small models with fine-tuning may be surprisingly capable for many real-world tasks
Prompting strategies enable models like GPT-3 to achieve new skills like playing chess at superhuman levels
LLMs are like computer vision in 2013 - on the cusp of huge new breakthroughs in capabilities
Access to AI research
Many key convos happen in private Discord channels and forums
Becoming part of these communities can provide great learning opportunities
Being willing to do real work, not just talk about ideas, is key to gaining access
The future of practical AI
Coding becoming more accessible to non-programmers through AI assistance
Pre-requisite programming experience for learning AI may no longer be needed
Huge open questions remain about how to best train, fine-tune, and prompt LLMs
Transcript
Alessio: Hey everyone, welcome to the Latent Space Podcast. This is Alessio, partner and CTO at Residence at Decibel Partners, and I'm joined by my co-host Swyx, founder of Smol AI. [00:00:21]
Swyx: Hey, and today we have in the remote studio, Jeremy Howard all the way from Australia. Good morning. [00:00:27]
Jeremy: The remote studio, also known as my house. Good morning. Nice to see you. [00:00:32]
Swyx: Nice to see you too. I'm actually very used to seeing you in your mask as a message to people, but today we're mostly audio. But thank you for doing the very important public service of COVID awareness. It was a pleasure. [00:00:46]
Jeremy: It was all very annoying and frustrating and tedious, but somebody had to do it. [00:00:52]
Swyx: Somebody had to do it, especially somebody with your profile. I think it really drives home the message. So we tend to introduce people for them and then ask people to fill in the blanks on the personal side. Something I did not know about you was that you graduated with a BA in philosophy from the University of Melbourne. I assumed you had a PhD. [00:01:14]
Jeremy: No, I mean, I barely got through my BA because I was working 80 to 100 hour weeks at McKinsey and Company from 19 years old onwards. So I actually didn't attend any lectures in second and third year university. [00:01:35]
Swyx: Well, I guess you didn't need it or you're very sort of self-driven and self-motivated. [00:01:39]
Jeremy: I took two weeks off before each exam period when I was working at McKinsey. And then, I mean, I can't believe I got away with this in hindsight, I would go to all my professors and say, oh, I was meant to be in your class this semester and I didn't quite turn up. Were there any assignments I was meant to have done, whatever. I can't believe all of them let me basically have it. They basically always would say like, okay, well, if you can have this written by tomorrow, I'll accept it. So yeah, stressful way to get through university, but. [00:02:12]
Swyx: Well, it shows that, I guess, you min-maxed the opportunities. That definitely was a precursor. [00:02:18]
Jeremy: I mean, funnily, like in as much as I, you know, in philosophy, the things I found interesting and focused on in the little bit of time I did spend on it was ethics and cognitive science. And it's kind of really amazing that it's now come back around and those are actually genuinely useful things to know about, which I never thought would happen. [00:02:38]
Swyx: A lot of, yeah, a lot of relevant conversations there. So you were a consultant for a while and then in the magical month of June 1989, you founded both Optimal Decisions and Fastmeal, which I also briefly used. So thank you for that. [00:02:53]
Jeremy: Oh, good for you. Yeah. Cause I had read the statistics, which is that like 90% or something of small businesses fail. So I thought if I start two businesses, I have a higher chance. In hindsight, I was thinking of it as some kind of stochastic thing I didn't have control over, but it's a bit odd, but anyway. [00:03:10]
Swyx: And then you were president and chief scientist at Kaggle, which obviously is the sort of composition platform of machine learning. And then Enlitic, where you were working on using deep learning to improve medical diagnostics and clinical decisions. Yeah. [00:03:28]
Jeremy: I was actually the first company to use deep learning in medicine, so I kind of founded the field. [00:03:33]
Swyx: And even now that's still like a pretty early phase. And I actually heard you on your new podcast with Tanish, where you went very, very deep into the stuff, the kind of work that he's doing, such a young prodigy at his age. [00:03:47]
Jeremy: Maybe he's too old to be called a prodigy now, ex-prodigy. No, no. [00:03:51]
Swyx: I think he still counts. And anyway, just to round out the bio, you have a lot more other credentials, obviously, but most recently you started Fast.ai, which is still, I guess, your primary identity with Rachel Thomas. So welcome. [00:04:05]
Jeremy: Yep. [00:04:06]
Swyx: Thanks to my wife. Thank you. Yeah. Doing a lot of public service there with getting people involved in AI, and I can't imagine a better way to describe it than fast, fast.ai. You teach people from nothing to stable diffusion in seven weeks or something, and that's amazing. Yeah, yeah. [00:04:22]
Jeremy: I mean, it's funny, you know, when we started that, what was that, like 2016 or something, the idea that deep learning was something that you could make more accessible was generally considered stupid. Everybody knew that deep learning was a thing that you got a math or a computer science PhD, you know, there was one of five labs that could give you the appropriate skills and that you would join, yeah, basically from one of those labs, you might be able to write some papers. So yeah, the idea that normal people could use that technology to do good work was considered kind of ridiculous when we started it. And we weren't sure if it was possible either, but we kind of felt like we had to give it a go because the alternative was we were pretty sure that deep learning was on its way to becoming, you know, the most or one of the most, you know, important technologies in human history. And if the only people that could use it were a handful of computer science PhDs, that seemed like A, a big waste and B, kind of dangerous. [00:05:28]
Swyx: Yeah. [00:05:29]
Alessio: And, you know, well, I just wanted to know one thing on your bio that at Kaggle, you were also the top rank participant in both 2010 and 2011. So sometimes you see a lot of founders running companies that are not really in touch with the problem, but you were clearly building something that you knew a lot about, which is awesome. Talking about deep learning, you created, published a paper on ULM fit, which was kind of the predecessor to multitask learning and a lot of the groundwork that then went to into Transformers. I've read back on the paper and you turned this model, AWD LSTM, which I did the math and it was like 24 to 33 million parameters, depending on what training data set you use today. That's kind of like not even small, it's like super small. What were some of the kind of like contrarian takes that you had at the time and maybe set the stage a little bit for the rest of the audience on what was kind of like the state of the art, so to speak, at the time and what people were working towards? [00:06:32]
Jeremy: Yeah, the whole thing was a contrarian take, you know. So okay, so we started Fast.ai, my wife and I, and we thought, yeah, so we're trying to think, okay, how do we make it more accessible? So when we started thinking about it, it was probably 2015 and then 2016, we started doing something about it. Why is it inaccessible? Okay, well, A, no one knows how to do it other than a few number of people. And then when we asked those few number of people, well, how do you actually get good results? They would say like, oh, it's like, you know, a box of tricks that aren't published. So you have to join one of the labs and learn the tricks. So a bunch of unpublished tricks, not much software around, but thankfully there was Theano and rappers and particularly Lasagna, the rapper, but yeah, not much software around, not much in the way of data sets, you know, very hard to get started in terms of the compute. Like how do you get that set up? So yeah, no, everything was kind of inaccessible. And you know, as we started looking into it, we had a key insight, which was like, you know what, most of the compute and data for image recognition, for example, we don't need to do it. You know, there's this thing which nobody knows about, nobody talks about called transfer learning, where you take somebody else's model, where they already figured out like how to detect edges and gradients and corners and text and whatever else, and then you can fine tune it to do the thing you want to do. And we thought that's the key. That's the key to becoming more accessible in terms of compute and data requirements. So when we started Fast.ai, we focused from day one on transfer learning. Lesson one, in fact, was transfer learning, literally lesson one, something not normally even mentioned in, I mean, there wasn't much in the way of courses, you know, the courses out there were PhD programs that had happened to have recorded their lessons and they would rarely mention it at all. We wanted to show how to do four things that seemed really useful. You know, work with vision, work with tables of data, work with kind of recommendation systems and collaborative filtering and work with text, because we felt like those four kind of modalities covered a lot of the stuff that, you know, are useful in real life. And no one was doing anything much useful with text. Everybody was talking about word2vec, you know, like king plus queen minus woman and blah, blah, blah. It was like cool experiments, but nobody's doing anything like useful with it. NLP was all like lemmatization and stop words and topic models and bigrams and SPMs. And it was really academic and not practical. But I mean, to be honest, I've been thinking about this crazy idea for nearly 30 years since