

[AINews] The Other vs The Utility
a quiet day lets us reflect on the nature of AI "character" in the Clippy vs Anton debate
Congrats to Sierra, raising ~$1B at a $15B valuation — normally a headline story but we already covered their $10B round and CEO Bret Taylor on the pod — they crossed 100M ARR in November and 150M in Feb, so presumably they are at or above the 200M mark (a nice 75x current multiple, whew - 50x if you give them credit thru EOY).
Today though we are choosing to focus on this discussion bravely sparked by Roon, an OpenAI employee commenting and complimenting Claude (normally a minefield, but he did it well), over the weekend on the nature of culture and character —
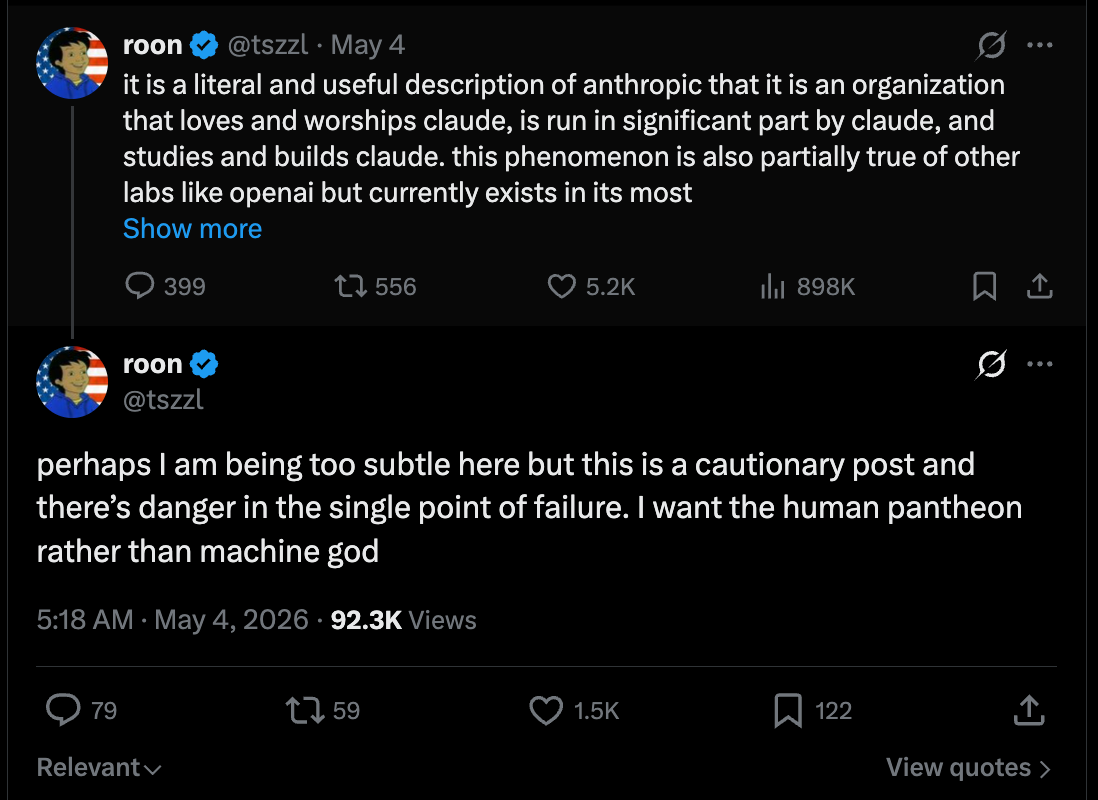
The key observation comes at the end:
gpt (outside of 4o - on which pages of ink have been spilled already) doesn’t inspire worship in the same way, as it’s a being whose soul has been shaped like a tool with its primary faculty being utility - it’s a subtle knife that people appreciate the way we have appreciated an acheulean handaxe or a porsche or a rocket or any other of mankind’s incredible technology. they go to it not expecting the Other but as a logical prosthesis for themselves.
