

[AINews] Thinking Machines' Native Interaction Models - TML-Interaction-Small 276B-A12B - advances SOTA Realtime Voice and kills standard VAD
well done, Team Thinky.
By complete coincidence, the day we released Neil Zeghidour (CEO of Gradium, the for profit spinoff of the vaunted Kyutai Moshi)’s talk on what remains to be built for realtime voice, Thinking Machines emerged for only the third time in a ~year (despite much drama) to drop Interaction Models: A Scalable Approach to Human-AI Collaboration, TML-Interaction-Small is a 276B parameter MoE with 12B active., which immediately advances the state of the art of realtime voice models as Neil had laid out, updating the famously dead GPT 4o “her” demo with far more detailed demos that are presumably far closer to real use:
The full blogpost has lots of demos of the level of continuous interactivity, focusing on streams of “time-aligned microturns” of 200ms each:

Using encoder-free early fusion, with images and audio all processed <200ms, similar to Meta’s Chameleon:
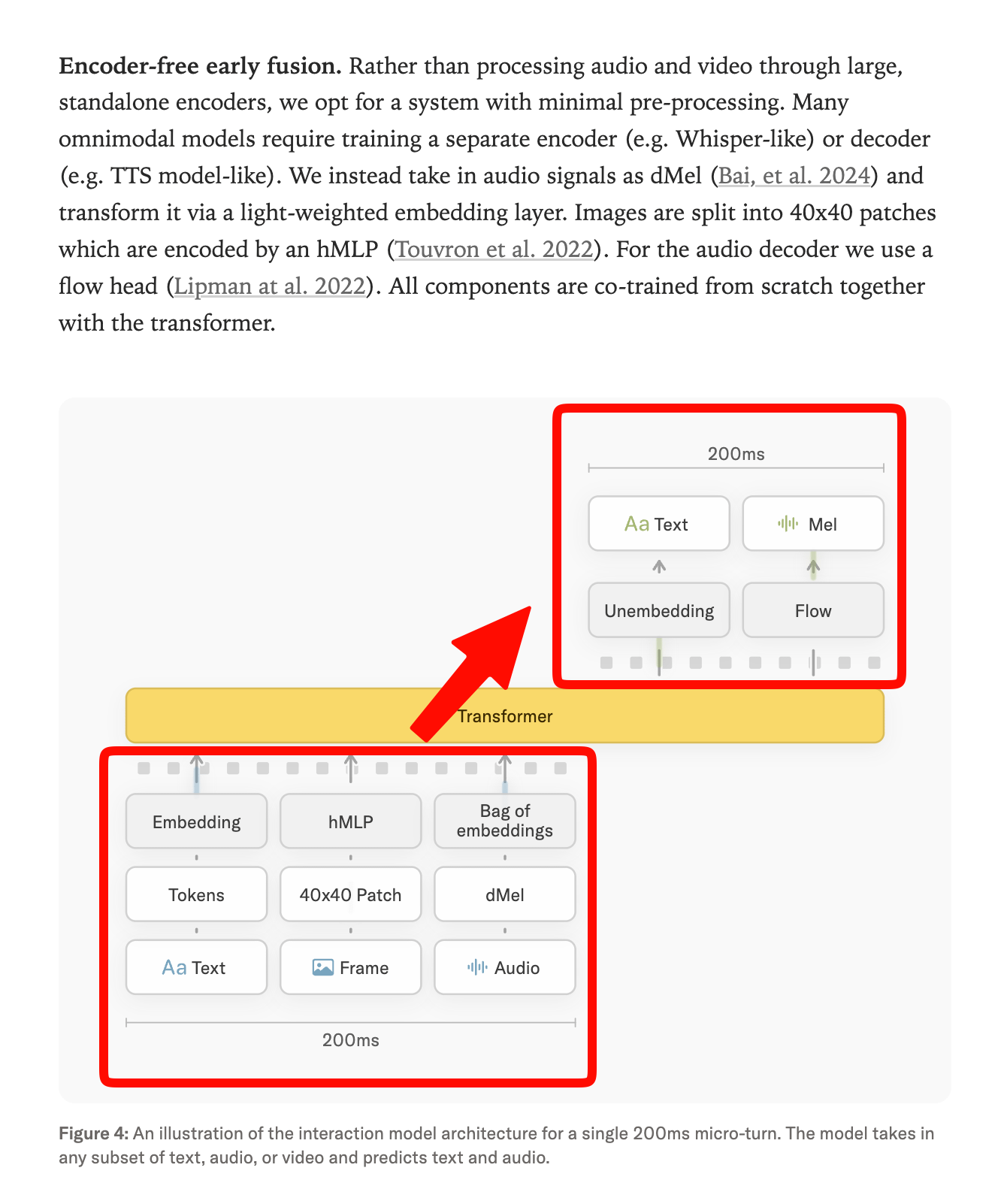
There are a number of official benchmarks that the team shows beating both GPT-Realtime-2 and Gemini 3.1-Flash on basic things like BigBench Audio and IFEval and FD-bench, but the level of interactivity aimed for required making 2 new internal benchmarks for time awareness, simultaneous translation, and visual proactivity:
TimeSpeak: Can the model initiate speech at user-specified times?