I had done cognitive science at university, where we talked a lot about the CELS Chinese room experiment. This idea of like, what if there was somebody that could kind of like, knew all of the symbolic manipulations required to answer questions in Chinese, but they didn't speak Chinese and they were kind of inside a room with no other way to talk to the outside world other than taking in slips of paper with Chinese written on them and then they do all their rules and then they pass back a piece of paper with Chinese back. And this room with a person in is actually fantastically good at answering any question you give them written in Chinese. You know, do they understand Chinese? And is this, you know, something that's intelligently working with Chinese? Ever since that time, I'd say the most thought, to me, the most thoughtful and compelling philosophical response is yes. You know, intuitively it feels like no, because that's just because we can't imagine such a large kind of system. But you know, if it looks like a duck and acts like a duck, it's a duck, you know, or to all intents and purposes. And so I always kind of thought, you know, so this is basically a kind of analysis of the limits of text. And I kind of felt like, yeah, if something could ingest enough text and could use the patterns it saw to then generate text in response to text, it could appear to be intelligent, you know. And whether that means it is intelligent or not is a different discussion and not one I find very interesting. Yeah. And then when I came across neural nets when I was about 20, you know, what I learned about the universal approximation theorem and stuff, and I started thinking like, oh, I wonder if like a neural net could ever get big enough and take in enough data to be a Chinese room experiment. You know, with that background and this kind of like interest in transfer learning, you know, I'd been thinking about this thing for kind of 30 years and I thought like, oh, I wonder if we're there yet, you know, because we have a lot of text. Like I can literally download Wikipedia, which is a lot of text. And I thought, you know, how would something learn to kind of answer questions or, you know, respond to text? And I thought, well, what if we used a language model? So language models are already a thing, you know, they were not a popular or well-known thing, but they were a thing. But language models exist to this idea that you could train a model to fill in the gaps. Or actually in those days it wasn't fill in the gaps, it was finish a string. And in fact, Andrej Karpathy did his fantastic RNN demonstration from this at a similar time where he showed like you can have it ingest Shakespeare and it will generate something that looks a bit like Shakespeare. I thought, okay, so if I do this at a much bigger scale, using all of Wikipedia, what would it need to be able to do to finish a sentence in Wikipedia effectively, to do it quite accurately quite often? I thought, geez, it would actually have to know a lot about the world, you know, it'd have to know that there is a world and that there are objects and that objects relate to each other through time and cause each other to react in ways and that causes proceed effects and that, you know, when there are animals and there are people and that people can be in certain positions during certain timeframes and then you could, you know, all that together, you can then finish a sentence like this was signed into law in 2016 by US President X and it would fill in the gap, you know. So that's why I tried to create what in those days was considered a big language model trained on the entirety on Wikipedia, which is that was, you know, a bit unheard of. And my interest was not in, you know, just having a language model. My interest was in like, what latent capabilities would such a system have that would allow it to finish those kind of sentences? Because I was pretty sure, based on our work with transfer learning and vision, that I could then suck out those latent capabilities by transfer learning, you know, by fine-tuning it on a task data set or whatever. So we generated this three-step system. So step one was train a language model on a big corpus. Step two was fine-tune a language model on a more curated corpus. And step three was further fine-tune that model on a task. And of course, that's what everybody still does today, right? That's what ChatGPT is. And so the first time I tried it within hours, I had a new state-of-the-art academic result on IMDB. And I was like, holy shit, it does work. And so you asked, to what degree was this kind of like pushing against the established wisdom? You know, every way. Like the reason it took me so long to try it was because I asked all my friends in NLP if this could work. And everybody said, no, it definitely won't work. It wasn't like, oh, maybe. Everybody was like, it definitely won't work. NLP is much more complicated than vision. Language is a much more vastly complicated domain. You know, and you've got problems like the grounding problem. We know from like philosophy and theory of mind that it's actually impossible for it to work. So yeah, so don't waste your time. [00:15:10]
Alessio: Jeremy, had people not tried because it was like too complicated to actually get the data and like set up the training? Or like, were people just lazy and kind of like, hey, this is just not going to work? [00:15:20]
Jeremy: No, everybody wasn't lazy. So like, so the person I thought at that time who, you know, there were two people I thought at that time, actually, who were the strongest at language models were Stephen Merity and Alec Radford. And at the time I didn't know Alec, but I, after we had both, after I'd released ULM Fit and he had released GPT, I organized a chat for both of us with Kate Metz in the New York Times. And Kate Metz answered, sorry, and Alec answered this question for Kate. And Kate was like, so how did, you know, GPT come about? And he said, well, I was pretty sure that pre-training on a general large corpus wouldn't work. So I hadn't tried it. And then I read ULM Fit and turns out it did work. And so I did it, you know, bigger and it worked even better. And similar with, with Stephen, you know, I asked Stephen Merity, like, why don't we just find, you know, take your AWD-ASTLM and like train it on all of Wikipedia and fine tune it? And he's kind of like, well, I don't think that's going to really lie. Like two years before I did a very popular talk at KDD, the conference where everybody in NLP was in the audience. I recognized half the faces, you know, and I told them all this, I'm sure transfer learning is the key. I'm sure ImageNet, you know, is going to be an NLP thing as well. And, you know, everybody was interested and people asked me questions afterwards and, but not just, yeah, nobody followed up because everybody knew that it didn't work. I mean, even like, so we were scooped a little bit by Dai and Lee, Kwok Lee at Google. They had, they had, I already, I didn't even realize this, which is a bit embarrassing. They had already done a large language model and fine tuned it. But again, they didn't create a general purpose, large language model on a general purpose corpus. They only ever tested a domain specific corpus. And I haven't spoken to Kwok actually about that, but I assume that the reason was the same. It probably just didn't occur to them that the general approach could work. So maybe it was that kind of 30 years of mulling over the, the cell Chinese room experiment that had convinced me that it probably would work. I don't know. Yeah. [00:17:48]
Alessio: Interesting. I just dug up Alec announcement tweet from 2018. He said, inspired by Cobe, Elmo, and Yola, I'm fit. We should have a single transformer language model can be fine tuned to a wide variety. It's interesting because, you know, today people think of AI as the leader, kind of kind of like the research lab pushing forward the field. What was that at the time? You know, like kind of like going back five years, people think of it as an overnight success, but obviously it took a while. [00:18:16]
Swyx: Yeah. Yeah. [00:18:17]
Jeremy: No, I mean, absolutely. And I'll say like, you know, it's interesting that it mentioned Elmo because in some ways that was kind of diametrically opposed to, to ULM fit. You know, there was these kind of like, so there was a lot of, there was a lot of activity at the same time as ULM fits released. So there was, um, so before it, as Brian McCann, I think at Salesforce had come out with this neat model that did a kind of multitask learning, but again, they didn't create a general fine tune language model first. There was Elmo, um, which I think was a lip, you know, actually quite a few months after the first ULM fit example, I think. Um, but yeah, there was a bit of this stuff going on. And the problem was everybody was doing, and particularly after GPT came out, then everybody wanted to focus on zero shot and few shot learning. You know, everybody hated fine tuning. Everybody hated transfer learning. And like, I literally did tours trying to get people to start doing transfer learning and people, you know, nobody was interested, particularly after GPT showed such good results with zero shot and few shot learning. And so I actually feel like we kind of went backwards for years and, and not to be honest, I mean, I'm a bit sad about this now, but I kind of got so disappointed and dissuaded by like, it felt like these bigger lab, much bigger labs, you know, like fast AI had only ever been just me and Rachel were getting all of this attention for an approach I thought was the wrong way to do it. You know, I was convinced was the wrong way to do it. And so, yeah, for years people were really focused on getting better at zero shot and few shots and it wasn't until, you know, this key idea of like, well, let's take the ULM fit approach, but for step two, rather than fine tuning on a kind of