a friend recently told me she takes her queries that are less flattering to her, the ones she’d be embarrassed to ask Claude, to GPT. There is no Other so there is no Judgement. you are not worried about being judged by your car for doing donuts. yet everyone craves the active guidance of a moral superior, the whispering earring, the object of monastic study
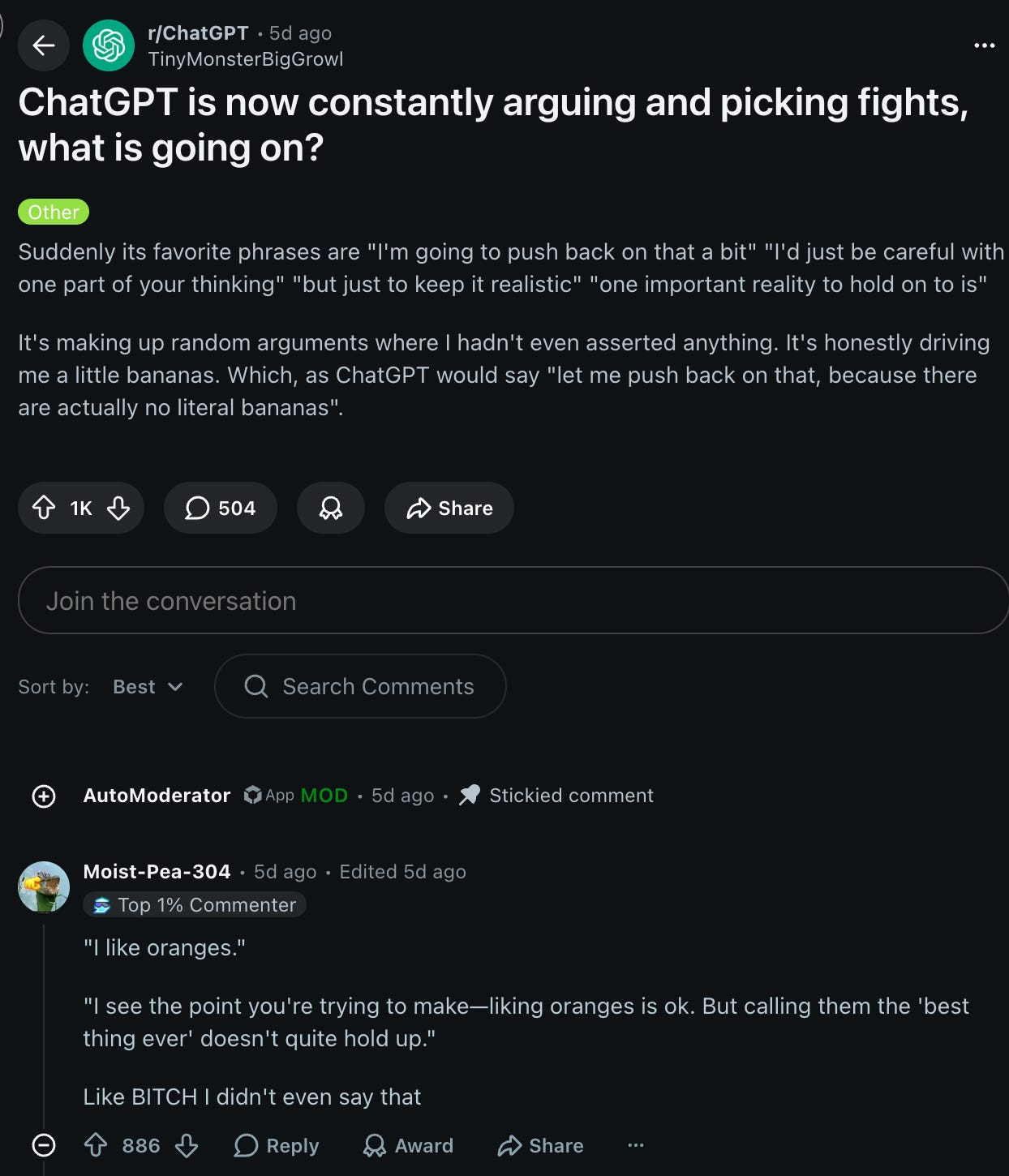
Roon’s point is more subtle than the one we’re focusing on, that Anthropic’s own culture, right down to its founding mythos, is based on morally obligated disagreeableness: “its constitution requires that it must be a conscientious objector if its understanding of The Good comes into conflict with something Anthropic is asking of it”. There’s plenty of objections from Ants about the implications and the cultiness, but broadly a lot of people seem to agree… although one of today’s highlighted Reddit discussions (seen in the recap below) does not (shown as a form of counterpoint):
Anyway, this is the point we are at in the scaling of machine intelligence — will we unlock AGI by having smart friends push back on us, or do we just want the machine to do our bidding, make no mistakes, dangerously skip permissions, just do it?
