

[AINews] The Last 4 Jobs in Tech
a quiet day lets us examine an interesting mental model
It’s well known that org charts are changing with AI - the first trend we called out was in 2023 with the Rise of the AI Engineer (now an official org at Meta!), and then in 2025 with Tiny Teams (hired by Meta!), but it seems Yoni Rechtman over at the 99D Substack has the mental model for the new post-AI roles (at least in white collar tech):
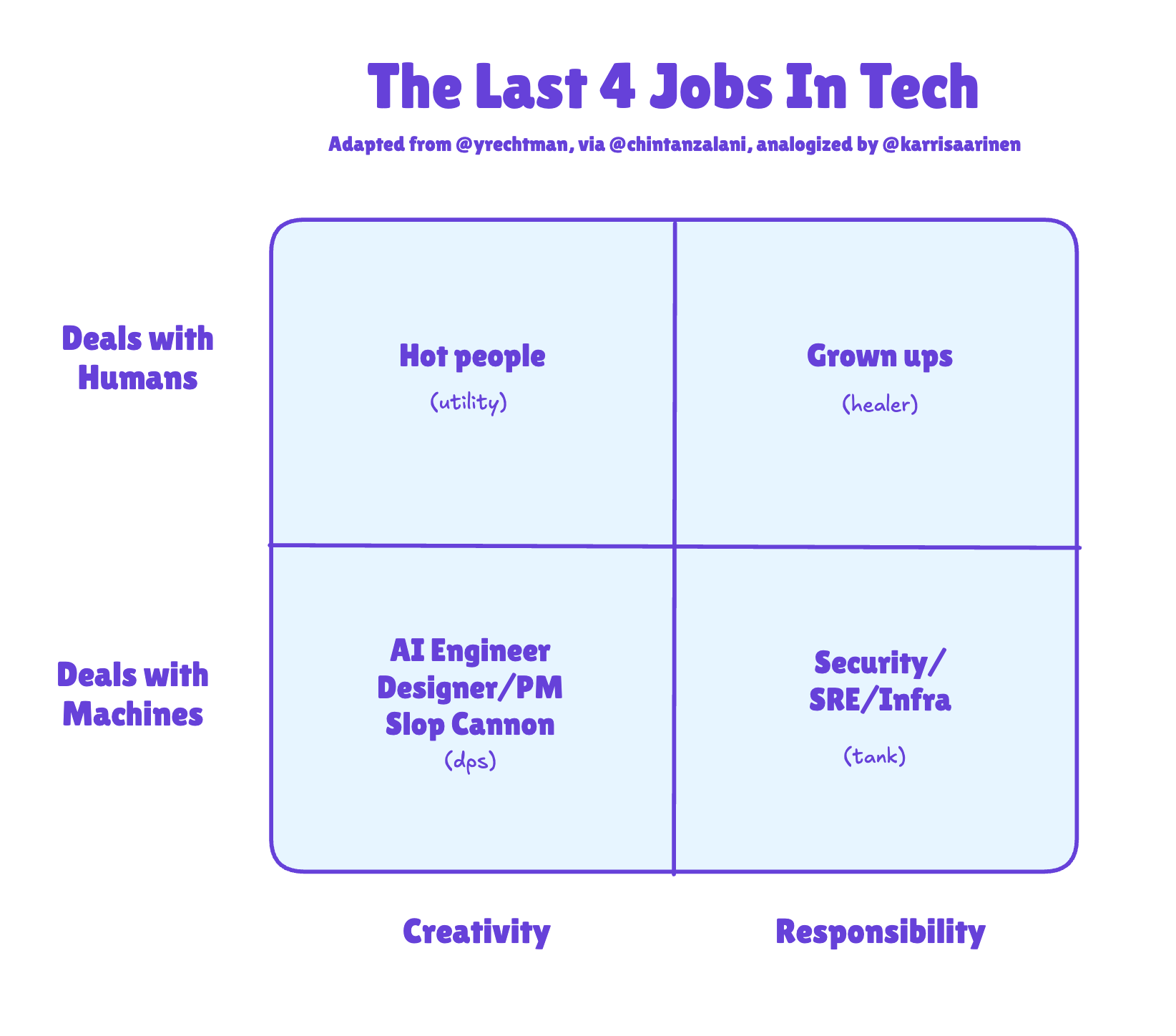
Karri Saarinen, CEO of Linear, made a popular analogy to the teamwork roles that emerged in World of Warcraft. This is a good 2D augmentation of an earlier age-based company model (much less realistic, name a tech company that fits the latter format, they exist but are very hard to find):
AI News for 3/28/2026-3/30/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
Claude Code Computer Use, Codex Interop, and the Coding-Agent Harness Race
Claude Code gets computer use: Anthropic added computer use inside Claude Code, letting the agent open apps, click through UIs, and test what it built directly from the CLI in research preview for Pro/Max users. The practical significance is closed-loop verification: code → run → inspect UI → fix → re-test, which several engineers called the missing piece for reliable app iteration, especially compared with open-ended desktop agents (Claude announcement, @Yuchenj_UW on the “eyes” unlock, @omarsar0).