a domain corpus, let's fine tune on an instruction corpus. And then in step three, rather than fine tuning on a reasonably specific task classification, let's fine tune on a, on a RLHF task classification. And so that was really, that was really key, you know, so I was kind of like out of the NLP field for a few years there because yeah, it just felt like, I don't know, pushing uphill against this vast tide, which I was convinced was not the right direction, but who's going to listen to me, you know, cause I, as you said, I don't have a PhD, not at a university, or at least I wasn't then. I don't have a big set of computers to fine tune huge transformer models. So yeah, it was definitely difficult. It's always been hard. You know, it's always been hard. Like I've always been somebody who does not want to build stuff on lots of big computers because most people don't have lots of big computers and I hate creating stuff that most people can't use, you know, and also stuff that's created on lots of big computers has always been like much more media friendly. So like, it might seem like a recent thing, but actually throughout my 30 years in data science, the attention's always been on, you know, the big iron results. So when I first started, everybody was talking about data warehouses and it was all about Teradata and it'd be like, oh, this big bank has this huge room full of computers and they have like terabytes of data available, you know, at the press of a button. And yeah, that's always what people want to talk about, what people want to write about. And then of course, students coming out of their PhDs and stuff, that's where they want to go work because that's where they read about. And to me, it's a huge distraction, you know, because like I say, most people don't have unlimited compute and I want to help most people, not the small subset of the most well-off people. [00:22:16]
Alessio: That's awesome. And it's great to hear, you do such a great job educating that a lot of times you're not telling your own story, you know? So I love this conversation. And the other thing before we jump into Fast.AI, actually, a lot of people that I know, they run across a new architecture and whatnot, they're like, I got to start a company and raise a bunch of money and do all of this stuff. And say, you were like, I want everybody to have access to this. Why was that the case for you? Was it because you already had a successful venture in like FastMail and you were more interested in that? What was the reasoning? [00:22:52]
Jeremy: It's a really good question. So I guess the answer is yes, that's the reason why. So when I was a teenager, I thought it would be really cool to like have my own company. You know, I didn't know the word startup. I didn't know the word entrepreneur. I didn't know the word VC. And I didn't really know what any of those things were really until after we started Kaggle, to be honest. Even the way it started to what we now call startups. I just thought they were just small businesses. You know, they were just companies. So yeah, so those two companies were FastMail and Optimal Decisions. FastMail was the first kind of synchronized email provider for non-businesses. So something you can get your same email at home, on your laptop, at work, on your phone, whatever. And then Optimal Decisions invented a new approach to insurance pricing. Something called profit-optimized insurance pricing. So I saw both of those companies, you know, after 10 years. And at that point, I had achieved the thing that as a teenager I had wanted to do. You know, it took a lot longer than it should have because I spent way longer in management consulting than I should have because I got caught up in that stupid rat race. But, you know, eventually I got there and I remember my mom saying to me, you must be so proud. You know, because she remembered my dream. She's like, you've done it. And I kind of reflected and I was like, I'm not proud at all. You know, like people quite liked FastMail. You know, it's quite nice to have synchronized email. It probably would have happened anyway. Yeah, I'm certainly not proud that I've helped some insurance companies suck more money out of their customers. Yeah, no, I'm not proud. You know, it's actually, I haven't really helped the world very much. You know, maybe in the insurance case I've made it a little bit worse. I don't know. So, yeah, I was determined to not waste more years of my life doing things, working hard to do things which I could not be reasonably sure would have a lot of value. So, you know, I took some time off. I wasn't sure if I'd ever work again, actually. I didn't particularly want to, because it felt like, yeah, it felt like such a disappointment. And, but, you know, and I didn't need to. I had enough money. Like, I wasn't super rich, but I had enough money. I didn't need to work. And I certainly recognized that amongst the other people I knew who had enough money that they didn't need to work, they all worked ridiculously hard, you know, and constantly put themselves in extremely stressful situations. And I thought, I don't want to be one of those idiots who's tied to, you know, buying a bigger plane than the next guy or whatever. You know, Kaggle came along and I mainly kind of did that just because it was fun and interesting to hang out with interesting people. But, you know, with Fast.ai in particular, you know, Rachel and I had a very explicit, you know, long series of conversations over a long period of time about like, well, how can we be the most helpful to society as a whole, and particularly to those people who maybe need more help, you know? And so we definitely saw the world going in a potentially pretty dystopian direction if the world's most powerful technology was controlled by a small group of elites. So we thought, yeah, we should focus on trying to help that not happen. You know, sadly, it looks like it still is likely to happen. But I mean, I feel like we've helped make it a little bit less likely. So we've done our bit. [00:26:39]
Swyx: You've shown that it's possible. And I think your constant advocacy, your courses, your research that you publish, you know, just the other day you published a finding on, you know, learning that I think is still something that people are still talking about quite a lot. I think that that is the origin story of a lot of people who are going to be, you know, little Jeremy Howards, furthering your mission with, you know, you don't have to do everything by yourself is what I'm saying. No, definitely. Definitely. [00:27:10]
Jeremy: You know, that was a big takeaway from like, analytic was analytic. It definitely felt like we had to do everything ourselves. And I kind of, I wanted to solve medicine. I'll say, yeah, okay, solving medicine is actually quite difficult. And I can't do it on my own. And there's a lot of other things I'd like to solve, and I can't do those either. So that was definitely the other piece was like, yeah, you know, can we create an army of passionate domain experts who can change their little part of the world? And that's definitely happened. Like I find nowadays, at least half the time, probably quite a bit more that I get in contact with somebody who's done really interesting work in some domain. Most of the time I'd say, they say, yeah, I got my start with fast.ai. So it's definitely, I can see that. And I also know from talking to folks at places like Amazon and Adobe and stuff, which, you know, there's lots of alumni there. And they say, oh my God, I got here. And like half of the people are fast.ai alumni. So it's fantastic. [00:28:13]
Swyx: Yeah. [00:28:14]
Jeremy: Actually, Andre Kapathy grabbed me when I saw him at NeurIPS a few years ago. And he was like, I have to tell you, thanks for the fast.ai courses. When people come to Tesla and they need to know more about deep learning, we always send them to your course. And the OpenAI Scholars Program was doing the same thing. So it's kind of like, yeah, it's had a surprising impact, you know, that's just one of like three things we do is the course, you know. [00:28:40]
Swyx: Yes. [00:28:40]
Jeremy: And it's only ever been at most two people, either me and Rachel or me and Sylvia nowadays, it's just me. So yeah, I think it shows you don't necessarily need a huge amount of money and a huge team of people to make an impact. [00:28:56]
Swyx: Yeah. So just to reintroduce fast.ai for people who may not have dived into it much, there is the courses that you do. There is the library that is very well loved. And I kind of think of it as a nicer layer on top of PyTorch that people should start with by default and use it as the basis for a lot of your courses. And then you have like NBDev, which I don't know, is that the third one? [00:29:27]
Jeremy: Oh, so the three areas were research, software, and courses. [00:29:32]
Swyx: Oh, sorry. [00:29:32]
Jeremy: So then in software, you know, fast.ai is the main thing, but NBDev is not far behind. But then there's also things like FastCore, GHAPI, I mean, dozens of open source projects that I've created and some of them have been pretty popular and some of them are still a little bit hidden, actually. Some of them I should try to do a better job of telling people about. [00:30:01]
Swyx: What are you thinking about? Yeah, what's on the course of my way? Oh, I don't know, just like little things. [00:30:04]