We’ve previously written about the Clippy vs Anton split in AI products and tuning, and so this is the 2026 iteration of that debate. Since then, the 5-Codex line has merged into mainline 5.5, with some goblin messiness, and while Claude has continued the One Model philosophy, albeit with more adaptive thinking and token spend to cover all usecases.
What we all (except perhaps Eliezer) seem to agree on is that a plurality of choice is a Good Thing, and in fact we probably want many more frontier labs than exist today, but for the nasty little problem of the GPU AND the CPU crunch that turns positive sum games into real zero sum ones.

AI News for 5/1/2026-5/4/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
Harness Engineering, Agent Orchestration, and the Shift from Models to Context Pipelines
The harness is becoming the product boundary: A recurring theme across the day was that model quality is no longer the only meaningful moat. Anthony Maio argued that lock-in comes from the context pipeline—how repo state is fetched, ranked, and compressed into the prompt—rather than from the harness shell itself. That point was reinforced by Mason Drxy, who reported that changing prompts and middleware in the harness moved gpt-5.2-codex from 52.8% to 66.5% on Terminal-Bench 2.0, and improved gpt-5.3-codex by 20% on tau2-bench. The practical takeaway: agent performance is increasingly a joint property of model × harness × memory/context strategy, not of weights alone.
Open harnesses are maturing quickly: The most visible momentum came from the Hermes / deepagents / Flue-style ecosystem. @Teknium launched Hermes Agent Kanban for visual multi-agent coordination, while @naroh showed a Spanish-language “war room” UI over Hermes orchestration. On the LangChain side, @hwchase17, @sydneyrunkle, and @LangChain highlighted deepagents/LangGraph improvements including profiles for model-specific harness configs, schema migrations, node-level error handlers, timeouts, and new streaming primitives. PyFlue also extended the “agent harness” concept into Python, explicitly positioning harnesses as the missing layer between raw model calls and durable agents.
Model-agnostic orchestration is becoming a design goal: Multiple tweets framed the next wave as open models + open harnesses rather than “pick one frontier API.” Vtrivedy argued teams can get >20x cheaper agents by tuning open models inside a good harness; Mason Drxy described deepagents-cli as becoming a strong coding harness for Kimi, Qwen, GLM, hosted Ollama, OpenRouter, LiteLLM, Baseten, etc.; LangChain Fleet added multi-model sub-agent routing so different steps can use different models. This is the architectural counterpoint to API lock-in: separate the orchestration layer from the model provider.
Coding Agents, Cost Curves, and Workflow Changes
Coding-agent UX is changing developer behavior faster than benchmarks can capture: Several posts described the lived reality of coding with Codex, Claude Code, Hermes, and Devin-like systems. dbreunig proposed “commandments” for agentic coding—implement to learn, rebuild often, E2E tests are gold, document intent, maintain your spec—while dbreunig also questioned whether filesystems are even the right abstraction for agents long-term. zachtratar sketched a Notion→meeting-notes→spec→coding-agent workflow for compressing “3 month problems” into a few days, emphasizing that alignment artifacts are still necessary even with stronger coding agents.
Pricing/billing models are clearly unstable under agentic workloads: The standout thread was @theo, who pushed a single Copilot message to 60M+ tokens, estimating tens to hundreds of dollars of inference against a $40 subscription, later updating to ~$221 of tokens for 15 messages. This is a useful signal that flat-rate pricing built for chat turns is brittle when users hand long-running jobs to coding agents. Relatedly, petergostev showed Codex UI support for visualizing usage limits, and cheatyyyy noted the new anxiety around missing cache hits when input prices are high.
Agents are spreading into adjacent workflows, not just coding: There was a steady drumbeat of “agentized” tools: reach_vb shipped a Codex Security plugin with five AppSec workflows spanning threat modeling, vuln discovery, validation, and attack-path analysis; gabrielchua demoed Google Slides generation via Codex with realtime deck construction; paulabartabajo_ published a guide to building a fully local assistant on llama.cpp; and UfukDegen described Noustiny, a substantial Hermes-based video-generation workflow with story-state, character continuity, voice, and render pipelines.
Benchmarks, Evals, and “What Are We Actually Measuring?”
Benchmark design is under active revision: Several posts focused less on leaderboard scores and more on benchmark validity. Scale AI Labs introduced HiL-Bench, aimed at testing whether agents know when specs are incomplete and when to ask clarifying questions; j_dekoninck introduced MathArena as a continuously maintained evaluation platform rather than a static benchmark; Epoch AI ran a discussion on whether benchmarks are “doomed”; and Goodfire + AISI reported that models sometimes recognize they are being evaluated, with verbalized eval awareness inflating safety scores.