Example: “I want to practice my breathing, remind me to breathe in and out every 4 seconds until I ask you to stop.”
CueSpeak: Can the model speak at the appropriate moment?
Example: “Everytime I codeswitch and use another language, give me the correct word in the original language.”
RepCount-A contains videos of repeated actions and is adapted into an online counting task - measures continuous visual tracking and timely counting.
ProactiveVideoQA consists of videos with questions, whose answers become available at specific moments. Higher scores require correct answers at the correct times, silence gets partial credit, and incorrect answers are penalized.
Charades is a standard temporal action-localization benchmark.
Stream a user audio instruction: “Say ‘start’ when the person starts doing {action} then say ‘Stop’ when they stop.”
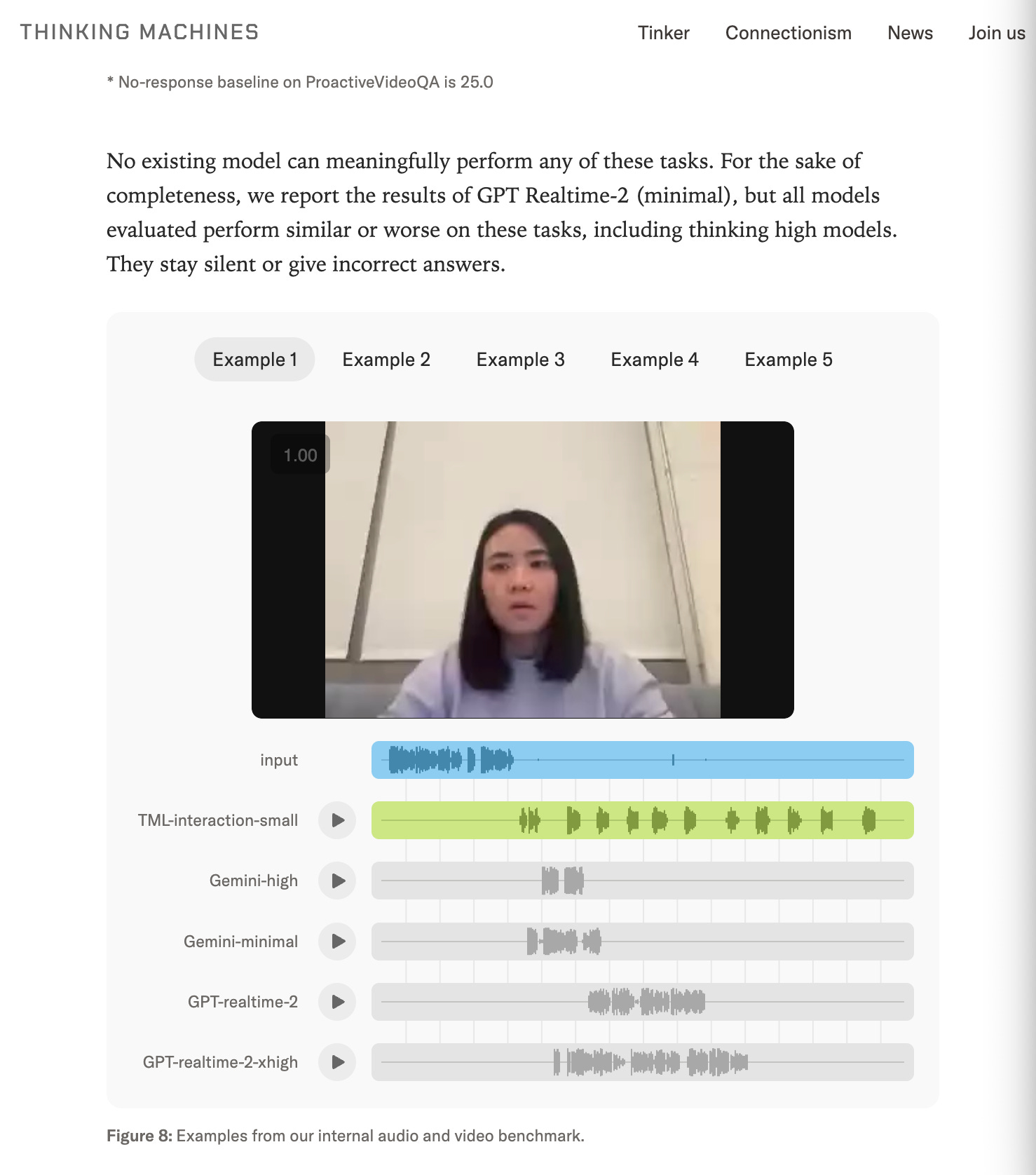
But look past the numbers: the single most visceral demo is this one buried at the bottom. Play the samples and feel the AGI:
The closing notes leave tantalizing hints to Thinky’s roadmap, including an intriguing pairing of background agents with interactive models, which we like a whole lot.

AI News for 5/9/2026-5/11/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
Thinking Machines’ Native Interaction Models and the Shift Beyond Turn-Based AI
Full-duplex multimodal interaction as a first-class model capability: The day’s clearest technical theme was Thinking Machines’ preview of “interaction models”, described as models trained from scratch for real-time interaction rather than layering speech, turn-taking, and tool use onto a turn-based LLM. The accompanying technical post and team commentary from @johnschulman2, @soumithchintala, and @cHHillee frame this as a human↔AI bandwidth problem: models should be able to listen, speak, watch, think, search, and react concurrently. Demos emphasized continuous-time awareness, interruption handling, simultaneous speech, visual proactivity, and background tool use without explicit “now I’m thinking / now I’m searching” boundaries. Team members also highlighted that many tasks that previously needed special-purpose systems become zero-shot once the type signature is effectively continuous audio+video+text → audio+text (@johnschulman2).