Jeremy: Like, for example, for working with EC2 and AWS, I created a FastEC2 library, which I think is like way more convenient and nice to use than anything else out there. And it's literally got a whole autocomplete, dynamic autocomplete that works both on the command line and in notebooks that'll like auto-complete your instance names and everything like that. You know, just little things like that. I try to make like, when I work with some domain, I try to make it like, I want to make it as enjoyable as possible for me to do that. So I always try to kind of like, like with GHAPI, for example, I think that GitHub API is incredibly powerful, but I didn't find it good to work with because I didn't particularly like the libraries that are out there. So like GHAPI, like FastEC2, it like autocompletes both at the command line or in a notebook or whatever, like literally the entire GitHub API. The entire thing is like, I think it's like less than 100K of code because it actually, as far as I know, the only one that grabs it directly from the official open API spec that GitHub produces. And like if you're in GitHub and you just type an API, you know, autocomplete API method and hit enter, it prints out the docs with brief docs and then gives you a link to the actual documentation page. You know, GitHub Actions, I can write now in Python, which is just so much easier than writing them in TypeScript and stuff. So, you know, just little things like that. [00:31:40]
Swyx: I think that's an approach which more developers took to publish some of their work along the way. You described the third arm of FastAI as research. It's not something I see often. Obviously, you do do some research. And how do you run your research? What are your research interests? [00:31:59]
Jeremy: Yeah, so research is what I spend the vast majority of my time on. And the artifacts that come out of that are largely software and courses. You know, so to me, the main artifact shouldn't be papers because papers are things read by a small exclusive group of people. You know, to me, the main artifacts should be like something teaching people, here's how to use this insight and here's software you can use that builds it in. So I think I've only ever done three first-person papers in my life, you know, and none of those are ones I wanted to do. You know, they were all ones that, like, so one was ULM Fit, where Sebastian Ruder reached out to me after seeing the course and said, like, you have to publish this as a paper, you know. And he said, I'll write it. He said, I want to write it because if I do, I can put it on my PhD and that would be great. And it's like, okay, well, I want to help you with your PhD. And that sounds great. So like, you know, one was the masks paper, which just had to exist and nobody else was writing it. And then the third was the Fast.ai library paper, which again, somebody reached out and said, please, please write this. We will waive the fee for the journal and everything and actually help you get it through publishing and stuff. So yeah, so I don't, other than that, I've never written a first author paper. So the research is like, well, so for example, you know, Dawn Bench was a competition, which Stanford ran a few years ago. It was kind of the first big competition of like, who can train neural nets the fastest rather than the most accurate. And specifically it was who can train ImageNet the fastest. And again, this was like one of these things where it was created by necessity. So Google had just released their TPUs. And so I heard from my friends at Google that they had put together this big team to smash Dawn Bench so that they could prove to people that they had to use Google Cloud and use their TPUs and show how good their TPUs were. And we kind of thought, oh shit, this would be a disaster if they do that, because then everybody's going to be like, oh, deep learning is not accessible. [00:34:20]
Swyx: You know, to actually be good at it, [00:34:21]
Jeremy: you have to be Google and you have to use special silicon. And so, you know, we only found out about this 10 days before the competition finished. But, you know, we basically got together an emergency bunch of our students and Rachel and I and sat for the next 10 days and just tried to crunch through and try to use all of our best ideas that had come from our research. And so particularly progressive resizing, just basically train mainly on small things, train on non-square things, you know, stuff like that. And so, yeah, we ended up winning, thank God. And so, you know, we turned it around from being like, like, oh shit, you know, this is going to show that you have to be Google and have TPUs to being like, oh my God, even the little guy can do deep learning. So that's an example of the kind of like research artifacts we do. And yeah, so all of my research is always, how do we do more with less, you know? So how do we get better results with less data, with less compute, with less complexity, with less education, you know, stuff like that. So ULM fits obviously a good example of that. [00:35:37]
Swyx: And most recently you published, can LLMs learn from a single example? Maybe could you tell the story a little bit behind that? And maybe that goes a little bit too far into the learning of very low resource, the literature. [00:35:52]
Jeremy: Yeah, yeah. So me and my friend, Jono Whittaker, basically had been playing around with this fun Kaggle competition, which is actually still running as we speak, which is, can you create a model which can answer multiple choice questions about anything that's in Wikipedia? And the thing that makes it interesting is that your model has to run on Kaggle within nine hours. And Kaggle's very, very limited. So you've only got 14 gig RAM, only two CPUs, and a small, very old GPU. So this is cool, you know, if you can do well at this, then this is a good example of like, oh, you can do more with less. So yeah, Jono and I were playing around with fine tuning, of course, transfer learning, pre-trained language models. And we saw this, like, so we always, you know, plot our losses as we go. So here's another thing we created. Actually, Sylvain Guuger, when he worked with us, created called fast progress, which is kind of like TQEDM, but we think a lot better. So we look at our fast progress curves, and they kind of go down, down, down, down, down, down, down, a little bit, little bit, little bit. And then suddenly go clunk, and they drop. And then down, down, down, down, down a little bit, and then suddenly clunk, they drop. We're like, what the hell? These clunks are occurring at the end of each epoch. So normally in deep learning, this would be, this is, you know, I've seen this before. It's always been a bug. It's always turned out that like, oh, we accidentally forgot to turn on eval mode during the validation set. So I was actually learning then, or, oh, we accidentally were calculating moving average statistics throughout the epoch. So, you know, so it's recently moving average or whatever. And so we were using Hugging Face Trainer. So, you know, I did not give my friends at Hugging Face the benefit of the doubt. I thought, oh, they've fucked up Hugging Face Trainer, you know, idiots. Well, you'll use the Fast AI Trainer instead. So we switched over to Learner. We still saw the clunks and, you know, that's, yeah, it shouldn't really happen because semantically speaking in the epoch, isn't like, it's not a thing, you know, like nothing happens. Well, nothing's meant to happen when you go from ending one epoch to starting the next one. So there shouldn't be a clunk, you know. So I kind of asked around on the open source discords. That's like, what's going on here? And everybody was just like, oh, that's just what, that's just what these training curves look like. Those all look like that. Don't worry about it. And I was like, oh, are you all using Trainer? Yes. Oh, well, there must be some bug with Trainer. And I was like, well, we also saw it in Learner [00:38:42]
Swyx: and somebody else is like, [00:38:42]
Jeremy: no, we've got our own Trainer. We get it as well. They're just like, don't worry about it. It's just something we see. It's just normal. [00:38:48]
Swyx: I can't do that. [00:38:49]
Jeremy: I can't just be like, here's something that's like in the previous 30 years of neural networks, nobody ever saw it. And now suddenly we see it. [00:38:57]
Swyx: So don't worry about it. [00:38:59]
Jeremy: I just, I have to know why. [00:39:01]
Swyx: Can I clarify? This is, was everyone that you're talking to, were they all seeing it for the same dataset or in different datasets? [00:39:08]
Jeremy: Different datasets, different Trainers. They're just like, no, this is just, this is just what it looks like when you fine tune language models. Don't worry about it. You know, I hadn't seen it before, but I'd been kind of like, as I say, I, you know, I kept working on them for a couple of years after ULM fit. And then I kind of moved on to other things, partly out of frustration. So I hadn't been fine tuning, you know, I mean, Lama's only been out for a few months, right? But I wasn't one of those people who jumped straight into it, you know? So I was relatively new to the kind of Lama fine tuning world, where else these guys had been, you know, doing it since day one. [00:39:49]
Swyx: It was only a few months ago, [00:39:51]
Jeremy: but it's still quite a bit of time. So, so yeah, they're just like, no, this is all what we see. [00:39:56]
Swyx: Don't worry about it. [00:39:56]
Jeremy: So yeah, I, I've got a very kind of like, I don't know, I've just got this brain where I have to know why things are. And so I kind of, I ask people like, well, why, why do you think it's happening? And they'd be like, oh, it would pretty obviously, cause it's like memorize the data set. It's just like, that can't be right. It's only seen it once. Like, look at this, the loss has dropped by 0.3, 0.3, which is like, basically it knows the answer. And like, no, no, it's just, it is, it's just memorize the data set. So yeah. So look, Jono and I did not discover this and Jono and I did not come up with a hypothesis. You know, I guess we were just the ones, I guess, who had been around for long enough to recognize that like, this, this isn't how it's meant to work. And so we, we, you know, and so we went back and like, okay, let's just run some experiments, you know, cause nobody seems to have actually published anything about this. [00:40:51]
Well, not quite true.