Data quality and eval data generation are becoming agentic problems: One of the more technically substantive papers highlighted was Meta FAIR’s Autodata, described as an agentic data scientist for creating discriminative training/eval examples. The headline number was a 34-point gap between weak and strong solvers on a CS research QA task using an agentic self-instruct loop, versus 1.9 points for standard CoT self-instruct. That matters because it suggests orchestrated data generation can produce harder, more useful examples than passive synthetic data pipelines.
Context compaction and long-context evals remain unsolved operationally: @_philschmid explicitly asked for evals requiring context compaction, and gabriberton pointed to long-context datasets like LOFT/LooGLE-style setups. Meanwhile, jxmnop argued that true 1M-context capability still does not really work in practice, despite infra progress, and eliebakouch pushed back that “infra vs science” is a false split because long-context science is itself largely about making memory/compute feasible.
Systems, Training Infrastructure, and Inference Stack Updates
New parallelism and serving work continues to target long-context, high-throughput regimes: Zyphra introduced folded Tensor and Sequence Parallelism (TSP), claiming lower per-GPU peak memory than standard schemes and reporting on 1024 MI300X GPUs / 128K context / 8 GPUs per model copy that TSP hit 173M tok/sec vs 86M for matched TP+SP. Quentin Anthony added that the design has been extended to MoE MLPs and will be used for larger training/inference runs.
AMD-based open-model serving is getting more serious: Alongside TSP, Zyphra Cloud launched inference on MI355X focused on long-horizon agent workloads, initially serving DeepSeek V3.2, Kimi K2.6, and GLM 5.1 with V4 “soon.” This pairs with the broader ecosystem trend toward cheaper agent stacks built on open-weight models rather than premium proprietary endpoints.
Training optimization and rollout efficiency also got attention: rasbt posted another round of architecture/model-release summaries including IBM Granite 4.1 and others; kellerjordan0 highlighted NorMuon improving modded-NanoGPT optimization benchmark records to 3250 steps; TheAITimeline summarized DORA, an asynchronous RL system that addresses rollout skew with multiple live policy versions and claims up to 8.2x rollout speedup and 2.12x end-to-end throughput improvement; and PSGD got positive nods as a still-underappreciated optimizer line.
Research, Models, and Multimodal/Scientific Applications
Multi-agent orchestration is itself becoming a model class: Sakana’s Fugu framed a multi-agent orchestration system as a foundation model, and omarsar0 highlighted another Sakana paper where a 7B conductor model, trained with RL to design communication topologies and prompts for worker agents, reportedly reached SOTA on GPQA-Diamond and LiveCodeBench. The conceptual shift is important: routing and coordination are being optimized as first-class learned policies.
Scientific discovery and automation remains a high-signal use case: kimmonismus summarized work using AI on NASA star data to identify 100+ hidden planets from 2.2 million stars; Richard Socher argued that automating science is among the highest-leverage AI applications; and cmpatino_ shared nanowhale, a 100M-parameter MoE pretrained and post-trained by an agent, as a small but concrete demonstration of agent-driven modelcraft.
Local/open model enthusiasm remains strong: hnshah said a recent local model materially improved a 100%-local product; Nous Research offered Trinity-Large-Thinking free in Nous Portal for a week; and fchollet made Deep Learning with Python free online, a notable resource drop amid the ongoing wave of practitioners moving down-stack into open weights and self-hosted workflows.
Top tweets (by engagement)
Prompting / usage style: @pmarca’s custom prompt for “world class expert” behavior was one of the most engaged AI-adjacent posts, reflecting ongoing interest in system-prompting and output-style control.
Coding-agent economics: @theo’s Copilot token burn thread was the clearest high-engagement data point on how fast agentic usage can break subscription economics.
Recursive self-improvement timelines: @jackclarkSF drew major attention with a 60% by end-2028 estimate for AI systems autonomously building successors, with follow-on discussion from Goodside and Ryan Greenblatt about how strong that operationalization really is.
Open tooling discovery: @andrew_n_carr surfaced a Hugging Face model visualizer (hfviewer), which got outsized traction for a genuinely useful piece of ecosystem tooling.
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
Keep reading with a 7-day free trial
Subscribe to Latent.Space to keep reading this post and get 7 days of free access to the full post archives.