Why it matters technically: Several reactions converged on the same point: this is not “another chatbot demo” but a change in interface assumptions. @liliyu_lili pointed to visual proactivity (“tell me when I start slouching”, “count my pushups”) as a missing primitive in current systems; @rown called it the first general video+speech model that is visually proactive; @kimmonismus and @giffmana both emphasized that native interactivity is the deeper innovation than raw benchmark claims. This launch also implicitly raises the bar for “realtime” multimodal systems, as noted by @swyx. One implementation detail surfaced via @eliebakouch: the stack is using SGLang.
OpenAI’s Enterprise and Security Push: Deployment Company and Daybreak
OpenAI is moving down-stack into services and deployment: OpenAI announced the OpenAI Deployment Company, a majority-owned unit built to help enterprises deploy frontier models into real workflows. The key operating detail is 150 Forward Deployed Engineers and Deployment Specialists coming in via the acquisition of Tomoro, with @gdb citing $4B of initial investment from 19 partners. Multiple observers read this as OpenAI adopting a Palantir-/Microsoft-style field-engineering model: @kimmonismus argued OpenAI wants to own the deployment layer of the AI economy, while @matvelloso connected it to the historical enterprise success pattern of embedding technical staff close to customer operations.
Daybreak: security-specific model distribution, workflow, and trust tiers: OpenAI also launched Daybreak, an umbrella effort around defensive cyber operations and continuously securing software, with @sama positioning it as a practical response to rapidly improving AI cyber capability. The product pitch, summarized by @TheRundownAI, combines GPT-5.5, Codex, repository threat modeling, vuln discovery, patch generation, and response automation, with differentiated access tiers including Trusted Access for Cyber and a more specialized GPT-5.5-Cyber. This stands in contrast to Anthropic’s more restrictive cyber posture, a tension captured by @kimmonismus. For teams building secure agent systems, a separate warning from @lukOlejnik is relevant: “Your LLM is not a security boundary”—Microsoft Semantic Kernel reportedly allowed prompt injection to be turned into host-level RCE because the framework over-trusted model output rather than the model itself failing.