Some people had published things, but nobody ever actually stepped back and said like, what the hell, you know, how can this be possible? Is it possible? Is this what's happening? And so, yeah, we created a bunch of experiments where we basically predicted ahead of time. It's like, okay, if this hypothesis is correct, that it's memorized in the training set, then we ought to see blah, under conditions, blah, but not under these conditions. And so we ran a bunch of experiments and all of them supported the hypothesis that it was memorizing the data set in a single thing at once. And it's a pretty big data set, you know, which in hindsight, it's not totally surprising because the theory, remember, of the ULMFiT theory was like, well, it's kind of creating all these latent capabilities to make it easier for it to predict the next token. So if it's got all this kind of latent capability, it ought to also be really good at compressing new tokens because it can immediately recognize it as like, oh, that's just a version of this. So it's not so crazy, you know, but it is, it requires us to rethink everything because like, and nobody knows like, okay, so how do we fine tune these things? Because like, it doesn't even matter. Like maybe it's fine. Like maybe it's fine that it's memorized the data set after one go and you do a second go and okay, the validation loss is terrible because it's now really overconfident. [00:42:20]
Swyx: That's fine. [00:42:22]
Jeremy: Don't, you know, don't, I keep telling people, don't track validation loss, track validation accuracy because at least that will still be useful. Just another thing that's got lost since ULMFiT, nobody tracks accuracy of language models anymore. But you know, it'll still keep learning and it does, it does keep improving. But is it worse? You know, like, is it like, now that it's kind of memorized it, it's probably getting a less strong signal, you know, I don't know. So I still don't know how to fine tune language models properly and I haven't found anybody who feels like they do, like nobody really knows whether this memorization thing is, it's probably a feature in some ways. It's probably some things that you can do usefully with it. It's probably, yeah, I have a feeling it's messing up training dynamics as well. [00:43:13]
Swyx: And does it come at the cost of catastrophic forgetting as well, right? Like, which is the other side of the coin. [00:43:18]
Jeremy: It does to some extent, like we know it does, like look at Code Llama, for example. So Code Llama was a, I think it was like a 500 billion token fine tuning of Llama 2 using code. And also pros about code that Meta did. And honestly, they kind of blew it because Code Llama is good at coding, but it's bad at everything else, you know, and it used to be good. Yeah, I was pretty sure it was like, before they released it, me and lots of people in the open source discords were like, oh my God, you know, we know this is coming, Jan Lukinsk saying it's coming. I hope they kept at least like 50% non-code data because otherwise it's going to forget everything else. And they didn't, only like 0.3% of their epochs were non-code data. So it did, it forgot everything else. So now it's good at code and it's bad at everything else. So we definitely have catastrophic forgetting. It's fixable, just somebody has to do, you know, somebody has to spend their time training a model on a good mix of data. Like, so, okay, so here's the thing. Even though I originally created three-step approach that everybody now does, my view is it's actually wrong and we shouldn't use it. [00:44:36]
Jeremy: And that's because people are using it in a way different to why I created it. You know, I created it thinking the task-specific models would be more specific. You know, it's like, oh, this is like a sentiment classifier as an example of a task, you know, but the tasks now are like a, you know, RLHF, which is basically like answer questions that make people feel happy about your answer. So that's a much more general task and it's a really cool approach. And so we see, for example, RLHF also breaks models like, you know, like GPT-4, RLHDEFT, we know from kind of the work that Microsoft did, you know, the pre, the earlier, less aligned version was better. And these are all kind of examples of catastrophic forgetting. And so to me, the right way to do this is to fine-tune language models, is to actually throw away the idea of fine-tuning. There's no such thing. There's only continued pre-training. And pre-training is something where from the very start, you try to include all the kinds of data that you care about, all the kinds of problems that you care about, instructions, exercises, code, general purpose document completion, whatever. And then as you train, you gradually curate that, you know, you gradually make that higher and higher quality and more and more specific to the kinds of tasks you want it to do. But you never throw away any data. You always keep all of the data types there in reasonably high quantities. You know, maybe the quality filter, you stop training on low quality data, because that's probably fine to forget how to write badly, maybe. So yeah, that's now my view, is I think ULM fit is the wrong approach. And that's why we're seeing a lot of these, you know, so-called alignment tacks and this view of like, oh, a model can't both code and do other things. And, you know, I think it's actually because people are training them wrong. [00:46:47]
Swyx: Yeah, well, I think you have a clear [00:46:51]
Alessio: anti-laziness approach. I think other people are not as good hearted, you know, they're like, [00:46:57]
Swyx: hey, they told me this thing works. [00:46:59]
Alessio: And if I release a model this way, people will appreciate it, I'll get promoted and I'll kind of make more money. [00:47:06]
Jeremy: Yeah, and it's not just money. It's like, this is how citations work most badly, you know, so if you want to get cited, you need to write a paper that people in your field recognize as an advancement on things that we know are good. And so we've seen this happen again and again. So like I say, like zero shot and few shot learning, everybody was writing about that. Or, you know, with image generation, everybody just was writing about GANs, you know, and I was trying to say like, no, GANs are not the right approach. You know, and I showed again through research that we demonstrated in our videos that you can do better than GANs, much faster and with much less data. And nobody cared because again, like if you want to get published, you write a GAN paper that slightly improves this part of GANs and this tiny field, you'll get published, you know. So it's, yeah, it's not set up for real innovation. It's, you know, again, it's really helpful for me, you know, I have my own research lab with nobody telling me what to do and I don't even publish. So it doesn't matter if I get citations. And so I just write what I think actually matters. I wish there was, and, you know, and actually places like OpenAI, you know, the researchers there can do that as well. It's a shame, you know, I wish there was more academic, open venues in which people can focus on like genuine innovation. [00:48:38]
Swyx: Twitter, which is unironically has become a little bit of that forum. I wanted to follow up on one thing that you mentioned, which is that you checked around the open source discords. I don't know if it's too, I don't know if it's a pusher to ask like what discords are lively or useful right now. I think that something I definitely felt like I missed out on was the early days of Luther AI, which is a very hard bit. And, you know, like what is the new Luther? And you actually shouted out the alignment lab AI discord in your blog post. And that was the first time I even knew, like I saw them on Twitter, never knew they had a discord, never knew that there was actually substantive discussions going on in there and that you were an active member of it. Okay, yeah. [00:49:23]
Jeremy: And then even then, if you do know about that and you go there, it'll look like it's totally dead. And that's because unfortunately, nearly all the discords, nearly all of the conversation happens in private channels. You know, and that's, I guess. [00:49:35]
Swyx: How does someone get into that world? Because it's obviously very, very instructive, right? [00:49:42]
Jeremy: You could just come to the first AI discord, which I'll be honest with you, it's less bustling than some of the others, but it's not terrible. And so like, at least, to be fair, one of Emma's bustling channels is private. [00:49:57]
Swyx: I guess. [00:49:59]
Jeremy: So I'm just thinking. [00:50:01]
Swyx: It's just the nature of quality discussion, right? Yeah, I guess when I think about it, [00:50:05]
Jeremy: I didn't have any private discussions on our discord for years, but there was a lot of people who came in with like, oh, I just had this amazing idea for AGI. If you just thought about like, if you imagine that AI is a brain, then we, you know, this just, I don't want to talk about it. You know, I don't want to like, you don't want to be dismissive or whatever. And it's like, oh, well, that's an interesting comment, but maybe you should like, try training some models first to see if that aligns with your intuition. Like, oh, but how could I possibly learn? It's like, well, we have a course, just actually spend time learning. Like, you know, anyway. And there's like, okay, I know the people who always have good answers there. And so I created a private channel and put them all in it. And I got to admit, that's where I post more often because there's much less, you know, flight of fancy views about how we could solve AGI, blah, blah, blah. So there is a bit of that. But having said that, like, I think the bar is pretty low. Like if you join a Discord and you can hit the like participants or community or whatever button, you can see who's in it. And then you'll see at the top, who the admins or moderators or people in the dev role are. And just DM one of them and say like, oh, here's my GitHub. Well, here's some blog posts I wrote. You know, I'm interested in talking about this, you know, can I join the private channels? And I've never heard of anybody saying no. I will say, you know, Alutha's all pretty open. So you can do the Alutha Discord still. You know, one problem with the Alutha Discord is it's been going on for so long that it's like, it's very inside baseball. It's quite hard to get started. Yeah. Carpa AI looks, I think it's all open. That's just less stability. That's more accessible. [00:52:03]