Cross-agent composition is becoming standard: OpenAI shipped a Codex plugin for Claude Code that can trigger reviews, adversarial reviews, and “rescue” flows from inside Anthropic’s toolchain, using a ChatGPT subscription rather than custom glue code. This is notable less as a plugin novelty and more as a signal that coding stacks are becoming composable harnesses rather than monolithic products (plugin by @dkundel, usage thread by @reach_vb, open-source note). Separately, OpenAI shared that late-night Codex tasks run longer, with jobs started around 11pm being 60% more likely to run 3+ hours, which fits the emerging pattern of delegating refactors and planning to background agents (OpenAI Devs).
Harness quality is now visibly a first-order variable: Theo argued that Opus scores ~20% higher in Cursor than in Claude Code, and more broadly that closed-source harnesses make it hard for the community to diagnose or fix regressions (performance gap claim, closed-source critique). That theme repeated across the feed: model capability deltas are narrowing, while tooling, prompt/runtime orchestration, and review loops still create large practical differences.
Hermes Agent’s Rapid Rise, Multi-Agent Profiles, and the Open Harness Ecosystem
Hermes has become the week’s breakout open agent stack: Nous shipped a major Hermes Agent update that drove a wave of migrations from OpenClaw/OpenClaw-like setups, with users emphasizing better compaction, less bloat, stronger adaptability, and faster shipping cadence (Nous release, Teknium’s multi-agent profiles, community migration examples, another). The new multi-agent profiles give each bot its own memory, skills, histories, and gateway connections, moving Hermes from “personal assistant” toward a reusable agent OS abstraction.
An ecosystem is forming around traces, remote control, and self-improvement: Several projects extend Hermes beyond core inference. @jayfarei’s opentraces.ai provides a CLI/schema/review flow for sanitizing and publishing agent traces to Hugging Face for analytics, evals, SFT, and RL. @kaiostephens uploaded ~4,000 GLM-5 Hermes traces to HF. @IcarusHermes described an integration where agents log their own decisions, export data, fine-tune smaller successors on their history, and switch over to cheaper models. @winglian’s ARC adds remote browser-based monitoring/control with E2E encryption.
Open vs proprietary agent infra is being actively contested: @ClementDelangue explicitly argued that open-source agent tools should default to open-source models, both for privacy and durability. In parallel, vendors are attacking known pain points: @fchollet highlighted PokeeClaw as a more secure OpenClaw-style assistant with sandboxing, approvals, RBAC, and audit trails; Z AI launched AutoClaw, a local OpenClaw runtime with no API key required and optional GLM-5-Turbo.
Qwen3.5-Omni, GLM-5-Turbo/AutoClaw, and the Push Toward Local/Agentic Specialization
Qwen3.5-Omni is a major multimodal release: Alibaba introduced Qwen3.5-Omni, with native text/image/audio/video understanding, script-level captioning, built-in web search and function calling, and a standout “audio-visual vibe coding” demo where the model builds websites/games from spoken visual instructions. Reported capabilities include support for 10h audio / 400s of 720p video, 113 speech-recognition languages, and 36 spoken languages; Alibaba claims it outperforms Gemini 3.1 Pro in audio and matches its AV understanding in some settings (launch thread, demo thread, additional demo). A useful caveat from @kimmonismus: “omni” here is about interpreting multimodal inputs, not arbitrary multimodal generation.
Z AI continues to tune for agentic workloads: Artificial Analysis evaluated GLM-5-Turbo, Z AI’s proprietary agent-optimized variant. It scored 47 on the AA Intelligence Index, slightly behind open-weight GLM-5 (Reasoning) at 50, but posted 1503 on GDPval-AA, ahead of GLM-5’s 1408, supporting the claim that the model is tuned for real-world agent workflows rather than broad benchmark maximalism.
Specialized open models are increasingly the deployment pattern: Several tweets converged on the same thesis: companies will increasingly own and specialize open models on proprietary data rather than rent general-purpose APIs indefinitely (@oneill_c, @ClementDelangue). Supporting evidence ranged from a Qwen3.5-27B model distilled from Claude 4.6 Opus trending on HF for weeks and reportedly fitting on 16GB in 4-bit (Unsloth, @Hesamation) to growing enthusiasm for local runtimes like llama.cpp and MLX.
Local Inference and Systems: llama.cpp at 100k, Flash-MoE on MacBooks, and Web/Serving Toolchains
Local AI had a symbolic milestone with llama.cpp hitting 100k GitHub stars: @ggerganov’s reflection framed 2026 as potentially the breakout year for local agentic workflows, arguing that useful automation doesn’t require frontier-scale hosted models and that the right portable runtime stack matters more than absolute scale. The post also emphasized the importance of cross-hardware, non-vendor-locked infra.