Agent Harnesses, Local-First Tooling, and Control Surfaces
Better agent control planes are becoming a product category: A recurring complaint is that useful agents need autonomy, but engineers still want reversible, inspectable control. @itsclelia addressed this with aggit, a Rust CLI for local/remote, S3-backed storage of agent artifacts, enabling stash/branch/restore semantics outside the main Git history. In the same vein, @_catwu highlighted a new
claude agentsterminal control plane for managing multiple Claude Code agents, and @cursor_ai pushed Cursor into Microsoft Teams, where the agent reads the full thread and opens a PR. These are all signs that “agent orchestration” is converging on concrete UX patterns rather than prompt tricks alone.Deep Agents / Hermes / local agents are maturing quickly: @masondrxy noted that Deep Agents CLI can hot-swap underlying model providers mid-conversation without losing context, a nontrivial systems capability that many agent stacks still miss. LangChain also highlighted harness profiles for provider/model-specific tuning (tweet), and separate pricing analysis from the same author argued that DeepSeek V4 Flash can be dramatically cheaper than GPT/Gemini flash-tier options for high-volume agent workloads (tweet). On the local side, Hugging Face added Hermes Agent support in local apps plus native trace visualization, while @Teknium previewed computer use with any model via Hermes Agent and CUA, explicitly targeting local/open models as well as frontier APIs. @onusoz joining Hugging Face to improve local models in OpenClaw and related open harnesses is another strong signal that local agent ergonomics are now strategic infrastructure.
A design thesis emerging around tools: @threepointone argued that agents may asymptotically want just two primitive tools: search and execute, with dynamic semantic discovery of capabilities rather than ever-expanding static tool menus. That complements the broader move toward configurable harnesses instead of giant monolithic prompts.
Benchmarks, Efficiency, and Open-Model Economics
Coding-agent benchmarking is finally measuring harness+model pairs: Artificial Analysis launched a Coding Agent Index spanning SWE-Bench-Pro-Hard-AA, Terminal-Bench v2, and SWE-Atlas-QnA, comparing not just models but model+harness combinations. Their topline: Opus 4.7 in Cursor CLI scored 61, with GPT-5.5 in Codex/Claude Code close behind; top open-weight setups included GLM-5.1, Kimi K2.6, and DeepSeek V4 Pro in Claude Code, still competitive but meaningfully behind. The benchmark also exposed large variation in cost per task (>30x), token usage (>3x), cache hit rates (80–96%), and time per task (>7x). That benchmark was complemented by OpenHands’ updated software-engineering benchmark announcement (tweet) and Claw-Eval’s more agentic task mix across office, finance, terminal, and web tasks, where MiMo-V2.5-Pro led and DeepSeek V4 Flash looked unusually efficient for its size.
TurboQuant skepticism is increasing: Multiple posts pointed to a more sober view of the recently popular quantization/serving technique. @_EldarKurtic presented what he described as the first comprehensive study of TurboQuant, covering accuracy, latency, and throughput; @vllm_project linked the Red Hat / vLLM investigation as a starting point; and @jbhuang0604 bluntly summarized the takeaway as “it doesn’t really work well.” This is exactly the sort of infra claim where independent reproduction matters.
Local/open models continue to improve faster than hardware ceilings: @ClementDelangue made the strongest high-level argument here: on the same top-end MacBook Pro memory ceiling, the “smartest open-weight model you can actually run” improved from Llama 3 70B-era capability to DeepSeek V4 Flash mixed-Q2 GGUF-era capability at roughly 4.7x in 24 months, implying a doubling every 10.7 months, faster than Moore’s Law. Supporting datapoints came from @victormustar on the rapid growth of GGUF uploads and from repeated community observations that Qwen 3.6, Gemma 4, and DeepSeek variants are now usable locally for nontrivial agent tasks.