Swyx: Yeah. [00:52:04]
Jeremy: There's also just recently, now it's research that does like the Hermes models and data set just opened. They've got some private channels, but it's pretty open, I think. You mentioned Alignment Lab, that one it's all the interesting stuff is on private channels. So just ask. If you know me, ask me, cause I've got admin on that one. There's also, yeah, OS Skunkworks, OS Skunkworks AI is a good Discord, which I think it's open. So yeah, they're all pretty good. [00:52:40]
Swyx: I don't want you to leak any, you know, Discords that don't want any publicity, but this is all helpful. [00:52:46]
Jeremy: We all want people, like we all want people. [00:52:49]
Swyx: We just want people who like, [00:52:51]
Jeremy: want to build stuff, rather than people who, and like, it's fine to not know anything as well, but if you don't know anything, but you want to tell everybody else what to do and how to do it, that's annoying. If you don't know anything and want to be told like, here's a really small kind of task that as somebody who doesn't know anything is going to take you a really long time to do, but it would still be helpful. Then, and then you go and do it. That would be great. The truth is, yeah, [00:53:19]
Swyx: like, I don't know, [00:53:20]
Jeremy: maybe 5% of people who come in with great enthusiasm and saying that they want to learn and they'll do anything. [00:53:25]
Swyx: And then somebody says like, [00:53:25]
Jeremy: okay, here's some work you can do. Almost nobody does that work. So if you're somebody who actually does the work and follows up, you will massively stand out. That's an extreme rarity. And everybody will then want to help you do more work. [00:53:41]
Swyx: So yeah. [00:53:41]
Jeremy: So just, yeah, just do work and people will want to support you. [00:53:47]
Alessio: Our Discord used to be referral only for a long time. We didn't have a public invite and then we opened it and they're kind of like channel gating. Yeah. A lot of people just want to do, I remember it used to be like, you know, a forum moderator. [00:54:00]
Swyx: It's like people just want to do [00:54:01]
Alessio: like drive-by posting, [00:54:03]
Swyx: you know, and like, [00:54:03]
Alessio: they don't want to help the community. They just want to get their question answered. [00:54:07]
Jeremy: I mean, the funny thing is our forum community does not have any of that garbage. You know, there's something specific about the low latency thing where people like expect an instant answer. And yeah, we're all somehow in a forum thread where they know it's like there forever. People are a bit more thoughtful, but then the forums are less active than they used to be because Discord has got more popular, you know? So it's all a bit of a compromise, you know, running a healthy community is, yeah, it's always a bit of a challenge. All right, we got so many more things [00:54:47]
Alessio: we want to dive in, but I don't want to keep you here for hours. [00:54:50]
Swyx: This is not the Lex Friedman podcast [00:54:52]
Alessio: we always like to say. One topic I would love to maybe chat a bit about is Mojo, modular, you know, CrystalLiner, not many of you on the podcast. So we want to spend a little time there. You recently did a hacker's guide to language models and you ran through everything from quantized model to like smaller models, larger models, and all of that. But obviously modular is taking its own approach. Yeah, what got you excited? I know you and Chris have been talking about this for like years and a lot of the ideas you had, so. [00:55:23]
Jeremy: Yeah, yeah, yeah, yeah, no, absolutely. So I met Chris, I think it was at the first TensorFlow Dev Summit. And I don't think he had even like, I'm not sure if he'd even officially started his employment with Google at that point. So I don't know, you know, certainly nothing had been mentioned. So I, you know, I admired him from afar with LLVM and Swift and whatever. And so I saw him walk into the courtyard at Google. It's just like, oh shit, man, that's Chris Latner. I wonder if he would lower his standards enough to talk to me. Well, worth a try. So I caught up my courage because like nobody was talking to him. He looked a bit lost and I wandered over and it's like, oh, you're Chris Latner, right? It's like, what are you doing here? What are you doing here? And I was like, yeah, yeah, yeah. It's like, oh, I'm Jeremy Howard. It's like, oh, do you do some of this AI stuff? And I was like, yeah, yeah, I like this AI stuff. Are you doing AI stuff? It's like, well, I'm thinking about starting to do some AI stuff. Yeah, I think it's going to be cool. And it's like, wow. So like, I spent the next half hour just basically brain dumping all the ways in which AI was stupid to him. And he listened patiently. And I thought he probably wasn't even remember or care or whatever. But yeah, then I kind of like, I guess I re-caught up with him a few months later. And it's like, I've been thinking about everything you said in that conversation. And he like narrated back his response to every part of it, projects he was planning to do. And it's just like, oh, this dude follows up. Holy shit. And I was like, wow, okay. And he was like, yeah, so we're going to create this new thing called Swift for TensorFlow. And it's going to be like, it's going to be a compiler with auto differentiation built in. And blah, blah, blah. And I was like, why would that help? [00:57:10]
Swyx: You know, why would you? [00:57:10]
Jeremy: And he was like, okay, with a compiler during the forward pass, you don't have to worry about saving context, you know, because a lot will be optimized in the backward. But I was like, oh my God. Because I didn't really know much about compilers. You know, I spent enough to kind of like, understand the ideas, but it hadn't occurred to me that a compiler basically solves a lot of the problems we have as end users. I was like, wow, that's amazing. Okay, you do know, right, that nobody's going to use this unless it's like usable. It's like, yeah, I know, right. So I was thinking you should create like a fast AI for this. So, okay, but I don't even know Swift. And he was like, well, why don't you start learning it? And if you have any questions, ask me. It's just like, holy shit. Like, not only has Chris Latner lowered his standards enough to talk to me, but he's offering me personal tutoring on the programming language that he made. So I was just like, I'm not going to let him down. So I spent like the next two months, like just nerding out on Swift. And it was just before Christmas that I kind of like started writing down what I'd learned. And so I wrote a couple of blog posts on like, okay, this is like my attempt to do numeric programming in Swift. And these are all the challenges I had. And these are some of the issues I had with like making things properly performant. And here are some libraries I wrote. And I sent it to Chris and was like, I hope he's not too disappointed with me, you know, because that would be the worst. It's like, you know, and I was also like, I was like, I hope he doesn't dislike the fact that I, you know, didn't love everything. [00:58:46]
Jeremy: And yeah, he was like, oh, thanks for sending me that. Let's get on a call and talk about it. And we spoke and he was like, this is amazing. I can't believe that you made this. This is exactly what Swift needs. And he was like, and so like somebody set up like a new Swift, what they call them, the equivalent of a pep, you know, kind of RFC thing of like, oh, you know, let's look at how we can implement Jeremy's ideas and the language. And so it's like, oh, wow. And so, yeah, you know, and then we ended up like literally teaching some lessons together about Swift for TensorFlow. And we built a fast AI kind of equivalent with him and his team. It was so much fun. Then in the end, you know, Google didn't follow through, which is fair enough, like asking everybody to learn a new programming language is going to be tough. But like, it was very obvious, very, very obvious at that time that TensorFlow 2 is going to be a failure, you know, and so it's felt like, okay, I, you know, well, you know, what are you going to do? Like, you can't focus on TensorFlow 2 because it's not going to, like, it's not working. It's never going to work. You know, nobody at Google's using it. Internally. So, you know, in the end, Chris left, you know, Swift for TensorFlow got archived. [01:00:13]
Swyx: There was no backup plan. [01:00:15]
Jeremy: So it kind of felt like Google was kind of screwed, you know, and Chris went and did something else. But we kept talking and I was like, look, Chris, you know, you've got to be your own boss, man. It's like, you know, you've got the ideas, you know, like only you've got the ideas, you know, and if your ideas are implemented, we'd all be so much better off because like Python's the best of a whole bunch of shit, you know, like I would, it's amazing, but it's awful, you know, compared to what it could be. And anyway, so eventually a few years later, he called me up and he was like, Jeremy, I've taken your advice. I've started a company. And I was like, oh my God. It's like, we've got to create a new language. We're going to create a new infrastructure. It's going to build, it's going to have all the stuff we've talked about. And it's like, oh wow. So that's what Mojo is. And so Mojo is like, you know, building on all the stuff that Chris has figured out over, I mean, really from when he did his PhD thesis, which developed LLVM onwards, you know, in Swift and MLIR, you know, the TensorFlow runtime engine, which is very good. You know, that was something that he built and has lasted. So yeah, I'm pumped about that. I mean, it's very speculative. Creating a whole new language is tough. I mean, Chris has done it before and he's created a whole C++ compiler amongst other things. Looking pretty hopeful. I mean, I hope it works because, you know, [01:01:53]