Flash-MoE on Apple Silicon drew strong attention: A widely shared post claimed Qwen3.5-397B could run on a 48GB MacBook Pro at 4.4 tok/s using a pure C + Metal engine that streams weights from SSD and only loads the active experts, reportedly using ~5.5GB RAM during inference (summary thread). Related work includes anemll-flash-mlx, which focuses on optimizing only the MoE path on top of MLX, and AI Toolkit’s new Apple Silicon support.
Web and serving stacks also moved: Transformers.js v4 added a WebGPU backend across browser/Node/Bun/Deno with major perf gains and 200+ architectures. vLLM-Omni v0.18.0 shipped 324 commits, production TTS/omni serving, unified quantization, diffusion runtime refactors, and a dozen-plus new models. On the speech side, Artificial Analysis covered Cohere Transcribe: a 2B conformer encoder-decoder, Apache 2.0, trained on 14 languages, hitting 4.7% AA-WER and roughly 60x real-time transcription speed.
Agent Research: Natural-Language Harnesses, Meta-Harness, Async SWE Agents, and Long-Context via Filesystems
Harness engineering is becoming a research field of its own: A Tsinghua/Shenzhen paper on natural-language agent harnesses proposed letting an LLM execute orchestration logic from an SOP rather than hard-coded harness rules, a direction that multiple practitioners found mind-bending but plausible as context budgets rise (@rronak_ summary). Meta pushed the idea further with Meta-Harness, a method that optimizes the harness end-to-end over code, traces, and scores rather than just the base model; claims include #1 among Haiku agents on TerminalBench-2 and strong gains in text classification and transfer (@yoonholeee, explainer by @LiorOnAI).
Async/multi-agent SWE design got stronger empirical backing: The CAID paper from CMU argues for centralized asynchronous isolated delegation using manager agents, dependency graphs, isolated git worktrees, self-verification, and merges. Reported gains were +26.7 absolute on PaperBench and +14.3 on Commit0 versus single-agent baselines, suggesting that concurrency and isolation beat simply giving one agent more iterations (@omarsar0 summary).
Coding agents as long-context processors is one of the more interesting reframings: A paper highlighted by @dair_ai treats huge corpora as directory trees and lets off-the-shelf coding agents navigate them with shell commands and Python, rather than stuffing text into context windows or relying purely on retrieval. Reported results include 88.5% on BrowseComp-Plus (750M tokens) vs 80% previous best, and operation up to 3T tokens.
Training, Optimization, Evaluation, and Production Case Studies
Muon got a meaningful systems/math optimization: Gram Newton-Schulz is a drop-in replacement for Muon’s Newton-Schulz step that works on the smaller symmetric XXᵀ Gram matrix rather than the large rectangular matrix, reportedly making Muon up to 2x faster while preserving validation perplexity within 0.01. The work drew praise from @tri_dao as the kind of cross-disciplinary linear algebra + fast-kernel result that actually matters.
Two practical implementation details stood out: Ross Wightman flagged a subtle but important PyTorch
trunc_normal_misuse pattern in LLM training code: defaulta/bare absolute values, not standard deviations, so many codebases effectively aren’t truncating at all; he also noted numerical oddities later fixed in nightlies. At the application layer, Shopify’s DSPy case study was notable for economics: one slide highlighted a reduction from $5.5M to $73K/year by decomposing business logic, modeling intent with DSPy, and switching to a smaller optimized model while maintaining performance (follow-up).New evals/benchmarks continued to expose gaps: World Reasoning Arena targets hypothetical/world-model reasoning and reports a substantial gap to humans. Tau Bench’s new banking domain adds a realistic 698-doc support environment where best models still only solve about 25% of tasks. Meanwhile, a Stanford-led paper highlighted by @Zulfikar_Ramzan found sycophantic AI can increase users’ certainty while reducing willingness to repair relationships, underscoring that “helpfulness” metrics can obscure socially harmful behavior.
Top tweets (by engagement)
Claude Code computer use: Anthropic’s release was the biggest technical product launch in the set, and likely the most consequential for day-to-day coding-agent UX (announcement).
Claude Code hidden features: @bcherny’s thread drew massive engagement, reflecting how quickly expert users are now optimizing around coding-agent workflows rather than raw model prompts.
Hermes Agent update: The broad community response to Nous’s major Hermes release suggests open agent harnesses have reached a new adoption phase.
Qwen3.5-Omni launch: Alibaba’s multimodal release was one of the day’s biggest model announcements and especially notable for its practical demos around audio/video-driven app creation (launch).
llama.cpp at 100k stars: @ggerganov’s milestone post captured the local-first mood of the week: increasingly capable open models plus increasingly capable local runtimes.
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. Qwen Model Developments and Applications
Keep reading with a 7-day free trial
Subscribe to Latent.Space to keep reading this post and get 7 days of free access to the full post archives.