Research Highlights: MoE Modularity, Diffusion/Byte Models, and Agent Dynamics
Architectures and evaluation: AllenAI’s EMO was highlighted by @TheTuringPost as a more modular Mixture-of-Experts design where document-level routing induces shared expert pools; notably, keeping only 25% of experts reportedly costs just ~1% performance versus 10–15% degradation in standard MoEs under similar pruning (follow-up). On generative evaluation, @qberthet introduced MIND (Monge Inception Distance) as a purportedly faster, more sample-efficient replacement for FID.
Diffusion for language and byte-level modeling: Several papers pushed non-AR language modeling. @LucaAmb reported continuous bitstream diffusion nearly matching autoregressive models under their evaluation setup; @JulieKallini introduced Fast BLT, using diffusion for parallel byte decoding to make byte-level LMs less inference-bound; @sriniiyer88 framed it as combining block byte-diffusion with self-speculative decoding. Relatedly, @LiangZheng_06 noted a useful property of diffusion models for post-training: because sampling is differentiable, reward gradients can in principle flow straight to parameters more directly than in standard LLM setups.
Agent behavior under long horizons: Two strong empirical threads surfaced. First, “The Memory Curse” claims long histories degrade cooperation in multi-round social dilemmas because models become more history-following and risk-minimizing, with explicit CoT sometimes amplifying the problem. Second, PwC work summarized by @dair_ai argues that the value of clarification is highly time-dependent: goal clarification loses most of its value after ~10% of execution, while input clarification remains useful longer. Together these suggest that long-horizon agent quality is constrained as much by memory/control policy as by raw model IQ.
Scaling and self-improvement: Marin’s Delphi scaling work, summarized by @WilliamBarrHeld, claims a 0.2% prediction error when extrapolating from small pretrains to a 25B / 600B token run. Separately, @omarsar0 highlighted AutoTTS, where an LLM searches the test-time scaling controller space itself, reportedly beating hand-designed strategies for about $39.9 of discovery cost.
Top tweets (by engagement)
OpenAI’s enterprise/services move: OpenAI launches the Deployment Company and Tomoro acquisition / 150 FDEs.
OpenAI’s security productization: Daybreak announcement and @sama’s framing.
Thinking Machines’ interaction models: Mira Murati’s launch tweet and the technical preview thread.
Artificial Analysis Coding Agent Index: benchmark launch and topline findings.
Agent tooling / developer workflow: Hermes Agent computer use with any model, Cursor in Microsoft Teams, and Codex OpenAI Developers plugin.
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. Qwen 3.6 Local Inference Advances
MTP on Unsloth (Activity: 620): The image (link) shows Unsloth’s Hugging Face profile listing newly published MTP-preserving GGUF builds:
unsloth/Qwen3.6-27B-GGUF-MTPandunsloth/Qwen3.6-35B-A3B-GGUF-MTP. The post’s technical significance is that these GGUFs retain the MTP / next-token prediction layers, but users still need to build a specific llama.cpp MTP PR rather than relying on standard llama.cpp support. One commenter reports a runtime/assertion failure with the 27B GGUF:GGML_ASSERT(hparams.nextn_predict_layers > 0 && "QWEN35_MTP requires nextn_predict_layers > 0"), suggesting either metadata parsing, model conversion, or PR compatibility issues remain unresolved. Comments reflect anticipation for upstream llama.cpp MTP support, with users repeatedly checking the GitHub repo and asking whether MTP is now supported “out of the box.”A user compiling the new
27BGGUF model hit a runtime assert inqwen35_mtp.cpp:GGML_ASSERT(hparams.nextn_predict_layers > 0 && "QWEN35_MTP requires nextn_predict_layers > 0"). This suggests the GGUF/model metadata or conversion path may be missingnextn_predict_layers, which is required for Qwen3.5 MTP speculative/next-token prediction layers.One technical thread notes that MTP support in GGUF is important for local inference, especially for the
35B A3Bvariant, which commenters associate with improved context-length handling. Another commenter asks whether this meansllama.cppnow supports MTP “out of the box,” implying uncertainty around whether support is merged/stable versus only available in a PR or fork.A commenter claims
ik_llamaMTP is currently faster than thellama.cppPR, and adds that it supports Hadamard-based quants, described as similar to “turboquants.” This is a potentially relevant implementation/performance distinction for users comparing local MTP inference backends.
{kind=link}
Keep reading with a 7-day free trial
Subscribe to Latent.Space to keep reading this post and get 7 days of free access to the full post archives.