Alessio: You told them to quit his job. [01:01:55]
Swyx: So I mean, in the meantime, I will say, you know, [01:02:00]
Jeremy: Google now does have a backup plan, you know, they have Jax, which was never a strategy. It was just a bunch of people who also recognized TensorFlow 2 as shit and they just decided to build something else. And for years, my friends in that team were like, don't tell anybody about us because we don't want to be anything but a research project. So now these poor guys, suddenly they're the great white hope for Google's future. And so Jax is, you know, also not terrible, but it's still written in Python. Like it would be cool if we had all the benefits of Jax, but in a language that was designed for those kinds of purposes. So, you know, fingers crossed that, yeah, that Mojo turns out great. [01:02:45]
Swyx: Yeah. [01:02:47]
Alessio: Any other thoughts on when, where people should be spending their time? So that's more the kind of language framework level. Then you have the, you know, GGML, some of these other like quantization focused kind of model level things. Then you got the hardware people. It's like a whole other bucket. Yeah. What are some of the exciting stuff that you're excited about? [01:03:08]
Jeremy: Well, you won't be surprised to hear me say this, but I think fine tuning transfer learning is still a hugely underappreciated area. So today's zero shot, few shot learning equivalent is retrieval augmented generation, you know, RAC, which is like, just like few shot learning is a thing. Like it's a real thing. It's a useful thing. It's not a thing anybody would want to ignore. Why are people not spending at least as much effort on fine tuning? You know, cause you know, RAG is like such a inefficient hack really, [01:03:45]
Swyx: isn't it? [01:03:45]
Jeremy: It's like, you know, segment up my data in some somewhat arbitrary way, embed it, ask questions about that, you know, hope that my embedding, you know, model embeds questions in the same bedding space as the paragraphs, which obviously is not going to, if your question is like, if I've got a whole bunch of archive papers embeddings, and I asked like, what are all the ways in which we can make inference more efficient? Like the only paragraphs it'll find is like if there's a review paper, here's a list of ways to make, you know, inference more efficient. Doesn't have any of the specifics. No, it's not going to be like, oh, here's one way, here's one way, here's a different way in different papers, [01:04:33]
Swyx: you know? Yeah. [01:04:35]
Jeremy: If you fine tune a model, then all of that information is getting directly incorporated into the weights of your model in a much more efficient and nuanced way. And then you can use RAG on top of that. So I think that that's one area that's definitely like underappreciated. And also the kind of like the confluence or like, okay, how do you combine RAG and fine tuning, for example. [01:05:00]
Swyx: Something that I think a lot of people are uncertain about, and I don't expect you to know either, is that whether or not you can fine tune new information in, and I think that that is the focus of some of your open questions. And of course you can, right? [01:05:17]
Jeremy: Like, obviously you can, because there's no such thing as fine, there's no such thing as fine tuning. There's only continued pre-training. So fine tuning is pre-training, like they're literally the same thing. So the knowledge got in there in the first place through pre-training. So how could like continuing to pre-train not put more knowledge in? Like it's the same thing. The problem is just we're really bad at it because everybody's doing it dumb ways. So, you know, it's a good question. And it's not just new knowledge, but like new capabilities. You know, I think like in my Packers Guide to LLM, into Packers Guide to LLM's talk, I show a simple, I mean, it's a funny, that's a simple example, because it doesn't sound it, but like taking a pre-trained based model and getting it to generate SQL. And it took 15 minutes to train on a single GPU. You know, I think that might surprise people that that capability is at your fingertips. And, you know, because it was already there, it was just latent in the base model. Really pushing the boundaries of what you can do with small models, I think is a really interesting question. Like what can you do with a, like, I mean, there isn't much in the way of good small models. A really underappreciated one is a BTLM 3B, which is a like kind of 7B quality 3B model. There's not much at the 1 to 2B range sadly, there are some code ones, but like the fact that there are some really good code ones in that 1 to 2B range shows you that that's a great size for doing complex tasks well. [01:06:56]
Swyx: There was PHY 1 recently, which has been the subject of a little bit of discussion about whether to train on benchmarks. [01:07:04]
Jeremy: PHY 1.5 as well. So that's not a good model yet. [01:07:09]
Swyx: Why not? [01:07:11]
Jeremy: It's good at doing, so PHY 1 in particular is good at doing a very specific thing, which is creating very small Python snippets. [01:07:19]
Swyx: The thing, okay, [01:07:21]
Jeremy: so like PHY 1.5 has never read Wikipedia, for example, so it doesn't know who Tom Cruise is, you know, it doesn't know who anybody is, it doesn't know about any movies, it doesn't really know anything about anything, like, because it's never read anything, you know, it was trained on a nearly entirely synthetic data set, which is designed for it to learn reasoning, and so it was a research project, and a really good one, and it definitely shows us a powerful direction in terms of what you can do with synthetic data, and wow, gosh, even these tiny models can get pretty good reasoning skills, pretty good math skills, pretty good coding skills, [01:08:04]
Jeremy: but I don't know if it's a model you could necessarily build on. Some people have tried to do some fine tunes of it, and again, they're like surprisingly good in some ways for a 1.5b model, but not sure you'd find it useful for anything. [01:08:24]
Swyx: I think that's the struggle of pitching small models, because small is great, you know, you don't need a lot of resources to run them, but the performance evaluation is always so iffy, it's always just like, yeah, it works on some things, and we don't trust it for others. [01:08:41]
Jeremy: Yeah, so that's why we're back to fine tuning. So Microsoft did create a 5.1.5 web, but they didn't release it, unfortunately. I would say a 5.1.5 web with fine tuning for your task, you know, might quite, you know, might solve a lot of tasks that people have in their kind of day-to-day lives. You know, particularly in kind of an enterprise setting, I think there's a lot of like repetitive kind of processing that has to be done. It's a useful thing for coders to know about, because I think quite often you can like replace some thousands and thousands of lines of complex buggy code, maybe with a fine tune, you know. [01:09:24]
Swyx: Got it. Yeah. [01:09:27]
Alessio: And Jeremy, before we let you go, I think one question on top of a lot of people's minds. So you've done practical deep learning for coders in 2018, 19, 21, 22. I feel like the more time goes by, the more the GPUs get concentrated. If you're somebody who's interested in deep learning today and you don't want to go join OpenAI, you don't want to join Anthropic, what's like the best use of their time? Should they focus on, yeah, small model development? Should they focus on fine tuning math and all of that? Should they just like focus on making Ragnar a hack and coming up with a better solution? Yeah, what's a practical deep learning for coders 2024 kind of look like? [01:10:10]
Jeremy: Yeah. [01:10:11]
Swyx: I mean, good question. [01:10:12]
Jeremy: I'm trying to figure that out for myself. You know, like what should I teach? Because I definitely feel like things have changed a bit. You know, one of the ways in which things have changed is that coding is much more accessible now. So if you look at a lot of the folks in the kind of open source LLM community, they're folks who really hadn't coded before a year ago. And they're using these models to help them build stuff they couldn't build before, which is just fantastic, you know? So one thing I kind of think is like, okay, well, we need a lot more material to help these people use this newfound skill they have because they don't really know what they're doing, you know, and they don't claim to, but they're doing it anyway. And I think that's fantastic, you know? So like, are there things we could do to help people, [01:10:58]
Swyx: you know, bridge this gap? [01:11:00]
Jeremy: Because previously, you know, I know folks who were, you know, doing manual jobs a year ago, and now they're training language models thanks to the help of Codex and Copilot and whatever. So, you know, yeah, what does it look like to like really grab this opportunity? You know, maybe Fast.ai's goals can be dramatically expanded now to being like, let's make coding more accessible, you know, kind of AI-oriented coding more accessible. If so, our course should probably look very different, you know, and we'd have to throw away that like, oh, you have to have at least a year of full-time programming, you know, as a prerequisite. Yeah, what would happen if we got rid of that? So that's kind of one thought that's in my head. You know, as to what should other people do? Honestly, I don't think anybody has any idea, like, the more I look at it, what's going on. I know I don't, you know, like, we don't really know how to do anything very well. Clearly OpenAI do, like, they seem to be quite good at some things, or they're talking to folks at, or who have recently left OpenAI. [01:12:17]
Swyx: Even there, it's clear there's a lot of stuff [01:12:19]
Jeremy: they haven't really figured out, and they're just kind of like using recipes that they've noticed have been okay, so, yeah, we don't really know how to train these models well, we don't know how to fine-tune them well, we don't know how to do React well, we don't know what they can do, we don't know what they can't do, we don't know how big a model you need to solve different kinds of problems, we don't know what kind of problems they can't do, we don't know what good prompting strategies are for particular problems, you know. Like, somebody sent me a message the other day saying they've written something that is a prompting strategy for GPT-4, for GPT-4, they've written, like, 6,000 lines of Python code, and it's to help it play chess. And then they've said they've had it play against other chess engines, including the best Stockfish engines, and it's got an ELO of 3,400, [01:13:11]
Swyx: which would make it close to [01:13:13]
Jeremy: the best chess engine in existence. And I think this is a good example of, like, people were saying, like, GPT-4 can't play chess. I mean, I was sure that was wrong. I mean, obviously, it can play chess. But the difference between, like, with no prompting strategy, it can't even make legal moves, with good prompting strategies, it might be just about the best chess engine in the world, far better than any human player. So, yeah, I mean, we don't really know what the capabilities are yet. So I feel like it's all blue sky at this point. It feels like computer vision in 2013 to me, which was, like, in 2013, computer vision was, like, OK, OK. [01:13:51]
Swyx: We just had the AlexNet. [01:13:52]
Jeremy: We've had AlexNet. We've had VGGNet. It's around the time Zyler and Fergus, like, no, it's probably before that. So we hadn't yet had the Zyler and Fergus, like, oh, this is actually what's going on inside the layers. So, you know, we don't actually know what's happening inside these transformers. We don't know how to create good training dynamics. We don't really know anything much. And there's a reason for that, right? And the reason for that is language models suddenly got really useful. And so the kind of economically rational thing to do, like, this is not criticism. This is true. The economic rational thing to do is to, like, OK, like, build that as fast as possible. You know, make something work, get it out there. And that's what, you know, OpenAI in particular did and Anthropic kind of did. But there's a whole lot of technical debt everywhere. You know, nobody's really figured this stuff out because everybody's been so busy [01:14:53]
Swyx: building what we know works as quickly as possible. [01:14:57]
Jeremy: So, yeah, I think there's a huge amount of opportunity to, you know, I think we'll find things can be made to work a lot faster, a lot less memory. I got a whole bunch of ideas I want to try, you know, every time I look at something closely, like really closely, I'm always like, oh, it turns out this person actually had no idea what they're doing, you know, [01:15:21]
Swyx: which is fine. [01:15:23]
Jeremy: Like, none of us know what we're doing. We should experiment with that. As we had a trade out on the podcast [01:15:32]
Alessio: who created FlashAttention. Yeah. And I asked him, did nobody think of using SRAM before you? Like, were people just like, no. And he was like, yeah, people just didn't think of it. They didn't try. They didn't come from like a systems background. [01:15:48]
Swyx: Yeah. [01:15:48]
Jeremy: I mean, the thing about FlashAttention is, I mean, lots of people absolutely had thought of that. So had I, right? But I mean, the honest truth is, particularly before Triton, like everybody knew that tiling is the right way to solve anything. And everybody knew that attention, fused attention wasn't tiled. That was stupid. But not everybody's got his ability to like, be like, oh, well, I am confident enough in CUDA and or Triton to use that insight to write something better, you know? And this is where, like, I'm super excited about Mojo, right? And I always talk to Chris about FlashAttention because I'm like, you know, there is a thousand FlashAttentions out there for us to build. You just got to make it easy for us to build them. Like Triton definitely helps, but it's still not easy. You know, it still requires kind of really understanding the GPU architecture and writing it in that kind of very CUDA-ish way. So yeah, I think, you know, if Mojo or something equivalent can really work well, we're going to see a lot more FlashAttentions popping up. [01:17:06]
Swyx: Great, Jerry. [01:17:08]
Alessio: And before we wrap, we usually do a quick lightning round. [01:17:10]
Swyx: We're going to have three simple questions. [01:17:13]
Alessio: So the first one is around acceleration. And you've been in this field a long time. What's something that it's already here today in AI that you thought would take much longer? I don't think anything. [01:17:24]
Jeremy: So I've actually been slightly too bullish. So in my 2014 TED talk, I had a graph and I said, like, this is like the slope of human capabilities and this is the slope of AI capabilities. And I said, oh, and I put a dot saying we are here. It was just before they passed. And I looked back at the transcript the other day and I said, in five years, I think we'll, you know, we might have crossed that threshold in which computers will be better at most human tasks than most humans or most average humans. And so that might be almost true now for non-physical tasks. So I was like, took, you know, took that twice as long as I thought it might. [01:18:11]
Jeremy: Yeah, no, I wouldn't say anything surprised me too much. It's still like, definitely like, I got to admit, you know, I had a very visceral reaction using GPT-4 for the first time. Not because I found it surprising, but actually doing it, like something I was pretty sure would exist by about now, maybe a bit earlier. But actually using it definitely is different to just feeling like it's probably on its way, you know, and yeah, whatever GPT-5 looks like. I'm sure, I imagine I'll have the same visceral reaction, you know. [01:18:56]
Swyx: It's really amazing to watch develop. We also have an exploration question. So what do you think is the most interesting unsolved question in AI? [01:19:07]
Jeremy: How do language models learn? You know, what are the training dynamics? Like I want to see, there was a great paper about ResNets a few years ago that showed how, that was able to like plot a kind of projected three-dimensional loss surface for a ConvNet with and without skip connections. And you know, you could very clearly see without the skip connections, it was bumpy, and with the skip connections, it was super smooth. That's the kind of work we need. Like, so there was actually an interesting blog post that came out just today from the PyTorch team where some of them have created this like 3D matrix product visualization thing. [01:19:56]
Swyx: The MatMul Visualizer. [01:19:58]
Jeremy: Yeah, and they actually showed some nice examples of like a GPT-2 attention layer and like showed an animation and said, like, if you look at this, we can actually see a bit about what it's doing. You know, so again, it reminds me of the Zeiler and Fergus, you know, ConvNet paper that was the first one to do these reverse convolutions to show what's actually being learned in each layer in a ConvNet. Yeah, we need a lot more of this, like, what is going on inside these models? How do they actually learn? And then how can we use those insights to help them to learn better? So I think that would be one. The other exploration I'd really like to see is a much more rigorous analysis of what kind of data do they need at what level? And when do they need it? And how often? So that kind of like dataset mixing, curation, so forth. [01:20:52]
Swyx: Right. In order to get the best capabilities. Yeah. How much is Wikipedia? Yeah. [01:20:58]
Jeremy: Yeah. [01:20:59]
Swyx: Very uncertain. [01:20:59]
Jeremy: Fine-tune what, you know, what kind of mix do you need for it to keep its capabilities? And what are the kind of underlying capabilities that it most needs to keep? And if it loses those, it would lose all these other ones. And what data do you need to keep those? And, you know, other things we can do to change the loss function, to help it to not forget to do things, stuff like that. [01:21:20]
Swyx: Awesome. [01:21:21]
Alessio: And yeah, before wrapping, what's one message, one idea you want everyone to remember and think about? [01:21:27]
Jeremy: You know, I guess the main thing I want everybody to remember is that, you know, there's a lot of people in the world. And they have a lot of, you know, diverse experiences and capabilities. And they all matter. And now that we have a, you know, newly powerful technology in our lives, we could think of that one of two ways. One would be, gee, that's really scary. What would happen if all of these people in the world had access to this technology? Some of them might be bad people. Let's make sure they can't have it. Or one might be, wow, of all those people in the world, I bet a lot of them could really improve the lives of a lot of humanity if they had this tool. This has always been the case, you know, from the invention of writing, to the invention of the printing press, to the, you know, development of education. And it's been a constant battle between people who think that the distributed power is unsafe and it should be held on to by an elite few. And people who think that humanity on net, you know, is a marvelous species, particularly when part of a society and a civilization. And we should do everything we can to enable more of them to contribute. This is a really big conversation right now. And, you know, I want to see more and more people showing up and showing what, you know, what the great unwashed masses out there can actually achieve. You know, that actually, you know, regular people are going to do a lot of really valuable work and actually help us be, you know, more safe and also flourishing in our lives and providing a future for our children to flourish in. You know, if we lock things down to the people that we think, you know, the elites that we think can be trusted to run it for us, yeah, I think all bets are off about where that leaves us as a society, you know. [01:24:00]
Alessio: Yep. Now that's an important message. And yeah, that's why we've been promoting a lot of open source developers, open source communities, I think, letting the builders build and explore. That's always a good idea. Thank you so much for coming on, Jeremy. This was great. [01:24:20]
Jeremy: Thank you for having me. [01:24:22]